一、集合框架
1、什么是集合框架
Java集合框架(Java?Collection Framework),又被稱為容器(container),是定義在java.util包下的一組接口(interfaces)和其實現類(classes).
主要表現為把多個元素(element)放在一個單元中,用于對這些元素進行快速、便捷的存儲(store)、檢索(retrieve)、管理(manipulate),即平時俗稱的增刪改查(CRUD)
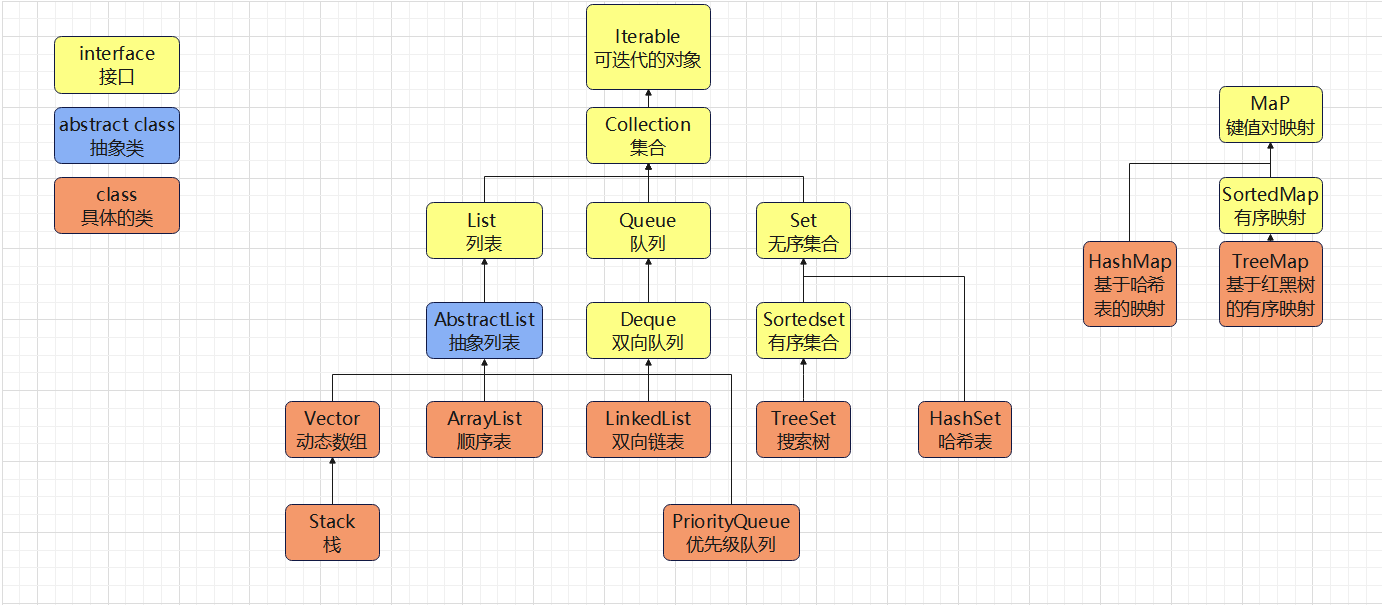
類和接口總覽

2、背后涉及的數據結構以及算法
2.1什么是數據結構
數據結構(Data Structure)是計算機存儲、組織數據的方式,指互相之間存在一種或多種特定關系的數據元素的集合
2.2容器背后對應的數據結構
(1)Collection:一個接口,包含了大部分容器常用的一些方法
(2)List:一個接口,規范了ArrayList和LinkedList中要實現的方法
????????????????????????ArrayList:實現了List接口,底層為動態類型順序表
????????????????????????LinkedList:實現了List接口,底層為雙向鏈表
(3)Stack:底層是棧,棧是一種特殊的順序表
(4)Queue:底層是隊列,隊列是一種特殊的順序表
(5)Deque:是一個接口
(6)Set:集合,是一個接口,里面放置的是K模型
????????????????????????HashSet:底層為哈希桶,查詢的時間復雜度為O(1)
????????????????????????TreeSet:底層為紅黑樹,查詢的時間復雜度為O( logN?),關于key有序的
(7)Map:映射,里面存儲的是K-V模型的鍵值對
HashMap:底層為哈希桶,查詢時間復雜度為O(1)
TreeMap:底層為紅黑樹,查詢的時間復雜度為O(logN),關于key有序
2.3什么是算法
算法(Algorithm):就是定義良好的計算過程,他取一個或一組的值為輸入,并產生出一個或一組值作為輸出。簡單來說算法就是一系列的計算步驟,用來將輸入數據轉化成輸出結果。
二、時間和空間復雜度
1、算法效率
算法效率分析分為兩種:第一種是時間效率,第二種是空間效率。時間效率被稱為時間復雜度,而空間效率被稱作空間復雜度。時間復雜度主要衡量的是一個算法的運行速度,而空間復雜度主要衡量一個算法所需要的額外空間
(在計算機發展的早期,計算機的存儲容量很小。所以對空間復雜度很是在乎。但是經過計算機行業的迅速發展,計 算機的存儲容量已經達到了很高的程度。所以我們如今已經不需要再特別關注一個算法的空間復雜度。)
2、時間復雜度
2.1時間復雜度的概念
時間復雜度的定義:在計算機科學中,算法的時間復雜度是一個數學函數,它定量描述了該算法的運行時間。一個算法執行所耗費的時間,從理論上說,是不能算出來的,只有你把你的程序放在機器上跑起來,才能知道。但是我們需要每個算法都上機測試嗎?是可以都上機測試,但是這很麻煩,所以才有了時間復雜度這個分析方式。一個算法所花費的時間與其中語句的執行次數成正比例,算法中的基本操作的執行次數,為算法的時間復雜度。
2.2大O的漸進表示法
// 請計算一下func1基本操作執行了多少次?void func1(int N){int count = 0;for (int i = 0; i < N ; i++) {for (int j = 0; j < N ; j++) {count++;}}//N^2for (int k = 0; k < 2 * N ; k++) {count++;}//2*Nint M = 10;while ((M--) > 0) {count++;}//10System.out.println(count);}也就是F(N) = N^2 + 2*N + 10
實際我們計算時間復雜度時,我們只需要算大概執行的次數,也就是大O的漸進表示法
大O符號(Big O notation):是用于描述函數漸進行為的數學符號。
2.3推導大O階方法
(1)用常數1取代運行時間中的所有加法常數(換常數)
(2)在修改后的運行次數函數中,只保留最高階項(只保留最高相)
(3)如果最高階項存在且不是1,則去除與這個項目相乘的常數。得到的結果就是大O階。(系數變成1)
使用大O的漸進表示法以后,Func1的時間復雜度為:O(N^2)
通過上面我們會發現大O的漸進表示法去掉了那些對結果影響不大的項,簡潔明了的表示出了執行次數。 另外有些算法的時間復雜度存在最好、平均和最壞情況:
最壞情況:任意輸入規模的最大運行次數(上界)(最慢)
平均情況:任意輸入規模的期望運行次數
最好情況:任意輸入規模的最小運行次數(下界)(最快)
2.4常見的時間復雜度計算舉例
例一、
