前言
ChatGPT出來后的兩年多,也是我瘋狂寫博的兩年多(年初deepseek更引爆了下),比如從創業起步時的15年到后來22年之間 每年2-6篇的,干到了23年30篇、24年65篇、25年前兩月18篇,成了我在大模型和具身的原始技術積累
如今一轉眼已到25年3月初,時光走得太快,近期和團隊接了好幾個大客戶訂單,使得3月起 不得不全力加速落地,自己也得每天摳paper、搞代碼
so,為何在明明如此之忙 一天當兩天用的情況下,還要繼續努力更新博客呢?
原因在于
- 一方面,我確實喜歡分享,因為寫博的這10多年下來 確實可以幫到很多、很多人,不然本博客也不會有如今如此巨大的訪問量與影響力
更何況有些文章是之前既定計劃中的,在本文之前,上一篇關于π0的文章是π0_fast《π0開源了且推出自回歸版π0-FAST——打造機器人動作專用的高效Tokenizer:比擴散π0的訓練速度快5倍但效果相當》,文中提到,會解讀π0的源碼
至于什么是π0
詳見此文《π0——用于通用機器人控制的VLA模型:一套框架控制7種機械臂(基于PaliGemma和流匹配的3B模型)》
- 二方面,我司「七月在線」在做一系列工廠落地場景的過程中,我們也希望團結到可以和我們一塊做的朋友,而若想團結,便需要借助博客 順帶分享我們每個季度在重點做的業務場景
比如過去一周,我把lerobot、reflect vlm、π0的仿真環境都在我自己本地電腦上跑了下
過程中,GitHub copilot這種AI編程工具在環境的安裝上幫了我很大的忙——各種環境 只要幾句命令,直接幫我裝好,真心不錯)
如此硬著頭皮冥思苦想、摸索了好幾天,隨后使得我自己知道怎么帶隊完成『太多工廠希望實現的一個生產線任務』了,3月初先仿真訓練,2-3個月內部署到真機
當然了,也不單純只是「這幾天的想」就能想出來的,?這幾天之前
- 有把過去一年當三年用的具身技術積累
- 有一年多來,和同事們 如姚博士,以及朋友們許多的討論
- 有去年十幾個工廠對我們的支持與信任
我們正在不斷壯大隊伍
- 有我司內部同事,亦有我聯合帶的北理、中南等985的具身研究生,及一塊合作開發的朋友,很快會把多個生產線任務并行開發起來
- 且無論哪個項目,都是不斷長期迭代的,故過程中少不了科研層面的突破,歡迎更多伙伴加入我們(全職、兼職、實習皆可,有意者,敬請私我),和我們一塊開發

話休絮煩,本文便按照如下圖所示的源碼結構,重點解讀一下π的整個源碼?「?π0及π0-FAST的GitHub地址:github.com/Physical-Intelligence/openpi」
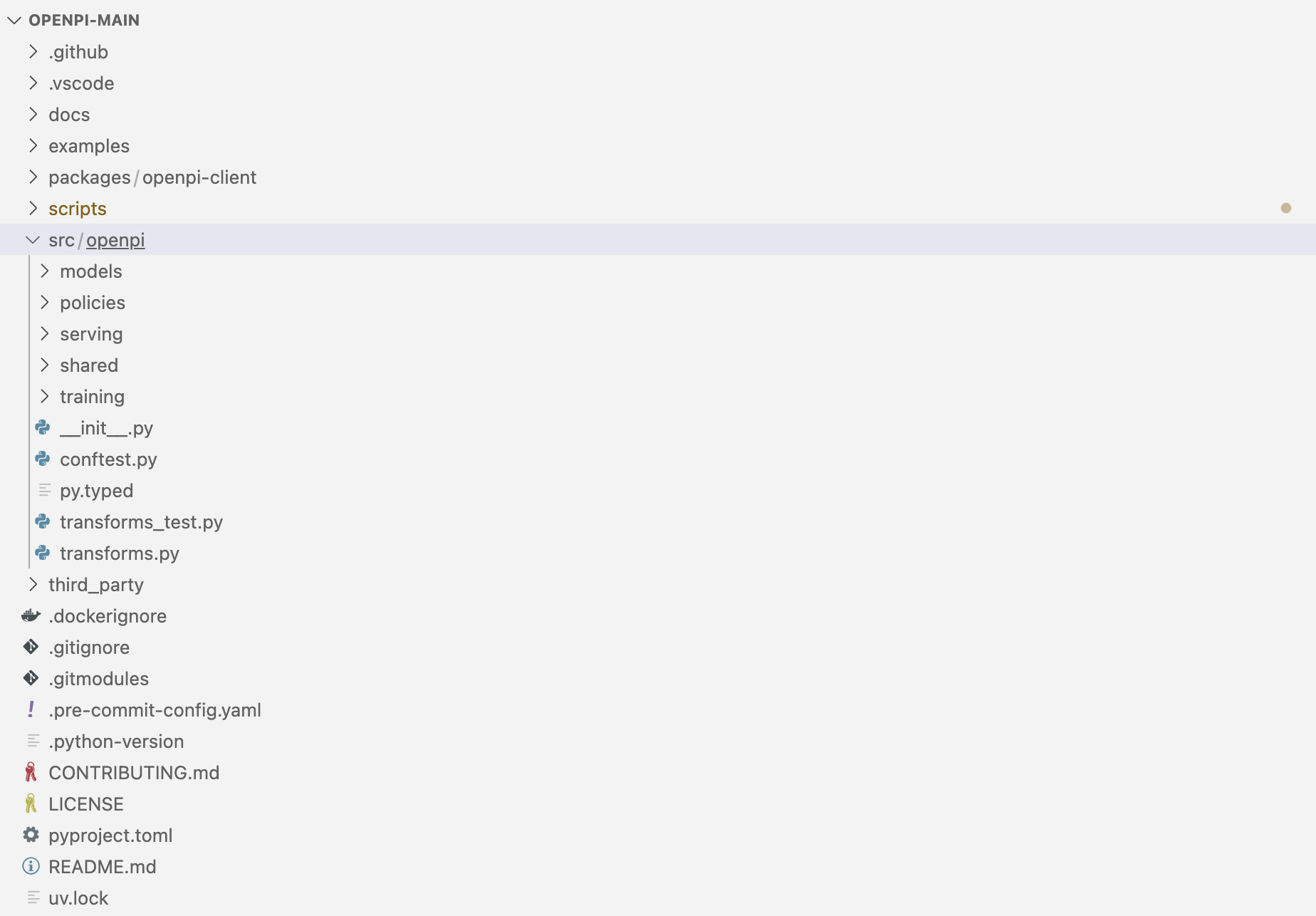
- π0的源碼結構非常清晰、可讀性高,不愧是成熟的商業化公司,是我司七月的學習榜樣之一
另,我在解讀時,除了盡可能像解讀iDP3那樣,比如特意在分析代碼文件之前,貼一下對應的代碼結構截圖——避免只是堆砌代碼,我還會盡可能把模塊之間、模塊內部的函數之間彼此的聯系及互相調用的關系 都闡述出來
如此,不但從宏觀上做到一目了然(注意,本文按照上圖π0的代碼結構,先解讀src模塊下的model-對應下文第一部分、policy-對應下文第二部分、training-對應下文第三部分,第四部分則解讀圖中src上面的packages/openpi-client,以及scripts),更從微觀上做到抽絲剝繭,看到彼此的聯系與調用關系 - 我身邊的很多朋友目前都在做π0的微調及二次開發,相信本文無論對我身邊的朋友,還是對更多人的學習與工作,都會起到比較大的提升
PS,?有興趣或也在對π0做微調的,歡迎私我一兩句自我簡介(比如在哪個公司做什么,或在哪個高校研幾什么專業),邀請進:『七月具身:π0復現微調交流群』
第一部分 π0模型架構的實現:src下models的全面分析與解讀
接下來,我們來看核心src下的各個模塊,首先是其中的src/openpi/models

1.1?models/model.py:核心基礎模型的定義
這是模型框架的核心文件,定義了基礎的抽象類和數據結構:
- `BaseModelConfig`: 所有模型配置的抽象基類
- `BaseModel`: 所有模型實現的抽象基類
- `Observation`: 保存模型輸入的數據類
- `Actions`: 定義動作數據格式
- 提供了通用功能如`preprocess_observation`和`restore_params`
1.1.1 基礎組件和關鍵常量
首先是模型類型枚舉,定義了兩種支持的模型類型:
- `PI0`:標準PI0模型
- `PI0_FAST`:自回歸版PI0模型
class ModelType(enum.Enum):"""Supported model types."""PI0 = "pi0"PI0_FAST = "pi0_fast"接下來是 圖像輸入配置,定義了模型期望的圖像輸入的鍵名。這表明模型設計為同時接收三個視角的圖像:
- 一個基礎視圖(機器人環境的全局視圖)
- 左手腕視圖(來自左手腕攝像頭)
- 右手腕視圖(來自右手腕攝像頭)
# The model always expects these images
IMAGE_KEYS = ("base_0_rgb","left_wrist_0_rgb","right_wrist_0_rgb",
)再其次,是圖像分辨率設置——定義了模型處理圖像的標準分辨率為224×224像素
# This may need change if we release a small model.
IMAGE_RESOLUTION = (224, 224)1.1.2?`Observation` 類與Actions類型的詳解
`Observation` 類是 OpenPI 框架中的一個核心數據結構,用于存儲和管理模型的輸入數據
首先,它包含了機器人感知系統收集的所有必要信息:
- 圖像數據 (`images`)
類型:`dict[str, at.Float[ArrayT, "*b h w c"]]class Observation(Generic[ArrayT]):"""Holds observations, i.e., inputs to the model.See `Observation.from_dict` to see the expected dictionary form. This is the formatthat should be produced by the data transforms."""# Images, in [-1, 1] float32.images: dict[str, at.Float[ArrayT, "*b h w c"]]
用途:存儲多個攝像頭視角的圖像數據
格式:浮點數數組,范圍在 [-1, 1] 之間
維度:`*b` 表示任意批量維度,`h` 和 `w` 是圖像高度和寬度,`c` 是顏色通道數 - 圖像掩碼 (`image_masks`)
類型:`dict[str, at.Bool[ArrayT, "*b"]]`# Image masks, with same keys as images.image_masks: dict[str, at.Bool[ArrayT, "*b"]]
用途:標記對應的圖像是否有效
格式:布爾值數組
維度:與圖像批量維度相同 - 機器人狀態 (`state`)
類型:`at.Float[ArrayT, "*b s"]`# Low-dimensional robot state.state: at.Float[ArrayT, "*b s"]
用途:存儲低維度的機器人狀態向量
維度:`*b` 表示批量維度,`s` 表示狀態向量維度 - 語言提示相關字段
`tokenized_prompt`:已經tokenized的語言提示
`tokenized_prompt_mask`:語言提示的掩碼# Tokenized prompt.tokenized_prompt: at.Int[ArrayT, "*b l"] | None = None
當然了,兩者都是可選字段(可以為 `None`)# Tokenized prompt mask.tokenized_prompt_mask: at.Bool[ArrayT, "*b l"] | None = None - PI0-FAST 模型特有字段
`token_ar_mask`:自回歸模型的標記掩碼
`token_loss_mask`:損失計算的標記掩碼# Token auto-regressive mask (for FAST autoregressive model).token_ar_mask: at.Int[ArrayT, "*b l"] | None = None# Token loss mask (for FAST autoregressive model).token_loss_mask: at.Bool[ArrayT, "*b l"] | None = None
接下來,定義了`from_dict` 方法,用于從非結構化的字典數據創建 `Observation` 對象:
- 數據驗證:確保 `tokenized_prompt` 和 `tokenized_prompt_mask` 要么同時存在,要么同時不存在
def from_dict(cls, data: at.PyTree[ArrayT]) -> "Observation[ArrayT]":"""This method defines the mapping between unstructured data (i.e., nested dict) to the structured Observation format."""# Ensure that tokenized_prompt and tokenized_prompt_mask are provided together.if ("tokenized_prompt" in data) != ("tokenized_prompt_mask" in data):raise ValueError("tokenized_prompt and tokenized_prompt_mask must be provided together.") - 圖像格式轉換:如果輸入圖像是 `uint8` 格式(0-255 范圍),自動轉換為 `float32` 格式(范圍 [-1, 1])
# If images are uint8, convert them to [-1, 1] float32.for key in data["image"]:if data["image"][key].dtype == np.uint8:data["image"][key] = data["image"][key].astype(np.float32) / 255.0 * 2.0 - 1.0 - 結構化數據創建:從字典數據創建結構化的 `Observation` 對象
return cls(images=data["image"],image_masks=data["image_mask"],state=data["state"],tokenized_prompt=data.get("tokenized_prompt"),tokenized_prompt_mask=data.get("tokenized_prompt_mask"),token_ar_mask=data.get("token_ar_mask"),token_loss_mask=data.get("token_loss_mask"),)
再接下來,又定義了`to_dict` 方法,將 `Observation` 對象轉換回非結構化的字典格式:
- 使用 `dataclasses.asdict()` 將數據類轉換為字典
def to_dict(self) -> at.PyTree[ArrayT]:"""Convert the Observation to a nested dict."""result = dataclasses.asdict(self) - 重命名字段以符合原始數據格式約定(`images` → `image`,`image_masks` → `image_mask`)
result["image"] = result.pop("images")result["image_mask"] = result.pop("image_masks")return result
最后,在類外定義了 `Actions` 類型,用于表示模型的輸出動作:
# Defines the format of the actions. This field is included as "actions" inside the dictionary
# produced by the data transforms.
Actions = at.Float[ArrayT, "*b ah ad"]- 類型:`at.Float[ArrayT, "*b ah ad"]`
- 維度:`*b` 表示批量維度,`ah` 表示動作時間步長,`ad` 表示每個動作的維度
一朋友在我組建的『七月具身:π0復現微調交流群』問了個比較細節的問題,即
我想采集自己的數據來微調這個openpi,然后在采自己的數據時,我的action到底應該采什么(如果采當前幀末端位姿的話,和state有什么區別,只是差個fk而已,不是冗余了么)真正送到模型訓練的時候,action又是什么,有大佬可以解決一下嗎
根據OpenPI的代碼結構,state和action在robotics任務中具有不同的含義:
State (狀態),代表機器人當前的狀態信息,包括:
- 機器人當前的配置,比如關節角度、末端執行器位置等
- 末端執行器(end-effector)的位置和方向
- 可能還包括物體的狀態、環境信息等
如果只采集末端位姿,確實與狀態信息存在冗余,只是差一步FK(正向運動學)計算。實際上,有效的Action (動作)代表機器人應該執行的下一步控制命令(告訴機器人如何移動)——通常是從當前狀態到下一個目標狀態的轉換,可能是:
- 關節控制
表示目標關節角度,或關節角度的增量變化(delta)
說白了,state描述:我在哪里,action描述:我要去哪里- 相對位移/速度
末端位置到目標位置(target position)的增量變化,和方向- 控制信號
直接發送給執行器的命令,或力矩
1.1.3?preprocess_observation
1.1.4?BaseModelConfig(abc.ABC)
1.1.5?class BaseModel(nnx.Module, abc.ABC)
1.1.6?restore_params
// 待更
1.2 models/pi0.py的實現
Pi0是一個多模態擴散模型:繼承自`BaseModel`,使用SigLIP處理視覺輸入、使用Gemma處理語言輸入,實現了基于擴散的動作生成系統,且包含`compute_loss`和`sample_actions`方法的實現
總之,Pi0結合了多模態輸入(圖像和文本)來生成機器人動作序列。下面是對代碼的詳細解析:
1.2.1 make_attn_mask:注意力掩碼生成函數
這個函數生成transformer中使用的注意力掩碼,控制 token 之間的注意力流動方式
def make_attn_mask(input_mask, mask_ar):"""從big_vision項目改編的注意力掩碼生成函數Token可以關注那些累積mask_ar小于等于自己的有效輸入token。這樣`mask_ar` bool[?B, N]可用于設置幾種類型的注意力,例如:[[1 1 1 1 1 1]]: 純因果注意力。[[0 0 0 1 1 1]]: 前綴語言模型注意力。前3個token之間可以互相關注,后3個token有因果注意力。第一個條目也可以是1,不改變行為。[[1 0 1 0 1 0 0 1 0 0]]: 4個塊之間的因果注意力。一個塊的token可以關注所有之前的塊和同一塊內的所有token。參數:input_mask: bool[B, N] 如果是輸入的一部分則為true,如果是填充則為falsemask_ar: bool[?B, N] 如果前面的token不能依賴于它則為true,如果它共享與前一個token相同的注意力掩碼則為false"""# 將mask_ar廣播到與input_mask相同的形狀mask_ar = jnp.broadcast_to(mask_ar, input_mask.shape) # 計算mask_ar在序列維度上的累積和cumsum = jnp.cumsum(mask_ar, axis=1) # 創建注意力掩碼:當目標位置的累積值<=查詢位置的累積值時,允許注意力流動attn_mask = cumsum[:, None, :] <= cumsum[:, :, None] # 創建有效掩碼:只有有效的輸入位置之間才能有注意力valid_mask = input_mask[:, None, :] * input_mask[:, :, None] # 結合注意力掩碼和有效掩碼return jnp.logical_and(attn_mask, valid_mask) 它支持多種注意力模式:
- 純因果注意力(每個 token 只能關注自己和之前的 token)
- 前綴語言模型注意力(允許前綴內部自由注意,后綴部分使用因果注意力)
- 塊狀因果注意力(在塊內自由注意,塊之間是因果的)
1.2.2 posemb_sincos:位置編碼函數
使用正弦余弦函數實現位置編碼
def posemb_sincos(pos: at.Real[at.Array, Any], embedding_dim: int, min_period: float, max_period: float
) -> at.Float[at.Array, f"b {embedding_dim}"]:"""計算標量位置的正弦余弦位置嵌入向量"""if embedding_dim % 2 != 0: # 檢查嵌入維度是否為偶數raise ValueError(f"embedding_dim ({embedding_dim}) must be divisible by 2")fraction = jnp.linspace(0.0, 1.0, embedding_dim // 2) # 創建均勻分布的分數值period = min_period * (max_period / min_period) ** fraction # 計算周期值,對數空間中均勻分布sinusoid_input = jnp.einsum("i,j->ij",pos,1.0 / period * 2 * jnp.pi, # 計算角頻率precision=jax.lax.Precision.HIGHEST, # 使用最高精度進行計算)# 連接sin和cos值,形成完整的位置編碼return jnp.concatenate([jnp.sin(sinusoid_input), jnp.cos(sinusoid_input)], axis=-1)1.2.3 class Pi0Config:含inputs_spec、get_freeze_filter
Pi0Config這個類中,定義了
- 動作專家底層結構gemma_300m
- inputs_spec:π0模型本身接收的輸入數據格式
- get_freeze_filter(決定對VLM和action expect的哪部分微調,還是都微調)
1.2.3.1?模型配置參數的定義
首先,這個類定義了模型的配置參數,比如PaLI-Gemma 變體:`gemma_2b,尤其值得注意的是在本π0的官方實現中,動作專家的底層結構用的300M大小的gemma模型變體
class Pi0Config(_model.BaseModelConfig):dtype: str = "bfloat16" # 設置數據類型為bfloat16paligemma_variant: _gemma.Variant = "gemma_2b" # 設置PaLI-Gemma變體為2B參數版本action_expert_variant: _gemma.Variant = "gemma_300m" # 設置動作專家為gemma的300M變體版本# 設置模型特定的默認值action_dim: int = 32 # 設置動作維度為32action_horizon: int = 50 # 設置動作序列長度為50步max_token_len: int = 48 # 設置最大token長度為481.2.3.2?inputs_spec:定義了π0模型本身接收的輸入數據格式
其次,通過inputs_spec函數定義了π0模型本身接收的輸入數據格式,函數采用關鍵字參數 `batch_size`(默認為1),返回一個包含觀察規格和動作規格的元組
def inputs_spec(self, *, batch_size: int = 1) -> Tuple[Type[_model.Observation], Type[_model.Actions]]- 其支持多種輸入,比如
視覺輸入(三個不同視角的RGB圖像)、語言輸入(分詞后的文本prompt)、狀態輸入(當前機器人狀態) - 輸出上
則是一個時序動作序列(包含50個連續的動作向量,每個動作向量有32個維度,可能對應關節角度或其他控制信號)
具體而言該函數進行如下4個操作
一、創建圖像規格
image_spec = jax.ShapeDtypeStruct([batch_size, *_model.IMAGE_RESOLUTION, 3], jnp.float32)其中的
- `[batch_size, *_model.IMAGE_RESOLUTION, 3]` 定義了圖像張量的形狀:比如
? 批次大小
- `jnp.float32` 指定了數據類型為 32 位浮點數
二、創建圖像掩碼規格
image_mask_spec = jax.ShapeDtypeStruct([batch_size], jnp.bool_)其定義了圖像掩碼規格,每個批次中的每個圖像都有一個布爾值,這個掩碼用于指示哪些圖像是有效的(`True`)或無效的(`False`)
三、創建觀察規格:包含視覺輸入、機器人狀態、指令輸入
`at.disable_typechecking()` 臨時禁用類型檢查,可能是因為這里創建的是類型規格而不是實際的數據,且觀察規格包含多個組件:
- 多視角圖像
base_0_rgb: 機器人底座/身體視角的RGB圖像
left_wrist_0_rgb: 左手腕視角的RGB圖像
right_wrist_0_rgb: 右手腕視角的RGB圖像with at.disable_typechecking():observation_spec = _model.Observation(images={"base_0_rgb": image_spec,"left_wrist_0_rgb": image_spec,"right_wrist_0_rgb": image_spec,}, - 圖像掩碼
對應每個視角圖像的有效性掩碼 - 機器人狀態:
形狀為 `[batch_size, self.action_dim]` 的浮點數張量,其中的`self.action_dim` 默認為32,表示狀態向量的維度state=jax.ShapeDtypeStruct([batch_size, self.action_dim], jnp.float32), - 分詞后的文本prompt
形狀為 `[batch_size, self.max_token_len]` 的整數張量
`self.max_token_len` 默認為48,表示最大token數量
數據類型為 `jnp.int32`,表示token ID - 提示掩碼
與分詞提示相同形狀的布爾張量,用于指示哪些位置有有效的tokenstate=jax.ShapeDtypeStruct([batch_size, self.action_dim], jnp.float32),tokenized_prompt=jax.ShapeDtypeStruct([batch_size, self.max_token_len], jnp.int32),tokenized_prompt_mask=jax.ShapeDtypeStruct([batch_size, self.max_token_len], bool),)
四、創建動作規格
action_spec = jax.ShapeDtypeStruct([batch_size, self.action_horizon, self.action_dim], jnp.float32)其定義了動作數據的形狀和類型:
- `batch_size`: 批次大小
- `self.action_horizon`: 動作序列長度,默認為50
- ?`self.action_dim`: 每個動作的維度,默認為32
- `jnp.float32` 指定了數據類型為32位浮點數
然后返回
return observation_spec, action_spec1.2.3.3?get_freeze_filter:參數凍結器,包含誰則相當于誰被凍結/過濾
此外,該配置類還實現了get_freeze_filter這個函數,作用是如果選擇LoRA微調(凍結原始預訓練模型的參數,只更新新添加的低秩適應層參數),則需要對模型中的某些參數做凍結
三種可能的情況:
- 只對 PaLI-Gemma 使用 LoRA
意味著只凍結 Gemma 原始參數,然后排除動作專家原始參數,微調Gemma原始參數之外的少量LoRA部分
注意
「關于什么是LoRA,詳見此文《LLM高效參數微調方法:從Prefix Tuning、Prompt Tuning、P-Tuning V1/V2到LoRA、QLoRA(含對模型量化的解釋)》的第4部分」
畢竟lora微調的本質是 原始參數凍結,而是微調「兩個可以近似原矩陣的兩個小矩陣」參數
- 只對動作專家使用 LoRA
意味著只凍結動作專家參數,微調動作專家原始參數之外的少量LoRA部分 - 對兩者都使用 LoRA
意味著凍結兩者的基礎參數,微調兩者原始參數之外的少量LoRA部分
如此,可以選擇性地微調模型的特定部分(語言部分或動作預測部分)
具體而言,該get_freeze_filter分為4大階段
第一階段,定義函數本身、初始化變量,并創建參數過濾器
- 首先,定義函數
def get_freeze_filter(self) -> nnx.filterlib.Filter:"""返回基于模型配置的凍結過濾器""" - 其次,初始化變量
filters = [] # 初始化過濾器列表has_lora = False # 初始化LoRA標志 - 接著,創建參數過濾器
# 匹配所有LLM參數的正則表達式,用于選擇 Gemma 語言模型的參數gemma_params_filter = nnx_utils.PathRegex(".*llm.*") # 匹配動作專家參數的正則表達式action_expert_params_filter = nnx_utils.PathRegex(".*llm.*_1.*")
第二階段,分情況添加LoRA權重
即要么只對語言模型使用LoRA(意味著不對動作專家使用LoRA),要么只對動作專家使用LoRA
- 即,接下來是對PaLI-Gemma變體的處理
如果只對PaLI-Gemma使用LoRA,則
# 如果只針對PaLI-Gemma使用LoRAif "lora" in self.paligemma_variant:# 過濾器列表添加Gemma的原始參數filters.append(gemma_params_filter,)if "lora" not in self.action_expert_variant:# 因為只凍結Gemma參數,故過濾器列表不添加動作專家expert的原始參數filters.append(nnx.Not(action_expert_params_filter),)has_lora = True - 再下來是對動作專家變體的處理,如果對action_expert_variant使用LoRA,則過濾器列表添加動作專家expert的原始參數,而微調動作專家原始參數之外的少量LoRA部分
elif "lora" in self.action_expert_variant:# 如果動作專家使用LoRA,則過濾器列表添加動作專家expert的原始參數filters.append(action_expert_params_filter,)has_lora = True
