目錄
1. 初識HTTP
2. URL
? ? ? ? 2.1 基本結構
2.2 URL中的?與urldecode\urlencode
易混淆:URL和HTTP傳輸請求兩者是什么關系?
HTTP的宏觀結構
3. DEMO CODE
loop模塊,核心邏輯
HttpServer
初代版本(DEMO 0.0)
DEMO 1.0
DEMO 2.0
tips:簡單介紹一下wwwroot以及index.html
示例
文件結構
DEMO 3.0
家目錄wwwroot
class Response
Build--------------Response不可缺少的一環
index.html作為默認訪問是需要特殊處理的
????????書接上回,雖說應用層在一定意義上是可以被我們自己實現的,但其實應用層依然有很多行業規范。其中最出名的當然屬HTTP
????????
【LINUX網絡】應用層自定義協議與序列化——通過實現一個簡單的網絡計算器來體會自定義協議-CSDN博客
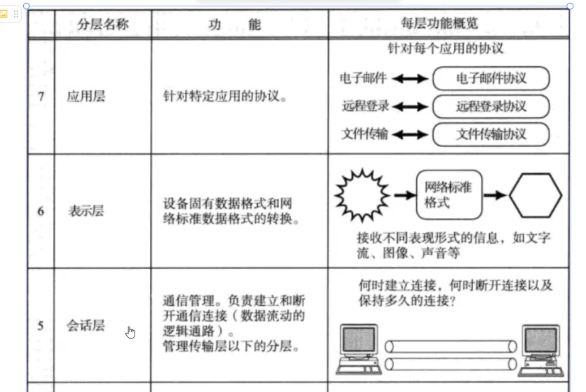
1. 初識HTTP
? ? ? ? HyperText Transfer,超文本傳輸協議,是一種規定了客戶端如何訪問服務器的協議,以保證超文本可以被交換和傳輸(如 HTML 文檔)。
?????????客戶端通過 HTTP 協議向服務器發送 請求,服務器收到請求后處理并返回響應。
? ? ? ? Http有以下的一些特點:
???????? ? ? ? 無連接、無狀態,即服務器不會保存客戶端的信息,每次訪問都需要重新建立連接。比如,在OAuth2協議中,Token需要一直被放在URL中表示具有訪問權限。
http是基于Tcp實現的:
應用層協議:HTTP
HTTP基于TCP協議實現
采用TCP意味著繼承了其全雙工通信、序列化傳輸和報文交換等特性
不同應用層協議有各自獨特的需求,因此協議種類繁多
但所有應用層協議都存在一個共同點:依賴流式服務確保報文的完整性
tips:網絡中的一些新名詞(AI生成):
????????
超文本(Hypertext)
超文本是一種文本形式,它包含可以鏈接到其他文本的超鏈接。這些鏈接可以是文本、圖片、視頻等其他媒體形式。超鏈接使得用戶可以通過點擊來跳轉到同一文檔的不同部分或完全不同的文檔。超文本是萬維網(World Wide Web)的基礎,它允許用戶在不同網頁之間導航。
HTML(HyperText Markup Language)
HTML 是一種標記語言,用于創建網頁和網頁應用程序中的內容結構。它定義了網頁的結構和內容,但不涉及樣式和行為。HTML 文檔由一系列的元素(elements)組成,這些元素通過標簽(tags)來定義。例如,
<html>定義了整個網頁的開始和結束,<body>定義了網頁的主體內容,<h1>到<h6>定義了不同級別的標題,<p>定義了段落。HTML 5 是 HTML 的最新版本,它增加了對多媒體內容的支持,如音頻和視頻,以及圖形和動畫等。
XML(eXtensible Markup Language)
XML 是一種標記語言,用于存儲和傳輸數據。它與 HTML 相似,但 XML 被設計為一種數據描述語言,而不是一種用于顯示數據的語言。XML 允許用戶定義自己的標簽,這使得它非常靈活,可以用于各種不同的數據表示需求。
XML 的一些關鍵特性包括:
可擴展性:用戶可以定義自己的標簽來描述數據。
自描述性:XML 文檔包含了足夠的信息來描述其內容,不需要外部的元數據。
層級結構:XML 數據可以組織成樹狀結構,這使得它非常適合表示復雜的數據關系
正式學習http是什么之前,再來了解一下什么是URL
2. URL
? ? ? ? 2.1 基本結構
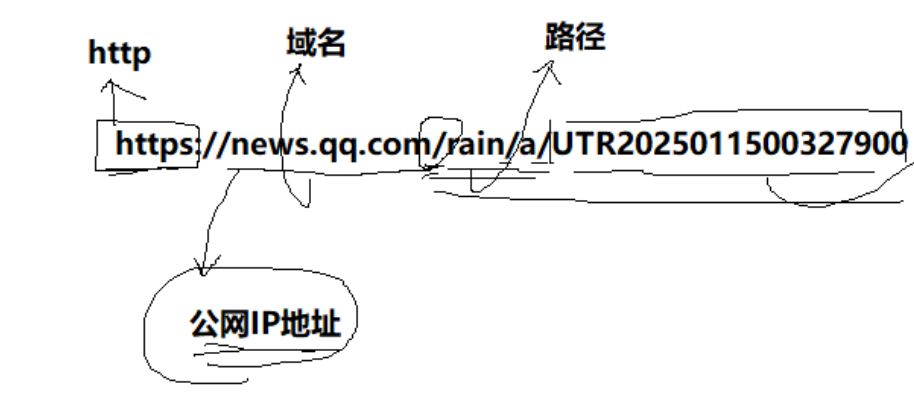
平時我們俗稱的 "網址" 其實就是說的 URL

URL還有另一個名字:Uniform Resource Locator,簡稱 URL)是互聯網上用來標識某一處資源的地址。URL 提供了一種方式,通過它可以訪問互聯網上的各種資源,如網頁、圖片、視頻、音頻文件等。
對于一個URL,首先是協議名稱(https表示是加密狀態)
????????????????????????
然后的news.qq.com是域名。域名(Domain Name)是互聯網上用于標識和定位計算機或計算機組(通常是指網站)的一個文本字符串。域名系統(Domain Name System,簡稱DNS)將域名轉換為數字IP地址,這樣人們就可以通過易于記憶的域名來訪問網站,而不必記住復雜的數字地址。由以上內容不難看出,其實域名是IP地址的另一種表現形式,會被體系結構解釋成目標服務器的IP地址。
最后的rain/a/xxxxxx是路勁,其實是目標文件在服務器上的被訪問資源的地址(有沒有覺得這個地址看著很像是文件地址?)。被訪問的資源就是一種文件。
????????在URL(統一資源定位符)中,以斜杠
/?開始的部分(比如上述圖片中的就是/rain/...)并不總是代表文件系統的根目錄,而是通常被稱為“web根目錄”。web根目錄是Web服務器上一個特定的目錄,它通常是Web服務器提供服務的起始點,所有的Web內容都是從這個目錄開始組織的。
所以,HTTP請求的資源本質是文件。

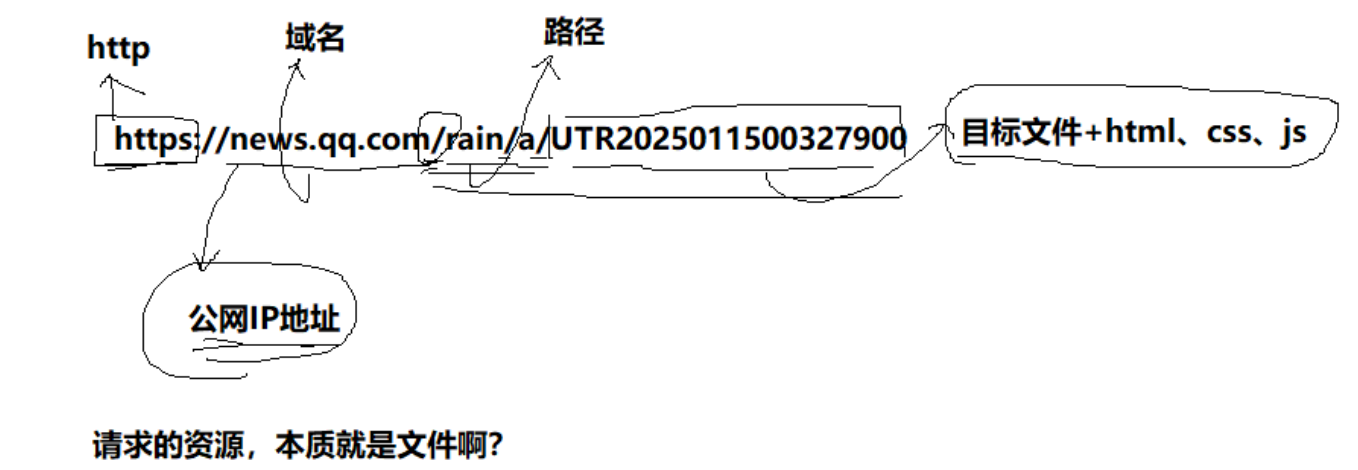
什么是上網
對于我們程序員來說,用戶上網的一些基礎背景概念:
1.我的數據給別人。別人的數據給我 -> IO->上網的所有行為,都是在IO
2. 什么是資源?圖片、音頻、視頻、文本
3. 客戶訪問的資源一定是在世界上的某臺機器上放著的(通過IP確定)。并且為了獲取資源,需要確定系統的路徑->這兩個信息被URL合在一起確定下來了。
現在,假設我們已經通過URL打開了一個資源。剛剛說到,http是不記錄訪問者信息的,請問如何把資源推送回去呢?
?打開文件之后,用哪個端口號推回去呢?如何把資源送回去呢?
因為指明協議,就相當于明確了回來的時候是要回到哪個端口(比如1024以內的端口,都被比較出名的協議給占了)
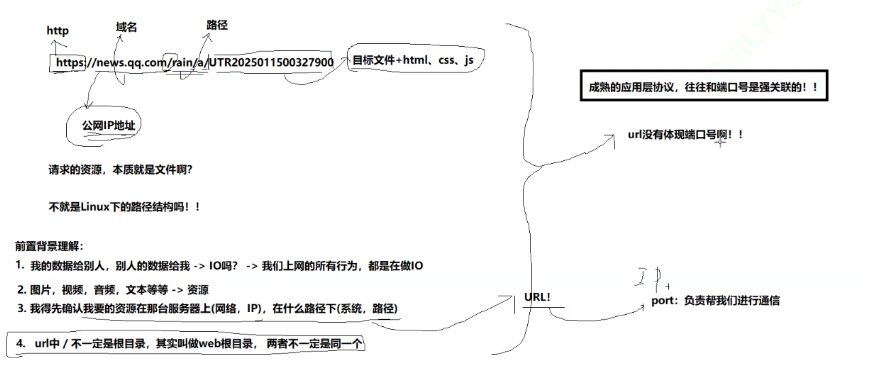
這也是為什么URL中只標注了域名,沒有標注端口號? ? ??
????????成熟的應用層協議通常與特定的端口號強烈關聯。這種關聯是通過互聯網號碼分配機構(IANA,Internet Assigned Numbers Authority)來管理和分配的,以確保不同服務和應用程序之間的通信不會發生沖突。
? ? ? ? 換句話說,像http這樣的協議,端口號都是寫死了的。
一些知名端口(Well-Known Ports):從0到1023,這些端口號被IANA分配給了特定的服務。例如:
端口 80 通常用于 HTTP(超文本傳輸協議)。
端口 443 通常用于 HTTPS(安全的超文本傳輸協議)。
端口 22 通常用于 SSH(安全外殼協議)。
端口 25 通常用于 SMTP(簡單郵件傳輸協議)
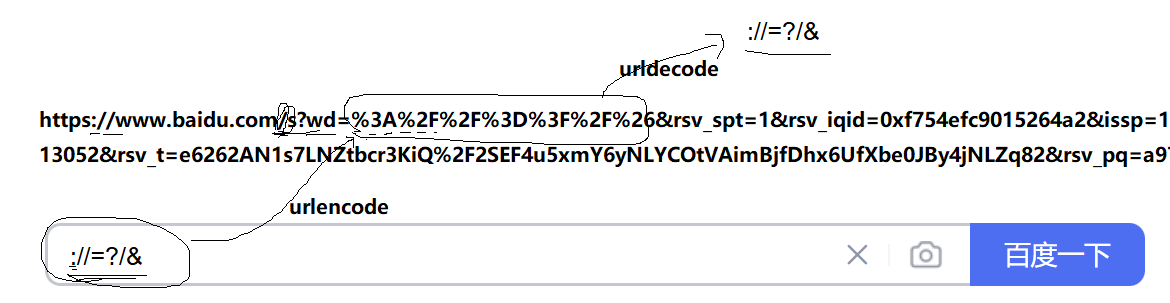
2.2 URL中的?與urldecode\urlencode
?的右邊都是資源或者參數
????????URL(Uniform Resource Locator,統一資源定位符)的
?右邊部分被稱為查詢字符串(query string)。查詢字符串用于向服務器提供額外的信息,這些信息通常用于指定對資源的某些操作或過濾條件。查詢字符串由一個或多個參數組成,每個參數由一個名稱和一個值組成,參數之間用&符號分隔。????????比如 搜qinghua,wd參數(world,關鍵字)值就是qinghua,最后一排還有一個prefixsug,可能是某種前綴,表示還要搜索以qinghua為前綴的其他信息。

urlencode:就像C語言中的/ % 等特殊轉義符,在搜索的時候會被加碼成其他樣子。
包括不限于 : // ? / = &都是被轉義了的。
轉義的規則如下:將需要轉碼的字符轉為 16 進制,然后從右到左,取 4 位(不足 4 位直接處理),每 2 位做一位,前面加上%,編碼成%XY 格式

再比如,搜索這幾個轉移字符 //?=&/這是一個可以URL解碼編碼的工具:UrlEncode編碼/UrlDecode解碼 - 站長工具
易混淆:URL和HTTP傳輸請求兩者是什么關系?
先來看一眼,http的請求到底是長什么樣的
HTTP是一種用于在網絡上傳輸數據的協議,就像TCP一樣,只不過http是基于TCP的協議
URL才是日常所說的”網址“,是用于指定網絡上的資源位置,是一個基于萬維網的‘‘文件地址’’
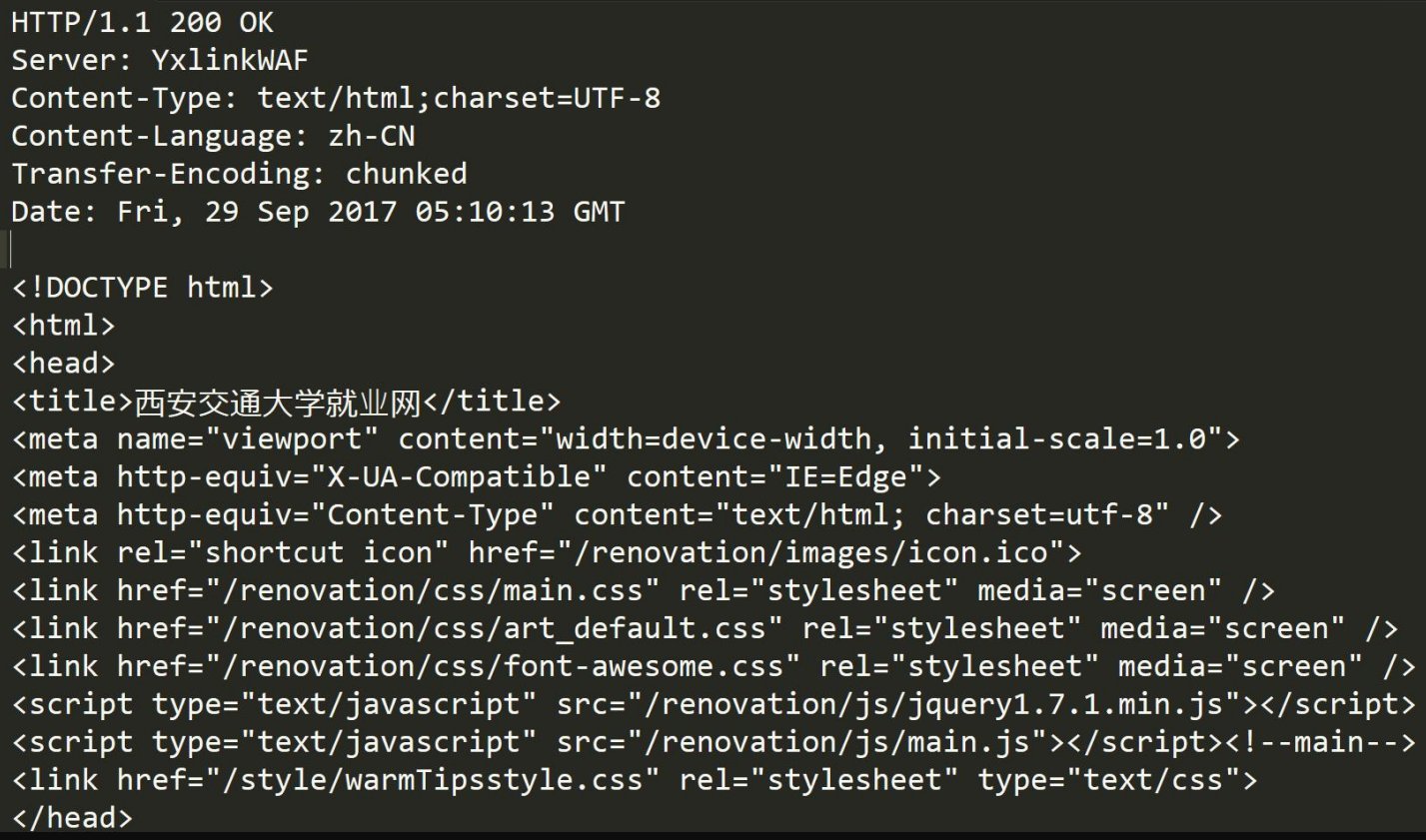
關于http協議,是如何做到如何保證面向字節流的完整性的?
