https://dl.acm.org/doi/pdf/10.1145/3708985
https://www.doubao.com/chat/15495707526837250
Advances and Challenges in Foundation Agents–Memory調研
論文翻譯
基于大型語言模型代理的用戶行為模擬
摘要
在推薦系統、社交網絡等以人為中心的應用中,高質量的用戶行為數據模擬一直是一個基礎性且具有挑戰性的問題。用戶行為模擬的主要難點源于人類認知和決策過程的復雜機制。近年來,大量證據表明,通過學習海量的網絡知識,大型語言模型(LLMs)能夠具備類人智能和泛化能力。受此啟發,本文初步探索了在推薦領域使用大型語言模型進行用戶行為模擬的潛力。為了讓大型語言模型表現得像人類,我們設計了檔案、記憶和行動模塊來裝備它們,構建基于大型語言模型的代理以模擬真實用戶。為了實現不同代理之間的交互并觀察它們的行為模式,我們設計了一個沙盒環境,在該環境中,每個代理都可以與推薦系統進行交互,不同代理之間可以通過一對一聊天或一對多社交廣播與朋友交流。在實驗中,我們首先通過主觀和客觀評估來證明代理生成行為的可信度。然后,為了展示我們方法的潛在應用,我們模擬并研究了兩種社會現象:(1)信息繭房;(2)用戶從眾行為。我們發現,控制推薦算法的個性化程度和提高用戶社會關系的異質性可以作為緩解信息繭房問題的兩種有效策略,而用戶的從眾行為會受到其社會關系數量的顯著影響。為了推動這一方向的發展,我們已在https://github.com/RUC-GSAI/YuLan-Rec發布了我們的項目。
1 引言
以人為中心的人工智能(AI)致力于推動為人類服務的技術發展,在過去幾十年中引起了工業界和學術界的廣泛關注。用戶行為分析是以人為中心的人工智能的一個基本方面,尤其在推薦系統、社交網絡和搜索引擎等應用中。它旨在理解和推斷人類的偏好和行為模式,這對于優化用戶體驗和系統性能至關重要[1]。用戶行為分析的準確性在很大程度上依賴于高質量用戶數據的可用性。然而,嚴格的隱私法規(例如通用數據保護條例)和倫理擔憂極大地限制了數據共享的范圍。此外,多樣化和全面的數據集的有限可用性使得有效開發和評估推薦系統變得困難。這些挑戰需要替代方案來獲取用戶行為數據,特別是那些能夠在不違反隱私規范的情況下模擬現實場景的方案[2]。傳統的模擬策略,如數據驅動和模型驅動方法,存在明顯的局限性。數據驅動方法雖然具有適應性和準確性,但嚴重依賴于高質量的真實世界數據,引發了隱私和倫理方面的擔憂。另一方面,模型驅動方法需要復雜的規則定義,并且往往無法捕捉現實世界用戶行為的動態性和細微差別[3]。這些局限性凸顯了對創新模擬方法的需求,這些方法需要在適應性、可擴展性和真實性之間取得平衡。