第三階段,針對需要LoRA微調的少量參數處理,以及如果沒有需要LoRA微調時的處理
- 如果有需要被LoRA微調的部分,則過濾器列表里不添加原始參數之外的LoRA相關參數(代表著不被過濾)
if has_lora:# If any lora is used, exclude all lora params.filters.append(nnx.Not(nnx_utils.PathRegex(".*lora.*")),) - 如果沒有被凍結/過濾的參數,則什么都不需要處理——即默認微調所有參數
if not filters:return nnx.Nothing
第四階段,返回所有需要被凍結/被過濾的參數,這畢竟是get_freeze_filter函數本身定義所追求的目標
return nnx.All(*filters)值得注意的是,也是我之前看到這里思考過的一個問題,即在訓練 π0 的動作預測能力時
- 默認會同時調整 VLM 和動作專家的參數
- 如果需要只調整動作專家的參數,可以通過修改 `get_freeze_filter` 方法來凍結 VLM 的參數
1.2.4?class Pi0:含特征嵌入(embed_prefix/embed_suffix)、損失函數(訓練去噪的準確性)、推理(去噪生成動作)
核心模型類,繼承自 `_model.BaseModel`,實現了:
- 多模態輸入處理
處理多視角圖像(基礎視角、左手腕視角、右手腕視角)
處理文本提示(如指令)
處理機器人當前狀態 - 擴散過程
訓練時:將干凈動作添加噪聲,讓模型學習去噪
推理時:從純噪聲開始,逐步降噪生成動作序列 - 注意力機制
使用精心設計的注意力掩碼控制信息流動
前綴(圖像和文本)內部使用全注意力
后綴(狀態和動作)使用特殊的注意力模式
1.2.4.1 初始化方法 `__init__`
class Pi0(_model.BaseModel):def __init__(self, config: Pi0Config, rngs: nnx.Rngs):# 初始化基類super().__init__(config.action_dim, config.action_horizon, config.max_token_len)# 獲取PaLI-Gemma和動作專家配置paligemma_config = _gemma.get_config(config.paligemma_variant)action_expert_config = _gemma.get_config(config.action_expert_variant)其組合了多個核心組件:
一個是PaLI-Gemma 模型:結合了 Gemma 語言模型和 SigLIP 視覺模型

- 先是對語言模型的初始化
# 創建并初始化語言模型# TODO: 用NNX重寫Gemma,目前使用橋接llm = nnx_bridge.ToNNX(_gemma.Module(configs=[paligemma_config, action_expert_config], # 配置兩個Gemma模型embed_dtype=config.dtype, # 設置嵌入數據類型))llm.lazy_init(rngs=rngs, method="init") # 延遲初始化LLM - 然后是對視覺模型的初始化
# 創建并初始化圖像模型img = nnx_bridge.ToNNX(_siglip.Module(num_classes=paligemma_config.width, # 設置圖像特征維度與語言模型寬度相匹配variant="So400m/14", # 使用400M參數SigLIP模型pool_type="none", # 不使用池化,保留所有圖像tokenscan=True, # 啟用掃描優化dtype_mm=config.dtype, # 設置矩陣乘法數據類型))# 使用假觀察中的圖像初始化圖像模型img.lazy_init(next(iter(config.fake_obs().images.values())), train=False, rngs=rngs) - 最后,把語言模型和視覺模型組合成PaLI-Gemma多模態模型
# 組合LLM和圖像模型為PaLI-Gemma多模態模型self.PaliGemma = nnx.Dict(llm=llm, img=img)
另一個是線性投影層:用于
- 狀態投影
# 狀態投影層:將機器人狀態投影到模型維度self.state_proj = nnx.Linear(config.action_dim, action_expert_config.width, rngs=rngs) - 動作投影
# 動作輸入投影層:將動作投影到模型維度self.action_in_proj = nnx.Linear(config.action_dim, action_expert_config.width, rngs=rngs) - 時間-動作混合等
# 動作-時間MLP輸入層:將連接的動作和時間特征投影到模型維度self.action_time_mlp_in = nnx.Linear(2 * action_expert_config.width, action_expert_config.width, rngs=rngs)# 動作-時間MLP輸出層self.action_time_mlp_out = nnx.Linear(action_expert_config.width, action_expert_config.width, rngs=rngs)# 動作輸出投影層:將模型輸出投影回動作維度self.action_out_proj = nnx.Linear(action_expert_config.width, config.action_dim, rngs=rngs)
1.2.4.2 特征嵌入方法:embed_prefix(圖像和文本輸入)、embed_suffix(狀態和動作信息)
- `embed_prefix`:處理圖像和文本輸入(圖像通過SigLip模型編碼,文本通過Gemma LLM編碼),創建前綴 token,皆為雙向注意力,用ar_mask = false表示
- `embed_suffix`:處理機器人狀態信息
、噪聲化的動作信息
(狀態和噪聲動作經過線性投影和MLP處理),創建后綴 token
其中
首先,對于前者embed_prefix
def embed_prefix(self, obs: _model.Observation) -> Tuple[at.Float[at.Array, Any], at.Bool[at.Array, Any], at.Bool[at.Array, Any]]:"""嵌入前綴部分(圖像和文本)"""input_mask = [] # 初始化輸入掩碼列表ar_mask = [] # 初始化自回歸掩碼列表tokens = [] # 初始化token列表其工作流程為
- 圖像處理:說白了,就是把圖像token化
使用SigLip視覺模型處理每個圖像,生成圖像tokens序列# 嵌入圖像for name in obs.images:# 通過圖像模型獲取圖像tokenimage_tokens, _ = self.PaliGemma.img(obs.images[name], train=False)tokens.append(image_tokens) # 添加圖像token - 圖像掩碼擴展
將圖像掩碼擴展到與圖像tokens相同的序列長度,使用einops.repeat進行形狀變換,這些掩碼會指示哪些圖像是有效的,而哪些是填充的# 重復圖像掩碼以匹配token維度input_mask.append(einops.repeat(obs.image_masks[name],"b -> b s", # 調整形狀:批次維度保持不變,添加序列維度s=image_tokens.shape[1], # 序列長度等于圖像token數)) - 自回歸掩碼設置
設置圖像tokens之間的注意力為雙向(False表示雙向注意力),原因在于圖像內容通常是非時序性的數據# 圖像token之間互相關注(非自回歸)ar_mask += [False] * image_tokens.shape[1] - 文本處理
使用LLM模型對文本輸入tokenized_inputs進行嵌入
且同樣設置為雙向注意力,相當于語言token可以關注圖像token,圖像token反過來亦可關注語言token,最終實現多模態融合# 添加語言(即分詞后的輸入)if obs.tokenized_prompt is not None:# 通過語言模型嵌入分詞后的提示tokenized_inputs = self.PaliGemma.llm(obs.tokenized_prompt, method="embed")tokens.append(tokenized_inputs) # 添加文本tokeninput_mask.append(obs.tokenized_prompt_mask) # 添加提示掩碼# 圖像和語言輸入之間完全關注(非自回歸)ar_mask += [False] * tokenized_inputs.shape[1] - 最后,連接所有token和掩碼,其中包含了
# 連接所有token和掩碼tokens = jnp.concatenate(tokens, axis=1) # 在序列維度上連接tokeninput_mask = jnp.concatenate(input_mask, axis=1) # 在序列維度上連接輸入掩碼ar_mask = jnp.array(ar_mask) # 轉換自回歸掩碼為數組return tokens, input_mask, ar_mask # 返回token、輸入掩碼和自回歸掩碼
順便,再回顧下此圖
其次,對于后者embed_suffix
定義如下,其參數包括obs(一般包含圖像和機器人狀態)、noisy_actions、timestep
def embed_suffix(self, obs: _model.Observation, noisy_actions: _model.Actions, timestep: at.Float[at.Array, Any]) -> Tuple[at.Float[at.Array, Any], at.Bool[at.Array, Any], at.Bool[at.Array, Any]]:"""嵌入后綴部分(狀態和動作)"""input_mask = [] # 初始化輸入掩碼列表ar_mask = [] # 初始化自回歸掩碼列表tokens = [] # 初始化token列表其工作流程為
- 狀態處理
將狀態信息投影到embedding空間
并設置為單向注意力(True),表明圖像和語言輸入不能關注狀態信息,因為image/language do not attend to state or actions# 添加單個狀態tokenstate_token = self.state_proj(obs.state)[:, None, :] # 投影狀態并添加序列維度tokens.append(state_token) # 添加狀態token# 添加狀態掩碼(全為1),表示這個狀態token是有效的input_mask.append(jnp.ones((obs.state.shape[0], 1), dtype=jnp.bool_))# 圖像/語言輸入不關注狀態或動作(自回歸)ar_mask += [True] - 時間步嵌入,使用正弦-余弦位置編碼生成時間步嵌入
# 使用正弦余弦位置編碼嵌入時間步,敏感度范圍為[0, 1]time_emb = posemb_sincos(timestep, self.action_in_proj.out_features, min_period=4e-3, max_period=4.0) - 動作和時間信息融合,比如通過action_time_tokens連接:「帶噪聲的動作」和「時間token」
# 混合時間步 + 動作信息,使用MLPaction_tokens = self.action_in_proj(noisy_actions) # 投影帶噪聲的動作# 重復時間嵌入以匹配動作序列長度time_tokens = einops.repeat(time_emb, "b emb -> b s emb", s=self.action_horizon)# 連接動作和時間tokenaction_time_tokens = jnp.concatenate([action_tokens, time_tokens], axis=-1) - MLP處理
使用兩層MLP和swish激活函數對「動作和時間的組合表示」進行非線性變換,以進一步融合:(噪聲)動作和時間信息# 通過MLP處理action_time_tokens = self.action_time_mlp_in(action_time_tokens) # 輸入層action_time_tokens = nnx.swish(action_time_tokens) # Swish激活函數action_time_tokens = self.action_time_mlp_out(action_time_tokens) # 輸出層 - 注意力掩碼設置
第一個動作token設置為單向注意力「上面說過了的,單向注意力,用ar_mask = true表示」,其余動作tokens之間設置為雙向注意力# 添加動作時間tokentokens.append(action_time_tokens)# 添加掩碼(全為1),表示所有動作token都是有效的input_mask.append(jnp.ones(action_time_tokens.shape[:2], dtype=jnp.bool_)) # 圖像/語言/狀態輸入不關注動作token(動作第一個是自回歸的——單向,其余不是——雙向)ar_mask += [True] + ([False] * (self.action_horizon - 1)) - 最后連接所有token和掩碼
# 連接所有token和掩碼tokens = jnp.concatenate(tokens, axis=1) # 在序列維度上連接tokeninput_mask = jnp.concatenate(input_mask, axis=1) # 在序列維度上連接輸入掩碼ar_mask = jnp.array(ar_mask) # 轉換自回歸掩碼為數組return tokens, input_mask, ar_mask # 返回token、輸入掩碼和自回歸掩碼
1.2.4.3 損失函數compute_loss:訓練模型去噪的準確率
總的來講
- 訓練的時候,對其中的「原始動作action」數據加噪,最后去預測所添加的真實噪聲
,預測噪聲的結果為
,然后計算預測噪聲
也就是說,訓練時的本質 其實是為了讓模型具備生成真正想要動作的能力,以確保在推理時,能得到真正想要動作的能力
那可能有同學疑問了,既然通過對原始動作加噪
減掉預測噪聲
其實我之前在此文《圖像生成發展起源:從VAE、擴散模型DDPM、DDIM到DETR、ViT、Swin transformer》中的「2.1.1 從擴散模型概念的提出到DDPM(含U-Net網絡的簡介)、DDIM」已經講了,原因在于
1 對噪聲的預測,比對動作的預測更容易,一者 預測噪聲收斂更穩定,二者 噪聲通常是標準化的,比如高斯噪聲的均值為0 方差為1,使得模型預測噪聲時不需要適應不同尺度的輸出
2? - 如此,便可以在推理的時候,針對一個隨機生成的純噪聲,基于observation(包含圖像和機器人狀態),逐步去噪生成機器人的動作序列
具體而言,compute_loss實現了擴散模型的訓練損失計算
- 對輸入觀察進行預處理,其中
preprocess_rng用于觀察預處理(比如圖像增強等)
noise_rng用于生成噪聲
time_rng用于從beta分布采樣時間步def compute_loss(self, rng: at.KeyArrayLike, observation: _model.Observation, actions: _model.Actions, *, train: bool = False) -> at.Float[at.Array, Any]:"""計算擴散模型的損失函數"""# 分割隨機數生成器為三部分,用于不同的隨機操作preprocess_rng, noise_rng, time_rng = jax.random.split(rng, 3) - 生成隨機噪聲并采樣時間點 t
# 獲取動作的批次形狀batch_shape = actions.shape[:-2]# 生成與動作相同形狀的高斯噪聲noise = jax.random.normal(noise_rng, actions.shape)# 從Beta分布采樣時間點,范圍為[0.001, 1],Beta(1.5, 1)偏向較低的值time = jax.random.beta(time_rng, 1.5, 1, batch_shape) * 0.999 + 0.001# 擴展時間維度以匹配動作形狀time_expanded = time[..., None, None] -
創建帶噪動作序列 x_t,相當于x_t是噪聲化的動作,隨著時間從0到1,原始動作
逐漸添加真實噪聲
而
故所添加的噪聲?# 創建帶噪聲的動作:t * noise + (1-t) * actionsx_t = time_expanded * noise + (1 - time_expanded) * actions# 計算真實噪聲減去動作的差異,這是模型需要預測的目標u_t = noise - actions - 嵌入前綴和后綴
# 一次性前向傳遞前綴+后綴# 嵌入前綴(圖像和文本)prefix_tokens, prefix_mask, prefix_ar_mask = self.embed_prefix(observation)# 嵌入后綴(狀態和帶噪聲的動作)suffix_tokens, suffix_mask, suffix_ar_mask = self.embed_suffix(observation, x_t, time) - 構建注意力掩碼和位置編碼
根據下圖
可得# 連接掩碼:通過鏈接前綴和后綴的掩碼,從而創建完整的輸入掩碼input_mask = jnp.concatenate([prefix_mask, suffix_mask], axis=1)ar_mask = jnp.concatenate([prefix_ar_mask, suffix_ar_mask], axis=0)# 創建注意力掩碼make_attn_mask,從而控制不同token之間的可見性attn_mask = make_attn_mask(input_mask, ar_mask)# 計算位置編碼positions = jnp.cumsum(input_mask, axis=1) - 1 - 模型前向傳播,即調用PaliGemma進行推理,處理前綴和后綴token
當然了,輸出中我們只關注與后綴相關的部分,因為其中包含了我們想要的動作預測的部分# 通過PaLI-Gemma模型處理token_, suffix_out = self.PaliGemma.llm([prefix_tokens, suffix_tokens], mask=attn_mask, positions=positions) - 預測噪聲
# 將模型輸出投影回動作空間v_t = self.action_out_proj(suffix_out[:, -self.action_horizon :]) - 計算預測噪聲
# 返回預測噪聲和真實噪聲之間的均方誤差return jnp.mean(jnp.square(v_t - u_t), axis=-1)
注解 LeRobotDataset:訓練數據集的來源(即訓練數據集長什么樣)
不知道有沒有同學會疑問這段代碼里面的數據集 是從哪來的,比如原始動作action 從哪來的,我暫且不管有沒有疑惑,假設有人有此疑惑,故我來解釋下數據集的來源途徑
π0主要使用兩種數據集:
- FakeDataset - 生成隨機數據用于測試
- LeRobotDataset?- 真實的機器人操作數據
LeRobotDataset 是一個專為機器人學習設計的數據集格式,來自`lerobot.common.datasets.lerobot_dataset`模塊。這個數據集包含了訓練π0模型所需的觀察數據和動作數據,其包含
- Aloha數據集,側重雙臂協同的精確操作,適合特定任務的模仿學習,比如這個是打開筆帽的任務
- Libero數據集,注重多樣化任務和泛化能力,適合語言引導的通用機器人控制
LeRobotDataset 數據通常包含以下幾個關鍵部分:
- 觀察數據 (Observation)
圖像數據:來自不同攝像頭的圖像狀態數據:機器人的關節角度等狀態信息"observation.images.cam_high" "observation.images.cam_low" "observation.images.cam_left_wrist" "observation.images.cam_right_wrist""observation.state"- 動作數據 (Actions)
動作序列:每個時間步的機器人動作指令時間戳信息:通過`delta_timestamps`定義的時間間隔"action"- 任務信息
任務描述:可用于生成提示(prompt)
元數據:包括幀率(fps)等信息數據集示例
- ALOHA數據集
physical-intelligence/aloha_pen_uncap_diverse其中,14維機器人狀態向量的含義{"observation": {"images": {"cam_high": np.ndarray(shape=(3, 224, 224), dtype=np.uint8),"cam_left_wrist": np.ndarray(shape=(3, 224, 224), dtype=np.uint8),"cam_right_wrist": np.ndarray(shape=(3, 224, 224), dtype=np.uint8)},"state": np.ndarray(shape=(14,), dtype=np.float32)},"action": np.ndarray(shape=(14,), dtype=np.float32),"prompt": "uncap the pen" }[# 左臂關節角度 (6維)left_shoulder_pitch,left_shoulder_roll,left_shoulder_yaw,left_elbow_pitch,left_elbow_roll,left_wrist_pitch,# 左手爪狀態 (1維)left_gripper,# 右臂關節角度 (6維)right_shoulder_pitch,right_shoulder_roll,right_shoulder_yaw,right_elbow_pitch,right_elbow_roll,right_wrist_pitch,# 右手爪狀態 (1維)right_gripper ]- 一個LeRobotDataset的樣本可能看起來像這樣
比如Libero數據集:physical-intelligence/libero再比如{"observation": {"images": {# 高視角RGB圖像,224x224x3"cam_high": np.ndarray(shape=(224, 224, 3), dtype=np.uint8),# 低視角RGB圖像"cam_low": np.ndarray(shape=(224, 224, 3), dtype=np.uint8),# 左手腕視角RGB圖像"cam_left_wrist": np.ndarray(shape=(224, 224, 3), dtype=np.uint8),# 右手腕視角RGB圖像"cam_right_wrist": np.ndarray(shape=(224, 224, 3), dtype=np.uint8)},# 機器人狀態向量,包含關節角度等信息"state": np.ndarray(shape=(14,), dtype=np.float32), },# 動作序列,50個時間步,每步14維動作向量"actions": np.ndarray(shape=(50, 14), dtype=np.float32),# 任務描述文本"prompt": "fold the towel" }{"observation": {"images": {"cam_high": <224x224x3 RGB image of robot workspace from above>,"cam_left_wrist": <224x224x3 RGB image from left gripper>,"cam_right_wrist": <224x224x3 RGB image from right gripper>},"state": [0.1, -0.5, 0.3, ...], # 14維機器人關節狀態},"actions": [[0.1, -0.2, 0.3, ...], # t=0時刻的動作[0.15, -0.25, 0.35, ...], # t=1時刻的動作... # 共50個時間步],"prompt": "pick up the blue cube and place it in the red bowl" }

真實數據來自`lerobot_dataset`模塊,通過以下代碼加載——下文「2.2.2?create_dataset:創建適合訓練的數據集」還會詳解:
dataset_meta = lerobot_dataset.LeRobotDatasetMetadata(repo_id, local_files_only=data_config.local_files_only)
dataset = lerobot_dataset.LeRobotDataset(data_config.repo_id,delta_timestamps={key: [t / dataset_meta.fps for t in range(model_config.action_horizon)]for key in data_config.action_sequence_keys},local_files_only=data_config.local_files_only,
)這里的`repo_id`指向一個特定的數據倉庫,是Hugging Face上的數據集或其他存儲位置。數據集通過配置文件中的參數指定,例如我們在`config.py`中看到的配置——下文「2.1 配置系統 (config.py)」還會詳解:
# Inference Aloha configs.#TrainConfig(name="pi0_aloha",model=pi0.Pi0Config(),data=LeRobotAlohaDataConfig(assets=AssetsConfig(asset_id="trossen"),),),以下是對數據流程總結
- 從LeRobot數據集加載原始數據,包含觀察(observation)和動作(action)
- 通過數據轉換管道處理數據,包括重打包和歸一化
- 在訓練期間,向原始動作添加噪聲
- 模型學習預測添加的噪聲,而不是直接預測原始動作
- 在推理時,模型從純噪聲開始,通過迭代去噪過程生成動作序列
這種基于擴散的方法允許π0從噪聲中逐步精煉動作,最終生成平滑且符合任務要求的機器人動作序列
1.2.4.4 推理函數 `sample_actions`:基于擴散模型逆向采樣(即去噪),生成機器人動作序列?
