一,IOU置信度與非極大值抑制NMS
在第一篇文章中我們講到,對于一張圖片,在前向傳播的過程后(也就是卷積,池化,全連接等等),會生成許許多多個預測框,那么怎么從這么多預測框篩選出最好的幾個框來達到預測功能呢?這里就需要用到IOU和非極大值抑制。
(1)IOU:
什么是IOU?

(1.1)訓練階段:
在模型訓練階段IOU會首先篩選置信度小于閾值的檢測框,接著將剩下的預測框與人工標注的真實框做IOU匹配,用來判斷是否正確檢測到了目標,為后面的反向傳播做準備
(1.2)推理預測階段:
用于非極大值抑制,
推理階段計算IoU的主要目的是篩選重疊的預測框,避免重復檢測同一個目標。具體步驟如下:
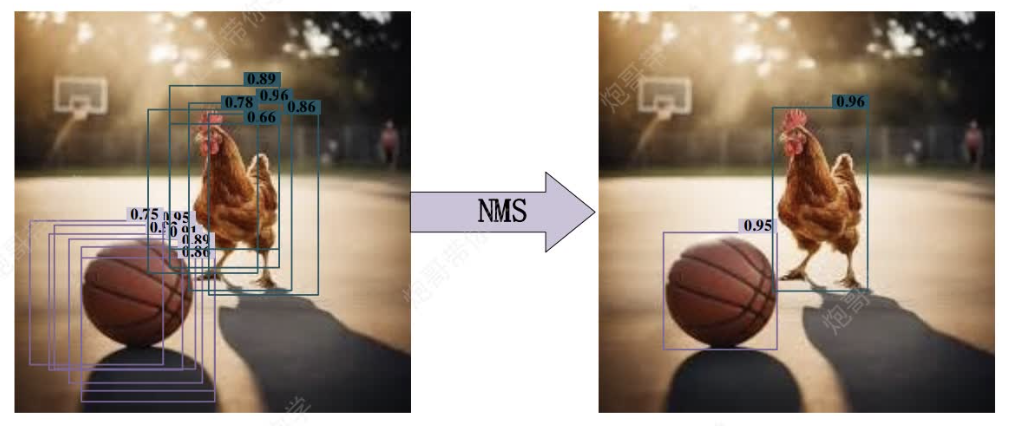
- 按置信度排序:將所有預測框按置信度從高到低排序。
- 選擇最高置信度的框:保留置信度最高的框作為有效檢測。
- 計算IoU:計算該框與其他所有未處理的框的IoU。
- 抑制重疊框:
- 如果某個框與當前最高置信度框的IoU超過閾值(如0.5),則認為它們檢測的是同一個目標,因此丟棄置信度較低的框。
(這里是什么意思呢?就是說因為一個物體必然會占據7*7個小方格中的許多個,都是有效檢測的,如果采取只保留置信度最高的,那么如果圖片里面有多個同類物體,那么只能檢測一個類別物體中的一個,所以我們采用IoU超過閾值(如0.5)舍棄的方法,因為如果兩個同類物體雖然置信度都很高,但是彼此不重疊,所以iou值很低,不會被刪除,這樣既能獲取最高的置信度框,又能避免刪去同類的其他物體,而這就是非極大值抑制) - 重復上述過程,直到處理完所有框。
- 如果某個框與當前最高置信度框的IoU超過閾值(如0.5),則認為它們檢測的是同一個目標,因此丟棄置信度較低的框。
ps:類別置信度=(確實有目標物體的前提下)置信度×類別概率
后處理階段=IOU+NMS?
二,關于YOLOV2的改進點?
