一、酶作用優化算法
酶作用優化(Enzyme Action Optimizer, EAO)算法是一種2025年提出的新型仿生優化算法,靈感源于生物系統中酶的催化機制,發表于JCR 2區期刊《The Journal of Supercomputing》。其核心思想是模擬酶與底物的特異性結合、催化反應及動態適應過程,通過平衡搜索空間的探索與開發,實現復雜優化問題的高效求解。
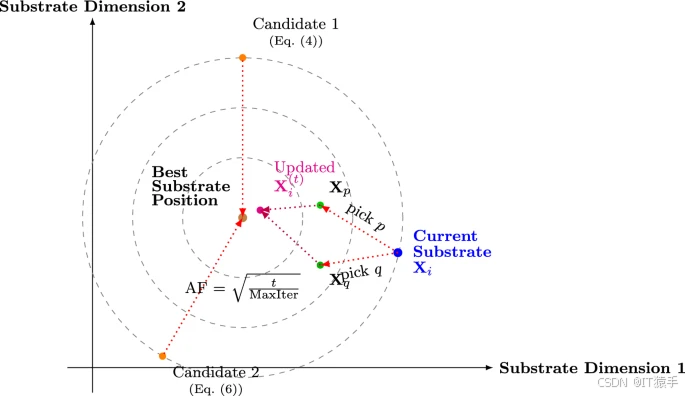
1. 核心機制與數學建模
-
初始化:搜索代理(模擬“底物”)在解空間內隨機初始化,位置滿足:
Xi(0)=LB+(UB?LB)⊙ri\mathbf{X}_i^{(0)} = \text{LB} + (\text{UB} - \text{LB}) \odot \mathbf{r}_iXi(0)?=LB+(UB?LB)⊙ri?
其中LB\text{LB}LB和UB\text{UB}UB為變量上下界,ri\mathbf{r}_iri?為(0,1)(0,1)(0,1)區間隨機向量,⊙\odot⊙表示元素乘法。初始適應度通過目標函數f(Xi(0))f(\mathbf{X}_i^{(0)})f(Xi(0)?)評估,最優初始位置記為Xbest(0)\mathbf{X}_{\text{best}}^{(0)}Xbest(0)?。 -
自適應因子(AF):隨迭代動態調整,平衡探索與開發:
AFt=tMaxIter\text{AF}_t = \sqrt{\frac{t}{\text{MaxIter}}}AFt?=MaxItert??
其中ttt為當前迭代,MaxIter\text{MaxIter}MaxIter為最大迭代次數,確保后期逐步聚焦局部搜索。 -
候選位置生成:每次迭代中,每個底物生成兩個候選位置:
- 基于當前最優解(模擬“酶”)的定向搜索:
Xi,1(t)=(Xbest(t?1)?Xi(t?1))+ρi⊙sin?(AFt?(Xbest(t?1)?Xi(t?1)))\mathbf{X}_{i,1}^{(t)} = (\mathbf{X}_{\text{best}}^{(t-1)} - \mathbf{X}_i^{(t-1)}) + \rho_i \odot \sin(\text{AF}_t \cdot (\mathbf{X}_{\text{best}}^{(t-1)} - \mathbf{X}_i^{(t-1)}))Xi,1(t)?=(Xbest(t?1)??Xi(t?1)?)+ρi?⊙sin(AFt??(Xbest(t?1)??Xi(t?1)?))
其中ρi\rho_iρi?為隨機向量,正弦函數引入波動以增強探索。 - 基于隨機底物差異的多樣化搜索:
Xi,2(t)=Xi(t?1)+sc1d+AFt?sc2(Xbest(t?1)?Xi(t?1))\mathbf{X}_{i,2}^{(t)} = \mathbf{X}_i^{(t-1)} + sc_1 \mathbf{d} + \text{AF}_t \cdot sc_2 (\mathbf{X}_{\text{best}}^{(t-1)} - \mathbf{X}_i^{(t-1)})Xi,2(t)?=Xi(t?1)?+sc1?d+AFt??sc2?(Xbest(t?1)??Xi(t?1)?)
其中d\mathbf{d}d為兩個隨機底物的位置差,sc1,sc2sc_1, sc_2sc1?,sc2?為縮放因子(受酶濃度參數EC\text{EC}EC調控)。
- 基于當前最優解(模擬“酶”)的定向搜索:
-
更新策略:選擇適應度更優的候選位置更新底物,同時更新全局最優解Xbest\mathbf{X}_{\text{best}}Xbest?,確保解始終在可行域內。