sample_actions函數是Pi0模型的核心推理方法,實現了基于擴散模型的逆向采樣過程——說白了 就是去噪,它從純噪聲開始,通過多步驟逐漸"去噪",最終生成符合條件分布的機器人動作序列
函數的核心是一個基于while循環的迭代過程,每一步都使用訓練好的神經網絡預測從當前噪聲化動作到目標動作的方向——從噪聲到目標的方向 代表速度場,畢竟咱們去噪的方向得對 不然就去歪了
總之,這個函數將觀察數據(圖像和可選的文本提示)轉換為具體的動作軌跡,是模型部署時的主要接口,簡言之,其包含以下流程
- 首先從純噪聲開始 (t=1)
- 通過重復迭代降噪步驟,逐步將噪聲轉化為有意義的動作序列
- 使用KV緩存優化推理速度
- 實現了一個迭代降噪過程
- 最終返回完全降噪后的動作序列 x_0
具體而言,包含如下步驟
第一,初始化
首先,函數對輸入觀察數據進行預處理,包括標準化圖像大小等操作
def sample_actions(self,rng: at.KeyArrayLike, # 隨機數生成器observation: _model.Observation, # 觀察輸入,包含圖像和文本等*,num_steps: int = 10, # 擴散過程的步數,默認為10步
) -> _model.Actions: # 返回生成的動作序列# 對觀察數據進行預處理,不進行訓練時的數據增強observation = _model.preprocess_observation(None, observation, train=False)然后設置時間步長`dt`為負值(因為是從t=1向t=0方向演化),生成初始隨機噪聲作為起點,且時間上約定:"t=1是噪聲,t=0是目標分布",這是擴散文獻中常見的約定,不過與Pi0論文相反
# 注意:這里使用擴散模型文獻中更常見的約定,t=1是噪聲,t=0是目標分布# 這與pi0論文相反dt = -1.0 / num_steps # 計算時間步長,從1到0batch_size = observation.state.shape[0] # 獲取批次大小# 生成初始噪聲,形狀為[批次大小, 動作序列長度, 動作維度]noise = jax.random.normal(rng, (batch_size, self.action_horizon, self.action_dim))第二,Key-Value緩存初始化(預計算并存儲前綴表示,減少冗余計算)
處理觀察數據,得到前綴表示和相關掩碼
# 首先通過前綴的前向傳遞填充KV緩存# 獲取前綴的token表示和掩碼prefix_tokens, prefix_mask, prefix_ar_mask = self.embed_prefix(observation)# 創建前綴的注意力掩碼prefix_attn_mask = make_attn_mask(prefix_mask, prefix_ar_mask)# 計算位置編碼positions = jnp.cumsum(prefix_mask, axis=1) - 1然后使用PaliGemma語言模型進行一次前向傳遞,生成Key-Value緩存(`kv_cache`)——這是一個性能優化:因為前綴部分在整個采樣過程中保持不變,預先計算并緩存它們的表示可以避免重復計算
# 進行前向傳遞,獲取KV緩存_, kv_cache = self.PaliGemma.llm([prefix_tokens, None], mask=prefix_attn_mask, positions=positions)第三,通過step函數構建注意力掩碼系統并讓PaliGemma做推理
核心迭代通過 `jax.lax.while_loop` 實現
根據源碼
可知,該class Pi0(_model.BaseModel)類的最后兩行是
# 使用while循環進行迭代采樣,從t=1(噪聲)開始x_0, _ = jax.lax.while_loop(cond, step, (noise, 1.0))# 返回最終的去噪結果(生成的動作序列)return x_0

具體而言,包含 `step` 函數和 `cond` 函數,其中,`step` 函數是每次迭代的核心
首先,step函數通過 `embed_suffix` 處理當前狀態,包括狀態信息嵌入、噪聲化動作、時間步編碼
def step(carry):"""定義單步去噪函數"""x_t, time = carry # carry數組包含當前狀態和時間# 將時間廣播到批次維度,并嵌入后綴(狀態和動作)suffix_tokens, suffix_mask, suffix_ar_mask = self.embed_suffix(observation, x_t, jnp.broadcast_to(time, batch_size))其次,構建復雜的注意力掩碼系統,處理前綴-后綴之間的注意力關系——這個復雜的掩碼系統允許后綴token(包括狀態和動作)有選擇地關注前綴token(圖像和文本),實現了條件生成,具體而言,其構建了三層注意力掩碼:
- 后綴內部注意力掩碼,控制后綴token(狀態和動作)之間的注意力關系
# 創建后綴內部的注意力掩碼,形狀為(批次, 后綴長度, 后綴長度)suffix_attn_mask = make_attn_mask(suffix_mask, suffix_ar_mask)- 前綴-后綴注意力掩碼,控制后綴token如何關注前綴token(圖像和文本輸入)
# 創建后綴對前綴的注意力掩碼,形狀為(批次, 后綴長度, 前綴長度)prefix_attn_mask = einops.repeat(prefix_mask, "b p -> b s p", s=suffix_tokens.shape[1])- 完整注意力掩碼,將前兩個掩碼組合,形成完整的注意力控制機制
# 組合掩碼,形狀為(批次, 后綴長度, 前綴長度+后綴長度)# 控制后綴token(生成查詢)如何關注完整序列(生成鍵和值)full_attn_mask = jnp.concatenate([prefix_attn_mask, suffix_attn_mask], axis=-1)當然了,過程中還做了形狀檢查,確保張量維度正確
# 驗證掩碼形狀正確assert full_attn_mask.shape == (batch_size,suffix_tokens.shape[1],prefix_tokens.shape[1] + suffix_tokens.shape[1],)接著,計算位置編碼,為后綴token計算其在完整序列中的位置,這對于Transformer模型理解序列順序很重要
# 計算后綴token的位置編碼positions = jnp.sum(prefix_mask, axis=-1)[:, None] + jnp.cumsum(suffix_mask, axis=-1) - 1之后,模型推理,使用PaliGemma語言模型進行推理,利用緩存的前綴信息(`kv_cache`)提高效率
# 使用KV緩存進行高效的前向傳遞(prefix_out, suffix_out), _ = self.PaliGemma.llm([None, suffix_tokens], mask=full_attn_mask, positions=positions, kv_cache=kv_cache)# 且確保前綴輸出為None(因為使用了KV緩存)assert prefix_out is None第四,step函數中做最后的速度預測與動作更新(去噪)
在每一步中,模型預測速度場 `v_t`(從噪聲到目標的方向),并通過類歐拉法更新動作表示——使用簡單而有效的歐拉方法進行軌跡采樣
本質就是對去噪,而
便是預測的噪聲,
是時間步長——如上面說過的「時間步長`dt`為負值(因為是從t=1向t=0方向演化),生成初始隨機噪聲作為起點,且時間上約定:"t=1是噪聲,t=0是目標分布"」
具體而言
- 一方面,提取模型輸出并預測速度場`v_t`——相當于本質是通過PaliGemma模型預測去噪方向 `v_t`
# 預測噪聲v_t = self.action_out_proj(suffix_out[:, -self.action_horizon :])- 二方面,使用歐拉法更新動作狀態和時間步
# 使用歐拉方法更新狀態和時間return x_t + dt * v_t, time + dt至于cond函數確定何時停止迭代,通過檢查時間是否接近零(當然,要考慮浮點精讀可能存在的誤差)
def cond(carry):"""定義循環終止條件"""x_t, time = carry# 考慮浮點誤差,當時間接近0時停止return time >= -dt / 21.3 語言模型實現:models/gemma.py
src/openpi/models/gemma.py實現了Gemma語言模型的核心組件,定義了RMSNorm、Embedder、Attention、FeedForward等模塊,且提供了不同規模Gemma模型的配置(300M, 2B等)
// 待更
1.4 視覺模型實現:models/siglip.py
`siglip.py`:?實現了視覺編碼器,基于Vision Transformer (ViT),定義了位置編碼、注意力池化等組件,支持不同大小的模型變體
// 待更
1.5?tokenizer.py: 提供文本tokenization功能
這段代碼實現了兩個相關但功能不同的tokenizer類:`PaligemmaTokenizer` 和 `FASTTokenizer`
1.5.1 PaligemmaTokenizer 類:專門處理文本prompt
`PaligemmaTokenizer` 是一個相對簡單的Tokenizer,專門處理文本prompt
第一方面,在初始化階段
- `__init__` 方法接收一個 `max_len` 參數(默認為 48)來設定token序列的最大長度
# 初始化方法,設置最大token長度,默認為48def __init__(self, max_len: int = 48): # 存儲最大token長度self._max_len = max_len - 接著,它調用 `download.maybe_download` 函數從 Google Cloud Storage 獲取預訓練的 PaliGemma 分詞模型
這個下載機制設計得很智能:如果本地緩存中已存在該模型,則直接使用,避免重復下載;否則,會創建一個鎖文件確保并發安全,并從 `gs://big_vision/paligemma_tokenizer.model` 下載模型文件。參數 `gs={"token": "anon"}` 表示使用匿名方式訪問 GCS 存儲桶# 下載PaliGemma分詞器模型path = download.maybe_download("gs://big_vision/paligemma_tokenizer.model", gs={"token": "anon"}) - 下載完成后,代碼以二進制讀取模式打開文件,并使用 SentencePiece 處理器加載模型
# 以二進制讀取模式打開下載的模型文件with path.open("rb") as f: # 初始化SentencePiece處理器self._tokenizer = sentencepiece.SentencePieceProcessor(model_proto=f.read())
第二方面,`tokenize` 方法是處理文本輸入的核心,它執行以下步驟:
- 文本清理:首先通過 `strip()` 去除首尾空白,然后將下劃線替換為空格,并將換行符也替換為空格,確保輸入文本格式一致
# 定義分詞方法,輸入為提示文本,返回tokens和maskdef tokenize(self, prompt: str) -> tuple[np.ndarray, np.ndarray]: # 清理文本:移除首尾空格,將下劃線和換行符替換為空格cleaned_text = prompt.strip().replace("_", " ").replace("\n", " ") - Tokenizer:將清理后的文本送入 SentencePiece 編碼器,設置 `add_bos=True` 添加句子開始token
特別的是,它還單獨編碼了一個換行符 `\n` 并將其附加到token序列末尾,作為"答案開始"的特殊token。這種設計允許模型明確區分提示和生成內容的邊界# 單獨將"\n"作為"答案開始"的token# 對清理后的文本編碼,添加開始標記,并附加換行符的編碼tokens = self._tokenizer.encode(cleaned_text, add_bos=True) + self._tokenizer.encode("\n") - 長度處理:根據實際編碼后的token序列長度
代碼采取兩種策略:# 獲取token列表長度tokens_len = len(tokens)
# 如果token長度小于最大長度if tokens_len < self._max_len: # 創建填充列表,用False填充padding = [False] * (self._max_len - tokens_len) # 創建mask列表,真實token位置為True(如此,填充位置自然為False)mask = [True] * tokens_len + padding # 對token列表進行填充tokens = tokens + padding# 如果token長度大于或等于最大長度else: # 如果token長度大于最大長度if len(tokens) > self._max_len: # 記錄警告日志logging.warning( # 警告token長度超出最大長度,將進行截斷f"Token length ({len(tokens)}) exceeds max length ({self._max_len}), truncating. " # 建議如果頻繁發生,增加模型配置中的最大token長度"Consider increasing the `max_token_len` in your model config if this happens frequently." )# 截斷token列表,只保留前max_len個tokens = tokens[: self._max_len] # 創建全True的mask列表,長度為max_lenmask = [True] * self._max_len - 返回結果:最后,方法將token序列和掩碼轉換為 NumPy 數組并返回,便于后續的模型處理
# 將token列表和mask列表轉換為numpy數組并返回return np.asarray(tokens), np.asarray(mask)
1.5.2 FASTTokenizer 類
`FASTTokenizer` 是一個更復雜的Tokenizer,可同時處理文本和動作數據,詳見此文《π0開源了且推出自回歸版π0-FAST——打造高效Tokenizer:比擴散π0的訓練速度快5倍但效果相當(含π0-FAST源碼剖析)》
首先是初始化過程
- 同樣下載 PaliGemma Tokenizer模型
# 定義FAST分詞器類 class FASTTokenizer: # 初始化方法,設置最大長度和FAST分詞器路徑def __init__(self, max_len: int = 256, fast_tokenizer_path: str = "physical-intelligence/fast"): # 存儲最大token長度self._max_len = max_len # 下載PaliGemma分詞器模型path = download.maybe_download("gs://big_vision/paligemma_tokenizer.model", gs={"token": "anon"}) # 以二進制讀取模式打開模型文件with path.open("rb") as f: self._paligemma_tokenizer = sentencepiece.SentencePieceProcessor(model_proto=f.read() - 加載專門的 FAST Tokenizer——用于處理動作序列
# 實例化FAST分詞器# 從預訓練路徑加載FAST處理器self._fast_tokenizer = AutoProcessor.from_pretrained(fast_tokenizer_path, trust_remote_code=True) - 設置 `_fast_skip_tokens = 128` 以跳過 PaliGemma 詞匯表末尾的特殊token
# 跳過PaliGemma詞表中的最后128個token,因為它們是特殊tokenself._fast_skip_tokens = 128
其次,是Tokenizer流程
- 接收文本提示、狀態數組和可選的動作數組
# 定義分詞方法def tokenize( # 輸入:提示文本、狀態數組和可選的動作數組self, prompt: str, state: np.ndarray, actions: np.ndarray | None # 返回四個numpy數組:tokens、token_mask、ar_mask和loss_mask) -> tuple[np.ndarray, np.ndarray, np.ndarray, np.ndarray]: # 清理文本:轉小寫,移除首尾空格,將下劃線替換為空格cleaned_text = prompt.lower().strip().replace("_", " ") - 將狀態值離散化為 256 個區間(范圍 [-1, 1])
# 約定:狀態被離散化為256個離散區間(假設歸一化后的范圍:[-1, 1])# 將狀態數組離散化為0-255的整數discretized_state = np.digitize(state, bins=np.linspace(-1, 1, 256 + 1)[:-1]) - 1 - 創建格式化前綴prefix,包含文本提示和狀態信息
# 約定:前綴包括提示和狀態的字符串表示,后跟';'# 將離散化狀態轉換為空格分隔的字符串state_str = " ".join(map(str, discretized_state)) # 構建前綴文本,包含任務和狀態信息prefix = f"Task: {cleaned_text}, State: {state_str};\n" # 使用PaliGemma分詞器編碼前綴,添加開始tokenprefix_tokens = self._paligemma_tokenizer.encode(prefix, add_bos=True) - 如果提供了動作:
使用 FAST Tokenizer對動作進行Tokenizer
通過 `_act_tokens_to_paligemma_tokens` 將這些動作token映射到 PaliGemma 詞匯表中# 如果提供了動作if actions is not None: # 使用FAST分詞器對動作進行分詞,并映射到PaliGemma詞表的最后部分# 將動作轉換為tokenaction_tokens = self._fast_tokenizer(actions[None])[0]
創建包含 "Action:" 的后綴,后跟編碼的動作和結束符 "|"# 將FAST token轉換為PaliGemma tokenaction_tokens_in_pg = self._act_tokens_to_paligemma_tokens(action_tokens)# 約定:后綴包含'Action:',然后是FAST token,最后是'|'# 構建后綴tokenpostfix_tokens = ( # 編碼"Action: "文本self._paligemma_tokenizer.encode("Action: ") # 添加轉換后的動作token+ action_tokens_in_pg.tolist() # 添加結束分隔符'|'的編碼+ self._paligemma_tokenizer.encode("|") )# 如果沒有提供動作else: # 后綴token為空列表postfix_tokens = [] - 創建三種掩碼:
# 創建輸出token序列和掩碼# AR掩碼在前綴上為0(雙向注意力),在后綴上為1(對所有先前token的因果注意力)# 合并前綴和后綴tokentokens = prefix_tokens + postfix_tokens # 創建token掩碼,全為Truetoken_mask = [True] * len(tokens) # 創建自回歸掩碼,前綴部分為0,后綴部分為1ar_mask = [0] * len(prefix_tokens) + [1] * len(postfix_tokens) # 創建損失掩碼,僅在后綴部分計算損失loss_mask = [False] * len(prefix_tokens) + [True] * len(postfix_tokens) - 處理所有token序列和掩碼的填充或截斷
別忘了,上文所說的
1.2.4.2 特征嵌入方法:embed_prefix(圖像和文本輸入)、embed_suffix(狀態和動作信息)
- `embed_prefix`:處理圖像和文本輸入(圖像通過SigLip模型編碼,文本通過Gemma LLM編碼),創建前綴 token,皆為雙向注意力,用ar_mask = false表示
- `embed_suffix`:處理機器人狀態信息
其中
再其次,是動作提取功能
- 從token序列中提取動作
# 定義從token中提取動作的方法def extract_actions(self, tokens: np.ndarray, action_horizon: int, action_dim: int) -> np.ndarray: # 解碼預測的輸出token —— 將token列表解碼為文本decoded_tokens = self._paligemma_tokenizer.decode(tokens.tolist()) - 定位 "Action:" 后和 "|" 前的部分
# 從FAST模型輸出中提取動作:如果解碼文本中不包含"Action: "if "Action: " not in decoded_tokens: # 返回全零動作數組return np.zeros((action_horizon, action_dim), dtype=np.float32) - 重新映射token以恢復原始動作空間
# 從解碼的token中提取動作raw_action_tokens = np.array( # 提取"Action: "和"|"之間的內容,并編碼為tokenself._paligemma_tokenizer.encode(decoded_tokens.split("Action: ")[1].split("|")[0].strip()))# 將原始action token轉換為PaliGemma token格式action_tokens = self._act_tokens_to_paligemma_tokens(raw_action_tokens) # 使用FAST分詞器將token解碼為動作向量return self._fast_tokenizer.decode( [action_tokens.tolist()], time_horizon=action_horizon, action_dim=action_dim)[0]
最后是token映射函數
# 定義將FAST token轉換為PaliGemma token的方法def _act_tokens_to_paligemma_tokens(self, tokens: np.ndarray | list[int]) -> np.ndarray: # 如果輸入是列表if isinstance(tokens, list): # 轉換為numpy數組tokens = np.array(tokens) # 將FAST token映射到PaliGemma詞表的對應位置return self._paligemma_tokenizer.vocab_size() - 1 - self._fast_skip_tokens - tokens- `_act_tokens_to_paligemma_tokens` 方法實現了 FAST 動作token到 PaliGemma 詞匯空間的雙向映射
- 計算公式:`vocab_size - 1 - skip_tokens - token_id`
- 這種巧妙的映射讓兩個不同的Tokenizer系統能夠協同工作
1.6 `lora.py` :實現了LoRA (Low-Rank Adaptation)微調方法
如之前所述,「關于什么是LoRA,詳見此文《LLM高效參數微調方法:從Prefix Tuning、Prompt Tuning、P-Tuning V1/V2到LoRA、QLoRA(含對模型量化的解釋)》的第4部分」
1.6.1?Einsum類中的setup
`setup` 方法,負責初始化模塊所需的所有參數
- 首先,方法通過調用 `self.param` 創建了一個名為 "w" 的參數,這是模塊的主要權重矩陣
