模型介紹
在 Transformer 之前,主流的序列模型是 **RNN(循環神經網絡)**工作方式類似「逐字閱讀」:處理序列時,必須從第一個詞開始,一個接一個往后算(比如翻譯時,先看 “我”,再看 “愛”,再看 “你”,不能同時看三個詞)。
這種串行計算有兩個致命問題:
- 推理速度慢:因為無法實現并行計算,對于長文章來說,處理效率極低
- 長距離依賴差:比如一句話的開頭和結尾有邏輯關聯(如 “小明…… 他……”),但 RNN隔得太遠就會 “記不清”。
對于翻譯任務來說,文字之間存在語法關系,如果只是按照串行方式進行翻譯,最終得到的翻譯序列會是一個語法混亂的序列
而 Transformer 徹底拋棄了循環結構,改用 注意力機制 實現「并行計算」,同時能直接捕捉任意兩個詞之間的關聯(無論距離多遠)。這就是它能在 NLP 任務中碾壓前任的核心原因。
整體模塊介紹
模塊由兩部分組成:編碼器、解碼器,一個模型中含有n個結構相同的編碼器和解碼器(可以自己定義數量)
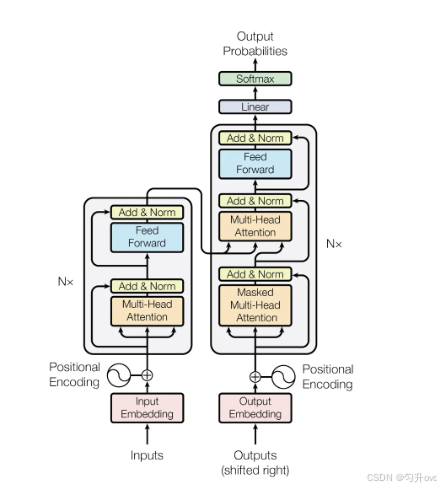
以翻譯任務為例:
編碼器負責對原始文字序列的語義特征進行提取
解碼器負責預測原始文字序列對應的目標文字序列
分模塊解析
編碼器
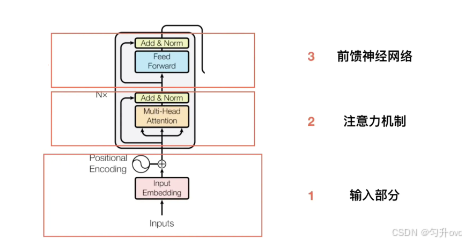
輸入部分
編碼器的原始輸入是一段文字序列,比如"我愛你"在輸入部分有兩個關鍵預處理步驟,分別是:
- 詞嵌入(Embedding)
- 位置編碼(Positional Encoding)
詞嵌入(Embedding)
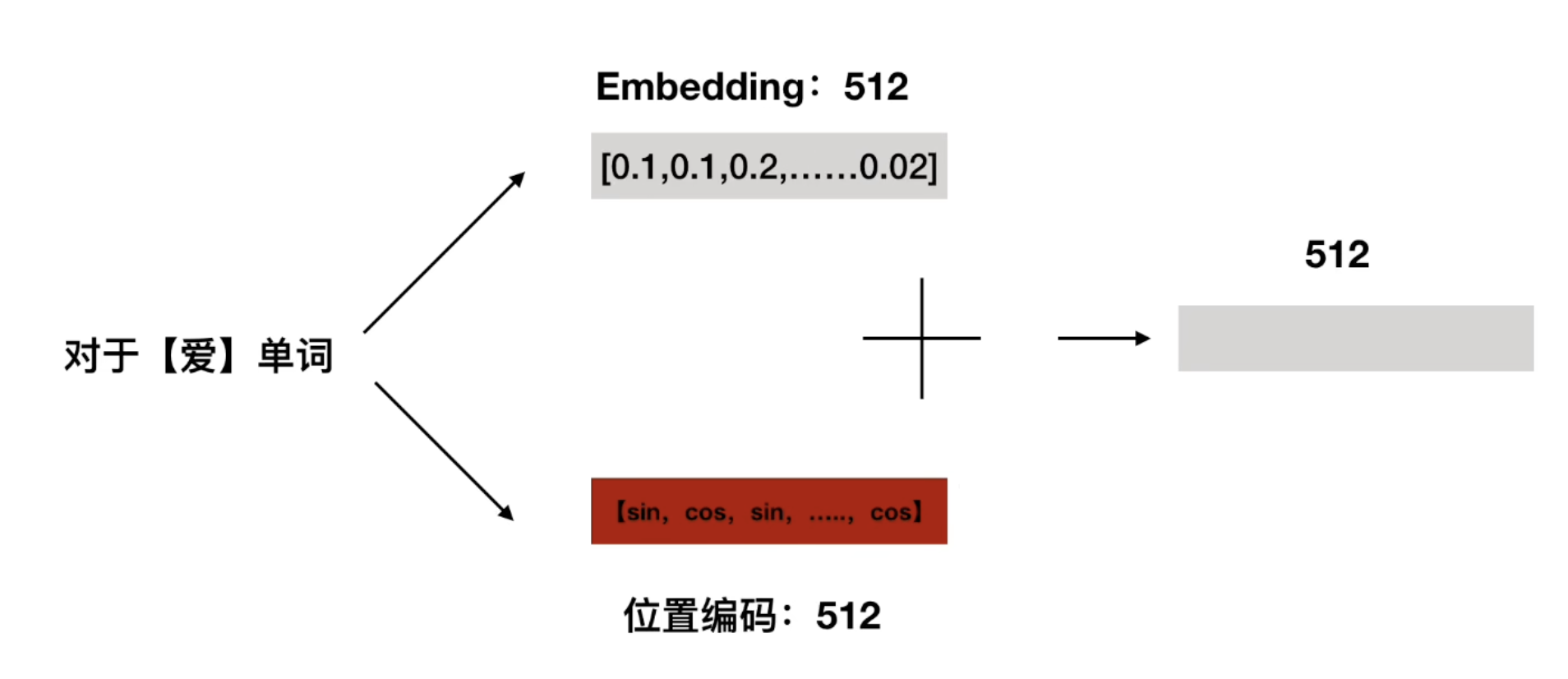
