(1)Spark基礎入門
①什么是Spark
Spark是一款分布式內存計算的統一分析引擎。其特點就是對任意類型的數據進行自定義計算。Spark可以計算:結構化、半結構化、非結構化等各種類型的數據結構,同時也支持使用Python、Java、Scala、R以及SQL語言去開發應用程序計算數據。Spark的適用面非常廣泛,所以,被稱之為 統一的(適用面廣)的分析引擎(數據處理)
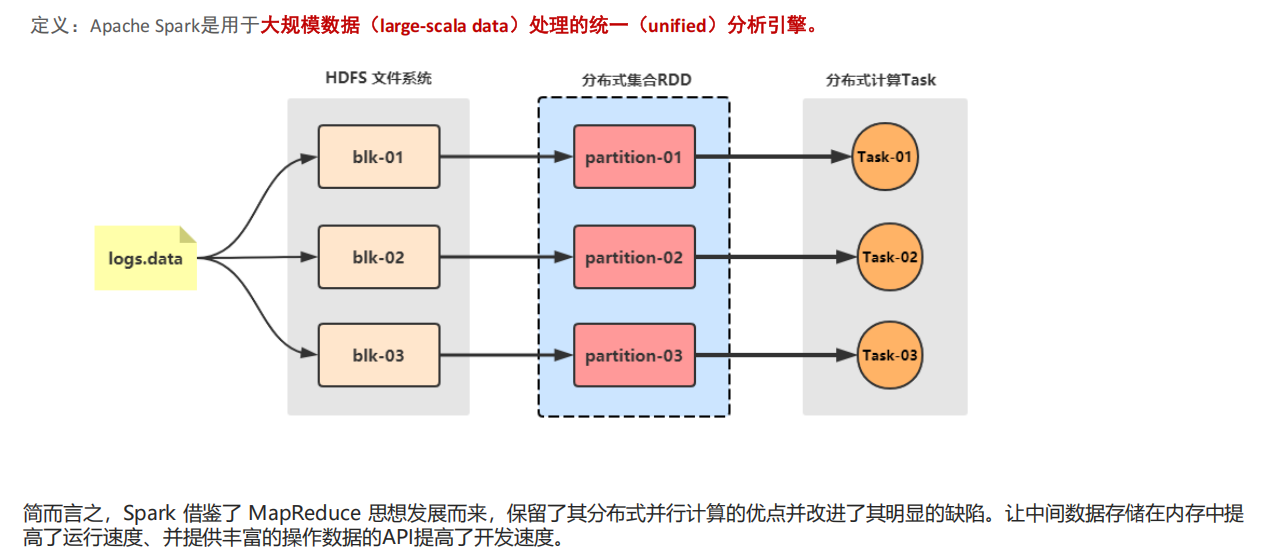
RDD 是一種分布式內存抽象,其使得程序員能夠在大規模集群中做內存運算,并且有一定的容錯方式。而這也是整個 Spark 的核心數據結構,Spark 整個平臺都圍繞著RDD進行。可以說RDD就是一種數據結構抽象。
RDD(Resilient Distributed Dataset),是指彈性分布式數據集。
①數據集:Spark中的編程是基于RDD的,將原始數據加載到內存變成RDD,RDD再經過若干次轉化,仍為RDD。
②分布式:讀數據一般都是從分布式系統中去讀,如hdfs、kafka等,所以原始文件存在磁盤是分布式的,spark加載完數據的RDD也是分布式的,換句話說RDD是抽象的概念,實際數據仍在分布式文件系統中;因為有了RDD,在開發代碼過程會非常方便,只需要將原始數據理解為一個集合,然后對集合進行操作即可
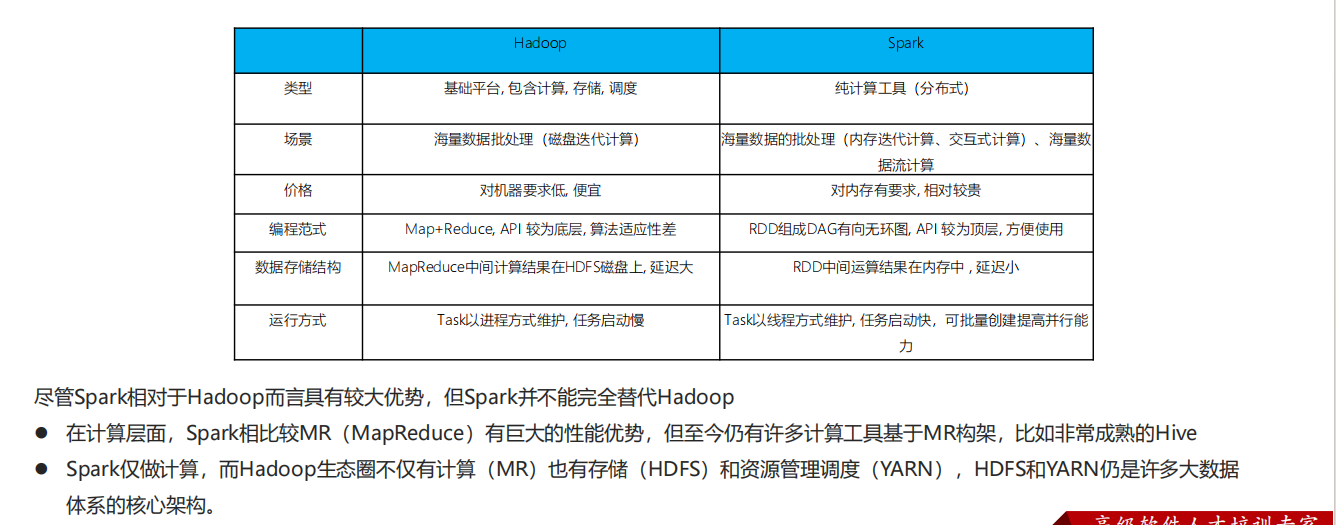
②Spark VS Hadoop(MapReduce)
③Spark 框架模塊

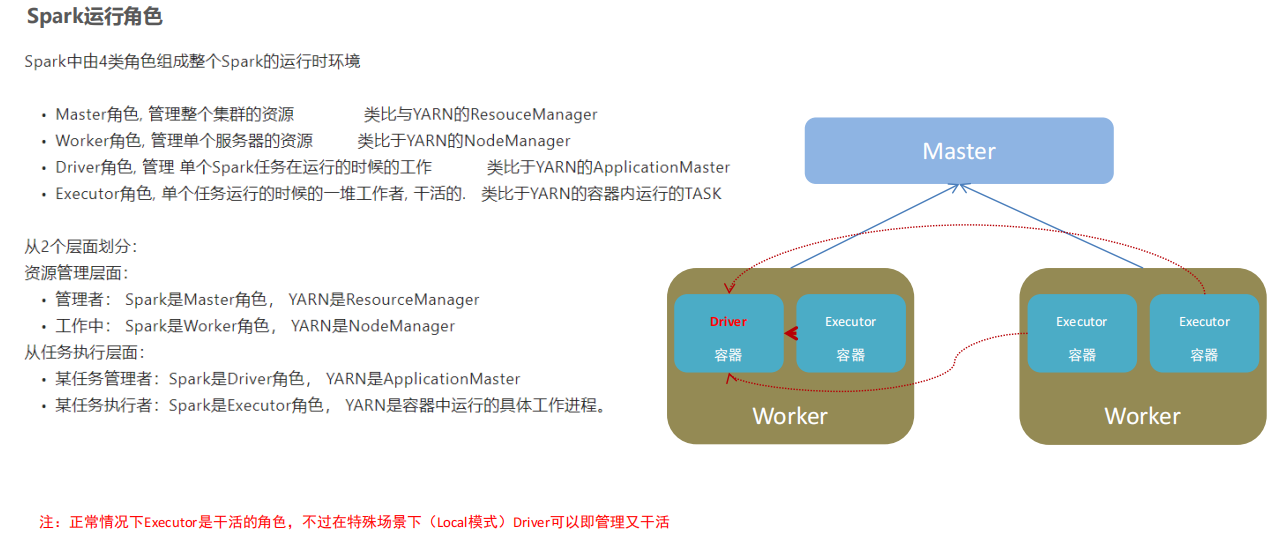
④Spark的架構角色
⑤Spark本地運行環境
"Local"指的是本地運行模式,即在單個機器上(而非集群)運行Spark應用程序的開發測試模式。這種模式允許開發者在沒有分布式環境的情況下快速測試和調試Spark代碼


這種模式下面有三種運行方式:
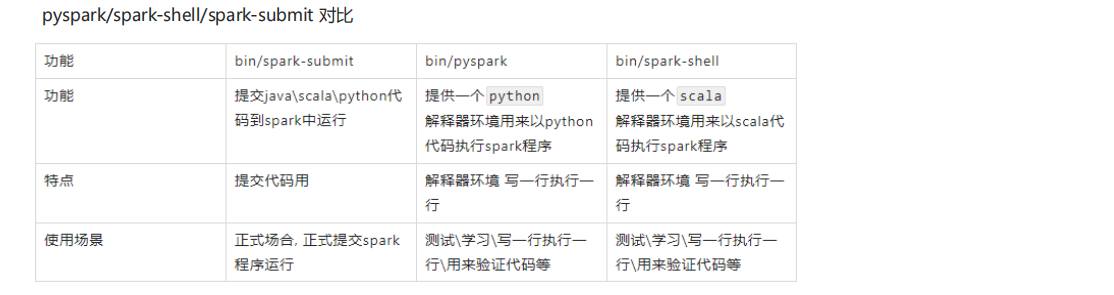
①以下是基于Pyspark的測試:
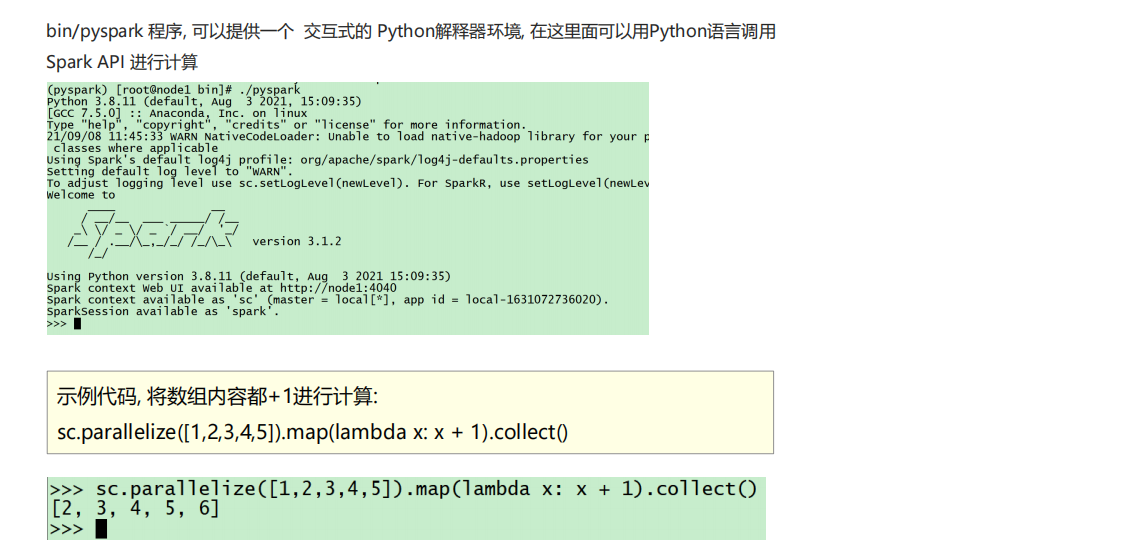
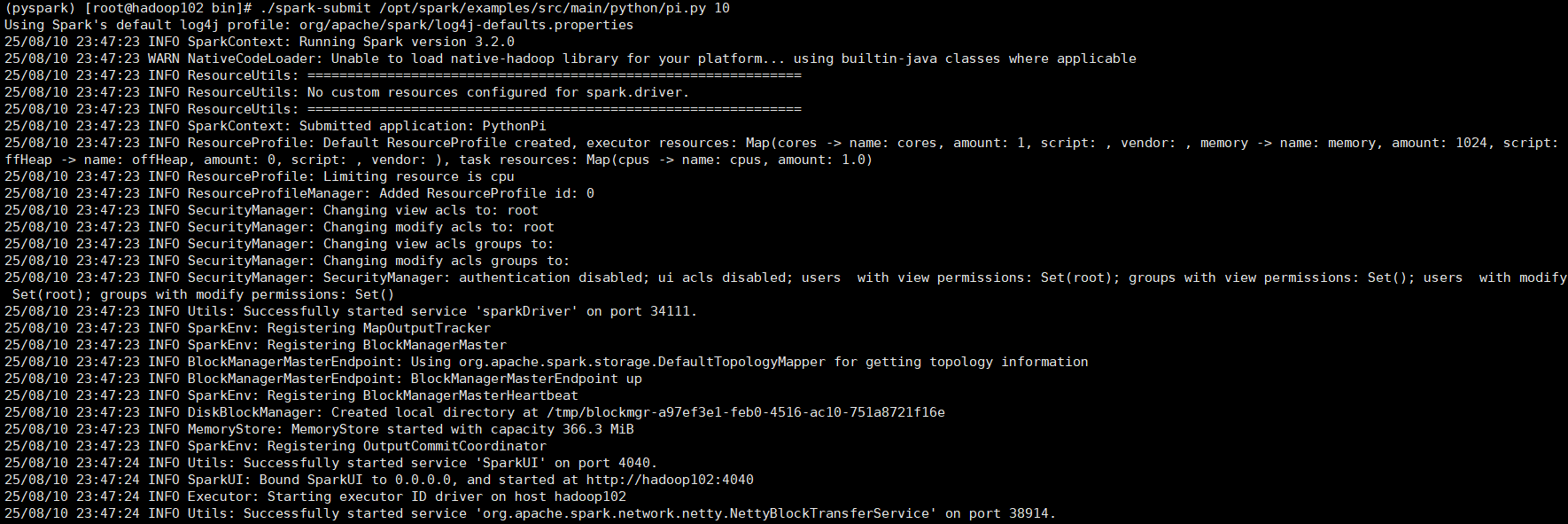
②以下是spark-submit的測試代碼:
代碼格式為:./spark-submit [可選的一些選項] jar包或者python代碼的路徑 [代碼的參數]
示例如下:./spark-submit /opt/spark/examples/src/main/python/pi.py 10

以下是總結:
①Local模式的運行原理:Local模式就是以一個獨立進程配合其內部線程來提供完成Spark運行時環境. Local模式可以通過spark-shell/pyspark/spark-submit等來開啟
②bin/pyspark是什么程序:**是一個交互式的解釋器執行環境,環境啟動后就得到了一個Local Spark環境,**可以運行Python代碼去進行Spark計算,類似Python自帶解釋器
③Spark的4040端口是什么:Spark的任務在運行后,會在Driver所在機器綁定到4040端口,提供當前任務的監控頁面供查看
(2)SparkCore
①RDD詳解
分布式計算涉及到了以下步驟:
(1)分區控制:分區控制是將大規模數據集劃分為多個邏輯分片(Partition),以便分布式并行處理。通過合理分區(如按Key哈希、范圍劃分等),可確保數據均勻分布,避免傾斜問題。例如,Spark的RDD、Flink的KeyedStream都依賴分區實現并行計算,分區數通常與并行度掛鉤。
(2)Shuffle控制:Shuffle是跨節點數據重分布的過程,涉及數據的洗牌和重組。例如,在Reduce或Join操作時,相同Key的數據需聚合到同一節點,例如Spark的reduceByKey、Flink的keyBy都會觸發Shuffle。
(3)數據存儲\序列化\發送:分布式計算中,數據需高效存儲(如HDFS、內存)、序列化(如Kryo、Protobuf)和跨節點傳輸。序列化影響網絡開銷,需權衡速度與體積;存儲格式(如Parquet)影響I/O效率。數據傳輸依賴RPC或消息隊列(如Netty),需考慮容錯與流量控制。
(4)數據計算API:計算API提供分布式操作的編程接口(如Map、Reduce、Join),隱藏底層復雜性。API設計需兼顧表達能力與性能,如Spark的RDD,Flink的DataStream。
這些功能, 不能簡單的通過Python內置的本地集合對象(如 List\ 字典等)去完成.我們在分布式框架中, 需要有一個統一的數據抽象對象, 來實現上述分布式計算所需功能.這個抽象對象, 就是RDD


RDD有5大特性:
①RDD是具有分區的。 ②RDD的方法會作用在所有分區上面。 ③RDD之間有互相依賴的關系
④Key-Value型的RDD可以有分區器 :只有PairRDD(元素是鍵值對(K, V)的RDD)才能顯式指定分區器,因為分區邏輯通常基于Key的哈希或范圍(如HashPartitioner或RangePartitioner)。非Key-Value型RDD(如普通數組)的分區是簡單的輪詢或隨機分配,無需依賴Key的規則。
⑤RDD所在的分區規劃會盡量靠近服務器以實現本地存儲。
以下是以WordCount案例為核心分析RDD
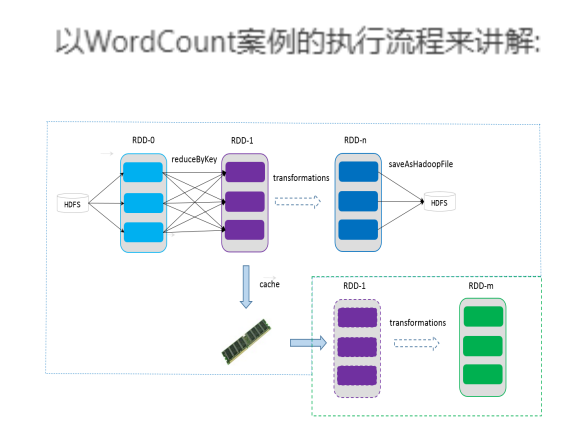
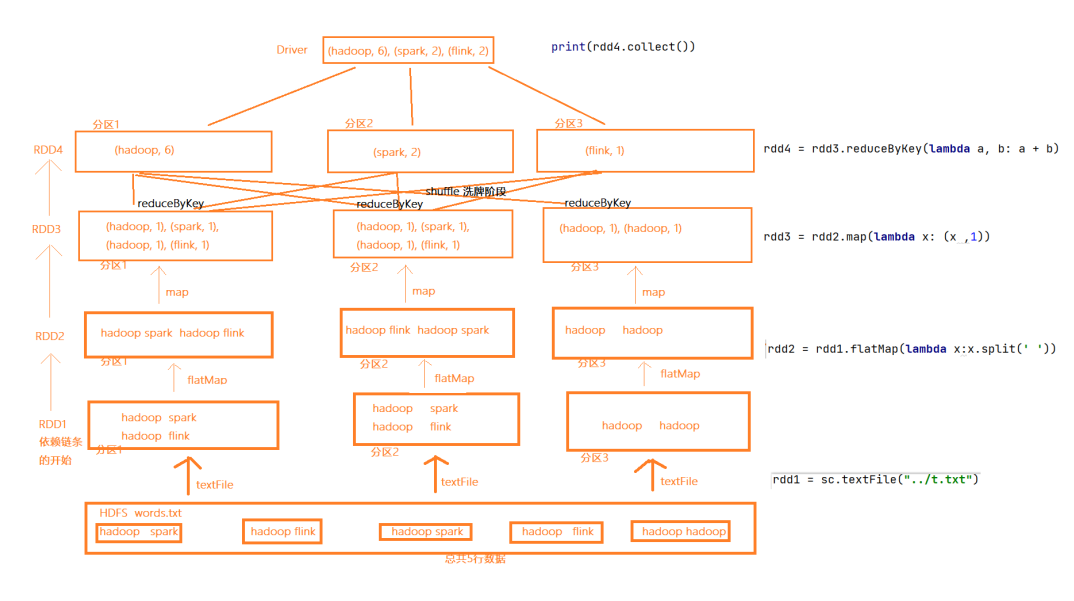
(2)RDD 編程入門
