一、可愛版 pytest 插件 & hook 知識大禮包 🎁
?
準備好和 pytest 插件來一場可愛約會了嗎~ 咱們用超甜的 emoji 把知識串成棉花糖🍡 一口一個知識點!
?
一、 pytest 插件:框架的 “魔法百寶箱” 🧙?♀?
1. 核心秘密:75% 都是插件!
pytest 源碼里?3/4 都是插件代碼!這說明啥?
→ pytest 本身就是個 “插件大禮包”🎁 所有靈活擴展的功能,全靠插件機制撐起來!
2. 插件能做啥?
給 pytest 裝插件,就像給手機裝 App~
- 想生成花里胡哨的測試報告?裝報告插件!📊
- 想自定義測試用例收集規則?裝收集插件!🧹
- 想在測試前后自動初始化數據?裝初始化插件!🧪
- 總之:插件 = pytest 的 “超能力擴展包”,想改功能、加功能,全靠它!
二、寫 pytest 插件的 “甜甜四步法” 🍰
給 pytest 寫插件,就像給朋友做定制禮物🎁 分四步:
1. 第一步:摸清 pytest 的 “鉤子清單”?
pytest 有 52 個左右的?hook(鉤子),全藏在?_pytest/hookspec.py?文件里!
每個 hook 長這樣:
@hookspec
def pytest_addhooks(pluginmanager): ...
→ 你需要知道:
- 名字:比如?
pytest_addhooks?是 hook 的 “身份證”~ - 參數:它需要啥參數(比如?
pluginmanager),插件里的函數必須 “對得上”! - 返回值:它要返回啥(比如?
None),插件實現時得 “按規矩來”~ - 執行時機:它在 pytest 運行的哪個階段觸發(比如 “初始化時”“收集測試用例時”)
2. 第二步:對準需求選 hook 🎯
先想清楚:你想讓 pytest 做啥?
- 需求:“想在測試報告里加表情包!” → 選?
Reporting hooks?相關的 hook~ - 需求:“想跳過特定環境的測試!” → 選?
Test running hooks?相關的 hook~ - → 整理出能解決你痛點的 hook,就像 “選對工具做手工”??
3. 第三步:實現 hook(寫插件!) ?
找到想擴展的 hook 后,寫插件函數~ 記得貼?@hookimpl?標簽!
示例:想在測試前打印 “加油”💪
from pluggy import hookimpldef pytest_runtest_setup(item):print("💪 測試加油!這是插件擴展的邏輯~")
→ 關鍵點:
- 函數名和 hook 名字一致(比如?
pytest_runtest_setup)~ - 參數和 hook 聲明的參數一致(比如?
item?代表測試用例)~ - 用?
@hookimpl?裝飾器標記,告訴 pytest:“我是插件!”
4. 第四步:打包插件(分享甜蜜!) 📦
寫好的插件,要打包成 “安裝包”~
- 用?
setuptools?寫?setup.py,把插件打包成?whl?或?tar.gz?文件~ - 別人裝你的插件,就像?
pip install 你的插件包,超方便!
三、 hook 的 “執行時機”: pytest 的生命周期派對 🎉
pytest 運行時,像一場 “分階段派對”,每個階段觸發不同的 hook~
1. 官方分類(超甜版) 🍬
pytest 把 hook 分成 6 類,對應派對的 6 個環節:
| 分類名 | 派對環節比喻 | 作用 |
|---|---|---|
| Bootstrapping hooks | 派對籌備 | 初始化 pytest 最基礎的配置 |
| Initialization hooks | 賓客簽到 | 初始化插件、配置,準備測試 |
| Collection hooks | 菜品收集 | 收集要執行的測試用例(找 “測試菜”) |
| Test running hooks | 吃飯環節 | 執行測試用例(干飯!) |
| Reporting hooks | 寫用餐評價 | 生成測試報告(寫好評 / 差評) |
| Debugging/Interaction hooks | 突發狀況處理 | 調試、交互(比如測試卡住時干預) |
2. 執行順序:派對流程 🎊
pytest 運行時,hook 會按以下順序 “登場”:
籌備(Bootstrapping)?→?簽到(Initialization)?→?收菜(Collection)?→?干飯(Test running)?→?寫評價(Reporting)?→?處理突發狀況(Debugging)
→ 每個環節的 hook 依次調用,像接力賽一樣~ 前一個環節的 hook 跑完,下一個接上!
