Mini DeepSeek-v3 訓練腳本詳細技術說明(腳本在文章最后)
📋 概述
這是一個實現了Mini DeepSeek-v3大語言模型的訓練腳本,集成了多項先進的深度學習技術。該腳本支持自動GPU選擇和分布式訓練,適合在多GPU環境下訓練Transformer模型。
🚀 快速開始
運行方式
# 方式1:自動選擇GPU并啟動分布式訓練
python train_mini_deepseek.py# 方式2:手動指定GPU
CUDA_VISIBLE_DEVICES=1,4 torchrun --standalone --nproc_per_node=2 train_mini_deepseek.py
🏗? 架構解析
1. GPU自動選擇機制 (pick_top_gpus)
作用:自動選擇顯存最大的GPU進行訓練
原理:
- 使用NVML庫查詢所有GPU的顯存狀態
- 按空閑顯存大小排序,選擇前N個GPU
- 如果NVML不可用,默認選擇前N個GPU
通俗解釋:就像在停車場找最空的停車位,程序會自動找到顯存最充足的GPU來訓練模型。
2. 模型配置 (CFG類)
class CFG:vocab = 32_000 # 詞匯表大小:模型能理解多少個不同的詞max_seq = 1_024 # 最大序列長度:一次能處理多長的文本d_model = 1_024 # 模型維度:每個詞用多少個數字來表示n_layer = 6 # 層數:模型有多少層神經網絡n_head = 16 # 注意力頭數:同時關注多少個方面latent_k = 64 # 潛在空間維度mlp_mult = 4 # MLP倍數moe_expert = 2 # 專家數量
通俗解釋:這就像定義一個大腦的結構參數 - 能記住多少詞匯、能同時思考多長的句子、大腦有多少層等等。
🧠 核心算法詳解
3. RMSNorm 歸一化
傳統LayerNorm問題:計算復雜,需要計算均值和方差
RMSNorm優勢:
- 只計算RMS (Root Mean Square),更簡單高效
- 公式:
x * rsqrt(mean(x2) + ε) * weight
通俗解釋:想象你在調音響的音量,RMSNorm就是一個自動音量控制器,確保每層神經網絡的"音量"都保持在合適的范圍內,這樣信息傳遞更穩定。
def forward(self, x):var = x.pow(2).mean(-1, keepdim=True) # 計算平方的平均值x = x * torch.rsqrt(var + self.eps) # 歸一化return self.weight * x # 加權輸出
4. RoPE 旋轉位置編碼
問題:Transformer如何知道詞語在句子中的位置?
RoPE解決方案:
- 將位置信息編碼為旋轉角度
- 通過復數旋轉在高維空間中表示位置
- 具有良好的外推性能
通俗解釋:就像給每個詞戴上一個特殊的"位置手環",手環會根據詞的位置旋轉不同的角度,這樣模型就能知道每個詞在句子中的確切位置。
def rope(x, pos):d = x.size(-1); half = d // 2freq = torch.arange(half, device=x.device) / halftheta = pos[:, None] / (10000 ** freq) # 計算旋轉角度cos, sin = theta.cos(), theta.sin()xe, xo = x[..., 0::2], x[..., 1::2] # 分離奇偶維度# 應用旋轉變換return torch.cat([xe * cos - xo * sin, xe * sin + xo * cos], -1)
5. MHLA (Multi-Head Latent Attention)
創新點:引入潛在空間的注意力機制
三個階段:
- Read階段:從輸入序列中讀取信息到潛在空間
- Latent Self階段:在潛在空間內進行自注意力
- Write階段:將潛在空間的信息寫回到輸出序列
通俗解釋:想象你在開會做筆記:
- Read:把別人說的話記錄到你的筆記本上
- Latent Self:在腦海中整理和思考這些信息
- Write:基于思考結果給出你的回應
def forward(self, x, pos):# Read: 從輸入讀取到潛在空間z1 = self._attn(self.qL(z0), self.kX(x), self.vX(x))# Latent Self: 潛在空間內自注意力z2 = self._attn(self.qS(z1), self.kS(z1), self.vS(z1))# Write: 從潛在空間寫回輸出y = self._attn(self.qX2(x), self.kL2(z2), self.vL2(z2))
6. MoE (Mixture of Experts)
核心思想:不是所有神經元都參與每次計算
工作原理:
- Gate網絡:決定激活哪個專家
- 專家網絡:每個專家負責處理特定類型的輸入
- 路由機制:根據輸入特征選擇最合適的專家
通俗解釋:就像一個醫院,不同的病人會被分配給不同專科的醫生。Gate網絡是分診臺,專家網絡是各科醫生,每個"病人"(輸入數據)會被送到最合適的"醫生"(專家)那里處理。