這部分是將原始輸入序列轉變成計算機能理解的詞**向量,**如 “我”→ [0.2, 0.5, -0.1]),讓計算機能理解;要注意的是,在初始時,詞向量是隨機生成的,并將隨機數定格在某個范圍內,在訓練時會經過反向傳播動態調整詞向量
對于"我愛你",初始時可能會轉變成[[0.2, 0.5, -0.1],[0.1, 0.3, -0.2],[0.5, 0.2, -0.2]]
位置編碼(Positional Encoding):
為每個詞向量生成**"位置信息",原因是**Transformer 并行處理,本身不知道詞的順序,加入位置編碼后可以在訓練過程中逐漸學習到每個詞的先后順序關系位置編碼的生成公式
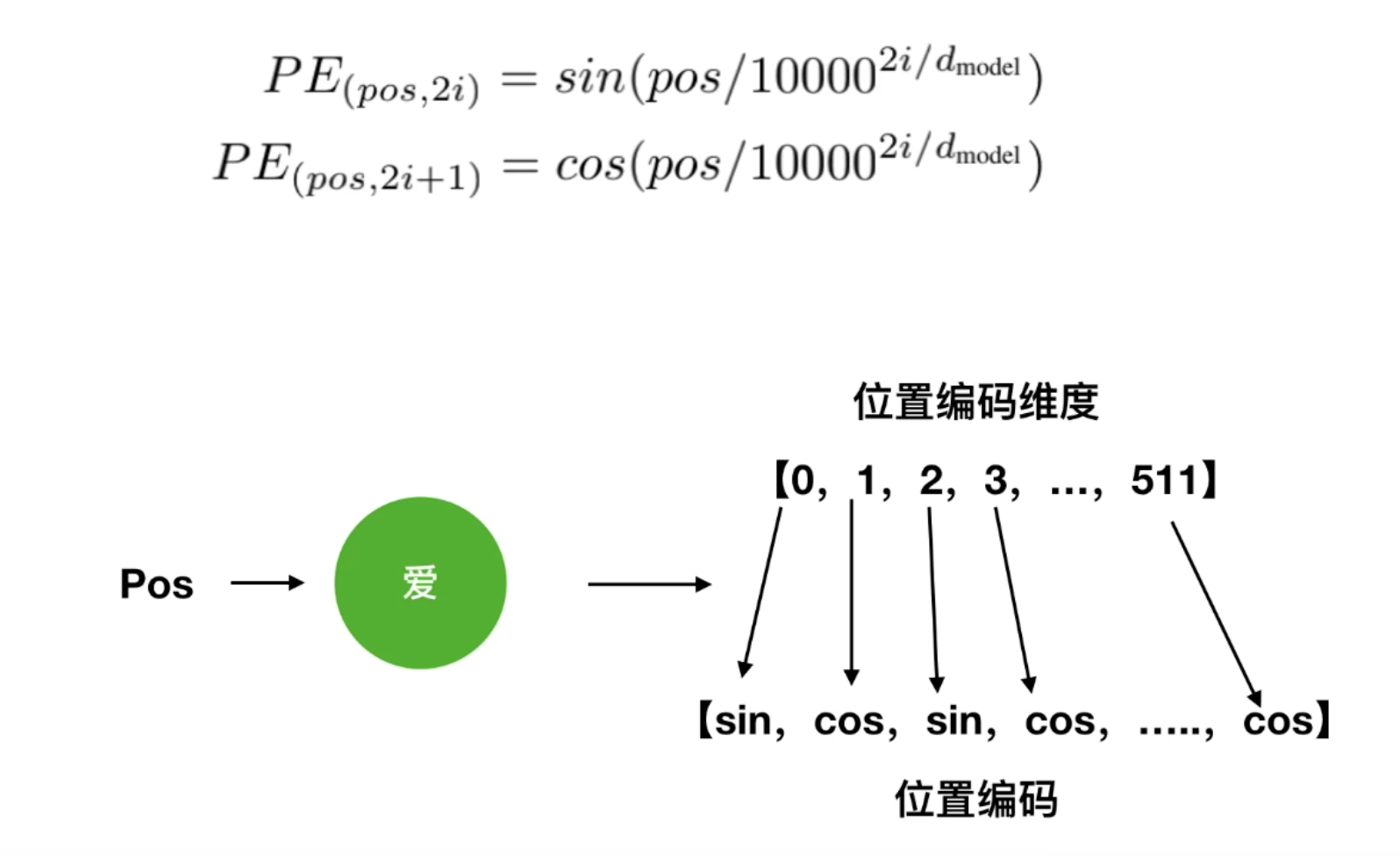
pos表示的是當前詞在整個輸入序列中的位置,例如"我"的pos為0,“愛”的pos為1
2i和2i+1中的i表示的是某個詞向量的第i個維度,以上面的例子,一個詞被分為了512個維度。
而2i表示為偶數的維度,2i+1表示為奇數的維度
為什么要這樣做呢,因為這個公式蘊含著詞匯之間的相對關系

所以在訓練調整權重時,模型能根據輸入向量之間的數學關系來學習他們之間的位置關系
在計算完位置編碼后,將詞向量與位置編碼進行相加,得到的新向量就是編碼器的第二個模塊注意力機制的輸入
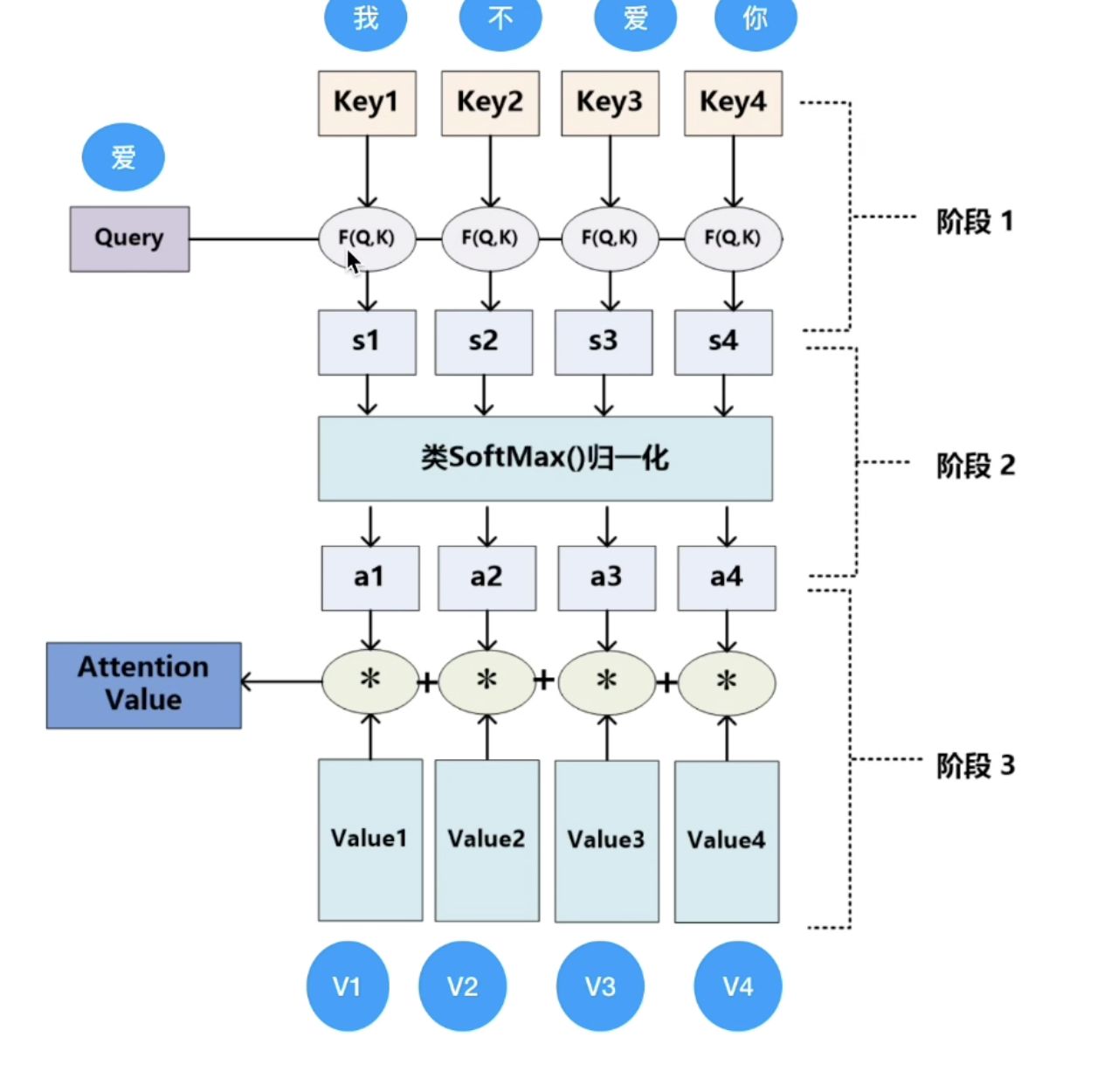
多頭自注意力機制
自注意力機制是 Transformer 的靈魂,作用是:**讓輸入序列中的每個詞,都能 “看到” 其他詞,并計算它們之間的關聯度**。舉個例子:輸入 “貓坐在墊子上,它很舒服”,“它” 指的是 “貓”,自注意力會讓 “它” 重點關注 “貓”,而不是 “墊子” 或 “舒服”。
