目錄
一、實驗目的
二、實驗環境
三、實驗內容
3.1 ??LM_BoundBox
3.1.1 實驗代碼
3.1.2 實驗結果
3.2 ??LM_Anchor
3.2.1 實驗代碼
3.2.2 實驗結果
3.3 ??LM_Multiscale-object-detection
3.3.1 實驗代碼
3.3.2 實驗結果
四、實驗小結
一、實驗目的
- 了解python語法
- 了解目標檢測的原理
- 了解邊界框、錨框、多尺度目標檢測的實現
二、實驗環境
Baidu 飛槳AI Studio
三、實驗內容
3.1 ??LM_BoundBox
3.1.1 實驗代碼
%matplotlib?inline
import?torch
from?d2l?import?torch?as?d2l
d2l.set_figsize()
img?=?d2l.plt.imread('./img/catdog.jpg')
d2l.plt.imshow(img);def?box_corner_to_center(boxes):x1,?y1,?x2,?y2?=?boxes[:,?0],?boxes[:,?1],?boxes[:,?2],?boxes[:,?3]cx?=?(x1?+?x2)?/?2cy?=?(y1?+?y2)?/?2w?=?x2?-?x1h?=?y2?-?y1boxes?=?torch.stack((cx,?cy,?w,?h),?axis=-1)return?boxesdef?box_center_to_corner(boxes):cx,?cy,?w,?h?=?boxes[:,?0],?boxes[:,?1],?boxes[:,?2],?boxes[:,?3]x1?=?cx?-?0.5?*?wy1?=?cy?-?0.5?*?hx2?=?cx?+?0.5?*?wy2?=?cy?+?0.5?*?hboxes?=?torch.stack((x1,?y1,?x2,?y2),?axis=-1)return?boxes
dog_bbox?,?cat_bbox=[60.0,?45.0,?378.0,?516.0],?[400.0,?112.0,?655.0,?493.0]?
boxes?=?torch.tensor((dog_bbox,?cat_bbox))
box_center_to_corner(box_corner_to_center(boxes))?==?boxesdef?bbox_to_rect(bbox,?color):return?d2l.plt.Rectangle(xy=(bbox[0],?bbox[1]),?width=bbox[2]-bbox[0],?height=bbox[3]-bbox[1],fill=False,?edgecolor=color,?linewidth=2)
fig?=?d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox,?'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox,?'red'));import?torch
from?d2l?import?torch?as?d2l
d2l.set_figsize()
img2=d2l.plt.imread('./img/dog1.jpg')
d2l.plt.imshow(img2);
def?box_corner_to_center(boxes):x1,?y1,?x2,?y2?=?boxes[:,?0],?boxes[:,?1],?boxes[:,?2],?boxes[:,?3]cx?=?(x1?+?x2)?/?2cy?=?(y1?+?y2)?/?2w?=?x2?-?x1h?=?y2?-?y1boxes?=?torch.stack((cx,?cy,?w,?h),?axis=-1)return?boxes
def?box_center_to_corner(boxes):cx,?cy,?w,?h?=?boxes[:,?0],?boxes[:,?1],?boxes[:,?2],?boxes[:,?3]x1?=?cx?-?0.5?*?wy1?=?cy?-?0.5?*?hx2?=?cx?+?0.5?*?wy2?=?cy?+?0.5?*?hboxes?=?torch.stack((x1,?y1,?x2,?y2),?axis=-1)
return?boxes
dog_box=[250.0,50.0,1080.0,1200.0]
box_test?=?torch.tensor(dog_box).view(1,?-1)
centered_box?=?box_corner_to_center(box_test)