def forward(self, x):route = self.gate(x).softmax(-1) # 計算路由概率idx = route.argmax(-1) # 選擇最佳專家out = torch.zeros_like(x)for i, exp in enumerate(self.experts):m = idx == i # 找到分配給專家i的數據if m.any(): out[m] = exp(x[m]) # 專家處理對應數據return out
7. SwiGLU 激活函數
組合設計:Swish + GLU (Gated Linear Unit)
公式:SwiGLU(x) = Swish(W1(x)) ? W2(x)
優勢:
- 結合了Swish的平滑特性
- 加入了門控機制增強表達能力
通俗解釋:像一個智能開關,不僅能控制信號的強弱(Swish部分),還能決定哪些信號可以通過(門控部分)。
def forward(self, x): return self.w3(torch.nn.functional.silu(self.w1(x)) * self.w2(x))# ↑ Swish激活 ↑ 門控機制 ↑ 輸出變換
🔧 訓練流程詳解
8. 分布式訓練設置
初始化過程:
- 獲取本地GPU編號 (
LOCAL_RANK) - 設置當前設備
- 初始化進程組 (
nccl后端) - 將模型包裝為DDP
通俗解釋:就像組織一個團隊項目,每個GPU就是一個團隊成員,需要先分配任務、建立通信機制,然后協同工作。
9. 學習率調度
Warmup + 線性遞減策略:
def lr(it):if it < CFG.warmup: return CFG.lr * it / CFG.warmup # 預熱階段:逐漸增加return CFG.lr * (1 - it / CFG.total_step) # 訓練階段:線性遞減
通俗解釋:就像開車一樣,剛開始要慢慢加速(warmup),然后在行程接近結束時逐漸減速,這樣能讓模型訓練更穩定。
10. 訓練循環
核心步驟:
- 前向傳播:輸入數據,計算預測結果
- 計算損失:比較預測和真實結果
- 反向傳播:計算梯度
- 梯度裁剪:防止梯度爆炸
- 參數更新:優化模型參數
for x, y in dl:logits = model(x)[:, :-1].reshape(-1, CFG.vocab) # 前向傳播loss = nn.functional.cross_entropy(logits, y[:, 1:].reshape(-1)) # 計算損失loss.backward() # 反向傳播torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) # 梯度裁剪opt.step() # 參數更新
📊 性能優化要點
內存優化
- 梯度檢查點:犧牲計算時間換取內存空間
- 混合精度訓練:使用FP16減少內存占用
- 優化器狀態管理:
set_to_none=True釋放內存
計算優化
- Fused AdamW:融合優化器操作減少kernel啟動
- Pin Memory:加速CPU到GPU的數據傳輸
- 非阻塞傳輸:
non_blocking=True并行化數據傳輸
🎯 實際應用建議
硬件要求
- 最低配置:2張RTX 3090 (24GB顯存)
- 推薦配置:2張RTX 4090 (24GB顯存)
- 內存:至少32GB系統內存
調參建議
- 學習率:根據batch size調整,遵循線性縮放規則
- Warmup步數:通常設為總訓練步數的5-10%
- 批次大小:根據顯存容量調整,保證梯度穩定
常見問題
- OOM (Out of Memory):減少batch_size或max_seq_len
- 訓練不穩定:檢查學習率設置和梯度裁剪閾值
- 收斂緩慢:調整warmup策略和學習率調度
🔍 代碼擴展建議
功能增強
- 添加驗證集評估
- 實現模型檢查點保存/加載
- 集成Wandb等實驗跟蹤工具
- 支持更多數據格式
性能提升
- 實現動態batch size
- 添加梯度累積功能
- 支持更多優化器選擇
- 集成Flash Attention
這個腳本展示了現代大語言模型訓練中的多項前沿技術,是學習和研究Transformer架構的優秀參考實現。
mini_ds.py
# train_mini_deepseek.py ②GPU ?動挑卡版
"""
Mini DeepSeek-v3, auto-pick 2 GPUs with max free memory.Run simply:python train_mini_deepseek.py # auto pick & spawn
or:CUDA_VISIBLE_DEVICES=1,4 torchrun --standalone --nproc_per_node=2 train_mini_deepseek.py
"""import os
import random
import subprocess
import sysimport math
from torch.distributed.elastic.multiprocessing.errors import record# ---------- 0. GPU AUTO-PICK & SELF-SPAWN ----------