四、生成 & 讀 pytest 的 debug log:看 hook 怎么 “蹦迪” 🕺
想知道 hook 具體啥時候執行?用 debug log 看它們的 “蹦迪軌跡”!
1. 生成 log:開啟 debug 模式?
在命令行執行:
# Windows
set PYTEST_DEBUG=1
pytest 你的測試文件.py > pytest.log # Linux/Mac
PYTEST_DEBUG=1 pytest 你的測試文件.py > pytest.log
→ 這會讓 pytest 把?所有 hook 調用、執行細節?都記在?pytest.log?里,像 “蹦迪全程錄像”!
2. 讀 log:找 hook 的 “蹦迪鏡頭” 🎥
打開?pytest.log,搜索?pytest_?開頭的函數名(比如?pytest_runtest_setup),就能看到:
DEBUG: pytest: Calling hook pytest_runtest_setup
DEBUG: pytest: Hook pytest_runtest_setup executed with args (...)
→ 這說明:
Calling hook...:pytest 要開始調用這個 hook 啦(喊它 “上臺蹦迪”)~executed with args...:hook 執行了,還帶了參數(比如測試用例信息)~
3. 看執行時機:派對時間線 🕒
把所有 hook 的?Calling hook?日志按順序排,就能畫出 pytest 的 “生命周期時間線”~
比如:
Calling hook pytest_collectstart # 開始收測試用例
Calling hook pytest_runtest_setup # 準備執行測試
Calling hook pytest_runtest_call # 正在執行測試
Calling hook pytest_runtest_teardown # 測試結束清理
→ 這樣就清楚每個 hook 在 “派對” 的哪個時間點蹦迪啦!
總結: pytest 插件 & hook 超甜關系 💕
- pytest?是 “派對主辦方”,提供基礎流程~
- hook?是 “派對環節接口”,每個環節開放給插件擴展~
- 插件?是 “派對嘉賓”,用?
@hookimpl?實現 hook,在對應環節 “表演節目”~
想玩轉 pytest 源碼或寫插件?記住這顆 “糖”:hook 是橋梁,插件是魔法,pytest 靠它們無限擴展!?🍭
二、用 pytest hook 自動生成測試用例 🧪?
一、項目結構(更簡單!)
my_project/
├── conftest.py # 核心:寫插件邏輯
├── test_data/ # 測試數據文件夾
│ ├── test_add.json
│ └── test_sub.json
└── test_demo.py # 測試文件(觸發插件)
二、編寫 conftest.py(核心!)
# conftest.py
from _pytest.nodes import Item
from pathlib import Path
import json# 1. 自定義測試項類:實現測試邏輯
class CatDataItem(Item):def __init__(self, *, name, parent, data):super().__init__(name=name, parent=parent)self.data = data # 保存測試數據def runtest(self):a = self.data["a"]b = self.data["b"]expected = self.data["c"]result = a + bassert result == expected, f"{a} + {b} != {expected}"def reportinfo(self):return self.fspath, 0, f"CatData: {self.name}"# 2. 實現 pytest_pycollect_makeitem hook
def pytest_pycollect_makeitem(collector, name, obj):# 只處理特定測試文件(這里假設文件名包含 "test_data")if "test_data" not in collector.name:return None # 不是目標文件,走默認流程# 獲取測試數據文件夾路徑(相對于當前執行目錄)data_dir = Path(__file__).parent / "test_data"# 收集所有 .json 文件test_files = list(data_dir.glob("test_*.json"))if not test_files:return None # 沒有測試數據文件,走默認流程# 為每個 JSON 文件創建一個測試項items = []for test_file in test_files:with open(test_file, "r", encoding="utf-8") as f:test_data = json.load(f)# 創建測試項,名字取自 JSON 中的 "name" 字段item = CatDataItem.from_parent(parent=collector,name=test_data["name"],data=test_data)items.append(item)return items # 返回所有自定義測試項
三、編寫測試數據(test_data/ 目錄)
1.?test_add.json
{"name": "test_addition","a": 1,"b": 2,"c": 3
}
2.?test_sub.json
{"name": "test_subtraction","a": 5,"b": 2,"c": 3
}
四、編寫測試文件(test_demo.py)
# test_demo.py
# 文件名包含 "test_data",會觸發我們的插件邏輯
def test_data_demo():pass # 這個函數本身不會被執行,只是作為觸發插件的載體
五、運行測試(無需安裝插件!)
