25年4月來自新加坡技術和設計大學的論文“NORA: a Small Open-Sourced Generalist Vision Language Action Model for Embodied Tasks”。
現有的視覺-語言-動作 (VLA) 模型在零樣本場景中展現出優異的性能,展現出令人印象深刻的任務執行和推理能力。然而,視覺編碼的局限性也帶來巨大的挑戰,這可能導致諸如物體抓取等任務的執行失敗。此外,這些模型通常由于規模龐大(通常超過 70 億個參數)而導致計算開銷高昂。雖然這些模型在推理和任務規劃方面表現出色,但它們產生的大量計算開銷使其不適用于實時機器人環境,因為在實時機器人環境中速度和效率至關重要。鑒于針對特定任務對 VLA 模型進行微調的常見做法,顯然需要一個更小、更高效的模型,該模型可以在消費級 GPU 上進行微調。為了解決現有 VLA 模型的局限性, NORA,一個 30 億個參數的模型,旨在降低計算開銷的同時保持強大的任務性能。 NORA 采用 Qwen-2.5-VL-3B 多模態模型作為主干模型,利用其卓越的視覺語義理解能力來增強視覺推理和動作推理能力。此外,NORA 基于 97 萬個真實機器人演示進行訓練,并配備 FAST+ token 化器,可高效生成動作序列。實驗結果表明,NORA 的表現優于現有的大規模 VLA 模型,在顯著降低計算開銷的同時實現了更優的任務性能,使其成為實時機器人自主控制的更實用的解決方案。
VLM
視覺語言模型 (VLM) 已成為強大的圖像理解和推理框架,展現出基于視覺輸入生成文本以及識別圖像中物體的能力。這使其成為 VLA 的絕佳主干模型。基于預訓練 VLM 進行微調的 VLA 顯著受益于這些模型所經歷的互聯網規模的圖像和文本預訓練。這種預訓練賦予 VLA 對視覺語義的豐富理解,使 VLA 能夠將語言扎根于視覺世界中,并將這種理解轉化為有意義的機器人動作。這種扎根有助于泛化到分布外的指令和環境中。例如,VLA 可以從先前的視覺語言經驗中進行泛化,從而在之前未見過的場景中解釋和執行“拿起玩具”之類的指令,即使在訓練過程中沒有遇到過完全相同的短語或上下文。
最近的視覺-語言模型 (VLM) 包含一個圖像編碼器 (Oquab,2023)、一個大語言模型 (LLM) 主干 (Touvron,2023) 和一個將視覺表征映射到共享嵌入空間的投影網絡。這種架構使 LLM 能夠有效地推理文本和圖像模態。VLM 的預訓練通常利用各種多模態數據集,包括交錯的圖像-文本對、視覺知識源、目標基礎、空間推理和多模態問答數據集。