- 接下來,代碼使用海象運算符(`:=`)檢查是否提供了 `lora_config`。如果存在配置,則進入 LoRA 參數的初始化流程
LoRA 的核心思想是將權重更新分解為兩個低秩矩陣 A 和 B 的乘積。為此,代碼首先創建了原始形狀的可變副本 `shape_a` 和 `shape_b`,使用 `list()` 將可能是元組的 `self.shape` 轉換為可修改的列表 - 隨后,`shape_a` 的第二個指定軸(由 `config.axes[1]` 索引)被替換為 `config.rank`
而 `shape_b` 的第一個指定軸(由 `config.axes[0]` 索引)也被替換為相同的 `config.rank`
說白了,就是A矩陣是降維矩陣,故第二個指定軸是rank
b是升維矩陣,故b的第一個指定軸是rank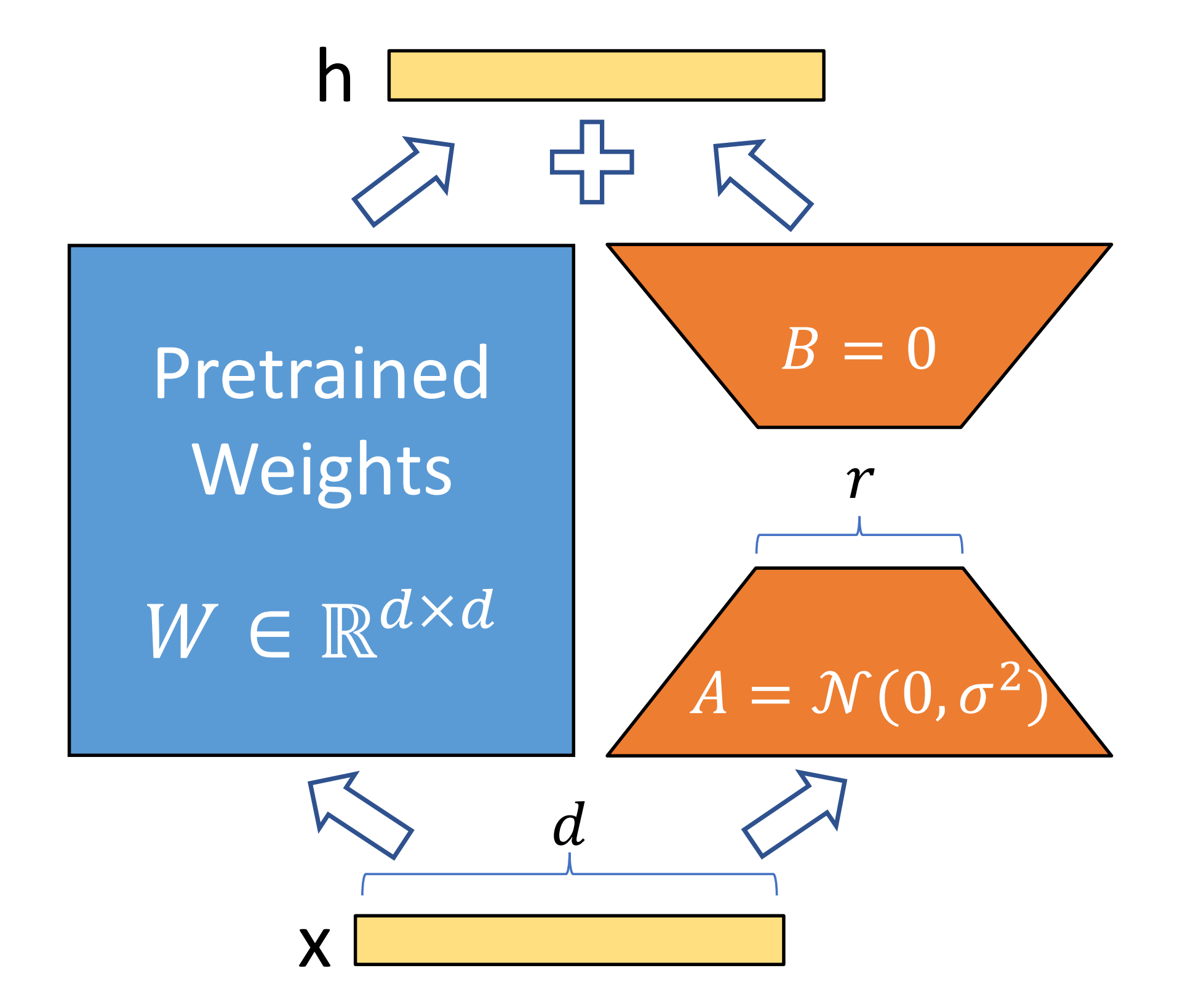
- 最后,代碼使用 `config.init_fn` 初始化函數(通常是一個小標準差的正態分布)和修改后的形狀,創建了兩個 LoRA 參數:`self.w_a` 和 `self.w_b`。這些參數分別對應于 LoRA 的 A 和 B 矩陣,它們將在前向傳播過程中用于計算 LoRA 更新
1.6.2?Einsum類中的__call__
`__call__` 方法實現了支持 LoRA (Low-Rank Adaptation) 技術的前向傳播邏輯
- 首先,方法獲取并存儲輸入張量 `x` 的數據類型 (`dtype`)
- 接下來,方法使用 `jnp.einsum` 函數計算標準的 Einstein 求和乘積,將輸入 `x` 與權重矩陣 `self.w` 相乘。注意權重矩陣會被顯式轉換為與輸入相同的數據類型,這是通過 `self.w.astype(dtype)` 實現的
此操作產生的 `result` 變量表示不帶 LoRA 修正的基礎輸出 - 如果模塊配置了 LoRA(通過 `self.lora_config` 存在),代碼會進入 LoRA 計算分支。使用海象運算符 (`:=`) 既檢查了 `lora_config` 的存在性,又將其賦值給局部變量 `config` 以便后續使用
LoRA 計算過程首先調用 `self._make_lora_eqns` 方法,將原始 einsum 方程轉換為兩個新方程 `eqn_a` 和 `eqn_b`,分別用于與 LoRA 矩陣 A 和 B 的乘法運算
然后,代碼執行這兩個 einsum 運算:第一個將輸入 `x` 與矩陣 A (`self.w_a`) 相乘,結果存儲在 `lora` 變量中;第二個將 `lora` 與矩陣 B (`self.w_b`) 相乘,更新 `lora` 變量
同樣,為保持數值一致性,LoRA 參數也會被轉換為與輸入相同的數據類型
最后,將 LoRA 計算結果乘以配置中指定的縮放值 (`config.scaling_value`)——縮放因子通常設置為 `alpha/rank` 或對于 RS-LoRA 為 `alpha/sqrt(rank)`,并將其添加到基礎輸出中,形成最終結果
1.6.3?Einsum類中的_make_lora_eqns
_make_lora_eqns負責將標準的 Einstein 求和表達式轉換為兩個新的表達式,以支持 LoRA 的低秩分解計算。其工作原理基于巧妙的字符串處理,將一個矩陣乘法操作分解為兩個連續的矩陣乘法
- 方法首先執行兩項重要的驗證
如果存在,方法會拋出 `ValueError` 異常,因為 "L" 被保留用作 LoRA 的特殊維度標識符def _make_lora_eqns(self, eqn: str) -> tuple[str, str]:if "L" in eqn:raise ValueError(f"L already in eqn: {eqn}")
如果方程格式不符合此模式,方法會拋出另一個 `ValueError`
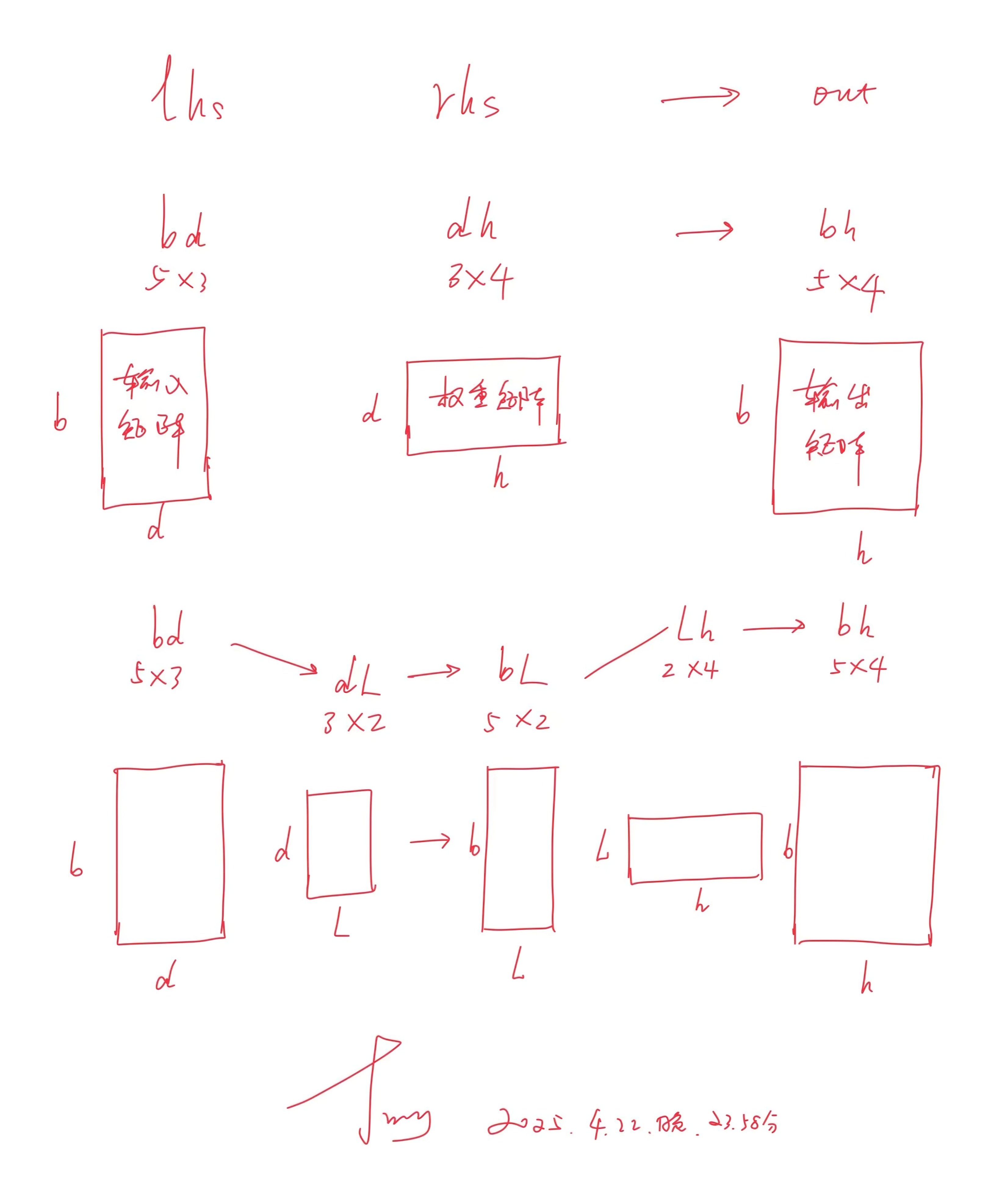
成功匹配后,方法通過調用 `m.groups()` 提取這三個組件,并將它們分別存儲在 `lhs`、`rhs` 和 `out` 變量中if not (m := re.match("(.*),(.*)->(.*)", eqn)):raise ValueError(f"Unsupported einsum eqn: {eqn}")例如,對于方程 "bd,dh->bh",這些變量將分別包含 "bd"、"dh" 和 "bh"lhs, rhs, out = m.groups() - 接下來是方法的核心部分
首先,根據 `self.lora_config.axes` 指定的索引,從 `rhs` 字符串中提取兩個關鍵軸標簽 `a_label` 和 `b_label`
例如,如果 `rhs` 是 "dh" 且 `axes` 為 (-2, -1)——代表最后兩個軸,則assert self.lora_config is not Nonea_label, b_label = (rhs[x] for x in self.lora_config.axes)label = self.lora_config.label
`a_label` 為 "d"
`b_label` 為 "h"
其次,進行兩步字符串替換,創建兩個新的 einsum 方程
例如,對于前面 "lhs,rhs->out所對應的例子"bd,dh->bh",`a_rhs`-dh 會變成 "dL",`a_out`-bh 會變成 "bL"
生成的 `eqn_a` 為 "bd,dL->bL",表示將輸入bd?與 LoRA 矩陣 A dL相乘,得到此第一步的結果bLa_rhs = rhs.replace(b_label, label)a_out = out.replace(b_label, label)eqn_a = f"{lhs},{a_rhs}->{a_out}"
使用前面 "lhs,rhs->out所對應的例子"bd,dh->bh"
`b_rhs-dh` 將變為 "Lh"
然后構造第二個方程 `eqn_b`,形式為 "bL/bL,Lh->bh"b_rhs = rhs.replace(a_label, label)
為何這里的輸入是bL/bL呢,因為其表示的就是將第一步的結果bL/bL與 LoRA 矩陣 B Lh?相乘eqn_b = f"{a_out},{b_rhs}->{out}" - 最后,方法返回這兩個新創建的 einsum 方程作為元組
這些方程將被用于在前向傳播過程中計算 LoRA 的低秩更新return eqn_a, eqn_b
總的來說,上面的整個過程 還是比較繞的,為方便大家一目了然的快速理解,我特意花了10分鐘畫了個圖示——而我一個人多花10分鐘,可以讓數千人、數萬人在理解上 少花10分鐘,這價值非常大,會更清晰
1.6.4?FeedForward類中的setup、__call__、_dot
1.7 `vit.py`: Vision Transformer實現
// 待更
第二部分 策略適配接口:src下policy的全面分析與解讀
src/openpi/policies目錄包含以下文件:
BasePolicy (policy.py)
├── Policy
│ ? ├── BaseModel
│ ? └── transforms.py
├── AlohaPolicy (aloha_policy.py)
├── DroidPolicy (droid_policy.py)
└── LiberoPolicy (libero_policy.py)
此外,每個特定機器人都有自己的策略文件,如
- aloha_policy.py
- droid_policy.py
- libero_policy.py
這些文件定義了特定于機器人的輸入和輸出轉換函數,處理數據格式、規范化和特定的轉換需求
- 比如每種機器人(ALOHA、DROID、LIBERO)的策略文件定義了特定的輸入/輸出轉換類
- 這些轉換類作為 `transforms` 參數傳遞給 `Policy` 構造函數,例如,`AlohaInputs` 處理 ALOHA 機器人特有的狀態和圖像格式,`AlohaOutputs` 處理對應的輸出轉換
2.1?policy.py:實現了Policy類和 PolicyRecorder類
2.1.1 Policy 類
policy.py 定義了基本的 `Policy` 類和 `PolicyRecorder` 類,它們繼承自`openpi_client.base_policy.BasePolicy`
首先,做一系列初始化
class Policy(BasePolicy): # 定義Policy類,繼承自BasePolicydef __init__(self,model: _model.BaseModel, # 模型參數,必須是BaseModel的實例*, # 之后的所有參數必須使用關鍵字傳遞rng: at.KeyArrayLike | None = None, # 隨機數生成器,可選# 輸入轉換函數序列,默認為空transforms: Sequence[_transforms.DataTransformFn] = (), # 輸出轉換函數序列,默認為空output_transforms: Sequence[_transforms.DataTransformFn] = (), # 傳遞給sample_actions的額外參數,可選sample_kwargs: dict[str, Any] | None = None, metadata: dict[str, Any] | None = None, # 元數據字典,可選):# 使用JIT編譯model的sample_actions方法提高性能self._sample_actions = nnx_utils.module_jit(model.sample_actions) # 組合所有輸入轉換函數為一個函數self._input_transform = _transforms.compose(transforms) # 組合所有輸出轉換函數為一個函數self._output_transform = _transforms.compose(output_transforms) self._rng = rng or jax.random.key(0) # 設置隨機數生成器,如果未提供則創建一個新的self._sample_kwargs = sample_kwargs or {} # 存儲采樣參數,如果未提供則使用空字典self._metadata = metadata or {} # 存儲元數據,如果未提供則使用空字典其次,對于infer 方法——在策略內部流程上
- 復制輸入觀察數據
def infer(self, obs: dict) -> dict: # type: ignore[misc] # 推理方法,接收觀察字典,返回動作字典# 復制輸入,因為轉換可能會修改輸入inputs = jax.tree.map(lambda x: x, obs) # 使用JAX樹映射創建輸入的深拷貝 - 應用輸入轉換
Policy.infer` 方法首先應用輸入轉換:self._input_transform,將客戶端提供的觀察轉換為模型所需的格式inputs = self._input_transform(inputs) # 應用輸入轉換函數處理輸入數據 - 將數據轉換為批處理格式并轉為 JAX 數組
生成新的隨機數鍵# 將輸入轉換為批處理格式并轉為jax數組inputs = jax.tree.map(lambda x: jnp.asarray(x)[np.newaxis, ...], inputs) # 添加批次維度并轉為JAX數組self._rng, sample_rng = jax.random.split(self._rng) # 分割隨機數鍵以保持隨機性 - 模型推理
調用模型的 `sample_actions` 方法「該方法的實現,詳見上文的1.2.4.4 推理函數 `sample_actions`:基于擴散模型逆向采樣,生成機器人動作序列」進行推理,即獲取動作預測outputs = {"state": inputs["state"], # 保留狀態信息"actions": self._sample_actions(sample_rng, _model.Observation.from_dict(inputs), **self._sample_kwargs), # 使用模型生成動作} - 解除批處理并轉換為 NumPy 數組
# 移除批次維度并轉換為NumPy數組outputs = jax.tree.map(lambda x: np.asarray(x[0, ...]), outputs) # 取第一個樣本并轉為NumPy數組 - 輸出轉換
最后應用輸出轉換 (`self._output_transform`),將模型輸出轉換為客戶端期望的格式return self._output_transform(outputs) # 應用輸出轉換并返回結果
2.1.2 `PolicyRecorder`
PolicyRecorder是一個裝飾器類,它包裝了一個基礎策略,并在執行策略的同時將所有的輸入和輸出保存到磁盤,用于記錄策略的行為
對于初始化函數:`policy`,涉及被包裝的基礎策略、record_dir`:保存記錄的目錄路徑
對于infer 方法
- 調用被包裝策略的 `infer` 方法獲取結果
- 將輸入和輸出數據組織為字典
- 使用 Flax 的 `flatten_dict` 函數將嵌套字典展平
- 構建輸出文件路徑
- 將數據保存為 NumPy 數組文件
- 返回策略結果
// 待更
2.2 policy_config.py
policy_config.py 定義了 `PolicyConfig` 類和 `create_trained_policy` 函數
`create_trained_policy` 函數用于從訓練好的檢查點創建策略實例,加載模型參數、歸一化統計數據,并配置轉換函數
相當于客戶端代碼會實例化一個 `Policy` 對象,通常是通過 `create_trained_policy` 函數,客戶端通過調用 `policy.infer(obs)` 方法獲取策略輸出
2.2.1 PolicyConfig 數據類
`PolicyConfig` 是一個使用 `@dataclasses.dataclass` 裝飾的數據類,用于存儲創建策略所需的所有配置信息:
# 定義策略配置類
class PolicyConfig: model: _model.BaseModel # 模型實例,必須是BaseModel類型norm_stats: dict[str, transforms.NormStats] # 歸一化統計信息,鍵是特征名稱,值是歸一化統計數據input_layers: Sequence[transforms.DataTransformFn] # 輸入數據轉換函數序列output_layers: Sequence[transforms.DataTransformFn] # 輸出數據轉換函數序列model_type: _model.ModelType = _model.ModelType.PI0 # 模型類型,默認為PI0default_prompt: str | None = None # 默認提示文本,可選sample_kwargs: dict[str, Any] | None = None # 采樣參數字典,可選這個類主要是作為配置容器,將所有策略創建時需要的參數組織在一起
2.2.2 create_trained_policy 函數
`create_trained_policy` 函數是從訓練好的檢查點創建可用策略的工廠函數
def create_trained_policy(train_config: _config.TrainConfig, # 訓練配置對象,包含訓練時的所有參數設置checkpoint_dir: pathlib.Path | str, # 檢查點目錄路徑,可以是Path對象或字符串*, # 強制后續參數使用關鍵字傳遞repack_transforms: transforms.Group | None = None, # 可選的重新打包轉換組sample_kwargs: dict[str, Any] | None = None, # 采樣參數,可選default_prompt: str | None = None, # 默認提示文本,可選norm_stats: dict[str, transforms.NormStats] | None = None, # 歸一化統計信息,可選
) -> _policy.Policy: # 返回類型是Policy對象函數的核心流程是:
- 處理輸入參數,確保 `repack_transforms` 不為空
且檢查并可能下載檢查點目錄repack_transforms = repack_transforms or transforms.Group() # 確保repack_transforms不為空,如果未提供則創建空Groupcheckpoint_dir = download.maybe_download(str(checkpoint_dir)) # 檢查并可能下載檢查點目錄 - 使用 `train_config` 加載模型參數
logging.info("Loading model...") # 記錄日志,表示正在加載模型# 加載模型參數并創建模型實例,使用bfloat16數據類型model = train_config.model.load(_model.restore_params(checkpoint_dir / "params", dtype=jnp.bfloat16)) - 創建數據配置
data_config = train_config.data.create(train_config.assets_dirs, train_config.model) # 創建數據配置if norm_stats is None: # 如果未提供歸一化統計信息# 我們從檢查點而非配置資源目錄加載歸一化統計信息,以確保策略使用與原始訓練過程相同的歸一化統計信息 - 如果未提供 `norm_stats`,從檢查點加載歸一化統計信息
if data_config.asset_id is None: # 如果數據配置中沒有asset_idraise ValueError("Asset id is required to load norm stats.") # 拋出異常,需要asset_id來加載歸一化統計信息norm_stats = _checkpoints.load_norm_stats(checkpoint_dir / "assets", data_config.asset_id) # 從檢查點加載歸一化統計信息 - 構建并返回 `Policy` 實例,將所有轉換函數組織為有序的處理流程:
輸入處理:重新打包轉換 → 注入默認提示 → 數據轉換 → 歸一化 → 模型特定轉換return _policy.Policy( # 創建并返回Policy實例model, # 傳入模型
輸出處理:模型特定轉換 → 反歸一化 → 數據轉換 → 重新打包轉換transforms=[ # 輸入轉換函數序列*repack_transforms.inputs, # 展開重打包轉換的輸入部分transforms.InjectDefaultPrompt(default_prompt), # 注入默認提示*data_config.data_transforms.inputs, # 展開數據轉換的輸入部分transforms.Normalize(norm_stats, use_quantiles=data_config.use_quantile_norm), # 添加歸一化轉換*data_config.model_transforms.inputs, # 展開模型特定轉換的輸入部分],output_transforms=[ # 輸出轉換函數序列*data_config.model_transforms.outputs, # 展開模型特定轉換的輸出部分transforms.Unnormalize(norm_stats, use_quantiles=data_config.use_quantile_norm), # 添加反歸一化轉換*data_config.data_transforms.outputs, # 展開數據轉換的輸出部分*repack_transforms.outputs, # 展開重打包轉換的輸出部分],sample_kwargs=sample_kwargs, # 設置采樣參數metadata=train_config.policy_metadata, # 設置策略元數據)
`create_trained_policy` 函數是框架中連接訓練過的模型與實際部署使用的關鍵橋梁,它通過組合各種轉換函數,創建出可直接用于推理的 `Policy` 實例
2.3 policies/aloha_policy.py
這段代碼實現了一個用于 Aloha 策略的輸入輸出處理和數據轉換的模塊
2.3.1?make_aloha_example:輸入示例——狀態向量、圖像數據、文本prompt
首先,`make_aloha_example` 函數創建了一個隨機的輸入示例,包括一個14維的狀態向量和四個攝像頭的圖像數據(高、低、左腕、右腕視角),以及一個文本提示信息
# 定義一個函數,創建Aloha策略的隨機輸入示例
def make_aloha_example() -> dict: # 返回一個字典,包含狀態、圖像和提示信息return { # 創建一個14維的狀態向量,所有值為1"state": np.ones((14,)), # 創建一個包含四個攝像頭圖像的字典"images": { # 高位攝像頭圖像"cam_high": np.random.randint(256, size=(3, 224, 224), dtype=np.uint8), # 低位攝像頭圖像"cam_low": np.random.randint(256, size=(3, 224, 224), dtype=np.uint8), # 左手腕攝像頭圖像 "cam_left_wrist": np.random.randint(256, size=(3, 224, 224), dtype=np.uint8), # 右手腕攝像頭圖像"cam_right_wrist": np.random.randint(256, size=(3, 224, 224), dtype=np.uint8), },"prompt": "do something", }這些數據將用于測試和驗證 Aloha 策略的輸入處理
可能有的同學對上面的4個攝像頭有疑問,簡單,詳見此文《 一文通透動作分塊算法ACT:斯坦福ALOHA團隊推出的動作序列預測算法(Action Chunking with Transformers)》的「1.2 硬件套裝:ALOHA——低成本的開源硬件系統,用于手動遠程操作」
如下圖所示
- 左側為前、頂部和兩個手腕攝像機的視角(這4個相機的視角分別用從當前往后的藍線、從頂向下的綠線、從左往右的紅線、從右往左的紅線表示),以及ALOHA雙手工作空間的示意圖
具體而言,總計4個Logitech C922x網絡攝像頭,每個流輸出480×640 RGB圖像

2.3.2?AlohaInputs:定義Aloha 策略的輸入數據結構
接下來,`AlohaInputs` 類定義了 Aloha 策略的輸入數據結構
class AlohaInputs(transforms.DataTransformFn): # 定義AlohaInputs類,繼承自transforms.DataTransformFn"""Inputs for the Aloha policy.# 預期輸入格式# 圖像字典,鍵是名稱,值是形狀為[channel, height, width]的圖像- images: dict[name, img]# 狀態向量,長度為14- state: [14] # 動作矩陣,形狀為[action_horizon, 14]- actions: [action_horizon, 14] """# 模型的動作維度,將用于填充狀態和動作action_dim: int # 動作維度# 如果為True,將關節和夾持器值從標準Aloha空間轉換為pi內部運行時使用的空間# pi內部運行時使用的空間用于訓練基礎模型# 是否適配pi內部運行時,默認為Trueadapt_to_pi: bool = True # 預期的攝像頭名稱,所有輸入攝像頭必須在此集合中。缺失的攝像頭將用黑色圖像替代# 缺失的攝像頭將用黑色圖像替代,對應的`image_mask`將設置為False# 預期的攝像頭名稱集合EXPECTED_CAMERAS: ClassVar[tuple[str, ...]] = ("cam_high", "cam_low", "cam_left_wrist", "cam_right_wrist") - 這個類使用 `dataclasses.dataclass` 裝飾器來簡化類的定義,并確保實例是不可變的(`frozen=True`)