(1)程序執行入口 SparkContext對象:Spark RDD 編程的程序入口對象是SparkContext對象from pyspark import SparkConf, SparkContextconf = SparkConf().setAppName("WordCount").setMaster("spark://hadoop102:7077") # 前者是任務名字修改為你的 Master URLsc = SparkContext(conf=conf)(2)創建RDD的方法1 直接從集合對象創建rdd = sparkcontext.parallelize(參數1,參數2)# 參數1 集合對象即可,比如lis 參數2 分區數data =[1,2,3,4,5,6,7,8,9]rdd =sc.parallelize(data,numSlices=3)rdd.getNumPartitions() #獲得分區數2 從文件當中讀取resultRDD = sc.textFile("hdfs://hadoop102:8020/input/article.txt") (3)RDD算子1 Transformation算子:返回的還是rdd,參數是函數式接口rdd = sc.parallelize([1, 2, 3, 4, 5])# 1. map: 對每個元素應用函數mapped = rdd.map(lambda x: x * 2) # 輸出: [2, 4, 6, 8, 10]# 2. flatMap: 先映射后扁平化(如拆分單詞)words = sc.parallelize(["hello world", "spark demo"])flattened = words.flatMap(lambda x: x.split(" ")) # 輸出: ["hello", "world", "spark", "demo"]# 3. filter: 過濾滿足條件的元素filtered = rdd.filter(lambda x: x > 3) # 輸出: [4, 5]# 4. distinct: 去重distinct = sc.parallelize([1, 2, 2, 3]).distinct() # 輸出: [1, 2, 3]# 5. sample: 隨機采樣sampled = rdd.sample(withReplacement=False, fraction=0.5) # 無放回采樣50%數據接下來是對Key-value類型的RDD操作pair_rdd = sc.parallelize([("a", 1), ("b", 2), ("a", 3)])# 6. mapValues: 僅對Value映射upper_values = pair_rdd.mapValues(lambda v: v * 10) # 輸出: [("a", 10), ("b", 20), ("a", 30)]# 7. reduceByKey: 按Key聚合(優化版groupByKey)sum_by_key = pair_rdd.reduceByKey(lambda a, b: a + b) # 輸出: [("a", 4), ("b", 2)]# 8. groupByKey: 按Key分組(可能OOM)grouped = pair_rdd.groupByKey() # 輸出: [("a", [1, 3]), ("b", [2])]# 9. sortByKey: 按Key排序sorted_rdd = pair_rdd.sortByKey(ascending=False) # 降序輸出: [("b", 2), ("a", 1), ("a", 3)]# 10. keys: 提取所有Keykeys = pair_rdd.keys() # 輸出: ["a", "b", "a"]# 11. values: 提取所有Valuevalues = pair_rdd.values() # 輸出: [1, 2, 3]多RDD操作rdd1 = sc.parallelize([1, 2, 3])rdd2 = sc.parallelize([3, 4, 5])# 12. union: 合并兩個RDD(不去重)union_rdd = rdd1.union(rdd2) # 輸出: [1, 2, 3, 3, 4, 5]# 13. intersection: 返回交集intersection_rdd = rdd1.intersection(rdd2) # 輸出: [3]# 14. subtract: 返回rdd1有但rdd2沒有的元素subtracted = rdd1.subtract(rdd2) # 輸出: [1, 2]# 15. cartesian: 笛卡爾積(慎用!)cartesian_rdd = rdd1.cartesian(rdd2) # 輸出: [(1,3), (1,4), ..., (3,5)]分區/重分區控制# 16. repartition: 全局重分區(全量Shuffle)repartitioned = rdd.repartition(4) # 強制分成4個分區# 17. coalesce: 合并分區(減少分區,避免Shuffle)coalesced = rdd.coalesce(2) # 合并為2個分區# 18. partitionBy: 按分區器重分(僅PairRDD)from pyspark.rdd import HashPartitionerpartitioned = pair_rdd.partitionBy(HashPartitioner(3)) # 按Key哈希分到3個分區2 Action算子:1. 