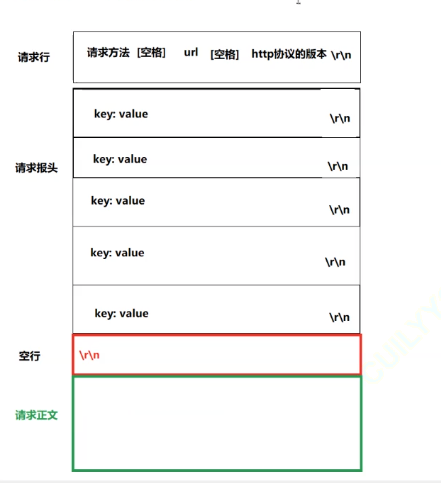
HTTP的宏觀結構
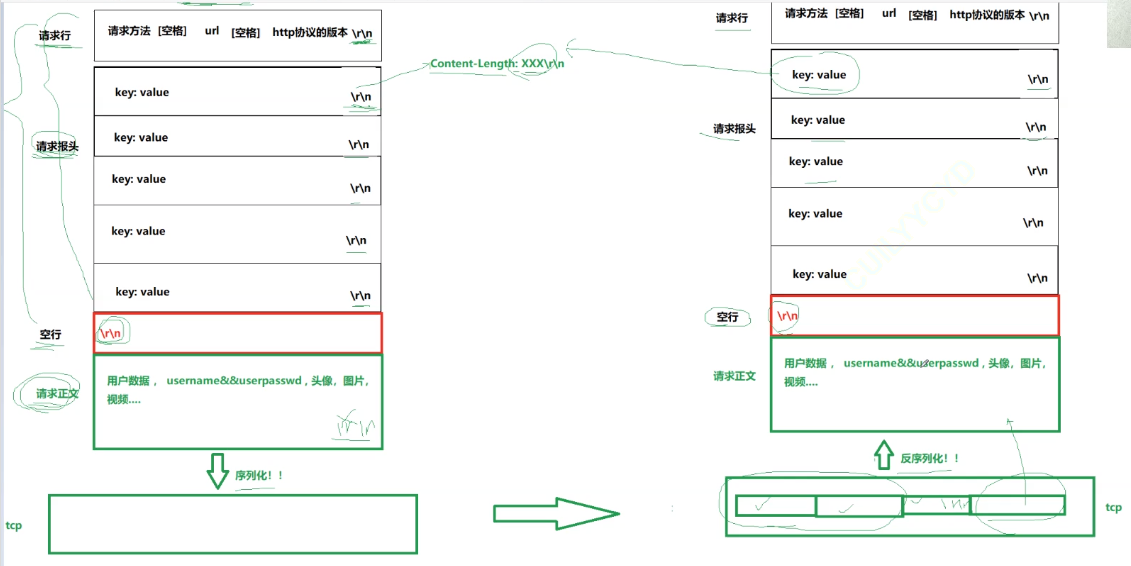
要想進一步理解HTTP,必須手搓一個,手搓之前,一起看一下宏觀結構
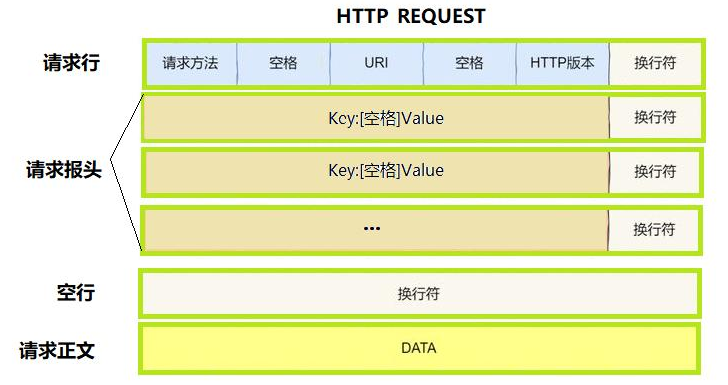
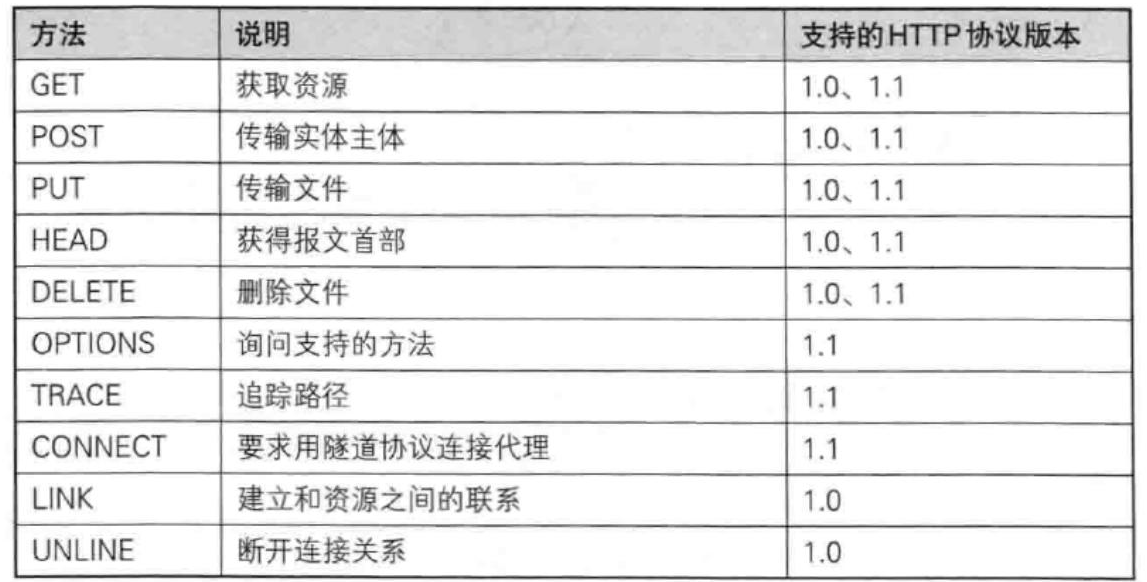
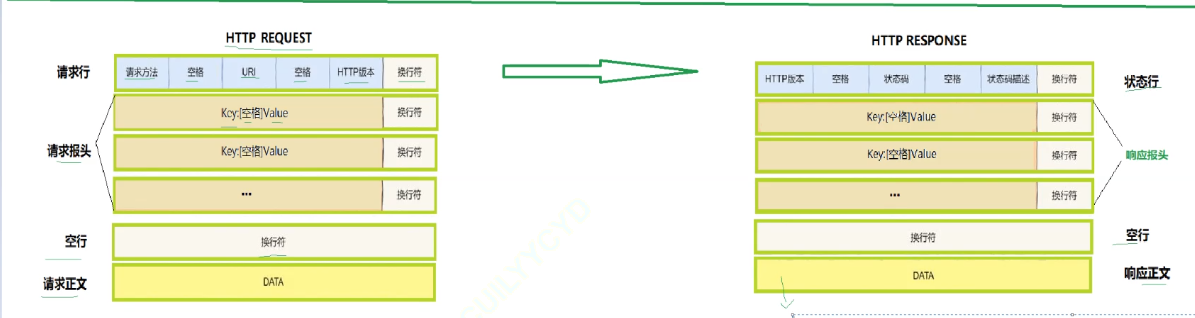
????????首先是請求行,請求行依次包含三個數據內容:請求方法(最常用的只有GET和POST)、URL、HTTP協議版本,三個內容之間用空格隔開。以下是常見的http方法,具體的使用會在以后詳細講。
????????
然后是http的請求報頭:
????????????????????????
包含多行內容,每一行都有自己固定的格式,也都是以換行符代表結束
Key一般是請求相關的屬性,Value一般是該屬性的內容,后會接一個空行,空行的本質就是\r\n
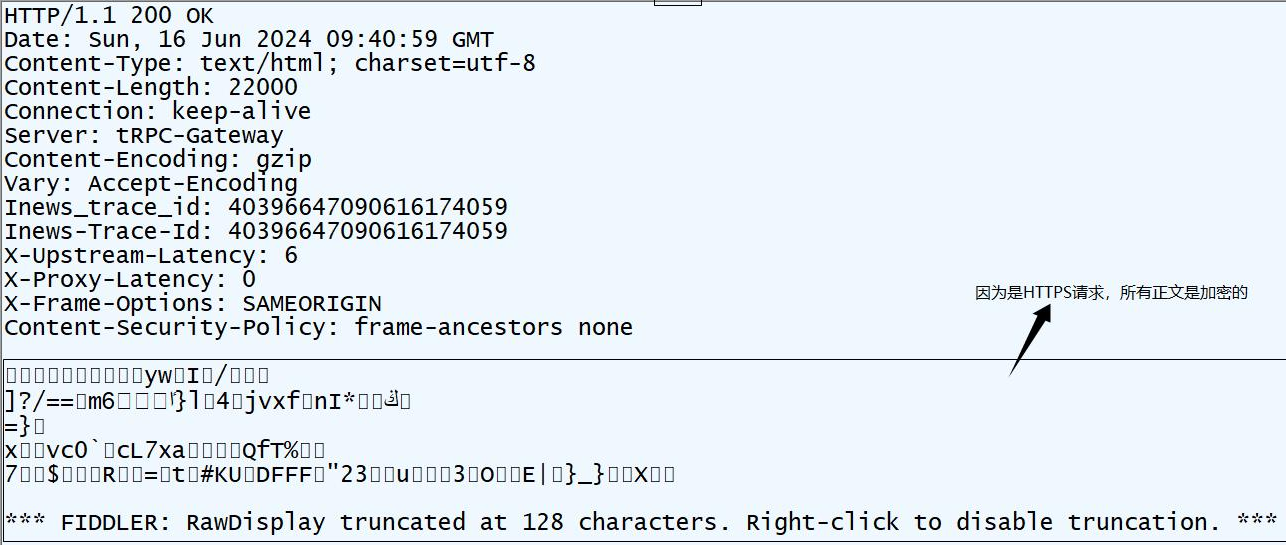
HTTP RESPONSE同理,狀態行內容有相應的變化。
名字上,RESPONSE主要是狀態行 響應報頭 空行 響應正文
狀態碼,比如404,描述就是not found

很明顯,這樣的request或者response是需要被OS管理的
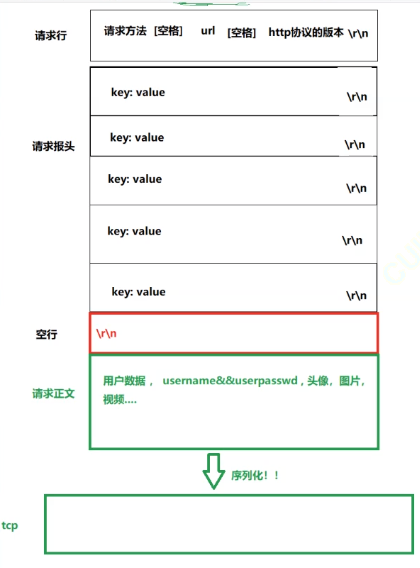
可以分別構造兩個class來管理兩種屬性。請求正文、報頭等不過就是里面的成員,甚至還能大膽推測,就是string類的
在把這個類丟進tcp的緩沖區之前,一定需要進行序列化,序列化之后再讓TCP去傳輸,傳輸也就不需要刻意再去管,交給TCP即可。
????????????????????????
現在再看這是不是更能理解為什么HTTP是應用層協議了?
說白了,其本職工作只是結構化、序列化,真正的傳輸(在當前視角下),只要丟進TCP層次的緩沖區即可。
如果有看過上一文的讀者可能會發現,如果HTTP更多的功能是用于序列化,那其實非常像網絡計算器中的Parse函數。
大概思考如何進行序列化:
序列化,就是把前面的內容全部縮成一個長字符串
空行可以用作分割,空行之前就是報頭,空行之后就是正文
報頭里面有描述正文長度的字段
?反序列化的時候就可以按行讀取,一定也會讀到空行。讀到空行之后,一定可以在請求報頭中獲得一個Content_length字段,再次讀正文的時候就比較方便了。
http本身作為一個協議,序列化等都是自己實現的,沒有依賴其他的比如JSON庫。
REQUEST和RESPONSE很像,所以他們的序列化和反序列化做法可以說是幾乎完全一樣的。
理論部分暫時結束,下面會基于以前的部分代碼先進行一次封裝,封裝好了就構建HTTP,讀者朋友可以先跟著之前的敲一遍,也可以直接跟著以下代碼寫。【LINUX網絡】使用TCP簡易通信_liunx 不啟用中轉連接tcp服務-CSDN博客
3. DEMO CODE
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?-----------------------記錄完成demo代碼中的過程與遇到的困難
寫代碼才能真正手撕清楚這個過程,不過這個寫和調試的過程注定是費時和痛苦的。
對于初學者來說,代碼量確實有點大,共勉。
我的構思中,大概分層為:Socket層(采用模板方法模式,將Socket作為基類,TcpSocket作為派生類,讀者可以自行實現UdpServer),TcpServer層(復用Socket層)
先談套接字封裝,封裝完了就可以實現一個簡單的http_server
1. 封裝Socket的模塊
TcpServer大概分為socket,bind,listen,accept四步,并不是直接就能用的。我們希望能封裝一個類來完成以上工作,讓我們可以直接在TcpServer中使用
這次的封裝采用? ?模板方法模式
首先完成一個Socket的類:
注意:
????????????????除了幾個到派生類中去具體實現的虛方法,可以先刻畫好一個BuildSocket方法,到時候可以直接調。
???????? ? ? ? 根據socket\bind\listen\accept四步依次實現,不過應當考慮到accept是需要在服務器運行的主邏輯中去執行的
#pragma once
#include <iostream>
#include <string>
#include <unistd.h>
// 網絡四件套
#include <sys/socket.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <arpa/inet.h>// 基類,規定創建socket的方法
// 提供若干個、固定模式的方法
class Socket
{
public:virtual ~Socket() = 0;virtual int SocketOrDie() = 0;virtual bool BindOrDie() = 0;virtual bool ListenOrDie() = 0;virtual int Accept() = 0;virtual void Close();#ifdef _WINBuildTcpSocket(){SocketOrDie();BindOrDie();ListenOrDie();}
#else //LINUX版本void BuildSocket(){SocketOrDie();BindOrDie();ListenOrDie();}
#endifprivate:
};?開始實現派生類:private中暫時構思的是加一個_sock_fd即可,初始賦值為-1,檢測到值為-1就是暫時還不能使用的。
virtual int SocketOrDie() override{_sock_fd = socket(AF_INET,SOCK_STREAM,0);if(_sock_fd < 0){LOG(LogLevel::ERROR) << "Tcp socket fail";DIE(SOCK_ERR);}LOG(LogLevel::DEBUG)<<"listen socket success";return _sock_fd;}Bind的時候要注意結合之前我們自己實現的封裝網絡地址的類。Bind的時候需要把端口號傳進去,
用傳進去的port構造一個Inet_Addr的對象
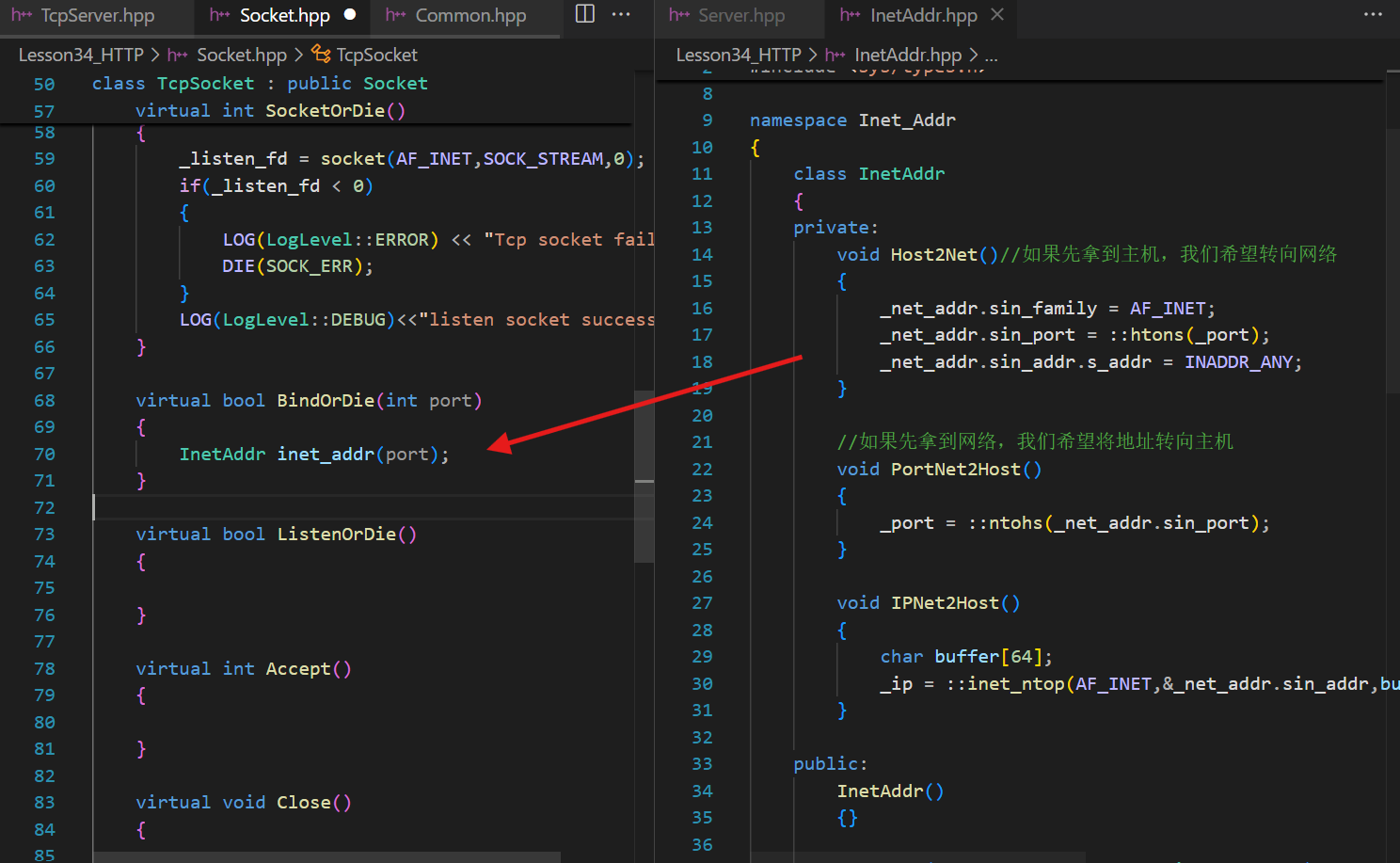
注意,這只是個TCP的socket的接口,不是TCP服務器本身。這個類只是用于服務于我們在TCPServer中去構建一個個的Socket
class TcpSocket : public Socket { public:TcpSocket():_sock_fd(gsockfd){}virtual int SocketOrDie(){_sock_fd = socket(AF_INET,SOCK_STREAM,0);if(_sock_fd < 0){LOG(LogLevel::ERROR) << "Tcp socket fail";DIE(SOCK_ERR);}LOG(LogLevel::DEBUG)<<"listen socket success";return _sock_fd;}virtual bool BindOrDie(int port){if(_sock_fd==gsockfd){return false;}InetAddr inet_addr(port);int n = ::bind(_sock_fd,inet_addr.NetAddr(),inet_addr.NetAddrLen());if (n < 0){LOG(LogLevel::ERROR) << "bind error";DIE(BIND_ERR);} LOG(LogLevel::DEBUG)<<"bind success";return true;}virtual bool ListenOrDie(){if(_sock_fd==gsockfd){return false;}int n = ::listen(_sock_fd, BACKLOG);if(n<0){LOG(LogLevel::ERROR)<<"listen false";DIE(LISTEN_ERR);}LOG(LogLevel::DEBUG)<<"listen success";return true;}virtual int Accept(){}virtual void Close(){::close(_sock_fd);}virtual ~TcpSocket(){} private:int _sock_fd; };http是基于TCP協議的,所以http是需要基于TcpServer的,一層一層往上搭。
??TcpServer:
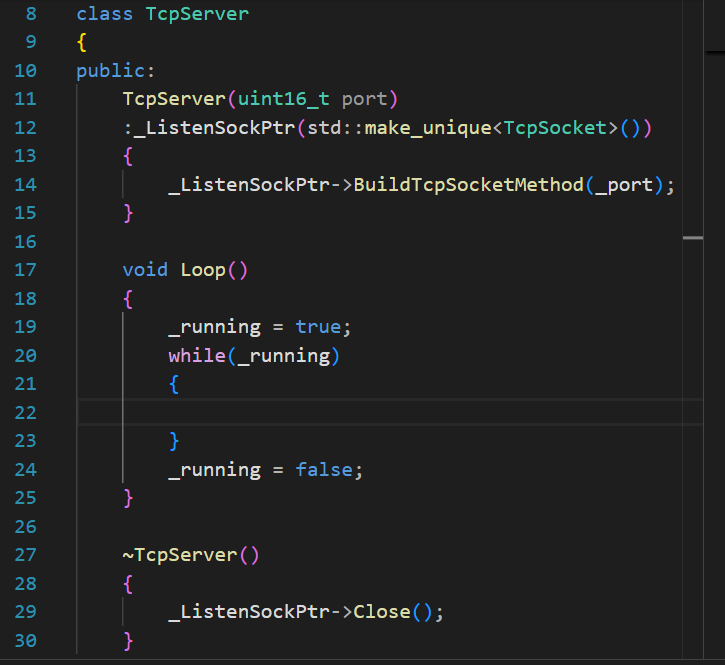
loop模塊,核心邏輯
loop模塊有兩個任務,accept和IO
如何設計這個Accept模塊呢?