void func3(int N, int M) {int count = 0; for (int k = 0; k < M; k++) {count++;//M} for (int k = 0; k < N ; k++) {count++;//N} System.out.println(count);}由于基本操作執行了N+M次,并且兩數都是未知數,所以時間復雜度為O(N+M)
例二、
void bubbleSort(int[] array) {for (int end = array.length; end > 0; end--) {boolean sorted = true;for (int i = 1; i < end; i++) {if (array[i - 1] > array[i]) {Swap(array, i - 1, i);sorted = false;}//N*(N-1)/2} if (sorted == true) {break;}}}由于循環執行,第一次執行(N-1)次,最后一次執行了0次,共N次,求每次比前一次少一次,因此得到N*(N-1)/2,因此時間復雜度為O(N^2)
例三、
int binarySearch(int[] array, int value) {int begin = 0;int end = array.length - 1;while (begin <= end) {int mid = begin + ((end-begin) / 2);if (array[mid] < value)begin = mid + 1;else if (array[mid] > value)end = mid - 1;elsereturn mid;}return -1;}
二分查找,一次是原來的一半可以得出(N/2)^O=1,計算可得時間復雜度為O(logN)(logN是以2為底,lgN是以10為底)
例四、
long factorial(int N) {return N < 2 ? N : factorial(N-1) * N;}階乘遞歸是在比較N和2的大小關系進行選擇,可以發現共遞歸了N次,所以時間復雜度為O(N)
例五、
int fibonacci(int N) {return N < 2 ? N : fibonacci(N-1)+fibonacci(N-2);}可以發現,左側最頂端(第一次)是(N-1),最后一次是1,也就可以得到近似的1+2^1+……+2^(N-1),也就是2^N-1,同理,右側也可以計算出是2^(N-1)-1,因此時間復雜度為O(2^N)
我們常遇到的復雜度有:O(1) < O(logN) < O(N) < O(N*logN) < O(N^2)
3、空間復雜度
空間復雜度是對一個算法在運行過程中臨時占用存儲空間大小的量度 。空間復雜度不是程序占用了多少bytes的空間,因為這個也沒太大意義,所以空間復雜度算的是變量的個數。空間復雜度計算規則基本跟時間復雜度類似,也使用大O漸進表示法。
例一、
void bubbleSort(int[] array) {for (int end = array.length; end > 0; end--) {boolean sorted = true;for (int i = 1; i < end; i++) {if (array[i - 1] > array[i]) {Swap(array, i - 1, i);sorted = false;}}if (sorted == true) {break;}}
}因為使用了常數個額外空間,所以空間復雜度為O(1)
例二、
int[] fibonacci(int n) {long[] fibArray = new long[n + 1];fibArray[0] = 0;fibArray[1] = 1;for (int i = 2; i <= n ; i++) {fibArray[i] = fibArray[i - 1] + fibArray [i - 2];}return fibArray;}因為動態開辟了N個空間,空間復雜度為 O(N)
例三、
long factorial(int N) {return N < 2 ? N : factorial(N-1)*N;}因為遞歸調用了N次,開辟了N個棧幀,每個棧幀使用了常數個空間,因此空間復雜度為O(N)
三、包裝類&簡單認識泛類
1、包裝類
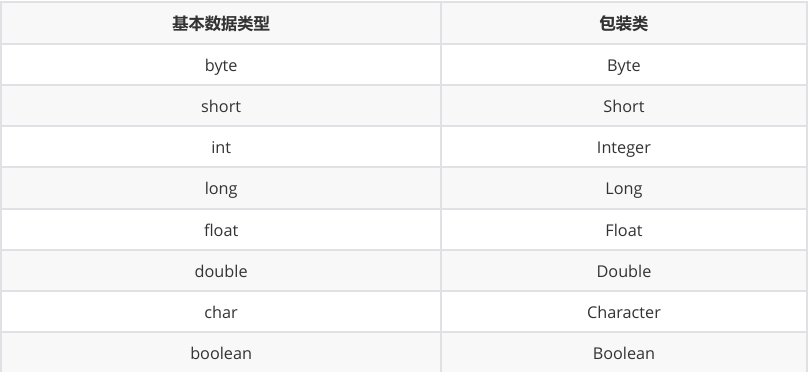
在Java中,由于基本類型不是繼承自Object,為了在泛型代碼中可以支持基本類型,Java給每個基本類型都對應了一個包裝類型。
1.1基本數據類型和對應的包裝類
1.2裝箱和拆箱