- 類中定義了輸入數據的預期格式,包括圖像、狀態和動作數據
__call__方法,實現了對Aloha策略輸入數據的標準化處理。該方法將原始輸入數據轉換為模型可接受的格式,包括多項關鍵處理步驟,比如進行必要的解碼和填充操作,并檢查圖像數據是否包含預期的攝像頭視角
- 首先,方法通過調用`_decode_aloha`函數對輸入數據進行初步解碼,根據`adapt_to_pi`參數決定是否將數據適配到π內部運行時環境
這一步主要處理狀態向量以及將圖像格式從`[channel, height, width]`轉換為`[height, width, channel]`# 定義__call__方法,處理輸入數據def __call__(self, data: dict) -> dict: # 解碼Aloha數據,根據adapt_to_pi參數進行適配data = _decode_aloha(data, adapt_to_pi=self.adapt_to_pi) - 接著,方法將14維的狀態向量使用零填充擴展到模型所需的動作維度(`action_dim`)
隨后,進行輸入圖像的驗證:檢查輸入圖像的鍵集合是否超出了預期的攝像頭列表范圍,若發現未知攝像頭視角則拋出`ValueError`# 獲取狀態數據,將其從14維填充到模型的動作維度# 使用transforms.pad_to_dim函數填充狀態數據state = transforms.pad_to_dim(data["state"], self.action_dim)# 獲取輸入圖像數據in_images = data["images"] # 檢查輸入圖像是否包含所有預期的攝像頭if set(in_images) - set(self.EXPECTED_CAMERAS): # 如果缺少預期的攝像頭,拋出異常raise ValueError(f"Expected images to contain {self.EXPECTED_CAMERAS}, got {tuple(in_images)}") - 在構建輸出字典時,方法首先假定"cam_high"(高視角攝像頭)圖像必定存在
并將其作為基礎圖像(`base_0_rgb`)# 假設基礎圖像總是存在,獲取高位攝像頭圖像base_image = in_images["cam_high"]
同時創建了相應的圖像掩碼字典,標記該圖像為有效# 創建圖像字典images = { # 基礎圖像"base_0_rgb": base_image, }# 創建圖像掩碼字典image_masks = { # 基礎圖像掩碼為True"base_0_rgb": np.True_, } - 對于其他攝像頭視角(左腕和右腕),方法使用映射關系字典進行處理:
如果相應的源圖像存在,則將其添加到輸出圖像字典并標記為有效;# 添加額外的圖像# 額外圖像名稱映射extra_image_names = { # 左手腕圖像"left_wrist_0_rgb": "cam_left_wrist", # 右手腕圖像"right_wrist_0_rgb": "cam_right_wrist", }
若不存在,則創建一個與基礎圖像相同大小的全零圖像(黑圖),并標記為無效# 遍歷額外圖像名稱映射for dest, source in extra_image_names.items(): # 如果輸入圖像中包含該圖像if source in in_images: # 添加到圖像字典images[dest] = in_images[source] # 設置圖像掩碼為Trueimage_masks[dest] = np.True_
這種處理方式確保了模型在缺失某些視角圖像時仍能正常工作# 如果輸入圖像中不包含該圖像else: # 用黑色圖像替代images[dest] = np.zeros_like(base_image) # 設置圖像掩碼為Falseimage_masks[dest] = np.False_# 創建輸入字典inputs = { "image": images, # 圖像數據"image_mask": image_masks, # 圖像掩碼"state": state, # 狀態數據} - 方法還會處理訓練時特有的數據,如動作序列
若輸入數據包含"actions"字段,則將其轉換為NumPy數組,應用`_encode_actions_inv`進行編碼轉換,并使用零填充擴展到模型動作維度
最后,如果輸入包含"prompt"文本提示,也會將其添加到輸出字典中,然后返回處理后的輸入數據# 動作數據僅在訓練期間可用# 如果輸入數據中包含動作數據if "actions" in data: # 將動作數據轉換為NumPy數組actions = np.asarray(data["actions"]) # 編碼動作數據,根據adapt_to_pi參數進行適配actions = _encode_actions_inv(actions, adapt_to_pi=self.adapt_to_pi) # 填充動作數據到模型的動作維度inputs["actions"] = transforms.pad_to_dim(actions, self.action_dim)# 如果輸入數據中包含提示信息if "prompt" in data: # 添加提示信息到輸入字典inputs["prompt"] = data["prompt"] # 返回處理后的輸入數據return inputs
整體而言,這個方法實現了從多樣化的原始輸入到標準化模型輸入的轉換流程,處理了數據格式轉換、缺失數據補充、維度調整等核心問題,確保了Aloha策略模型能夠接收一致的輸入格式,從而實現穩定的推理和訓練
2.3.3?AlohaOutputs:定義Aloha 策略的輸出數據結構
`AlohaOutputs` 類定義了 Aloha 策略的輸出數據結構,同樣使用 `dataclasses.dataclass` 裝飾器
# 定義AlohaOutputs類,繼承自transforms.DataTransformFn
class AlohaOutputs(transforms.DataTransformFn): # 如果為True,將關節和夾持器值從標準Aloha空間轉換為pi內部運行時使用的空間# pi內部運行時使用的空間用于訓練基礎模型adapt_to_pi: bool = True # 是否適配pi內部運行時,默認為True`__call__` 方法處理輸出數據,僅返回前14個維度的動作數據,并進行必要的編碼轉換
# 定義__call__方法,處理輸出數據def __call__(self, data: dict) -> dict: # 僅返回前14維的動作數據,即將動作數據轉換為NumPy數組,并取前14維actions = np.asarray(data["actions"][:, :14]) # 編碼動作數據并返回字典return {"actions": _encode_actions(actions, adapt_to_pi=self.adapt_to_pi)} 2.3.4 多個輔助函數:數據的標準化、反標準化、關節角度翻轉
此外,代碼中還包含多個輔助函數,用于數據的標準化、反標準化、關節角度翻轉、夾持器位置的線性和角度轉換等
這些函數確保了數據在不同控制系統之間的兼容性和一致性
// 待更
第三部分 模型訓練的配置:src下training模塊的全面分析與解讀
training模塊是 OpenPI 項目中負責訓練相關功能的核心部分,該目錄下包含了以下主要文件:
- checkpoints.py - 檢查點管理
- config.py - 配置系統
- data_loader.py - 數據加載器
- data_loader_test.py - 數據加載器測試
- optimizer.py - 優化器實現
- sharding.py - 模型分片工具
- utils.py - 通用工具函數
- weight_loaders.py - 模型權重加載器
3.1 配置系統 (config.py)
定義了訓練過程的各種配置類型,包括:
- `TrainConfig`:頂級訓練配置,包含模型、數據、優化器等所有訓練參數
- `DataConfigFactory`:抽象工廠類,用于創建特定環境的數據配置
- `AssetsConfig`:管理資產(如歸一化統計數據)的位置
- 預定義了多種常用配置(如 ALOHA、DROID、LIBERO 等環境的配置)
- 通過 `get_config` 函數根據名稱檢索預定義配置
在配置流程上
? ?- 訓練腳本通過 `_config.cli()` 或 `_config.get_config()` 獲取配置
? ?- 配置系統加載預定義的訓練參數,確定訓練環境和模型參數
? ?- 數據配置通過工廠模式創建,根據不同環境(ALOHA、DROID 等)提供不同的預處理流程
3.1.1 基礎配置類AssetsConfig、DataConfig
一個是AssetsConfig
class AssetsConfig:"""用于確定數據pipeline所需資產(如歸一化統計信息)的位置"""assets_dir: str | None = None ? # 資產目錄asset_id: str | None = None ? ? # 資產ID一個是DataConfig
@dataclasses.dataclass(frozen=True)
class DataConfig:repo_id: str | None = None # 數據集倉庫IDasset_id: str | None = None # 資產IDnorm_stats: dict[str, _transforms.NormStats] | None = None # 歸一化統計信息repack_transforms: _transforms.Group # 數據重打包轉換data_transforms: _transforms.Group # 數據預處理轉換model_transforms: _transforms.Group # 模型特定轉換3.1.2 數據集配置:包含ALOHA、Libero兩套數據集——LeRobotLiberoDataConfig
涉及兩個配置
- 一個是LeRobotAlohaDataConfig
@dataclasses.dataclass(frozen=True) class LeRobotAlohaDataConfig(DataConfigFactory):"""ALOHA數據集配置"""use_delta_joint_actions: bool = True # 是否使用關節角度增量default_prompt: str | None = None # 默認提示語adapt_to_pi: bool = True # 是否適配到π內部運行時 - 一個是LeRobotLiberoDataConfig
@dataclasses.dataclass(frozen=True) class LeRobotLiberoDataConfig(DataConfigFactory):"""Libero數據集配置"""
對于后者的結構,詳見下圖
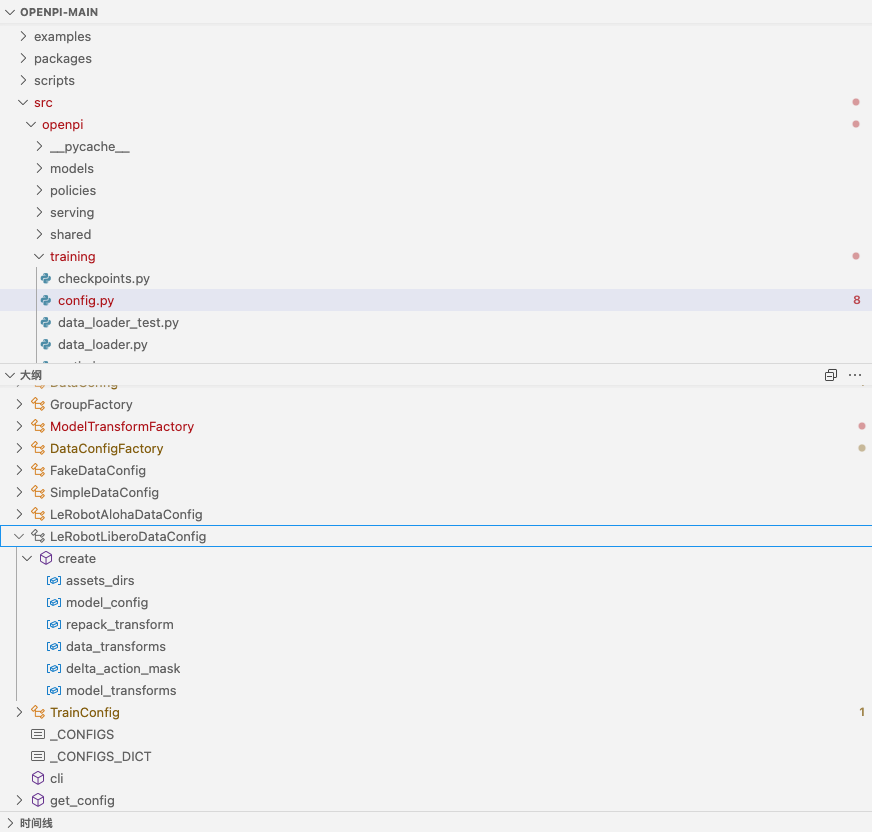
- `LeRobotLiberoDataConfig` 是一個用于機器人控制系統的數據配置類,它負責定義整個數據管道中不同階段的數據轉換操作。這個類通過 `@dataclasses.dataclass(frozen=True)` 裝飾器聲明為不可變數據類,確保配置一旦創建就不能被修改,增強了數據處理的穩定性
- 該類重寫了基類 `DataConfigFactory` 的 `create` 方法,該方法是整個配置系統的核心,負責構建完整的數據配置
方法接收兩個關鍵參數:存放數據資產的目錄路徑和模型配置對象,然后返回一個完整的 `DataConfig` 對象def create(self, assets_dirs: pathlib.Path, model_config: _model.BaseModelConfig) -> DataConfig:# 重寫父類方法,創建數據配置。參數包括資產目錄路徑和模型配置,返回DataConfig對象# .. - 在方法內部,首先定義了 `repack_transform`,這是一個僅在訓練階段應用的轉換器,用于將數據集中的鍵名映射到推理環境期望的鍵名
例如,將 `"observation/image"` 映射到 `"image"`。這種轉換確保了訓練數據和推理環境之間的一致性,是適配不同數據源的關鍵步驟 - 接下來,`data_transforms` 配置了同時應用于訓練和推理階段的轉換操作
它使用 `libero_policy.LiberoInputs` 處理輸入數據,`libero_policy.LiberoOutputs` 處理輸出數據
這些轉換器負責將原始數據調整為模型能夠處理的格式# 數據轉換應用于來自數據集的數據和推理過程中的數據# 下面,定義了進入模型的數據轉換("inputs")和從模型輸出的數據轉換("outputs")(后者僅在推理時使用)# 這些轉換在`libero_policy.py`中定義# 一旦創建了自己的轉換,你可以用自己的替換下面的轉換data_transforms = _transforms.Group(# 定義輸入轉換,使用LiberoInputs處理器inputs=[libero_policy.LiberoInputs(action_dim=model_config.action_dim, model_type=model_config.model_type)], # 定義輸出轉換,使用LiberoOutputs處理器outputs=[libero_policy.LiberoOutputs()], ) - 特別值得注意的是關于動作表示的轉換:該配置支持將絕對動作(如具體的關節角度)轉換為相對動作(相對于初始狀態的變化量)
通過 `delta_action_mask` 創建一個布爾掩碼,指定哪些動作維度需要進行轉換(這里是前6個維度對應機器人關節,保留最后一個維度對應夾爪不變)
這對于訓練基于相對動作的模型(如Pi0模型)非常重要# 創建動作掩碼,指定哪些維度需要轉換為相對動作(前6個關節),哪些保持絕對值(夾爪)# 創建布爾掩碼,前6個維度為True,最后一個維度為Falsedelta_action_mask = _transforms.make_bool_mask(6, -1) - 最后,`model_transforms` 處理模型特有的轉換操作,比如提示文本的token化和圖像尺寸調整
這些轉換由 `ModelTransformFactory` 根據模型類型動態創建,支持不同類型的模型(Pi0或Pi0_FAST)# 使用模型配置創建模型轉換——處理提示文本的token化和其他模型特定的轉換model_transforms = ModelTransformFactory()(model_config) - 整個方法通過 `dataclasses.replace` 將這些轉換器與基礎配置(通過 `create_base_config` 創建)合并,生成最終的數據配置對象
return dataclasses.replace(self.create_base_config(assets_dirs), # 創建基礎配置repack_transforms=repack_transform, # 設置重新打包轉換data_transforms=data_transforms, # 設置數據轉換model_transforms=model_transforms, # 設置模型轉換)
3.1.3 訓練配置TrainConfig:模型、數據、優化器等訓練參數的設置
class TrainConfig:name: str ? ? ? ? ? ? ? ? ? ? ? ? ?# 配置名稱project_name: str = "openpi" ? ? ? # 項目名稱exp_name: str ? ? ? ? ? ? ? ? ? ? ?# 實驗名稱model: _model.BaseModelConfig ? ? ?# 模型配置batch_size: int = 32 ? ? ? ? ? ? ?# 批次大小num_train_steps: int = 30_000 ? ? # 訓練步數lr_schedule: _optimizer.LRScheduleConfig ? # 學習率調度optimizer: _optimizer.OptimizerConfig ? ? # 優化器配置3.1.4 預定義配置:基于ALOHA/Libero數據集微調π0——比如完成aloha_sim_transfer_cube_human
文件最后定義了多個具體的訓練配置:
- 比如ALOHA的
當然,這里面還涉及到ALOHA中一個仿真環境中的操作任務TrainConfig(name="pi0_aloha_pen_uncap", # 配置名稱,反映模型和數據集model=pi0.Pi0Config(), # 使用pi0模型配置data=LeRobotAlohaDataConfig( # 使用LeRobotAloha數據集配置# 數據集倉庫IDrepo_id="physical-intelligence/aloha_pen_uncap_diverse", # 資產配置assets=AssetsConfig( # 資產目錄assets_dir="s3://openpi-assets/checkpoints/pi0_base/assets", # 資產IDasset_id="trossen", ),# 默認提示語default_prompt="uncap the pen", # 數據重打包轉換repack_transforms=_transforms.Group( inputs=[# 重打包轉換_transforms.RepackTransform( {"images": {# 高視角攝像頭圖像"cam_high": "observation.images.cam_high", # 左手腕攝像頭圖像"cam_left_wrist": "observation.images.cam_left_wrist",# 右手腕攝像頭圖像 "cam_right_wrist": "observation.images.cam_right_wrist", },# 機器人狀態"state": "observation.state", # 動作"actions": "action", })]),base_config=DataConfig(# 是否只使用本地數據集,False表示允許從Hugging Face下載local_files_only=False, ),),# 加載預訓練權重weight_loader=weight_loaders.CheckpointWeightLoader("s3://openpi-assets/checkpoints/pi0_base/params"), # 訓練步數為20,000步num_train_steps=20_000, ),# 這個配置用于演示如何在簡單的模擬環境中進行訓練 TrainConfig(name="pi0_aloha_sim", # 配置名稱model=pi0.Pi0Config(), # 使用pi0模型配置data=LeRobotAlohaDataConfig( # 使用LeRobotAloha數據集配置# 數據集倉庫IDrepo_id="lerobot/aloha_sim_transfer_cube_human", default_prompt="Transfer cube", # 默認提示語use_delta_joint_actions=False, # 是否使用關節角度增量),weight_loader=weight_loaders.CheckpointWeightLoader("s3://openpi-assets/checkpoints/pi0_base/params"), # 加載預訓練權重num_train_steps=20_000, # 訓練步數為20,000步 ), - 再比如Libero的
TrainConfig(# 更改名稱以反映你的模型和數據集name="pi0_libero",# 在這里定義模型配置 - 這個例子中我們使用pi0作為模型架構并執行完整微調# 在后面的例子中我們會展示如何修改配置來執行低內存(LORA)微調# 以及如何使用pi0-FAST作為替代架構model=pi0.Pi0Config(),# 在這里定義要訓練的數據集。這個例子中我們使用Libero數據集# 對于你自己的數據集,你可以更改repo_id指向你的數據集# 同時修改DataConfig以使用你為數據集創建的新配置data=LeRobotLiberoDataConfig(# 指定數據集的Hugging Face倉庫IDrepo_id="physical-intelligence/libero",# 基礎配置設置base_config=DataConfig(# 是否只使用本地數據集,False表示允許從Hugging Face下載local_files_only=False, # 這個標志決定是否從LeRobot數據集的task字段加載提示(即任務指令)# 如果設為True,提示將會出現在輸入字典的prompt字段中# 推薦設置為Trueprompt_from_task=True,),),# 在這里定義要加載哪個預訓練檢查點來初始化模型# 這應該與你上面選擇的模型配置匹配 - 即在這種情況下我們使用pi0基礎模型weight_loader=weight_loaders.CheckpointWeightLoader("s3://openpi-assets/checkpoints/pi0_base/params"),# 在下面你可以定義其他超參數,如學習率、訓練步數等# 查看TrainConfig類以獲取完整的可用超參數列表num_train_steps=30_000, # 設置訓練步數為30,000步 ),
3.2 數據加載系統 data_loader.py
定義了數據集和數據加載器的接口(`Dataset` 和 `DataLoader`)
- 實現了數據轉換管道,將原始數據轉換為模型可用的格式
- 支持各種數據源:真實數據集(通過 LeRobot 數據集接口)、模擬數據(使用 `FakeDataset`)
- 提供數據歸一化和轉換功能
在數據加載流程上
TrainConfig
? ?└── data (DataConfigFactory)
? ? ? ?├── create() → DataConfig
? ? ? ?│ ? ├── repo_id: 數據集 ID
? ? ? ?│ ? ├── norm_stats: 歸一化統計數據
? ? ? ?│ ? ├── repack_transforms: 數據重包裝轉換
? ? ? ?│ ? ├── data_transforms: 特定于環境的轉換
? ? ? ?│ ? └── model_transforms: 特定于模型的轉換
? ? ? ?└── _load_norm_stats() → 歸一化統計數據
? ?create_data_loader(config)
? ?├── data_config = config.data.create()
? ?├── dataset = create_dataset(data_config, config.model)
? ?├── dataset = transform_dataset(dataset, data_config)
? ?└── return DataLoaderImpl(data_config, TorchDataLoader(...))
3.2.1 FakeDataset類
3.2.2?create_dataset:創建適合訓練的數據集
`create_dataset` 函數是一個關鍵的數據準備工具,負責根據配置參數創建適合模型訓練的數據集。這個函數通過處理不同數據源和應用必要的轉換,為模型提供標準化的訓練數據。
- 首先,函數檢查 `data_config.repo_id` 的值,這個參數指定了數據倉庫的標識符
如果 `repo_id` 為 `None`,函數會拋出 `ValueError` 異常,明確指出無法創建數據集。這是一種防御性編程的體現,確保基本的配置參數存在def create_dataset(data_config: _config.DataConfig, model_config: _model.BaseModelConfig) -> Dataset:"""創建用于訓練的數據集"""# 從數據配置中獲取倉庫IDrepo_id = data_config.repo_id
如果 `repo_id` 的值為 "fake",函數則創建并返回一個 `FakeDataset` 實例,其樣本數設為 1024。這種虛擬數據集在測試模型架構、調試訓練流程或者進行性能基準測試時非常有用,無需加載真實數據即可快速驗證系統功能# 如果倉庫ID為空,拋出錯誤if repo_id is None:raise ValueError("Repo ID is not set. Cannot create dataset.")