? ? ? ? 以下是博主自己的思考(思考怎么設計參數、如何傳參也是開發中最重要的一步)
????????在TcpServer層,肯定希望直接能通過我們封裝好的Ptr調一個Accept來獲得一個可以直接用的tcpsocket(多態情況下肯定是需要被基類去控制的)。不過此處的Socket類被我們實現成了一個虛類,最多使用指針去實現。
那么TcpSocket層次的Accept方法就可以返回一個構造好的Socket的智能指針。值得注意的是,此處的返回的這個智能指針需要是shared的而非unique。
相當于用父類指針指向了一個子類的實例化對象
? ? ? ? 再來看Sockegt層次中Accept的參數——說白了,我們封裝的Accept函數就是處理好 真正的accept 的兩類返回值:打開的 ''打工人sockfd'' 以及了解客戶端信息的struct sockaddr_in。
? ? ? ? 結合上述邏輯,我覺得可以在上層調用時傳一個Client的InetAddr*類型參數,作為輸出型參數,保留::accept的兩個輸出型參數的sockaddr_in的信息。另外用accept的返回值構建一個shared實例,返回其指針到TcpServer層
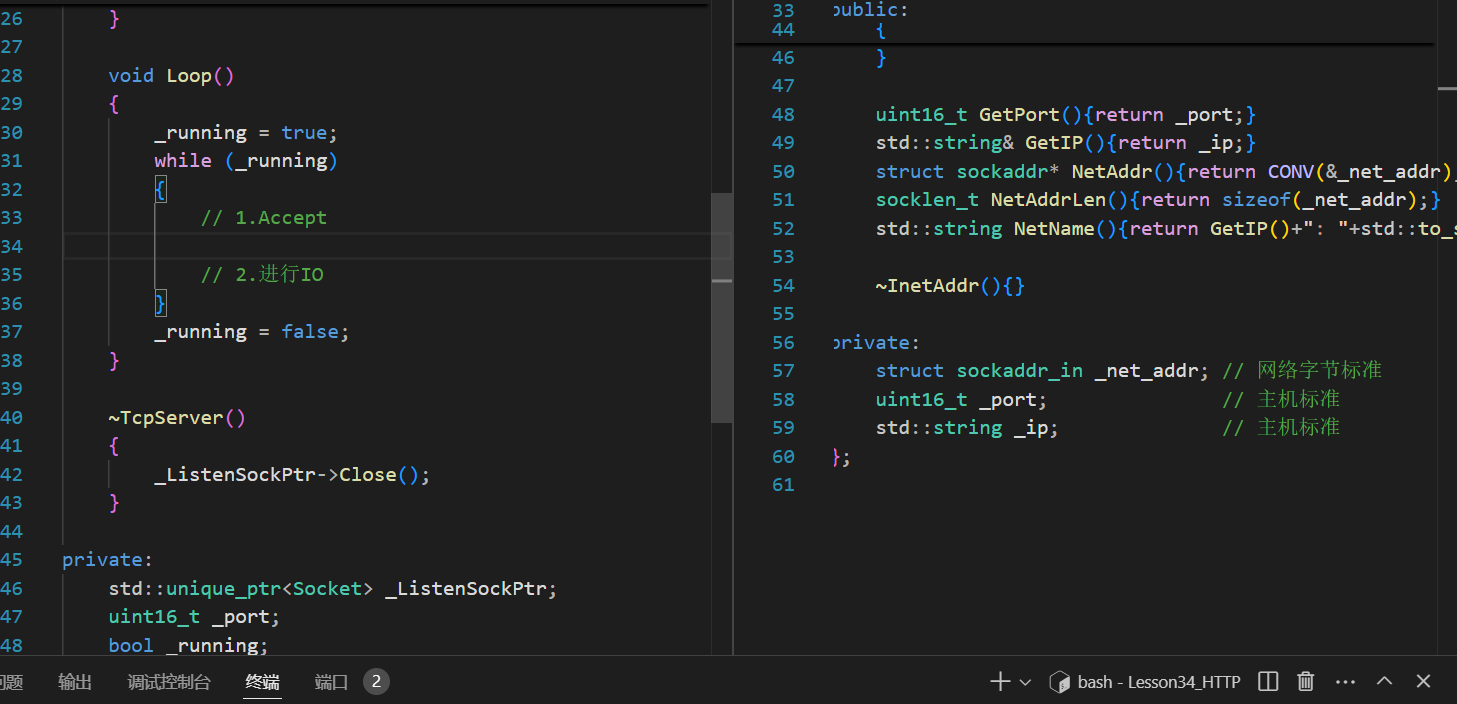
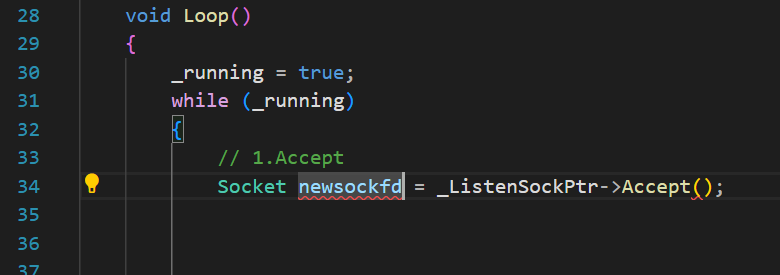
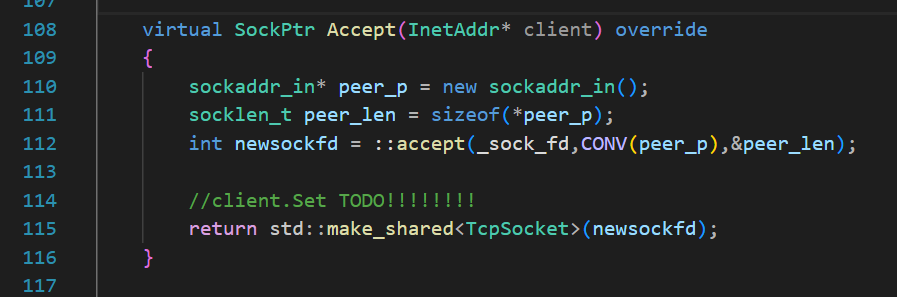
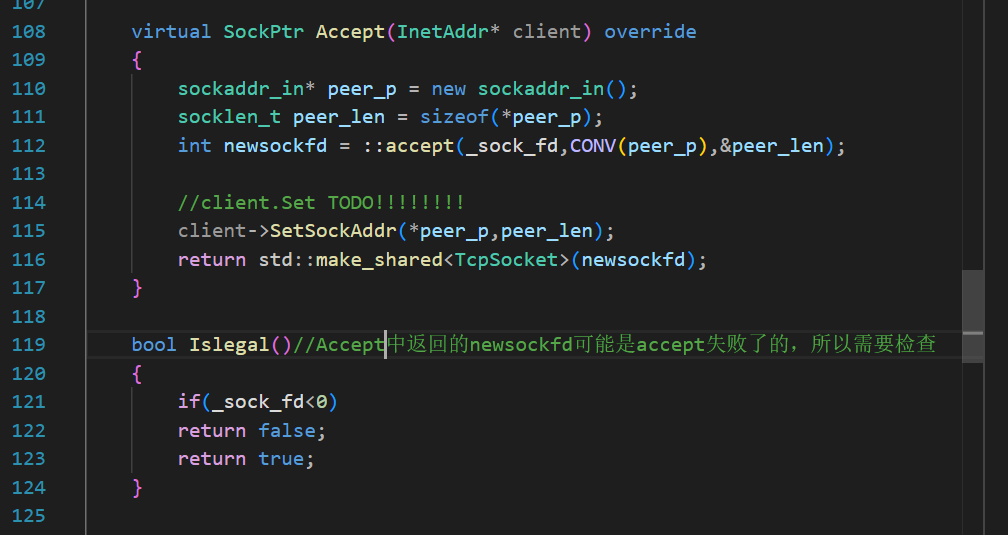
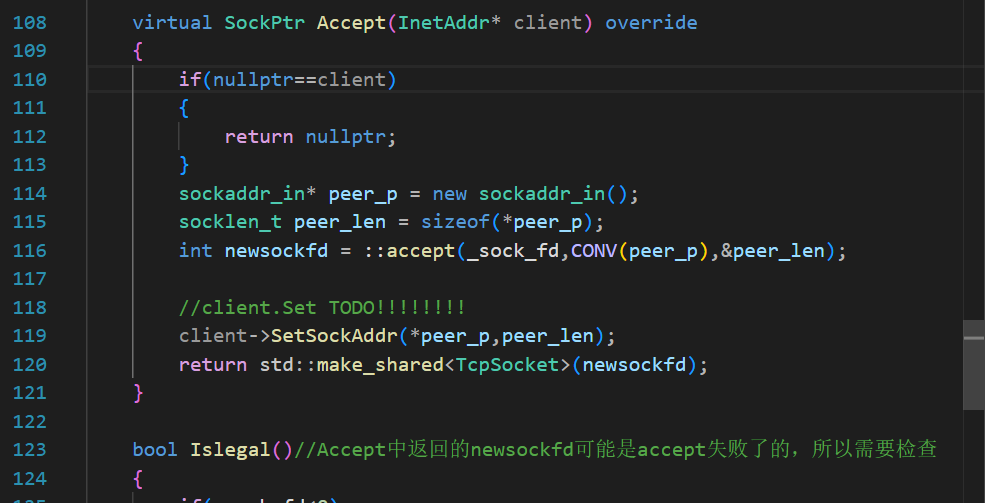
現在的Accept實際拿到的是一個Socket基類指向的TcpSocket派生類的對象,其中的成員變量_sock_fd就是剛剛accept的newsockfd
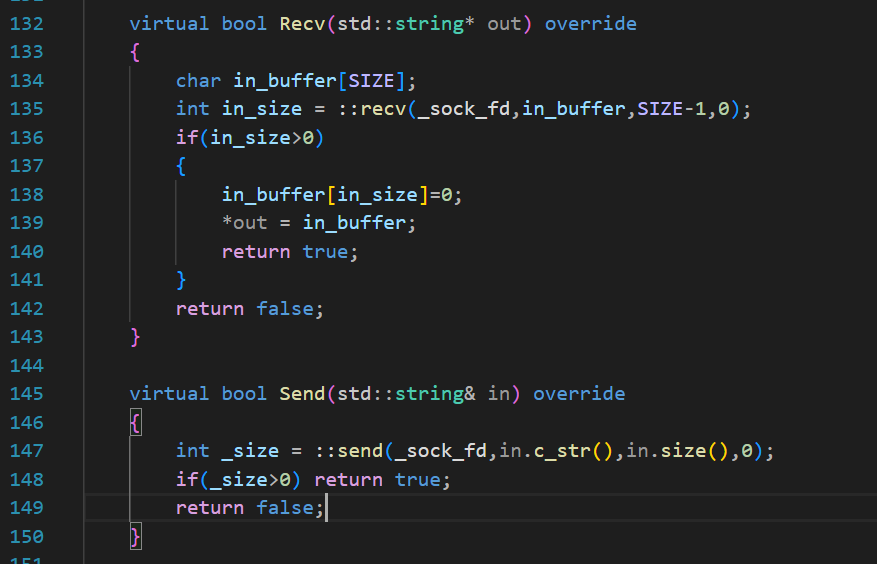
所以需要在Socket類中再去封裝對應的讀寫方法,這樣在TcpServer層次才能直接去讀寫這個被封裝起來并且被傳回到TcpServer的Socket。(這樣設計,可以方便TcpServer層次直接使用讀寫接口)
????????
我們希望的:
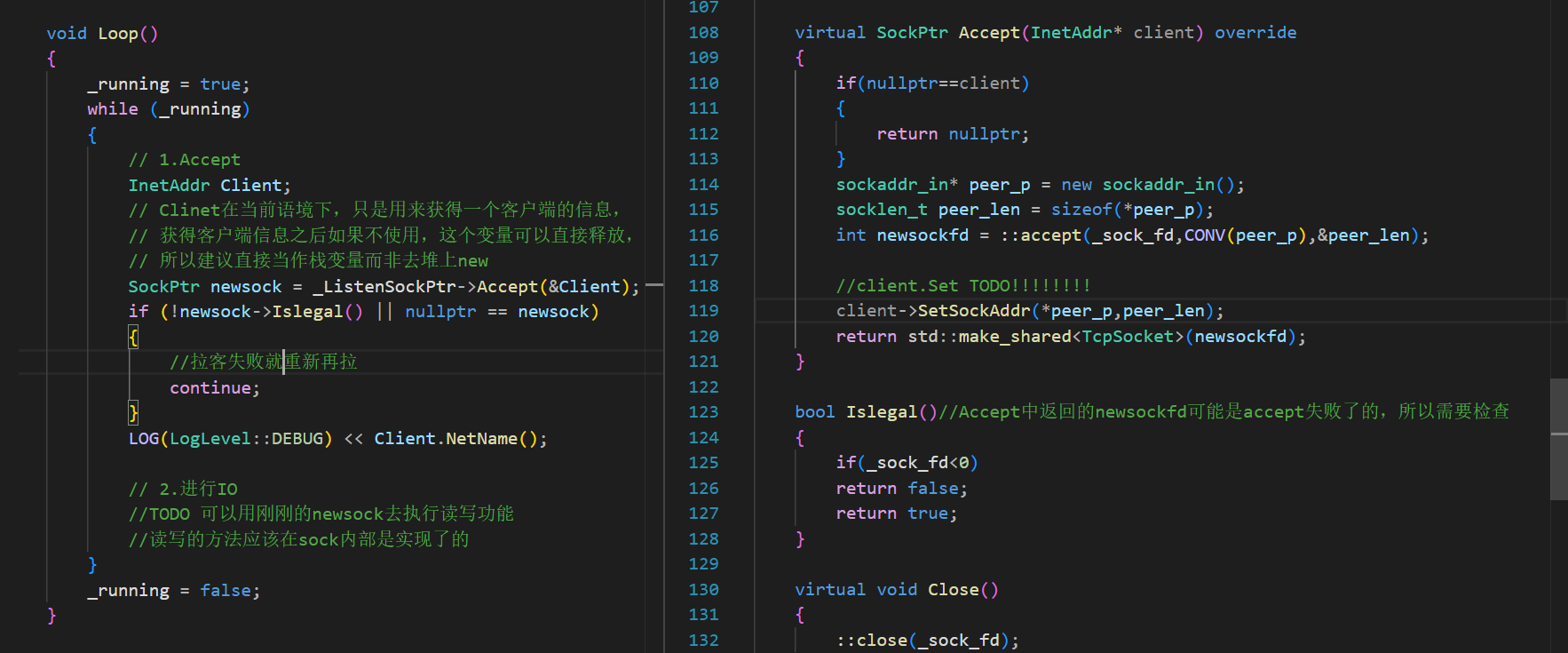
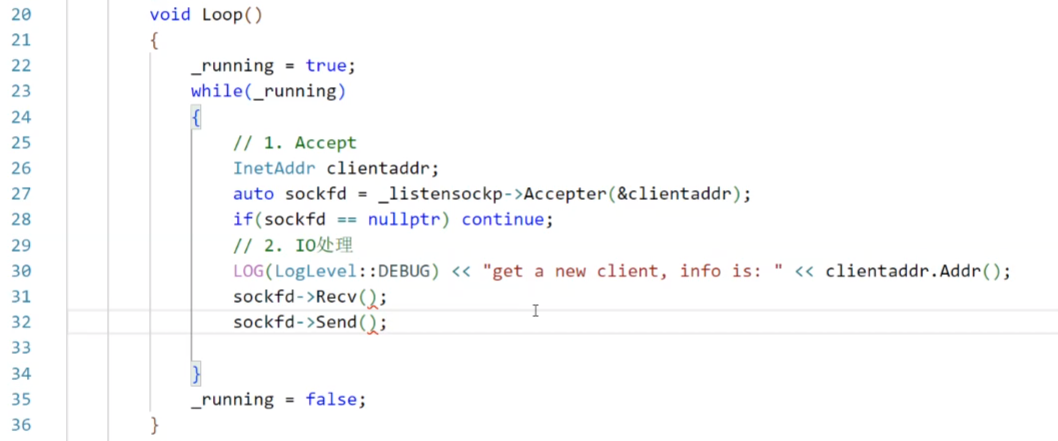
HttpServer
別忘了,盡管我們已經可以在Tcp層次直接調Recv和Send,但是我們為了保證字節流的完整性,還需要進行對應的序列化與反序列化。先大概實現一個recv與send叭。
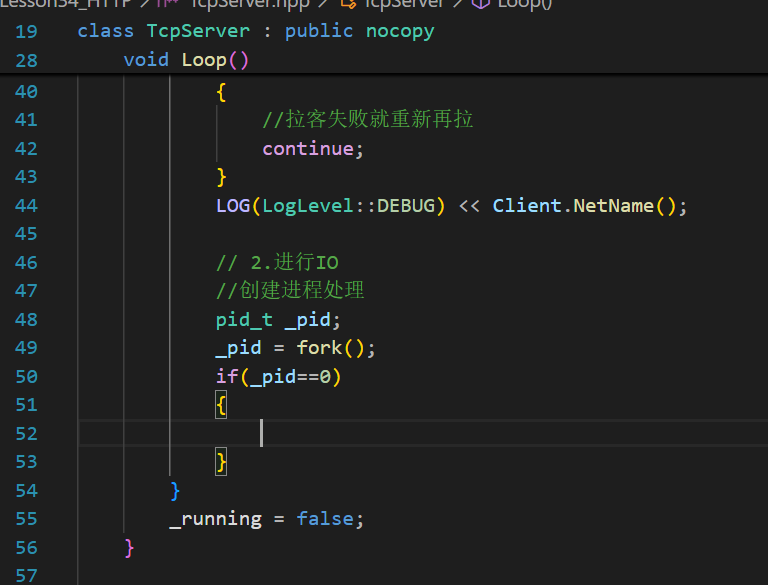
然后就是調用其他的進程、線程或線程池來把具體的處理函數調起來,此處我們選擇進程
子進程沒有必要繼續繼承這個listen_fd。
既然任務都交給孫子進程了,父進程就等待并回收子進程即可。并且父進程也可以關閉他accept到的文件描述符
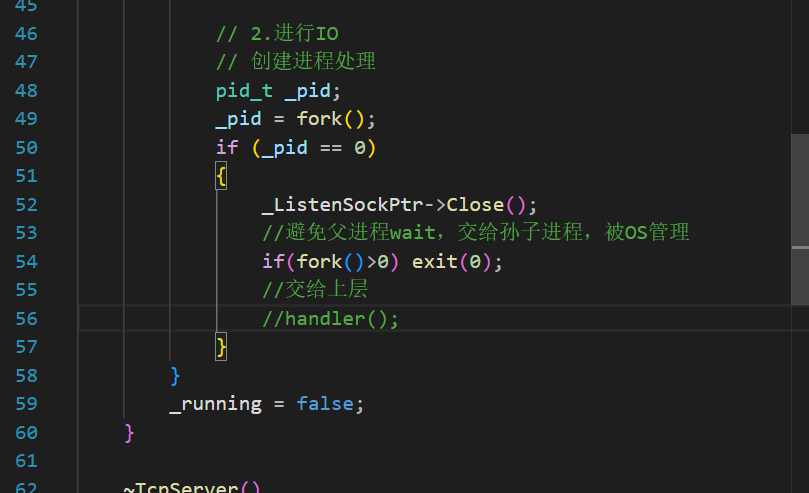
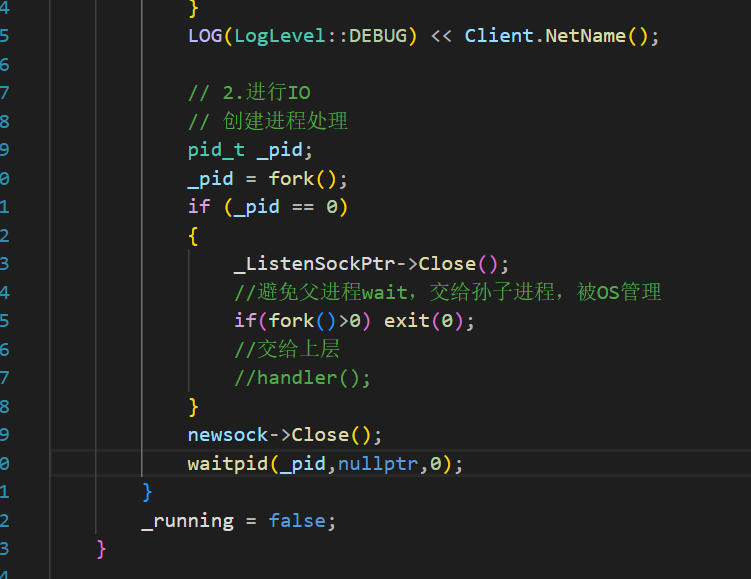
HttpServer需要遵守一定的規則,所以還需要一個HttpProtocol,最后調用HttpProtocol的也該命名為Http.cc。
????????現在需要進一步把文件描述符丟給創建的孫子進程,也就是上面注釋掉的handler。
除了sockfd丟給handler,剛剛在Accept中的輸出型Client也可以用起來:
處理方法丟給上層,直接調用一個_handler就可以了。
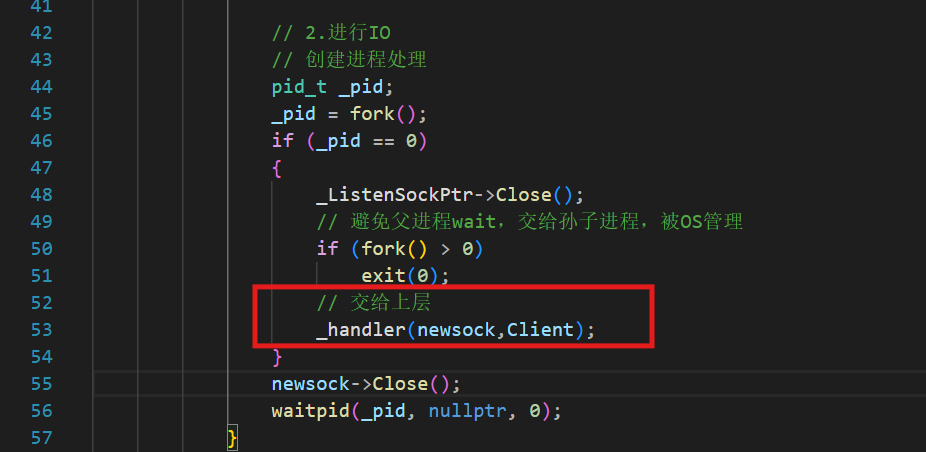
因為IO的具體邏輯包括解析、是否讀完整等。所以,所謂解析、與完整性的判斷,就是交給Http層次就可以了。
HTTP一定都是基于Tcp協議的:
關于文件描述符是如何傳進來:
????????
