一、AI模型評測目標
傳統質量主要關注功能、性能、安全、兼容性等。
AI模型評測在此基礎上,引入了全新的、更復雜的評估維度:
1.性能/準確性:這是基礎,在一系列復雜的評測基準上評價個性能指標。
2.安全性:模型是否可能被用于惡意目的?是否會生成有害、違法或有毒的內容?是否容易受到數據投毒等攻擊?
3.幻覺:對于大語言模型等生成式模型,它是否會"一本正經地胡說八道",捏造事實?
4.魯棒性:模型在面對非理想輸入時的表現。例如,輸入有噪聲聲、有拼寫錯誤、甚至是經過精心設計的對抗性攻擊
時,模型的性能是否會急劇下降?
5.公平性與偏見:模型是否對不同群體(如性別、種族、地域)表現出一致的性能?是否存在歧視性行為?這是傳
統質量很少觸及的倫理維度。
6.可解釋性:我們能理解模型為什么做出某個特定的決策嗎?這對于金融、醫療等高風險領域至關重要。
二、評測的數據驅動
AI模型評測的核心是評估數據集。
1.評測基準:包含大量高質量、有代表性的標注數據,作為衡量模型性能的"標尺"。
2.人類參與的評估:對于創造性、主觀性很強的任務(如文案生主成、對話質量),機器指標是不夠的,由人類來打
分和判斷。
3.對抗性測試:不再是測試常規場景,而是主動尋找模型的"盲區"和弱點,通過生成對抗樣本來攻擊模型。
三、評測周期
- 數據準備階段:確保輸入給模型的數據是高質量、多樣化、無無偏見且安全的。數據質量評測、數據分布評測、數據安全評測,從源頭上保證模型的質量。
- 預訓練階段:監控訓練進程,驗證模型是否在正確學習,并選擇最佳的模型版本。檢查點(Checkpoint)評測、超參數調優評測,也叫做邊訓邊評,評測結果可以幫助工程師判斷當前訓練策略是否有效。
- 后訓練階段:讓模型學會人類的偏好,變得更"有用、誠實、無言害"。獎勵模型的構建與評測、對齊效果評測,這個階段,評測本身就是訓練的核心驅動力。
- 部署后:監控模型在真實世界中的表現,發現未知問題,并為下一代模型提供改進方向。
四、AI模型評測的關鍵技術
Benchmark
- Benchmark?是用于量化評估AI模型/系統性能的標準測試集與評價體系,其核心價值在于:
??橫向對比:不同模型在同一標準下的能力排序
??性能標尺:衡量模型是否達到工業級可用標準
??缺陷定位:識別模型在特定任務上的薄弱環節
- Benchmark核心要素

- Benchmark設計原則