print("Centered?box:",?centered_box)cornered_box?=?box_center_to_corner(centered_box)
print("Cornered?box:",?cornered_box)
def?bbox_to_rect(bbox,?color):return?d2l.plt.Rectangle(xy=(bbox[0],?bbox[1]),?width=bbox[2]-bbox[0],?height=bbox[3]-bbox[1],fill=False,?edgecolor=color,?linewidth=2)
fig?=?d2l.plt.imshow(img2)
fig.axes.add_patch(bbox_to_rect(dog_box,?'blue'))代碼分析:
在代碼中,定義兩種對邊界框的表示,box_corner_to_center從兩角表示轉換為中心寬度表示,而box_center_to_corner從中心寬度表示轉換為兩角表示。輸入參數boxes可以是長度為4的張量,也可以是形狀為(nn,4)的二維張量,其中nn是邊界框的數量。將邊界框在圖中畫出,定義一個輔助函數bbox_to_rect。 它將邊界框表示成matplotlib的邊界框格式。
3.1.2 實驗結果
如下圖所示,在下面圖像中標記圖像中包含對象的邊界框。
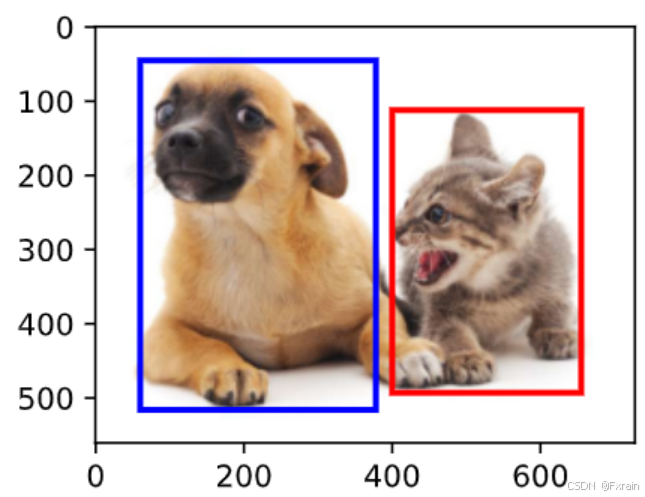
圖 1
常見的邊界框表示方法有兩種:
1.角點表示法:用左上角和右下角的坐標來表示邊界框。例如,對于邊界框 (x1, y1, x2, y2),其中 (x1, y1) 是左上角的坐標,(x2, y2) 是右下角的坐標。
2.中心點表示法:用中心點的坐標、寬度和高度來表示邊界框。例如,對于邊界框 (cx, cy, w, h),其中 (cx, cy) 是中心點的坐標,w 是寬度,h 是高度。函數 box_corner_to_center 和 box_center_to_corner 分別實現了從角點表示法到中心點表示法的轉換,以及從中心點表示法到角點表示法的轉換。
在這兩個函數中,輸入參數的最內層維度總是4,這是因為每個邊界框需要四個值來表示其位置信息。無論是使用角點表示法還是中心點表示法,都需要這四個值: 對于角點表示法,需要 (x1, y1, x2, y2) 四個值。 對于中心點表示法,需要 (cx, cy, w, h) 四個值。 因此,輸入參數的最內層維度總是4。
3.2 ??LM_Anchor
3.2.1 實驗代碼
%matplotlib?inline
import?torch
from?d2l?import?torch?as?d2ltorch.set_printoptions(2)??def?multibox_prior(data,?sizes,?ratios):in_height,?in_width?=?data.shape[-2:]device,?num_sizes,?num_ratios?=?data.device,?len(sizes),?len(ratios)boxes_per_pixel?=?(num_sizes?+?num_ratios?-?1)size_tensor?=?torch.tensor(sizes,?device=device)ratio_tensor?=?torch.tensor(ratios,?device=device)offset_h,?offset_w?=?0.5,?0.5steps_h?=?1.0?/?in_height??steps_w?=?1.0?/?in_width?center_h?=?(torch.arange(in_height,?device=device)?+?offset_h)?*?steps_hcenter_w?=?(torch.arange(in_width,?device=device)?+?offset_w)?*?steps_wshift_y,?shift_x?=?torch.meshgrid(center_h,?center_w)shift_y,?shift_x?=?shift_y.reshape(-1),?shift_x.reshape(-1)w?=?torch.cat((size_tensor?*?torch.sqrt(ratio_tensor[0]),sizes[0]?*?torch.sqrt(ratio_tensor[1:])))\*?in_height?/?in_width??h?=?torch.cat((size_tensor?/?torch.sqrt(ratio_tensor[0]),sizes[0]?/?torch.sqrt(ratio_tensor[1:])))anchor_manipulations?=?torch.stack((-w,?-h,?w,?h)).T.repeat(in_height?*?in_width,?1)?/?2out_grid?=?torch.stack([shift_x,?shift_y,?shift_x,?shift_y],dim=1).repeat_interleave(boxes_per_pixel,?dim=0)output?=?out_grid?+?anchor_manipulationsreturn?output.unsqueeze(0)img?=?d2l.plt.imread('./img/catdog.jpg')