本文工作基于 Qwen2.5-VL 模型 (Bai,2025),這是一個最先進的開源 VLM。Qwen2.5-VL 的一個顯著特點是它在訓練期間使用原始圖像分辨率,旨在增強模型對真實世界尺度和空間關系的感知。這種方法能夠更準確地理解物體的大小和位置,從而提升物體檢測和定位等任務的性能。可以利用 Qwen 2.5-VL 的落地和空間能力來構建 VLA,這將有利于機器人控制。
VLA
盡管 VLM 具有諸多優勢,但它們的內在設計并非旨在直接生成適用于機器人技術中特定體現配置的策略。這一局限性促使視覺-語言-動作 (VLA) 模型的出現,該模型通過利用多模態輸入(結合視覺觀察和語言指令)來彌補這一差距,從而在多樣化的多任務場景中生成自適應且廣義的機器人動作。根據動作建模方法,VLA 模型大致可分為兩類:連續動作模型(Octo Model Team,2024),通常采用擴散過程在連續動作空間中生成平滑軌跡;以及離散 token 模型(Brohan,2023b;c;Kim,2024;Sun,2024),其中機器人動作表示為離散 token 序列。在基于離散 token 的 VLA 模仿學習公式中,機器人在給定時間 t 的狀態由多模態觀察表征,包括視覺圖像 I_t、文本指令 L_t 和先前狀態上下文 S_t。目標是預測一系列離散標記 A_t,表示機器人可執行的動作。正式地說,該模仿學習策略模型 π_θ(A_t |I_t,L_t,S_t) 經過訓練,可以復制專家提供的動作序列,使機器人能夠將學習的行為泛化到由視覺語言提示引導的新場景中。
動作 token 化
在機器人系統中,動作通常表示為跨多個自由度 (DoF) 的連續控制信號,例如 (x, y, z) 方向的平移以及滾轉、俯仰和偏航方向的旋轉。為了兼容基于 Transformer 的語言主干,通常使用分箱方法將這些連續動作離散化 (Brohan et al., 2023c; b)。此過程使用基于分位數的策略將機器人動作的每個維度映射到 256 個離散箱中的一個,從而確保對異常值的魯棒性,同時保持足夠的粒度。OpenVLA (Kim et al., 2024) 通過覆蓋 LLaMA token 化器中 256 個最少使用的 tokens,將這些動作 tokens 合并到語言模型的詞匯表中,從而實現對動作序列的下一個 token 預測。