目錄
前言:
一、網絡傳輸基本流程
1.1、認識MAC地址
1.2、認識IP地址
二、socket編程預備?
2.1、端口號
2.2、傳輸層的代表
2.3、網絡字節序?
2.4、sockaddr 結構
總結:
前言:
大家好,上一篇文章,我們說到了協議。
我們說,協議,就是一種約定!!協議是分層的,本質原因是因為問題是分層的。
在代碼層面上,協議就是通信雙方都認識的數據結構。
那么我們今天繼續來學習網絡基礎的概念。
一、網絡傳輸基本流程
兩臺獨立的主機用一根網線連接起來,他們之間是否能相互通信?
是的。
幾個獨立的主機通過網線與交換機連接起來,就形成了局域網。
每臺主機在局域網上,要有唯一的標識來保證主機的唯一性:mac 地址。
1.1、認識MAC地址
MAC 地址是?網絡設備的物理硬件地址,用于在?局域網(LAN)?內唯一標識一臺設備(如電腦、手機、路由器等)。它工作在?OSI 模型的第 2 層(數據鏈路層),主要用于?以太網(Ethernet)、Wi-Fi(802.11)等本地網絡通信。
MAC地址是用來識別數據鏈路層中相連的節點,一般來說長度為48位,及6個字節。
一般用16進制數字加上冒號的形式來表示(例如:08:00:27:03:fb:19)
MAC地址在網卡出廠時就確定了(每個物理網卡在制造時會被分配一個唯一的 MAC 地址),不能進行修改,MAC地址通常是唯一的。
后面我們詳細談論數據鏈路層的時候,會談 mac 幀協議,此處我們做一個了解即可。
以以太網為例,在以太網中的任意時刻,都只允許一臺機器向網絡中發送數據。如果有多臺機器同時發送,就會發生數據干擾。我們稱之為:數據碰撞。
而所有發送數據的主機都需要進行碰撞檢測與碰撞避免。
所謂碰撞避免,就是發現此時有主機發送數據了,你就進行休眠,等一會再發送數據。
在沒有交換機的情況下,一個以太網就是一個碰撞域。
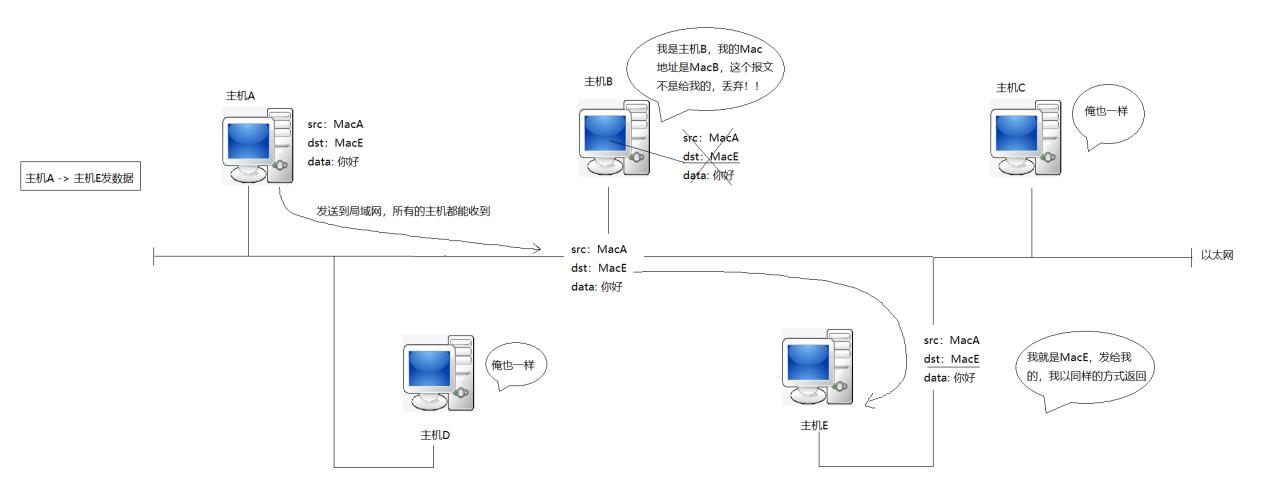
在我們的局域網通信的過程中,主機對收到的報文確認是否是發送給自己的,是由目標的MAC地址來判定的。