pytest -v
預期輸出:
test_demo.py::test_data_demo::CatData: test_addition PASSED [ 50%]
test_demo.py::test_data_demo::CatData: test_subtraction PASSED [100%]
?實際輸出:
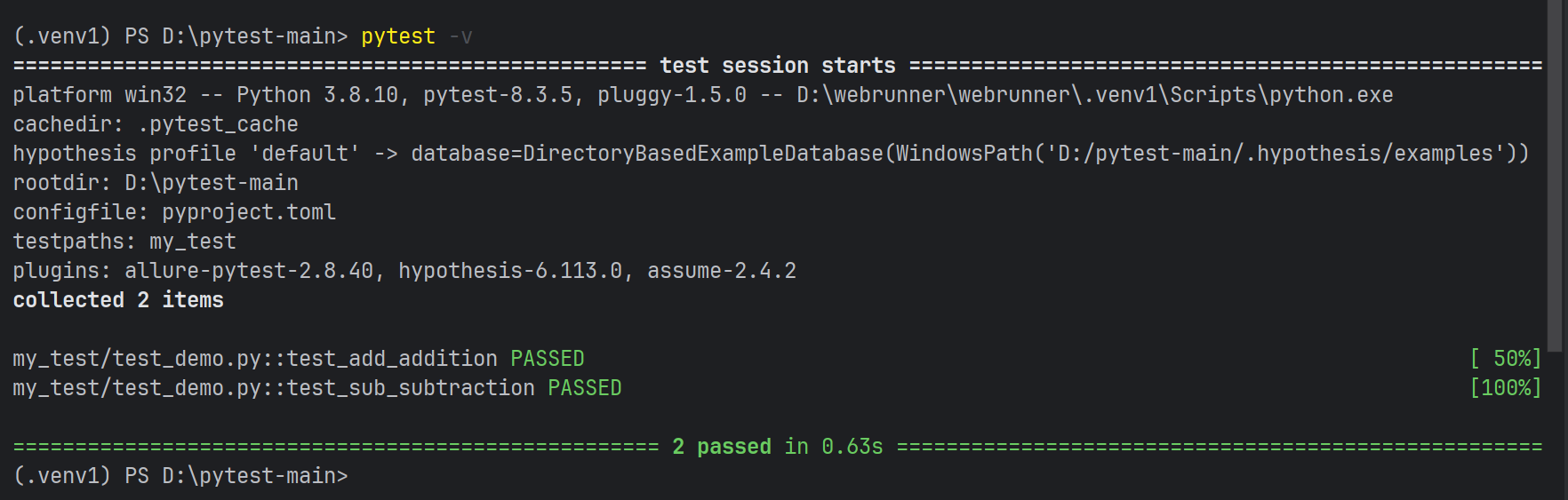
?
六、關鍵區別(與插件方式對比)
| 對比項 | conftest.py 方式 | 插件方式 |
|---|---|---|
| 位置 | 項目根目錄或測試目錄下的 conftest.py | 獨立的 Python 包(setup.py) |
| 安裝 | 無需安裝,pytest 自動發現 | 需要 pip install 或 poetry |
| 適用場景 | 單個項目自用 | 多個項目共享或發布到 PyPI |
| 復雜度 | 簡單,適合快速實現 | 復雜,適合大型插件 |
七、進階玩法(在 conftest.py 中)
1. 動態數據目錄(通過命令行參數)
# conftest.py
def pytest_addoption(parser):parser.addoption("--data-dir", action="store", default="test_data", help="測試數據目錄")def pytest_pycollect_makeitem(collector, name, obj):# ... 其他代碼不變 ...# 獲取命令行指定的數據目錄data_dir = Path(collector.config.getoption("--data-dir"))# ... 后續代碼不變 ...
使用方法:
pytest --data-dir=my_custom_data -v
2. 支持多種數據格式(JSON + YAML)
# 需要先安裝:pip install pyyaml
import yamldef pytest_pycollect_makeitem(collector, name, obj):# ... 其他代碼不變 ...for test_file in test_files:with open(test_file, "r", encoding="utf-8") as f:if test_file.suffix == ".json":test_data = json.load(f)elif test_file.suffix == ".yaml":test_data = yaml.safe_load(f)# ... 后續代碼不變 ...