數據收集與輸出rdd = sc.parallelize([1, 2, 3, 4, 5])# 1. collect(): 返回RDD所有元素到Driver(小心數據量!)result = rdd.collect() # 輸出: [1, 2, 3, 4, 5]# 2. take(n): 返回前n個元素first_two = rdd.take(2) # 輸出: [1, 2]# 3. first(): 返回第一個元素first_elem = rdd.first() # 輸出: 1# 4. takeSample(withReplacement, num, seed): 隨機采樣sampled = rdd.takeSample(False, 3) # 無放回隨機取3個元素,如 [2, 4, 1]# 5. takeOrdered(n, key=None): 按升序或自定義key返回前n個ordered = rdd.takeOrdered(3) # 輸出: [1, 2, 3]2. 統計與聚合# 6. count(): 返回RDD元素總數count = rdd.count() # 輸出: 5# 7. countByKey(): 統計每個Key的出現次數(僅PairRDD)pair_rdd = sc.parallelize([("a", 1), ("b", 2), ("a", 3)])key_counts = pair_rdd.countByKey() # 輸出: {"a": 2, "b": 1}# 8. countByValue(): 統計每個值的出現次數value_counts = rdd.countByValue() # 輸出: {1:1, 2:1, 3:1, 4:1, 5:1}# 9. reduce(func): 用func聚合所有元素(需滿足結合律)sum_all = rdd.reduce(lambda a, b: a + b) # 輸出: 15 (1+2+3+4+5)# 10. fold(zeroValue, func): 類似reduce,但需初始值sum_with_zero = rdd.fold(0, lambda a, b: a + b) # 輸出: 15# 11. aggregate(zeroValue, seqOp, combOp): 自定義聚合agg_result = rdd.aggregate((0, 0), lambda acc, x: (acc[0] + x, acc[1] + 1), # 分區內累加和計數lambda acc1, acc2: (acc1[0] + acc2[0], acc1[1] + acc2[1]) # 分區間合并) # 輸出: (15, 5) 總和和總個數3. 數據保存到外部存儲# 12. saveAsTextFile(path): 保存為文本文件(每行一個元素)rdd.saveAsTextFile("output/") # 生成目錄,內含part-00000等文件# 13. saveAsSequenceFile(path): 保存為SequenceFile(僅PairRDD)pair_rdd.saveAsSequenceFile("seq_output/")# 14. saveAsHadoopFile/pickleFile等: 其他格式保存(需配置)4. 迭代與調試# 15. foreach(func): 對每個元素應用func(無返回值)rdd.foreach(lambda x: print(x)) # 打印每個元素(在Executor端執行)# 16. foreachPartition(func): 對每個分區應用funcdef log_partition(iterator):print("Partition data:", list(iterator))rdd.foreachPartition(log_partition) # 按分區打印數據
Reduce算子的圖片:
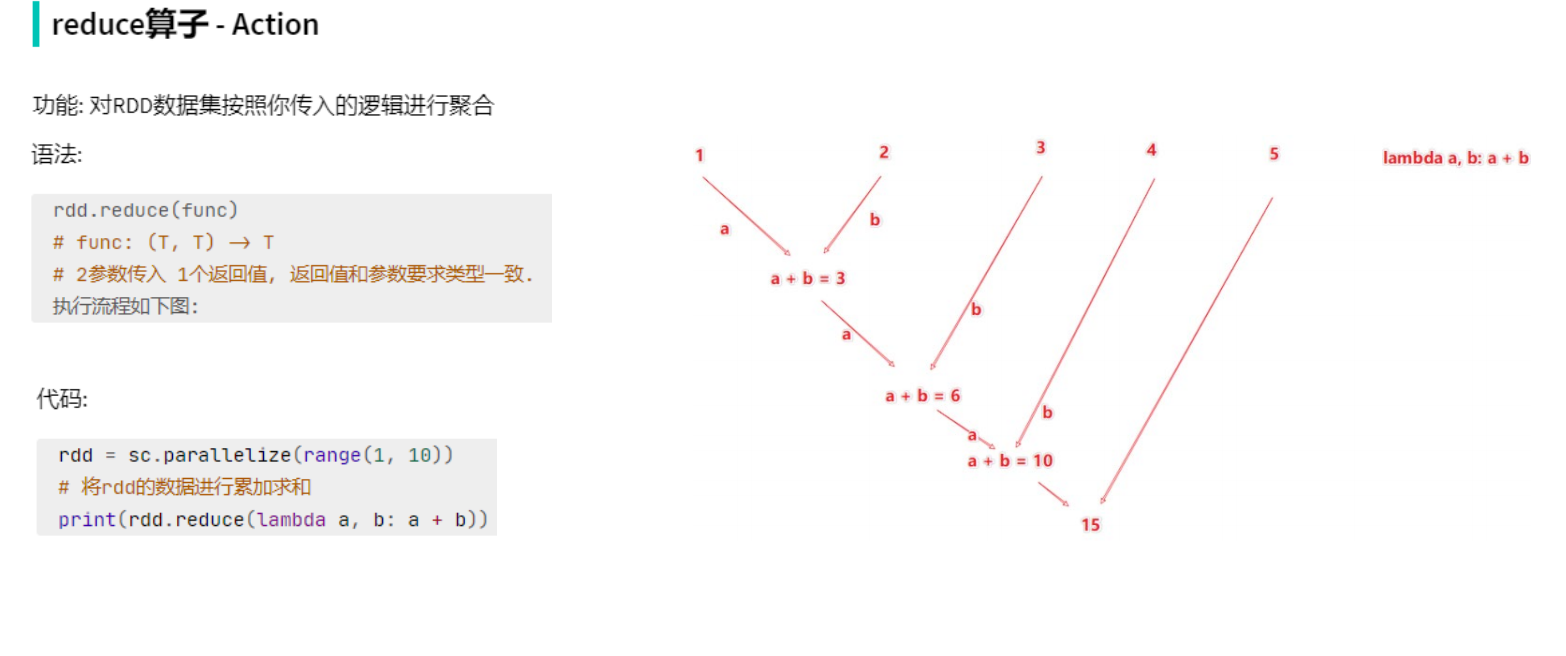
(3)SparkSQL
①什么是SparkSQL
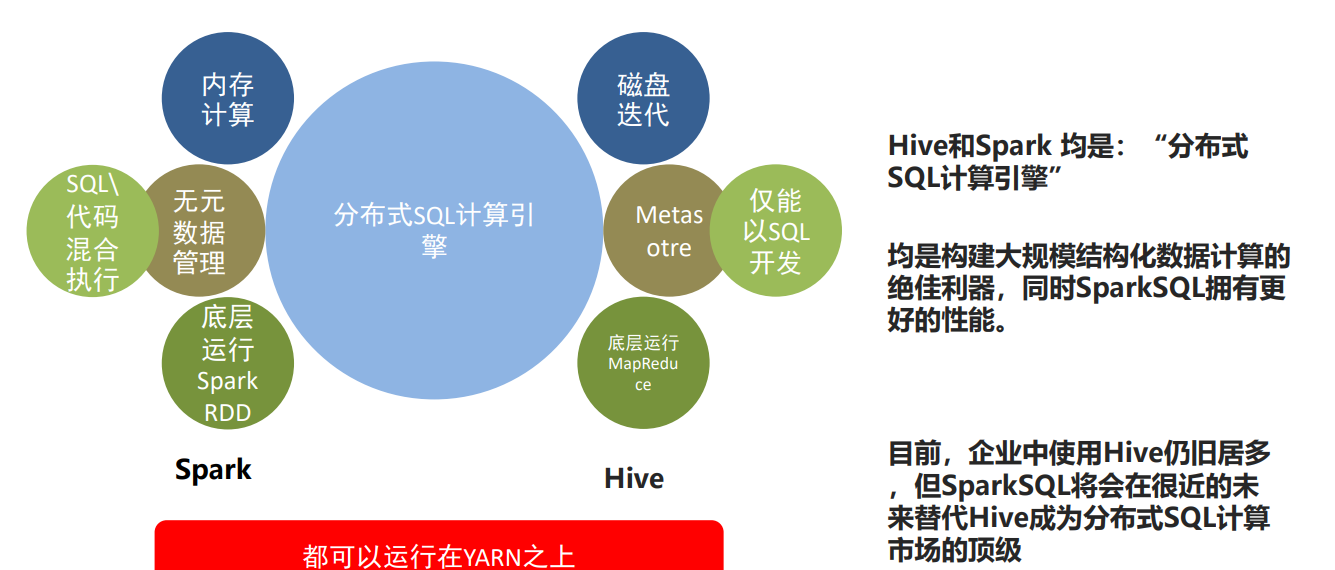
SparkSQL是非常成熟的 海量結構化數據處理框架。SparkSQL本身十分優秀, 支持SQL語言\性能強\可以自動優化\API簡單\兼容HIVE等等。企業大面積在使用SparkSQL處理業務數據。例如:離線開發,數倉搭建,科學計算,數據分析。SparkSQL具有以下特點:

以下是SparkSQL和Hive的對比:
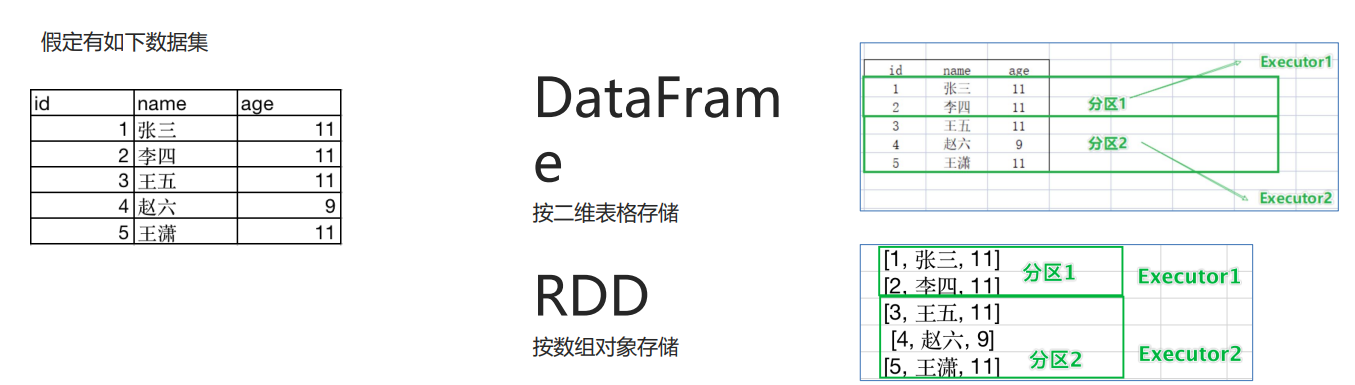
Spark的數據抽象如下:


DataFrame 是按照二維表格的形式存儲數據,RDD則是存儲對象本身。具體對比如下:
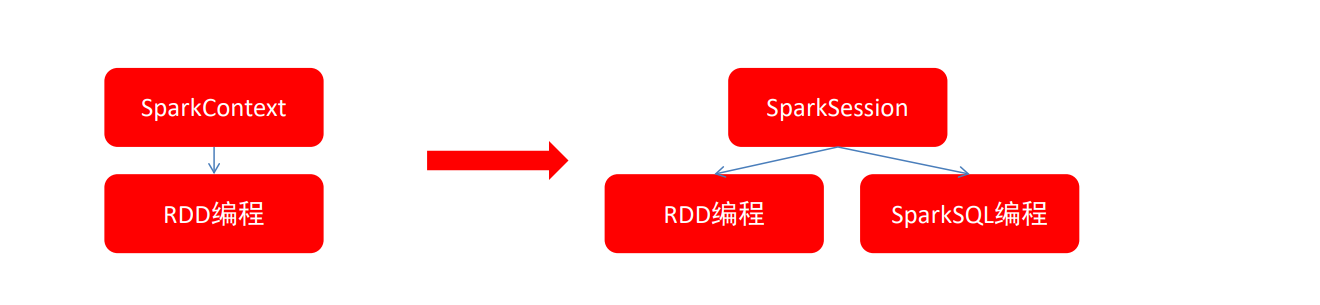
在RDD階段,程序的執行入口對象是: SparkContext
在Spark 2.0后,推出了SparkSession對象,作為Spark編碼的統一入口對象。SparkSession對象可以:
- 用于SparkSQL編程作為入口對象
- 用于SparkCore編程,可以通過SparkSession對象中獲取到SparkContext
以下是代碼:
# coding:utf8
# SparkSQL 中的入口對象是SparkSession對象
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 構建SparkSession對象, 這個對象是 構建器模式 通過builder方法來構建spark = SparkSession.builder.\appName("local[*]").\config("spark.sql.shuffle.partitions", "4").\getOrCreate()
# appName 設置程序名稱, config設置一些常用屬性
# 最后通過getOrCreate()方法 創建SparkSession對象
(2)DataFrame入門
以下是DataFrame的總體結構:

①以下是Dataframe的構建方式:
df = spark.createDataFrame(rdd, schema = ['name', 'age'])