在yolov1的基礎上,yolov2進行了許多改進,讓我們來看看吧~
改進點有:
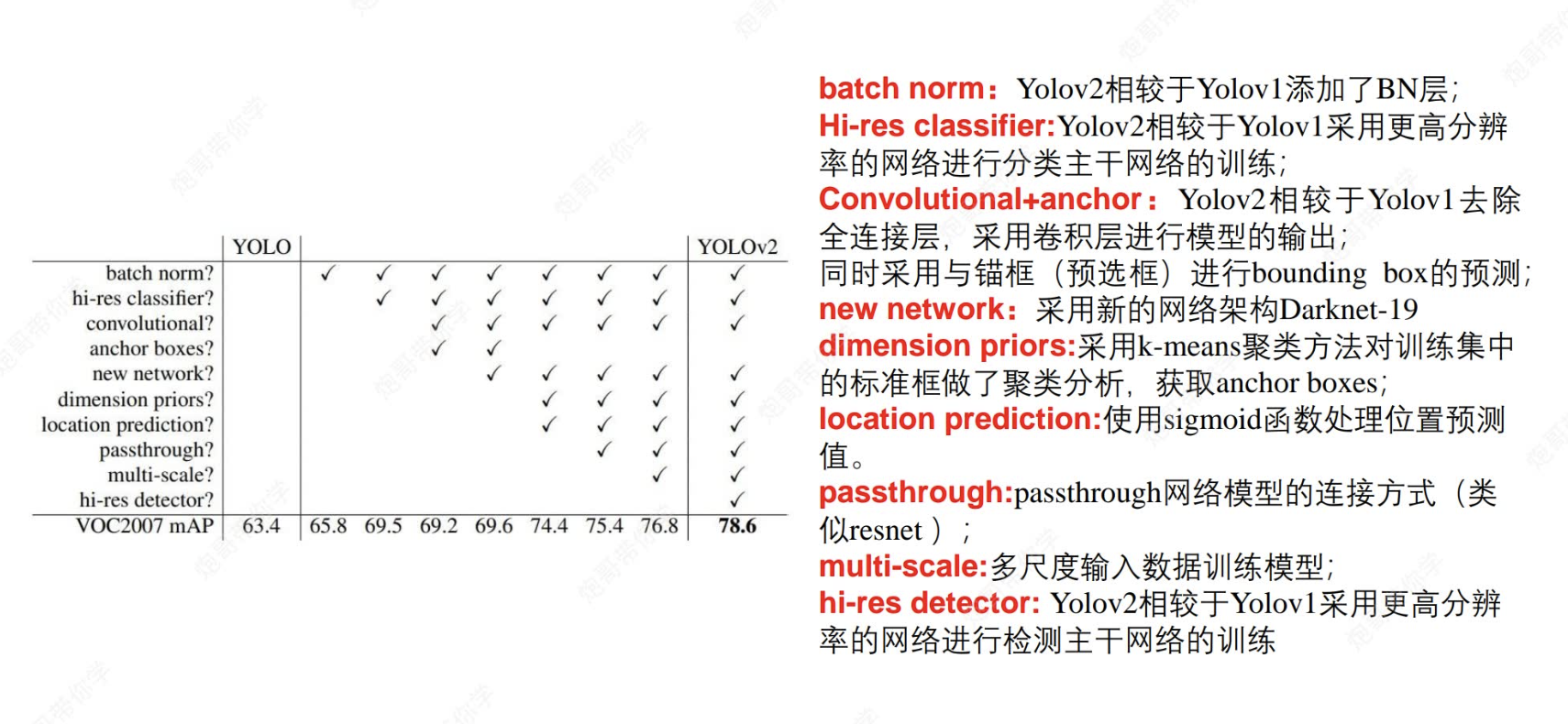
2.1 引入批歸一化(Batch Normalization, BN)層
問題來源:如下圖左邊:
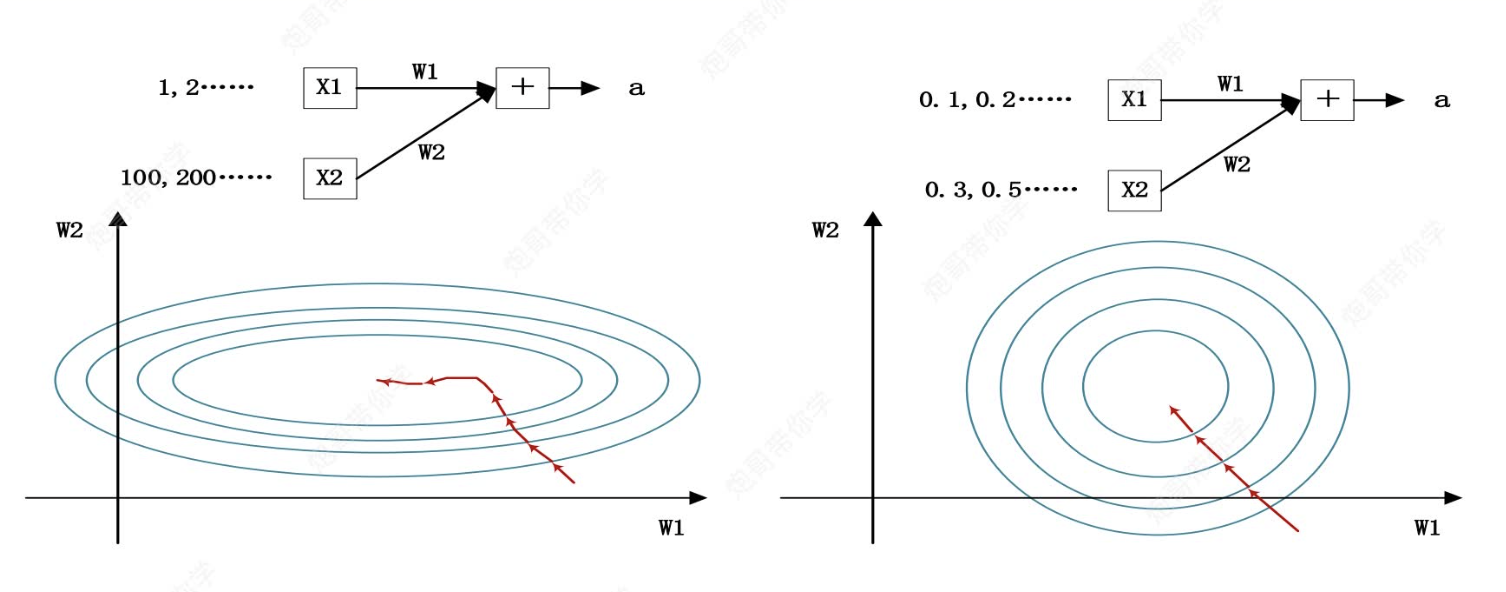
當我們在進行數據輸入時,我們知道,很多數據的量綱是不統一的。如果此時大小較小的數據?