對于其他情況(即使用真實數據),函數首先創建 `LeRobotDatasetMetadata` 對象來獲取數據集的元信息# 如果是fake數據集,返回包含1024個樣本的假數據集if repo_id == "fake":return FakeDataset(model_config, num_samples=1024)
然后初始化 `LeRobotDataset` 實例# 創建數據集元數據對象,包含數據集的基本信息(如fps等)dataset_meta = lerobot_dataset.LeRobotDatasetMetadata(repo_id, local_files_only=data_config.local_files_only)
特別值得注意的是,函數會根據模型的 `action_horizon`(動作預測的時間步長)和數據集的幀率(fps)計算 `delta_timestamps`,這些時間戳用于在時序數據中定位動作序列。這種計算確保了動作序列的時間間隔與模型預期一致,無論原始數據的采樣率如何# 創建LeRobot數據集實例dataset = lerobot_dataset.LeRobotDataset(data_config.repo_id,# 創建時間戳字典,用于采樣動作序列delta_timestamps={# 對每個動作序列鍵,根據模型的動作視界長度和數據集的fps生成時間戳列表key: [t / dataset_meta.fps for t in range(model_config.action_horizon)]for key in data_config.action_sequence_keys},# 是否只使用本地文件local_files_only=data_config.local_files_only,) - 最后,如果 `data_config.prompt_from_task` 設置為 `True`,函數會將原始數據集包裝在 `TransformedDataset` 中,并應用 `PromptFromLeRobotTask` 轉換
這個轉換可能將任務描述轉換為自然語言提示,增強模型對任務上下文的理解能力# 如果配置指定從任務中提取提示信息if data_config.prompt_from_task:# 創建轉換后的數據集,應用PromptFromLeRobotTask轉換,將任務描述轉換為提示dataset = TransformedDataset(dataset, [_transforms.PromptFromLeRobotTask(dataset_meta.tasks)])
然后返回處理好的數據集# 返回處理后的數據集return dataset
3.2.3?transform_dataset:對數據集應用轉換,比如數據清洗等(創建TransformedDataset實例)
`transform_dataset` 函數是數據預處理管道中的關鍵組件,負責對原始數據集應用一系列轉換操作,以滿足模型訓練的需求。該函數接收一個原始數據集、數據配置對象以及一個可選的控制標志,并返回經過轉換的新數據集
首先,函數會處理數據歸一化統計信息(normalization statistics)。對于實際數據集(非"fake"數據集),如果沒有顯式跳過歸一化統計(`skip_norm_stats=False`),函數會檢查數據配置中是否包含必要的歸一化統計數據。如果這些統計數據缺失,函數會拋出一個明確的錯誤信息,提示用戶需要運行特定腳本來計算這些統計數據。這種檢查機制確保了數據歸一化步驟能夠正確執行,避免了訓練過程中可能出現的數值問題
核心轉換邏輯通過創建一個 `TransformedDataset` 實例來實現,該實例封裝了原始數據集和一系列轉換函數。這些轉換函數按照特定順序應用:
- 首先是數據重新打包轉換(`repack_transforms`),可能用于調整數據的基本結構
- 接著是一般數據轉換(`data_transforms`),處理數據清洗、增強等操作
- 然后應用歸一化轉換(`Normalize`),使用前面獲取的統計數據
- 最后是模型特定的轉換(`model_transforms`),針對特定模型架構的數據格式要求
3.2.4?create_data_loader:創建用于訓練的數據加載器
`create_data_loader` 函數是整個數據處理流水線的核心組件,它協調多個模塊共同工作,創建一個用于模型訓練的數據加載器
整個函數的工作流程可以分為三個主要階段:
- 第一階段:數據集準備
函數首先通過調用 `data_config.create()` 方法創建數據配置對象,該對象包含了所有數據處理相關的配置信息
隨后,通過 `create_dataset` 函數創建原始數據集,這可能是一個真實的機器人數據集或者是一個用于測試的假數據集(當 `repo_id` 為 "fake" 時)
然后,調用 `transform_dataset` 函數應用一系列數據轉換,包括數據重新打包、數據清洗、歸一化和模型特定轉換。這些轉換確保了原始數據被正確處理為模型所需的格式 - 第二階段:PyTorch 數據加載器創建
接下來,函數實例化一個 `TorchDataLoader` 對象,這是對 PyTorch 數據加載器的封裝。這個過程涉及多個關鍵參數設置:計算各進程的本地批量大小(通過全局批量大小除以進程數)
配置數據分片策略(sharding)用于分布式訓練
設置是否打亂數據、工作進程數和隨機種子等
`TorchDataLoader` 的設計支持無限迭代數據(當 `num_batches` 為 `None` 時)或限定批次數的迭代,這對于訓練和評估場景都很適用。其內部使用 JAX 的分片機制確保數據在分布式環境中正確分布 - 第三階段:接口適配器實現
最后,函數通過定義嵌套類 `DataLoaderImpl` 來適配 `DataLoader` 協議接口。這個類封裝了前面創建的 `TorchDataLoader` 實例,并提供了兩個關鍵方法:
1. `data_config()` 返回數據配置信息,便于訓練代碼訪問數據處理的元信息
2. `__iter__()` 生成器方法對數據批次進行最后的格式轉換:
將字典格式的觀察數據轉換為結構化的 `Observation` 對象(通過 `Observation.from_dict`)提取動作數據
以元組形式 `(observation, actions)` 返回每個批次
這種設計實現了關注點分離,使數據加載、轉換和格式適配各自獨立,同時又協同工作,為模型訓練提供了一個干凈的數據流接口。函數還處理了多進程環境、數據分片和內存效率等復雜問題,這些都是大規模機器學習訓練中的關鍵挑戰
3.3 優化器系統 (optimizer.py)
定義了多種學習率調度策略:
- `CosineDecaySchedule`:余弦衰減學習率
- `RsqrtDecaySchedule`:反平方根衰減學習率
實現了常用優化器配置:
- `AdamW`:帶有權重衰減的 Adam 優化器
- `SGD`:隨機梯度下降優化器
通過 `create_optimizer` 函數統一創建優化器實例
3.4 檢查點系統 (checkpoints.py)
負責模型狀態的保存和恢復,比如管理訓練狀態的序列化,包括:
- 模型參數
- 優化器狀態
- EMA 參數(如果使用)
且使用 Orbax 庫實現高效的檢查點存儲
| 模型初始化流程 | 訓練步驟流程 | 與 models 模塊的交互 | 檢查點管理流程 |
| ? ?init_train_state(config, rng, mesh) ? ?├── 創建模型:model = config.model.create(rng) ? ?├── 加載權重:partial_params = config.weight_loader.load(params) ? ?├── 設置凍結參數:params = state_map(params, config.freeze_filter, ...) ? ?├── 創建優化器:tx = create_optimizer(config.optimizer, config.lr_schedule) ? ?└── 返回 TrainState | ? ?train_step(config, rng, state, batch) ? ?├── 計算梯度:loss, grads = value_and_grad(model.compute_loss)() ? ?├── 更新參數:updates, new_opt_state = state.tx.update(grads, state.opt_state, params) ? ?├── 應用更新:new_params = optax.apply_updates(params, updates) ? ?├── 更新 EMA 參數(如果配置) ? ?└── 返回 new_state, info | ? ?- 訓練系統加載模型定義 (`BaseModel`) ? ?- 處理模型參數的保存和加載 ? ?- 調用模型的 `compute_loss` 方法計算損失——詳見上文的「1.2.4.3 損失函數 `compute_loss`」 | ? ?save_state(checkpoint_manager, state, data_loader, step) ? ?├── _split_params(state) → 分離訓練狀態和推理參數 ? ?├── 保存歸一化統計數據到 assets 目錄 ? ?└── checkpoint_manager.save() → 保存檢查點 ? ? ? ?restore_state(checkpoint_manager, state, data_loader) ? ?├── checkpoint_manager.restore() → 恢復檢查點 ? ?└── _merge_params() → 合并恢復的參數 |
// 待更
3.5 模型分片系統(sharding.py):含FSDP的實現
實現分布式訓練時的模型參數分片
- 提供 `fsdp_sharding` 函數用于全參數數據并行(FSDP)的實現
- 基于 JAX 的分片機制,優化大規模模型的訓練性能
- 通過 `activation_sharding_constraint` 處理激活值的分片
3.6 權重加載系統 (weight_loaders.py)
定義了 `WeightLoader` 協議,用于加載預訓練權重,且實現了多種加載策略:
- `NoOpWeightLoader`:不加載權重(用于從頭訓練)
- `CheckpointWeightLoader`:從檢查點加載完整權重
- `PaliGemmaWeightLoader`:從官方 PaliGemma 檢查點加載權重
另,還支持權重合并功能,可以部分加載權重(如 LoRA 微調)
3.7 輔助工具(utils.py)
定義了 `TrainState` 數據類,封裝了訓練過程的狀態
- 提供日志記錄和調試功能
- 實現了 PyTree 轉換和可視化功能
// 待更
第四部分 模型的訓練與部署:基于客戶端-服務器C/S架構——openpi-Client/Scripts
packages/openpi-client,是一個獨立的客戶端庫openpi-client 庫,主要負責:
- 提供與策略服務器通信的接口:使用 WebSocketClientPolicy 連接服務器
- 處理觀察數據(圖像、狀態等)的發送,和動作數據的接收
- 管理客戶端運行時環境
- 被各種機器人平臺(如 ALOHA、DROID)使用來與服務器交互
scripts這個模塊提供了服務器端的各種工具和腳本,主要包括:
- 策略服務相關——serve_policy.py:啟動策略服務器,處理來自客戶端的請求
- 訓練相關——train.py: 模型訓練的入口點
- 數據處理——compute_norm_stats.py: 計算數據歸一化統計信息
- 部署相關:提供 Docker 相關的配置和安裝腳本
總的來說,這是一個典型的分布式系統設計:packages/openpi-client 提供輕量級的客戶端接口,而 scripts/ 則提供服務器端的功能實現,兩者通過 WebSocket 協議進行通信,形成了一個完整的策略部署和執行系統
所謂客戶端-服務器架構——Client-server model,也稱C/S架構、主從zòng式架構,是一種將客戶端與服務器分割開來的分布式架構。每一個客戶端軟件的實例都可以向一個服務器或應用程序服務器發出請求。有很多不同類型的服務器,例如文件服務器、游戲服務器等
客戶端的特征:
- 主動的角色(主)
- 發送請求
- 等待直到收到響應
服務端的特征:
- 被動的角色(從)
- 等待來自客戶端的請求
- 處理請求并傳回結果

4.1 packages/openpi-client:幫真機或Sim與策略服務器進行通信和交互
該模塊的目錄結構如下

這個客戶端包的設計非常模塊化,具有良好的擴展性,主要用于:
- 連接到 OpenPI 服務器
- 處理觀察數據和動作序列
- 管理機器人或仿真環境的運行
- 提供事件監控和記錄功能
它的設計允許在不同的機器人平臺上靈活部署,支持實時控制和異步通信,是 OpenPI 項目中連接模型服務器和實際機器人執行系統的重要橋梁
4.1.1 核心接口層
`BasePolicy`: 定義策略接口
`Environment`: 定義環境接口
`Agent`: 定義代理接口
4.1.2 通信層WebsocketClientPolicy
- `WebsocketClientPolicy`: 實現與服務器的 WebSocket 通信
- `msgpack_numpy`: 處理數據序列化
4.1.3 數據處理層
- `ActionChunkBroker`: 處理動作序列的分塊和緩存
- `image_tools`: 提供圖像處理和優化功能
4.1.4 運行時系統層
- `Runtime`: 核心運行時系統
- `Subscriber`: 事件訂閱系統
- `agents`: 具體代理實現
4.1.5 工具支持
- 圖像處理工具
- 數據類型轉換
- 網絡通信優化
4.2 scripts(策略服務器):包含數據處理、模型訓練、模型推理的多個腳本
根據下圖

可知,scripts 目錄包含多個 Python 腳本,這些腳本用于數據處理、模型訓練和服務部署等任務,每個腳本通常對應一個特定的功能或任務
- __init__.py
- compute_norm_stats.py: 計算數據的歸一化統計信息
- serve_policy.py:啟動策略服務,提供模型推理接口
總之,serve_policy.py 是 openpi 中的策略推理服務端腳本,作用為:啟動一個 WebSocket 服務器,加載預訓練策略模型,等待外部請求(如來自 main.py 的控制程序),然后執行動作推理并返回結果