h,?w?=?img.shape[:2]print(h,?w)
X?=?torch.rand(size=(1,?3,?h,?w))
Y?=?multibox_prior(X,?sizes=[0.75,?0.5,?0.25],?ratios=[1,?2,?0.5])
Y.shapeboxes?=?Y.reshape(h,?w,?5,?4)
boxes[250,?250,?0,?:]def?show_bboxes(axes,?bboxes,?labels=None,?colors=None):def?_make_list(obj,?default_values=None):if?obj?is?None:obj?=?default_valueselif?not?isinstance(obj,?(list,?tuple)):obj?=?[obj]return?objlabels?=?_make_list(labels)colors?=?_make_list(colors,?['b',?'g',?'r',?'m',?'c'])for?i,?bbox?in?enumerate(bboxes):color?=?colors[i?%?len(colors)]rect?=?d2l.bbox_to_rect(bbox.detach().numpy(),?color)axes.add_patch(rect)if?labels?and?len(labels)?>?i:text_color?=?'k'?if?color?==?'w'?else?'w'axes.text(rect.xy[0],?rect.xy[1],?labels[i],va='center',?ha='center',?fontsize=9,?color=text_color,bbox=dict(facecolor=color,?lw=0))d2l.set_figsize()
bbox_scale?=?torch.tensor((w,?h,?w,?h))
fig?=?d2l.plt.imshow(img)
show_bboxes(fig.axes,?boxes[250,?250,?:,?:]?*?bbox_scale,['s=0.75,?r=1',?'s=0.5,?r=1',?'s=0.25,?r=1',?'s=0.75,?r=2','s=0.75,?r=0.5'])def?box_iou(boxes1,?boxes2):box_area?=?lambda?boxes:?((boxes[:,?2]?-?boxes[:,?0])?*(boxes[:,?3]?-?boxes[:,?1]))areas1?=?box_area(boxes1)areas2?=?box_area(boxes2)inter_upperlefts?=?torch.max(boxes1[:,?None,?:2],?boxes2[:,?:2])inter_lowerrights?=?torch.min(boxes1[:,?None,?2:],?boxes2[:,?2:])inters?=?(inter_lowerrights?-?inter_upperlefts).clamp(min=0)inter_areas?=?inters[:,?:,?0]?*?inters[:,?:,?1]union_areas?=?areas1[:,?None]?+?areas2?-?inter_areasreturn?inter_areas?/?union_areasdef?assign_anchor_to_bbox(ground_truth,?anchors,?device,?iou_threshold=0.5):num_anchors,?num_gt_boxes?=?anchors.shape[0],?ground_truth.shape[0]jaccard?=?box_iou(anchors,?ground_truth)anchors_bbox_map?=?torch.full((num_anchors,),?-1,?dtype=torch.long,device=device)max_ious,?indices?