更為重要,那很明顯w1的值就要很大,但是由于梯度下降時漸進的,這時參數更新可能需要很多步才能到達最優點。而如果我們進行歸一化操作(如右圖),那么梯度更新將變得不那么復雜。也就是說,歸一化后的數據分布更穩定,網絡在訓練時更容易找到最優解,從而加快收斂速度。
當然,加入BN層還有其他好處。
2.1.1 BN層計算步驟

2.2 采用高分辨率網絡訓練?
相較于yolov1,yolov2先用低分辨率進行訓練,之后再用實際檢測需要的高分辨率數據進行再訓練,有效提高了準確率。

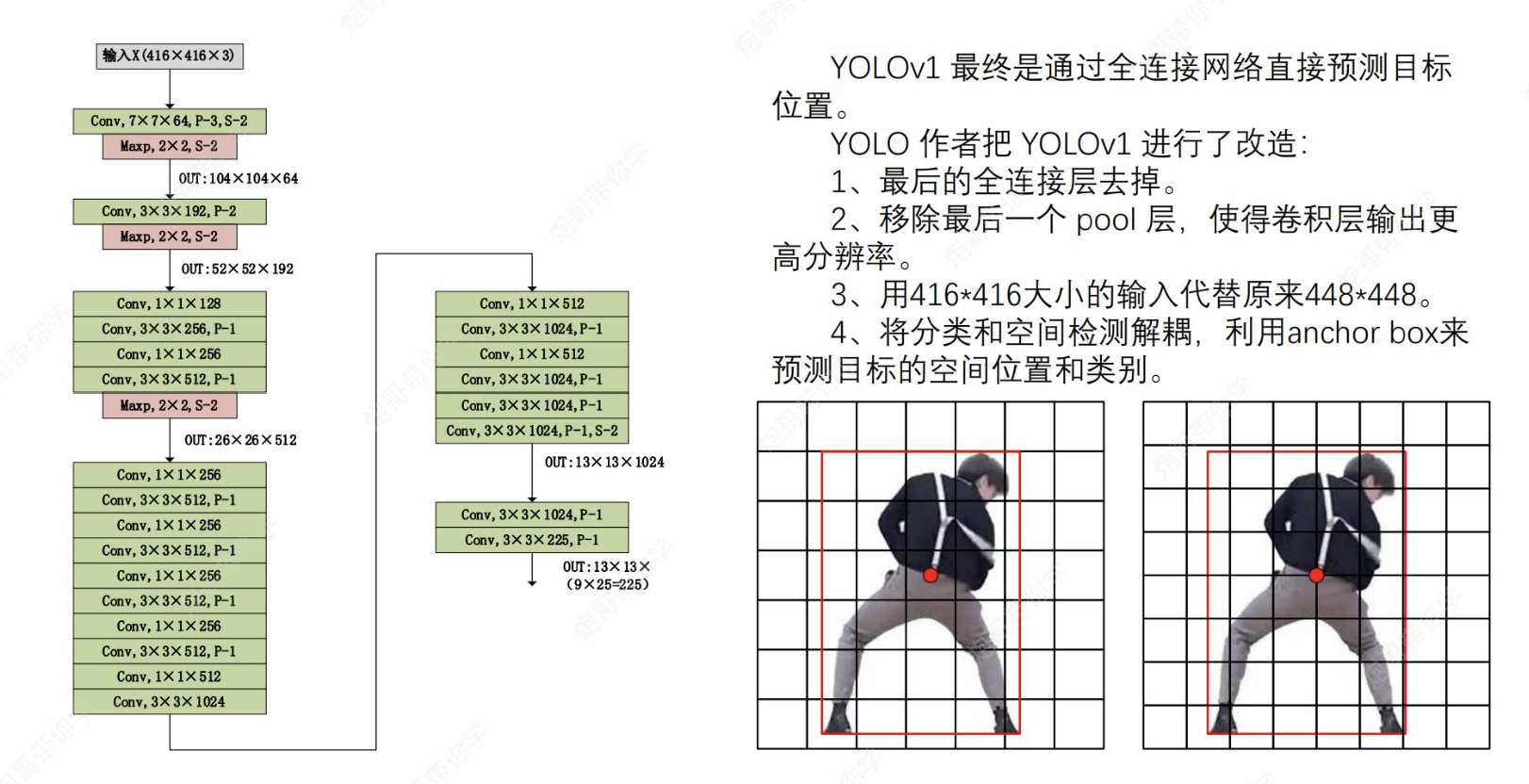
?2.3 刪去全連接層 -->convolutional
?