近年來,大型語言模型(LLMs)憑借從多樣化的網絡數據中編碼的廣泛知識,已成為能夠理解和生成類人行為的強大工具[4]。這種獨特的能力使大型語言模型非常適合模擬用戶行為,特別是在需要主觀決策、動態交互模式和個性化偏好的場景中。與傳統方法不同,基于大型語言模型的模擬可以在不依賴敏感用戶數據的情況下運行,這使其成為推進隱私保護和可擴展用戶行為分析研究的一個有前景的方向。然而,將大型語言模型的能力轉移到模擬現實場景中的用戶行為并非易事。首先,用戶具有多樣化的偏好、個性和背景,這使得大型語言模型難以有效模擬不同的用戶角色。此外,現實世界中的用戶行為是動態互聯的,先前的行為會影響后續的行為。由于普通的大型語言模型擅長一次性的靜態任務,我們需要設計額外的模塊來增強它們處理動態行為的能力。
此外,現實世界場景中的用戶行為數量龐大,其中許多是瑣碎的,例如“吃早餐”或“刷牙”等日常活動,這些與推薦系統無關。模擬每一個用戶行為既不必要也不切實際,因此需要仔細考慮哪些行為應該優先模擬。除了這些單用戶挑戰之外,設計一個環境和執行協議來有效組織多個用戶之間的交互也需要大量的努力。
為了解決上述問題,我們提出了一種新穎的推薦模擬器,稱為RecAgent。從用戶角度來看,我們用一個基于大型語言模型的自主代理來模擬每個用戶,該代理由檔案模塊、記憶模塊和行動模塊組成。檔案模塊可以靈活高效地生成不同的代理檔案。記憶模塊旨在使用戶行為在動態環境中更加一致,用戶先前的行為可以存儲在記憶中,以影響他們后續的決策。在行動模塊中,我們不僅納入了用戶在推薦系統內的行為,如點擊和瀏覽項目,還考慮了朋友聊天和社交廣告等外部因素,以更全面地模擬用戶決策過程。通過整合所有這些模塊,我們旨在實現更一致、合理和可靠的用戶行為模擬。從系統角度來看,我們的模擬器最多包含1000個代理。這種配置在現實的大規模模擬需求與實際考慮(如與大型語言模型推理相關的計算時間和資源需求)之間取得了平衡。它以輪次方式執行。在每一輪中,代理根據其預定義的活動水平自主執行操作。為了促進人機協作,我們允許真實人類作為代理在模擬器中參與,并與推薦系統和其他代理進行交互。此外,還可以通過暫停模擬過程、修改代理檔案,然后重新運行模擬器來主動干預系統。這種干預對于研究緊急事件的影響、用戶反事實行為等方面可能是有益的。