=?torch.max(jaccard,?dim=1)anc_i?=?torch.nonzero(max_ious?>=?0.5).reshape(-1)box_j?=?indices[max_ious?>=?0.5]anchors_bbox_map[anc_i]?=?box_jcol_discard?=?torch.full((num_anchors,),?-1)row_discard?=?torch.full((num_gt_boxes,),?-1)for?_?in?range(num_gt_boxes):max_idx?=?torch.argmax(jaccard)box_idx?=?(max_idx?%?num_gt_boxes).long()anc_idx?=?(max_idx?/?num_gt_boxes).long()anchors_bbox_map[anc_idx]?=?box_idxjaccard[:,?box_idx]?=?col_discardjaccard[anc_idx,?:]?=?row_discardreturn?anchors_bbox_mapdef?offset_boxes(anchors,?assigned_bb,?eps=1e-6):c_anc?=?d2l.box_corner_to_center(anchors)c_assigned_bb?=?d2l.box_corner_to_center(assigned_bb)offset_xy?=?10?*?(c_assigned_bb[:,?:2]?-?c_anc[:,?:2])?/?c_anc[:,?2:]offset_wh?=?5?*?torch.log(eps?+?c_assigned_bb[:,?2:]?/?c_anc[:,?2:])offset?=?torch.cat([offset_xy,?offset_wh],?axis=1)return?offsetdef?multibox_target(anchors,?labels):batch_size,?anchors?=?labels.shape[0],?anchors.squeeze(0)batch_offset,?batch_mask,?batch_class_labels?=?[],?[],?[]device,?num_anchors?=?anchors.device,?anchors.shape[0]for?i?in?range(batch_size):label?=?labels[i,?:,?:]anchors_bbox_map?=?assign_anchor_to_bbox(label[:,?1:],?anchors,?device)bbox_mask?=?((anchors_bbox_map?>=?0).float().unsqueeze(-1)).repeat(1,?4)class_labels?=?torch.zeros(num_anchors,?dtype=torch.long,device=device)assigned_bb?=?torch.zeros((num_anchors,?4),?dtype=torch.float32,device=device)indices_true?=?torch.nonzero(anchors_bbox_map?>=?0)bb_idx?=?anchors_bbox_map[indices_true]class_labels[indices_true]?=?label[bb_idx,?0].long()?+?1assigned_bb[indices_true]?=?label[bb_idx,?1:]offset?=?offset_boxes(anchors,?assigned_bb)?*?bbox_maskbatch_offset.append(offset.reshape(-1))batch_mask.append(bbox_mask.reshape(-1))batch_class_labels.append(class_labels)bbox_offset?=?torch.stack(batch_offset)bbox_mask?=?torch.stack(batch_mask)class_labels?=?torch.stack(batch_class_labels)return?(bbox_offset,?bbox_mask,?class_labels)ground_truth?=?torch.tensor([[0,?0.1,?0.08,?0.52,?0.92],[1,?0.55,?0.2,?0.9,?0.88]])