#直接通過SparkSession對象的createDataFrame方法來將RDD轉換為DataFrame:# StructType 類這個類 可以定義整個DataFrame中的Schema
schema = StructType().\
add("id", IntegerType(), nullable=False).\
add("name", StringType(), nullable=True).\
add("score", IntegerType(), nullable=False)
df = spark.createDataFrame(rdd, schema)
# 一個add方法 定義一個列的信息, 如果有3個列, 就寫三個add, 每一個add代表一個StructField# add方法: 參數1: 列名稱, 參數2: 列類型, 參數3: 是否允許為空#調用RDD的todf方法轉變
df = rdd.toDF(['id', 'subject', 'score']) #列名
df = rdd.toDF(schema) #傳入schema#基于自定義的pandas的DF,構建Pandas的DF,而后把將Pandas的DF對象轉換成Spark的DF
pdf = pd.DataFrame({
"id": [1, 2, 3],
"name": ["張大仙", '王曉曉', '王大錘'],"age": [11, 11, 11]
})
df = spark.createDataFrame(pdf)#sparksession讀取外部數據
sparksession.read.format("text|csv|json|parquet|orc|avro|jdbc|......")
.option("K", "V") # option可選
.schema(StructType | String)
.load("被讀取文件的路徑, 支持本地文件系統和HDFS")示例代碼如下:
1 text文件
schema = StructType().add("data", StringType(), nullable=True)
df = spark.read.format("text")\
.schema(schema)\
.load("../data/sql/people.txt")2 json文件
df = spark.read.format("json").\
load("../data/sql/people.json")
# JSON 類型 一般不用寫.schema, json自帶, json帶有列名 和列類型(字符串和數字)df.printSchema()3 csv文件
df = spark.read.format("csv")\
.option("sep", ";")\ # 列分隔符
.option("header", False)\ # 是否有CSV標頭
.option("encoding", "utf-8")\ # 編碼
.schema("name STRING, age INT, job STRING")\ # 指定列名和類型
.load("../data/sql/people.csv") # 路徑4 parquet數據
# parquet 自帶schema, 直接load啥也不需要了
df = spark.read.format("parquet").\
load("../data/sql/users.parquet")②以下是DataFrame的基本操作方式
DSL:領域特定語言。其實就是指DataFrame的特有API比如:df.where().limit()
SQL風格就是使用SQL語句處理DataFrame的數據比如:spark.sql(“SELECT * FROM xxx)
(1)DSL語法風格
# 1. 基本操作示例
df.show() # 展示 DataFrame 的前20行數據# 打印 DataFrame 的 schema
df.printSchema() # 以樹形結構打印 DataFrame 的列名和數據類型
columns = df.columns # 獲取 DataFrame 的所有列名列表
dtypes = df.dtypes # 獲取列名和對應數據類型的元組列表
schema = df.schema # 獲取 DataFrame 的完整 schema 信息
row_count = df.count() # 計算 DataFrame 中的總行數
stats = df.describe() # 對數值列計算 count, mean, stddev, min, max# 2. 列操作示例selected = df.select("name", "age") # 只選擇 name 和 age 兩列
new_df = df.withColumn("age_plus_10", col("age") + 10) # 創建新列 age_plus_10
renamed_df = df.withColumnRenamed("old_name", "new_name") # 將 old_name 列改名為 new_name
dropped_df = df.drop("unwanted_column") # 刪除 unwanted_column 列# 3. 過濾和排序示例filtered_df = df.filter(col("age") > 18) # 篩選 age 大于18的行
distinct_df = df.distinct() # 去除完全相同的重復行
sorted_df = df.orderBy("age", ascending=False) # 按 age 降序排列
limited_df = df.limit(100) # 只返回前100行數據# 4. 聚合操作示例