目標MAC地址一樣,就說明這個報文是發給自己的。
以太網就是一個臨界資源
主機abcd發送數據時執行的代碼是臨界區
我們采用碰撞避免碰撞檢測來保證臨界資源使用時數據的原子性
這個碰撞也是為什么人一多,我們的網就卡起來了,因為碰撞的次數增多了,休眠的時間就多了。
再來看同一個網段內的兩臺主機進行發送消息的過程:
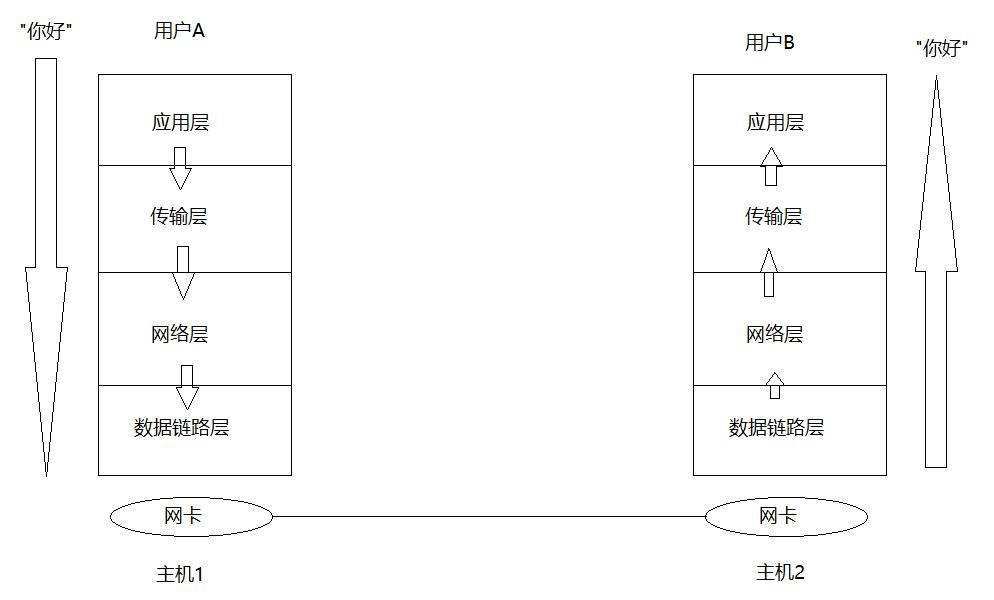
而其中每層都有協議,所以當我進行進行上述傳輸流程的時候,要進行封裝和解包。
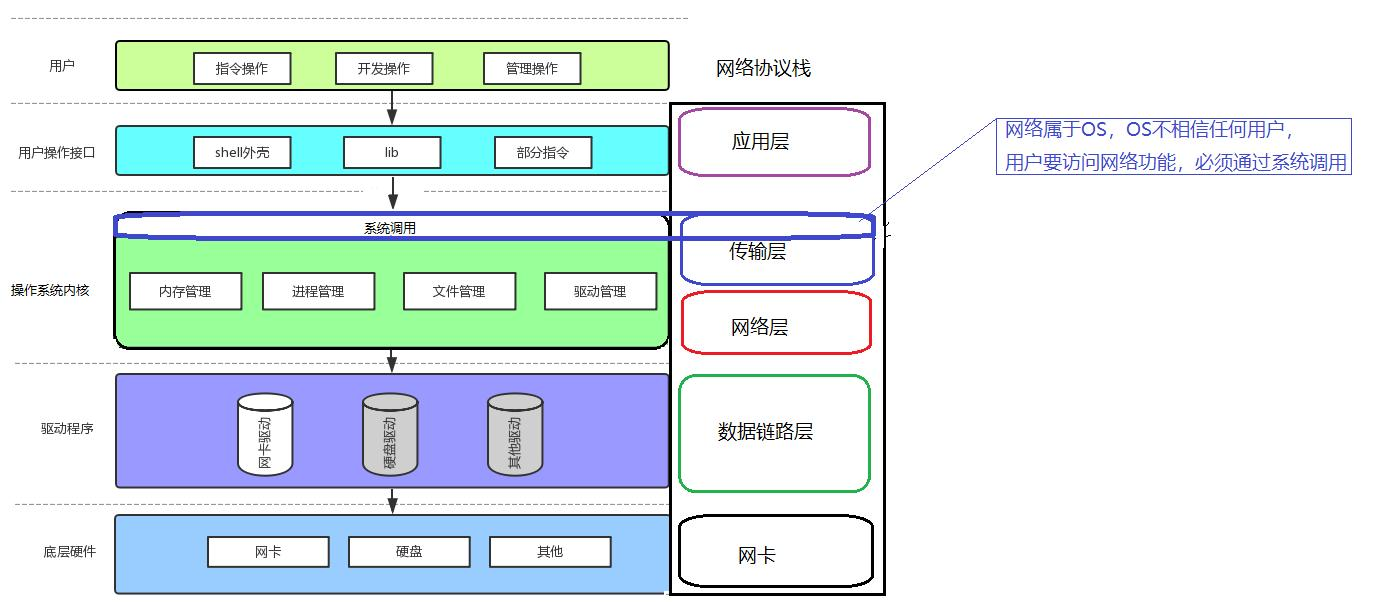
當應用程序發送網絡數據時,數據必須經過操作系統的網絡協議棧處理,最終由網卡(硬件)發送出去。這個過程是?“從上到下”?的,即:
-
應用層(用戶態) →
-
傳輸層(TCP/UDP)?→
-
網絡層(IP)?→
-
數據鏈路層(MAC/ARP)?→
-
物理層(網卡驅動)?→
-
網卡硬件(NIC)
為什么是這樣從上到下的貫穿?
這是因為網卡是硬件,管理工作由操作系統來進行,今天要訪問的網絡功能網絡層傳輸層是屬于內核的。
所以你發數據一定會使用系統調用,使用系統調用就一定會貫穿操作系統的,所以一定會走這條路?
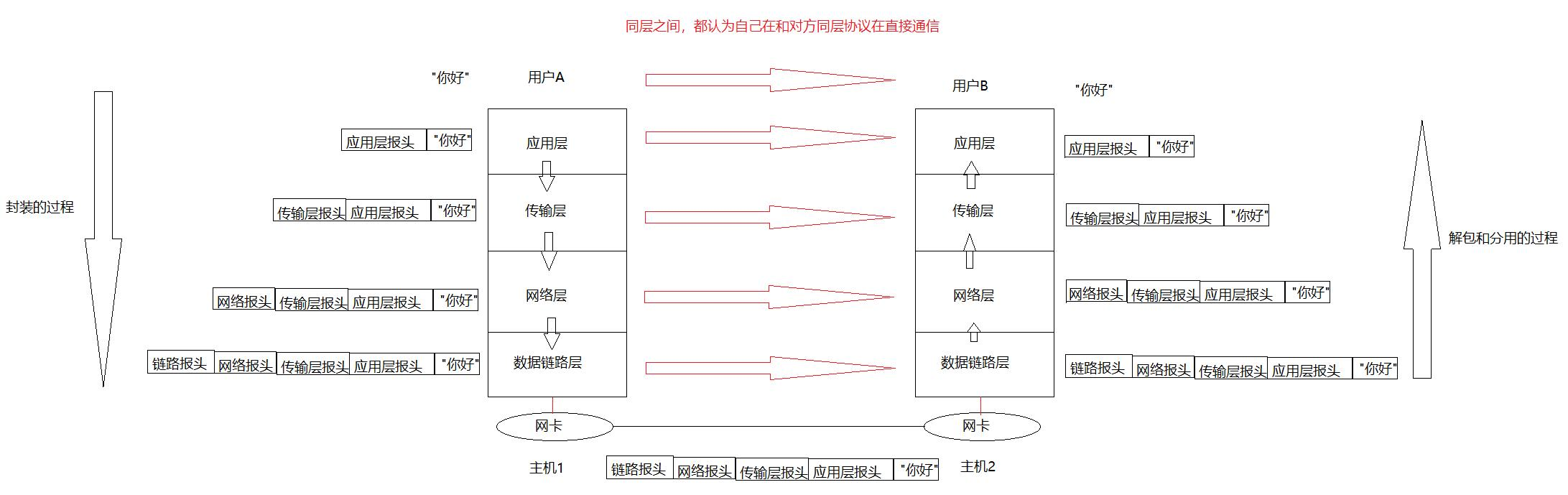
讓我們來解釋一下,為什么同層之間,都認為自己在和對方同層協議在直接通信。
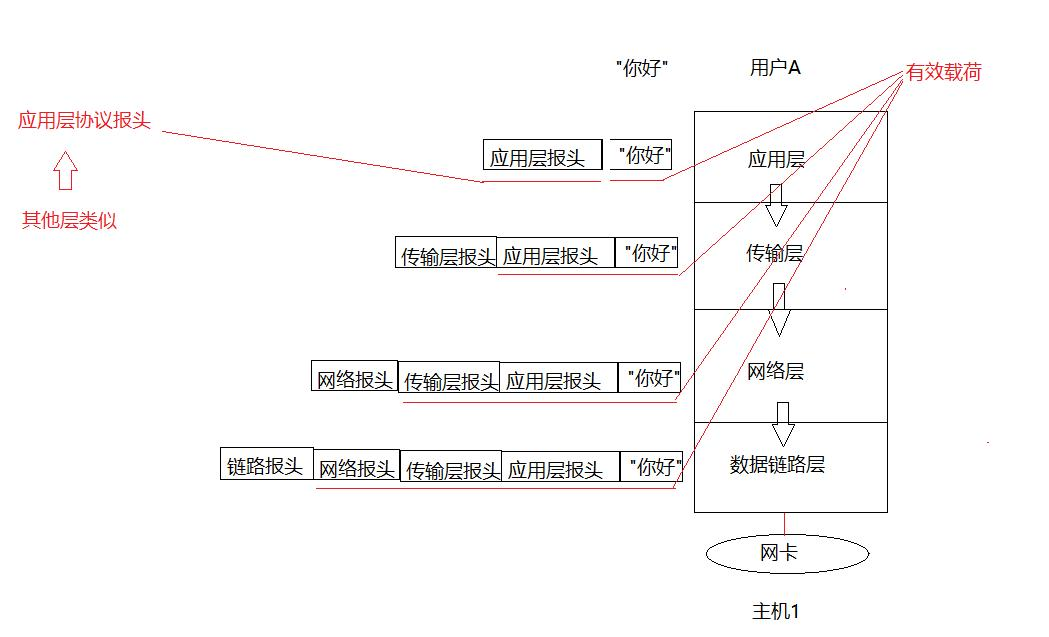
在我們用戶發送一個“你好”的信息后,用戶層會給這個信息添加一個用戶層的報頭。
報頭(Header)本質上是一種數據結構。它在計算機網絡中用于存儲協議控制信息,通常以固定或可變格式的二進制數據塊的形式存在,由協議規范明確定義其字段和排列方式。
以快遞為例,報頭類似于快遞單。
這個應用層匯報自己的報頭加有效載荷(這里是“你好”),傳遞給下一次傳輸層,由傳輸層再添加一個傳輸層報頭。隨后讓傳輸層報頭把自己的報頭加有效載荷(這里的有效載荷指的是應用層報頭+“你好”),傳遞給下一層網絡層。