自注意力機制的計算步驟是這樣的:
核心是三個變量的計算:Q(Query)、K(Key)、V(Value)可以類比成查字典:
- 你想查 “它” 指什么(這是 Query);
- 字典里的每個詞都有自己的 “標簽”(如 “貓” 的標簽是 “動物”,這是 Key);
- 查到后得到的解釋(如 “貓是一種動物”,這是 Value)。
具體計算如下:
- 生成Q、K、V:給每個詞向量(上一步的輸入)乘上三個不同的線型層矩陣,這3個線型層矩陣在初始時為隨機值,隨著訓練過程動態調整
- 計算注意力得分:用 Query 和每個詞的 Key 做 “匹配度” 計算(用「縮放點積」:Q?K / √d,d 是向量維度,防止值太大);
- 歸一化得分:用 softmax 把得分變成 0-1 的權重(總和為 1),表示 “關注程度”;得分越大,說明詞向量與這個key最為匹配 ,舉例子也就是貓坐在墊子上,它很舒服”,“它” 指的是 “貓”,所以“貓”這個key得分會更高
- 加權求和:用第三步的得分乘以每個詞的V向量,再進行累加,得到該詞的「注意力輸出」(即 “綜合了其他詞信息的新向量”)。
前饋神經網絡
這一個部分是為了**對每個詞的注意力輸出做獨立的特征處理(和其他詞無關)。**結構是:兩層線性變換 + ReLU 激活,公式可以簡化為:
FFN(x) = max(0, x·W1 + b1) · W2 + b2
作用類似 “特征提純”:把注意力捕捉到的關聯信息,進一步轉化為更有效的特征。
在此之后還有兩個部分