anchors?=?torch.tensor([[0,?0.1,?0.2,?0.3],?[0.15,?0.2,?0.4,?0.4],[0.63,?0.05,?0.88,?0.98],?[0.66,?0.45,?0.8,?0.8],[0.57,?0.3,?0.92,?0.9]])fig?=?d2l.plt.imshow(img)
show_bboxes(fig.axes,?ground_truth[:,?1:]?*?bbox_scale,?['dog',?'cat'],?'k')
show_bboxes(fig.axes,?anchors?*?bbox_scale,?['0',?'1',?'2',?'3',?'4']);labels?=?multibox_target(anchors.unsqueeze(dim=0),ground_truth.unsqueeze(dim=0))
def?offset_inverse(anchors,?offset_preds):anc?=?d2l.box_corner_to_center(anchors)pred_bbox_xy?=?(offset_preds[:,?:2]?*?anc[:,?2:]?/?10)?+?anc[:,?:2]pred_bbox_wh?=?torch.exp(offset_preds[:,?2:]?/?5)?*?anc[:,?2:]pred_bbox?=?torch.cat((pred_bbox_xy,?pred_bbox_wh),?axis=1)predicted_bbox?=?d2l.box_center_to_corner(pred_bbox)return?predicted_bbox
def?nms(boxes,?scores,?iou_threshold):B?=?torch.argsort(scores,?dim=-1,?descending=True)keep?=?[]?while?B.numel()?>?0:i?=?B[0]keep.append(i)if?B.numel()?==?1:?breakiou?=?box_iou(boxes[i,?:].reshape(-1,?4),boxes[B[1:],?:].reshape(-1,?4)).reshape(-1)inds?=?torch.nonzero(iou?<=?iou_threshold).reshape(-1)B?=?B[inds?+?1]return?torch.tensor(keep,?device=boxes.device)def?multibox_detection(cls_probs,?offset_preds,?anchors,?nms_threshold=0.5,pos_threshold=0.009999999):device,?batch_size?=?cls_probs.device,?cls_probs.shape[0]anchors?=?anchors.squeeze(0)num_classes,?num_anchors?=?cls_probs.shape[1],?cls_probs.shape[2]out?=?[]for?i?in?range(batch_size):cls_prob,?offset_pred?=?cls_probs[i],?offset_preds[i].reshape(-1,?4)conf,?class_id?=?torch.max(cls_prob[1:],?0)predicted_bb?=?offset_inverse(anchors,?offset_pred)keep?=?nms(predicted_bb,?conf,?nms_threshold)all_idx?=?torch.arange(num_anchors,?dtype=torch.long,?device=device)combined?=?torch.cat((keep,?all_idx))uniques,?counts?=?combined.unique(return_counts=True)non_keep?=?uniques[counts?==?1]all_id_sorted?=?torch.cat((keep,?non_keep))class_id[non_keep]?=?-1class_id?=?class_id[all_id_sorted]conf,?predicted_bb?=?conf[all_id_sorted],?predicted_bb[all_id_sorted]below_min_idx?=?(conf?<?pos_threshold)class_id[below_min_idx]?=?-1conf[below_min_idx]?=?1?-?conf[below_min_idx]pred_info?=?torch.cat((class_id.unsqueeze(1),conf.unsqueeze(1),predicted_bb),?dim=1)out.append(pred_info)return?torch.stack(out)