為了進一步提高預訓練效率,采用了一種快速 token 化方法 (Pertsch et al., 2025),該方法在每個時間步對動作維度應用離散余弦變換 (DCT)。這種方法可以去除聯合動作分量的相關性,并支持使用字節對編碼 (BPE) 將它們壓縮為更短、更高效的 token 序列。由此產生的表征減少詞匯量并加快收斂速度,同時使動作數據的結構與語言模型友好的 token 統計數據保持一致。在推理過程中,NORA 占用約 8.3GB 的 GPU 內存。
為機器人自主的神經編排器 (NORA),這是一個基于 Open X-Embodiment 數據集 (Collaboration et al., 2023) 訓練的 3B 參數視覺-語言-動作 (VLA) 模型。NORA 建立在現有的視覺-語言模型 (VLM) 之上,充分利用其強大的通用世界知識、多模態推理、表征學習和指令遵循能力。特別地,采用開源多模態模型 Qwen-2.5-VL-3B (Bai et al., 2025) 作為 NORA 的 VLM 主干,因為它在同等規模下實現性能與效率之間的完美平衡。另一方面,利用 FAST+ token 化器(Pertsch,2025)來離散化連續動作 tokens,因為它在包括單臂、雙手和移動機器人任務在內的各種動作序列中已被證明有效,使其成為訓練自回歸 VLA 模型的強大現成選擇。
架構
模型 NORA,如圖所示,利用預訓練的視覺語言模型 (VLM)(記為 M)自回歸地預測一個動作塊,該動作塊編碼了從時間 t 到 t + N 的未來動作,記為 a_t:t+N = [a_t,…,a_t+N]。M 的輸入包括自然語言任務指令 c 和時間 t 的 n 幀視覺觀察 o_t = [I_t1,…,I_tn],它們連接起來形成整體輸入 X_t = [o_t, c]。動作塊 a_t:t+N 由一系列離散tokens R = [r_t,…,r_t+N] 表示,并在訓練時使用 FAST+ 機器人 token 化器進行編碼。 VLM M 通過自回歸生成以 X_t 為條件的 token 序列 R 來預測此動作塊。
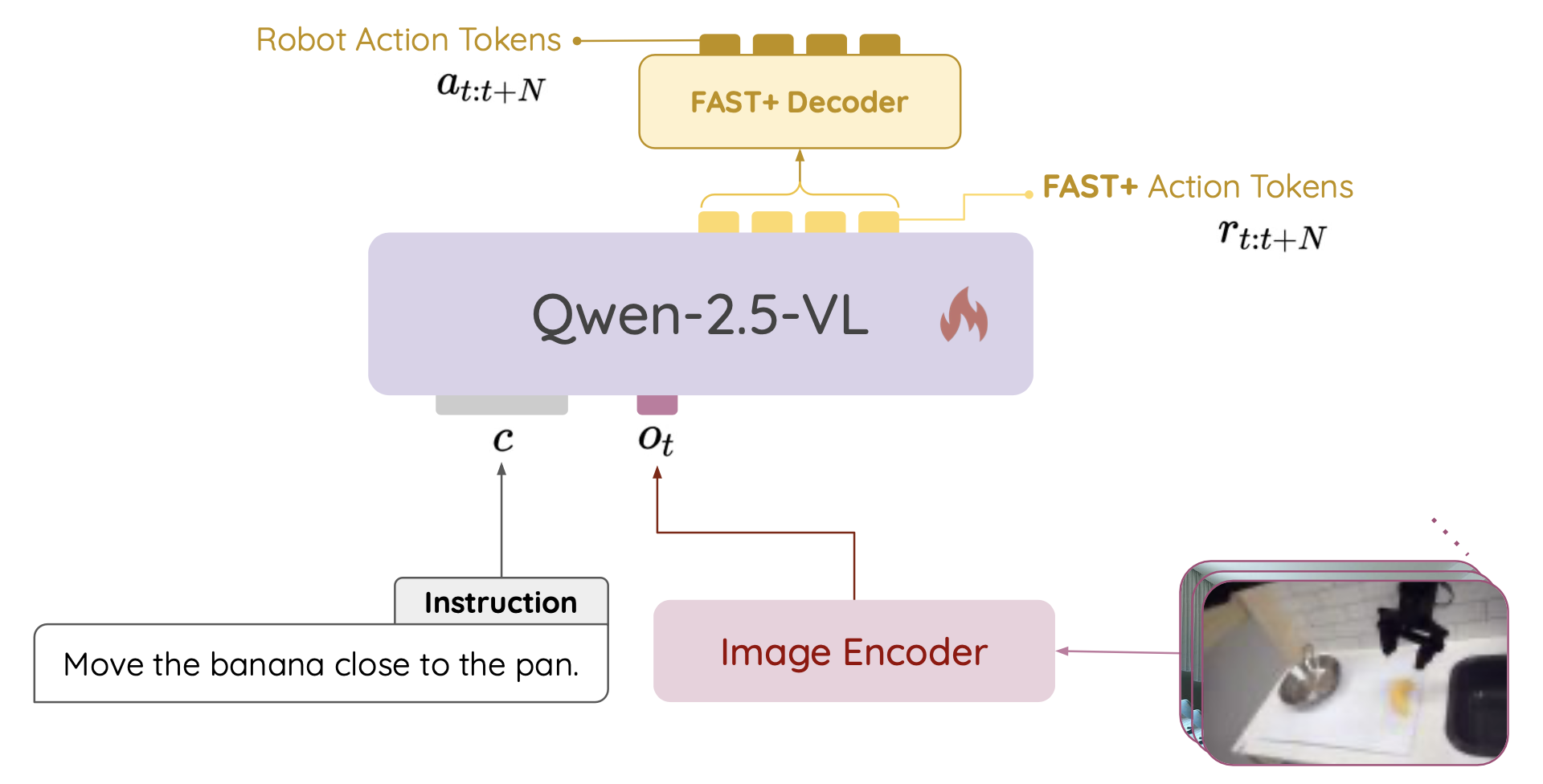
選擇最先進的開源 VLM Qwen-2.5-VL (Bai et al., 2025) 作為主干模型,因為它的參數規模較小,只有 3B。此外,通過 FAST+ token 化器引入的 2048 個 tokens,擴充 VLM token 化器的詞匯量。將觀察結果限制在單個視覺幀內。動作塊大小設為 1。隨后,用標準語言建模目標函數(即下一個 token 預測損失函數)訓練 NORA。