- 殘差連接:每個子層的輸出 = 子層輸入 + 子層計算結果(如注意力輸出)。作用是解決深層網絡的 “梯度消失”,讓模型更容易訓練。 “梯度消失”會使得模型訓練不動,權重無法修改
- 層歸一化:對每個詞的向量做歸一化(讓均值為 0,方差為 1)。作用是穩定訓練過程中的數值波動,讓模型收斂更快。
對于transformer模型而言,可能有n個編碼器,這n個編碼器結構完全一樣,但是內部權重不一樣。沒個編碼器都有自己初始的線型層矩陣(3個),都獨享矩陣參數。且一個編碼器的輸入是上一個編碼器的輸出。
編碼器的多層結構設計目的是逐步提煉和抽象輸入序列的特征(從低級特征到高級特征),而獨立的線性層矩陣是實現這一目標的關鍵:
- 第一層可能更關注基礎的語法關系(如主謂、動賓),其會學習 “如何提取語法相關的 Q、K 特征”(比如讓動詞的 Q 更易匹配主語的 K)。
- 第二層則更關注全局語義(如整個句子的場景或邏輯),其會學習 “如何提取語義相關的 Q、K 特征”(比如讓 “貓” 的 Q 更易匹配 “墊子” 的 K,因為它們共同構成 “貓坐在墊子上” 的場景)。
如果多層共享同一套線性層矩陣,模型就無法針對不同抽象層次的特征進行專門優化,難以實現 “逐層遞進” 的特征提取。
最后一個編碼器的output最作為input進入n個解碼器
解碼器
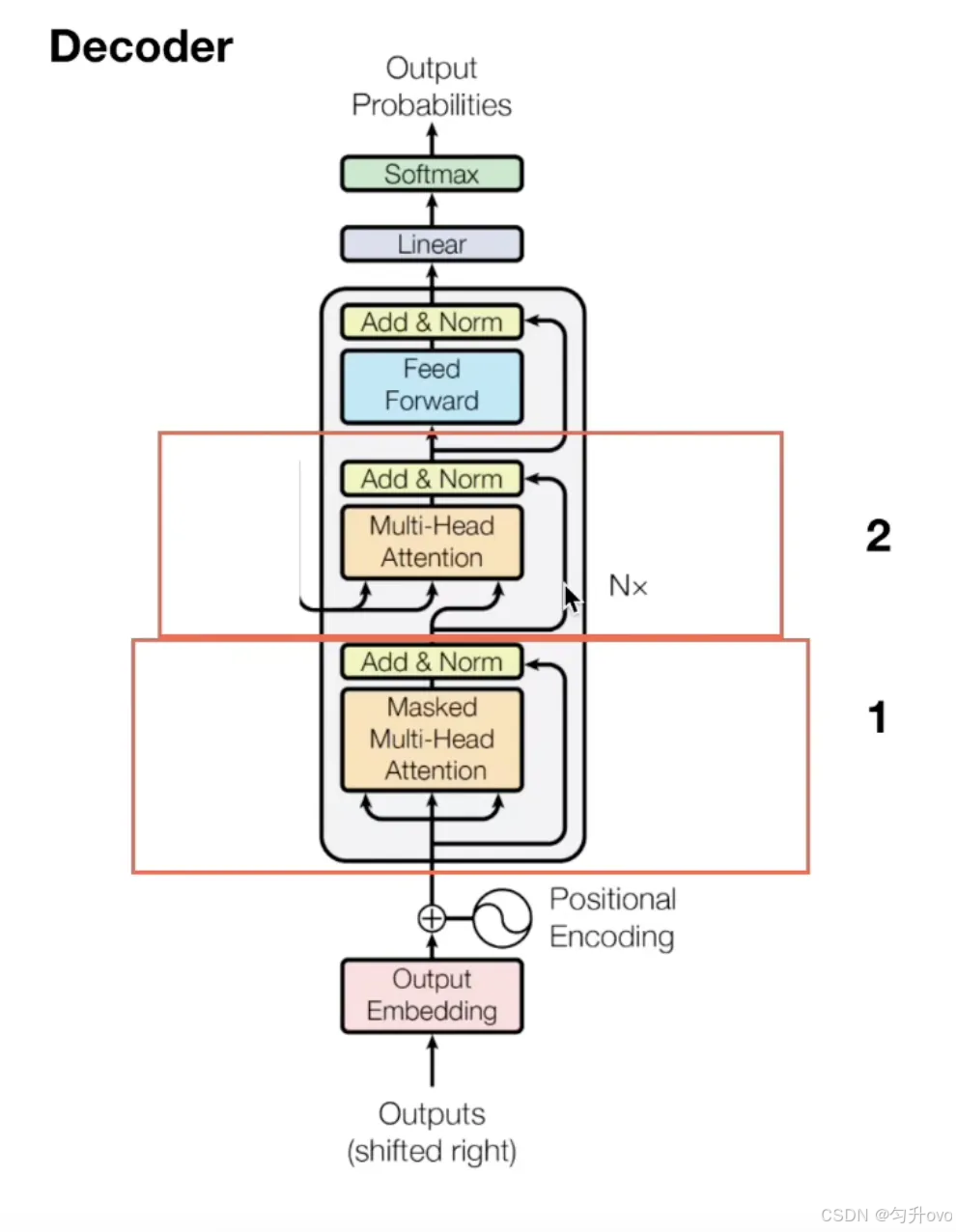
解碼器也由 N 個相同的層堆疊,每個層比編碼器多一個子層,共 3 個子層:
- 掩碼多頭自注意力(Masked Multi-Head Self-Attention);