def pick_top_gpus(num=2):"""return gpu indices with largest free memory"""try:import pynvml, torchpynvml.nvmlInit()infos = []for i in range(torch.cuda.device_count()):h = pynvml.nvmlDeviceGetHandleByIndex(i)free_mem = pynvml.nvmlDeviceGetMemoryInfo(h).freeinfos.append((free_mem, i))pynvml.nvmlShutdown()infos.sort(reverse=True) # by free memoryreturn [idx for _, idx in infos[:num]]except Exception:# NVML 失效或 CUDA 不可用 → 默認選前 num 個return list(range(num))if "LOCAL_RANK" not in os.environ:gpu_ids = pick_top_gpus(2)print(f'gpu_ids: {gpu_ids}')os.environ["CUDA_VISIBLE_DEVICES"] = ",".join(map(str, gpu_ids))print(f"[AutoPick] Use GPUs: {os.environ['CUDA_VISIBLE_DEVICES']}")# 重新啟動自身為 2 個分布式進程cmd = ["torchrun", "--standalone", f"--nproc_per_node={len(gpu_ids)}", sys.argv[0], *sys.argv[1:]]subprocess.check_call(cmd)sys.exit(0)# ---------- 1. 之后才 import torch 及重型包 ----------
import torch
from torch import nn
from torch.utils.data import DataLoader, Dataset
from torch.nn.parallel import DistributedDataParallel as DDPif not hasattr(nn, "RMSNorm"):class RMSNorm(nn.Module):def __init__(self, d, eps=1e-5):super().__init__()self.weight = nn.Parameter(torch.ones(d))self.eps = epsdef forward(self, x):# x: (B, N, d)var = x.pow(2).mean(-1, keepdim=True)x = x * torch.rsqrt(var + self.eps)return self.weight * xnn.RMSNorm = RMSNorm # 注冊到 torch.nn 里# ---------- 2. 配置 ----------
class CFG:vocab = 32_000;max_seq = 1_024d_model = 1_024;n_layer = 6;n_head = 16latent_k = 64mlp_mult = 4;moe_expert = 2lr = 3e-4;warmup = 100;total_step = 1_000batch = 4;seed = 42torch.manual_seed(CFG.seed);
random.seed(CFG.seed)# ---------- 3. 數據 ----------
class RandomDataset(Dataset):def __len__(self): return 10_000_000def __getitem__(self, idx):x = torch.randint(0, CFG.vocab, (CFG.max_seq,))y = torch.roll(x, -1)return x, y# ---------- 4. RoPE ----------
def rope(x, pos):d = x.size(-1);half = d // 2freq = torch.arange(half, device=x.device) / halftheta = pos[:, None] / (10000 ** freq)cos, sin = theta.cos(), theta.sin()xe, xo = x[..., 0::2], x[..., 1::2]return torch.cat([xe * cos - xo * sin, xe * sin + xo * cos], -1)# ---------- 5. MHLA ----------
