本文深入剖析 TensorFlow Serving 的核心架構與實現機制,結合源碼分析揭示其如何實現高可用、動態更新的生產級模型服務。
一、TensorFlow Serving 核心架構
1.1 分層架構設計
TensorFlow Serving 采用模塊化分層設計,各組件職責分明:
| 組件 | 職責 | 源碼位置 |
|---|---|---|
| Servables | 可服務對象(如模型),基礎服務單元 | core/servable.h |
| Loaders | 管理模型加載/卸載生命周期 | core/loader.h |
| Managers | 管理 Servable 集合,路由請求到正確版本 | core/manager.h |
| Sources | 提供 Loader,通知 Manager 新版本可用 | core/source.h |
| ServerCore | 中樞系統,協調各組件工作 | model_servers/server_core.h |
1.2 請求處理全流程
二、核心機制深度解析
2.1 動態模型加載機制
核心流程:
LoaderHarness 狀態機:
enum class State {kNew, // 新建狀態kLoading, // 加載中kReady, // 就緒狀態kQuiescing, // 靜默中kUnloading, // 卸載中kError // 錯誤狀態
};
關鍵設計:
- 線程安全狀態轉換:
Status LoaderHarness::Load() {mutex_lock l(mu_); // 狀態鎖TransitionState(State::kLoading);// ...執行加載
}
- 自動資源回收:
LoaderHarness::~LoaderHarness() {if (state_ == State::kReady) Unload();
}
2.2 ServerCore 啟動流程
BuildAndStart() 函數核心邏輯:
Status Server::BuildAndStart(const Options& opts) {// 1. 配置驗證if (opts.grpc_port == 0) return errors::InvalidArgument("端口未設置");// 2. 構建ServerCore配置ServerCore::Options options;// 3. 模型配置加載if (opts.model_config_file.empty()) {options.model_server_config = BuildSingleModelConfig(...);} else {TF_RETURN_IF_ERROR(ParseProtoTextFile(...));}// 4. 資源配置session_bundle_config.mutable_session_config()->mutable_gpu_options()->set_per_process_gpu_memory_fraction(0.8); // GPU內存限制// 5. 創建ServerCore核心TF_RETURN_IF_ERROR(ServerCore::Create(std::move(options), &server_core_));// 6. 啟動gRPC服務::grpc::ServerBuilder builder;builder.AddListeningPort(..., BuildServerCredentials(...));grpc_server_ = builder.BuildAndStart();// 7. 啟動HTTP服務if (opts.http_port != 0) {http_server_ = CreateAndStartHttpServer(...);}return Status::OK();
}
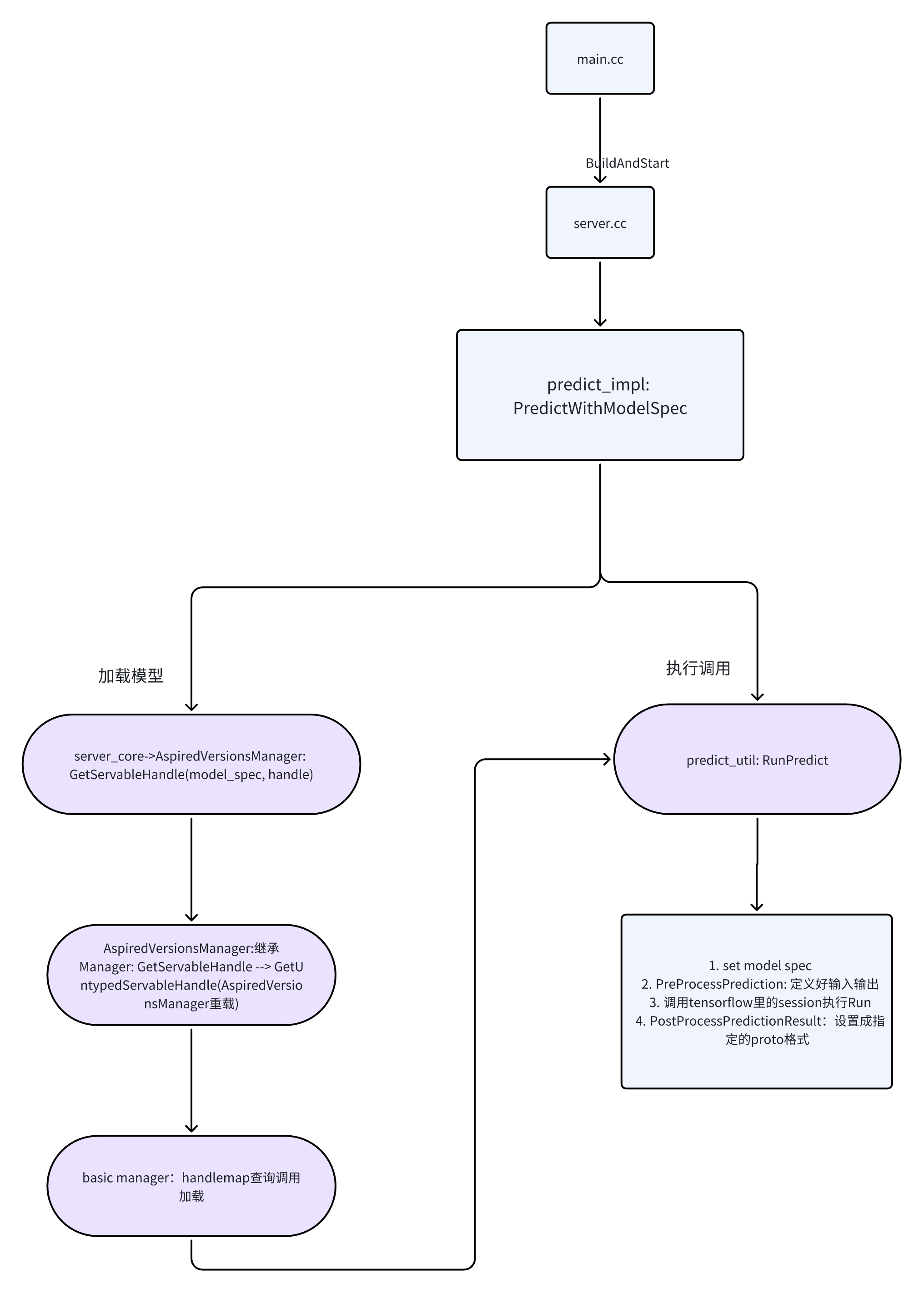
三、關鍵設計亮點
3.1 動態更新機制
實現代碼:
fs_config_polling_thread_.reset(new PeriodicFunction([this, config_file] {this->PollFilesystemAndReloadConfig(config_file);},poll_interval * 1000000 // 微秒單位
));
3.2 資源隔離設計
GPU內存隔離:
// 限制單模型GPU內存使用
session_bundle_config.mutable_session_config()->mutable_gpu_options()->set_per_process_gpu_memory_fraction(0.6);
并行計算優化:
// 智能并行配置
if (intra_op > 0 || inter_op > 0) {// 分別設置算子內/間并行度session_config->set_intra_op_parallelism_threads(intra_op);session_config->set_inter_op_parallelism_threads(inter_op);
} else {// 統一并行設置session_config->set_intra_op_parallelism_threads(session_parallel);session_config->set_inter_op_parallelism_threads(session_parallel);
}
四、生產級特性實現
4.1 服務高可用設計
| 機制 | 實現方式 | 效果 |
|---|---|---|
| 模型預熱 | enable_model_warmup 參數 | 避免冷啟動延遲 |
| 失敗重試 | max_num_load_retries 配置 | 提升模型加載成功率 |
| 版本回滾 | AvailabilityPreservingPolicy 策略 | 自動回退問題版本 |
4.2 安全通信保障
SSL/TLS 加密配置:
::grpc::SslServerCredentialsOptions ssl_ops(GRPC_SSL_REQUEST_AND_REQUIRE_CLIENT_CERTIFICATE_AND_VERIFY);
ssl_ops.pem_root_certs = custom_ca; // 自定義CA
五、核心參數大全
| 參數名 | 類型 | 默認值 | 作用 |
|---|---|---|---|
grpc_port | int | 無 | gRPC服務端口(必須設置) |
model_base_path | string | 空 | 單模型基路徑 |
per_process_gpu_memory_fraction | float | 1.0 | GPU內存分配比例 |
tensorflow_intra_op_parallelism | int | 0 | 算子內并行線程數 |
fs_model_config_poll_wait_seconds | int | 0 | 配置輪詢間隔(秒) |
enable_model_warmup | bool | false | 啟用模型預熱減少延遲 |
Reference
TensorFlow 入門實操 源代碼 tensorflow serving源碼分析_mob6454cc6bf0b7的技術博客_51CTO博客
TensorFlow Serving源碼解讀_tensorflow serving 代碼解析-CSDN博客
tensorflow-serving源碼閱讀1_tensorflow源碼閱讀-CSDN博客
tensorflow serving 源碼 tensorflow源碼閱讀_柳隨風的技術博客_51CTO博客
https://zhuanlan.zhihu.com/p/700830357



)



:序列數據處理的強大工具)
)

)
)
 ---- LinkedList 類)






![[VSCode] VSCode 設置 python 的編譯器](http://pic.xiahunao.cn/[VSCode] VSCode 設置 python 的編譯器)