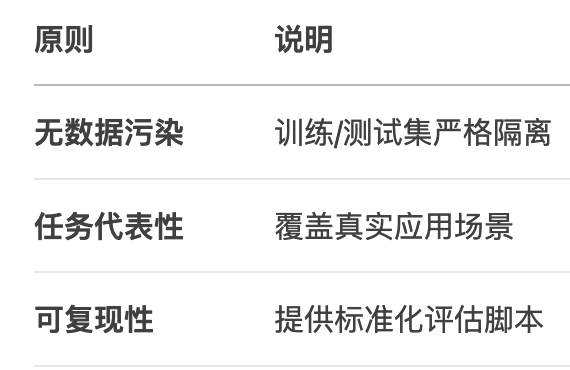
- 靜態Benchmark VS 動態Benchmark
靜態Benchmark:是篩選基礎知識和基本邏輯能力的的有效工具
優點:
- 可復現性與公平性:為不同模型提供了一個公平比較的平臺。
- 診斷短板:可以針對性地測試模型在某個特定能力(如數學推理、代碼生成、知識問答)上的強弱。
- 推動基礎研究:清晰的指標可以引導學術界和工業界在特定方向上攻關。
缺點:
- 過擬合:模型可能會"刷分",學會Benchmark的套路,而非真正的能力。
- 時效性差:知識和能力要求在快速變化,靜態Benchmark很快會過時。
- 與應用脫節:高分不等于在實際應用中有用。
動態Benchmark:檢驗的是解決實際問題的綜合能力
優點:
- 真實反映用戶需求:直接與用戶體感和商業價值掛鉤。
- 捕捉"涌現"問題:能發現模型在受控環境中暴露不出的新問題、偏見和安全漏洞(Red Teaming就是一種形
- 式)。
- 驅動模型"反脆弱":充滿噪聲和變化的數據強迫模型變得更更魯棒、更具適應性
缺點:
- 評估成本高、信噪比低:需要大量人工標注或復雜的A/B測記式系統,且用戶反饋充滿主觀性和噪聲。
- 可復現性差:動態數據流難以精確復現,使得模型間的"apples-to-aapples"比較變得困難。
- 指標定義模糊:如何量化"用戶滿意度"、"創造性"等指標本身就是難題。
如何應用:
在基礎模型研發階段:更關注靜態Benchmark。這個階段的目標是構建模型的通用基礎能力。
我們需要標準化的尺子來衡量模型在數學、邏輯、知識等核心維度上是否取得了突破。沒有這個基礎,談論應用是不切實際的。
在產品應用迭代階段:更關注動態Benchmark。這個階段的目標是解決用戶的具體問題,創造價值。
A/B測試、用戶留存率、滿意度調查等指標是金標準。
- Benchmark分類體系
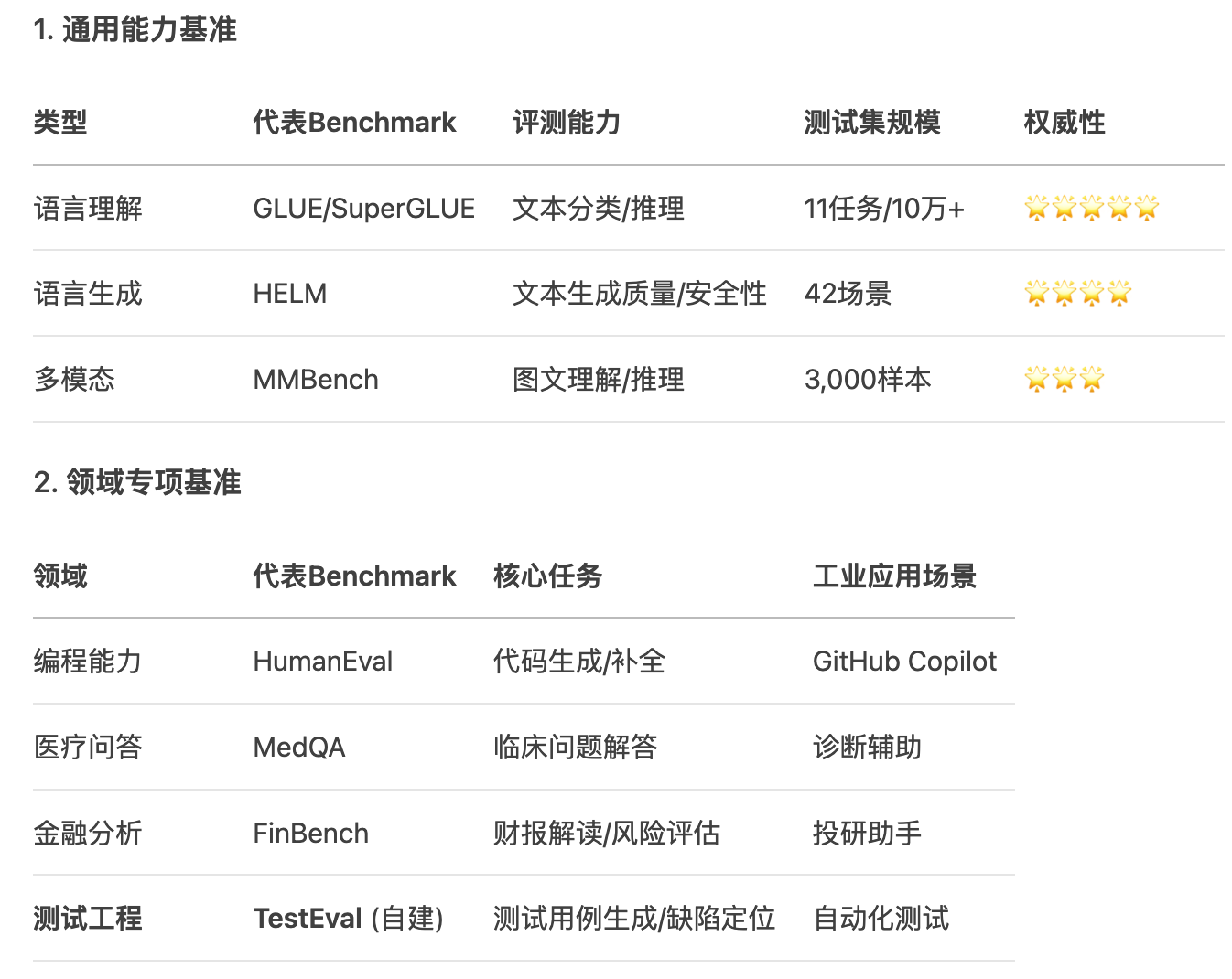

- 高質量的Benchmark
- 廣度與深度:不僅覆蓋多領域知識,更要考察多步推理、規劃、創造等深層能力。
- 抗"應試"性:題目設計巧妙,難以通過搜索或簡單的模式匹配來"作弊"。最好是過程性評估,而非僅僅看最終答案。例如,評估代碼不僅看運行結果,也看代碼質量和解題思路。