grouped_df = df.groupBy("department") # 按 department 列分組
agg_df = df.agg(avg("salary").alias("avg_salary")) # 計算 salary 列的平均值
count_df = df.groupBy("department").count() # 計算每個部門的記錄數
sum_df = df.groupBy("product").sum("sales") # 計算每個產品的總銷售額
avg_df = df.groupBy("class").avg("score") # 計算每個班級的平均分
max_df = df.groupBy("year").max("temperature") # 獲取每年的最高溫度
min_df = df.groupBy("month").min("price") # 獲取每月的最低價格
pivot_df = df.groupBy("date").pivot("category").sum("value") # 創建按日期和類別的透視表# 5. 連接操作示例
## 內連接
joined_df = df1.join(df2, df1.id == df2.id, "inner") # 基于 id 列的內連接,還有其他連接
union_df = df1.union(df2) # 垂直合并兩個結構相同的 DataFrame
union_by_name_df = df1.unionByName(df2) # 按列名合并,允許列順序不同# 6. 窗口函數示例
## 定義窗口分區
window_spec = Window.partitionBy("department").orderBy("salary") # 按部門分區并按工資排序
ranked_df = df.withColumn("rank", rank().over(window_spec)) # 計算每個部門內的工資排名
lag_df = df.withColumn("prev_salary", lag("salary").over(window_spec)) # 獲取前一行的工資值# 7. 缺失值處理示例
## 填充缺失值
filled_df = df.na.fill(0) # 將所有空值填充為0
dropped_na_df = df.na.drop() # 刪除包含任何空值的行
replaced_df = df.na.replace(["old_value"], ["new_value"], "column_name") # 替換指定列中的特定值# 8. 數據類型轉換示例
casted_df = df.withColumn("age_int", col("age").cast("integer")) # 將 age 列轉為整數類型# 9. 寫入操作示例
df.write.csv("output.csv") # 將 DataFrame 寫入 CSV 文件
df.write.parquet("output.parquet") # 將 DataFrame 寫入 Parquet 文件# 10. 其他常用操作示例
cached_df = df.cache() # 將 DataFrame 緩存到內存中
repartitioned_df = df.repartition(10) # 將數據重新分區為10個分區
coalesced_df = df.coalesce(2) # 將分區數減少到2個
df.explain() # 打印 DataFrame 的執行計劃
sampled_df = df.sample(0.1) # 隨機采樣10%的數據
data = df.collect() # 將所有數據收集到驅動程序節點
pandas_df = df.toPandas() # 將 Spark DataFrame 轉為 pandas DataFrame(2)SQL風格:DataFrame的一個強大之處就是我們可以將它看作是一個關系型數據表,
然后可以通過在程序中使用spark.sql() 來執行SQL語句查詢,結果返回一個DataFrame
如果想使用SQL風格的語法,需要將DataFrame注冊成表,采用如下的方式:
df.createTempView("score") # 注冊一個臨時視圖(表)
df.create0rReplaceTempView(“score") #注冊一個臨時表,如果存在進行替換
df.createGlobalTempView("score")# 注冊一個全局表
以下是示例:SQL風格處理, 以RDD為基礎做數據加載
#注冊sparktext和sparksession對象
spark = SparkSession.builder.\appName("create df").\
master("local[*]").\
getOrCreate()
sc = spark.sparkContext#讀取數據
rdd = sc.textFile("hdfs://node1:8020/input/words.txt").\
flatMap(lambda x: x.split(" ")).\
map(lambda x: [x])
df = rdd.toDF(["word"]
df.createTempView("words")# 使用sql語句處理df注冊的表
spark.sql("""
SELECT word, COUNT(*) AS cnt FROM words GROUP BY word ORDER BY cnt DESC
""").show()(3)數據清洗API:
#去重API dropDuplicates,無參數是對數據進行整體去重
df.dropDuplicates().show()