anchors?=?torch.tensor([[0.1,?0.08,?0.52,?0.92],?[0.08,?0.2,?0.56,?0.95],[0.15,?0.3,?0.62,?0.91],?[0.55,?0.2,?0.9,?0.88]])
offset_preds?=?torch.tensor([0]?*?anchors.numel())
cls_probs?=?torch.tensor([[0]?*?4,?[0.9,?0.8,?0.7,?0.1],?[0.1,?0.2,?0.3,?0.9]])?
fig?=?d2l.plt.imshow(img)
show_bboxes(fig.axes,?anchors?*?bbox_scale,['dog=0.9',?'dog=0.8',?'dog=0.7',?'cat=0.9'])
output?=?multibox_detection(cls_probs.unsqueeze(dim=0),offset_preds.unsqueeze(dim=0),anchors.unsqueeze(dim=0),nms_threshold=0.5)
output
fig?=?d2l.plt.imshow(img)
for?i?in?output[0].detach().numpy():if?i[0]?==?-1:continuelabel?=?('dog=',?'cat=')[int(i[0])]?+?str(i[1])show_bboxes(fig.axes,?[torch.tensor(i[2:])?*?bbox_scale],?label)代碼分析:
假設輸入圖像的高度為hh,寬度為ww。 我們以圖像的每個像素為中心生成不同形狀的錨框:比例為s∈(0,1]s∈(0,1],寬高比(寬高比)為r>0r>0。multibox_prior函數實現生成錨框,指定輸入圖像、尺度列表和寬高比列表,然后此函數將返回所有的錨框。將錨框變量Y的形狀更改為(圖像高度、圖像寬度、以同一像素為中心的錨框的數量,4)后,可以獲得以指定像素的位置為中心的所有錨框。 [訪問以(250,250)為中心的第一個錨框],它有四個元素:錨框左上角的(x,y)(x,y)軸坐標和右下角的(x,y)(x,y)軸坐標。 將兩個軸的坐標分別除以圖像的寬度和高度后,所得的值就介于0和1之間。定義show_bboxes函數來在圖像上繪制多個邊界框。
計算交并比來衡量錨框和真實邊界框之間、以及不同錨框之間的相似度。給定兩個錨框或邊界框的列表,通過box_iou函數在這兩個列表中計算它們成對的交并比。將真實邊界框分配給錨框,為每個錨框標記類別和偏移量。通過offset_inverse函數將錨框和偏移量預測作為輸入,并[應用逆偏移變換來返回預測的邊界框坐標]。再使用非極大值抑制(non-maximum suppression,NMS)合并屬于同一目標的類似的預測邊界框。最后返回預測邊界框和置信度。
3.2.2 實驗結果
(1)如下圖所示,在圖像中繪制錨框,并標記錨框的高寬比和縮放比
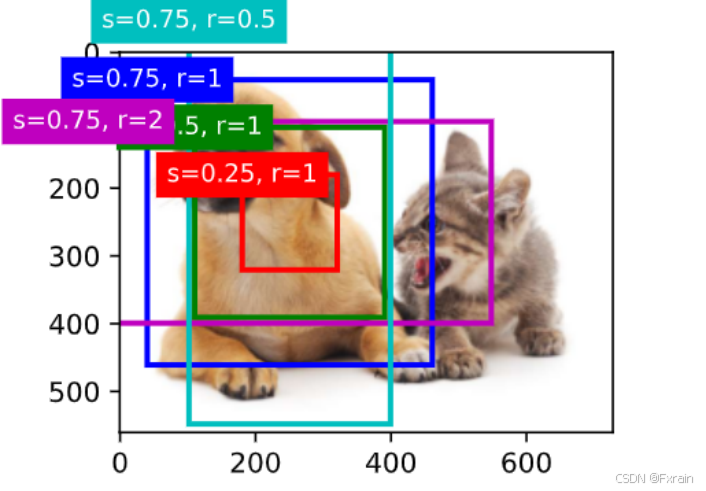
圖 3
(2)如下圖所示,在圖像中繪制邊界框和錨框,邊界框返回目標的類別(這里為“dog”和“cat”)。
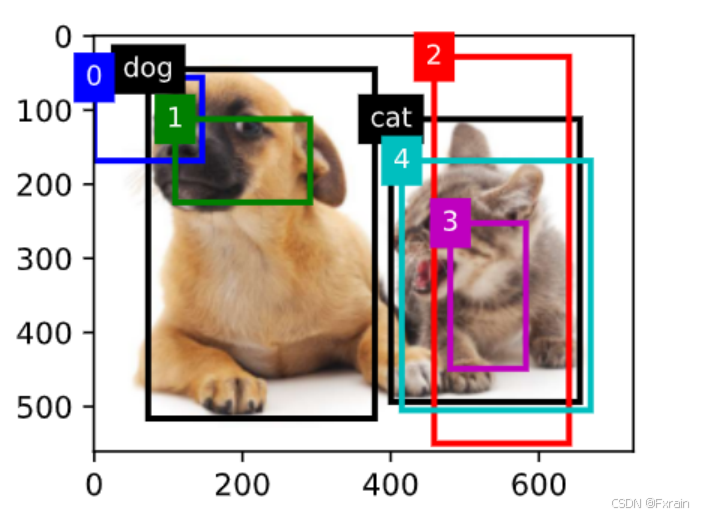
圖 4
(3)如下圖所示,在圖像上繪制預測邊界框和置信度

圖 6
(4)如下圖所示,輸出由非極大值抑制保存的最終預測邊界框
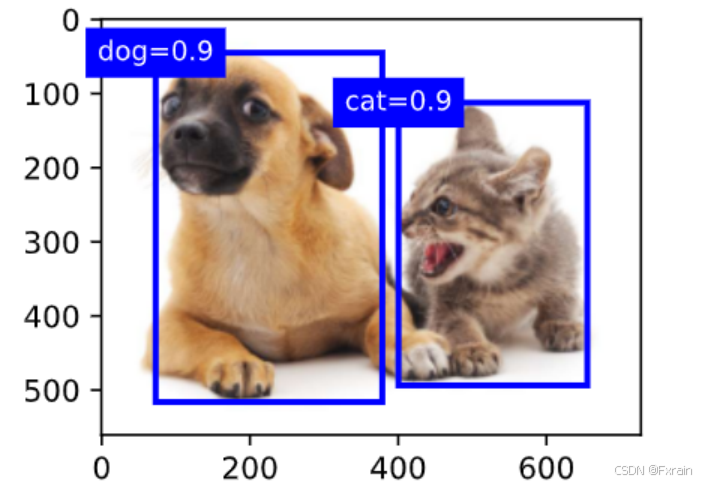
圖 7
在 multibox_prior 函數中,sizes 和 ratios 參數決定了生成的錨框的大小和長寬比。這些參數的變化將直接影響生成的錨框的形狀和分布。
(1)改變 sizes 參數。如果增加了 sizes 中的值,那么生成的錨框將會更大。如果減少了 sizes 中的值,那么生成的錨框將會更小。
(2)改變 ratios 參數。如果增加了 ratios 中的值,那么生成的錨框將會有更多不同的長寬比。如果減少了 ratios 中的值,那么生成的錨框將會更少地覆蓋不同的長寬比。
如果需要構建并可視化兩個IoU為0.5的邊界框,則代碼如下:
import?torchimport?matplotlib.pyplot?as?pltimport?matplotlib.patches?as?patchesdef?box_iou(boxes1,?boxes2):area1?=?(boxes1[:,?2]?-?boxes1[:,?0])?*?(boxes1[:,?3]?-?boxes1[:,?1])area2?=?(boxes2[:,?2]?-?boxes2[:,?0])?*?(boxes2[:,?3]?-?boxes2[:,?1])lt?=?torch.max(boxes1[:,?None,?:2],?boxes2[:,?:2])?rb?=?torch.min(boxes1[:,?None,?2:],?boxes2[:,?2:])??wh?=?(rb?-?lt).clamp(min=0)??inter?=?wh[:,?:,?0]?*?wh[:,?:,?1]??union?=?area1[:,?None]?+?area2?-?inter??return?inter?/?uniondef?visualize_iou_boxes(image,?ground_truth,?anchors,?iou_threshold=0.5):jaccard?=?box_iou(anchors,?ground_truth)max_ious,?indices?=?torch.max(jaccard,?dim=1)anc_i?=?torch.nonzero(max_ious?>=?iou_threshold).reshape(-1)box_j?=?indices[max_ious?>=?iou_threshold]fig,?ax?=?plt.subplots(1)ax.imshow(image)for?i?in?range(len(anc_i)):anchor?=?anchors[anc_i[i]]gt_box?=?ground_truth[box_j[i]]rect?=?patches.Rectangle((anchor[0],?anchor[1]),?anchor[2]?-?anchor[0],?anchor[3]?-?anchor[1],linewidth=1,?edgecolor='k',?facecolor='none')ax.add_patch(rect)rect?=?patches.Rectangle((gt_box[0],?gt_box[1]),?gt_box[2]?-?gt_box[0],?gt_box[3]?-?gt_box[1],linewidth=1,?edgecolor='b',?facecolor='none')ax.add_patch(rect)plt.show()image?=?plt.imread('./img/catdog.jpg')?ground_truth?=?torch.tensor([[50,?50,?400,?480],?[420,?150,?650,?480]])??anchors?=?torch.tensor([[60,?60,?380,?420],?[420,?190,?600,?450],?[100,?100,?200,?200],[450,200,600,350]])??visualize_iou_boxes(image,?ground_truth,?anchors,?iou_threshold=0.5)結果如下圖圖10所示,其中藍色為邊界框,黑色為錨框。可以看到,
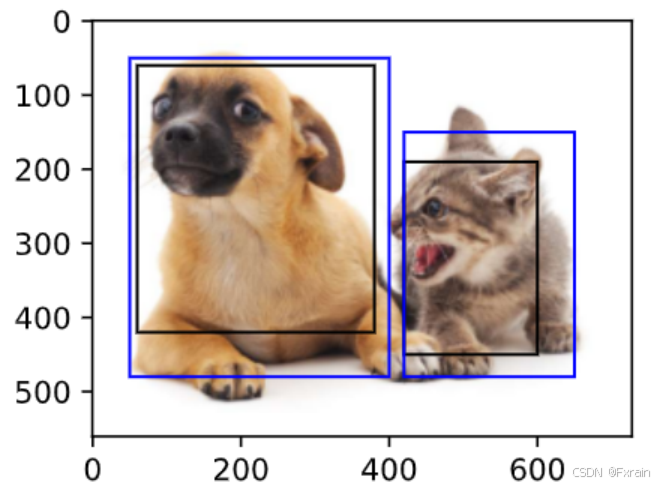
圖 10
在:numref:subsec_labeling-anchor-boxes中修改anchors變量會導致重新計算所有錨框與真實邊界框之間的 IoU,需要計算出新的IoU值。錨框的中心坐標和尺寸、中心坐標的偏移量、錨框的高寬比、最終的偏移量張量也會發生變化。總結來說,修改 anchors 會直接影響到錨框與真實邊界框之間的映射關系、偏移量計算以及最終的掩碼和類別標簽,從而導致整個函數的輸出結果發生變化。如圖11所示,修改anchors后的錨框尺寸改變。
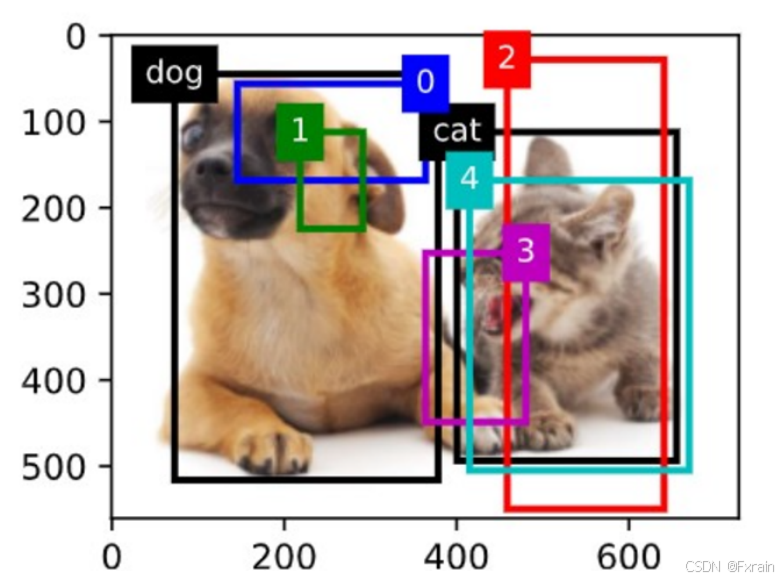
圖 11
在:numref:subsec_predicting-bounding-boxes-nms中修改anchors變量會導致錨框的位置變化,新的 anchors 會影響生成的邊界框的中心位置。如果 anchors 的中心位置不同,那么生成的邊界框的中心也會相應地移動。由于邊界框的位置和大小都發生了變化,最終的檢測結果可能會有所不同。這可能會導致一些目標被正確檢測到,而另一些目標則可能被漏檢或誤檢。如圖12、13、14所示,修改anchors后的錨框尺寸改變。
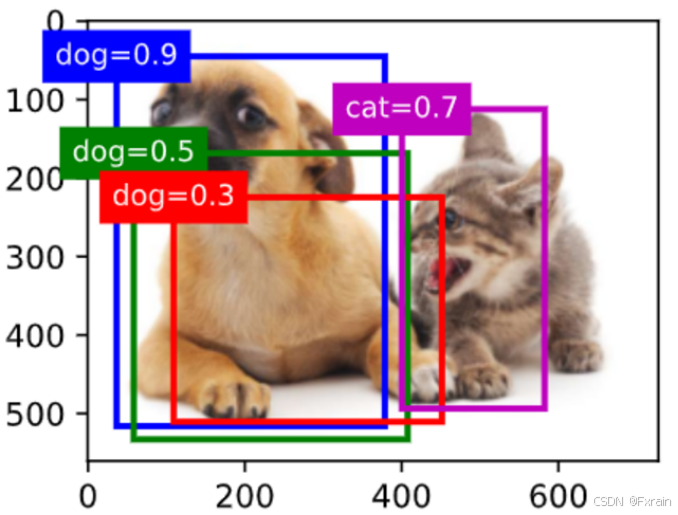
圖 12

圖 13
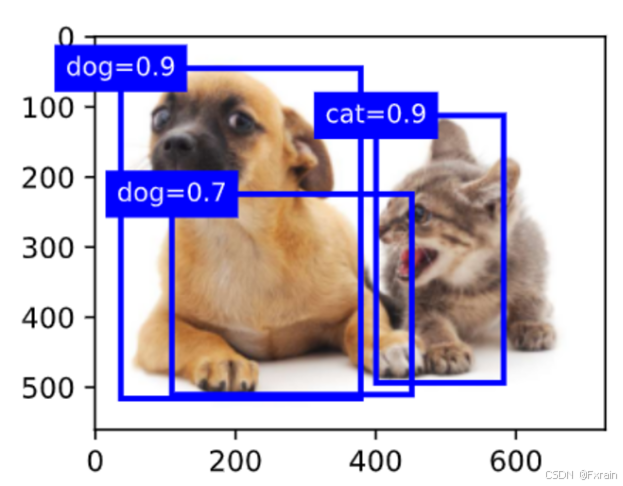
圖 14
3.3 ??LM_Multiscale-object-detection