一段報文,就等于自己的報頭+有效載荷。
不同的協議層對數據包有不同的稱謂,在傳輸層叫做段(segment),在網絡層叫做數據報 (datagram),在鏈路層叫做幀(frame)。
應用層數據通過協議棧發到網絡上時,每層協議都要加上一個數據首部(header),這個層層加封的過程,我們就稱為:封裝。
首部信息中包含了一些類似于首部有多長, 載荷(payload)有多長, 上層協議是什么等信息。
數據封裝成幀后發到傳輸介質上,到達目的主機后每層協議再剝掉相應的首部,根據首部中的 "上層協議字段" 將數據交給對應的上層協議處理。
這個把自己的報頭剝離,隨后把有效載荷傳遞給上層的過程,我們叫做解包。
在網絡傳輸的過程中,數據不是直接發送給對方主機的,而是先要自定向下將數據交付給下層協議,最后由底層發送,然后由對方主機的底層來進行接受,隨后再自底向上進行向上交付。
那么用戶b怎么知道網卡此時已經有數據了,要一步一步往上傳:硬件中斷!!!
在通信的雙方的同一層看來,報文都具有一樣的報頭,一樣的地址。所以就像同層之間都在和對方協議在直接通信一樣。
在Linux系統中,我們可以通過ifconfig命令來查看自己機器的MAC地址:
ether后面就是mac地址。
?在Windows上可以通過命令:ipconfig /all來看到自己的物理地址(即mac地址)。
1.2、認識IP地址
IP 協議有兩個版本, IPv4 和 IPv6。本文及后面的文章,如果沒有進行特殊說明,談到IP,都是指的是IPv4.
IP地址是在IP協議中,用來標識網絡中不同主機的地址。
對于IPv4來說,IP地址是一個4字節,32位的整數。
我們通常也用“點分十進制”的字符串來表示IP地址,這樣做的好處是可讀性高,例如:192.168.0.1;用點分隔的每一個數字表示一個字節,范圍是0-255。
跨網段的主機的數據傳輸. 數據從一臺計算機到另一臺計算機傳輸過程中要經過一個或多個路由器。
我們如何理解IP地址呢?