# API 同樣可以針對字段進行去重,如下傳入age字段,表示只要年齡一樣 就認為你是重復數據
df.dropDuplicates(['age','job']).show()# 如果有缺失,進行數據刪除
#無參數 為 how=any執行,只要有一個列是null 數據整行刪除,如果填入how='all'表示全部列為空 才會刪除,how參數默認是a
df.dropna().show()
#指定閥值進行刪除,thresh=3表示,有效的列最少有3個,這行數據才保留設定thresh后,how參數無效了
df.dropna(thresh=3).show()# 可以指定閥值 以及配合指定列進行工作,thresh=2,subset=['name','age'〕表示 針對這2個列,有效列最少為2個才保留數據。
df.dropna(thresh=2,subset=['name','age']).show()# 將所有的空,按照你指定的值進行填充,不理會列的任何空都被填充
df.fillna("loss").show()
#指定列進行填充
df.fillna("loss",subset=['job']).show()
# 給定字典 設定各個列的填充規則
df.fillna({"name":"未知姓名","age":1,"job":"worker"}).show()(4)DataFrame寫出:
df.write.mode().format().option(K,V).save(PATH)
# mode,傳入模式字符串可選:append 追加,overwrite 覆蓋,ignore 忽略,error 重復就報異常
# format,傳入格式字符串,可選:text,csV,json,parquet,orc,avro,jdbc
# 注意text源只支持單列df寫出
# option 設置屬性,如:.option("sep",",")r
# save 寫出的路徑,支持本地文件和HDFS下面是例子:
# Write text 寫出,只能寫出一個單列數據
df.select(F.concat_ws("_--","user id","movie_id", "rank", "ts")).\
write.\
mode("overwrite").\
format("text").\
save("../data/output/sql/text")# WriteCSV寫出
df.write.mode("overwrite").\
format("csv").\
option("sep",",").\
option("header",True).\
save("../data/output/sql/csv")#Write Json寫出
df.write.mode("overwrite").\
format("json").\
save("../data/output/sql/json")#Write Parquet 寫出
df.write.mode("overwrite").\format("parquet").\
save("../data/output/sql/parquet")#不給format,默認以 parquet寫出
df.write.mode("overwrite").save("../data/output/sql/default")(5)DataFrame 通過JDBC讀寫數據庫
# 寫DF通過JDBC到數據庫中
df.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/test?useSSL=false&useUnicode=true").\
option("dbtable","u data").\
option("user","root").\
option("password","123456").\
save()#從數據庫里面通過JDBC加載數據
df = spark.read.format("jdbc').\
option("url","jdbc:mysql://node1:3306/test?useSSL=false&useUnicode=true").\
option("dbtable","u data").\
option("user","root").\
option("password",“123456").\
load()
(3)Spark函數定義
①UDF函數


以下是代碼:
方法1
from pyspark.sql import SparkSession
from pyspark.sql.types import IntegerType
# 創建SparkSession
spark = SparkSession.builder.appName("UDF_Example").getOrCreate()
# 定義普通Python函數
def add_numbers(x, y):return x + y# 注冊UDF - 方式1
add_udf = spark.udf.register("add_udf_name", add_numbers, IntegerType())
# 使用SQL風格
spark.sql("CREATE TEMPORARY VIEW numbers AS SELECT 5 as num1, 10 as num2")
spark.sql("SELECT add_udf_name(num1, num2) as result FROM numbers").show()# 使用DSL風格
from pyspark.sql import functions as F
df = spark.createDataFrame([(5, 10)], ["num1", "num2"])
df.select(add_udf(F.col("num1"), F.col("num2")).alias("result")).show()方法2
