1 引言
在構建基于知識庫的問答系統時,"語義匹配" 是核心難題 —— 如何讓系統準確識別 "表述不同但含義相同" 的問題?比如用戶問 "對親人的期待是不是欲?",系統能匹配到知識庫中 "追名逐利是欲,那對孩子和親人的有所期待是不是欲?" 的答案。
2 系統原來的實現方式
原來的系統是用 BERT 生成句向量并實現匹配的。核心邏輯集中在_get_embedding(生成向量)和search(匹配答案)兩個方法中。
BERT 本身并不直接輸出 "句向量",需要手動從模型輸出中提取特征并處理,原來的核心思路是:
- BERT 的每一層隱藏層都包含不同粒度的語義(淺層偏字面,深層偏抽象)
- 融合最后 4 層的特征,并用手動設置的權重([0.15, 0.25, 0.35, 0.25])調整各層的重要性
- 用 [CLS] 標記的向量代表整個句子的語義
生成向量后,需要計算用戶問題與知識庫中所有問題的相似度
BERT 預訓練時通過 NSP 學到的 “句子間語義關聯能力”,已經內化為模型參數。這種能力會間接體現在句向量中:
- 例如,BERT 能理解 “親人” 和 “孩子” 在 “親近關系” 上的共性,“期待” 和 “期望” 的同義性 —— 這些都是 MLM 和 NSP 任務中學習到的語言知識;
- 系統通過融合 BERT 隱藏層向量,間接利用了這些知識,讓生成的句向量具備基礎語義區分能力。
“加權融合隱藏層” 是為了彌補原始 BERT 句向量生成能力的不足而設計的關鍵步驟。它的核心作用是整合 BERT 不同層的語義特征,生成更全面的句向量;
- 淺層(如第 1-4 層):更關注字面信息(如詞匯本身、簡單搭配)。例如 “對親人的期待”,淺層可能更關注 “親人”“期待” 這些詞的字面含義;
- 深層(如第 9-12 層):更關注抽象語義(如句子整體意圖、邏輯關系)。例如深層能捕捉到 “對親人的期待” 本質是 “一種情感訴求”。
3? BERT 的痛點
BERT 作為預訓練語言模型,在句子級任務中,它有兩個明顯局限:
3.1?計算效率低下
BERT 本身是為 “詞級” 理解設計的(如完形填空、命名實體識別)。
通常獲得句子向量的方法有兩種:
1.計算所有 Token 輸出向量的平均值
2.使用[cLs]位置輸出的向量
若要計算兩個句子的相似度,需將兩個句子拼接成?[CLS] 句子A [SEP] 句子B [SEP]?作為輸入,通過模型輸出的?[CLS]?向量判斷相似度。
計算量隨候選集規模線性增長
3.2??句子級語義捕捉不足
BERT 的?[CLS]?向量雖能代表句子語義,但本質是為 “句子對分類” 任務優化的(如判斷兩個句子是否同義),并非專門為 “單個句子的語義嵌入” 設計。在問答系統中,常出現 “語義相近但表述差異大” 的問題匹配不準的情況。
具體來說,當用 BERT 做 “判斷兩個句子是否同義” 時,輸入格式是固定的:[CLS] 句子A [SEP] 句子B [SEP]。