我們從一臺主機跨網段向另外一臺主機發送信息,就跟你人生的發展階段一樣。
我們的出生的嬰兒就是源IP地址,我們的死亡的時候的老人就是目標IP地址。
在我們從嬰兒到死老人的過程中,不是一蹴而就的,而是劃分了許多個階段。我們從嬰兒會長到小孩,又會從小孩長到青少年,最后是青年,壯年,中年,中老年,老年。
IP地址就像人生的起點與終點——從出生的嬰兒(源IP)到離世的老人(目標IP),代表通信雙方永恒不變的身份標識。
而MAC地址則是人生每個階段的臨時身份,隨著成長不斷變化。
就像從嬰兒到老人需要經歷童年、青年、中年等階段,數據包跨越不同網絡時,它的源MAC和目標MAC會在每一跳動態更新(如從家庭路由器到運營商網關,再到目標服務器),但IP地址始終如一。
這正體現了:IP負責全局尋址(人生方向),MAC負責局部傳輸(階段性的腳步)。
也許這里你還不能對IP地址有一個深刻的理解。沒關系,我們先繼續往下面看。
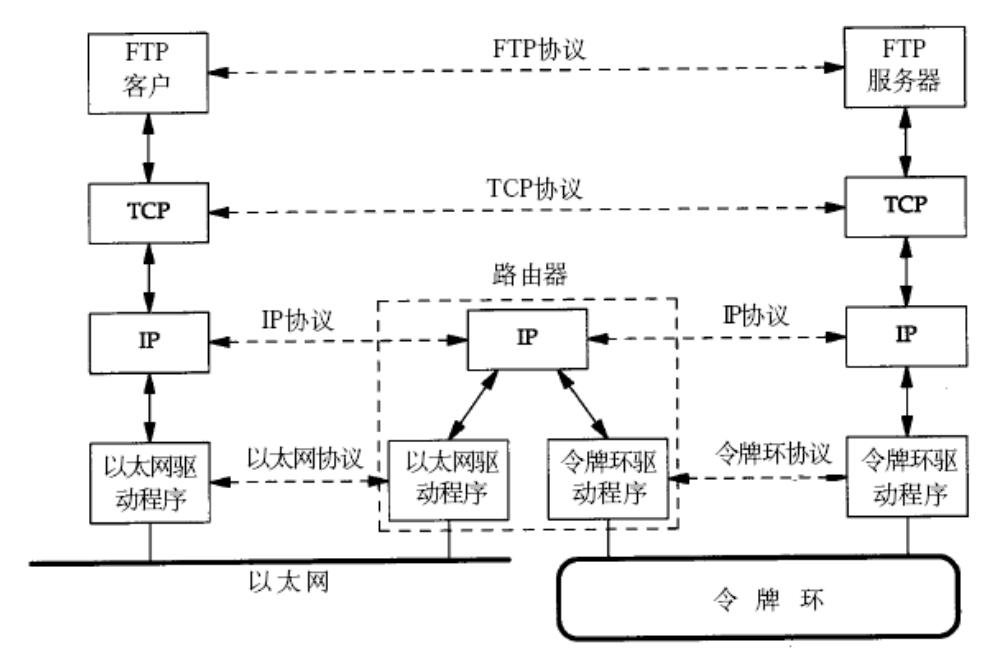
這張圖的通信雙方并不處于同一個局域網中,甚至于二者的局域網類型都不一樣。
他們之間如何進行通信呢?
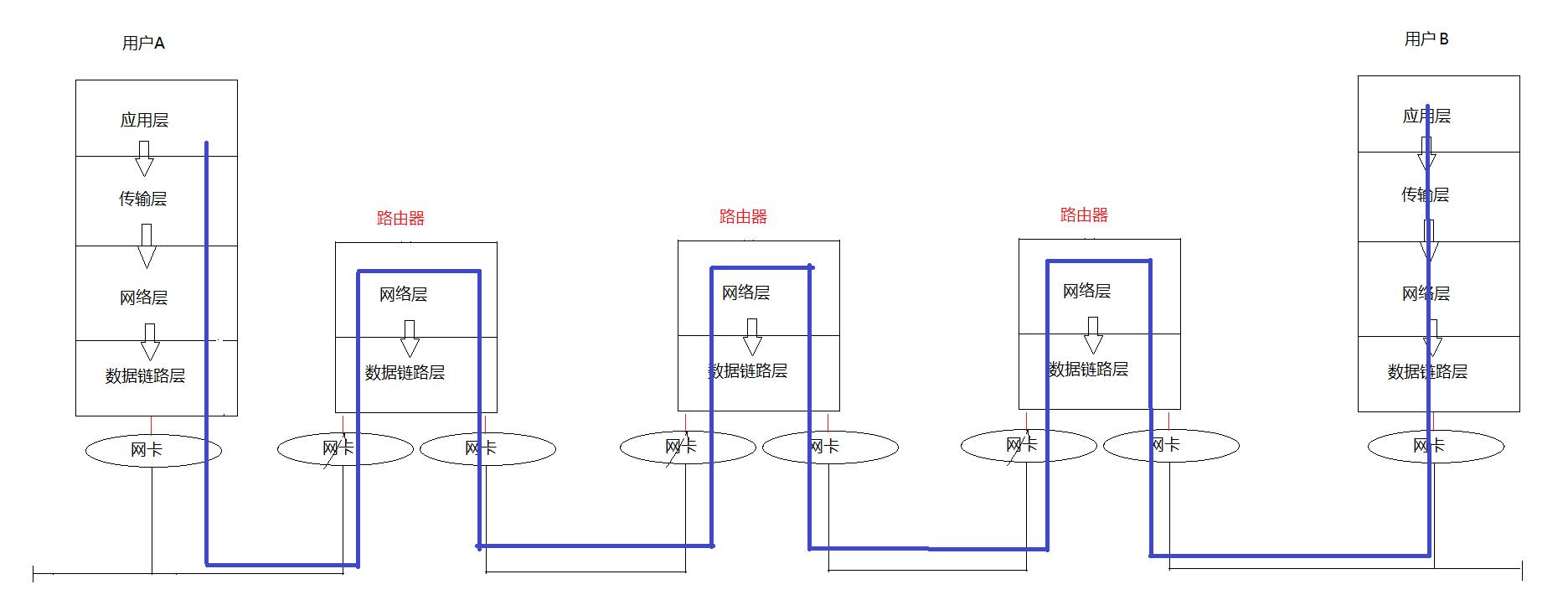
這就要通過我們的路由器了,所謂路由,就是進行路徑的選擇。
左側的FTP客戶,通過我們說的封裝過程,將IP層的IP報文封裝成以太網幀,添加源MAC(客戶端網卡)和目標MAC(默認網關,如路由器)。