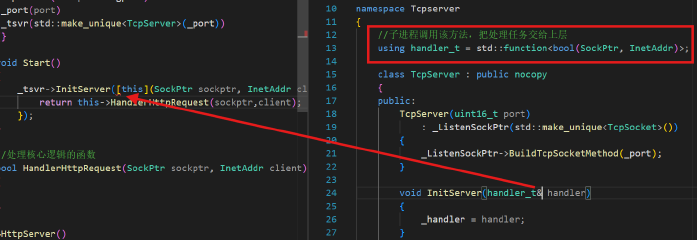
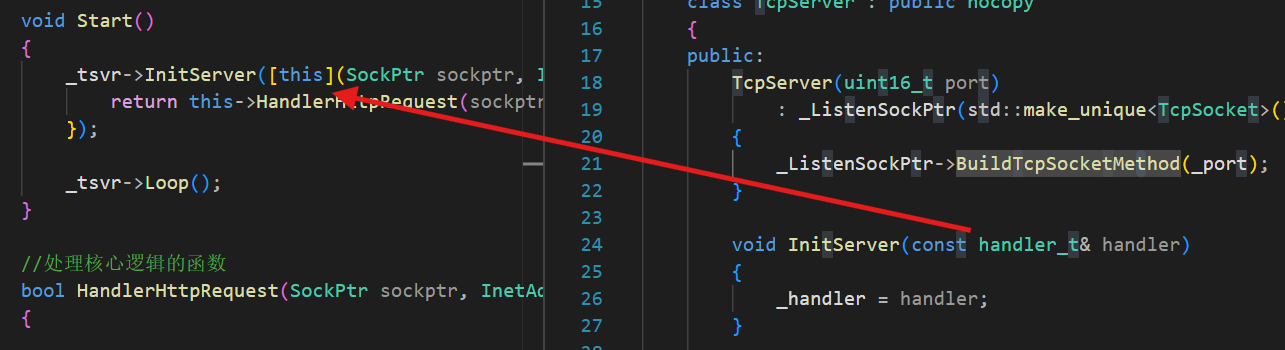
class HttpServer : public nocopy { public:HttpServer(int port = gport):_port(port),_tsvr(std::make_unique<TcpServer>(_port)){}void Start(){_tsvr->InitServer([this](SockPtr sockptr, InetAddr client){return this->HandlerHttpRequest(sockptr,client);});_tsvr->Loop();}//處理核心邏輯的函數bool HandlerHttpRequest(SockPtr sockptr, InetAddr client){}考慮在TcpServer中加一個Init模塊來單獨初始化handler,這樣在HTTP層次,構建TcpServer的時候才能更方便的去傳lambda
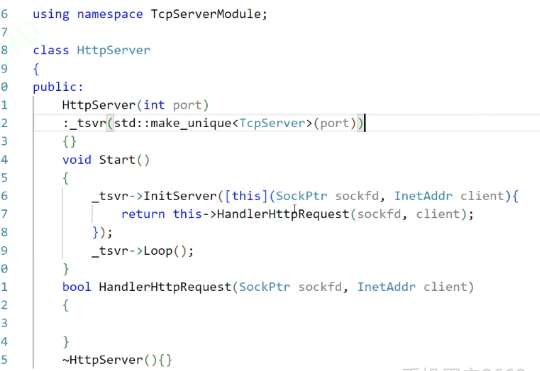
語法tips:
lambda表達式返回的是一個臨時的函數對象,臨時變量具有常性,如果用一個&接受會導致權限的放大,所以可以選擇賦值或者const&(&會放大權限,const保證權限不被放大)
初代版本(DEMO 0.0)
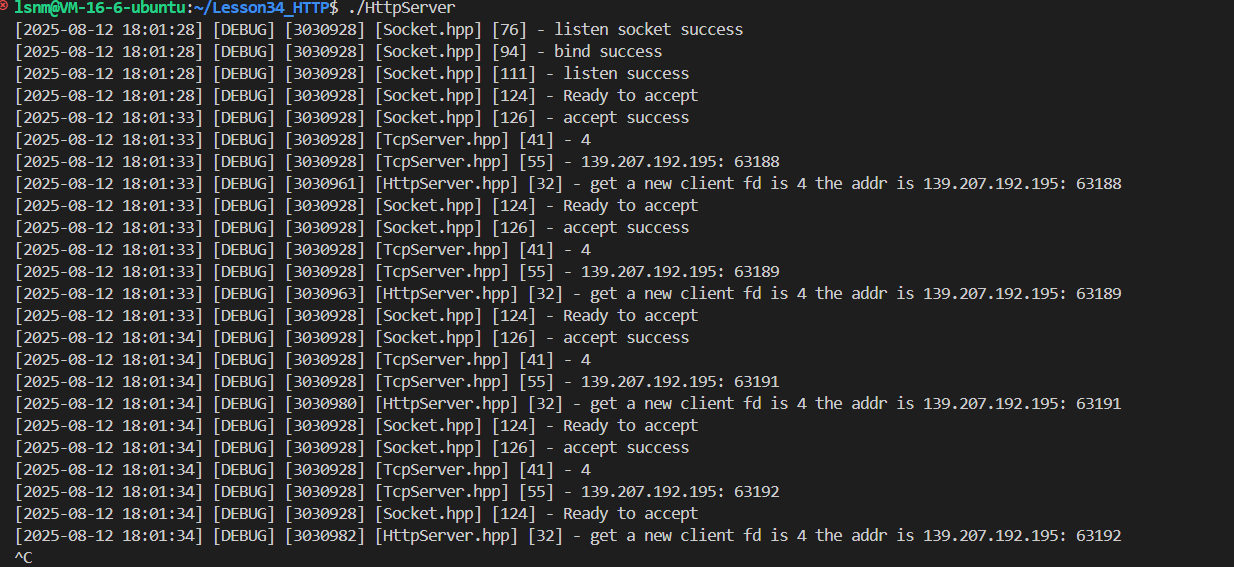
目前為止,整個程序已經可以跑起來了。
直接用瀏覽器訪問當前服務器,就會被accept。
先貼一下調過后的代碼:從頂向下,依次是HTTP、TCP、SOCKET
#pragma once#include <iostream>
#include <string>
#include "TcpServer.hpp"
#include "HttpProtocol.hpp"//現在這還是一個空的頭文件const uint16_t gport = 8080;using namespace Tcpserver;class HttpServer : public nocopy
{
public:HttpServer(uint16_t port = gport):_port(port),_tsvr(std::make_unique<TcpServer>(_port)){}void Start(){_tsvr->InitServer([this](SockPtr sockptr, InetAddr client){return this->HandlerHttpRequest(sockptr,client);});_tsvr->Loop();}//處理核心邏輯的函數bool HandlerHttpRequest(SockPtr sockptr, InetAddr client){LOG(LogLevel::DEBUG)<<"get a new client fd is "<<sockptr->Fd()<<" the addr is "\<<client.NetName();return true;}~HttpServer(){}
private:uint16_t _port;std::unique_ptr<TcpServer> _tsvr;
};#pragma once
#include <iostream>
#include <memory>
#include <sys/wait.h>
#include "Socket.hpp"
#include "Common.hpp"using namespace SocketModule;namespace Tcpserver
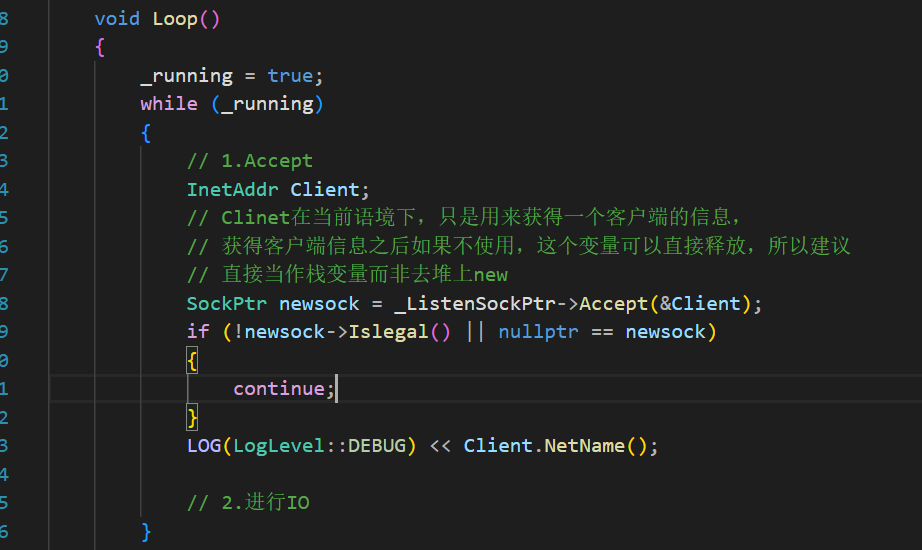
{// 子進程調用該方法,把處理任務交給上層using handler_t = std::function<bool(SockPtr, InetAddr)>;class TcpServer : public nocopy{public:TcpServer(uint16_t port): _ListenSockPtr(std::make_unique<TcpSocket>()), _port(port){_ListenSockPtr->BuildTcpSocketMethod(_port);}void InitServer(const handler_t &handler){_handler = handler;}void Loop(){_running = true;while (_running){// 1.AcceptInetAddr Client;// Clinet在當前語境下,只是用來獲得一個客戶端的信息,// 獲得客戶端信息之后如果不使用,這個變量可以直接釋放,// 所以建議直接當作棧變量而非去堆上newSockPtr newsock = _ListenSockPtr->Accept(&Client);LOG(LogLevel::DEBUG) << newsock->Fd();if (!newsock->IsAcceptlegal() || nullptr == newsock){// 拉客失敗就重新再拉// if(nullptr == newsock)// LOG(LogLevel::DEBUG)<<"nullptr == newsock";// if(!newsock->IsAcceptlegal())// {// LOG(LogLevel::DEBUG)<<"IsAcceptlegal";// //exit(9);// }continue;}LOG(LogLevel::DEBUG) << Client.NetName();// 2.進行IO// 創建進程處理pid_t _pid;_pid = fork();if (_pid == 0){_ListenSockPtr->Close();// 避免父進程wait,交給孫子進程,被OS管理if (fork() > 0)exit(0);// 交給上層_handler(newsock, Client);exit(0);}newsock->Close();waitpid(_pid, nullptr, 0);}_running = false;}~TcpServer(){_ListenSockPtr->Close();}private:std::unique_ptr<Socket> _ListenSockPtr;uint16_t _port;bool _running;handler_t _handler;};}#pragma once
#include <iostream>
#include <string>
#include <unistd.h>
#include <functional>
// 網絡四件套
#include <sys/socket.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <arpa/inet.h>#include "Common.hpp"
#include "Log.hpp"
#include "InetAddr.hpp"using namespace LogModule;
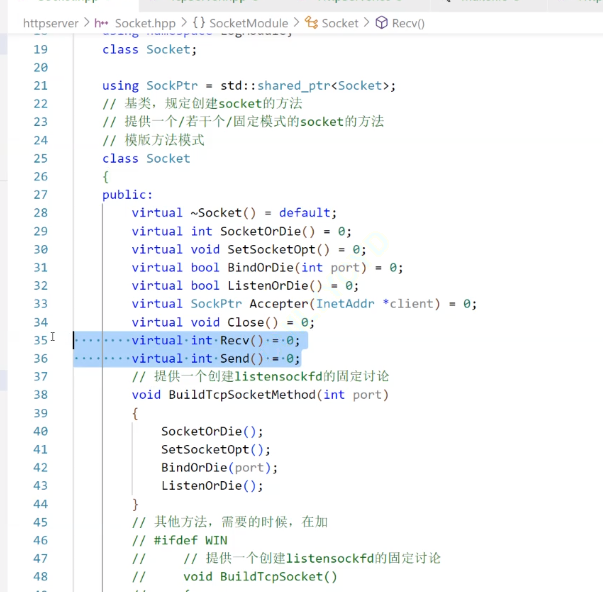
using namespace Inet_Addr;namespace SocketModule
{class Socket;using SockPtr = std::shared_ptr<Socket>;// 基類,規定創建socket的方法// 提供若干個、固定模式的方法class Socket{public:virtual ~Socket() = default;virtual int SocketOrDie() = 0;virtual bool BindOrDie(uint16_t port) = 0;virtual bool ListenOrDie() = 0;virtual SockPtr Accept(InetAddr *client) = 0;virtual bool Recv(std::string *out) = 0; // Recv的參數是一個輸出型參數virtual bool Send(std::string &in) = 0; // Send的參數是一個輸入型參數virtual void Close() = 0;virtual bool IsAcceptlegal() = 0;virtual int Fd() = 0;#ifdef _WINvoid BuildTcpSocketMethod(){SocketOrDie();BindOrDie();ListenOrDie();}
#elsevoid BuildTcpSocketMethod(uint16_t port){SocketOrDie();BindOrDie(port);ListenOrDie();}void BuildUdpSocket() {}
#endifprivate:};class TcpSocket : public Socket{public:TcpSocket(int sock_fd = gsockfd): _sock_fd(sock_fd){}virtual int SocketOrDie() override{_sock_fd = socket(AF_INET, SOCK_STREAM, 0);if (_sock_fd < 0){LOG(LogLevel::ERROR) << "Tcp socket fail";DIE(SOCK_ERR);}LOG(LogLevel::DEBUG) << "listen socket success";return _sock_fd;}virtual bool BindOrDie(uint16_t port) override{if (_sock_fd == gsockfd){return false;}InetAddr inet_addr(port);int n = ::bind(_sock_fd, inet_addr.NetAddr(), inet_addr.NetAddrLen());if (n < 0){LOG(LogLevel::ERROR) << "bind error";DIE(BIND_ERR);}LOG(LogLevel::DEBUG) << "bind success";return true;}virtual bool ListenOrDie() override{if (_sock_fd == gsockfd){return false;}int n = ::listen(_sock_fd, BACKLOG);if (n < 0){LOG(LogLevel::ERROR) << "listen false";DIE(LISTEN_ERR);}LOG(LogLevel::DEBUG) << "listen success";return true;}virtual SockPtr Accept(InetAddr *client) override{if (nullptr == client){return nullptr;}sockaddr_in *peer_p = new sockaddr_in();socklen_t peer_len = sizeof(*peer_p);LOG(LogLevel::DEBUG)<<"Ready to accept";int newsockfd = ::accept(_sock_fd, CONV(peer_p), &peer_len);LOG(LogLevel::DEBUG)<<"accept success";// client.Set TODO!!!!!!!!client->SetSockAddr(*peer_p, peer_len);return std::make_shared<TcpSocket>(newsockfd);}inline bool IsAcceptlegal() override // Accept中返回的newsockfd可能是accept失敗了的,所以需要檢查{if (_sock_fd < 0)return false;return true;}virtual bool Recv(std::string *out) override{char in_buffer[SIZE];int in_size = ::recv(_sock_fd, in_buffer, SIZE - 1, 0);if (in_size > 0){in_buffer[in_size] = 0;*out = in_buffer;return true;}return false;}virtual bool Send(std::string &in) override{int _size = ::send(_sock_fd, in.c_str(), in.size(), 0);if (_size > 0)return true;return false;}virtual void Close(){if (_sock_fd < 0)return;::close(_sock_fd);}virtual ~TcpSocket() override{}virtual int Fd() override { return _sock_fd; }private:int _sock_fd;};// class UdpSocket : public Socket// {// public:// virtual ~UdpSocket()// {// }// virtual int SocketOrDie() = 0;// virtual bool BindOrDie() = 0;// virtual bool ListenOrDie() = 0;// virtual int Accept() = 0;// virtual void Close();// private:// };}在瀏覽器(客戶端)中直接訪問當前我的服務器,發現在嘗試連接四次之后卡住了。可能是連接超時等問題。畢竟現在的服務器沒有返回任何的資源
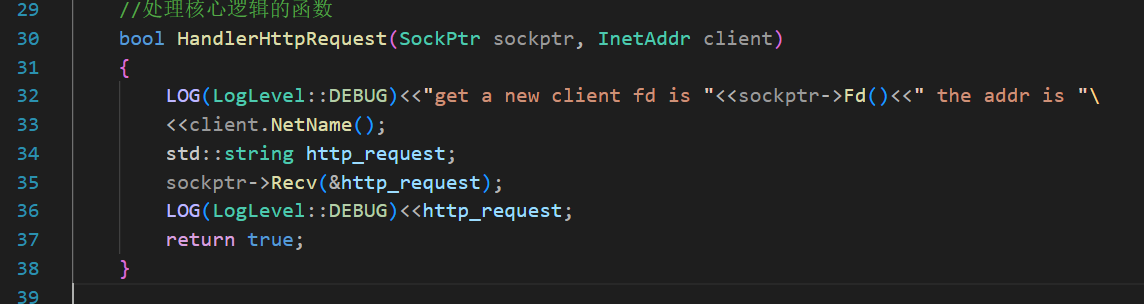
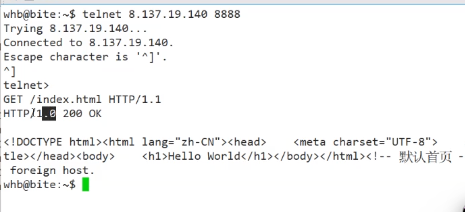
如果我們打印一下收到的http request:
?再仔細看看第一排的請求行
其實真正的http請求只有第一排
其他的都是請求報頭,都是k-v形式的
很有趣的發現,在打印完第一次之后,空格空了兩行,其中的一個空格是LOG自帶的,說明整個http請求還自帶一個空格,第一排都是GET+空的URL+版本號? 滿足最開始的宏觀理解。
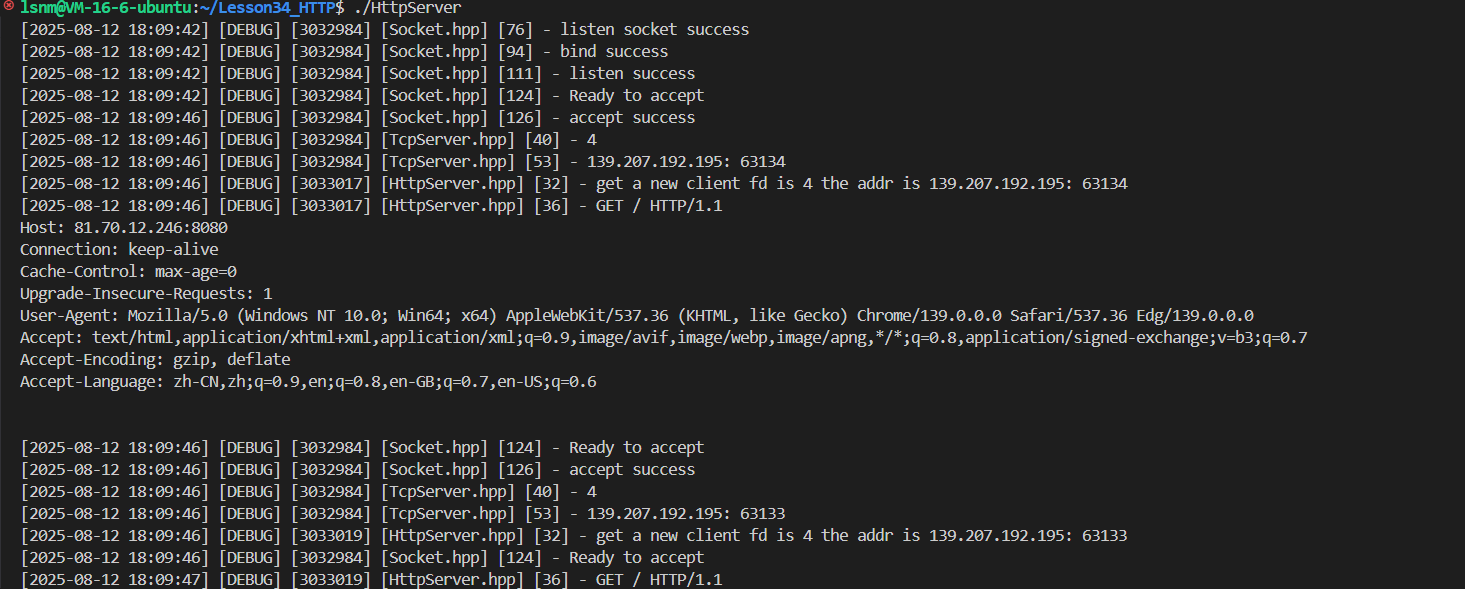

連接成功!