與傳統的推薦模擬策略相比,我們的模擬器使用大型語言模型來捕捉用戶的決策過程。由于大型語言模型已經學習了全面的網絡知識,它們在模擬推薦系統(這是一種典型的網絡應用)方面可能更有效。此外,我們的模擬器不需要額外的數據來初始化模擬過程,這使得聯合模擬多個場景成為可能。然而,在傳統的模擬策略中[3],數據驅動方法更具適應性和準確性,但需要真實世界的數據來初始化模擬器,而模型驅動方法需要手動定義復雜的規則,這些規則不具有可擴展性和有效性。
為了評估我們模擬器的有效性,我們從代理和系統兩個角度進行了廣泛的實驗。從代理角度來看,我們首先關注記憶模塊的評估,因為它是驅動代理行為的關鍵。然后,我們對代理進行整體評估,研究它是否能夠產生可信的用戶行為。從系統角度來看,我們關注模擬效率的評估以及主動干預模擬器是否能產生預期的用戶行為。最后,我們通過使用模擬器研究兩種現象(1)信息繭房和(2)用戶從眾行為,展示了模擬器的應用。
總之,本文的主要貢獻可以總結如下:
—
我們開創了在推薦領域使用基于大型語言模型的代理進行用戶行為模擬的方向。
—
作為該方向的初步嘗試,我們設計了一個統一的代理框架和多代理環境來模擬真實用戶行為。
—
我們進行了廣泛的實驗,以證明我們的模擬器所模擬的用戶行為的可信度。
—
我們通過研究信息繭房和用戶從眾行為現象,展示了我們模擬器的潛力。
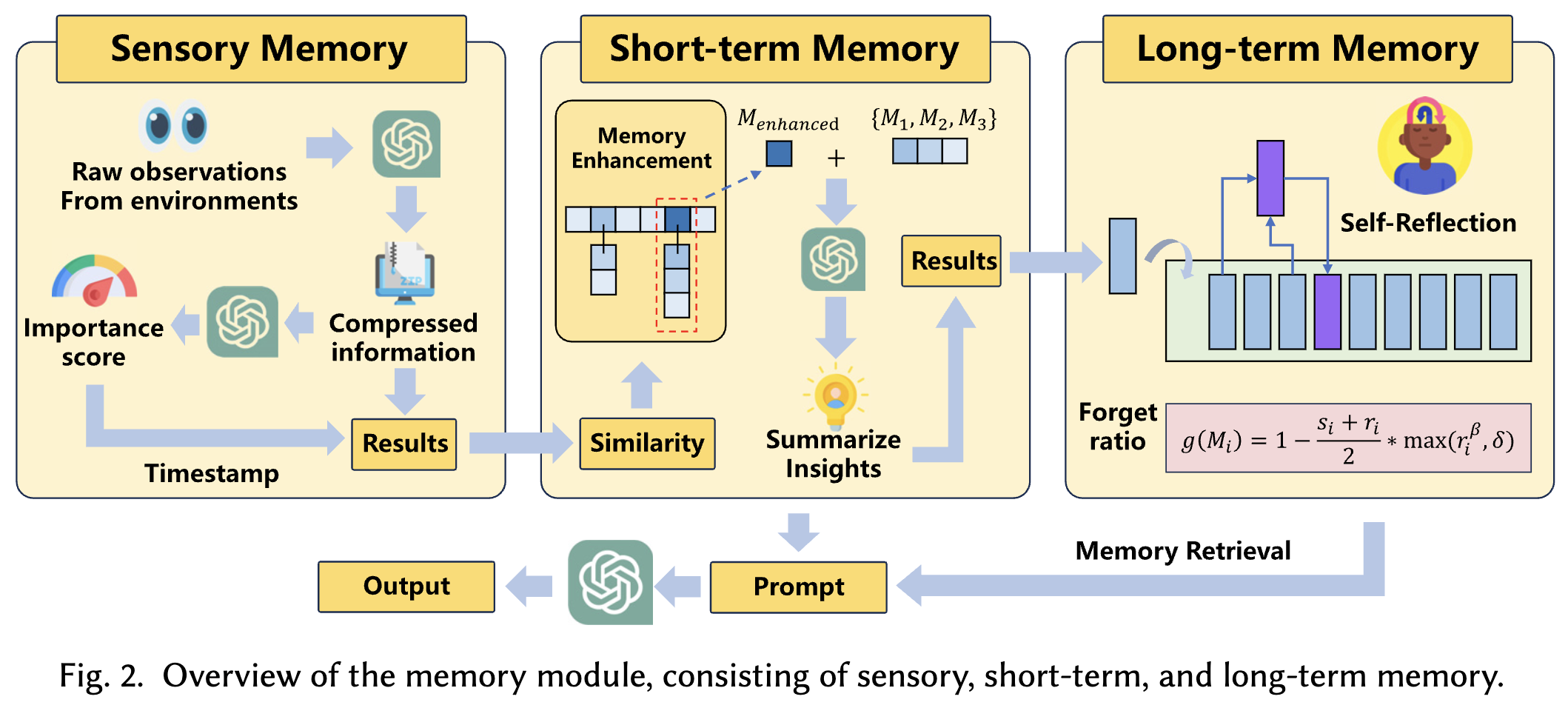
3.1.2 記憶模塊
認知神經科學的最新進展[63]強調了人類記憶的三個關鍵組成部分:感覺記憶、短時記憶和長時記憶。感覺記憶直接從環境中獲取信息,并僅能保留幾百毫秒。在此期間,重要信息會被轉移到短時記憶,而不太重要的信息則會被丟棄。短時記憶起到橋梁作用,其中的信息可以通過反復接觸得到強化,并最終轉移到長時記憶中。長時記憶能長時間存儲信息,使人類能夠根據經驗做出決策并產生高級見解。為了準確模擬用戶行為,我們基于上述人類記憶機制設計了模擬器的記憶模塊,其詳細工作原理如圖2所示。下面,我們首先詳細介紹模擬器中的代理感覺記憶、短時記憶和長時記憶,然后說明它們如何協同工作以完成不同的記憶操作。







)