int i = 10; // 裝箱操作,新建一個 Integer 類型對象,將 i 的值放入對象的某個屬性中Integer ii = Integer.valueOf(i);Integer ij = new Integer(i);// 拆箱操作,將 Integer 對象中的值取出,放到一個基本數據類型中int j = ii.intValue();
1.3自動裝箱和自動拆箱
我們可以看到在使用過程中,裝箱和拆箱帶來不少的代碼量,所以為了減少開發者的負擔,java 提供了自動機制。
int i = 10;Integer ii = i; // 自動裝箱
Integer ij = (Integer)i; // 自動裝箱int j = ii; // 自動拆箱
int k = (int)ii; // 自動拆箱
2.泛型
實現一個類,類中包含一個數組成員,使得數組中可以存放任何類型的數據,也可以根據成員方法返回數組中某個下標的值?
思路:
(1)我們以前學過的數組,只能存放指定類型的元素,例如:int[] array = new int[10]; String[] strs = new String[10];
(2)所有類的父類,默認為Object類。數組是否可以創建為Object?
class MyArray {public Object[] array = new Object[10];public Object getPos(int pos) {return this.array[pos];}public void setVal(int pos,Object val) {this.array[pos] = val;}}public class TestDemo {public static void main(String[] args) {MyArray myArray = new MyArray();myArray.setVal(0,10);myArray.setVal(1,"hello");//字符串也可以存放String ret = myArray.getPos(1);//編譯報錯System.out.println(ret);}}問題:以上代碼實現后發現
(1)任何類型數據都可以存放
(2)1號下標本身就是字符串,但是卻編譯報錯。必須進行強制類型轉換
雖然在這種情況下,當前數組任何數據都可以存放,但是,更多情況下,我們還是希望他只能夠持有一種數據類型。而不是同時持有這么多類型。所以,泛型的主要目的:就是指定當前的容器,要持有什么類型的對象。讓編譯 器去做檢查。此時,就需要把類型,作為參數傳遞。需要什么類型,就傳入什么類型。
2.1語法
class 泛型類名稱<類型形參列表> {// 這里可以使用類型參數
}class ClassName<T1, T2, ..., Tn> {
}
class 泛型類名稱<類型形參列表> extends 繼承類/* 這里可以使用類型參數 */ {// 這里可以使用類型參數
}class ClassName<T1, T2, ..., Tn> extends ParentClass<T1> {// 可以只使用部分類型參數
}上述代碼進行改寫如下:
class MyArray<T> {public Object[] array = new Object[10];public T getPos(int pos) {return (T)this.array[pos];}public void setVal(int pos,T val) {this.array[pos] = val;}}public class TestDemo {public static void main(String[] args) {MyArray<Integer> myArray = new MyArray<>();//1myArray.setVal(0,10);myArray.setVal(1,12);int ret = myArray.getPos(1);//2System.out.println(ret);myArray.setVal(2,"bit");//3}}
代碼解釋:
(1)類名后的代表占位符,表示當前類是一個泛型類
(了解: 【規范】類型形參一般使用一個大寫字母表示,常用的名稱有:
E 表示 Element
K 表示 Key
V 表示 Value
N 表示 Number
T 表示 Type
S, U, V 等等 - 第二、第三、第四個類型)
(2)注釋1處,類型后加入指定當前類型
(3)注釋2處,不需要進行強制類型轉換
(4)注釋3處,代碼編譯報錯,此時因為在注釋2處指定類當前的類型,此時在注釋3處,編譯器會在存放元素的時候幫助我們進行類型檢查。
3、泛型的使用
3.1語法
泛型類<類型實參> 變量名; // 定義一個泛型類引用
new 泛型類<類型實參>(構造方法實參); // 實例化一個泛型類對象例:
MyArray<Integer> list = new MyArray<Integer>();#注:泛型只能接受類,所有的基本數據類型必須使用包裝類!