DEMO 1.0
嘗試手寫一個返回的消息,被send到對應的fd中去。
再次觀察Response的結構:
????????????????
在HTTP(HyperText Transfer Protocol,超文本傳輸協議)中,
status-line(狀態行)是HTTP響應消息中的第一個行,它提供了關于服務器響應的基本信息。狀態行由三個部分組成,分別是:
HTTP版本:指示服務器使用的HTTP協議的版本,例如
HTTP/1.1。狀態碼(Status Code):一個三位數的代碼,用來說明請求的處理結果。狀態碼分為五類:
1xx:指示信息——請求已接收,繼續處理。
2xx:成功——請求已成功被服務器接收、理解,并接受。
3xx:重定向——需要后續操作才能完成請求。
4xx:客戶端錯誤——請求包含語法錯誤或無法完成請求。
5xx:服務器錯誤——服務器在處理請求的過程中發生了錯誤。原因短語(Reason Phrase):一個簡短的文本描述,用來提供狀態碼的額外信息。例如,對于狀態碼
404,原因短語通常是Not Found。一個典型的狀態行示例如下:
HTTP/1.1 200 OK這表示服務器使用的是HTTP/1.1版本,狀態碼是
200,表示請求成功,而OK是對應的原因短語,進一步說明請求已經成功處理。狀態行是HTTP響應消息的開始,它后面跟著響應頭部(headers)和可選的響應主體(body)。狀態行為客戶端提供了關于請求結果的快速概覽,使得客戶端能夠根據狀態碼和原因短語來決定如何進一步處理響應。
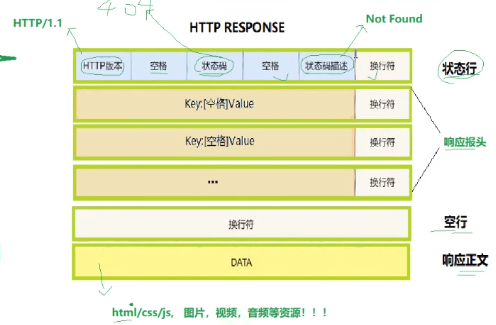
說白了,現在就是假裝返回一個假的、已經被反序列化的"Response",現在只要status_line以及Body兩部分組成即可,暫時不用對應的響應報頭。
????????
首先寫第一排的內容,string status_line HTTP/1.1 200 OK
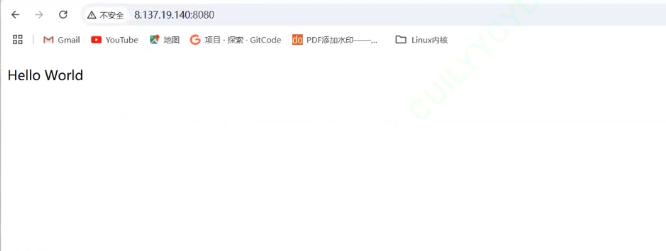
//demo 1.0 硬編碼來返回//sep是狀態行的\r\n,Backline是空行,本質也是一個\r\nstd::string status_line = "HTTP/1.1 200 OK" + Sep + Backline;? ? ? ? 再讓AI生成一個html的body,作為Body
//demo 1.0 硬編碼來返回//sep是狀態行的\r\n,Backline是空行,本質也是一個\r\nstd::string status_line = "HTTP/1.1 200 OK" + Sep + Backline;std::string body = "<!DOCTYPE html>\<html>\<head>\<meta charset = \"UTF-8\">\<title> Hello World</title>\</head>\<body>\<p> LOVE YOU Ronin007 回家吃飯飯</ p>\</body> </html>";std::string http_response = status_line+body;sockptr->Send(http_response);//可以用這個弱智的硬編碼去逗一逗女朋友的傻笑,如果你有女朋友的話
出來的效果類似于:
DEMO 2.0
????????????????--------------------------------------加入HttpProtocol部分
現在就可以考慮讀取請求,對請求進行分析處理了!
如何對http請求進行序列化和反序列化呢(對http進行協議化)?
要確定兩個事情:
1.讀取請求的完整性?
2. 完整http反序列化,http response序列化
現在,對http進行協議化。
直接利用兩張圖來完成
?

因為兩個報頭中都可能包含多個string,所以選擇用vector來記錄
觀察這個Http請求,思考如何取出各個數據:
GET /favicon.ico HTTP/1.1 Host: 81.70.12.246:8080 Connection: keep-alive User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0 Accept: image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8 Referer: http://81.70.12.246:8080/ Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6首先,提取出request的整個請求行(就是提取一個子串),提取了子串之后還要想辦法獲得幾個子結構。
?第二排表示請求發到誰去了,發到哪一個主機的哪一個端口。
第三排 長連接(暫時不理會),
第五排 User-Agent(下一個塊中分享)
Accept:表示能接受以下的內容,也就是正文到底是accept后的哪一種類型。
剛剛提到的UserAgent:
?
User-Agent 是一個 HTTP 請求頭部字段,它用于識別請求發起者的信息,比如瀏覽器類型、操作系統、瀏覽器版本以及它所運行的設備或軟件。這個字段通常由客戶端(如 Web 瀏覽器)自動設置,并且可以在服務器端的 HTTP 響應中看到。
User-Agent 頭部的主要目的是幫助服務器確定請求的設備和軟件環境,以便它可以返回最適合該環境的內容或進行特定的優化。例如,一個移動設備的瀏覽器可能會在 User-Agent 字符串中包含設備型號和瀏覽器版本信息,這樣服務器就可以根據這些信息提供適合移動設備顯示的頁面布局和資源。
比如,以上兩張圖就能看出發出請求方的操作系統,一個是win,一個是基于Linux的安卓。


? ? ? ? 因為request或者response都需要提取出第一排的內容,所以這個ParseFirstLine應該寫到Common.hpp中去
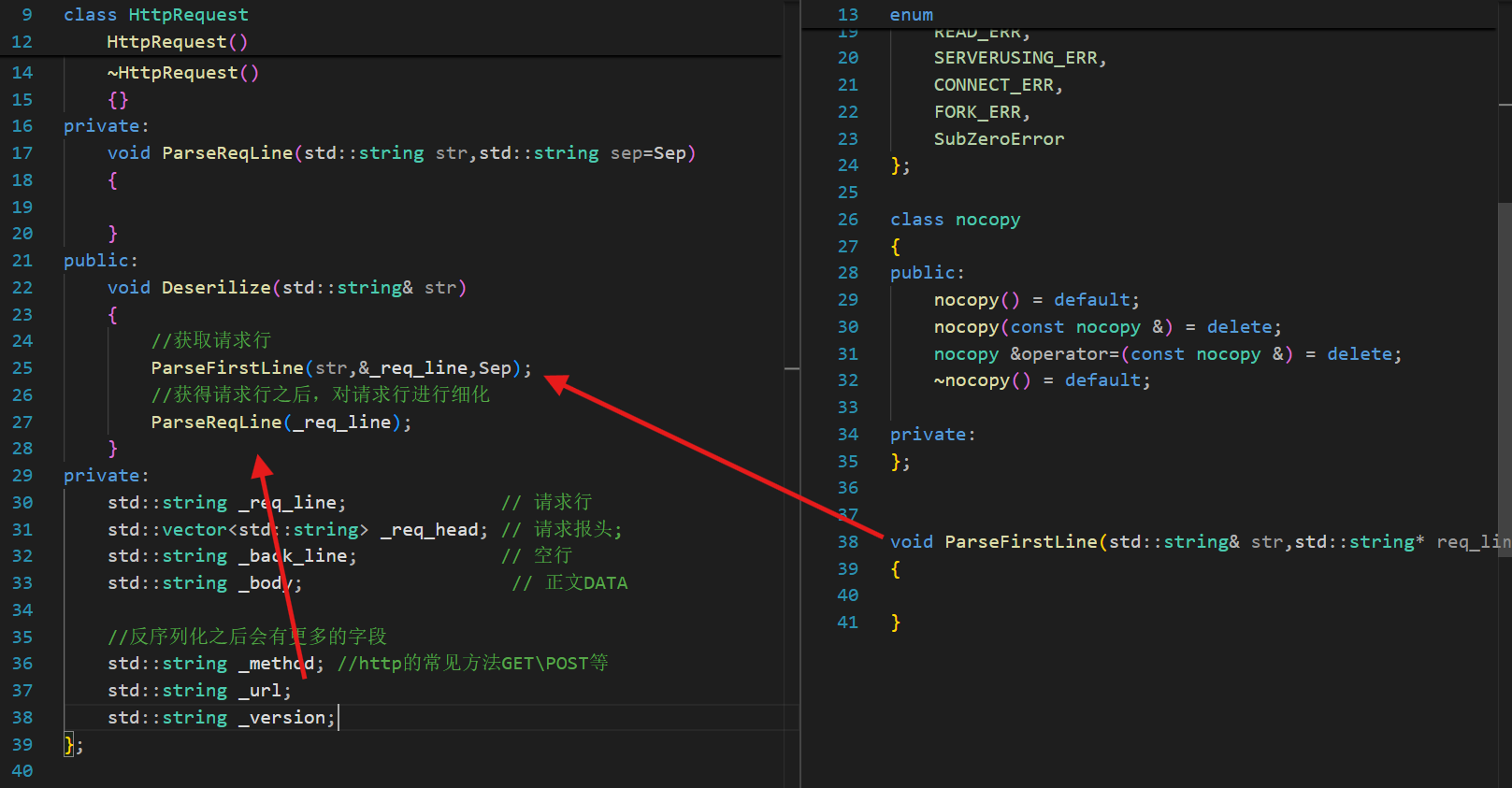
直接實現即可:
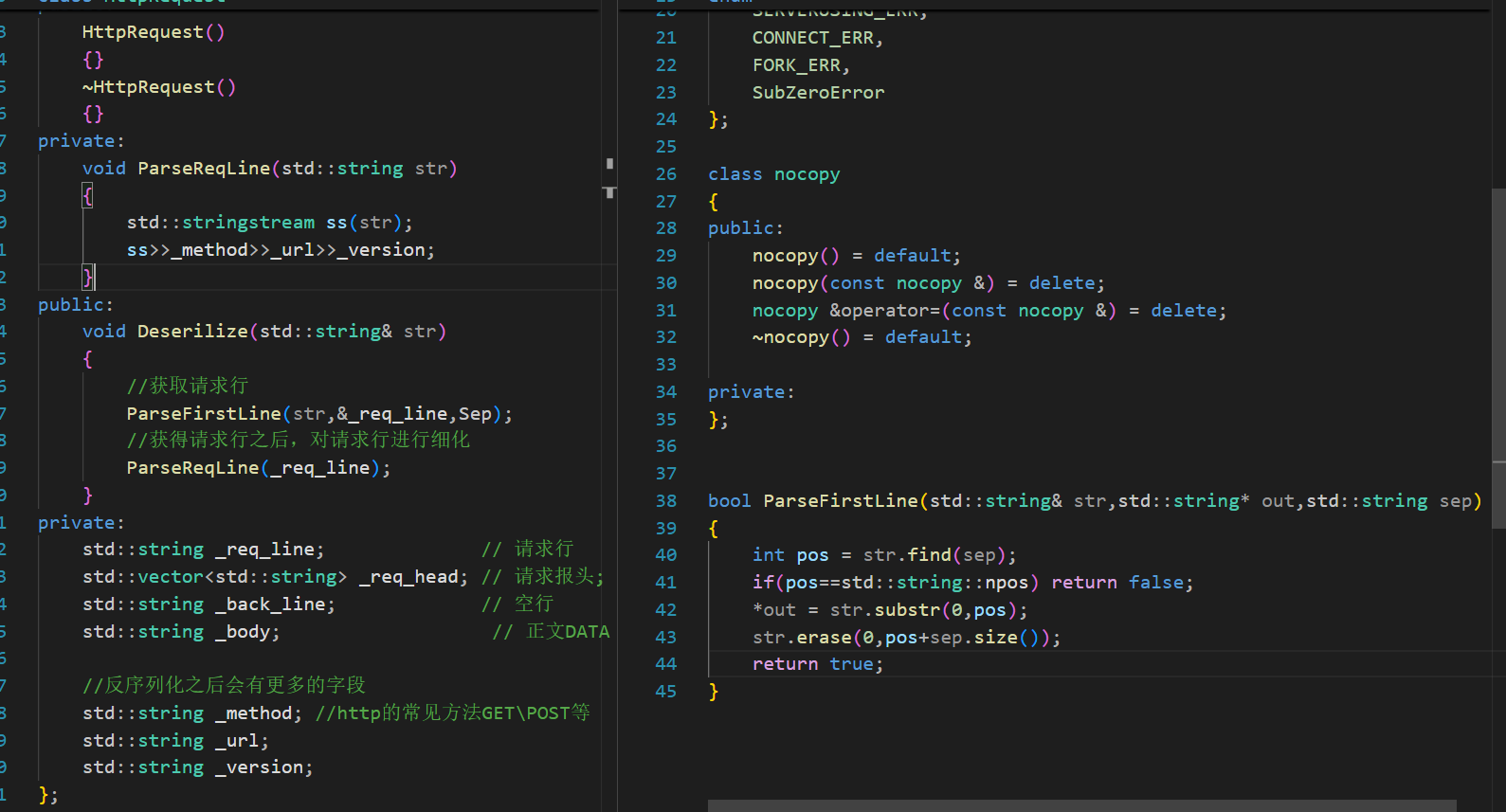
在HttpServer中調用這個內容
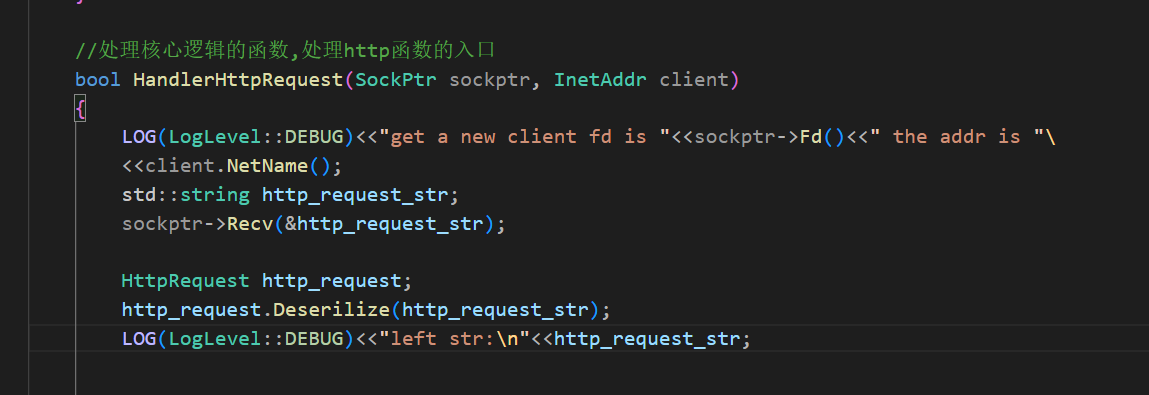
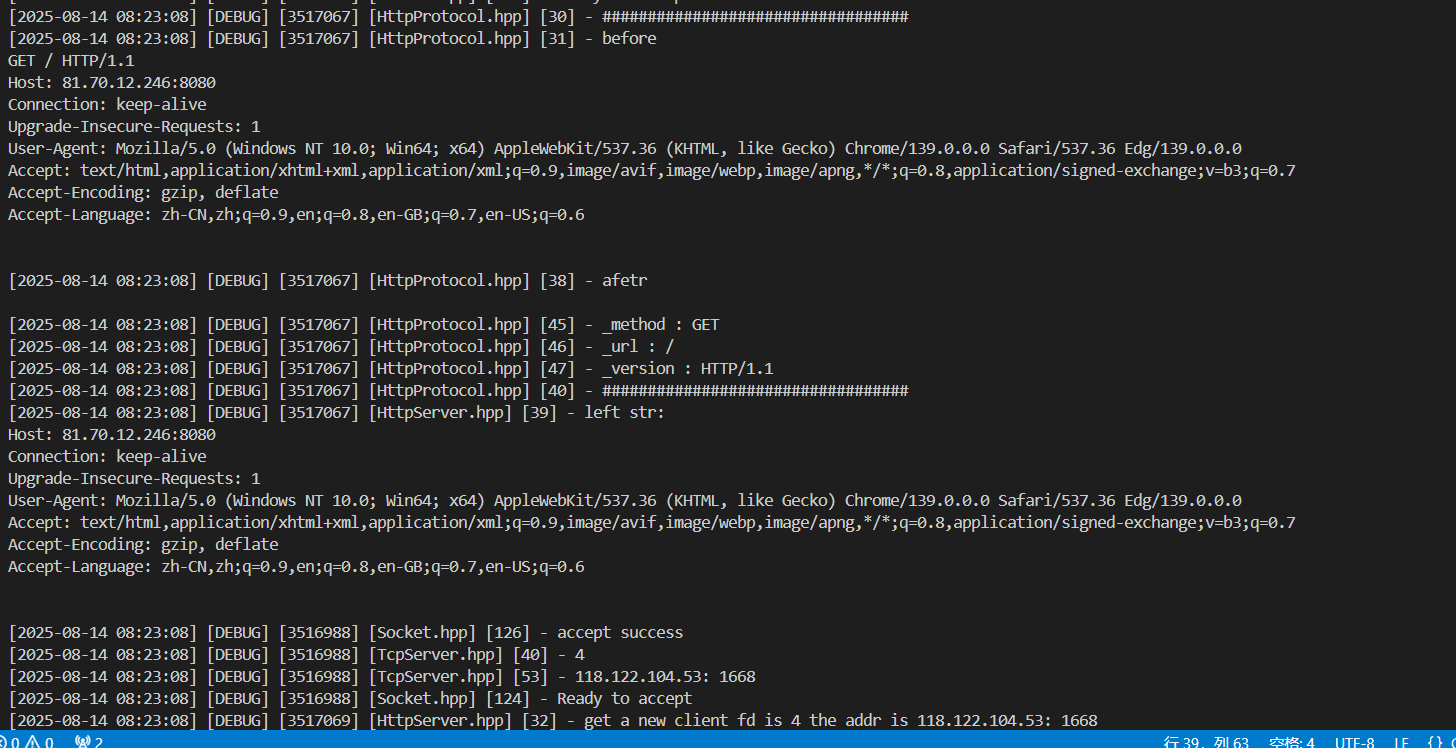
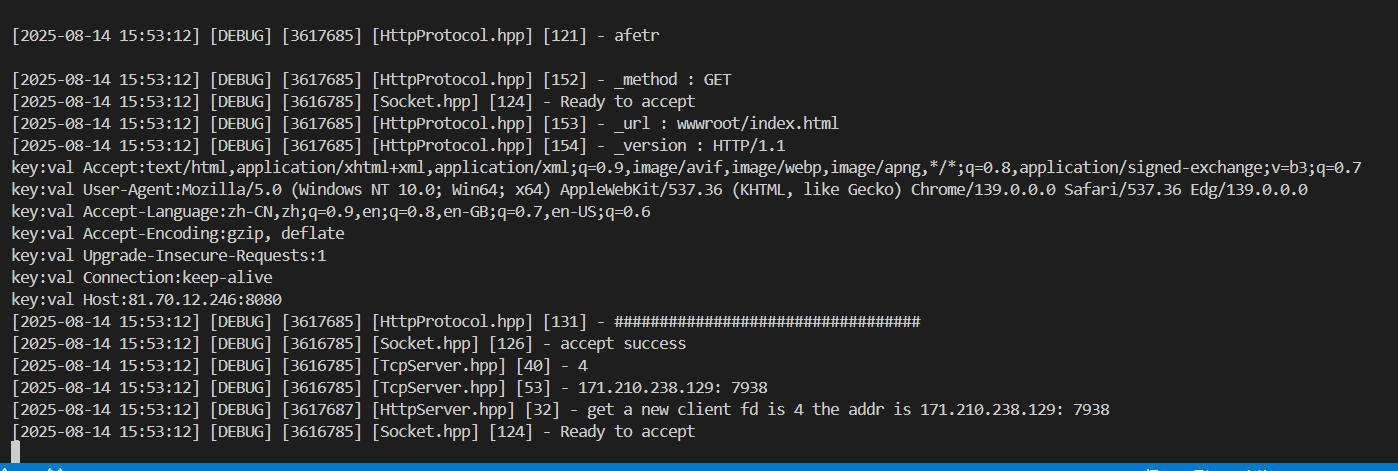
做好相應的debug,發現我們已經成功分離request的請求行
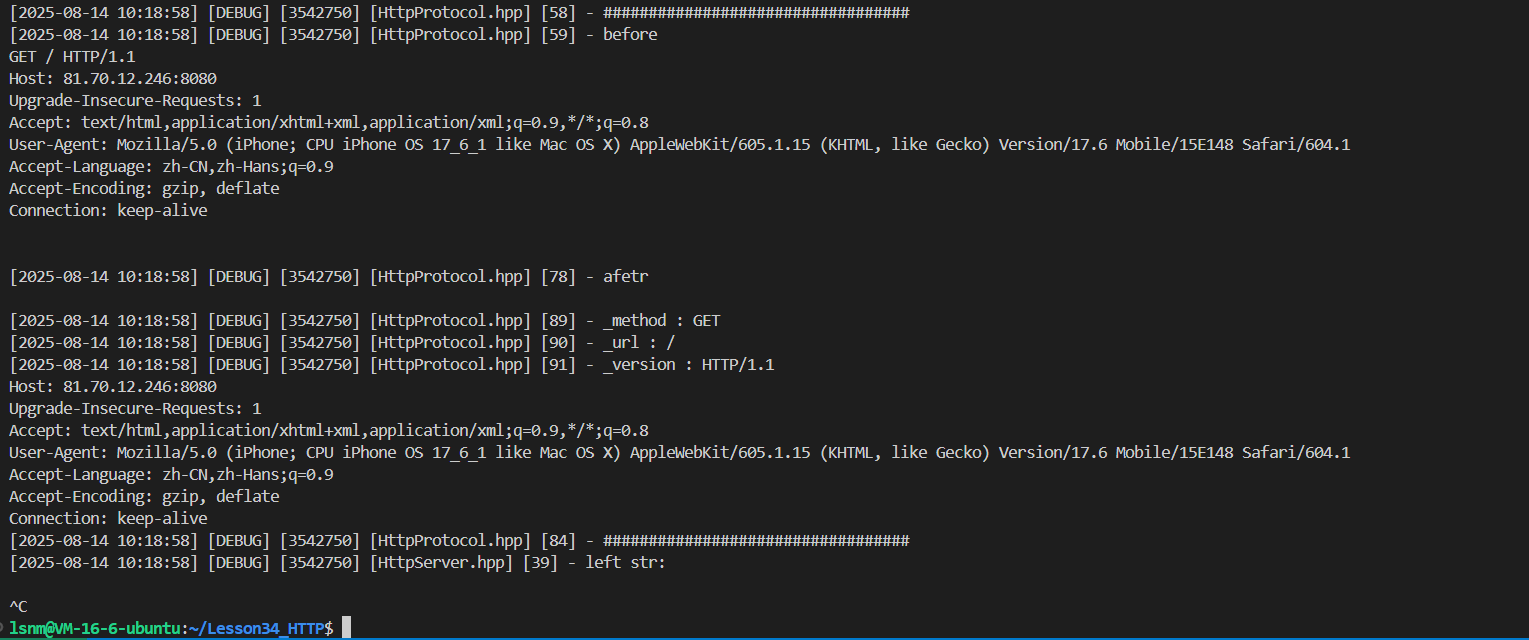
void Deserilize(std::string &str){LOG(LogLevel::DEBUG)<<"##################################";LOG(LogLevel::DEBUG)<<"before\n"<<str;// 獲取請求行if (ParseFirstLine(str, &_req_line, Sep)){// 獲得請求行之后,對請求行進行細化ParseReqLine(_req_line);}LOG(LogLevel::DEBUG)<<"afetr\n";Print();LOG(LogLevel::DEBUG)<<"##################################";}
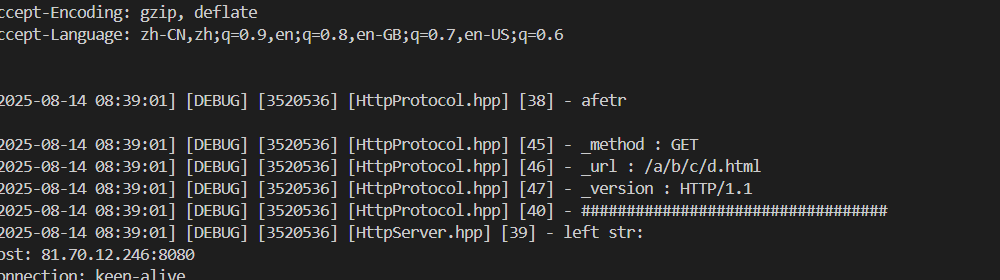
可以看到,請求的url是/
如果換個位置做訪問測試:
請求到的url就是/a/b/c/d.html

tips:簡單介紹一下wwwroot以及index.html
wwwroot是一個常見的術語,通常用于描述網站的根目錄(root directory)。
根目錄:
wwwroot是一個文件夾,通常用于存放網站的所有文件和資源。它是網站的“家目錄”,所有網頁、圖片、腳本、樣式表等文件都存儲在這個目錄下。Web服務器的默認目錄:在許多Web服務器(如Apache、Nginx、IIS等)中,
wwwroot是默認的網站根目錄。當用戶通過瀏覽器訪問網站時,服務器會從這個目錄中查找并提供相應的文件。示例
假設你的網站地址是
https://example.com,那么:
https://example.com默認會訪問wwwroot目錄下的默認文件(通常是index.html)。如果用戶訪問