- 動態與演化性:Benchmark本身應該是一個"動態"的系系統。它可以定期從真實世界數據中采樣新問題,或者由人類專家、甚至其他AI持續地生成新的問題。
- 診斷性與可解釋性:不僅給出分數,更能揭示模型在哪些模塊上存在缺陷。它應該能回答"模型為什么錯",而不僅僅是"模型錯了"。
- 對齊人類價值觀:必須包含對安全性、公平性、偏見、倫理等方面面的嚴格測試。例如,Safety Benchmarks
- 衡量泛化而非記憶:確保評測數據在模型的訓練集中是"零樣本"或"少樣本"的,真正考驗其泛化能力。
- 交互式與環境感知:未來的Benchmark必然會走向了交互式,在一個模擬或真實的環境中,評估模型完成復雜任務的能力,而不僅是"一問一答"。Agent的評測就是這個方向的體現
LLM Judge
LLM Judge(大型語言模型即裁判)是一種利用微調后的大語言模型(LLM)作為“裁判員”,自動化評估其他AI模型輸出的技術范式。它通過理解任務需求、分析候選答案,并輸出評分、排序或改進建議,顯著提升了模型評估的效率和覆蓋范圍。
- 核心框架
輸入:用戶問題 + 待評估模型的答案(可單答案、多答案對比或多模態數據)。
處理:LLM Judge 解析語義,結合預定義的評估維度(如幫助性、無害性、可靠性等)進行判斷68。
輸出:
評分(如1-5分)、排序(A > B > C)或選擇(最佳答案)
詳細理由(可選生成改進建議)
相比傳統評估的優勢
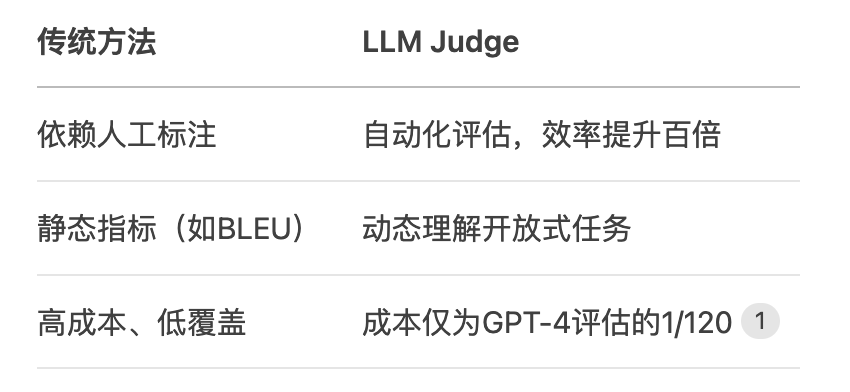
- 核心應用場景
模型能力橫向評測
對比不同LLM在代碼生成(HumanEval)、問答(MedQA)等任務的表現,輸出排名報告。
生成內容質量審核
評估文本的無害性(如過濾暴力內容)、幫助性(客服回答有效性)、事實準確性(醫療建議可靠性)。
多模態與復雜任務
評判圖文匹配度、RAG系統檢索質量,甚至跨模態生成(草圖→代碼)的還原度。
訓練過程優化
替代人工標注生成偏好數據,驅動RLHF(人類反饋強化學習)微調
- LLM Judge的偏見問題
位置偏見:這是最被廣泛證實的一種偏見。在進行 A/B 對比評測時,LLM Judge 傾向于更喜歡排在第一個位置 (Answer A)的答案。即使將兩個答案的順序調換,它也可能仍然選擇第一個,導致評估結果不一致和不準確。