這樣就將信息傳給了路由器,隨后路由器的以太網接口收到幀,校驗MAC地址(目標MAC是否匹配自身接口)。剝離以太網頭,解析IP包,查詢路由表決定下一跳去向哪里。
由于另外一側是令牌網,路由器就重新封裝IP包為令牌環幀(格式與以太網不同,如使用令牌控制訪問)。隨后更新源MAC(路由器令牌環接口MAC)和目標MAC(下一跳設備MAC)。
若目標服務器在令牌環網中,服務器網卡就接收令牌環幀,校驗MAC是否正確后剝離幀頭,將IP包上傳至內核協議棧。IP層檢查目標IP是否為本機,TCP層按端口號交付給FTP服務進程。
( 路由器通過多個接口連接不同子網,每個接口的IP充當該子網的網關。網關是路由器接口的IP地址,主機需配置網關才能訪問外部子網。)
抽象點的圖看看:
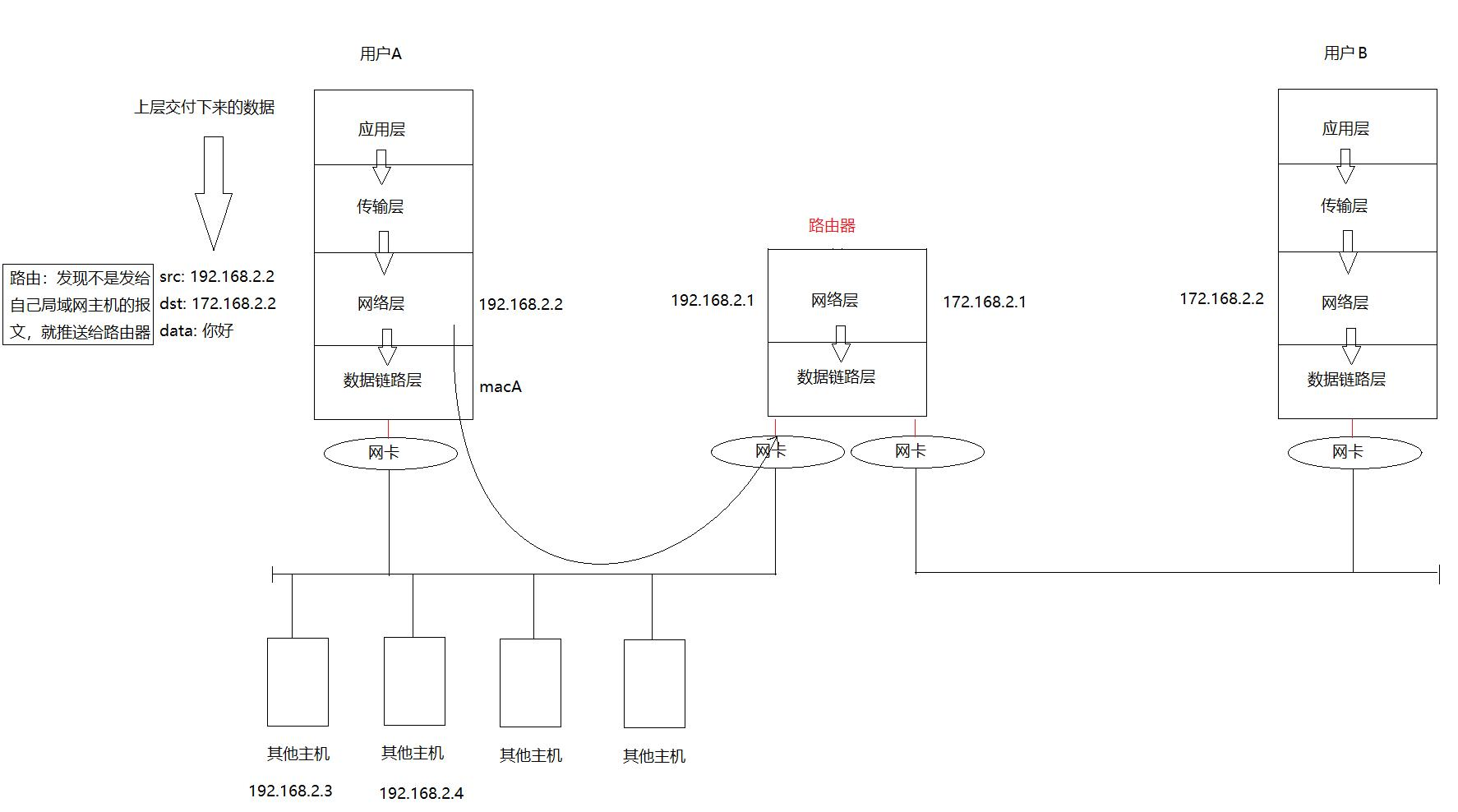
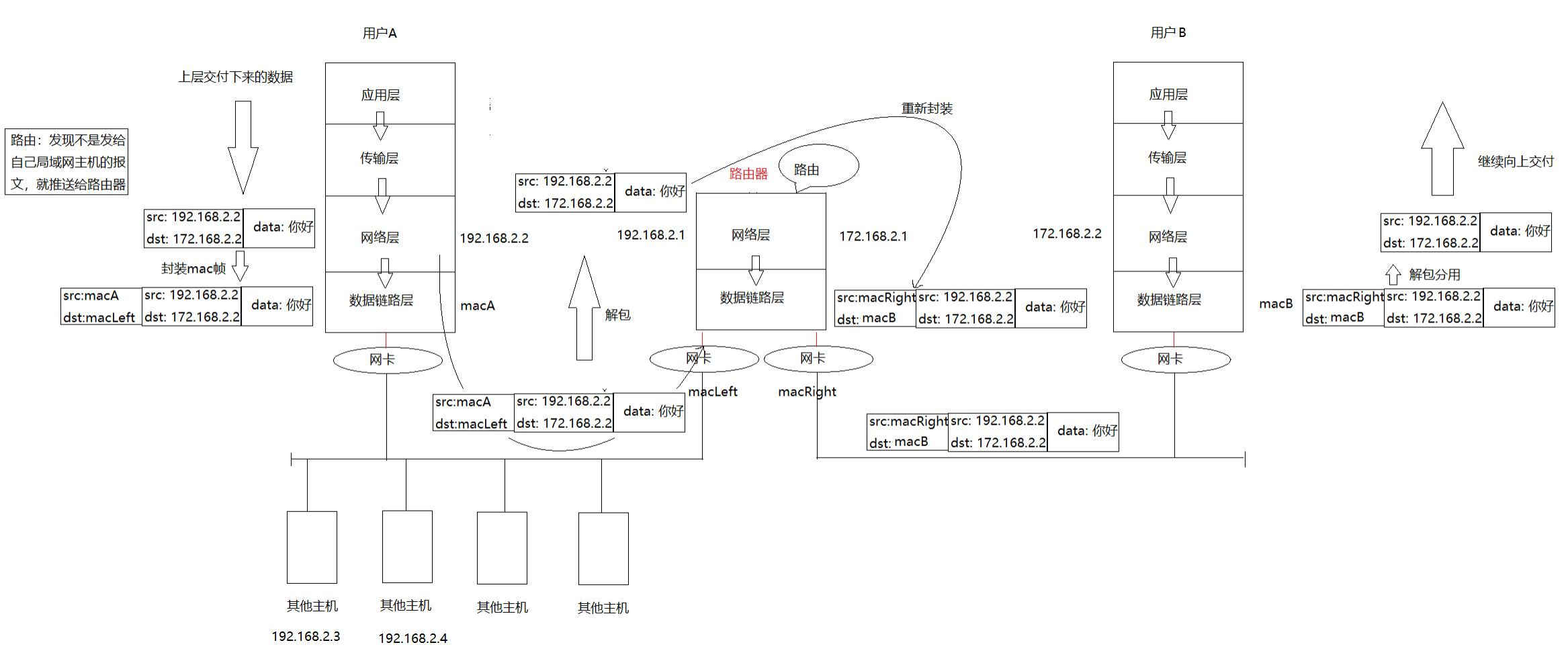
這個過程更詳細的來說,就是封裝到了網絡層,此時進行IP的封裝,確定好目標的IP地址與源IP地址,發現此時的IP地址前面的跟我們的局域網的IP地址不一樣(一般來說同一個局域網中的IP地址,點分十進制的話,前面三個數都是一樣的,所以我們就能判斷是否目標地址與我在同一個局域網,如果不是,就將目標MAC設為默認網關(路由器)的地址),隨后傳遞給鏈路層,進行mac地址的封裝。
封裝好之后,就要開始傳遞信息了。
在以太網中(以太網是一個局域網)有另外的其他許多主機,但是他們的mac地址都匹配不上,最后我們就匹配上了路由器的對應以太網接口的mac地址。
