通俗說法:在多模態自監督學習中,將共享信息和獨有信息分離開來
Abstract
問題: 傳統方法通常假設在訓練和推理階段都可以訪問所有模態信息,這在實際應用中面對模態不完整輸入時會導致性能顯著下降。
解決方法:提出了一種面向遙感數據融合和多模態Transformer的全新不完整多模態學習方法,有監督自監督訓練都適用
方法簡述: 利用多模態Transformer ,結合模態注意力,掩碼自注意力機制,整合額外學習得到的token
方法結合重構損失與對比損失
Introduction
傳統方法: 為了融合不同模態的互補信息,依賴于基于特定領域知識的人為設計特征和融合策略;
基于CNN的深度方法通常假設所有模態在訓練與推理階段都是完整可用的,這在實際應用中卻是一個限制因素,因為數據采集過程中可能存在部分模態缺失。
不完整模態學習: 對缺失模態用生成模型,或者知識蒸餾(幻覺網絡)盡管有一定的效果,但是需要為每一類模態分別部署和訓練一個模型。
目標:一些新方法致力于訓練一個統一模型來應對下游任務中的不完整模態問題,在這種背景下,實現模態不變(modality-invariant)的融合嵌入表示成為提高魯棒性的重要手段,尤其適用于部分模態缺失的情況。
近年來沒有同時滿足自監督和允許不完整模態輸入
why 自監督:有監督訓練泛化能力差,訓練大規模數據集成本高
why 不完整模態輸入:實際應用場景存在不完整模態
方法簡述
貢獻:1.提出在多模態Transformer中引入模態注意力與掩碼自注意力機制,用于構建跨模態的融合token,以實現適用于不完整模態輸入的對比與重構預訓練。
2.在下游任務中,我們基于上述機制提出了隨機模態組合訓練策略,確保模型在推理階段面對模態缺失時依然具備強性能。
3.再公開的DFC2023 Track2數據集,和自己構建的四模態數據集,與標準多模態Transformer 對比取得了當前最優性能
Conclusion
本問提出了一種適用于多模態遙感數據融合任務的不完整模態學習框架,支持有監督和自監督,我們的方法支持模態不完整的條件下進行模型的訓練和推理。
通過引入模態注意力機制與掩碼自注意力機制,我們能夠在 MultiMAE 框架中利用對比損失與重構損失對網絡進行預訓練,同時也可以通過隨機模態組合訓練策略,從零開始訓練或在下游任務中對模型進行微調。該策略使網絡在推理階段即便僅接收到部分模態甚至單一模態輸入時,也能保持較高的性能。
(通過倆注意力機制,用倆損失函數,和一個隨機組合模態的訓練策略訓練)
RELATED WORKS
多模態遙感數據融合
多模態掩碼自動編碼器(MultiMAE)
與依賴對比目標的自監督方法不同,MultiMAE 使用一種預訓練任務:對每個輸入模態的掩碼圖像塊進行重建。
多模態Transformer
METHODOLOGY
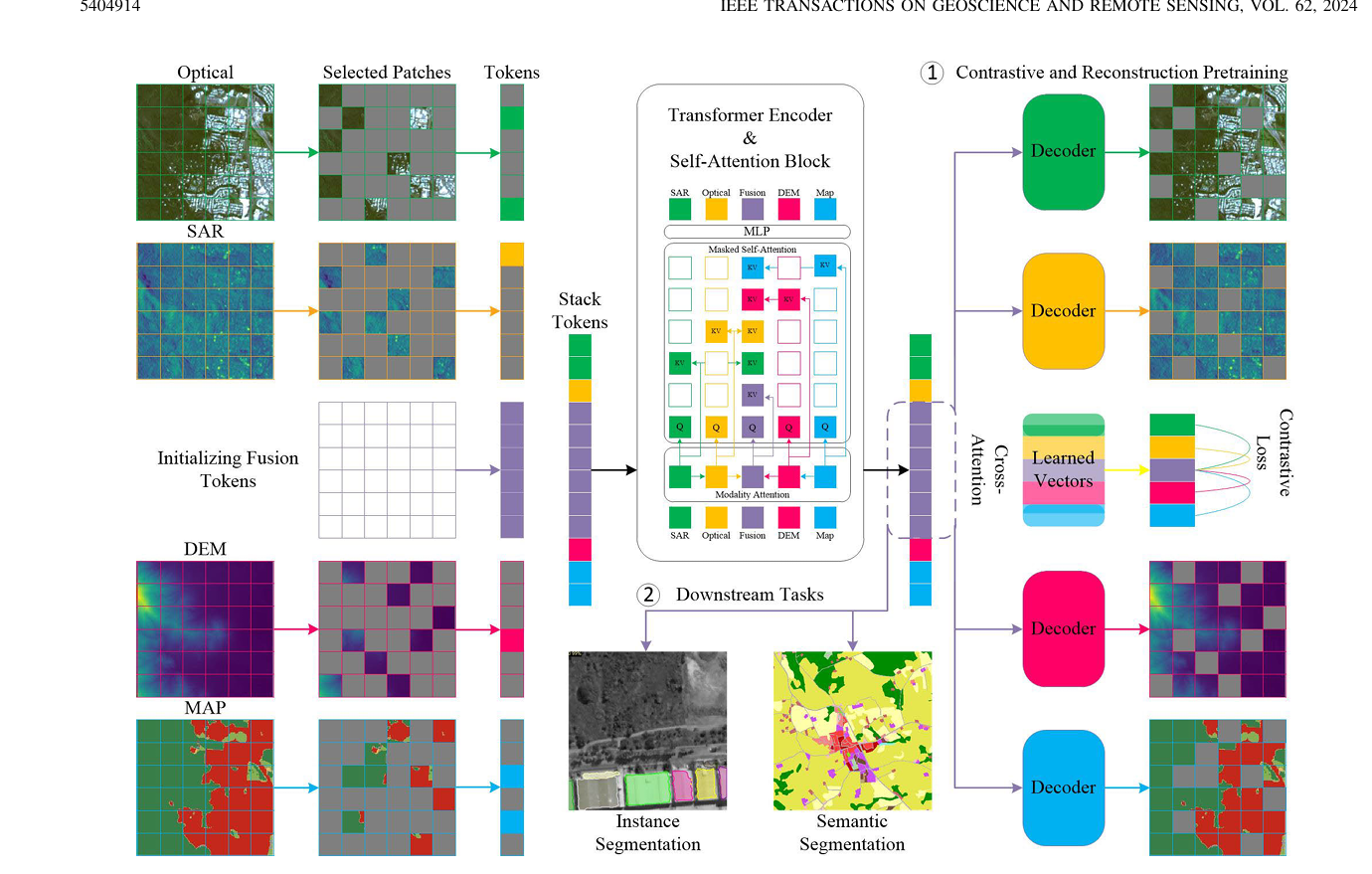
A 網絡架構
主體架構采用VIT ,對每個模態劃分16*16patch 進入線性層映射為D維,加入位置嵌入,引入融合token
與瓶頸融合token 不同,采用的是空間融合token,數量與patch一樣,然后模態自注意力機制把不同模態的信息融合到token,然后拼接送入Transformer 編碼器,使用掩碼自注意力機制
B 模態注意力