預訓練
預訓練階段的目標是在自然語言指令的驅動下,賦予 NORA 廣泛的機器人能力,并在各種任務、設置、模態和具體化方面實現強大的泛化能力。為此,在 Open X-Embodiment (Collaboration et al., 2023) (OXE) 數據集上訓練 NORA,該數據集包含執行各種任務的不同機器人的軌跡,包括 BridgeV2 (Walke et al., 2023)、DROID (Khazatsky et al., 2024) 等子集。與 OpenVLA (Kim et al., 2024) 類似,將所有幀的大小調整為 224 x 224 像素以進行訓練。
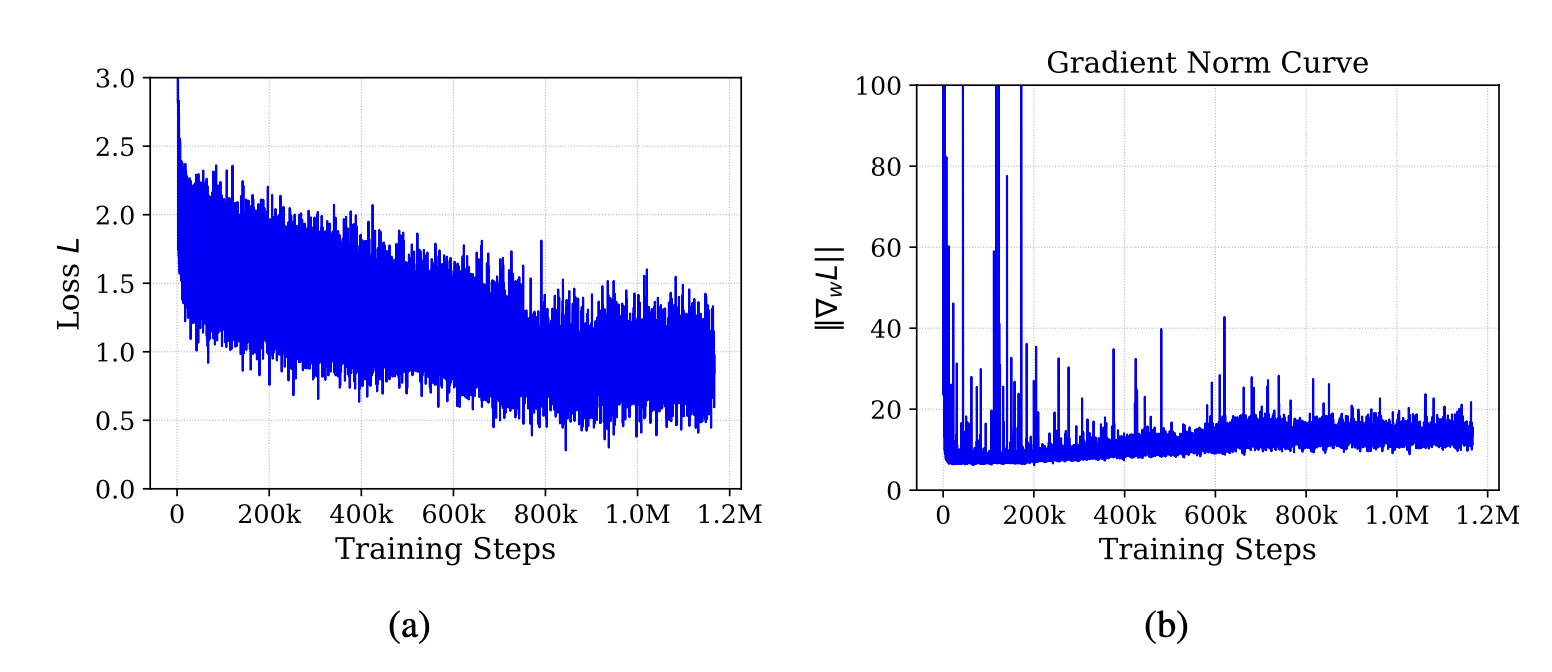
在 8xH100 GPU 的單節點上對 NORA 進行了大約三周的訓練,總計約 4000 個 H100 GPU 小時。用 256 的批次大小,并使用 AdamW (Loshchilov & Hutter, 2017) 優化器執行了 110 萬次梯度更新。在前 5 萬步中,進行線性預熱,使峰值學習率達到 5 × 10?5,然后以余弦衰減至零。為了提高訓練效率并減少內存占用,用 FlashAttention 并以 bf16 精度進行訓練。在下圖 a 和 b 中報告訓練損失和梯度范數曲線。訓練過程中的損失曲線總體穩定,呈下降趨勢,沒有出現明顯的峰值。雖然梯度范數曲線在整個訓練過程中偶爾出現峰值,但這似乎并未擾亂損失的整體平穩增長。
NORA-LONG
一些研究表明,動作分塊(即預測較長的動作范圍而無需頻繁重規劃)可帶來卓越的性能。(Zhao et al., 2023; Chi et al., 2024)。受這些發現的啟發,訓練 NORA 的一個變體,稱為 NORA-LONG,其動作塊大小為 5。NORA-LONG 與 NORA 的架構完全相同,但預測給定狀態下的動作范圍為 5 個動作。在與 NORA 相同的預訓練數據集上對 NORA-LONG 進行 90 萬步的預訓練。