3.3.1 實驗代碼
%matplotlib?inline
import?torch
from?d2l?import?torch?as?d2limg?=?d2l.plt.imread('./img/catdog.jpg')
h,?w?=?img.shape[:2]
h,?w
def?display_anchors(fmap_w,?fmap_h,?s):d2l.set_figsize()fmap?=?torch.zeros((1,?10,?fmap_h,?fmap_w))anchors?=?d2l.multibox_prior(fmap,?sizes=s,?ratios=[1,?2,?0.5])bbox_scale?=?torch.tensor((w,?h,?w,?h))d2l.show_bboxes(d2l.plt.imshow(img).axes,anchors[0]?*?bbox_scale)
display_anchors(fmap_w=4,?fmap_h=4,?s=[0.15])
display_anchors(fmap_w=2,?fmap_h=2,?s=[0.4])
display_anchors(fmap_w=1,?fmap_h=1,?s=[0.8])代碼分析:display_anchors函數均勻地對任何輸入圖像中fmap_h行和fmap_w列中的像素進行采樣。 以這些均勻采樣的像素為中心,將會生成大小為s(假設列表s的長度為1)且寬高比(ratios)不同的錨框。
3.3.2 實驗結果
如圖15所示,這里具有不同中心的錨框不會重疊: 錨框的尺度設置為0.15,特征圖的高度和寬度設置為4。 圖像上4行和4列的錨框的中心是均勻分布的。
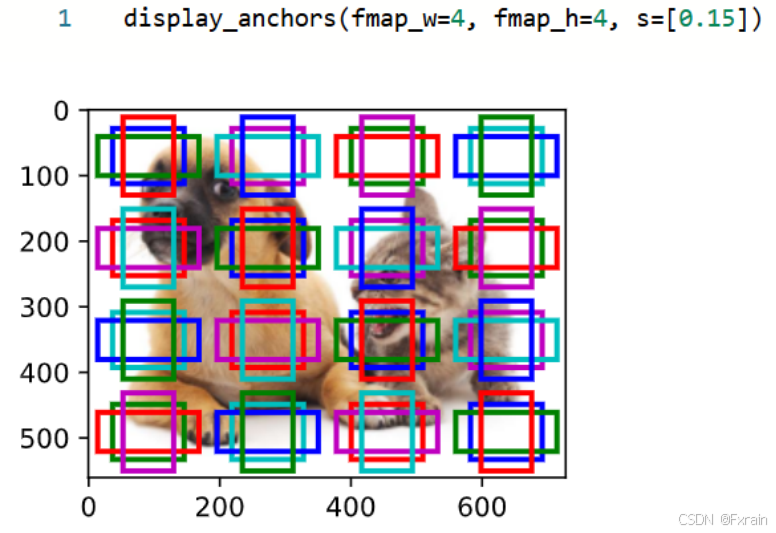
圖 15
如圖16所示,將特征圖的高度和寬度減小一半,然后使用較大的錨框來檢測較大的目標。 當尺度設置為0.4時,一些錨框將彼此重疊。
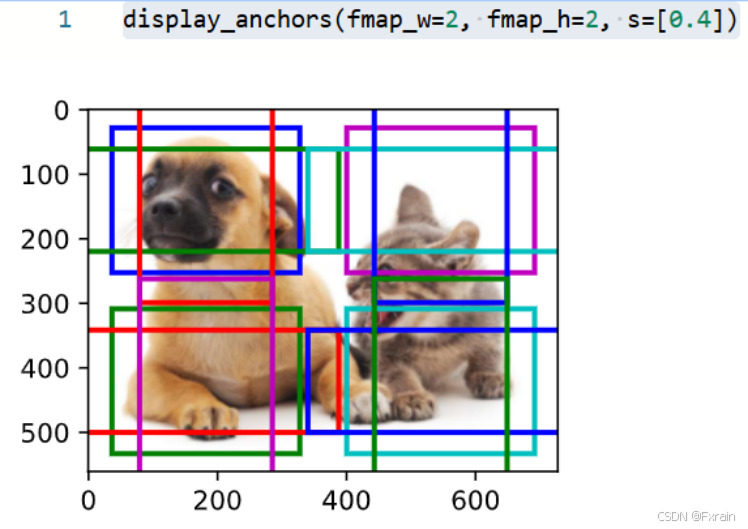
圖 16
如圖17所示,進一步將特征圖的高度和寬度減小一半,然后將錨框的尺度增加到0.8。 此時,錨框的中心即是圖像的中心。
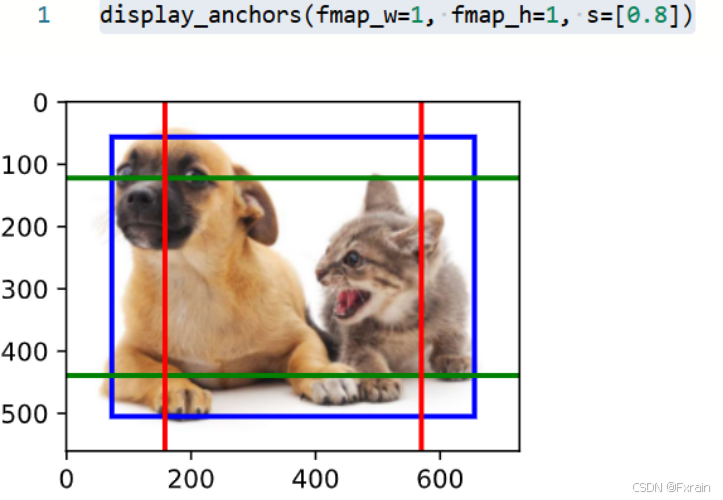
圖 17
深度神經網絡學習圖像特征級別抽象層次,隨網絡深度的增加而升級。在多尺度目標檢測中不同尺度的特征映射對應于不同的抽象層次。因為深度神經網絡在學習圖像特征時,會隨著網絡深度的增加而逐步從具體的細節特征轉向更高層次的語義信息。 深層網絡的感受野較大,能夠捕捉到更多的上下文信息和語義特征,但分辨率較低,幾何細節信息較弱。相反,低層網絡的感受野較小,能夠保留更多的幾何細節信息,但語義信息較弱。 深度神經網絡通過多個隱藏層的級聯,將輸入特征連續不斷地進行非線性處理,提取和變換出新的特征。 在多尺度目標檢測中,通常會結合不同尺度的特征映射來提高檢測性能。例如,在yolov3中,1/32大小的特征圖(深層)具有大的感受野,適合檢測大目標;而1/8大小的特征圖(較淺層)具有較小的感受野,適合檢測小目標。這種多尺度特征的融合能夠充分利用不同層次的特征信息,提高檢測的準確性和魯棒性。
給定形狀為1×c×h×w1×c×h×w的特征圖變量,其中cc、hh和ww分別是特征圖的通道數、高度和寬度,實現錨框定義:
(1)定義錨框:首先需要定義一組錨框(anchor boxes),這些錨框通常是預定義的矩形框,它們的大小和比例是固定的。
(2)生成錨框網格:在特征圖上生成一個與特征圖大小相同的錨框網格。每個位置上的錨框都是基于該位置的中心點生成的。
(3)計算偏移量:對于每個錨框,計算其相對于真實邊界框的偏移量。這包括中心點的偏移量(dx, dy)以及寬高的比例變化(dw, dh)。
(4)分類標簽:為每個錨框分配一個類別標簽,表示它是否包含目標對象。
假設有一個特征圖,其形狀為 1×c×h×w,并且我們定義了k 個錨框,那么輸出的形狀如下: 錨框類別:形狀為 1×(c×k)×h×w。每個位置有 c×k 個值,表示每個位置上的每個錨框的類別。 錨框偏移量:形狀為 1×(4×k)×h×w。每個位置有 4×k 個值,表示每個位置上的每個錨框的偏移量(dx, dy, dw, dh)。
四、實驗小結
在目標檢測中,特征提取是基礎步驟,它決定了后續分類和定位的準確性。邊界框是圍繞檢測到的物體繪制的矩形,由坐標、寬度和高度定義。錨框是預設的一組不同尺寸和寬高比的框,用于在圖像中預測物體的可能位置。評估預測邊界框與真實情況匹配程度的指標是交并比(IoU),它測量了預測和實際邊界框之間的重疊部分。隨著技術的不斷進步,目標檢測將在更多領域發揮其重要作用,為人們的生活帶來更多便利和安全保障。















)