順便記一下這些文件屬性的小tips:?
| 屬性 | 示例 (addition.json) | 輸出 |
|---|---|---|
.suffix | Path("addition.json").suffix | .json |
.stem | Path("addition.json").stem | addition |
.name | Path("addition.json").name | addition.json |
.parent | Path("addition.json").parent | test_data |
.parts | Path("test_data/addition.json").parts | ('test_data', 'addition.json') |
三、超詳細拆分和解讀代碼🐱
一、導入模塊
from _pytest.nodes import Item
from pathlib import Path
import json
Item:pytest 框架中的測試項基類,我們要繼承它來創建自定義測試Path:Python 的路徑操作工具,比字符串處理路徑更方便json:處理 JSON 格式數據的模塊
?
二、自定義測試項類
class CatDataItem(Item):def __init__(self, *, name, parent, data, path):super().__init__(name=name, parent=parent)self.data = dataself.path = path # 保存測試數據文件路徑,用于調試
CatDataItem:繼承自?Item?的自定義測試項類__init__:初始化函數,創建對象時自動調用name:測試名稱parent:父級測試容器data:從 JSON 文件加載的測試數據path:JSON 文件路徑(用于調試)
super().__init__:調用父類的初始化函數
?
三、測試執行邏輯
def runtest(self):a = self.data["a"]b = self.data["b"]expected = self.data["c"]result = a + bassert result == expected, f"{a} + {b} != {expected} (from {self.path.name})"
runtest:pytest 框架要求的方法,定義測試執行邏輯- a=self.data["a"] 在data里獲取鍵為a的值 把這個值賦值給變量a
?
四、測試報告信息
def reportinfo(self):return self.fspath, 0, f"CatData: {self.name}"
reportinfo:定義測試報告中顯示的信息- 返回元組:(文件路徑,行號,測試名稱)
- 第一個元素?
self.fspath:
測試項關聯的文件路徑(比如?test_demo.py?的路徑),用于在報告中顯示 “這個測試來自哪個文件”。 - 第二個元素?
0:
測試項在文件中的行號(這里固定為?0,因為你的測試是動態生成的,沒有實際行號)。 - 第三個元素?
f"CatData: {self.name}":
測試項的描述信息,會顯示在報告中。self.name?是你定義的測試名稱(比如?test_add_addition),前面加?CatData:?是為了區分這是你自定義的測試項。
pytest 有兩類核心鉤子,它們的工作方式不同:
1.?插件級鉤子(函數形式)
就是在?conftest.py?中寫的?pytest_pycollect_makeitem?這類函數 —— 它們必須以?pytest_?開頭,放在?conftest.py?中,pytest 會自動掃描并加載這些函數,作為插件擴展邏輯
這類鉤子需要?“顯式聲明”(通過命名規范和文件位置),因為它們是 “外部插件” 向框架注入邏輯的入口。
2.?類級鉤子(方法形式)
Item?類中的?runtest、reportinfo?這類方法屬于?“框架內部接口鉤子”—— 它們是框架提前定義好的 “接口方法”,要求子類必須(或可以)重寫,以實現特定功能。
這類鉤子?不需要插件聲明,因為它們是框架內部的 “約定”:只要你繼承了?Item?類,并重寫了這些方法,框架就會自動識別并調用它們,無需額外聲明。
?
五、防止重復處理的全局變量
# 用于跟蹤已處理的文件,避免重復
processed_files = set()
set():無序且唯一的數據集合- 記錄已經處理過的文件,避免重復生成測試
🐍 Python 里超好用的?
set()?集合!它就像一個神奇的小口袋,裝東西有特別的規矩哦~ 😜🌟 什么是?
set()?set?是 Python 的一種數據類型,中文叫 “集合”。它最大的特點就是:里面的元素不能重復,而且沒有固定順序~ 就像一堆散亂但絕不重復的糖果🍬,拿出來的時候順序說不定會變,但每種糖只會有一顆!🛠? 基本用法
1. 創建集合
# 用 {} 直接創建(注意:空集合不能用 {},要用 set()!) candies = {"草莓糖", "牛奶糖", "巧克力"} print(candies) # 可能輸出:{'牛奶糖', '草莓糖', '巧克力'}(順序不定)# 用 set() 轉換其他類型(比如列表) fruit_list = ["蘋果", "香蕉", "蘋果"] # 列表里有重復的蘋果哦 fruit_set = set(fruit_list) print(fruit_set) # 輸出:{'蘋果', '香蕉'}(自動去重啦!)2. 給集合 “加東西”
用?
