系列文章目錄
文章目錄
- 系列文章目錄
- 前言
- 一、卷積層的定義
- 1.常見的卷積操作
- 2. 感受野
- 3. 如何理解參數量和計算量
- 4.如何減少計算量和參數量
- 二、神經網絡結構:有些層前面文章說過,不全講
- 1. 池化層(下采樣)
- 2. 上采樣
- 3. 激活層、BN層、FC層
- 1).BatchNorm 層
- 2).FC 全連接層
- 3). dropout 層
- 4). 損失層
- 鳴謝
前言
??在前兩個實戰中,我們只學會了如何搭建神經網絡,但是里面有些函數接口不明白怎么回事,在這篇文章中,我們會逐一解答。
一、卷積層的定義
nn.Conv2d(in_channels,out_channels,kernel_size,stride=1,padding = 0,dilation = 1,groups = 1,bias = True)
- 輸入通道
- 輸出通道
- 卷積核大小
- 移動步長
- 卷積核膨脹
卷積核的大小一般是 3 x 3,卷積的時候,以該元素為中心形成一個 3 x 3的格子,然后與卷積核做內積。不懂的話去小破站學學,很簡單,這里不是重點。輸入通道和輸出通道不用過多解釋,卷積核的數量。padding = 1 我們有時候發現靠邊的元素卷積不夠,需要進行拓展,這句話就是添加一行和一列,完成邊緣元素的卷積。dilation = 1,這個是為了增加卷積核的視野感受范圍,3 x 3 的卷積核變成 7 x 7 的卷積核,在分割網絡中常用。卷積一個元素之后,stride = 1 移動的步長,如果等于 2 就有些元素沒有中心卷積。groups = 1 分組卷積,一個卷積核為一組,可以降低計算量,主要在深度可分離卷積中。bias=True 偏執量,輸出的結果經過 y = wx+b wx 可以理解卷積,b就是我們家的偏置量。
1.常見的卷積操作
- 分組卷積
- 空洞卷積
- 深度可分離卷積( 分組卷積 + 1 x 1 卷積)
- 反卷積
- 可變型卷積,卷積核不是固定的。
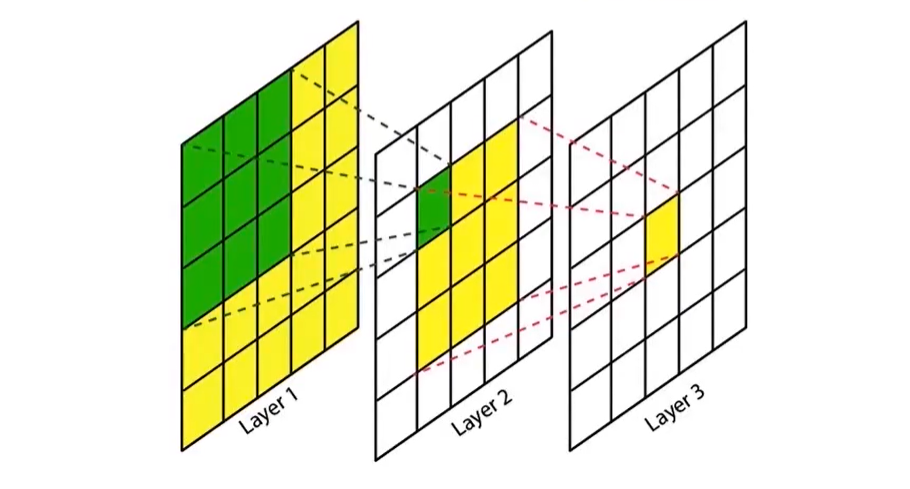
2. 感受野
??指的是神經網絡中卷積核看到的區域,在神經網絡中,feature_map 某個元素的計算受到輸入圖像上某個區域的影響,這個區域就是該元素的感受野。
3. 如何理解參數量和計算量
- 參數量:參與計算參數的個數,占用內存空間:對于一個卷積核而言參數量: ( C i n ? ( K ? K ) + 1 ) ? C o u t (Cin*(K*K)+1)*Cout (Cin?(K?K)+1)?Cout
- FLOPS:每秒浮點運算次數,可以理解是速度,用來衡量硬件的性能。
- FLOPs:s小寫,這個就是計算量,衡量算法模型的復雜度:
( C i n ? 2 ? K ? K ) ? H o u t ? W o u t ? C o u t (Cin * 2 * K* K ) * Hout * Wout * Cout (Cin?2?K?K)?Hout?Wout?Cout- MAC:乘加的次數
C i n ? K ? K ? H o u t ? W o u t ? C o u t Cin * K* K * Hout * Wout * Cout Cin?K?K?Hout?Wout?Cout
??FLOPs 把乘加分開算,所以乘以2,MAC 算一次,所以是 1。
4.如何減少計算量和參數量
?? 減少計算量很參數量還是要在卷積層動腦子,在不改變感受野和減少參數量的角度壓縮矩陣:
- 采用多個 3 x 3 的卷積核代替大的卷積核。
- 采用深度可分離卷積核,即分組卷積
- 通道 Shuffle
- Pooling 層:快速下采樣,可能有信息的損失。一般在前兩個卷積核使用。
- Stride = 2:卷積的步長加大
等等
二、神經網絡結構:有些層前面文章說過,不全講
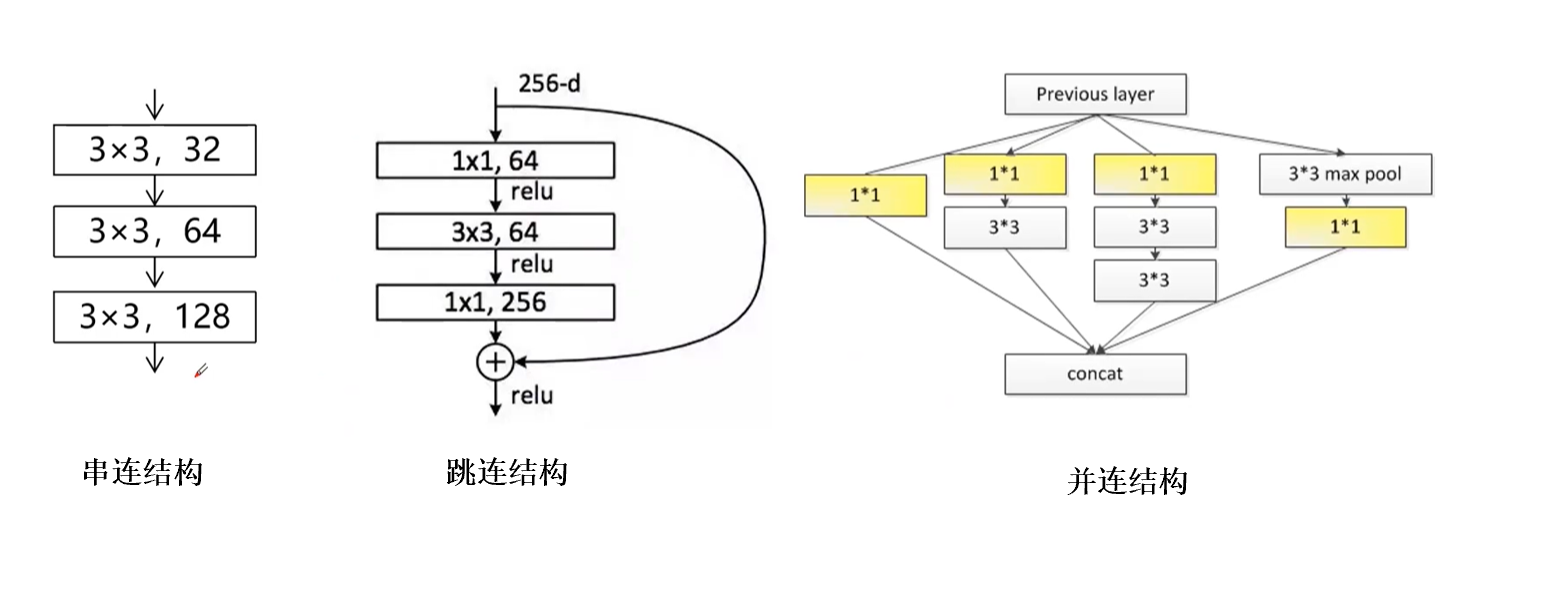
??神經網絡基本可以分成這三種金典的結構,如圖 2 所示。串聯結構、跳連結構、并連結構。跳連結構是把部分輸出直接作為輸出,這樣可以大幅度減少計算量。
1. 池化層(下采樣)
??池化層對輸入特征的壓縮:
- 一方面使特征圖變小,簡化網絡計算復雜度。
- 一方面進行特征壓縮,提取主要特征。
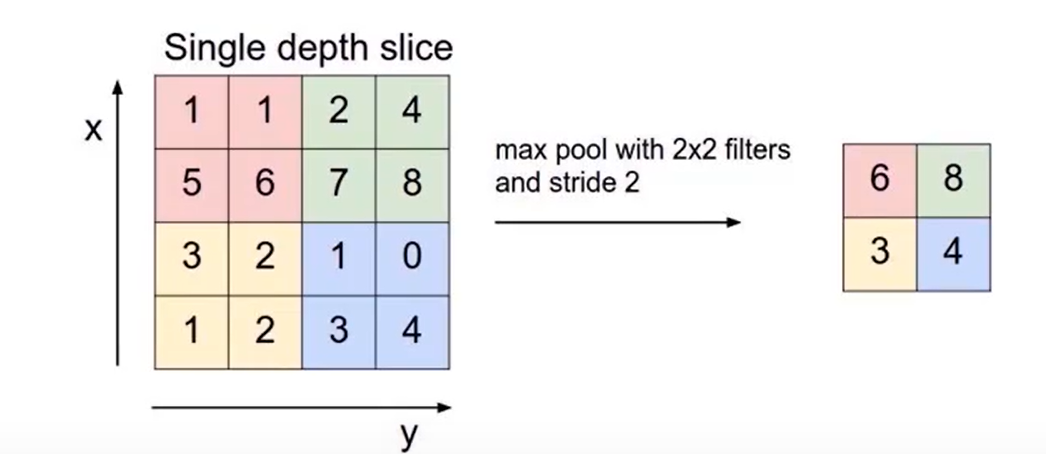
池化層常用兩種方法:最大池化(Max Pooling)和平均池化(Average Poling),
nn.MaxPool2d(kernel_size = ,Stride = ,pading =0 ,dilation = 1,return_indeces = False,ceil_mode = False)
前四個參數就不說了,上面有。這個 return_indeces,返回的是最大值的索引,這樣當我們恢復原圖的時候有很大作用,相似度更近。下面是一張最大池化的圖:
2. 上采樣
??上采樣有兩種方式:
- Resize,如雙線性插值直接放縮,類似于圖像放縮。
- 反卷積:Deconvolution,即 Transposed Convolution
代碼摘要:
nn.functional.interpolate(input,size = None,scalar_factor = None,model = 'nearest',align_corners = None)nn.ConvTranspose2d(in_channels,out_channels,kernel_size, stride = 1,padding = 0,bias = True)
通常我們采用Resize進行重構,計算量小,反卷積的計算量很大。