此時路由器的網卡收到了消息,開始網上解包,到了網絡層解包出了源IP地址與目標IP地址,查詢
路由表:若目標IP在直連網絡中,就重新封裝幀(更新源/目標MAC)并從對應接口轉發;否則交給下一跳路由器。
找到目標局域網后,這個路由器此時就繼續往下封裝成mac幀,由負責該局域網的網卡發出信
息,在這個局域網下的主機都會收到消息。
隨后通過目標mac地址是否匹配來判斷是否接收。
最后目標主機就匹配成功了,隨后逐漸網上解包,把消息給了用戶。
IP 網絡層存在的意義:提供網絡虛擬層,讓世界的所有網絡都是 IP 網絡,屏蔽最底層網絡的差異
最初通信依賴MAC地址,但MAC只能在局域網生效,且無法分層管理。IP層的引入屏蔽了底層網絡差異(如以太網、Wi-Fi、光纖),通過邏輯化的IP地址實現全球路由,讓不同技術的網絡能無縫互聯。
二、socket編程預備?
IP在網絡中,用來標識一個主機的唯一性。
但是這里我們要思考一個問題:數據傳輸到主機是目的嗎?
不是的!!因為數據是給人使用的。比如:聊天是人在聊天,下載是人在下載,瀏覽網頁是人在瀏覽。
但是人怎么看到聊天記錄的呢?怎么執行下載?瀏覽任務的呢?
是通過啟動的qq微信,網盤,瀏覽器。
而啟動的這些都是進程。換句話說,進程是人在系統中的代表,只要把數據傳給進程,就相當于人拿到了數據。
所以,數據傳輸到主機不是目的,而是手段。到達主機內部后,交給主機里的進程,才是目的。
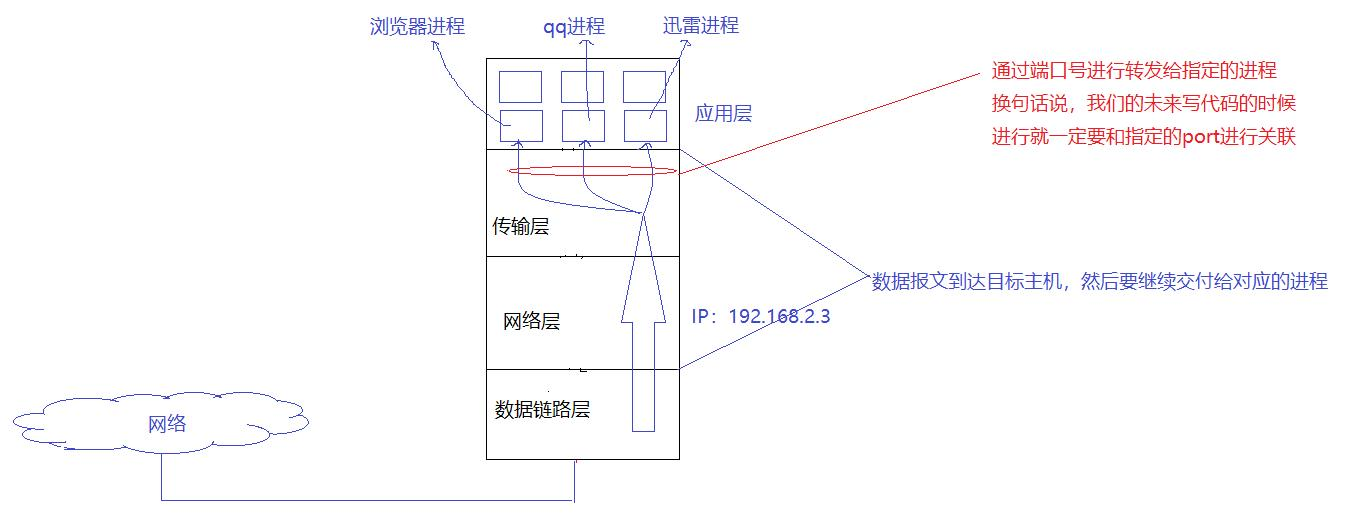
但是系統中,同時會存在許多個進程,當數據到達主機之后,怎么轉發給目標進程?