add()?方法,一次加一個元素~ 🍡pets = {"貓", "狗"} pets.add("兔子") # 加一只兔子 pets.add("貓") # 再加一只貓?不會成功哦,因為集合里不能有重復! print(pets) # 輸出:{'貓', '狗', '兔子'}3. 從集合 “拿東西”
用?
remove()?或?discard()?方法~ 注意?remove()?刪不存在的元素會生氣(報錯),discard()?會默默忽略哦~ 😌toys = {"積木", "娃娃", "汽車"} toys.remove("娃娃") # 刪掉娃娃 toys.discard("飛機") # 刪掉不存在的飛機,不報錯 print(toys) # 輸出:{'積木', '汽車'}4. 集合的 “魔法操作”
集合最擅長做 “交集、并集、差集”,就像玩拼圖一樣~ 🧩
a = {1, 2, 3, 4} b = {3, 4, 5, 6}# 交集(兩個集合都有的元素)& print(a & b) # 輸出:{3, 4}# 并集(兩個集合所有元素,去重)| print(a | b) # 輸出:{1, 2, 3, 4, 5, 6}# 差集(a有但b沒有的元素)- print(a - b) # 輸出:{1, 2}5. 檢查元素在不在集合里
用?
in?關鍵詞,超快速!比列表檢查快很多哦~ ?snacks = {"薯片", "餅干", "果凍"} print("薯片" in snacks) # 輸出:True(薯片在里面!) print("巧克力" in snacks) # 輸出:False(沒有巧克力~)🎯 什么時候用?
set()?- 想?去重?的時候(比如清理重復數據)
- 想快速?判斷元素是否存在?的時候(比列表快 N 倍!)
- 想做?集合運算?的時候(比如找共同元素、不同元素)
?
六、測試收集鉤子函數
def pytest_pycollect_makeitem(collector, name, obj):# 只處理 my_test 目錄下的 test_demo.pyif not hasattr(collector, 'fspath'):return None
這里是在檢查?collector(pytest 的收集器對象)有沒有?fspath?這個屬性。
fspath?是 “文件路徑” 的意思,只有當?collector?正在處理具體文件時,才會有這個屬性;- 如果?
collector?處理的是文件夾(或者其他非文件對象),就沒有?fspath,這時候就返回?None?跳過處理。
?
collector?是 pytest 中一類特殊的對象,中文叫 “收集器”,作用是?“發現并收集測試用例”。不同類型的?collector?負責處理不同的測試結構:
Module?類型的 collector:處理?.py?測試文件(比如?test_demo.py)。Class?類型的 collector:處理測試類(比如?class TestDemo:)。Function?類型的 collector:處理測試函數(比如?def test_add():)。- 還有?
Package(處理測試包)、File(處理非 Python 文件)等類型。
?
collector 是在哪里創建的?
當你運行?pytest?命令時,pytest 會按以下流程自動創建 collector:
- 掃描項目目錄:pytest 從指定目錄(默認當前目錄)開始,遞歸掃描所有文件和文件夾。
- 根據文件 / 內容創建 collector:
- 當掃描到一個?
.py?文件(比如?test_demo.py),pytest 會創建一個?Module?類型的 collector,負責處理這個文件里的測試內容。 - 如果這個?
.py?文件里有測試類(比如?class TestXXX:),pytest 會為這個類創建一個?Class?類型的 collector。 - 如果文件里有測試函數(比如?
def test_xxx():),會創建?Function?類型的 collector。
- 當掃描到一個?
- collector 工作:每個 collector 會 “收集” 自己負責的測試元素(比如?
Module?收集文件里的所有測試類和函數),并生成對應的測試項(Item)。
在的pytest_pycollect_makeitem?鉤子函數中,collector?是 pytest 自動傳遞給你的 “已經創建好的收集器”。比如:
- 當 pytest 掃描到?
my_test/test_demo.py?時,會創建一個?Module?類型的 collector(對應這個文件),然后調用你的鉤子函數,并把這個 collector 作為參數傳進來。 - 你的鉤子函數通過判斷這個 collector 的屬性(比如?
fspath?路徑),決定是否要為它生成自定義測試項(CatDataItem)。
?
七、路徑檢查與過濾
fspath = Path(collector.fspath)# 關鍵過濾:只處理 test_demo.py 中的 test_demo 函數
if (fspath.parent.name != "my_test"or fspath.name != "test_demo.py"or name != "test_demo"
):return None
fspath:轉換為 Path 對象的文件路徑- 只處理?
my_test/test_demo.py?文件中的?test_demo?函數 - 其他文件或函數會被忽略
?