(1)最后的幾個全連接層以及前面的最后一個pool層被刪去,這有利于獲得更高分辨率的圖片。
(2)采用416*416進行輸入的原因是最后的輸出是13*13是奇數矩陣,原來是偶數矩陣的弊端是,按照統計規律,圖片目標物體位于中心的可能性較大,這時物體中心點很可能位于映射邊框上,使得模型難以區分該點是屬于哪一格子里的。
(3)采用解耦合的好處,原來的格子是2個檢測框,每個格子的類別概率同屬2個檢測框,這樣會使得兩個檢測框只能檢測同一種物體。而解耦合能使得每個檢測框都有自己獨立的類別檢測概率,從而實現一個格子里面可以檢測出多種物體。
2.3.1 采用anchor錨框
?怎么理解這個錨框呢?就是我們考慮到yolo模型通過主干網絡提取的信息來確定框框的大小還是有點難的,所以我們給他點“提示”,我們先設定了大小,長寬比不同的box(共9個,后面會通過聚類算法減成5個),之后模型基于此anchor等比例縮放(而不是從0開始畫),就能比較好的結合獲取到的全局特征,檢測出物體并正確畫框。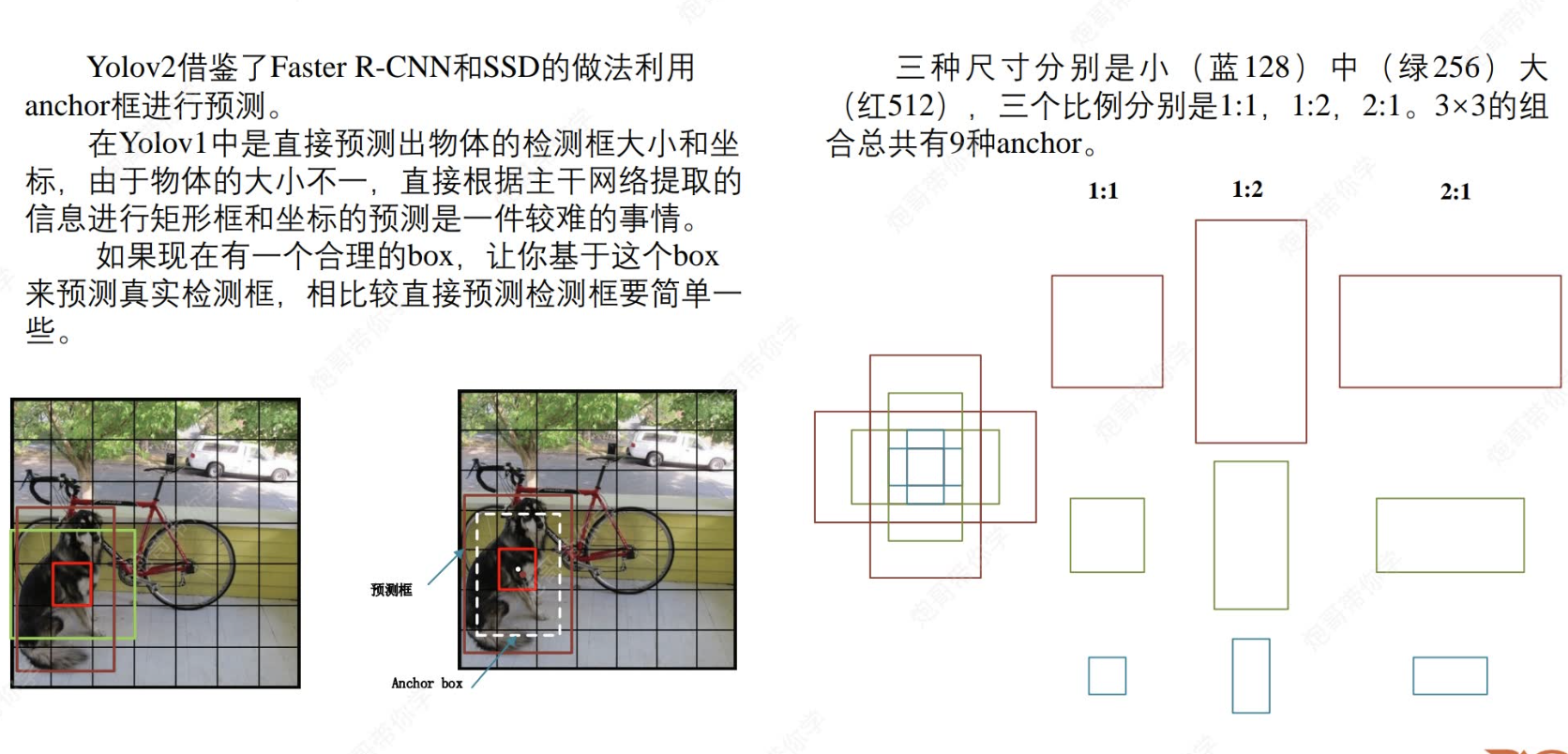
因此,基于convolutional+anchor,我們最后的輸出將變成13×13×125.其中125=(5(5個框)*25(每個框都有獨立的x,y,w,h,c+20個類別,且每個框都有anchor輔助)
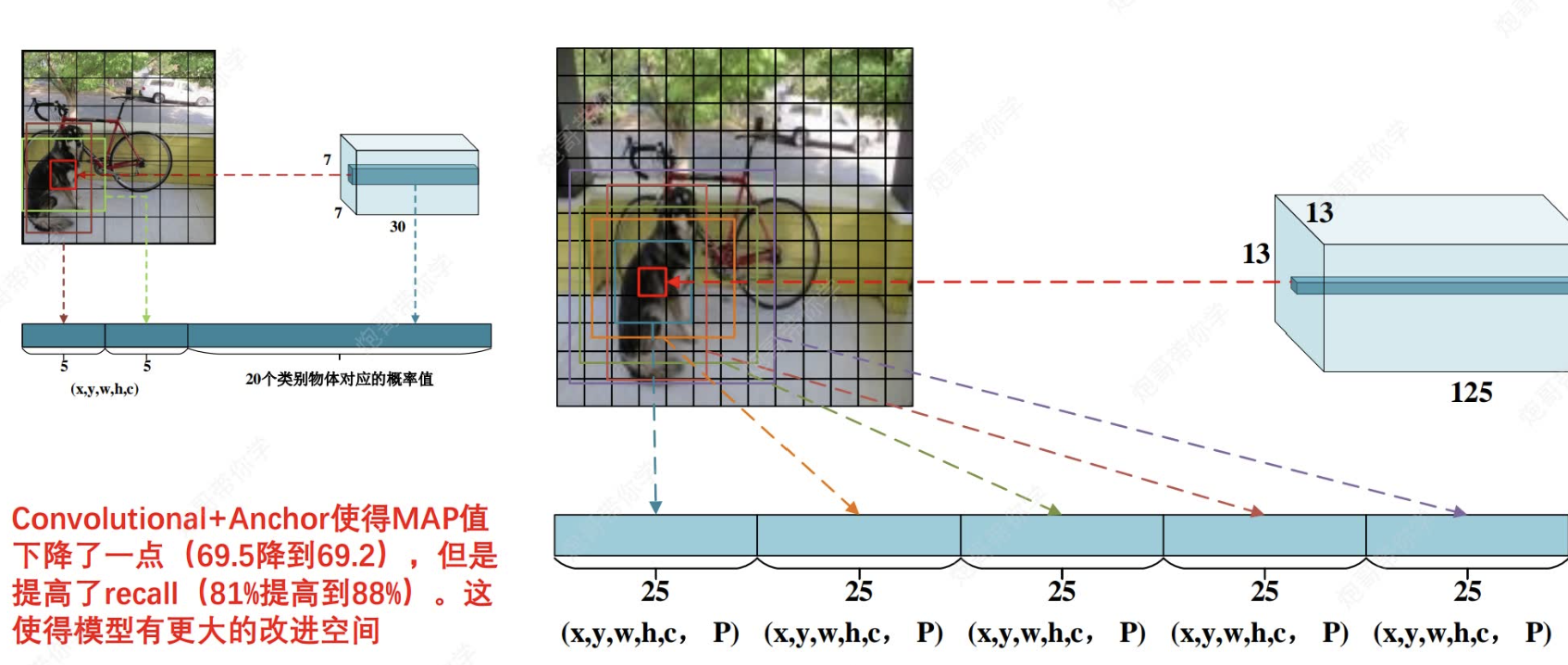 ?
?