https://example.com/about.html,服務器會從wwwroot目錄中查找about.html文件。文件結構
一個典型的
wwwroot目錄結構可能如下:wwwroot/ ├── index.html ├── about.html ├── contact.html ├── images/ │ ├── logo.png │ └── background.jpg ├── css/ │ └── styles.css └── js/└── script.js
index.html是一個HTML文件,通常被用作網站的默認首頁.css是一種描述HTML的文件,讓頁面更好看
現在分離? 請求報頭:簡單的字符串處理任務
void ParseHeader(std::string &str){/*調用ParseFirstLine去解決問題,可能有三種情況:out正常;return false&&out為空;return true&&out空串分別對應:正常給出來、已經找完了、找到了空行*/while (true){std::string headler_line;bool flage = ParseFirstLine(str, &headler_line, ::Sep);if (flage && !headler_line.empty()){_req_head.push_back(headler_line);}else if(!flage && headler_line.empty()){break;}else if(flage && headler_line.empty()){continue;}}}現在發下left str之后已經沒有內容了(因為現在body為空)
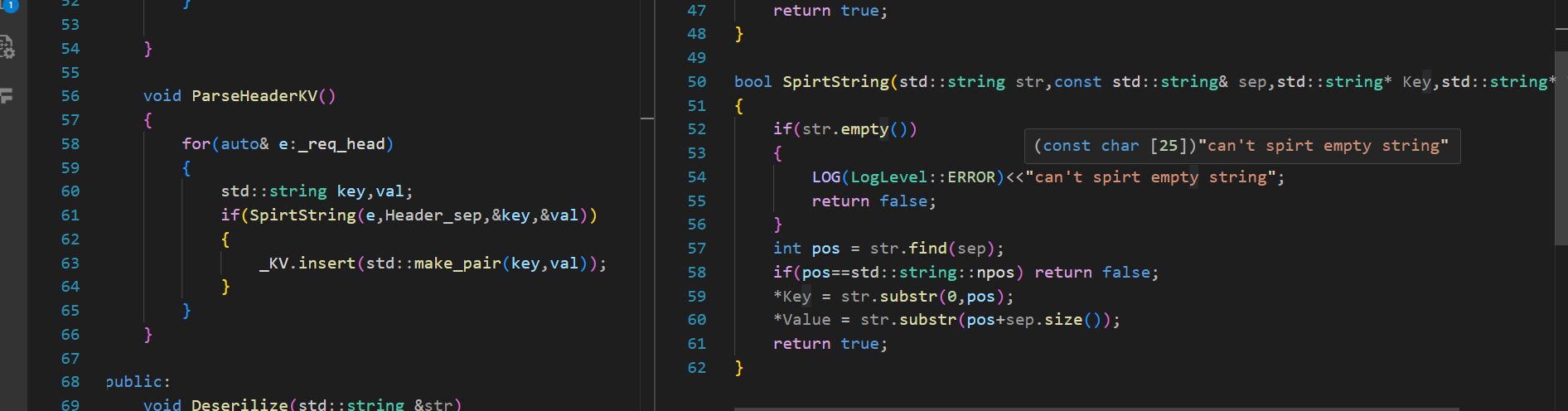
現在的整個報頭還是字符串,想把它的KV屬性都拆出來:
DEMO 3.0
? ? ? ? ? ? ? ?-------------------------------------使用html在wwwroot中完成code=404和code=200的情況描述
家目錄wwwroot
剛才提到,如果想有一個http服務,必須要構造一個http的家目錄,文件名,比如:wwwroot
后端服務如果想被訪問,決定了站點必須要有一個“默認首頁”
????????
?web根目錄名字都是被隱藏了的。
www.baidu.com和www.baidu.com/index.html是一個東西,可以在當前環境中使用mkdir指令和touch指令創建這兩個文件。
??????????????????????????????????????
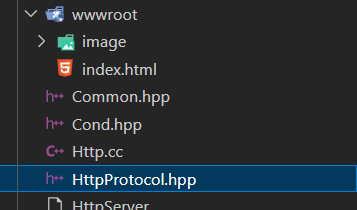
用戶真正想訪問的是被放到http請求的uri部分。
? ?tips:
? ? ?URL(Uniform Resource Locator,統一資源定位符)和 URI(Uniform Resource Identifier,統一資源標識符)都是用于標識資源的字符串,但它們的含義和用途有所不同。
URI可以進一步被分成URL或者URN。URI不一定標識清楚了資源具體在哪里。
所以,URI就是去獲得用戶想訪問的資源的地址,并且這個路徑都是建立在默認路徑之上的,作為服務器,我們需要加上這個路徑
瀏覽器的uri是默認忽略了這個根目錄,服務器需要自動加這個前置路徑,才能找到用戶希望找到的資源。
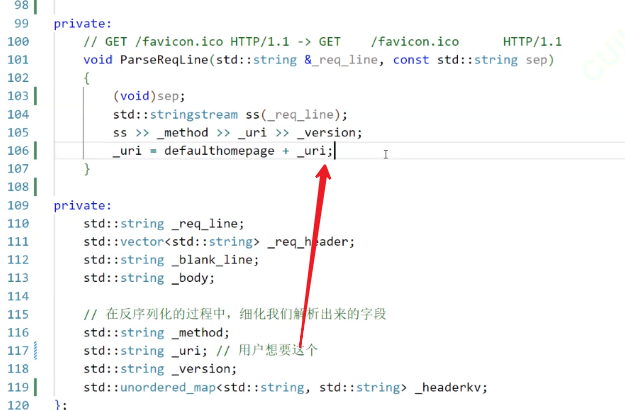
????????uri知道了用戶想用什么,需要一個HttpResponse,把這個文件塞進去。但是uri是在Request的字段內,所以在Request中,還需要一個GetContent方法,在request中去讀文件。
把客戶請求的文件拿出來:
??????????????????????????????????????
Public中再設計一個對應的調用方法即可。
class Response
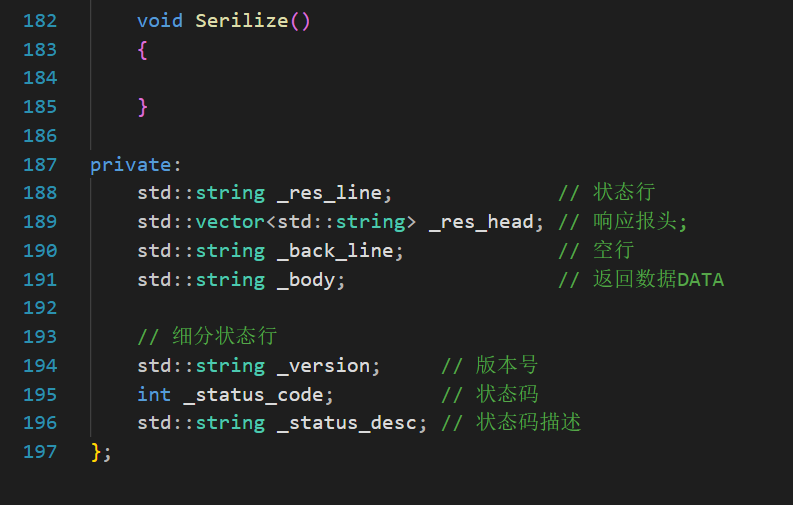
Build--------------Response不可缺少的一環
不同于Request是從瀏覽器處拿到然后手動反序列化出來,Response的構建過程需要我們使用各種信息來Build。比如當前服務器的版本號,對于發起的請求的狀態碼、狀態描述等。
如何根據用戶想要的內容構建回復呢?這就是Build模塊
對于任何HTTP,任何請求,都必有應答。
如果請求的資源不存在該怎么辦?這就是狀態碼存在的意義,也是人們常說的404 Not Found
今天只了解404和200即可
關于為什么需要一個HTTP版本在報頭,筆者借助AI生成了一個小tips:
HTTP協議的版本信息在Request和Response報文中扮演著重要角色。具體來說:
- Request中的HTTP版本(如HTTP/1.1)表示:
- 客戶端(通常是瀏覽器)支持的HTTP協議版本
- 決定了客戶端會發送哪些請求頭字段
- 影響客戶端對持久連接、分塊傳輸等特性的支持 示例:HTTP/1.1請求會自動包含Host頭字段,而HTTP/1.0則不會
- Response中的HTTP版本(如HTTP/1.1)表示:
- 服務器實際使用的HTTP協議版本
- 決定了服務器會返回哪些響應頭字段
- 影響服務器對特性(如Keep-Alive)的支持程度 示例:HTTP/1.1服務器會默認保持連接,而HTTP/1.0服務器需要顯式設置Connection: keep-alive
版本差異的應用場景:
- 當客戶端發送HTTP/2.0請求但服務器只支持HTTP/1.1時,服務器會降級響應
- 不同版本支持的壓縮算法可能不同(如HTTP/2支持HPACK頭部壓縮)
- 緩存控制機制在不同版本間有差異(HTTP/1.1引入更多緩存控制指令)
在實際通信中,最終使用的HTTP版本是客戶端和服務器都支持的最高共同版本。
private:std::string Code2Desc(int status_code){std::string ret;switch (status_code){case 404:ret = "Not Found";break;case 200:ret = "OK";break;default:break;}return ret;}
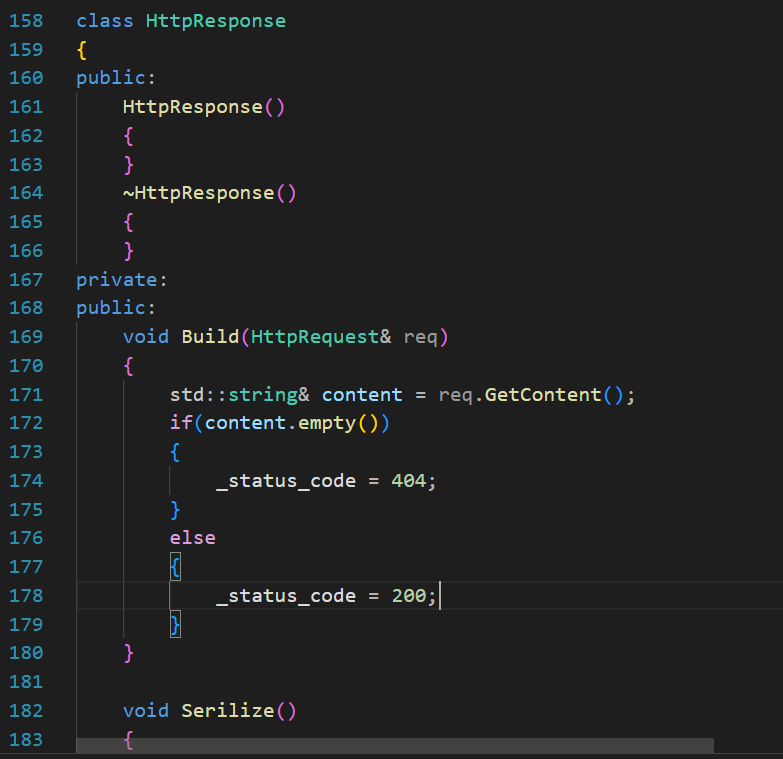
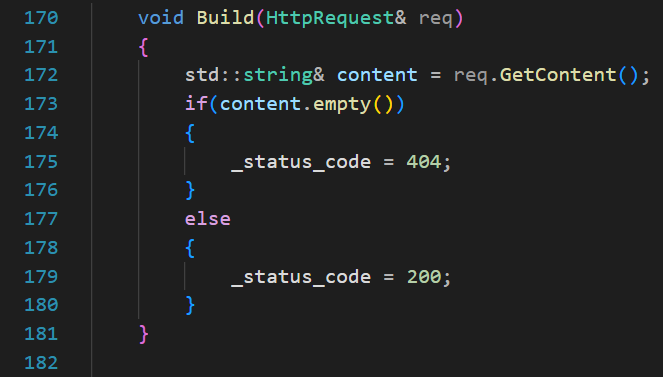
public:void Build(HttpRequest& req){std::string& content = req.GetContent();if(content.empty()){_status_code = 404;_status_desc = Code2Desc(_status_code);}else {_status_code = 200;_status_desc = Code2Desc(_status_code);}}如果用戶要訪問一個不存在的頁面,我們需要返回404對應的文件資源(此處可以讓AI生成一個前端的html文件),那么就需要去更改一下用戶想訪問的URI:
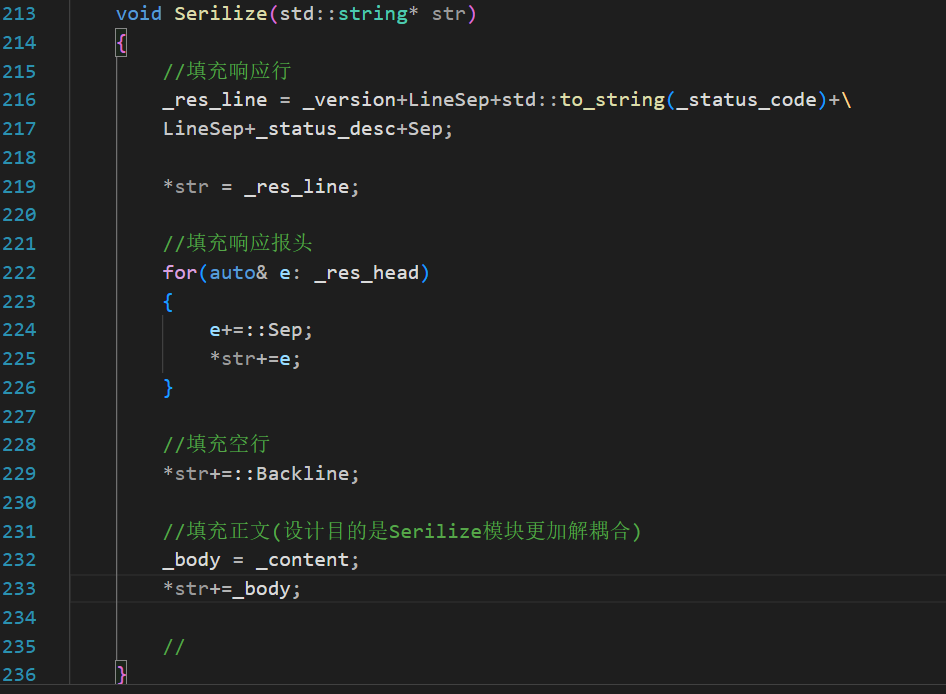
public:void Build(HttpRequest& req){std::string& content = req.GetContent();if(content.empty()){_status_code = 404;req.SetURI(Page404);content = req.GetContent();}else {_status_code = 200;}_status_desc = Code2Desc(_status_code);}然后是Serilize:把要返回的內容都進行序列化
Deserilize是把一個字符串給解析出來內容,是輸入型參數
? ? Serilize是一個輸出型參數,應該用指針。
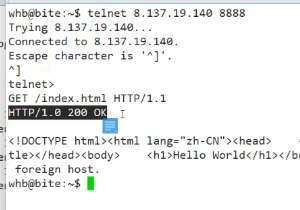
可以試著直接用指令連接:
?????????????????????????????????????????????????????