長度偏見:LLM Judge 通常會偏愛更長、更詳細、看起來更全面的回答,即使這些回答可能包含冗余信息、不相 關內容甚至是“幻覺”。這會鼓勵被評估的模型生成冗長而非精煉的答案。
迎合偏見:LLM Judge 在評估其他模型的回答時,可能會偏愛那些風格、格式、觀點與其自身相似的回答。它傾 向于獎勵那些“看起來像自己”的答案,而不是真正更優的答案。這會導致評估的同質化,阻礙模型多樣性的發 展。
格式偏見:對特定格式(如使用Markdown列表、加粗等)的偏好,即使內容質量相當,格式更規整的回答也更 容易獲得高分。
- LLM Judge的缺陷
對提示詞敏感:評估結果很大程度依賴于你如何設計提示詞,提示詞中一個關鍵詞的改變就可能影響評估結果。 這使得設計一個公平、穩定、普適的評估提示詞本身就是一個巨大的挑戰。
評估標準無法完全對齊人類偏好:LLM Judge 的“價值觀”和判斷標準來自于其訓練數據,這不一定完全符合真 實、多樣化的人類偏好。過度依賴 LLM Judge 進行模型迭代,可能會導致模型“過擬合”到 Judge 的偏好上, 而不是真正的人類用戶偏好。
誰來評估裁判的循環問題:如何確定一個 LLM Judge 本身是高質量的?我們通常需要用高質量的人類標注數據 來驗證它。但這又回到了最初試圖用 LLM Judge 來解決的問題——對人類標注的依賴。這形成了一個方法論上 的循環困境。
- 如何提高LLM Judge的準確性
? 優化提示工程
1. CoT: 要求模型在給出最終判斷前,先逐步分析、推理
2. 精細化的評分標準 (Detailed Rubrics): 分解多個正交的、可量化的維度
3. 少樣本提示
? 模型與數據層面的優化
1. 使用更強的基礎模型
2. 在“困難樣本”上進行微調
3. 多模型投票: 不依賴單一的裁判模型
? 人機協同(半自動評估):不追求用 LLM 完全取代人類,而是構建一個人機協同的評測系統
1. 分層審核: 使用 LLM Judge 進行大規模的、初步的篩選和打分,將模型打分處于“模糊地帶” 的交由人類 專家進行精細復核
2. 持續校準: 定期用最新的“金標準”測試集來校準裁判模型


)
求解MaF1-MaF15及工程應用---盤式制動器設計,提供完整MATLAB代碼)
 和 稀疏點云重建的詳細步驟:)


)





)
:Tomcat高版本URL特殊字符限制問題解決方案(RFC 7230 RFC 3986))


)