融合token :可學習參數,作為Query 在四種模態中學習怎么融合,整合信息。
C 掩碼自注意力機制
目的是讓每個模態輸出自己純凈的信息,讓融合的模態輸出的是融合的信息,需要通過掩碼來實現

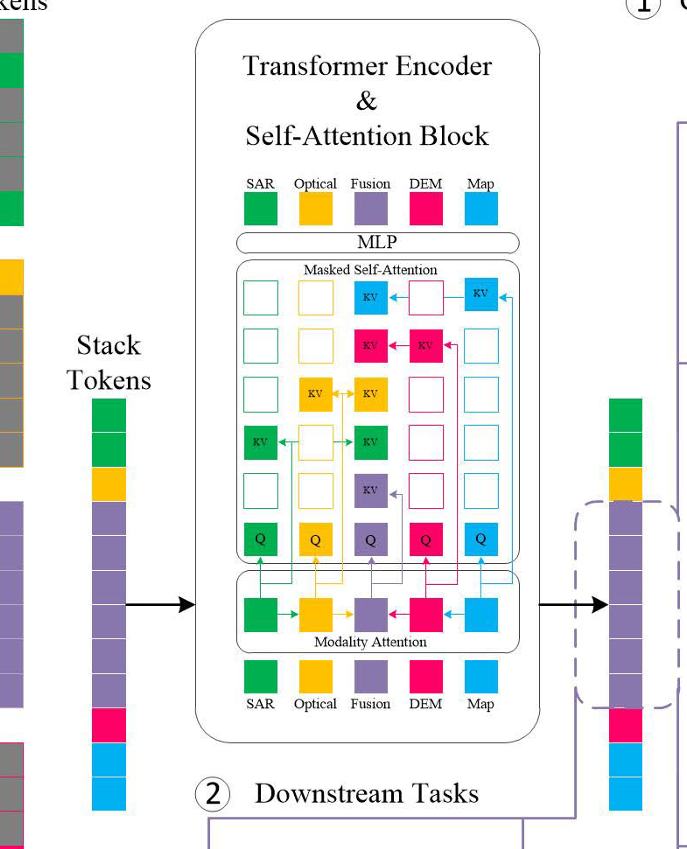
左側是融合后的token ,重建成5*5的權限矩陣,每個模態只能與自己做SA ,而融合模態要與其他四個做CA
是要設計權限矩陣也就是圖中的m,為每個模態計算時只關注每個模態純凈的信息。
D 重構預訓練
用融合后的token 去做生成與原圖計算損失,并應用于下游任務
使用淺解碼器是為了避免decoder過強而抹殺encoder 的學習
理解Transformer :最后算完的token 怎么用?當作庫,利用Qeury 不斷的和庫里的KV 算,進行預測
E 對比學習
為每個模態引入一個class_token ,對最后一個自注意力層輸出的token 做CA ,損失函數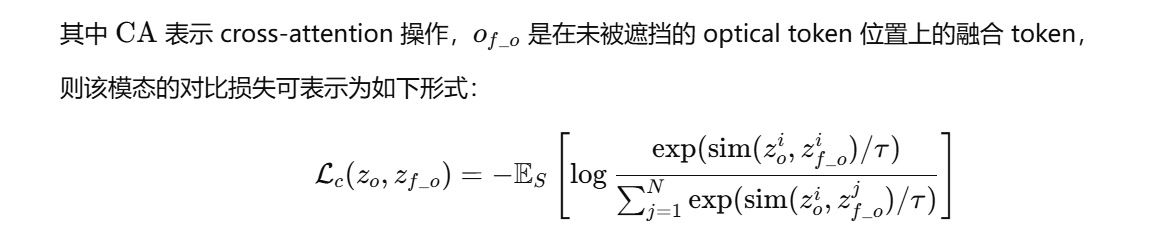
目的是在同一批次的樣本中,強迫模型認出哪個融合向量是與當前單模態向量真正“配對”的,并拉近它們的距離
F. Random Modalities Combination
Transformer 容易對任務中占主導地位的模態過擬合,為了提升魯棒性,提出一種隨機模態組合策略,在預訓練和下游任務訓練中
預訓練:patch 隨機掩碼
下游任務:1.patchdropout 2.隨機模態組合
實驗
數據集:
DFC2023 Track2 - 建筑物實例/語義分割
四元組數據集 - 土地利用土地覆蓋制圖
實驗部分核心內容提煉
一、 實驗目標與設置
核心目標:證明該方法在**模態不完整(有模態缺失)**的情況下,依然能保持強大性能,遠超傳統方法。
兩大任務:實驗在兩個實際的下游任務上進行,分別是建筑物分割和土地利用覆蓋(LULC)制圖。
兩種范式:對每個任務,都進行了兩種模式的評估:
從零開始監督學習:不使用任何預訓練權重,直接在任務數據上訓練。
預訓練后微調:先在大量數據上進行“重建+對比”的自監督預訓練,然后用預訓練好的模型去微調下游任務。