BERT 輸出的?[CLS]?向量(常用來代表整體語義),是 “針對句子 A 和句子 B 的關系” 生成的 —— 它包含的是 “兩個句子如何關聯” 的信息,而非 “句子 A 單獨的語義” 或 “句子 B 單獨的語義”。
單獨輸入句子 A([CLS] 句子A [SEP]),BERT 的?[CLS]?向量缺乏句子 B,生成的向量無法穩定代表句子 A 的語義。
句子對分類任務:輸入兩個句子,判斷它們的關系(如 “是否同義”“是否存在因果關系”“是否矛盾”)。
例:輸入 “我喜歡蘋果” 和 “蘋果是我愛的水果”,模型判斷 “同義”(輸出分類結果)。單個句子的語義嵌入:為單個句子生成一個向量(數字列表),這個向量需要 “完整代表句子的語義”—— 即 “語義越近的句子,向量越相似”。
例:“我喜歡蘋果” 和 “我喜愛蘋果” 的向量應該非常接近;和 “我討厭香蕉” 的向量應該差異很大。
舉例:
BERT 就像一臺 “雙人對比秤”:它擅長測量 “兩個人的體重差”(句子對關系),但如果單獨測一個人的體重(單個句子向量),結果可能不準(因為它的刻度是為 “對比” 設計的)。
而 “單個句子的語義嵌入” 需要的是 “單人精準秤”:能穩定測量單個人的體重,且兩個人的體重數值可以直接比較(比如 “60kg” 和 “61kg” 接近,“60kg” 和 “80kg” 差異大)。
4 Sentence-BERT(SBERT)
Sentence-BERT(SBERT)是專門為 "句子級語義任務" 設計的模型,它在 BERT 基礎上做了針對性優化,完美解決了上述問題。
Sentence-BERT(SBERT)的作者對預訓練的 BERT 進行修改:
微調+使用 Siamese and TripletNetwork(孿生網絡和三胞胎網絡)生成具有語義的句子 Embedding 向量。
語義相近的句子,其 Embedding 向量距離就比較近,從而可以使用余弦相似度、曼哈頓距離、歐氏距離等找出語義相似的句子。這樣 SBERT 可以完成某些新的特定任務,比如聚類、基于語義的信息檢索等
4.1 孿生網絡(Siamese)
模型結構
核心思想是 “用兩個共享參數的子網絡,學習兩個輸入的相似度”。它不像普通分類網絡那樣直接輸出類別,而是專注于判斷 “兩個輸入是否相似”。
如下圖
- 包含兩個結構完全相同、參數完全共享的子網絡(可以是 CNN、RNN、BERT 等任意網絡);
- 兩個子網絡接收不同輸入(如兩個句子),分別提取特征;
- 最后通過一個 “對比層” 計算兩個特征的相似度,輸出 “兩個輸入是否相似” 的判斷。
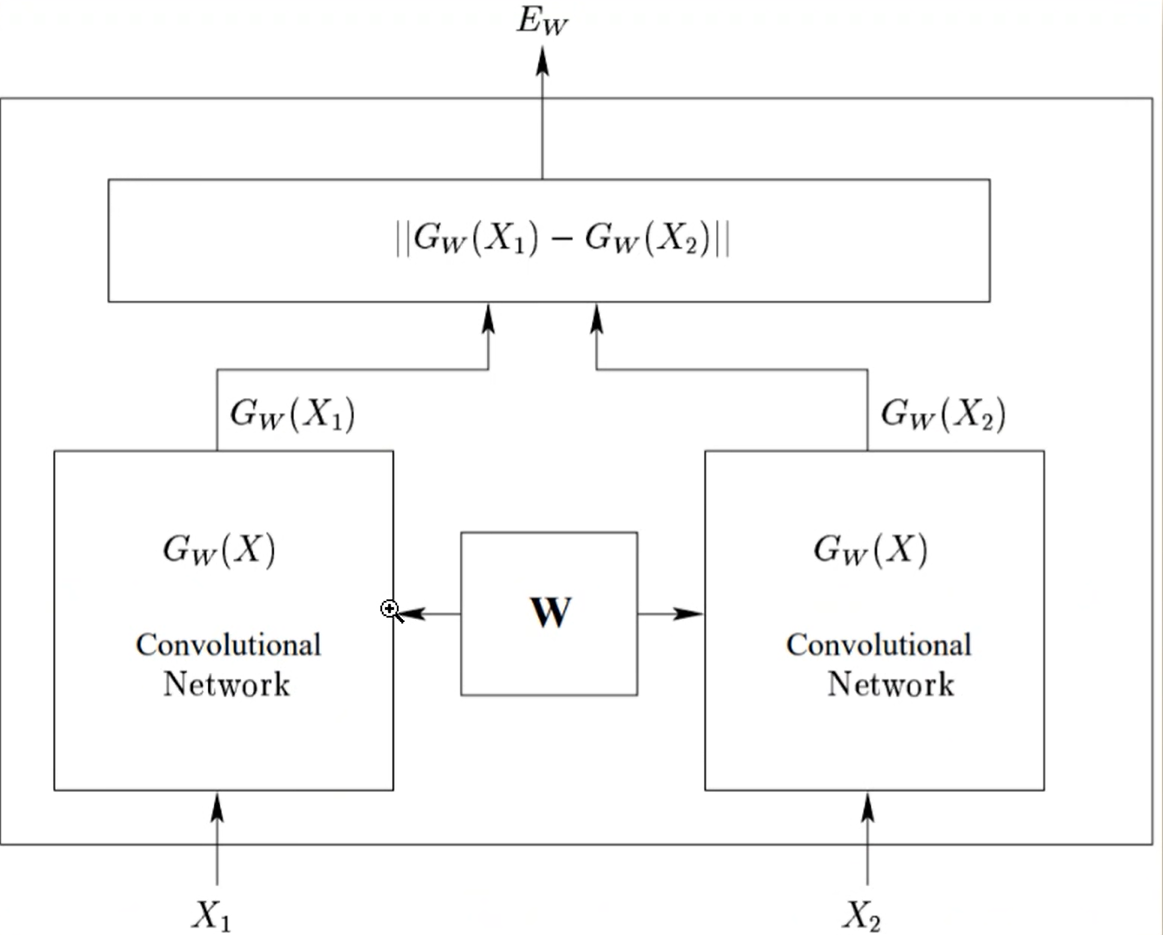
SBERT本質上是 “孿生網絡 + BERT + 對比學習” 的組合,專門解決句子語義相似度問題。
SBERT 的兩個子網絡就是 BERT,通過共享參數提取句子向量。傳入兩個句子,通過計算損失,反向傳播更新參數。對比層用余弦相似度計算向量距離,同時通過對比學習(訓練時讓相似句子向量更近)優化向量分布;
(注意傳入第一個句子時沒有辦法進行梯度回傳更新參數)
損失函數

