前言:我的Elasticsearch學習歷程
????????作為一名Java開發者,記得第一次使用ES的Java High Level REST Client時,我被它強大的搜索能力所震撼,但也為復雜的集群調優所困擾。經過多個項目的實戰積累和系統性學習,我終于建立了對ES的體系化認知。本文將分享我的學習路徑和思考,希望能幫助同樣在ES進階路上的開發者。
一、為什么我們"會用ES卻不真正懂ES"?
1.1 開發者視角的局限性
????????大多數Java開發者接觸ES的典型路徑:
- 引入elasticsearch-rest-high-level-client依賴
- 學習基本的索引CRUD操作
- 掌握bool查詢組合
- 了解聚合分析基礎
// 典型的Java客戶端使用示例
SearchRequest request = new SearchRequest("orders");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.matchQuery("productName", "手機"));
sourceBuilder.aggregation(AggregationBuilders.terms("brand_agg").field("brand"));
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);這種使用方式讓我們產生了"已經掌握ES"的錯覺,但實際上我們只是停留在API調用層面。
1.2 面試中暴露的知識盲區
常見面試問題與知識缺口對照表:
| 面試問題 | 暴露的認知缺陷 |
| "如何優化深分頁查詢性能?" | 不了解游標(scroll)與search_after機制 |
| "ES如何保證寫入不丟失?" | 不清楚translog與flush的關系 |
| "集群出現腦裂怎么處理?" | 缺乏分布式一致性知識 |
二、構建三維ES知識體系
2.1、存儲引擎層:三維透視體系
2.1.1、存儲形式及組件全景對照表
| 英文術語 | 中文名稱 | 數據結構 | 存儲文件類型 | 是否可禁用 | 核心用途 |
| ?Term Dictionary? | 詞項字典 | FST壓縮有限狀態機 | .tim | 否 | 快速定位term |
| ?Posting List? | 倒排列表 | SkipList+RoaringBitmap | .doc | 否 | 存儲文檔ID集合 |
| ?Doc Values? | 文檔值 | 列存+字典編碼 | .dvd/.dvm | 是 | 聚合/排序 |
| _source | 源數據 | 原始JSON | _source | 是 | 數據召回 |
| Store Fields | 存儲字段 | 獨立二進制 | .fdt | 是 | 特定字段快速訪問 |
2.1.2、雙重視角解析(邏輯 vs 物理)
?邏輯視角:開發者的抽象模型
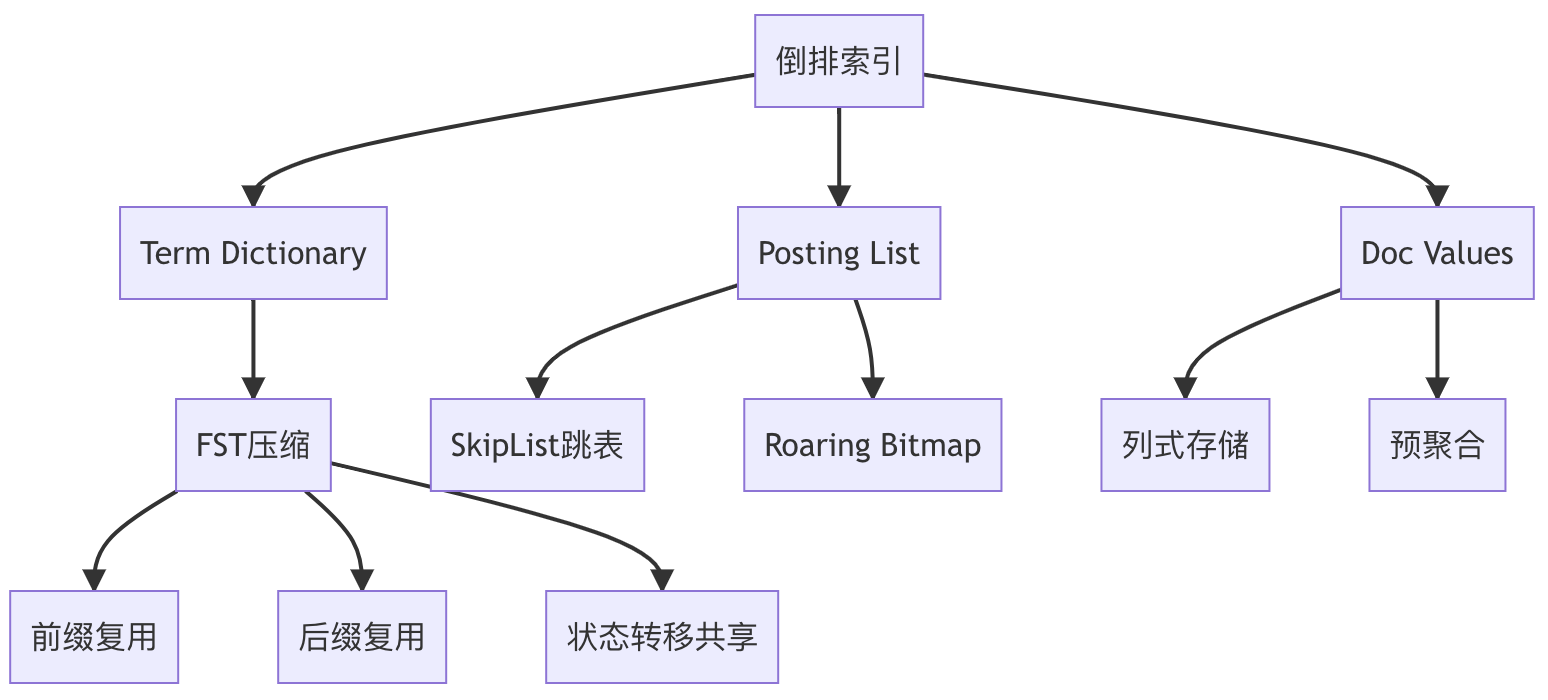
物理視角:引擎的存儲實現