如何把數據交付給進程?這就依賴于傳輸層的兩大協議:TCP與UDP,以及它們的“地址簿”——端口號(Port)。
2.1、端口號
端口號(port)是傳輸層協議的內容,通常是一個2字節十六位的整數。
端口號用來標識一個進程,告訴操作系統,當前的這個數據要交給哪一個進程來處理。
所以我們的IP地址+端口好能夠表示網絡的某一臺主機的某一個進程。
而一個進程可以占用多個端口號,可是一個端口號只能被一個進程占用。
0 - 1023: 知名端口號, HTTP, FTP, SSH 等這些廣為使用的應用層協議, 他們的端口號都是固定的.
而1024 - 65535: 操作系統動態分配的端口號. 客戶端程序的端口號, 就是由操作系統從這個范圍分配的。
我們之前在學習系統編程的時候, 學習了 pid 表示唯一一個進程; 此處我們的端口號也是唯一表示一個進程. 那么這兩者之間是怎樣的關系?
我們可以用“10086客服熱線”來進行類比
-
PID:相當于客服工號(如“工號1024”),用于內部管理,客戶無需知道。
-
端口號:相當于客服熱線號碼(如“10086”),客戶通過撥打號碼找到服務。
-
進程 ID 屬于系統概念,技術上也具有唯一性,確實可以用來標識唯一的一個進程,但是這樣做,會讓系統進程管理和網絡強耦合,實際設計的時候,并沒有選擇這樣做。
IP 地址用來標識互聯網中唯一的一臺主機,port 用來標識該主機上唯一的一個網絡進程
IP+Port 就能表示互聯網中唯一的一個進程
所以,通信的時候,本質是兩個互聯網進程代表人來進行通信,{srcIp,srcPort,dstIp,dstPort}這樣的 4 元組就能標識互聯網中唯二的兩個進程
所以,網絡通信的本質,也是進程間通信
這兩個進程具有十足的獨立性,運行在不同的主機上,但是他們之間也存在共享的資源:網絡!!兩個進程間通過共享的“網絡”這一公共資源交換數據。
另外,一個主機不斷從外部獲取數據到內核緩沖區,進程不斷的從內核緩沖區讀取數據。這不就是消費者生產者模型嗎?
我們把 ip+port 叫做套接字 socket。
2.2、傳輸層的代表
如果我們了解了系統,也了解了網絡協議棧,我們就會清楚,傳輸層是屬于內核的,那么我們要通過網絡協議棧進行通信,必定調用的是傳輸層提供的系統調用,來進行的網絡通信。
傳輸層主要有兩種核心協議:TCP(傳輸控制協議)?和?UDP(用戶數據報協議)。它們為應用層提供不同的數據傳輸服務,是互聯網通信的基礎。?
我們現在先來簡單的了解一下這兩種協議。
TCP(Transmission Control Protocol)是一種面向連接的、可靠的傳輸層協議,它為應用程序提供有序、無差錯的數據流傳輸服務。
主要特點就是以下四個:
傳輸層協議
有連接
可靠傳輸
面向字節流
我們只需要知道就行了,后面會詳細解釋。
UDP(User Datagram Protocol)是一種無連接的、不可靠的傳輸層協議,專注于低延遲和簡單性。
傳輸層協議
無連接
不可靠傳輸
面向數據報
這里的面向字節流與面向數據報我們簡單的說一下,面向字節流就是我們讀寫文件那樣的,數據像“水流”一樣無邊界連續傳輸,發送方寫入的字節數和接收方讀取的字節數無需一一對應。就是我們寫入的時候是十個字節的寫入的,讀取的時候不要求以十字節的方式讀出來。
而面向數據報是什么?就是你一次發送信息,就得對應一次接收一次。數據以獨立報文為單位傳輸,且報文長度固定,不會拆分或合并。
2.3、網絡字節序?
我們已經知道,內存中的多字節數據相對于內存地址有大端和小端之分, 磁盤文件中的多字節數據相對于文件中的偏移地址也有大端小端之分, 網絡數據流同樣有大端小端之分. 那么如何定義網絡數據流的地址呢?