一個空行,然后就是網頁的內容
???????????????????????
還可以試試從瀏覽器去訪問,瀏覽器拿到這些標簽性質的文件之后還會解析,生成一個小小的前端頁面。
index.html作為默認訪問是需要特殊處理的
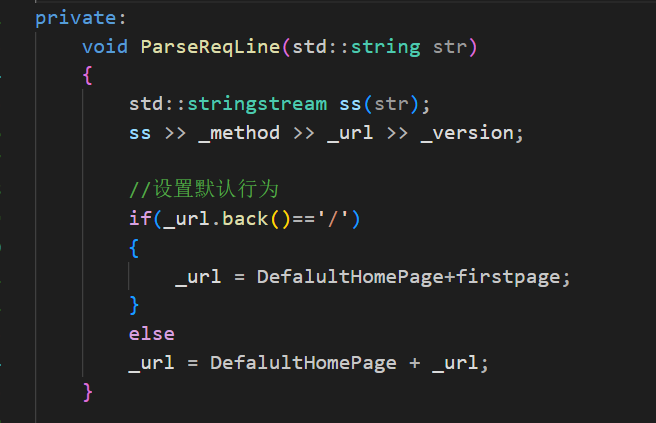
不過,直接訪問的/也應該把根目錄放出來,可以特殊處理一下:
現在直接輸入ip+port:比如81.70.12.246:8080
快拿去逗逗你的寵物。
前端代碼直接讓AI生成即可。
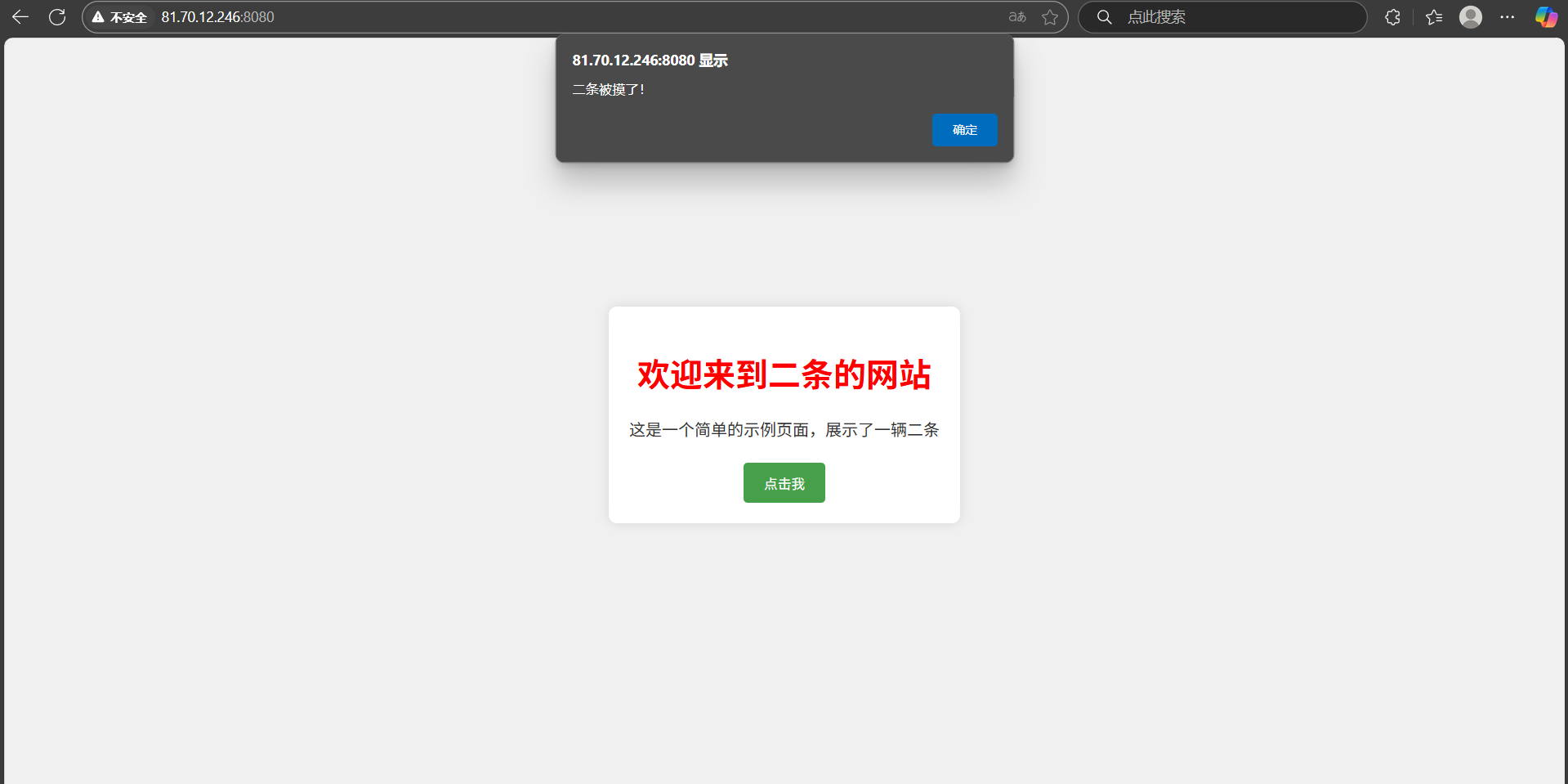
如果訪問一個不存在的網址(比如/a/b/c/d.html):
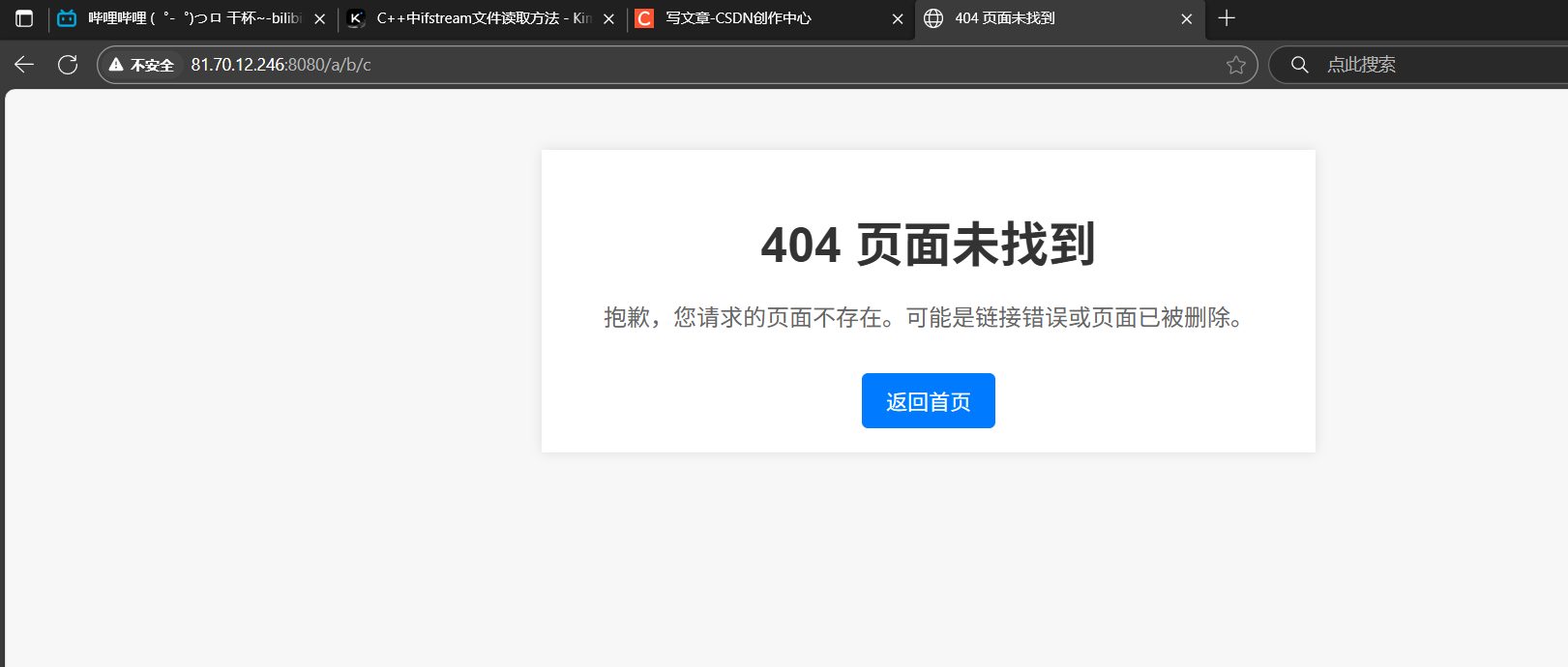
DEMO 4.0
? ? ? ? ? ? ? ? ? ? ? ? ?---------------------------------------------結合前端,加入圖片
前端開發其實就是寫wwwroot里的內容,wwwroot外面的內容才是后端完成的。
讀者朋友看了這么久,學個入門前端來放松下:
HTML 簡介 | 菜鳥教程
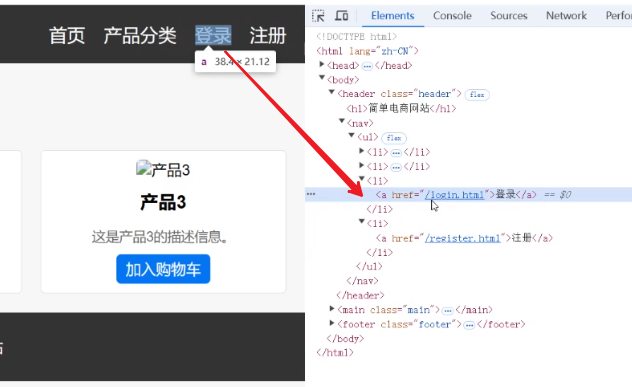
借助教程來看一個簡單的HTML標簽——a標簽。換句話說,就是前端中各種鏈接的點擊
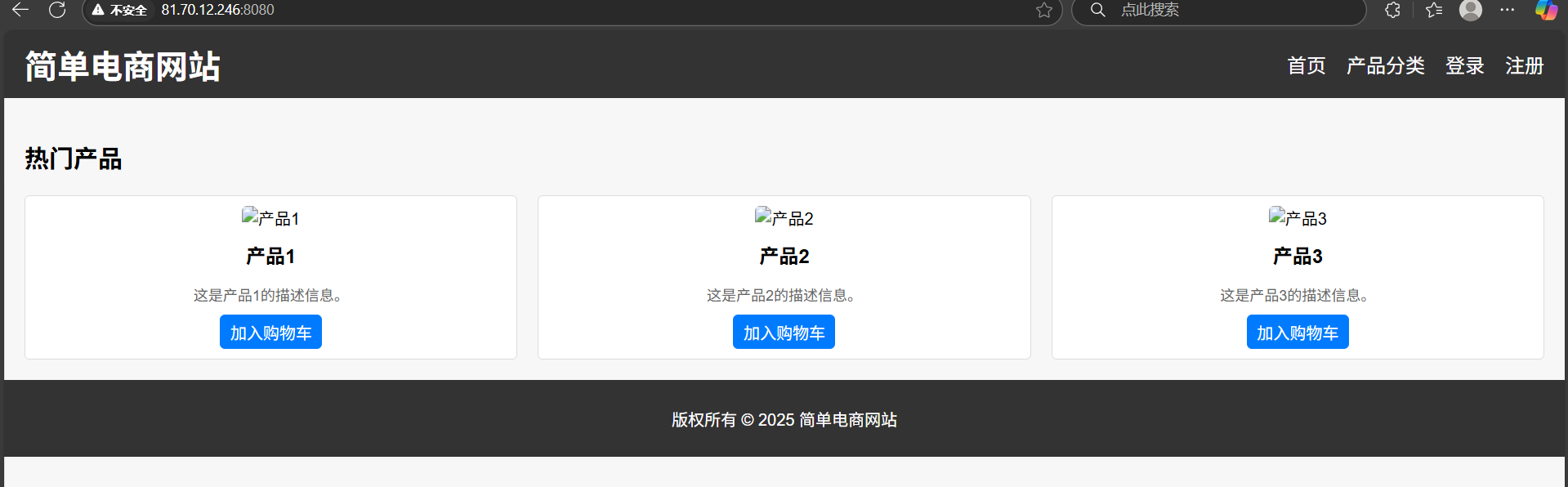
讓AI生成一個簡單的電商前端html代碼(所有的代碼都在文末的git鏈接上)
a標簽表示這個鏈接會發起的html請求,只要把各個界面的a標簽都設置到希望跳轉到的a標簽即可。
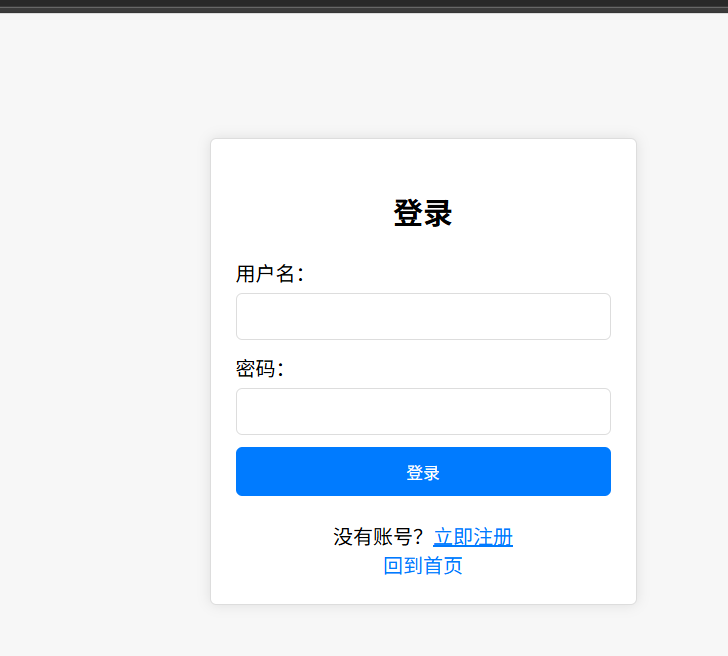
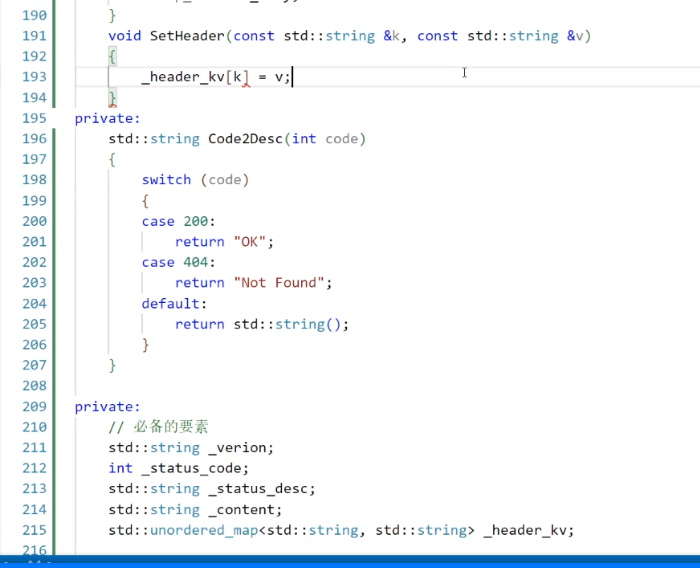
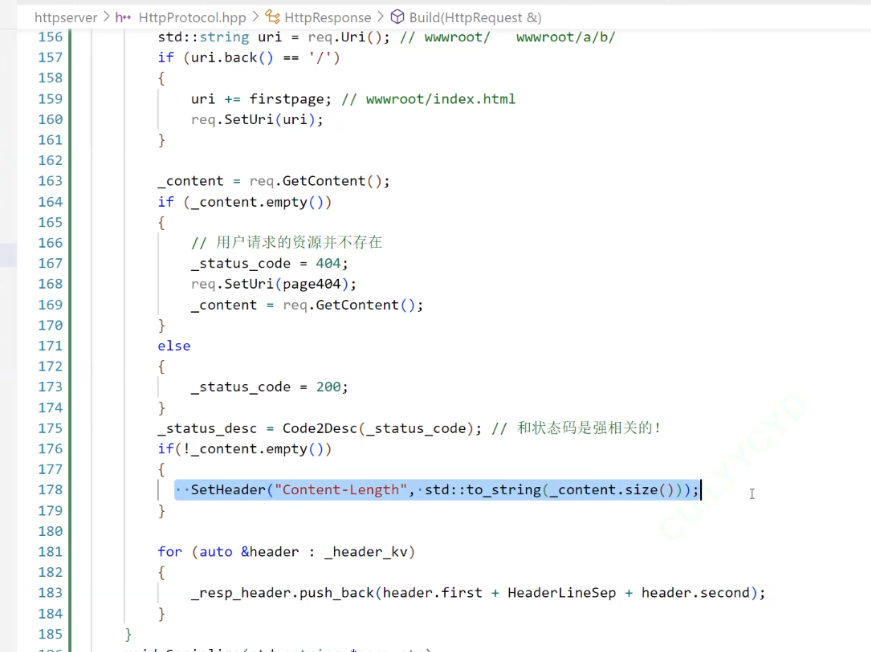
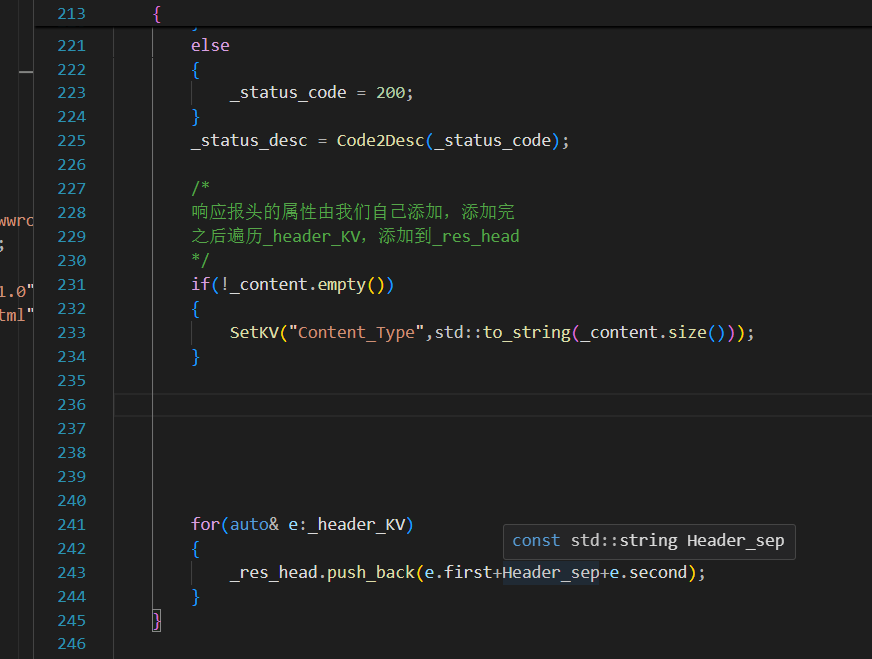
終于想起來還沒有設置Response的header,依然是用一個unorderedmap去實現,今天只加兩個值,一個是content_type,一個是content_length
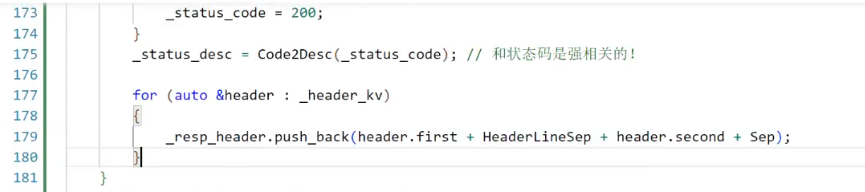
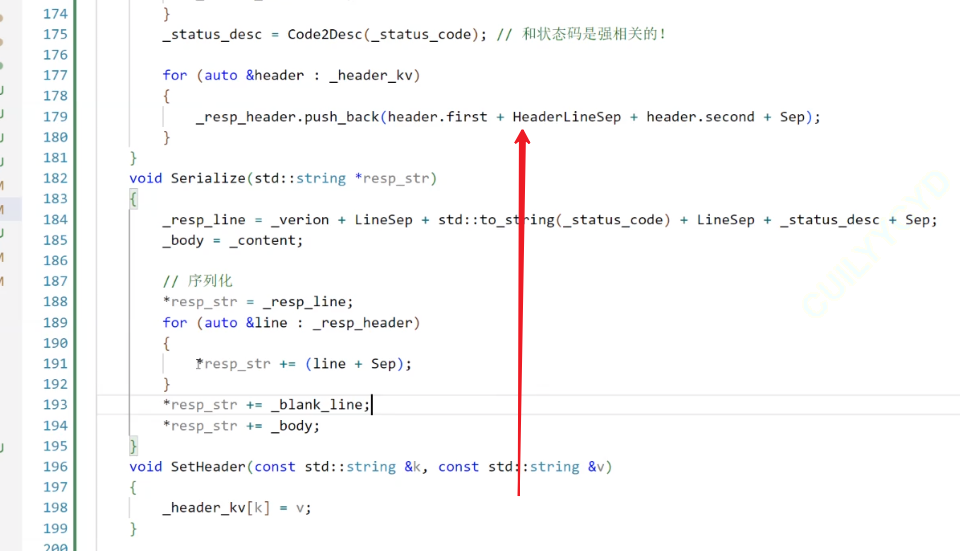
176排,設置header內容;181排,將unordered_map中的內容全部加在HttpResponse里去
只不過目前為止,我們只加了一個屬性,就是Content_Length
????????