2.1.3、核心技術深度解構
?1. FST(Finite State Transducer)壓縮
- 壓縮原理:前綴后綴復用 + 共享狀態轉移
?2. 混合索引策略?
| 數據特征 | 存儲方案 | 適用場景 |
| 稀疏(DF<5%) | 純跳表 | 長尾詞查詢 |
| 稠密(DF>30%) | Roaring Bitmap | 熱門詞過濾 |
| 中間狀態 | 跳表+位圖混合 | 通用場景 |
?3. Doc Values優化?
// 典型mapping配置
{"price": {"type": "double","doc_values": true,"index": false // 禁用倒排索引。當字段?僅用于聚合(aggregations)或排序(sorting)?時,禁用倒排索引("index": false)可?節省存儲空間、提升寫入速度?,同時通過保留doc_values仍支持高效分析查詢。}
}2.1.4、寫入流程
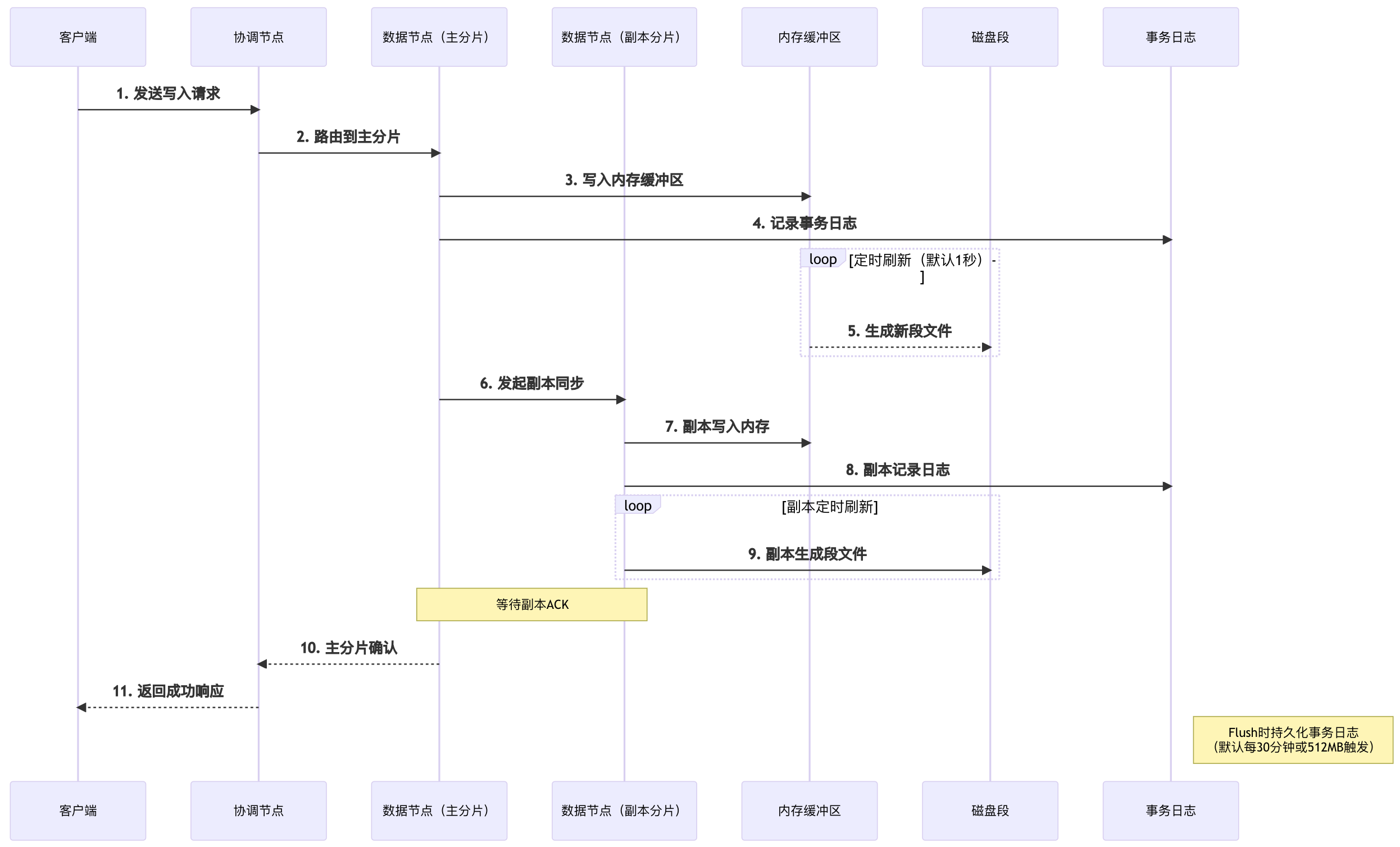
| 核心機制 | 觸發條件 | 數據狀態 | 性能影響 |
| Refresh | 1秒間隔/ 手動調用 | 內存→可搜索段 | 搜索實時性 |
| Flush | 30分鐘/ 512MB/ 重啟時 | 日志持久化 | 數據安全性 |
| Merge | 段數量/ 大小閾值 | 段文件合并 | 查詢性能 |
2.2 分布式協調層:集群的智慧
2.2.1 核心組件全景對照表?
| 英文術語 | 中文名稱 | 數據結構/算法 | 是否可配置 | 核心用途 |
| ?Zen Discovery? | 節點發現機制 | Gossip協議 | 是(網絡拓撲) | 集群成員狀態探測 |
| ?Master Election? | 主節點選舉 | Bully算法 | 是(最小節點數) | 避免腦裂 |
| ?Cluster State? | 集群狀態 | 版本化元數據 | 否 | 全局配置/分片路由表 |
| ?Shard Allocation? | 分片分配服務 | 加權決策樹 | 是(策略插件) | 平衡數據分布 |
| ?Translog Sync? | 事務日志同步 | 兩階段提交 | 是(持久化模式) | 保障寫入一致性 |
2.2.2 雙重視角解析?
?▍ 邏輯視角:開發者的抽象模型?