class MHLA(nn.Module):def __init__(self):super().__init__()d, h, k = CFG.d_model, CFG.n_head, CFG.latent_kself.h, self.k, self.d = h, k, ddef lin(): return nn.Linear(d, d, bias=False)self.qL, self.kX, self.vX = lin(), lin(), lin()self.qS, self.kS, self.vS = lin(), lin(), lin()self.qX2, self.kL2, self.vL2 = lin(), lin(), lin()self.out = lin()self.latent = nn.Parameter(torch.randn(1, k, d) / math.sqrt(d))self.n1 = nn.RMSNorm(d);self.n2 = nn.RMSNorm(d);self.n3 = nn.RMSNorm(d)def _split(self, x):B, N, _ = x.shapereturn x.view(B, N, self.h, -1).permute(0, 2, 1, 3).reshape(B * self.h, N, -1)def _merge(self, x, B, N): # inversereturn x.view(B, self.h, N, -1).permute(0, 2, 1, 3).reshape(B, N, self.d)def _attn(self, q, k, v):s = (q @ k.transpose(-2, -1)) / math.sqrt(q.size(-1))return (s.softmax(-1) @ v)def forward(self, x, pos):B, N, _ = x.shapez0 = self.latent.expand(B, -1, -1)# readz1 = self._attn(self._split(self.qL(z0)),self._split(self.kX(x)), self._split(self.vX(x)))z1 = self._merge(z1, B, self.k);z1 = self.n1(z0 + self.out(z1))# latent selfz2 = self._attn(self._split(self.qS(z1)),self._split(self.kS(z1)), self._split(self.vS(z1)))z2 = self._merge(z2, B, self.k);z2 = self.n2(z1 + self.out(z2))# writey = self._attn(self._split(self.qX2(x)),self._split(self.kL2(z2)), self._split(self.vL2(z2)))y = self._merge(y, B, N);y = self.n3(x + self.out(y))return y# ---------- 6. MoE FeedForward ----------
class SwiGLU(nn.Module):def __init__(self, d_in, d_hidden):super().__init__()self.w1 = nn.Linear(d_in, d_hidden, False)self.w2 = nn.Linear(d_in, d_hidden, False)self.w3 = nn.Linear(d_hidden, d_in, False)def forward(self, x): return self.w3(torch.nn.functional.silu(self.w1(x)) * self.w2(x))class MoE(nn.Module):def __init__(self):super().__init__()d, h = CFG.d_model, CFG.mlp_mult * CFG.d_modelself.experts = nn.ModuleList([SwiGLU(d, h) for _ in range(CFG.moe_expert)])self.gate = nn.Linear(d, CFG.moe_expert, False)def forward(self, x):route = self.gate(x).softmax(-1)idx = route.argmax(-1)out = torch.zeros_like(x)for i, exp in enumerate(self.experts):m = idx == iif m.any(): out[m] = exp(x[m])return out# ---------- 7. Transformer Block ----------
class Block(nn.Module):def __init__(self, i):super().__init__()self.attn = MHLA() if i % 2 else nn.MultiheadAttention(CFG.d_model, CFG.n_head, batch_first=True)self.norm = nn.RMSNorm(CFG.d_model)self.ffn = MoE()# Pre-compute causal mask for MultiheadAttentionif not isinstance(self.attn, MHLA):self.register_buffer('causal_mask',torch.triu(torch.ones(CFG.max_seq, CFG.max_seq) * float('-inf'), diagonal=1))def forward(self, x, pos):if