二、 主要實驗結論
模態完整時表現更優:在所有模態都可用的理想情況下,該方法性能已經優于一個簡化的對比模型(MultiViT)。
模態不完整時優勢巨大(最關鍵的結論):
當輸入模態有缺失時,對比模型(MultiViT)因為嚴重“偏科”(過擬合)于主導模態(如光學圖像),性能會斷崖式下跌,甚至完全失效。
而本文提出的方法,得益于**“隨機模態組合”的訓練策略,即使只輸入單一模態(甚至是“非主導”的模態),依然能保持非常高的性能**,展現出極強的魯棒性。
預訓練的有效性因任務而異:
對于建筑物分割任務,一個有趣的發現是“從零開始訓練”的模型表現最佳。
而對于土地利用覆蓋(LULC)制圖任務,經過“重建+對比”雙重預訓練的模型表現最好。這說明對比學習對于增強該任務的特征有顯著幫助。
三、 核心模塊有效性驗證(消融實驗)
作者通過“控制變量法”證明了其提出的每個模塊都是必不可少的:
隨機模態組合策略:極其重要。如果不使用這個策略,模型在模態缺失時性能會嚴重下降,證明這個“魔鬼訓練法”是提升魯棒性的關鍵。
模態注意力 (即交叉注意力):非常有效。如果移除這個模塊,性能會顯著下降,證明這是融合Token有效匯集各模態信息的關鍵一步。
掩碼自注意力:有益處。雖然它限制了模態間的直接交互,但實驗證明它對于保持單模態的“純凈性”和性能至關重要,最終對整體訓練過程產生了積極影響。
四、 對模態貢獻的分析與洞察
該框架還能幫助分析不同模態對特定任務的貢獻度:
對于建筑物分割:光學圖像的貢獻最大,其次是DSM(高度圖),而SAR圖像貢獻最小,有時甚至會引入噪聲。
對于土地利用覆蓋制圖:DNW地圖和Sentinel-2圖像貢獻最大,而DEM(高程)數據則不太關鍵。
這個分析表明,該方法不僅性能強大,還能為實際應用中如何選擇最優、最經濟的模態組合提供決策依據。





)



)
的編程實現方法:1、數據包格式定義結構體2、使用隊列進行數據接收、校驗解包)

)



——標準庫函數大全(持續更新))

![[SKE]Python gmssl庫的C綁定](http://pic.xiahunao.cn/[SKE]Python gmssl庫的C綁定)