同時,作者還采用聚類分析來自動設定anchor錨框,極大提高了準確性。
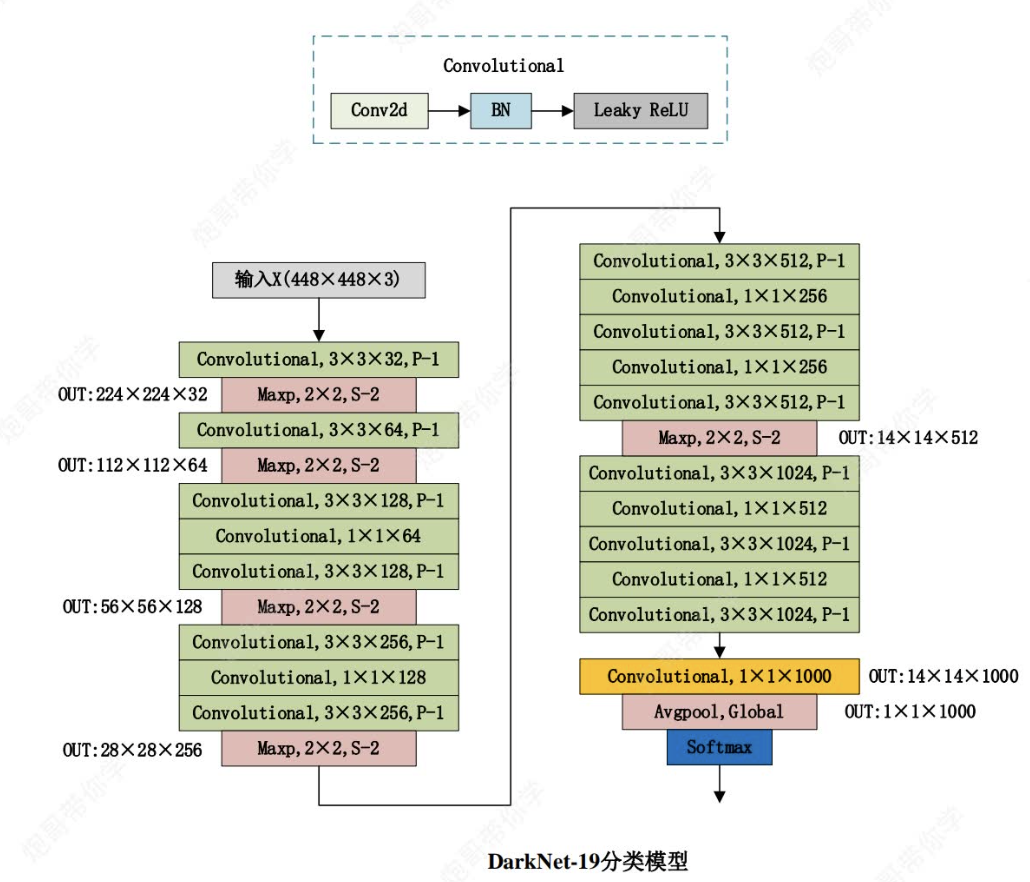
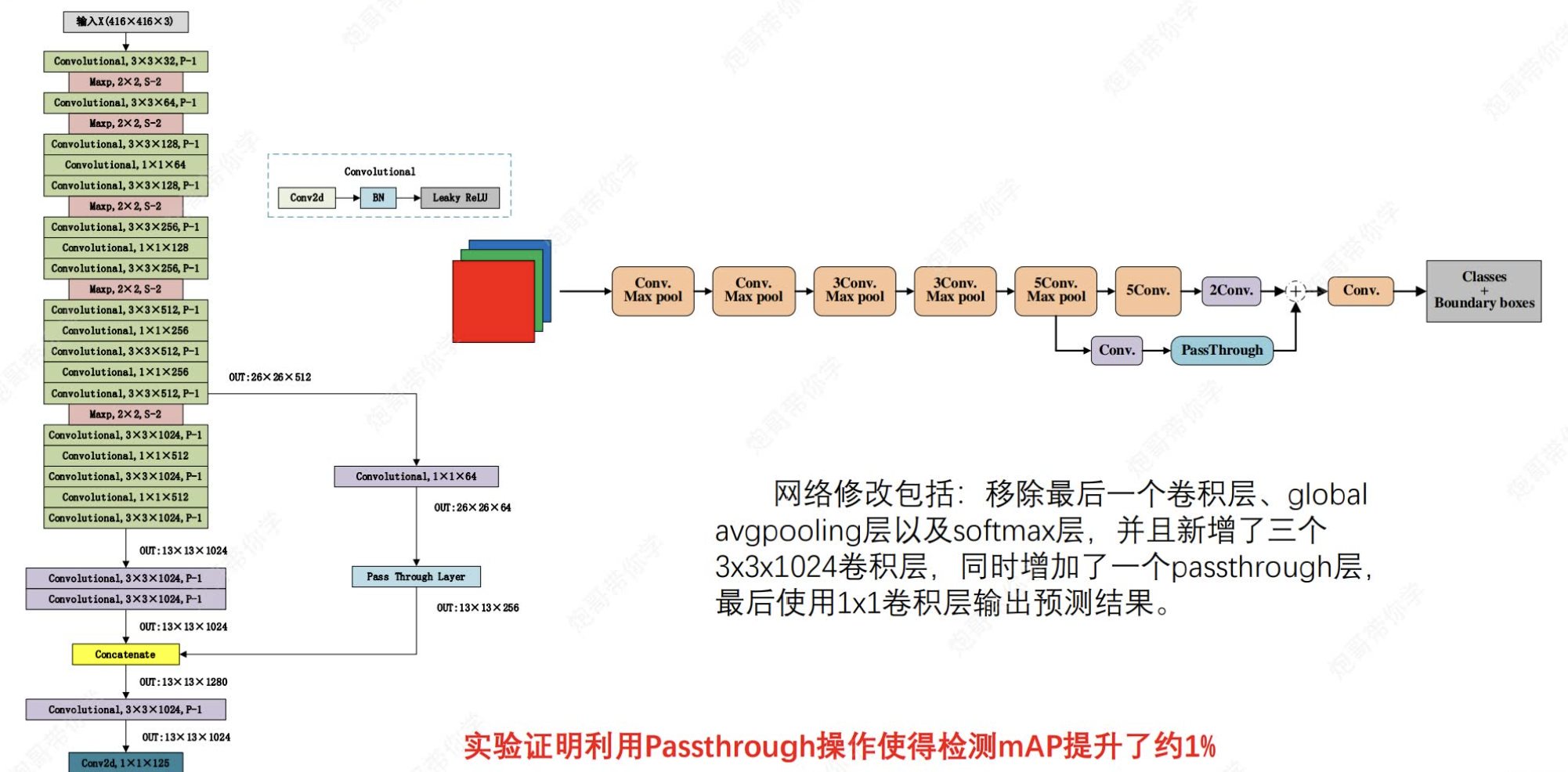
?2.3.2 引入了新的網絡架構Darknet-19
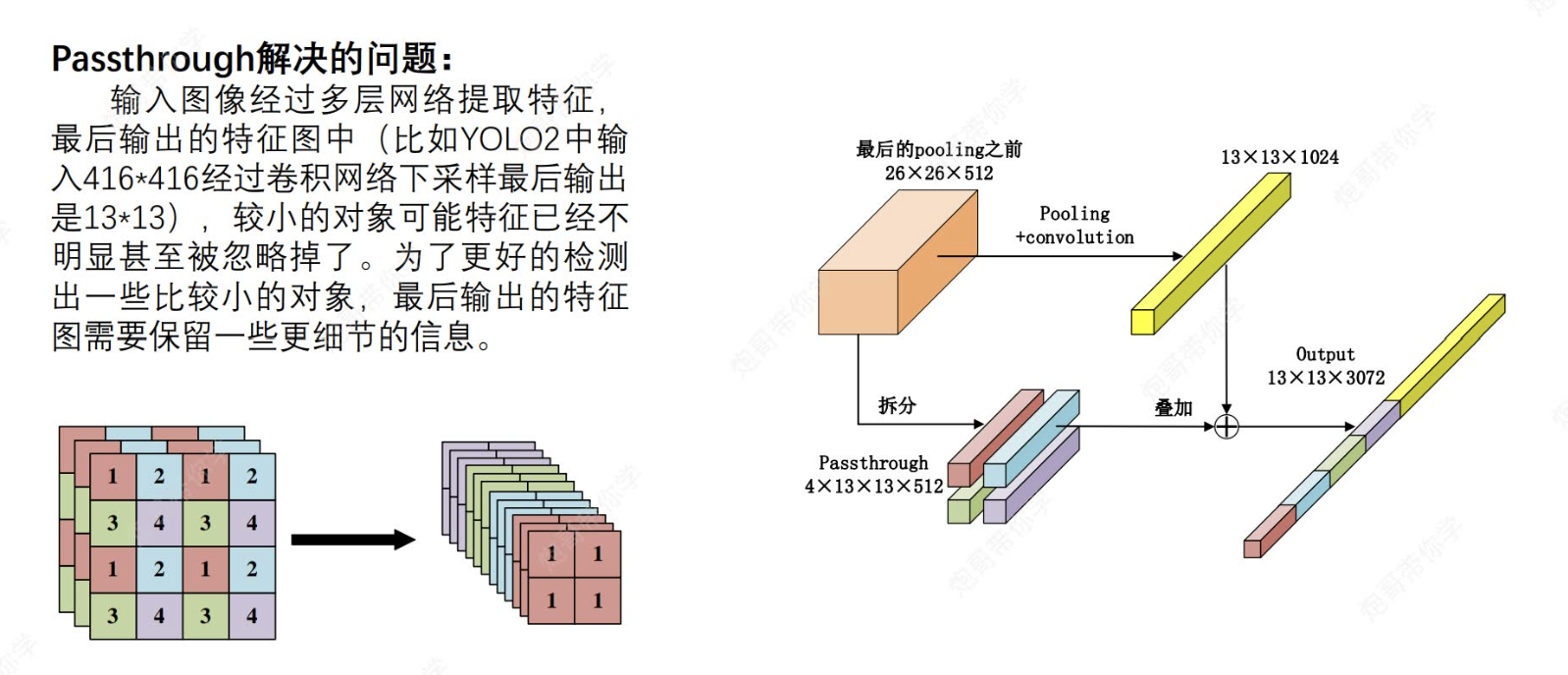
?2.4 采用了passthrough
這里就是說為了能夠保留細節信息,我們將某一階段卷積之后圖像先通過passthrough(也就是說如果最后輸出是13*13*m,那么我們就要將該圖像變換成13*13*4*n(n代表通道數,可以和m不一樣),然后將該圖像與最后輸出的特征圖進行contact操作,這樣最后輸出的圖像既有特征提取的,也保留了細節信息。
 ?