為了評估 NORA 在不同環境和機器人實現中的魯棒性,用 (i) Walke (2023) 開發的真實 WidowX 機器人平臺和 (ii) LIBERO (Liu,2023) 模擬基準,該基準包含 30 個程序生成的解纏結任務,這些任務需要深入理解不同的空間布局 (LIBERO-Spatial)、物體 (LIBERO-Object) 和任務目標 (LIBERO-Goal),以及 10 個長范圍糾纏任務 (LIBERO-Long);該基準測試還附帶一個訓練數據集。在這兩種情況下,策略模型都以第三人稱攝像機畫面和自然語言指令為輸入,預測末端執行器的速度動作,從而在 500 次試驗中控制機器人。在相應的數據集上對 NORA 進行了 150 次微調,批次大小為 128,學習率為 5 × 10?5。
為了確定策略模型的泛化能力,開發一套具有挑戰性的評估任務,涉及域外 (OOD) 目標、空間關系和多個拾取和放置任務,如圖所示。所有策略均在相同的真實世界設置下進行評估,確保攝像機角度、光照條件和背景一致。每項任務進行 10 次試驗,遵循 Kim (2024) 的方法。

如果機器人成功完成提示指定的任務,則計為成功 (succ),得分為 1;否則,得分為 0:
為了與 NORA 進行比較評估,將其性能與以下基準方法進行比較。
OpenVLA (Kim,2024):VLA 模型基于 Llama 2 語言模型 (Touvron,2023) 構建,并結合視覺編碼器,該編碼器集成來自 DINOv2 (Oquab,2023) 和 SigLIP (Zhai,2023) 的預訓練特征。該模型在 Open-X-Embodiment 數據集 (Collaboration,2023) 上進行預訓練,該數據集包含 97 萬個真實世界機器人演示。
SpatialVLA (Qu,2025):VLA 模型專注于機器人操控的空間理解,并融合空間運動等 3D 信息。它學習一種適用于各種機器人和任務的空間操控通用策略。 SpatialVLA 一次可預測四個動作。
TraceVLA(Zheng,2024):一個通過視覺軌跡提示增強時空推理的 VLA 模型。該模型基于機器人操作軌跡對 OpenVLA 進行微調,將狀態-動作歷史編碼為視覺提示,從而提升交互任務中的操作性能。
RT-1(Brohan,2023c):一個可擴展的 Robotics Transformer 模型,旨在從大型任務無關數據集中遷移知識。RT-1 基于多種機器人數據進行訓練,在各種機器人任務中實現高水平的泛化和任務特定性能,展現開放式任務無關高容量模型訓練的價值。














)

)