說白了,將一個 Pi0 策略模型部署為網絡服務(WebSocket API),供機器人主控進程遠程調用 - train_test.py: 訓練和測試模型
- train.py: 訓練模型
4.2.1 __init__.py
4.2.2?compute_norm_stats.py:計算數據的歸一化統計信息
4.2.3(上) serve_policy.py:啟動策略服務,用于模型推理——且支持定義特定任務的文本指令prompt
- 在這個代碼片段中,首先導入了一些必要的模塊和庫,包括 `policy`、`policy_config`、`websocket_policy_server` 和 `config`,這些模塊來自 `openpi` 項目
接下來定義了一個枚舉類 `EnvMode`,它表示支持的環境類型,包括 `ALOHA`、`ALOHA_SIM`、`DROID` 和 `LIBERO`from openpi.policies import policy as _policy # 導入 openpi.policies.policy 模塊并重命名為 _policy from openpi.policies import policy_config as _policy_config # 導入 openpi.policies.policy_config 模塊并重命名為 _policy_config from openpi.serving import websocket_policy_server # 導入 openpi.serving.websocket_policy_server 模塊 from openpi.training import config as _config # 導入 openpi.training.config 模塊并重命名為 _configclass EnvMode(enum.Enum):"""支持的環境。"""ALOHA = "aloha" # ALOHA 環境ALOHA_SIM = "aloha_sim" # ALOHA 模擬環境DROID = "droid" # DROID 環境LIBERO = "libero" # LIBERO 環境 - 然后定義了幾個數據類
`Checkpoint` 類用于從訓練好的檢查點加載策略,包含兩個字段:`config`(訓練配置名稱)和 `dir`(檢查點目錄)
`Default` 類表示使用默認策略
`Args` 類定義了腳本的參數,包括環境類型、默認prompt、端口、是否記錄策略行為以及如何加載策略
相當于如果你想定義你的特定任務指令prompt,則可以修改上面代碼中的default_prompt@dataclasses.dataclass class Args:"""Arguments for the serve_policy script."""# Environment to serve the policy for. This is only used when serving default policies.env: EnvMode = EnvMode.ALOHA_SIM# If provided, will be used in case the "prompt" key is not present in the data, or if the model doesn't have a default# prompt.default_prompt: str | None = None# Port to serve the policy on.port: int = 8000# Record the policy's behavior for debugging.record: bool = False# Specifies how to load the policy. If not provided, the default policy for the environment will be used.policy: Checkpoint | Default = dataclasses.field(default_factory=Default)
接下來定義了一個字典 `DEFAULT_CHECKPOINT`,它為每個環境類型指定了默認的檢查點配置# 每個環境應使用的默認檢查點 DEFAULT_CHECKPOINT: dict[EnvMode, Checkpoint] = {EnvMode.ALOHA: Checkpoint(config="pi0_aloha",dir="s3://openpi-assets/checkpoints/pi0_base",),EnvMode.ALOHA_SIM: Checkpoint(config="pi0_aloha_sim",dir="s3://openpi-assets/checkpoints/pi0_aloha_sim",),EnvMode.DROID: Checkpoint(config="pi0_fast_droid",dir="s3://openpi-assets/checkpoints/pi0_fast_droid",),EnvMode.LIBERO: Checkpoint(config="pi0_fast_libero",dir="s3://openpi-assets/checkpoints/pi0_fast_libero",), } - 加載策略模型
`create_default_policy` 函數根據環境類型創建默認策略,如果環境類型不支持,則拋出異常
`create_policy` 函數根據傳入的參數創建策略,如果參數中指定了檢查點,則從檢查點加載策略,否則使用默認策略def create_default_policy(env: EnvMode, *, default_prompt: str | None = None) -> _policy.Policy:"""為給定環境創建默認策略 """if checkpoint := DEFAULT_CHECKPOINT.get(env): # 獲取環境對應的默認檢查點return _policy_config.create_trained_policy(_config.get_config(checkpoint.config), checkpoint.dir, default_prompt=default_prompt) # 創建訓練好的策略raise ValueError(f"Unsupported environment mode: {env}") # 如果環境不支持,拋出異常def create_policy(args: Args) -> _policy.Policy:"""根據給定的參數創建策略 """match args.policy: # 匹配策略類型case Checkpoint(): # 如果是 Checkpoint 類型return _policy_config.create_trained_policy(_config.get_config(args.policy.config), args.policy.dir, default_prompt=args.default_prompt) # 創建訓練好的策略case Default(): # 如果是 Default 類型return create_default_policy(args.env, default_prompt=args.default_prompt) # 創建默認策略 - 啟動推理服務
`main` 函數是腳本的入口點,它首先調用 `create_policy` 函數創建策略,然后記錄策略的元數據
如果參數中指定了記錄策略行為,則使用 `PolicyRecorder` 包裝策略def main(args: Args) -> None:policy = create_policy(args) # 創建策略policy_metadata = policy.metadata # 獲取策略的元數據
接著獲取主機名和本地 IP 地址# 記錄策略的行為if args.record:# 使用 PolicyRecorder 記錄策略行為policy = _policy.PolicyRecorder(policy, "policy_records")
并創建一個 WebSocket 服務器來提供策略服務,最后調用 `serve_forever` 方法啟動服務器hostname = socket.gethostname() # 獲取主機名local_ip = socket.gethostbyname(hostname) # 獲取本地 IP 地址logging.info("Creating server (host: %s, ip: %s)", hostname, local_ip) # 記錄服務器創建信息server = websocket_policy_server.WebsocketPolicyServer(policy=policy,host="0.0.0.0",port=args.port,metadata=policy_metadata,) # 創建 WebSocket 策略服務器server.serve_forever() # 啟動服務器,永遠運行 - 在腳本的最后,使用 `logging` 模塊配置日志記錄,并調用 `main` 函數啟動腳本,參數通過 `tyro.cli` 解析
更多 還可以看下姚博士所寫的這篇文章:openpi π? 項目部署運行邏輯(三)——策略推理服務器 serve_policy.py
4.2.3(下) 人類下達的任務指令prompt是如何在整個代碼庫中流轉的
有一朋友在我建的「七月具身:π0復現微調交流群」里提問,為何不論設置怎樣的指令prompt,機器人都執行同一套動作「后來,在他們使用多任務數據集訓練后,π0可以實現prompt跟隨,之前不能的原因是因為評估時機器人使用了和訓練時的不同預備位姿」
對此,我特意梳理了下自定義的文本指令prompt在整個π0官方庫中的數據流轉——花了我一兩個小時的時間,^_^
第一階段,設定prompt,隨后分別啟動WebSocket服務器、WebSocket客戶端并互聯
- 在上面介紹的這里 設定prompt
class Args:"""Arguments for the serve_policy script."""# Environment to serve the policy for. This is only used when serving default policies.env: EnvMode = EnvMode.ALOHA_SIM# If provided, will be used in case the "prompt" key is not present in the data, or if the model doesn't have a default# prompt.default_prompt: str | None = None - 之后啟動策略服務器scripts/serve_policy.py,在這個策略服務器的代碼文件中,main函數中
而create_policy中,要么調用create_trained_policy,要么調用create_default_policydef main(args: Args) -> None:policy = create_policy(args)policy_metadata = policy.metadata
比如,如果最終選擇的是ALOHA的策略,則examples/aloha_real/main.py中的main函數會調用AlohaRealEnvironment類
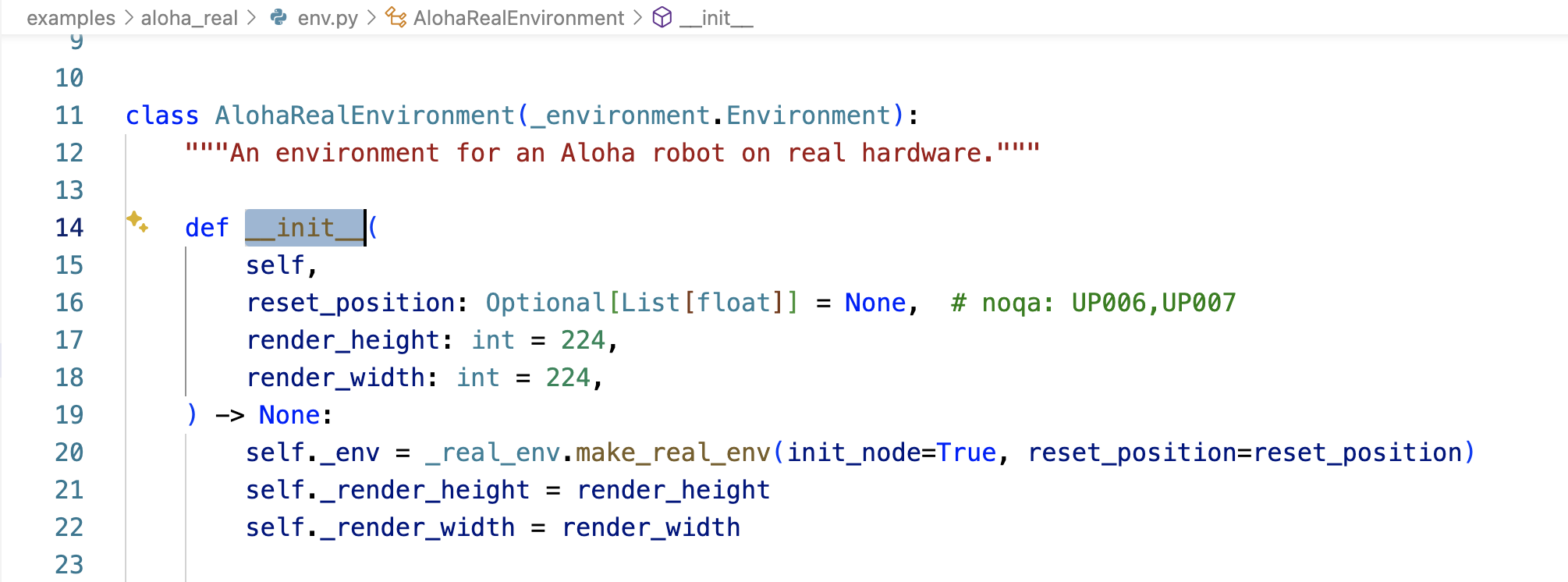
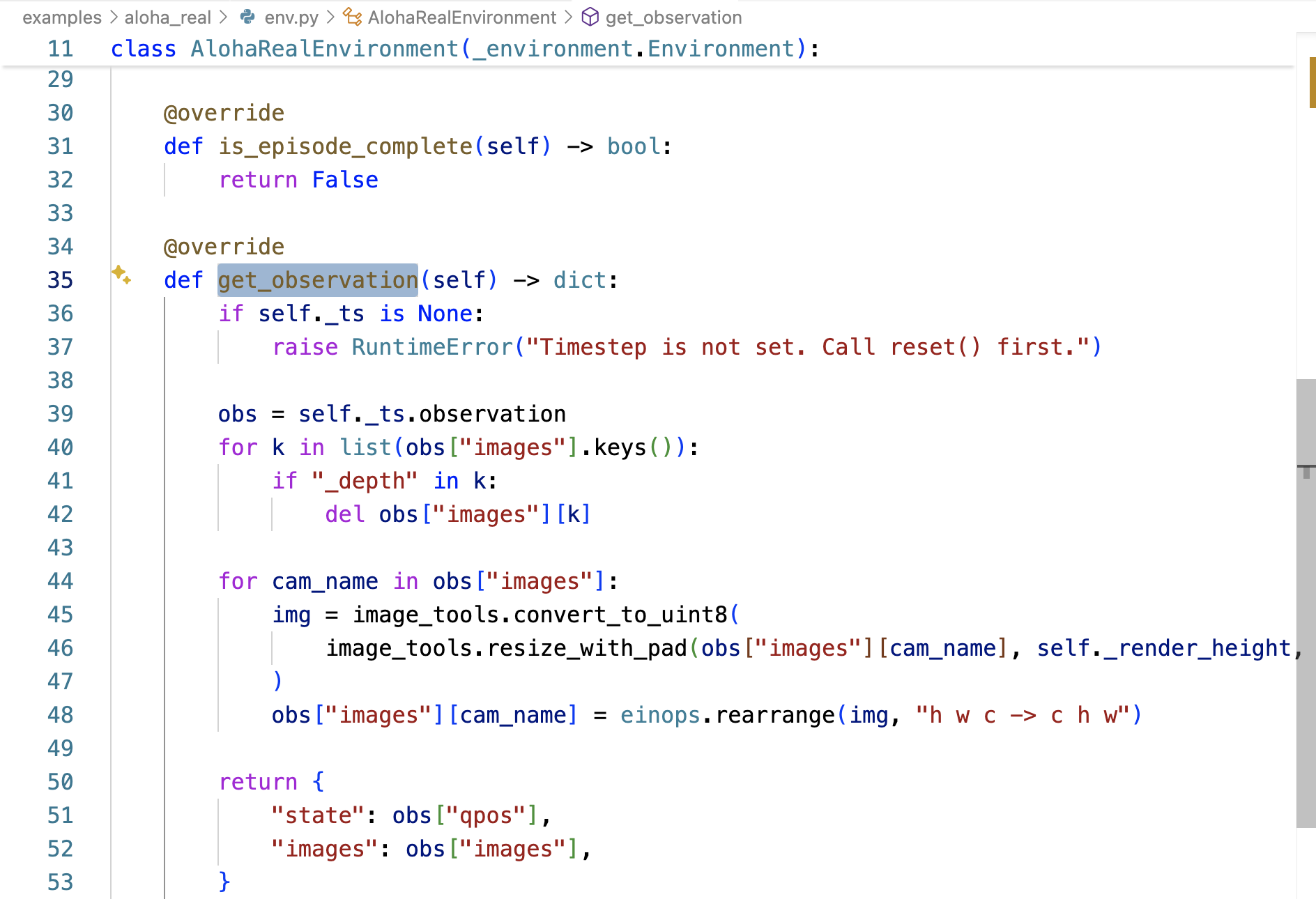
而AlohaRealEnvironment被定義在examples/aloha_real/env.py中的,隨后AlohaRealEnvironment通過其中的-__init__函數設定環境的初始化「注意,這個AlohaRealEnvironment類中還定義了get_observation,下文會介紹」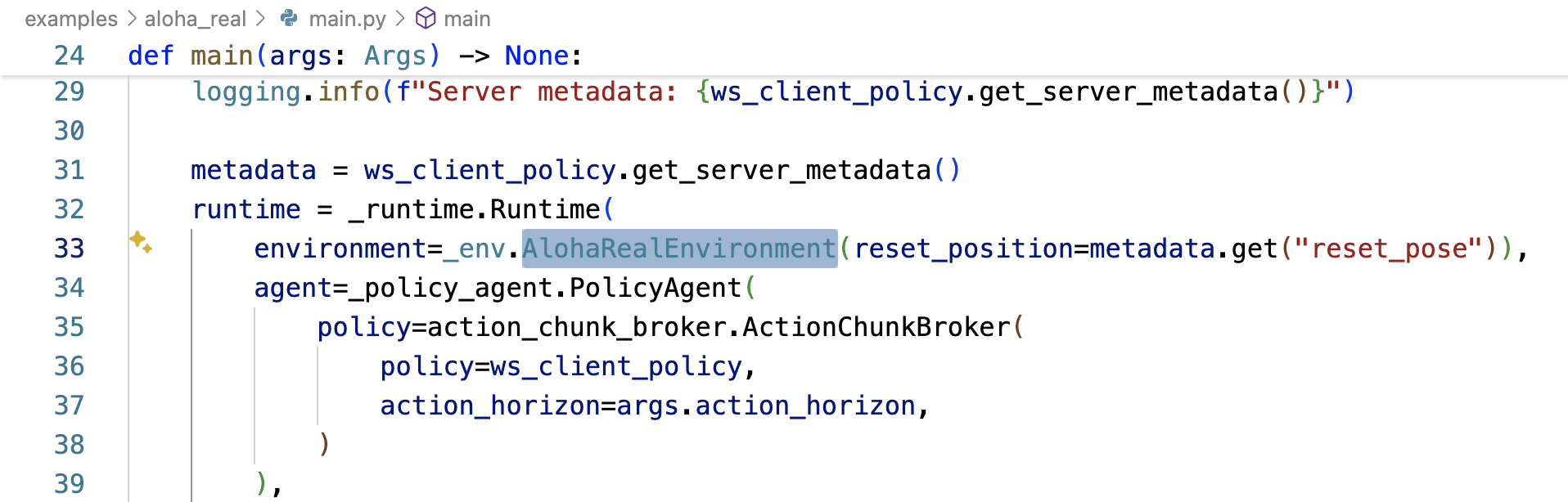
策略對象的metadata屬性會包含default_prompt,且其在policy_metadata = policy.metadata時被提取出來policy_metadata = policy.metadata
而上面這個WebsocketPolicyServer,被定義在
src/openpi/serving/websocket_policy_server.py
于此,(scripts/serve_policy.py中的)policy_metadata傳遞給它(openpi/serving中的WebsocketPolicyServer),存儲在服務器中的self._metadata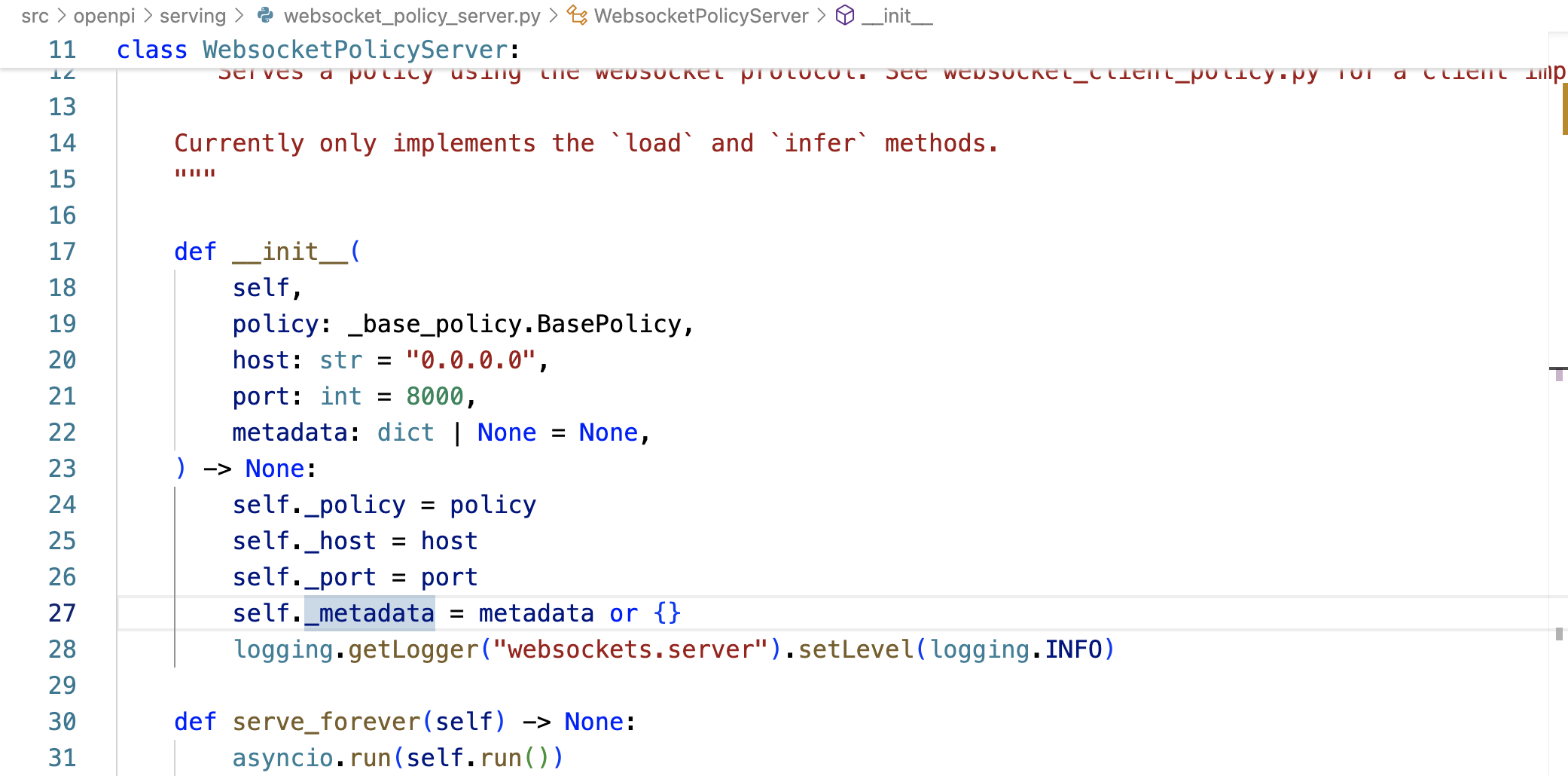
上面那個serve_forever被定義在src/openpi/serving/websocket_policy_server.py中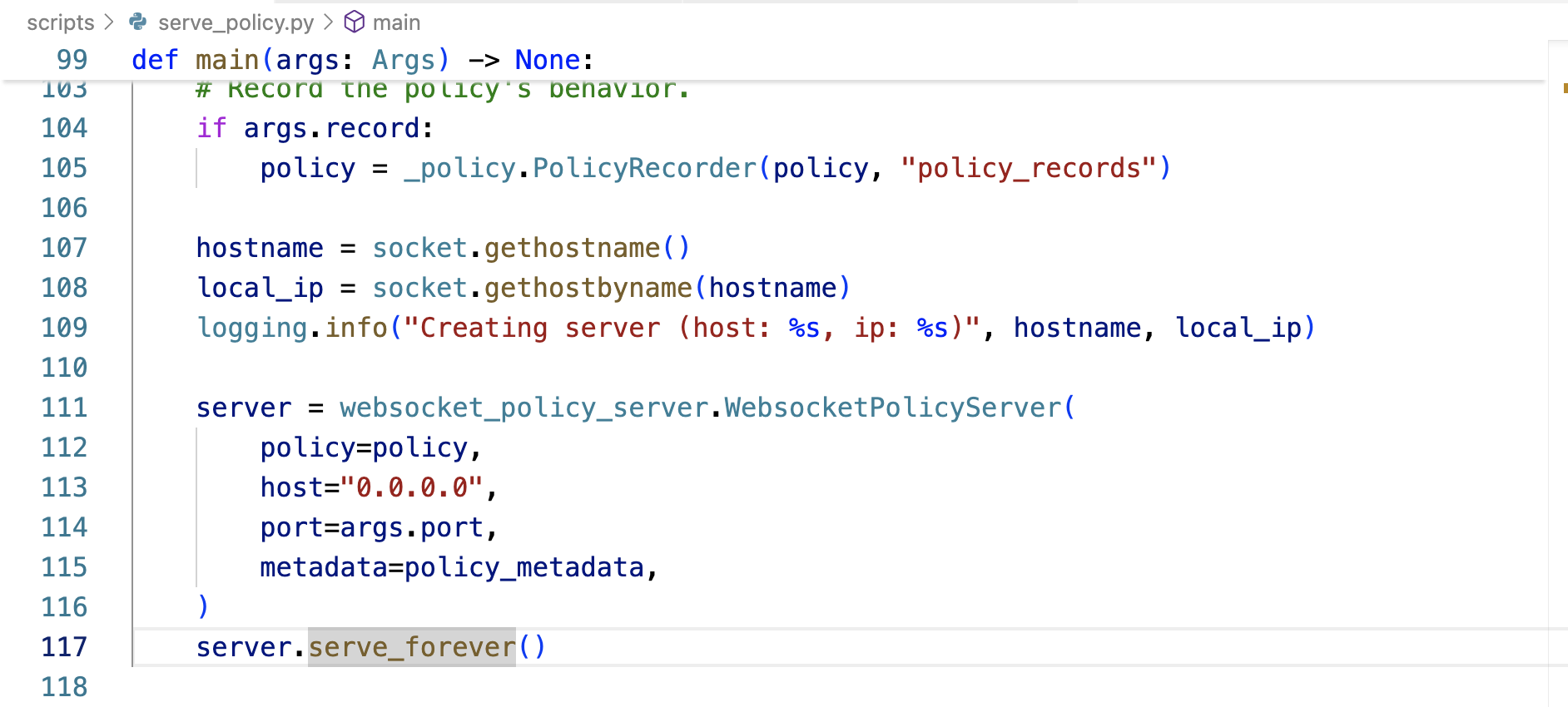
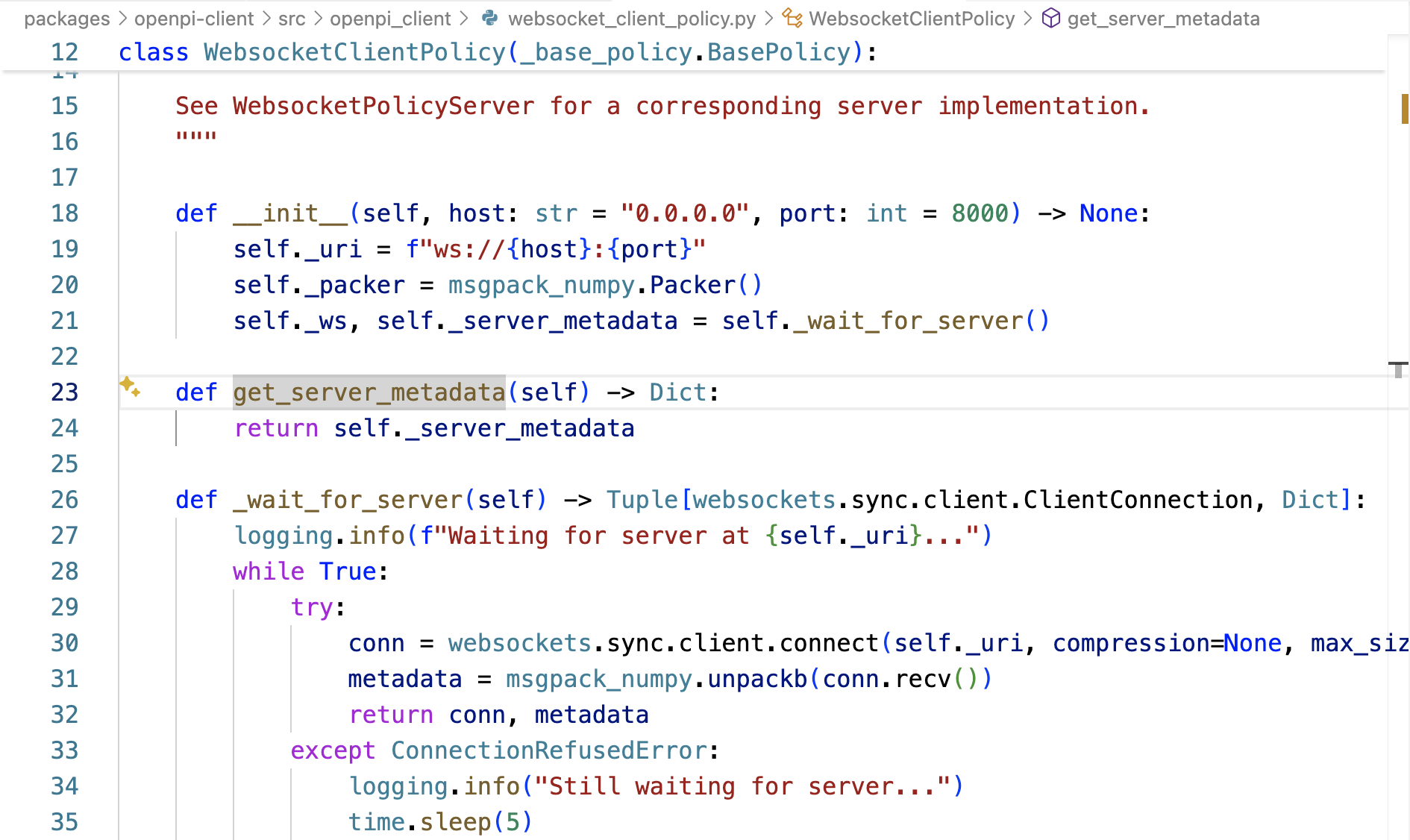
- 啟動WebSocket客戶端:WebsocketClientPolicy
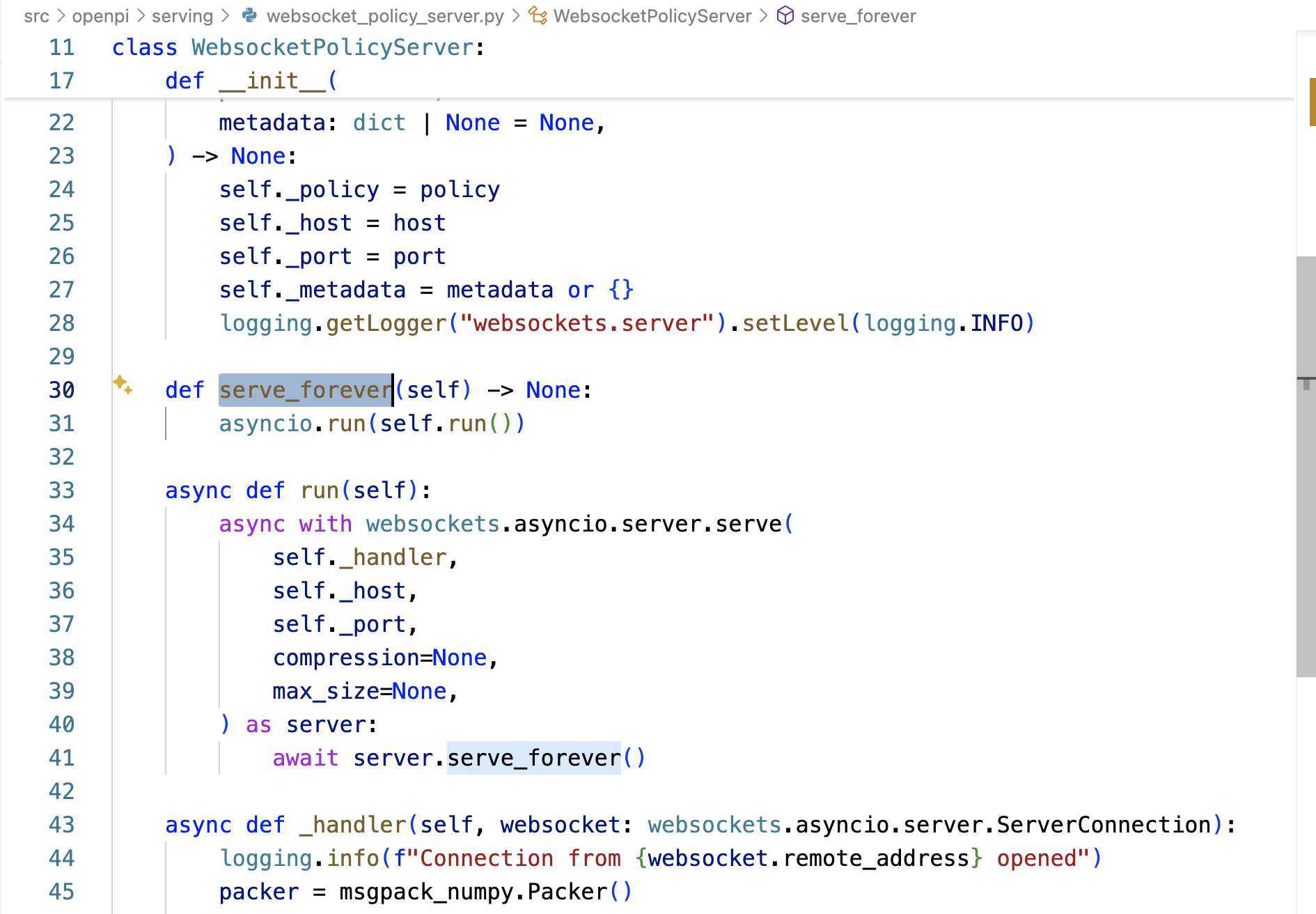
packages/openpi-client/src/openpi_client/websocket_client_policy.py中的WebsocketClientPolicy被初始化時,調用_wait_for_server 連接WebSocket服務端
服務端WebsocketPolicyServer的_handler方法在接受連接后,立即發送self._metadata——await websocket.send(packer.pack(self._metadata)) 給客戶端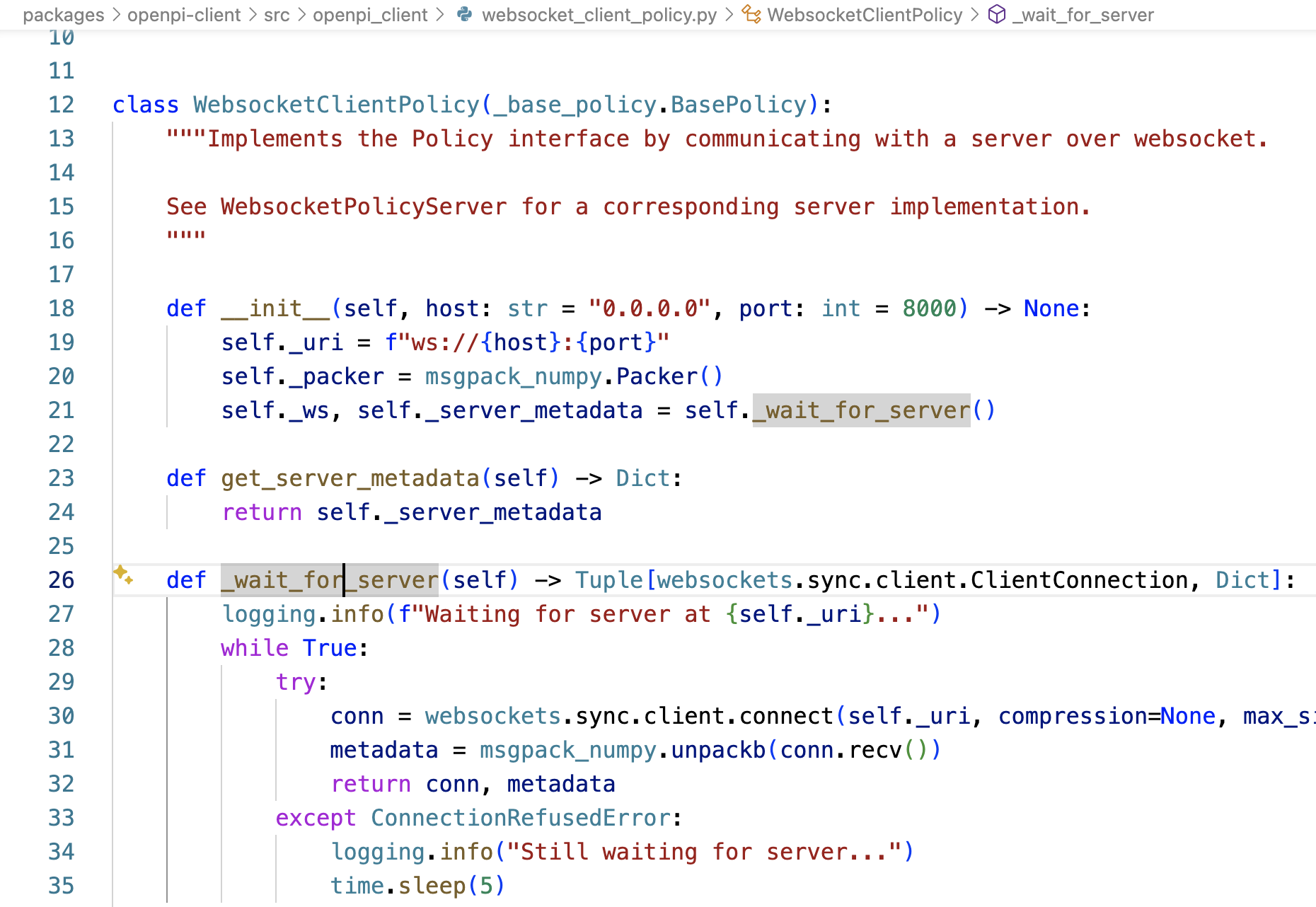
客戶端_wait_for_server的接收到這個元數據之后,便存儲在_server_metadata中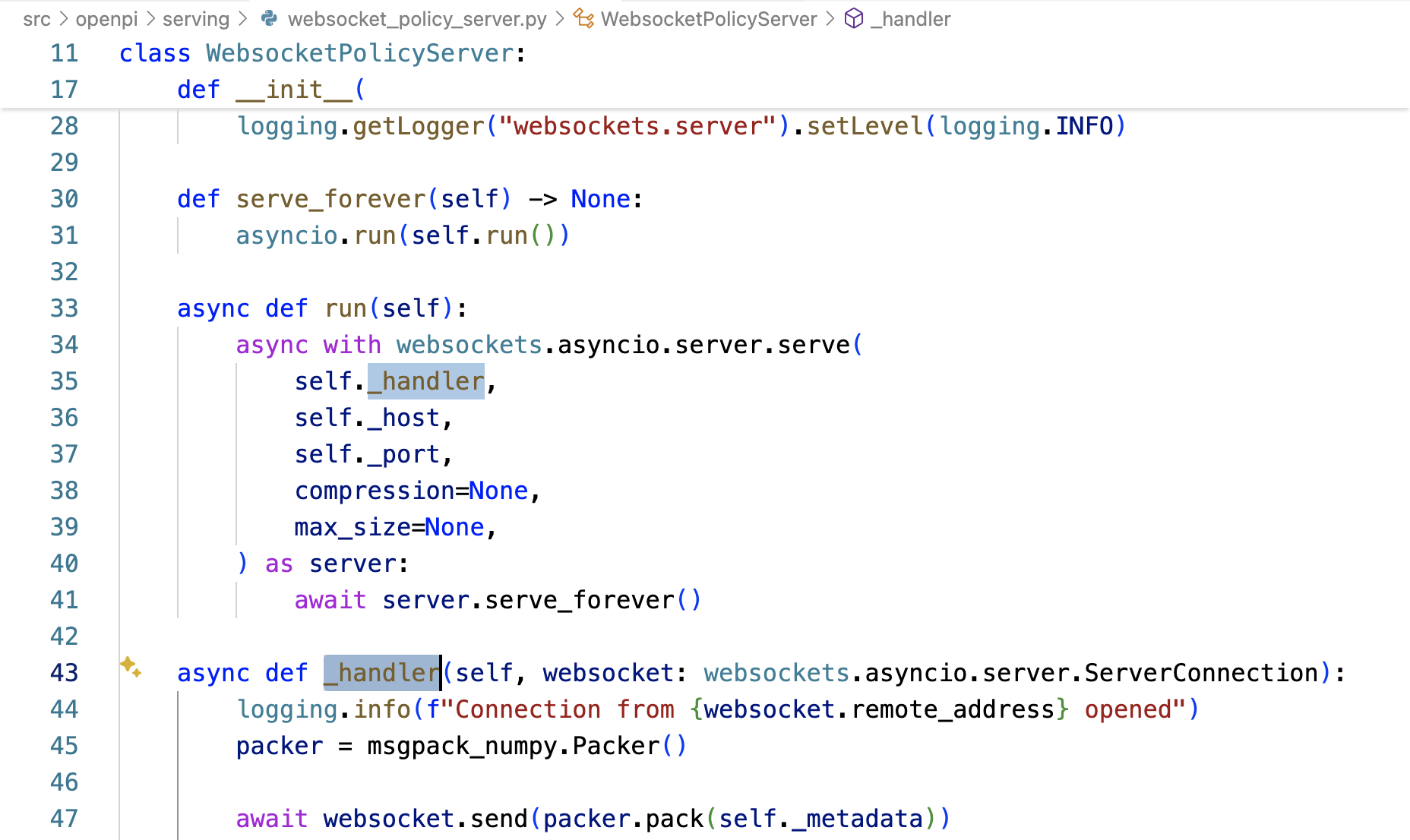
第二階段,客戶端發送推理請求、服務端處理推理請求
- 推理請求:客戶端向服務端發送全部數據
- 服務器處理推理請求
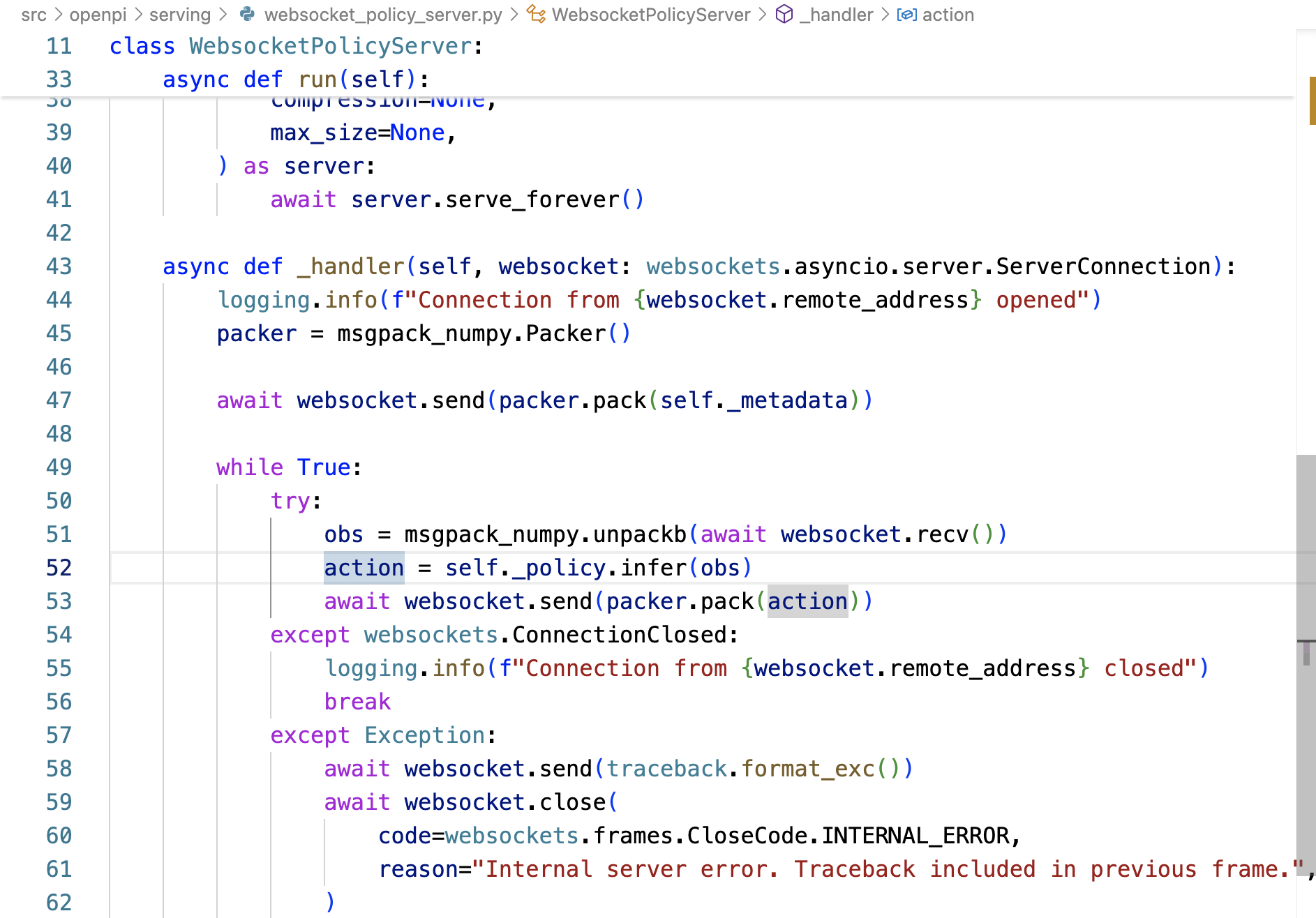
策略內部處理 (policies 下的具體策略文件)——策略的 `infer` 方法被調用以獲取prompt