八、防止重復處理
# 防止重復處理
if fspath in processed_files:return Noneprocessed_files.add(fspath)
- 如果該文件已經處理過,直接返回
- 否則將文件路徑添加到已處理集合中
?
九、加載 JSON 數據
# 加載 JSON 數據
data_dir = fspath.parent / "test_data"# 檢查數據目錄是否存在
if not data_dir.exists():return Nonetest_files = list(data_dir.glob("*.json"))if not test_files:return None
/ "test_data"- 這里的?
/?不是除法哦!在?pathlib?模塊里,它是?路徑拼接符,專門用來把 “父目錄” 和 “子目錄 / 文件名” 拼在一起。 - 所以?
fspath.parent / "test_data"?就是把?my_test?和?test_data?拼起來,得到?my_test/test_data。
- 這里的?
data_dir:測試數據目錄路徑exists():檢查目錄是否存在glob("*.json"):查找所有 JSON 文件
?
十、生成測試項
items = []
for test_file in test_files:with open(test_file, "r", encoding="utf-8") as f:test_data = json.load(f)# 使用 JSON 中的 name 字段作為測試名稱test_name = test_data.get("name", test_file.stem)# 使用文件名作為后綴(去掉 .json 擴展名)suffix = test_file.stemunique_name = f"{test_name}_{suffix}" # 例如: test_add_additionitem = CatDataItem.from_parent(parent=collector,name=unique_name,data=test_data,path=test_file)items.append(item)return items
CatDataItem.from_parent(...)?的作用和?CatDataItem(...)?一樣,都是創建?CatDataItem?類的實例(對象)。只不過?from_parent?是框架推薦的 “便捷工廠方法”,專門用于從父對象(這里的?collector)創建子對象。
from_parent?是?CatDataItem?類繼承自父類?Item?的一個類方法(用?@classmethod?定義的方法,專門用來創建實例)參數含義
parent=collector:指定當前測試項的父對象是?collector(之前說的 “收集器”,比如?test_demo.py?對應的模塊對象)。
為什么父對象很重要?
在這個層級結構中,每個收集器 / 測試項都有明確的父對象:
Module?收集器的父對象是?Package?或?Directory;Class?收集器的父對象是?Module;Function?收集器的父對象是?Class?或?Module;- 你的?
CatDataItem?測試項的父對象是?Module(因為它來自測試文件)。
父對象包含了重要的上下文信息,比如:
- 文件路徑(
fspath) - 配置信息(如命令行參數)
- 插件設置
- 其他環境信息
?
鉤子函數為什么需要父對象?
鉤子函數的核心作用是?“干預測試收集過程”,而父對象是這個過程中的關鍵節點。通過傳遞父對象,你可以:
- 獲取上下文信息:比如從父收集器的?
fspath?獲取測試文件所在目錄,從而定位測試數據文件。 - 保持層級關系:讓你的自定義測試項正確地掛載到測試樹中,確保報告和執行順序正確。
- 復用配置:繼承父對象的配置(如 pytest.ini 中的設置)。
name=unique_name:測試項的名稱(比如?test_add_addition)。data=test_data:從 JSON 文件加載的測試數據(比如?{"a":1, "b":2, "c":3})。path=test_file:測試數據文件的路徑(比如?test_data/addition.json)。item = ...這行代碼會創建一個?
CatDataItem?實例,并把它賦值給變量?item—— 這就是實例化的結果!items.append(item)把創建好的?
item?實例添加到?items?列表中,最后統一返回給 pytest,讓 pytest 知道 “這些是要執行的測試項”。
為什么不用?CatDataItem(...)?直接實例化?
雖然也可以用?CatDataItem(name=..., parent=...)?直接創建實例,但?from_parent?是 pytest 框架推薦的方式,它有兩個好處:
?
- 自動處理父子關系:
from_parent?會幫你把?item?和?collector?關聯起來,確保?item?能繼承?collector?的配置(比如路徑、測試上下文)。 - 符合框架規范:pytest 的各種內置測試項(比如函數測試、類測試)都是用?
from_parent?創建的,統一方式能避免兼容性問題。


)







:Material Icons圖標的使用)








樹的實現)