2. 算法特點
EAO通過模擬酶的自適應催化特性,動態平衡廣域探索(隨機擾動)與局部開發(定向收斂),在多維復雜優化問題中表現出良好的收斂速度與魯棒性。其核心優勢在于利用酶-底物相互作用的特異性,實現對優質解區域的精準挖掘。
參考文獻
[1]Rodan, A., Al-Tamimi, AK., Al-Alnemer, L. et al. Enzyme action optimizer: a novel bio-inspired optimization algorithm. J Supercomput 81, 686 (2025). https://doi.org/10.1007/s11227-025-07052-w.
二、多目標酶作用優化算法
針對單目標優化問題,酶作用優化算法已顯示出其有效性。然而,在面對多目標優化問題時,需要一種能夠同時處理多個沖突目標的算法。因此,本文提出多目標加權平均算法(Multi-objective Enzyme Action Optimizer, MOEAO)。
為了評估MOEAO的性能,我們將其應用于一組標準的基準測試函數,這組函數包括MaF1-MaF15及工程應用—盤式制動器設計。這些函數在測試多目標優化算法的效率方面被廣泛采用。此外,為了全面評估算法的收斂性和解的多樣性,我們使用了六種不同的性能度量指標:GD、IGD、HV、Spacing、Spread和Coverage。通過這些指標的綜合分析,我們可以有效地評估該算法在處理多目標優化問題時的整體性能。
盤式制動器設計的數學模型如下:

MOEAO算法的執行步驟可以描述如下:

2.1、六種性能評價指標介紹
-
GD(Generational Distance)世代距離:
GD指標用于評價獲得的帕累托前沿(PF)和最優帕累托前沿之間的距離。對于每個屬于PF的解,找到與其最近的最優帕累托前沿中的解,計算其歐式距離,GD為這些最短歐式距離的平均值。GD值越小,代表收斂性越好,找到的PF與最優帕累托前沿越接近。 -
IGD(Inverted Generational Distance)逆世代距離:
IGD與GD相似,但同時考慮了多樣性和收斂性。對于真實的最優帕累托前沿中的每個解,找到與其最近的PF中的解,計算其歐式距離,取平均值而不需開方。如果PF的數量大于最優帕累托前沿的數量,那么IGD就能最完整地表達PF的性能,IGD值越小,代表算法多樣性和收斂性越好。 -
HV(Hypervolume)超體積:
HV也稱為S metric,用于評價目標空間被一個近似集覆蓋的程度,是最為普遍的一種評價指標。需要用到一個參考點,HV值為PF與參考點之間組成的超立方體的體積。HV的比較不需要先驗知識,不需要找到真實的帕累托前沿。如果某個近似集A完全支配另一個近似集B,那么A的超容量HV會大于B,因此HV完全可以用于Pareto比較。 -
Spacing:
Spacing是衡量算法生成的非支配解集中各個解之間平均距離的指標。Spacing值越小,表示解集內部的解越密集,多樣性越高。 -
Spread:
Spread指標衡量算法生成的非支配解集在Pareto前沿上的分散程度。高的Spread值意味著解集在前沿上分布得更均勻,沒有聚集在某個區域。 -
Coverage:
Coverage指標衡量一個算法生成的Pareto前沿覆蓋另一個算法生成的Pareto前沿的比例。如果算法A的Coverage指標高于算法B,那么意味著算法A生成的Pareto前沿在某種程度上包含了算法B生成的Pareto前沿。
2.2、部分MATLAB代碼
%% 參數說明
%testProblem 測試問題序號
%Name 測試問題名稱
%dim 測試問題維度
%numObj測試問題目標函數個數
%lb測試問題下界
%ub測試問題上界
%SearchAgents_no 種群大小
%Max_iter最大迭代次數
%Fbest 算法求得的POF
%Xbest 算法求得的POS
%TurePF 測試問題的真實pareto前沿
%Result 評價指標
testProblem=2;
[Name,dim,numObj,lb,ub]=GetProblemInfo(testProblem);%獲取測試問題的相關信息
SearchAgents_no=200;%種群大小
Max_iter=200;%最大迭代次數
[Fbest,Xbest] = MOWAA(Max_iter,SearchAgents_no,Name,dim,numObj,lb,ub);%算法求解2.3、部分結果








 和 稀疏點云重建的詳細步驟:)


)





)
:Tomcat高版本URL特殊字符限制問題解決方案(RFC 7230 RFC 3986))


)


)