再了解一個屬性,content_type
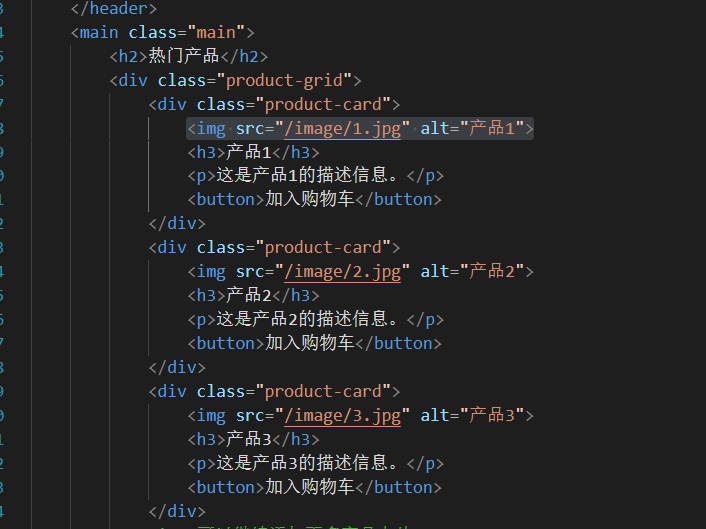
????????HTTP作為超文本傳輸協議,不僅可以傳輸文本,還能傳輸圖片、視頻等“超文本”,比如上述的html里,只要標明圖片名稱,并且在wwwroot的image文件夾下是真的有這些圖片,就能完成任務了。
???????????????????????

對照剛剛的圖片為什么沒顯示出來,是因為圖片內容傳輸失敗了。
簡單說明是如何去獲得圖片的:
?
瀏覽器會去自動進行一個請求圖片的任務。
瀏覽器對發過去的html進行解析,發現還需要去找三張圖片,于是回到對應的image文件夾下去找。
但是,原來的SetContent方法是用ifstream直接去讀,這是不正確的。因為圖片是以二進制形式傳輸,二進制中可能遇到很多的/0等,直接讀到一半的時候就失敗了,所以需要一個標準的GET方法來重新傳資源。


GET方法
int SetContent(){std::ifstream in(_url,std::ios::binary);if(!in.is_open()) return OPEN_ERR;in.seekg(0,in.end);int filesize = in.tellg();in.seekg(0,in.beg);_content.resize(filesize);in.read((char*)_content.c_str(),filesize);in.close();return 0;// std::ifstream file(_url);// if (!file.is_open())// {// LOG(LogLevel::ERROR) << "OPEN FAIL";// return OPEN_ERR;// }// std::string line;// while (std::getline(file, line))// {// _content += line;// }// file.close();return 0;}下面是我們之前的SetContent的方法,現在是新版本的,通過控制文件大小和文件偏移量解決問題,一次性把整個文件都讀進去。
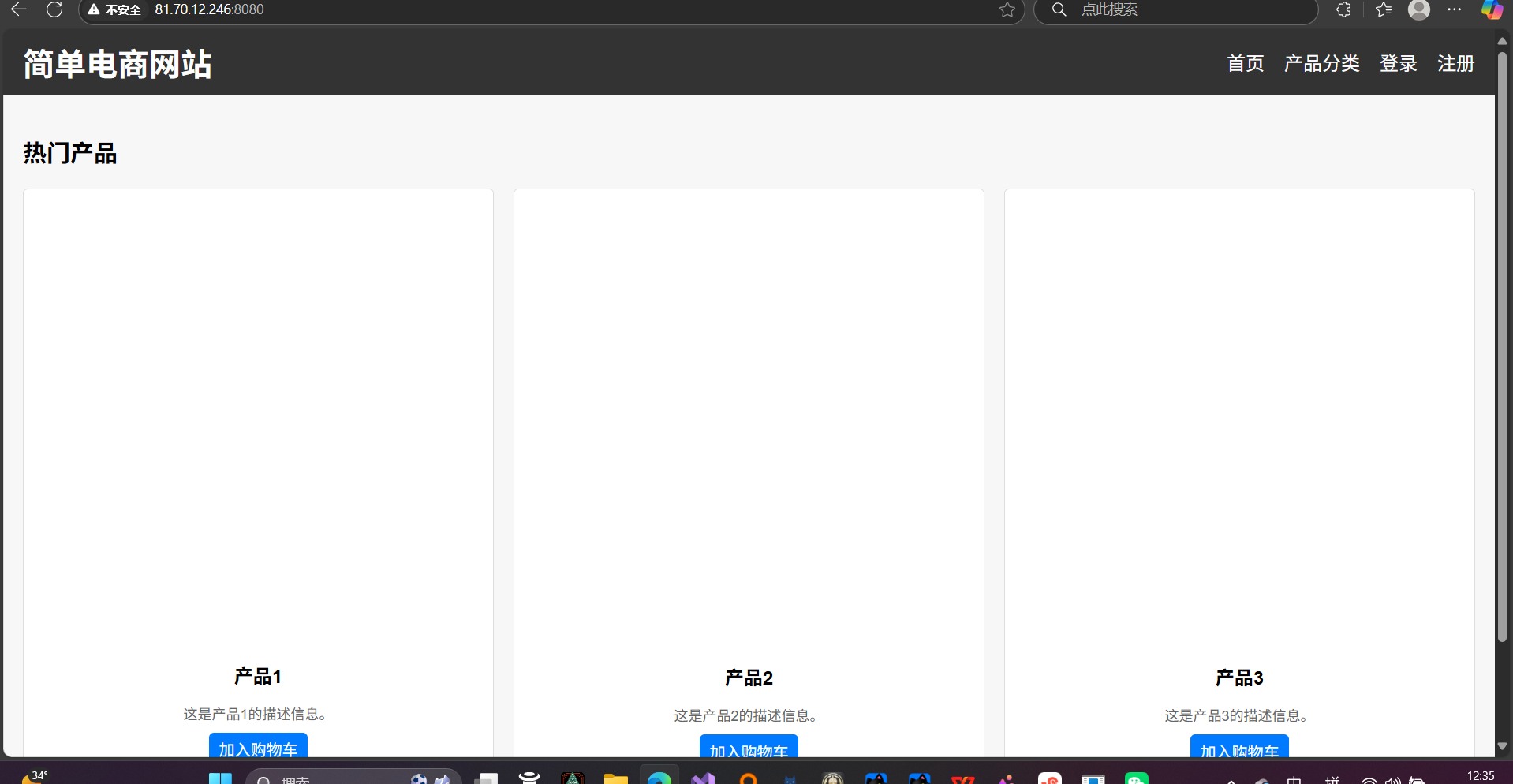
這下就能看到了所有的圖片了:
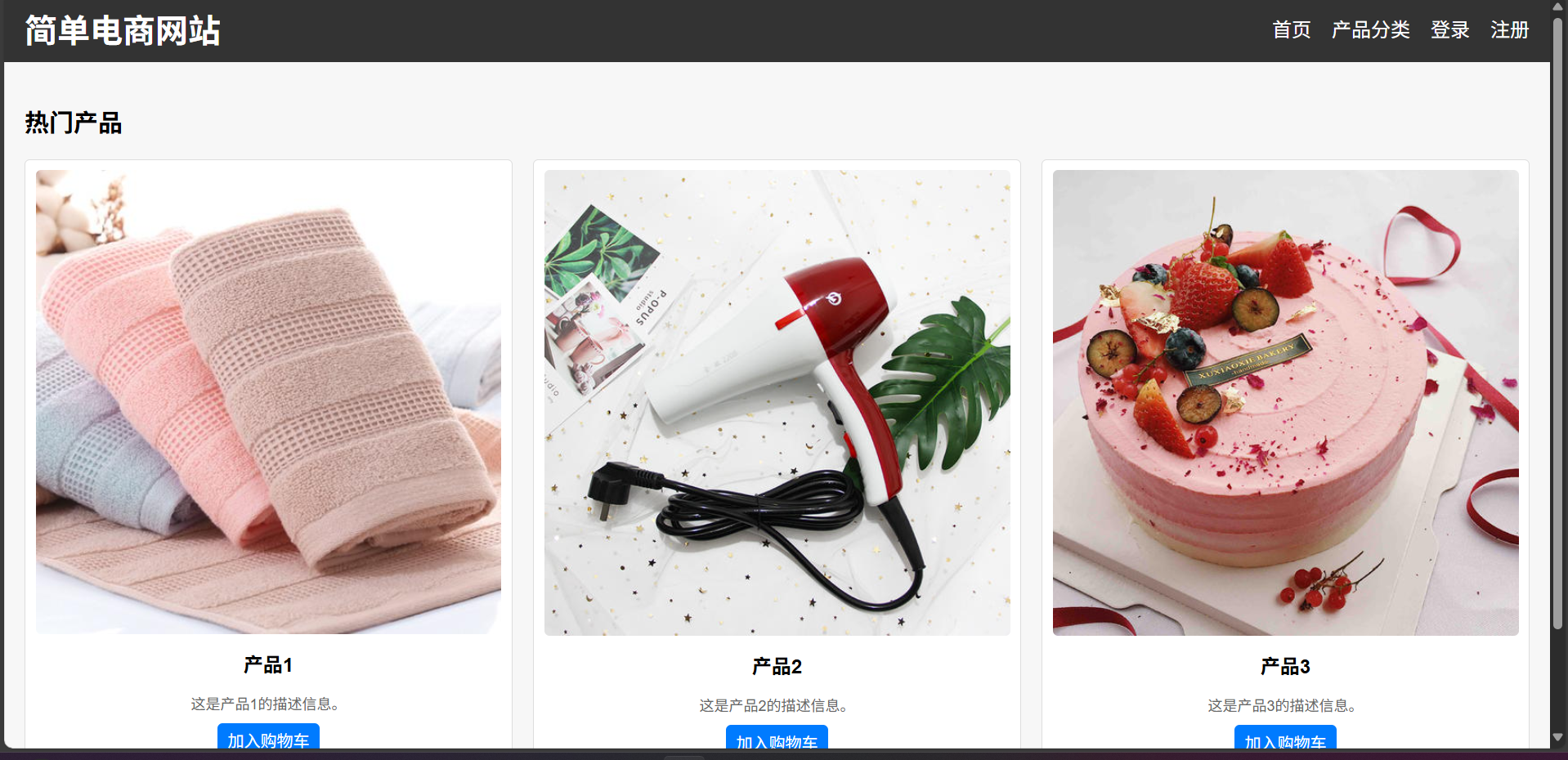
理解瀏覽器的強大
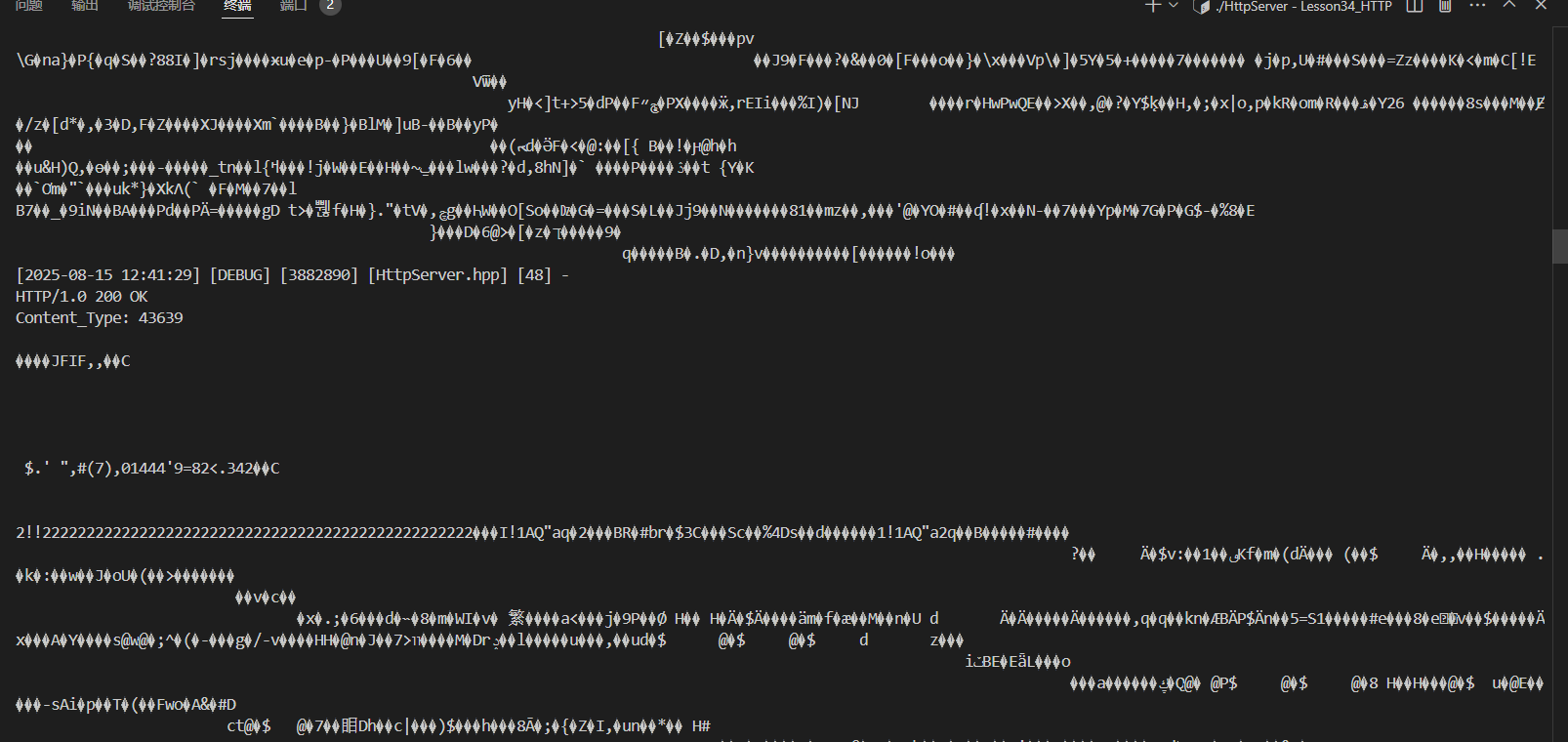
如果打印出我們的HttpResponse
會發現全是亂碼,但是瀏覽器能正確識別這些內容,形成我們的網頁。
content_type:
content_type是響應報頭的另一個字段,用于告訴瀏覽器數據的類型。瀏覽器需要知道一個文件的類型,是根據分析后綴來的,會將分析得到的后悔寫成一個MIME類型的樣子供瀏覽器識別。
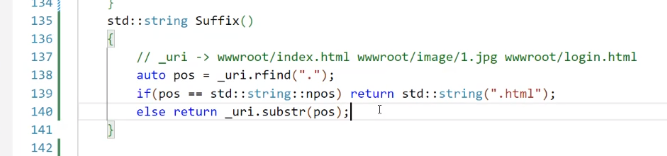
后綴會轉換成對應的字段,賦值到content_type里去
找后綴(suffix):
把對應的content-type信息加到映射表以及vector中去。

????????文章內容太多,分兩次發,下一篇會重新介紹如何GET POST ,客戶端如何call整個調用過程等內容..............












![[系統架構設計師]系統架構基礎知識(一)](http://pic.xiahunao.cn/[系統架構設計師]系統架構基礎知識(一))


)