?
2.5 多尺度訓練?
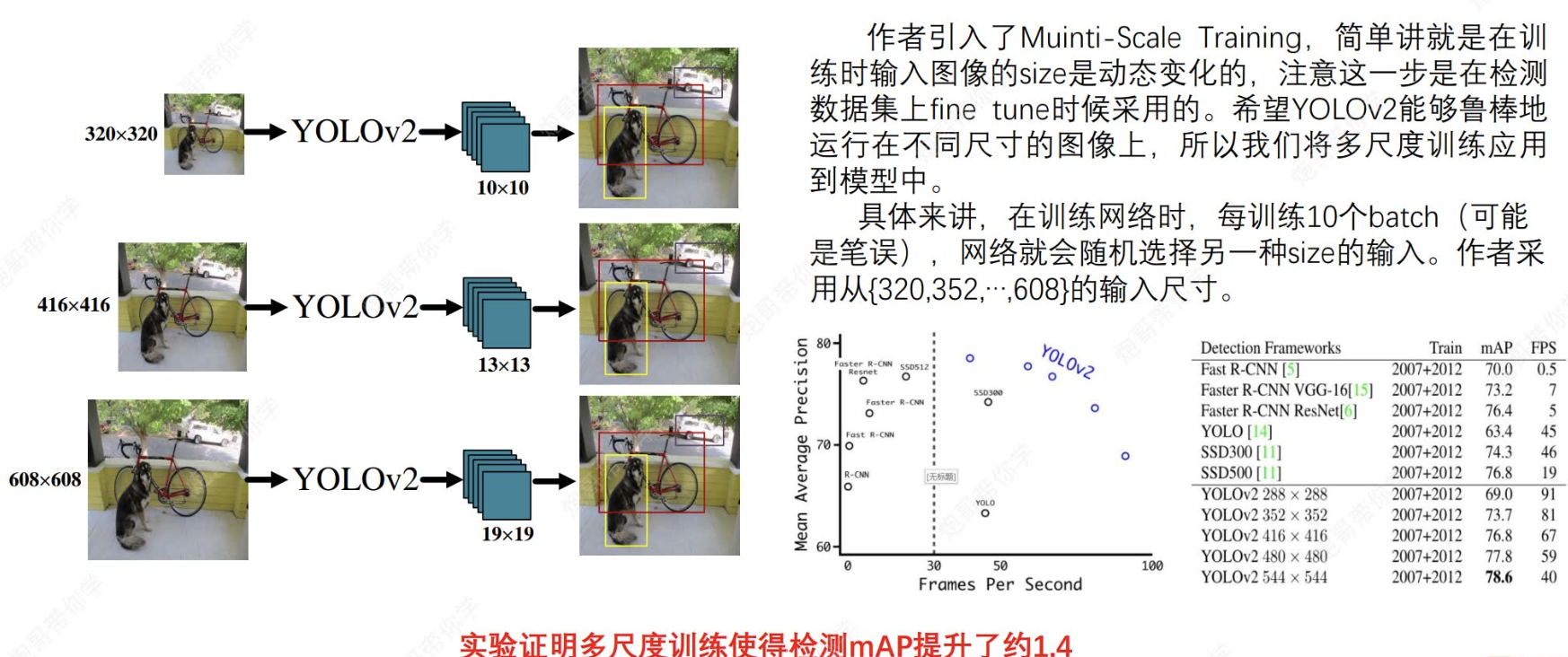
?ok,that's all。知識瘋狂涌進腦子,消化不過來了![]()







:Material Icons圖標的使用)








樹的實現)