3. 激活層、BN層、FC層
??在卷積層,其實就是一個線性操作y = wx +b w 和 b 就是卷積核的參數,線性函數并不能很好去擬合數據樣本,所以我們提出激活函數來解決這一問題,旨在提高網絡的非線性表達。
- 激活函數:為了增加網絡的非線性,進而增加網絡的表達能力。
- 常用函數:ReLU函數、Leakly ReLU函數、ELU 函數等
- 語句:
torch.nn.ReLU(inplace = True)
1).BatchNorm 層
- 通過一定的規范化手段,把每層神經網絡任意神經元的輸入值分布強行拉倒j標準正態分布上面,均值 0 ,方差 1.
- BatchNorm 是一種歸一化的手段,他會減少圖像之間的絕對差異,突出相對差異,加快模型的訓練速度。
- 不適合 image to image 和對噪聲敏感的任務中
- 語句:
nn.BatchNorm2d(num_features,eps = 1e-05,momentum =0.1,affine = True,track_runing_stats = True )
BatchNorm 層可以理解為工具層,我們在卷積層也可以加入,后面在更一個ReLU層,往往就是這么干的。
2).FC 全連接層
??連接所有的特征,把輸出值送給分類器(softmax層)。
- 對前層的特征進行一個加權和,(卷積層是將輸入數據映射到隱層特征空間) ,將特征空間通過線性變化映射到樣本標記空間。
- 也可以通過 1 x 1 卷積 + gloable average pooling 代替。
- 全連接層的參數冗余,一般情況需要 Dropout 限制參數。
- FC 層對圖片的大小尺寸非常敏感。
- 語句:
nn.Linear(in_features,out_features,bias)
3). dropout 層
- 在不同的訓練中隨機扔掉一些神經元。
- 在測試中不實用隨機失活,那么所有的神經元都激活。
- 作用:為了防止和減輕過擬合才使用的函數,一般用在全鏈接層。
- 語句:
nn.dropout
4). 損失層
??在網絡優化,反向傳播時非常重要的一個層,損失函數選擇取決于我們要訓練的任務。
- 損失層:設置一個損失函數用來比較輸出值和目標值,通過最小損失來驅動網絡的訓練。
- 網絡的損失通過前向操作計算,網絡的參數相較于損失函數,通過后向操作計算。
- 分類問題損失:
- nn.BCELoss
- nn.CrossEntrophyLoss 等等
- 回歸問題損失:
- nn.L1Loss
- nn.MSELoss
- nn.SmoothL1Loss 等等
鳴謝
??年齡越大,越不想欠誰。一生活得灑脫,一個人,幾個人也快樂。如果本文對大家有幫助,還請大家瀏覽一下我弟新開的小店,要黃了,哈哈哈。點擊這里。











)