isinstance(self.attn, nn.MultiheadAttention):q = k = v = rope(x, pos)seq_len = x.size(1)# Use the pre-computed causal mask, truncated to current sequence lengthmask = self.causal_mask[:seq_len, :seq_len]a, _ = self.attn(q, k, v, need_weights=False, attn_mask=mask)else:a = self.attn(rope(x, pos), pos)x = x + ax = x + self.ffn(self.norm(x))return x# ---------- 8. Model ----------
class MiniDeepSeek(nn.Module):def __init__(self):super().__init__()self.embed = nn.Embedding(CFG.vocab, CFG.d_model)self.blocks = nn.ModuleList([Block(i) for i in range(CFG.n_layer)])self.ln_f = nn.RMSNorm(CFG.d_model)self.head = nn.Linear(CFG.d_model, CFG.vocab, False)def forward(self, idx):pos = torch.arange(idx.size(1), device=idx.device)h = self.embed(idx)for blk in self.blocks: h = blk(h, pos)return self.head(self.ln_f(h))# ---------- 9. Train ----------
@record
def main():local_rank = int(os.environ["LOCAL_RANK"])torch.cuda.set_device(local_rank)torch.distributed.init_process_group("nccl")model = MiniDeepSeek().cuda()model = DDP(model, device_ids=[local_rank], find_unused_parameters=True)opt = torch.optim.AdamW(model.parameters(), lr=CFG.lr, fused=True)ds = RandomDataset()sampler = torch.utils.data.DistributedSampler(ds)dl = DataLoader(ds, batch_size=CFG.batch, sampler=sampler,pin_memory=True, num_workers=2)def lr(it):if it < CFG.warmup: return CFG.lr * it / CFG.warmupreturn CFG.lr * (1 - it / CFG.total_step)model.train()step = 0for x, y in dl:step += 1sampler.set_epoch(step)x, y = x.cuda(non_blocking=True), y.cuda(non_blocking=True)logits = model(x)[:, :-1].reshape(-1, CFG.vocab)loss = nn.functional.cross_entropy(logits, y[:, 1:].reshape(-1))loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)for g in opt.param_groups: g["lr"] = lr(step)opt.step()opt.zero_grad(set_to_none=True)if step % 50 == 0 and torch.distributed.get_rank() == 0:print(f"step {step}/{CFG.total_step} loss {loss.item():.4f}")if step >= CFG.total_step: breaktorch.distributed.destroy_process_group()if __name__ == "__main__":main()
# CUDA_VISIBLE_DEVICES=5,7 python -m torch.distributed.run --nproc_per_node=2 mini_ds.py
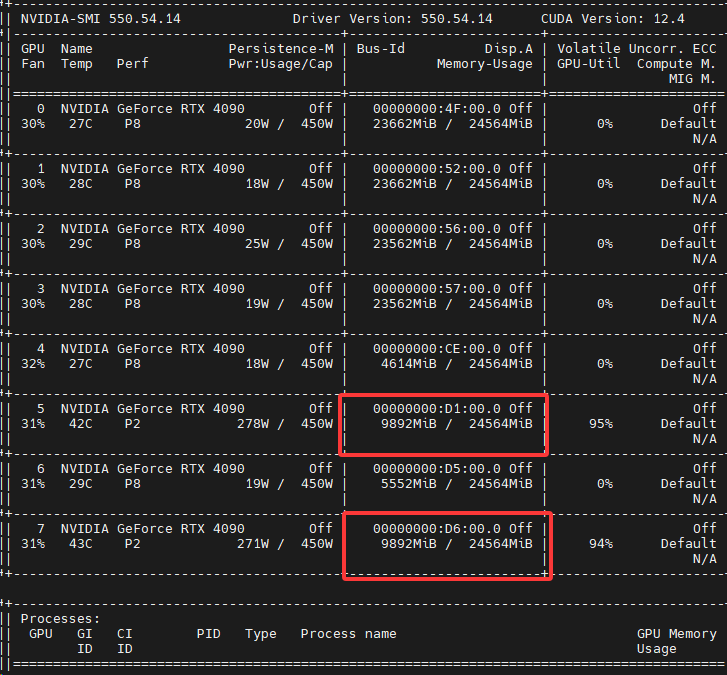
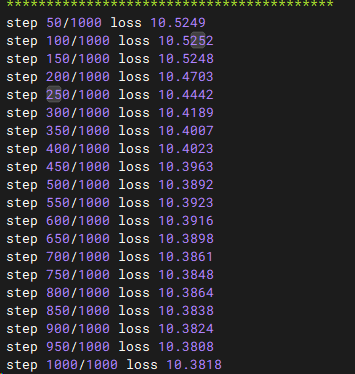
運行結果
執行腳本CUDA_VISIBLE_DEVICES=5,7 python -m torch.distributed.run --nproc_per_node=2 mini_ds.py








:讓AI自主行動 - 初探LangChain4j中的智能體(Agents))