發送主機通常將發送緩沖區中的數據按照內存地址從低到高的順序發出。接收主機把從網絡上接
到的字節依次保存到接收緩沖區中,也是按照內存地址從低到高的順序保存。
因此,網絡數據流的地址應該這樣規定:先發出的數據是低地址,后發出的數據是高地址。
所以TCP/IP協議規定,網絡數據流應采用大端字節序,即低地址高字節。
不管這臺主機是大端機還是小端機,都會按照這個協議規定的網絡字節序來發送和接收數據。如果當前發送主機是小段,就需要先把數據轉化成大端。
為使網絡程序具有可移植性,使同樣的 C 代碼在大端和小端計算機上編譯后都能正常運行,可以調用以下庫函數做網絡字節序和主機字節序的轉換。

這些函數名很好記,h 表示 host,n 表示 network,l 表示 32 位長整數,s 表示 16 位短整數。
例如 htonl 表示將 32 位的長整數從主機字節序轉換為網絡字節序,例如將 IP 地址轉換后準備發送。
如果主機是小端字節序,這些函數將參數做相應的大小端轉換然后返回; 如果主機是大端字節序,這些函數不做轉換,將參數原封不動地返回。
2.4、sockaddr 結構
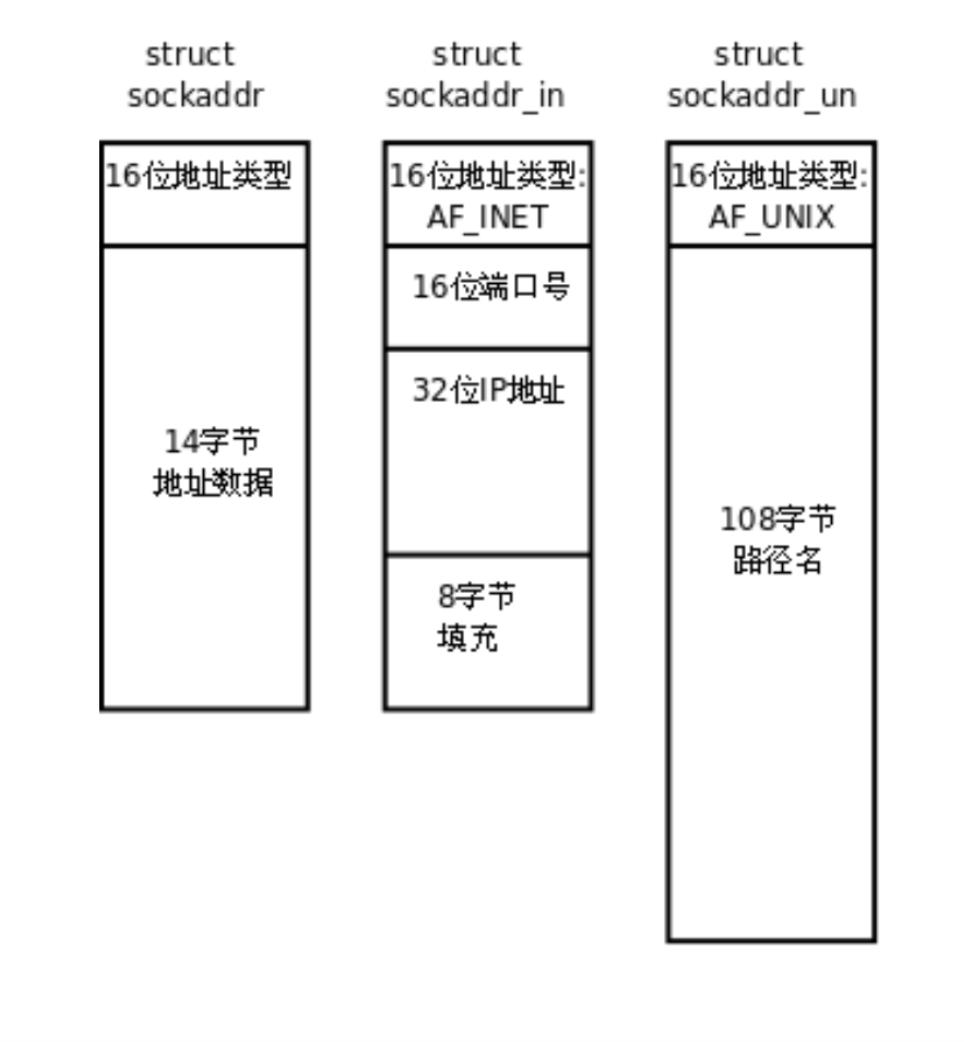
socket API 是一層抽象的網絡編程接口,適用于各種底層網絡協議,如 IPv4、IPv6,以及后面要講的 UNIX Domain Socket. 然而, 各種網絡協議的地址格式并不相同。
IPv4 和 IPv6 的地址格式定義在 netinet/in.h 中,IPv4 地址用 sockaddr_in 結構體表示,包括 16 位地址類型, 16 位端口號和 32 位 IP 地址.
IPv4、IPv6 地址類型分別定義為常數 AF_INET、AF_INET6. 這樣,只要取得某種 sockaddr 結構體的首地址,不需要知道具體是哪種類型的 sockaddr 結構體,就可以根據地址類型字段確定結構體中的內容
這樣有什么好處呢?
大家想一下,我們在使用socket的常見接口時,只需要把對應的結構體指針類型強制轉化為const struct sockaddr *,這樣我們不就能統一接口了嗎?
所以就降低了耦合性,提升代碼的通用性和可擴展性,無需為每種協議重復實現。
socket 常見 API接口:
// 創建 socket 文件描述符 (TCP/UDP, 客戶端 + 服務器)
int socket(int domain, int type, int protocol);// 綁定端口號 (TCP/UDP, 服務器)
int bind(int socket, const struct sockaddr *address,socklen_t address_len);// 開始監聽 socket (TCP, 服務器)
int listen(int socket, int backlog);// 接收請求 (TCP, 服務器)
int accept(int socket, struct sockaddr* address,socklen_t* address_len);// 建立連接 (TCP, 客戶端)
int connect(int sockfd, const struct sockaddr *addr,socklen_t addrlen);
這也就是為什么這些接口里的相關參數結構體指針類型都是const struct sockaddr *的原因。
轉化后,根據我們之前定義的常數 AF_INET、AF_INET6(因為這兩個結構體前16位被定義了常數,我們就可以通過if等判斷出來原來是什么結構體)
這其實也是C語言實現多態的一種用法。
總結:
我們的網絡基礎概念就先講到這里。
后面我們會繼續深化學習,更加深刻的理解網絡。




)










中取得成功)
商品管理)