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.sql.types import StringType# 創建SparkSession
spark = SparkSession.builder.appName("UDF_Example").getOrCreate()# 定義普通Python函數
def greet(name):return f"Hello, {name}!"# 注冊UDF - 方式2
greet_udf = F.udf(greet, StringType())# 使用DSL風格
df = spark.createDataFrame([("Alice",), ("Bob",)], ["name"])
df.select(greet_udf(F.col("name")).alias("greeting")).show()
②SparkSQL的窗口函數:PySpark的窗口函數(Window Functions)是一種在數據集的特定窗口范圍內執行計算的高級函數,它能在保留原始數據行的同時,對分組內的數據進行排序、聚合和分析。窗口函數的核心作用是為每一行計算基于其"窗口"(由PARTITION BY定義的分組和ORDER BY定義的排序)的衍生值,例如排名、累計和、移動平均等。與普通聚合函數不同,窗口函數不會減少數據行數,而是為每行添加新的計算列,保持原始數據的完整性。

PS:一個添加列的函數

代碼如下:
from pyspark.sql import functions as F
# 添加常量列
df = df.withColumn("country", F.lit("China"))# 基于現有列計算
df = df.withColumn("total_price", F.col("price") * F.col("quantity"))# 將salary列轉換為千元單位
df = df.withColumn("salary", F.col("salary") / 1000)# 修改數據類型
df = df.withColumn("age", F.col("age").cast("integer"))# 添加部門內薪水排名
window_spec = Window.partitionBy("department").orderBy(F.desc("salary"))
df = df.withColumn("dept_rank", F.rank().over(window_spec))df = df.withColumn("salary_level", F.when(F.col("salary") > 10000, "high").when(F.col("salary") > 5000, "medium").otherwise("low"))
以下是窗口函數的應用:
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.sql.window import Window
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DoubleType# 初始化SparkSession
spark = SparkSession.builder \.appName("WindowFunctionsDemo") \.getOrCreate()# 創建示例數據
data = [("Sales", "John", 5000, "2023-01-15"),("Sales", "Mike", 4500, "2023-01-10"),("Sales", "Lisa", 6000, "2023-01-20"),("IT", "Tom", 5500, "2023-01-12"),("IT", "Emma", 7000, "2023-01-18"),("IT", "Alex", 5200, "2023-01-05"),("HR", "Sarah", 4800, "2023-01-08"),("HR", "David", 5300, "2023-01-22")
]schema = StructType([StructField("department", StringType(), True),StructField("employee", StringType(), True),StructField("salary", IntegerType(), True),StructField("date", StringType(), True)
])df = spark.createDataFrame(data, schema)# 定義窗口規范 - 按部門分區并按薪水排序
window_spec_by_salary = Window.partitionBy("department").orderBy("salary")# 定義窗口規范 - 按部門分區并按日期排序
window_spec_by_date = Window.partitionBy("department").orderBy("date")# 定義窗口規范 - 按部門分區(不排序)
window_spec_partition_only = Window.partitionBy("department")# 定義行范圍窗口 - 當前行及其前后1行
window_spec_rows = Window.partitionBy("department").orderBy("salary").rowsBetween(-1, 1)# 定義無界窗口 - 從分區開始到當前行