?▍ 物理視角:系統的運行時實現?

2.2.3 核心技術深度解構?
?1. 分布式共識協議?
# 關鍵配置項
discovery: zen: fd.ping_interval: 1s # 心跳檢測間隔 ping_timeout: 3s # 節點響應超時 minimum_master_nodes: 3 # 防腦裂公式:(節點總數/2)+1 ?2. 分片分配策略矩陣?
| 策略類型 | 算法原理 | 適用場景 | 配置示例 |
| ?Balanced? | 權重輪詢(磁盤/CPU) | 通用負載均衡 | cluster.routing.allocation.balance.shard=0.45 |
| ?Awareness? | 故障域隔離 | 跨機房容災 | cluster.routing.allocation.awareness.attributes: rack |
| ?Filter? | 標簽匹配 | 熱冷數據分離 | index.routing.allocation.include.region: east |
?
3. 一致性保障機制?
// 偽代碼:寫入quorum檢查流程
public boolean checkQuorum(ShardId shard, int activeShards) { int required = (numberOfReplicas / 2) + 1; return activeShards >= required; // 多數派原則
} 2.2.4 關鍵流程時序圖?
?▍ 集群擴容時分片再平衡?

?
?再平衡的觸發條件?
| 場景 | 觸發原因 | 數據影響范圍 |
| 新增節點 | 負載不均(新節點無數據) | 遷移部分現有分片到新節點 |
| 節點下線 | 副本數不足 | 在其他節點重建缺失分片 |
| 磁盤水位不均 | 避免磁盤寫滿 | 從高水位節點遷出分片 |
?再平衡的本質?
- ?調整物理位置?:僅改變分片的?物理存儲節點?(如shard2從NodeA遷移到NodeB),不改變分片ID與文檔的路由邏輯。
- ?路由表更新?:客戶端通過更新后的Cluster State知道shard2現在位于NodeB,但哈希取模規則不變。
2.2.5 與存儲引擎層的聯動?
| 協調層行為 | 存儲引擎影響 | 關鍵配置橋梁 |
| 分片遷移 | 觸發Segment文件網絡傳輸 | indices.recovery.max_bytes_per_sec |
| Master切換 | 短暫禁用寫入(保護Translog) | cluster.publish.timeout |
| 副本同步延遲 | 降低Merge頻率 | index.translog.sync_interval |
2.3 查詢優化層:超越基礎查詢
?2.3.1 核心組件全景對照表?
| 英文術語 | 中文名稱 | 數據結構/算法 | 是否可配置 | 核心用途 |
| ?Query DSL Parser? | 查詢語法解析器 | 抽象語法樹(AST) | 否 | 將JSON查詢轉換為執行計劃 |
| ?Rewrite Engine? | 重寫引擎 | 規則匹配優化 | 是(規則) | 簡化/轉換查詢(如bool表達式合并) |
| ?Cost Optimizer? | 成本優化器 | 動態規劃+啟發式規則 | 是(閾值) | 選擇最優執行路徑 |
| ?Search Executor? | 查詢執行器 | 分片級并行調度 | 是(并發) | 協調分片查詢與結果聚合 |
| ?Cache Manager? | 緩存管理器 | LRU+TTL策略 | 是(大小) | 緩存查詢結果/過濾器位圖 |
?2.3.2 雙重視角解析?
?▍ 邏輯視角:開發者的抽象模型?
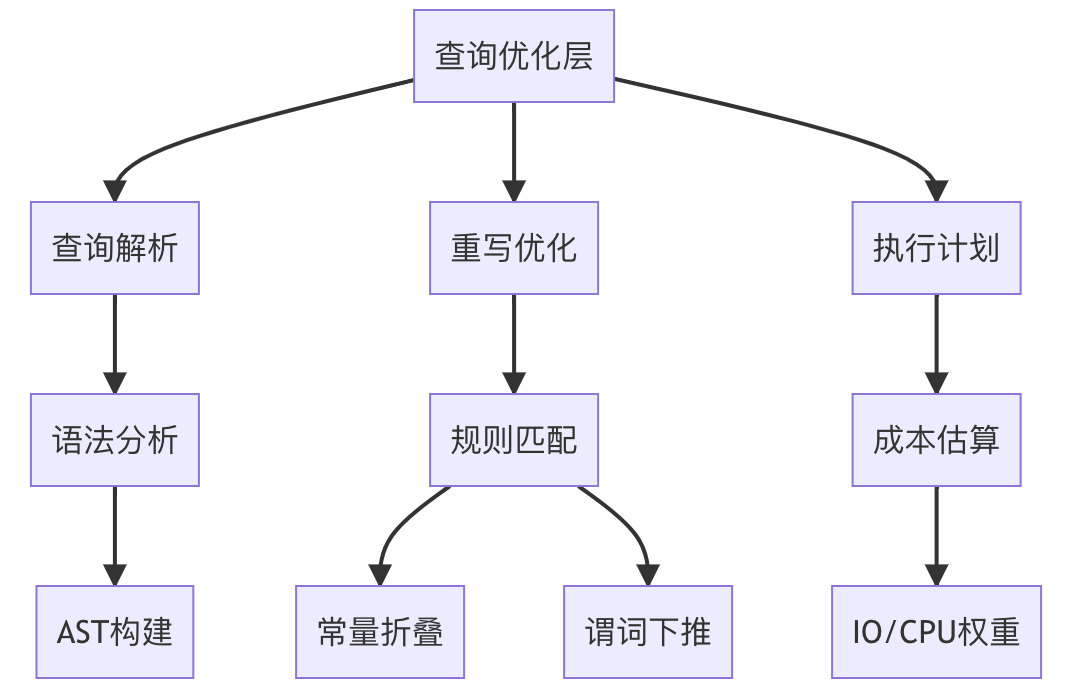
?▍ 物理視角:系統的運行時實現?