3.2 類型推導(Type Inference)
當編譯器可以根據上下文推導出類型實參時,可以省略類型實參的填寫
MyArray<Integer> list = new MyArray<>(); // 可以推導出實例化需要的類型實參為 Integer4、擦除機制
在編譯的過程當中,將所有的T替換為Object這種機制,我們稱為:擦除機制。
Java的泛型機制是在編譯級別實現的。編譯器生成的字節碼在運行期間并不包含泛型的類型信息。
編譯完成以后,T被擦除為Object(編譯期間用T進行類型的檢查和轉換)
5、泛型的上界
在定義泛型類時,有時需要對傳入的類型變量做一定的約束,可以通過類型邊界來約束。
5.1語法
class 泛型類名稱<類型形參 extends 類型邊界> {...}例:
public class MyArray<E extends Number> {...}只接受 Number 的子類型作為 E 的類型實參
MyArray<Integer> l1; // 正常,因為 Integer 是 Number 的子類型
MyArray<String> l2; // 編譯錯誤,因為 String 不是 Number 的子類型(當沒有指定的邊界時,可以認為E extends Object)
6、泛型方法
6.1定義語法
方法限定符 <類型形參列表> 返回值類型 方法名稱(形參列表) { ... }
例:
public class Util {//靜態的泛型方法 需要在static后用<>聲明泛型類型參數public static <E> void swap(E[] array, int i, int j) {E t = array[i];array[i] = array[j];array[j] = t;}}四、List的介紹
1、什么是List
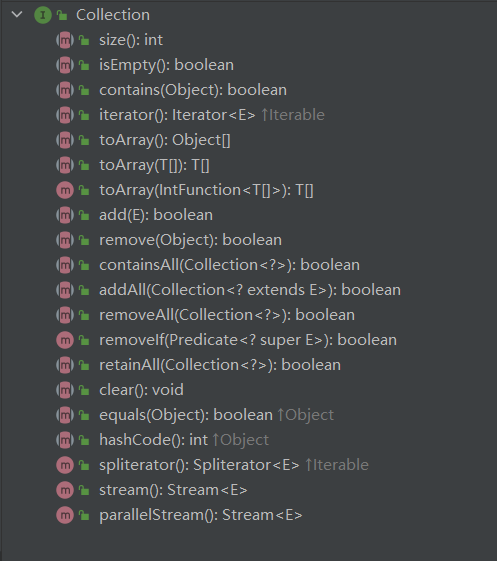
在集合框架中,List是一個接口,繼承自Collection。
Collection也是一個接口(繼承自Iterable),該接口中規范了后序容器中常用的一些方法,具體如下所示:
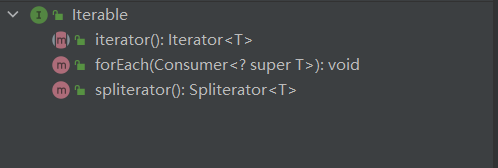
Iterable也是一個接口,表示實現該接口的類是可以逐個元素進行遍歷的,具體如下:
站在數據結構的角度來看,List就是一個線性表,即n個具有相同類型元素的有限序列,在該序列上可以執行增刪改查以及變量等操作。
在這里我們先簡單的認識一下List就可以了,后續內容會補充介紹,這里只需要簡單的看一下有什么就可以了(List太多,有興趣的話可以去自己看一下)



)


)




)




)
)
)