- 編碼器 - 解碼器注意力(Encoder-Decoder Attention);
- 前饋神經網絡(和編碼器的一樣)。
在解碼器的輸入部分,可分為兩種情況:
- 第一種是在訓練時,輸入部分是目標序列經過embedding以及位置編碼轉換后的向量以及編碼器最后一層的注意力機制模塊的K和V向量(這一部分會在解碼器的第二個部分作為輸入),這個目標序列怎么理解呢,加入我的編碼器的輸入原始序列是"我愛你",那么目標序列就是"i love you",訓練時為了并行計算,會把整個輸出序列(如 “I love you”)喂進去,但必須 “遮住” 每個詞后面的內容(比如計算 “I” 的注意力時,只能看到 “I”,看不到 “love” 和 “you”)。
在訓練階段,我已經知道原始序列對應的目標序列是什么,所以會隨機初始化一個**[目標序列長度??模型向量維度]**的矩陣作為解碼器的輸入
舉例:
目標序列為:[我, 愛, 機器學習]
移位后輸入:[<sos, 我, 愛, 機器學習](解碼器需要基于此預測[我, 愛, 機器學習, ])
- 第二種是在推理時,模型不知道完整目標序列,需要自回歸生成:每次生成一個詞,將其拼接到 “已生成序列” 后,作為下一次的輸入,直到生成<eos結束。所以它的輸入部分是上一次的輸出(最原始的輸入是開頭符)拼接到"已生成序列"之后再加上編碼器最后一層的注意力機制模塊的K和V向量
舉例:
● 第 1 步輸入:[<sos] → 生成 “我”
● 第 2 步輸入:[<sos, 我] → 生成 “愛”
● 第 3 步輸入:[<sos, 我, 愛] → 生成 “機器學習”
● 第 4 步輸入:[<sos, 我, 愛, 機器學習] → 生成,結束