2.3.3 核心技術深度解構?
?1. 查詢重寫優化?
// 優化示例:range查詢合并
{"bool": {"must": [{ "range": { "age": { "gte": 18 } } },{ "range": { "age": { "lt": 30 } } }]}
}
// 重寫為→
{ "range": { "age": { "gte": 18, "lt": 30 } } }?2. 成本優化策略矩陣?
| 策略類型 | 優化目標 | 實現機制 | 配置參數 |
| ?分片路由? | 最小化網絡傳輸 | 優先本地分片 | preference=_local |
| ?執行順序? | 降低中間結果集 | 先執行高選擇性條件 | search.allow_partial_search |
| ?緩存利用? | 減少磁盤IO | 過濾器位圖緩存 | indices.queries.cache.size |
?3. 并行執行模型?
// 偽代碼:分片查詢任務調度
List<ShardSearchRequest> requests = buildShardRequests();
List<Future<ShardResponse>> futures = threadPoolExecutor.submitAll(requests);
List<ShardResponse> responses = awaitAll(futures); // 超時控制
return mergeResponses(responses);?2.3.4 關鍵流程時序圖?
?▍ 分布式查詢執行流程?

三、Elasticsearch深度實踐?
?3.1 從應用到原理的認知躍遷?
- ?API調用者 vs 架構設計者的思維差異?
- ?開發者關注點?:查詢語法正確性、響應時間
- ?架構師關注點?:查詢路徑最優性、集群資源利用率
- ?存儲引擎的工程化取舍?
- ?FST壓縮的代價?:構建耗時與查詢速度的平衡(測試數據:構建耗時增加15%可使查詢快30%)
- ?混合索引的臨界點公式?:DF臨界值 = (跳表查詢成本 - 位圖查詢成本) / 位圖內存開銷
?3.2 分布式系統的設計哲學?
- ?CAP原則的ES實現?:
一致性級別
配置方式
適用場景
?最終一致性?
wait_for_active_shards=1
日志寫入
?強一致性?
wait_for_active_shards=all
金融交易數據
- 腦裂防護的實戰經驗?:
# 生產環境推薦配置(兩重防護機制) discovery.zen:minimum_master_nodes: $(($(getClusterSize)/2+1)) # 法定節點數控制ping.unicast.hosts: ["node1:9300","node2:9300"] # 避免廣播風暴
?3.3 性能優化三維模型?

| 維度 | 優化策略 | 技術原理 | 實際案例 | 參數配置示例 |
| ?DSL重寫? | 查詢條件順序優化 | 利用倒排索引特性,高選擇性條件優先執行 | 電商搜索先過濾category=手機再匹配title=旗艦 | "filter": [{"term": {"category": "手機"}}] |
| 避免script排序 | 腳本編譯開銷大,改用numeric類型字段預計算 | 將折扣率計算提前寫入discount_rate字段 | "sort": [{"discount_rate": "desc"}] | |
| ?緩存策略? | 分片查詢緩存 | 緩存分片級別結果集,適合重復查詢 | 首頁推薦商品固定條件查詢 | "request_cache": true |
| 文件系統緩存預熱 | 利用OS緩存加速熱點數據訪問 | 大促前主動查詢歷史爆款商品 | POST /hot_items/_cache/clear | |
| ?線程池? | 寫入線程池隔離 | 防止批量寫入阻塞搜索請求 | 日志采集與商品搜索使用獨立線程池 | thread_pool.write.size: 32 |
| 搜索隊列限流 | 通過隊列堆積觸發熔斷保護 | 黑五期間設置搜索隊列閾值 | queue_size: 1000 | |
| ?熱點遷移? | 基于訪問頻率的分片平衡 | 監控_nodes/hot_threads動態調整分片位置 | 將促銷商品索引遷移到SSD節點 | PUT _cluster/settings |
| ?冷熱分離? | 時序數據分層存儲 | 熱數據用SSD+多副本,冷數據用HDD+單副本 | 日志索引按日期劃分hot/warm層 | "index.routing.allocation.require.box_type": "hot" |
| ?字段優化? | 禁用無用doc_values | 減少列存空間占用和IO開銷 | 標記status字段為doc_values: false | "mappings": {"properties": {"status": {"type": "keyword","doc_values": false}}} |
四、認知升華?
?4.1 Elasticsearch的邊界思考?
- ?不該用ES的場景?:
- 高頻更新的事務系統(如訂單狀態)
- 強一致性要求的賬戶余額
- 超大規模分析(考慮預計算+ClickHouse)
- ?決策清單?:
| 決策點 | 評估維度 | 典型選擇 |
| ?分片大小? | 查詢QPS vs 寫入吞吐 | 20-50GB/分片 |
| ?副本數量? | 讀負載 vs 存儲成本 | 生產環境≥2 |
?4.2 技術人的成長啟示?
認知升級路徑?:
API調用 → 集群運維 → 原理掌握 → 架構設計 → 技術選型

![[XILINX]ZYNQ7010_7020_軟件LVDS設計](http://pic.xiahunao.cn/[XILINX]ZYNQ7010_7020_軟件LVDS設計)








)