window_spec_unbounded = Window.partitionBy("department").orderBy("date").rowsBetween(Window.unboundedPreceding, Window.currentRow)# ====================== 排名函數 ======================# 1. ROW_NUMBER() - 為每行分配唯一序號(相同值不同序號)
df = df.withColumn("row_num", F.row_number().over(window_spec_by_salary))# 2. RANK() - 為行分配排名(相同值相同排名,留空位)
df = df.withColumn("rank", F.rank().over(window_spec_by_salary))# 3. DENSE_RANK() - 為行分配排名(相同值相同排名,不留空位)
df = df.withColumn("dense_rank", F.dense_rank().over(window_spec_by_salary))# 4. PERCENT_RANK() - 計算行的相對排名(0到1之間)
df = df.withColumn("percent_rank", F.percent_rank().over(window_spec_by_salary))# 5. NTILE(n) - 將行分成n組并分配組號
df = df.withColumn("ntile_4", F.ntile(4).over(window_spec_by_salary)) # 分成4組# ====================== 分析函數 ======================# 6. LAG(col, offset, default) - 獲取前offset行的值
df = df.withColumn("prev_salary", F.lag("salary", 1).over(window_spec_by_date))# 7. LEAD(col, offset, default) - 獲取后offset行的值
df = df.withColumn("next_salary", F.lead("salary", 1).over(window_spec_by_date))# 8. FIRST_VALUE(col) - 獲取窗口中的第一個值
df = df.withColumn("first_salary", F.first_value("salary").over(window_spec_by_date))# 9. LAST_VALUE(col) - 獲取窗口中的最后一個值
df = df.withColumn("last_salary", F.last_value("salary").over(window_spec_by_date))# 10. CUME_DIST() - 計算行的累積分布(0到1之間)
df = df.withColumn("cume_dist", F.cume_dist().over(window_spec_by_salary))# ====================== 聚合函數 ======================# 11. SUM() OVER - 計算窗口內總和
df = df.withColumn("sum_salary", F.sum("salary").over(window_spec_partition_only))# 12. AVG() OVER - 計算窗口內平均值
df = df.withColumn("avg_salary", F.avg("salary").over(window_spec_partition_only))# 13. MIN() OVER - 找出窗口內最小值
df = df.withColumn("min_salary", F.min("salary").over(window_spec_partition_only))# 14. MAX() OVER - 找出窗口內最大值
df = df.withColumn("max_salary", F.max("salary").over(window_spec_partition_only))# 15. COUNT() OVER - 計算窗口內行數
df = df.withColumn("count_emp", F.count("employee").over(window_spec_partition_only))# ====================== 高級窗口函數 ======================# 16. 移動平均 - 當前行及其前后1行
df = df.withColumn("moving_avg", F.avg("salary").over(window_spec_rows))# 17. 累計總和 - 從分區開始到當前行
df = df.withColumn("running_total", F.sum("salary").over(window_spec_unbounded))# 18. 按值范圍計算 - 當前值±500的范圍
window_spec_range = Window.partitionBy("department").orderBy("salary").rangeBetween(-500, 500)
df = df.withColumn("range_avg", F.avg("salary").over(window_spec_range))# 顯示結果
df.orderBy("department", "salary").show(truncate=False)# 停止SparkSession
spark.stop()



進程、線程)





文本預處理:NLP 版 “給數據洗澡” 指南)