掩碼多頭自注意力
計算方式與編碼器的自注意力機制是一樣的,但是多了個**掩碼**,也就是說,在輸入的矩陣中,在計算注意力得分時,當前詞是看不到后面詞的K和V的,會將他們設置為0,**這樣的話,在計算得分時就不會將當前詞后面的詞的特征考慮進來,防止模型參考后面的句子來預測當前詞。**方便與推理時邏輯保持一致。編碼器 - 解碼器注意力
這個注意力的作用是:**讓解碼器 “關注” 編碼器輸出的上下文向量(即輸入序列的信息)。**
計算方式和自注意力類似,但 Q、K、V 的來源不同:
- Query(Q):來自解碼器第一層(掩碼注意力)的輸出;
- Key(K)和 Value(V):來自編碼器的最終輸出(上下文向量)
最終會得到一個注意力得分向量
前饋神經網絡(和編碼器的一樣)
所做的工作與編碼器一樣,是為了**對每個詞的注意力輸出做獨立的特征處理(和其他詞無關)。**也有殘差連接和歸一化兩個步驟
輸出處理
解碼器的最終輸出是一個 512 維的向量(論文中如此設置),需要轉換成 “下一個詞的概率”:- 經過一個線性層:把 512 維向量映射到 “詞表大小” 維度(比如詞表有 10000 個詞,就變成 10000 維);
- 經過 softmax:把 10000 維向量變成概率分布(每個值在 0-1 之間,總和為 1);
- 取概率最大的詞作為輸出,然后把這個詞再喂回解碼器,重復生成下一個詞,直到生成 “結束符”。
至此,整個從輸入到輸出的流程就結束了,在進行完一輪epoch后,會計算損失然后進行反向傳播修改各個矩陣參數權重。


)





原理,RTK/PPK/PPP區別討論)