輸入:兩個待比較的對象
輸入 A:用戶問題 “對親人的期待是不是欲?”
輸入 B:知識庫問題 “對孩子的期待屬于欲望嗎?”
特征提取:兩個子網絡生成特征向量
輸入 A 進入子網絡 1,生成特征向量 V1(比如通過 BERT 提取的語義向量);
輸入 B 進入子網絡 2(和子網絡 1 結構、參數完全相同),生成特征向量 V2;
關鍵:因為參數共享,兩個子網絡對 “相似語義” 的理解標準完全一致(比如 “期待” 和 “期望” 會被映射到相近的向量)。
(這里還是通過計算所有 Token 輸出向量的平均值或者使用[cLs]位置輸出的向量來獲得句向量)
對比:計算向量相似度,輸出判斷結果
通過 “對比層” 計算 V1 和 V2 的相似度(如余弦相似度、歐氏距離);
若相似度高于閾值(如 0.8),判斷為 “相似”(匹配成功);否則為 “不相似”。
5 總結
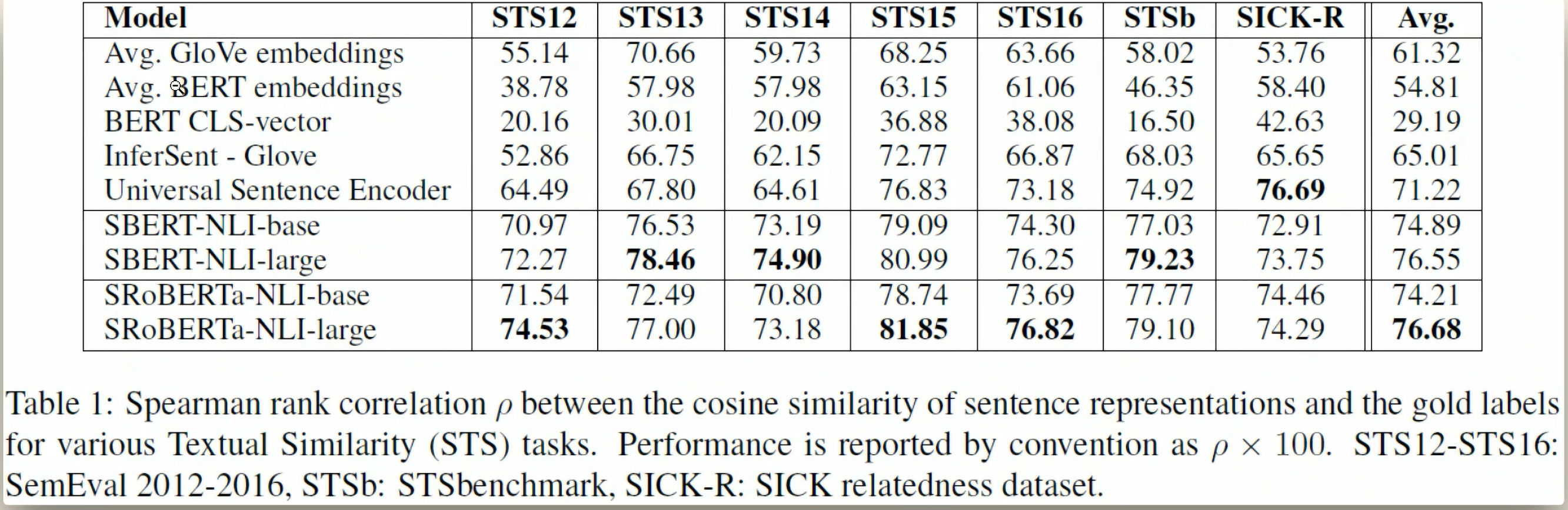
對比原始 BERT 的實現,SBERT 的優勢明顯:
- 無需手動提取隱藏層(省去
hidden_states[-4:]相關邏輯) - 無需加權融合(模型內置最優融合策略)
- 支持批量編碼(
model.encode(questions)直接處理列表)





)


)




)




)
)