由于傳入的 `obs` 字典沒有?`"prompt"` 鍵,策略會查找并使用它在步驟 1 中存儲的 `self._default_prompt`,類似prompt_to_use = obs.get("prompt", self._default_prompt)`。這里 `prompt_to_use` 會被賦值為自定義的指令字符串
第三階段,模型獲得全部輸入數據,生成動作序列
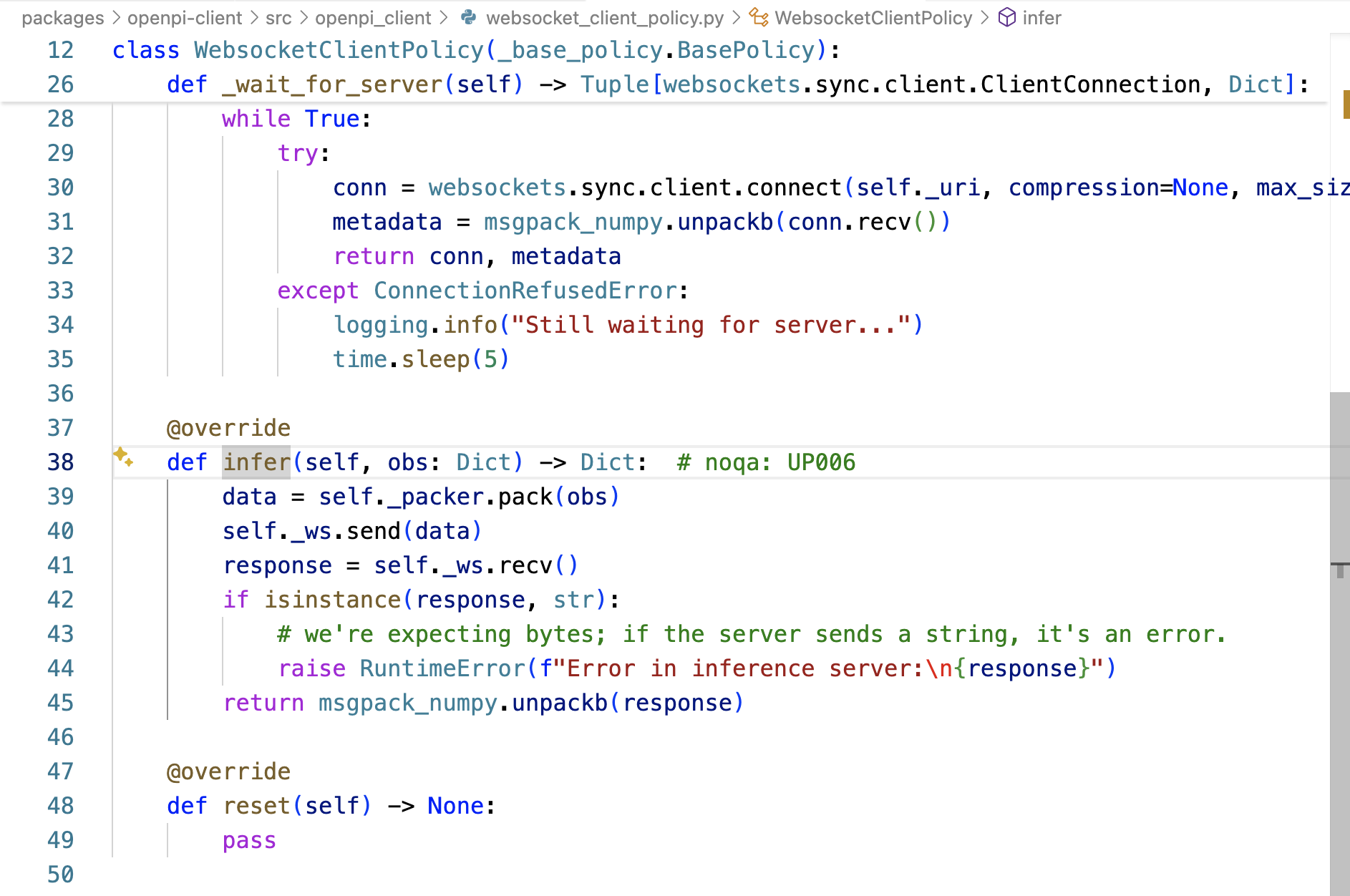
- 獲取到的prompt被傳遞給分詞器Tokennizer,其將文本指令轉換為token ID序列
這些token ID序列與圖像數據、狀態數據一起被輸入到π0中 - π0處理這些輸入,生成預測的動作序列
// 待更
4.2.4?train_test.py:訓練和測試模型
4.2.5?train.py:訓練模型——損失函數計算、梯度下降、參數更新
這段代碼是一個基于JAX的分布式訓練腳本,集成了模型初始化、訓練循環、日志記錄、實驗跟蹤和檢查點管理等功能。以下是對代碼的模塊化解讀:
一開始先后涉及日志初始化 (`init_logging`)、Weights & Biases 初始化 (`init_wandb`)、權重加載與驗證 (`_load_weights_and_validate`)
之后是訓練狀態初始化 (`init_train_state`)
- 創建優化器(`tx`)和模型實例
- 合并預訓練參數(若有)到模型狀態
- 參數類型轉換(如凍結參數轉`bfloat16`)
- 定義分布式分片策略(`fsdp_sharding`)
- 返回值:包含模型參數、優化器狀態、EMA參數的`TrainState`對象及分片信息
再之后,是單步訓練`train_step`
- 前向計算:模型計算損失(啟用訓練模式),loss_fn中調用的損失函數來自——1.2.4.3 損失函數compute_loss:訓練模型去噪的準確率(含訓練數據集的來源介紹)
def train_step(config: _config.TrainConfig,rng: at.KeyArrayLike,state: training_utils.TrainState,batch: tuple[_model.Observation, _model.Actions], ) -> tuple[training_utils.TrainState, dict[str, at.Array]]:"""執行單個訓練步驟"""# 合并模型定義和參數model = nnx.merge(state.model_def, state.params)model.train() # 設置模型為訓練模式@at.typecheckdef loss_fn(model: _model.BaseModel, rng: at.KeyArrayLike, observation: _model.Observation, actions: _model.Actions):"""損失函數"""# 計算每個數據項的損失chunked_loss = model.compute_loss(rng, observation, actions, train=True)return jnp.mean(chunked_loss) # 返回平均損失 - 隨機數生成
# 根據當前步數折疊隨機數種子,確保每步使用不同隨機數train_rng = jax.random.fold_in(rng, state.step)# 解包批次數據observation, actions = batch - 梯度計算:通過`nnx.value_and_grad`獲取梯度,僅更新可訓練參數
# 過濾出可訓練參數diff_state = nnx.DiffState(0, config.trainable_filter)# 計算損失和梯度loss, grads = nnx.value_and_grad(loss_fn, argnums=diff_state)(model, train_rng, observation, actions) - 參數更新:應用優化器更新,合并新參數到模型
# 過濾出可訓練參數params = state.params.filter(config.trainable_filter)# 使用優化器更新參數updates, new_opt_state = state.tx.update(grads, state.opt_state, params)new_params = optax.apply_updates(params, updates)# 更新模型參數并返回新的完整狀態nnx.update(model, new_params)new_params = nnx.state(model) - EMA維護:指數平滑更新關鍵參數
# 創建新的訓練狀態,更新步數、參數和優化器狀態new_state = dataclasses.replace(state, step=state.step + 1, params=new_params, opt_state=new_opt_state)if state.ema_decay is not None:# 如果使用EMA,更新EMA參數new_state = dataclasses.replace(new_state,ema_params=jax.tree.map(lambda old, new: state.ema_decay * old + (1 - state.ema_decay) * new, state.ema_params, new_params),)# 過濾出核心參數(不包括偏置、縮放等)kernel_params = nnx.state(model,nnx.All(nnx.Param, # 必須是參數nnx.Not(nnx_utils.PathRegex(".*/(bias|scale|pos_embedding|input_embedding)")), # 排除特定名稱lambda _, x: x.value.ndim > 1, # 必須是多維的),) - 指標收集:損失、梯度范數、參數范數(過濾非核參數)
# 收集訓練信息info = {"loss": loss, # 損失值"grad_norm": optax.global_norm(grads), # 梯度范數"param_norm": optax.global_norm(kernel_params), # 參數范數}return new_state, info
最后是主函數`main`
- 環境初始化:日志、JAX配置、隨機種子、設備分片
- 數據準備:分布式數據加載器,分片策略(數據并行)
- 狀態恢復:檢查點管理器處理恢復邏輯。
- 訓練循環:
JIT編譯的分布式訓練步驟(`ptrain_step`)
定期日志記錄(控制臺 + W&B)
檢查點保存(間隔保存 + 最終保存) - 清理:等待異步保存操作完成
// 待更
4.2.6 scripts/docker
好的,下面是對 `openpi-main/scripts/docker` 目錄的詳細分析。這個目錄通包含與 Docker 相關的腳本和配置文件,用于構建和管理 Docker 容器,具體而言,包含以下文件和子目錄:

主要文件和功能如下所示
- docker/compose.yml
- docker/install_docker_ubuntu22.sh
- docker/install_nvidia_container_toolkit.sh
- docker/serve_policy.Dockerfile
// 待更
第五部分 examples :各種機器人平臺及策略客戶端的示例實現
根據π0對應examples模塊的結構

其涉及以下模塊
- aloha_real/:真實機器人ALOHA的示例
- aloha_sim/:ALOHA模擬器的示例
- droid/:DROID機器人的示例
- libero/:LIBERO基準測試的示例
- simple_client/:簡單客戶端的示例
- ur5/:UR5機器人的示例
- inference.ipynb:推理示例的Jupyter Notebook
- policy_records.ipynb:策略記錄示例的Jupyter Notebook
5.1?aloha_real
`aloha_real` 模塊是OpenPI項目中用于控制真實ALOHA雙臂機器人的完整實現。它提供了從OpenPI策略模型到真實機器人硬件的完整控制鏈路
5.1.1 核心架構
- 主控制流程 (main.py)
作為系統入口點,協調各個組件
其關鍵組件包括
- 環境接口 (env.py 和 real_env.py)
`AlohaRealEnvironment` (高級封裝):提供標準化的環境接口、處理圖像預處理和尺寸調整 (224x224)、將圖像格式從 HWC 轉換為 CHW
`RealEnv` (底層硬件接口)
? [left_arm_qpos(6), left_gripper(1), right_arm_qpos(6), right_gripper(1)]
`qpos`: 關節位置 (14維)
`qvel`: 關節速度 (14維)?
`images`: 4個攝像頭視角
- `cam_high`: 俯視視角
- `cam_low`: 平視視角
- `cam_left_wrist`: 左手腕視角
- `cam_right_wrist`: 右手腕視角 - 硬件常量定義 (constants.py)
關節名稱: `["waist", "shoulder", "elbow", "forearm_roll", "wrist_angle", "wrist_rotate"]`
夾爪位置限制: 開合狀態的物理限位
標準化函數: 將夾爪位置映射到[0,1]區間
默認復位姿態: `[0, -0.96, 1.16, 0, -0.3, 0]` - 數據轉換工具
convert_aloha_data_to_lerobot.py
robot_utils.py
包含機器人設置和數據記錄工具
Recorder: 記錄關節狀態數據
ImageRecorder: 記錄攝像頭圖像數據
5.1.2 系統工作流程與部署方式
- 初始化階段
啟動ROS節點 → 初始化雙臂機器人 → 連接攝像頭 → 建立WebSocket連接 - 運行時循環(50Hz)
獲取觀察(圖像+狀態) → 發送到策略服務器 → 接收動作序列 → 執行動作 → 更新狀態 - 動作執行
策略預測25步動作序列
`ActionChunkBroker`管理動作緩沖和執行
每步動作包含14維關節目標位置
至于部署方式有以下兩種
一個是Docker部署,則直接安裝 Docker 并運行
export SERVER_ARGS="--env ALOHA --default_prompt='take the toast out of the toaster'"
docker compose -f examples/aloha_real/compose.yml up --build一個是本地部署,其需要啟動3個終端
[終端1] 機器人客戶端 ←→ WebSocket ←→ [終端3] 策略服務器/serve_policy.py↓ ↑
[終端2] ROS硬件層 OpenPI模型推理- 機器人控制客戶端,相當于WebSocket客戶端
該客戶端從機器人硬件獲取觀察數據(圖像 + 狀態),然后通過WebSocket發送觀察數據到策略服務器
之后,接收策略服務器返回的動作指令,將動作指令發送給機器人執行
————————————————
具體而言,初始化虛擬環境并運行機器人控制主程序
以上代碼分別對應# Create virtual environment uv venv --python 3.10 examples/aloha_real/.venv source examples/aloha_real/.venv/bin/activate uv pip sync examples/aloha_real/requirements.txt uv pip install -e packages/openpi-client# Run the robot python -m examples.aloha_real.main
1 創建Python 3.10虛擬環境
使用 uv 工具創建一個 Python 虛擬環境,路徑為 examples/aloha_real/.venv ?
uv 是一個替代 venv + pip 的高性能依賴管理工具
2 激活虛擬環境
進入剛才創建的虛擬環境,使之后的 Python 執行與 pip 安裝都僅作用于該環境
3 安裝所需依賴
安裝 requirements.txt 中精確指定的依賴版本
sync 是比 install -r 更穩定的方式,確保包版本鎖定且無冗余
4 安裝 openpi-client 為本地開發模式
使用 -e(editable)方式安裝本地 openpi-client 包,允許實時修改代碼而無需重裝
5 啟動主程序控制機器人(主線程)
啟動 Pi0 控制機器人動作的主循環,包括攝像頭讀取、電機控制、感知更新等
此模塊會連接 ROS 節點并與推理服務通信 - ROS節點服務
其作用為:啟動機器人硬件驅動、啟動攝像頭節點、提供底層硬件接口
————————————————
具體而言,啟動ROS驅動
使用 ROS 啟動 aloha 平臺硬件驅動,包括:roslaunch aloha ros_nodes.launch
控制機械臂的 Dynamixel 電機驅動
相機接口節點
ROS 的 topic 廣播、TF 樹等
這一步是讓機器人硬件對接 ROS 網絡層,確保后續主控程序可調用硬件資源PS:如姚博士所說,此處 ROS 配置根據項目子模塊配置,以及 ROS 系統主要針對 ALOHA 一類的舵機機器人
- openpi策略服務器,相當于WebSocket服務器
其作用為:加載訓練好的openpi模型,監聽WebSocket連接,以及接收觀察數據 運行策略推理,從而最終返回動作序列
————————————————
具體而言,運行策略推理服務器
上述代碼相當于啟動 serve_policy.py 推理服務:uv run scripts/serve_policy.py --env ALOHA --default_prompt='take the toast out of the toaster'
加載一個策略(如 pi0)和預訓練權重
等待來自主控制進程的請求(語言提示 + 視覺輸入)
返回動作序列給控制主進程
綜上,三進程間的協同流程可以總結為:
[ROS系統(終端2)] <== 硬件數據 ==> [主控進程 main.py(終端1)] <== 請求 ==> [推理服務 serve_policy.py(終端3)]即三個終端分別主要負責:
- 啟動虛擬環境 + 控制主邏輯,控制主程序需要同步感知與動作控制
- 啟動 ROS 節點驅動機器人硬件,ROS 啟動通常是獨立的進程
- 啟動語言策略模型的推理服務,推理服務需常駐監聽 socket 請求
// 待更







)







)



)