文章目錄
- Pre
- 引言:為何提前暴露指標與分析的重要性
- 指標暴露與監控接入
- Prometheus 集成
- 性能剖析工具:火焰圖與 async-profiler
- async-profiler 下載與使用
- 結合 Flame 圖優化示例
- HTTP 及 Web 層優化
- CDN 與靜態資源加速
- Cache-Control/Expires 在 Nginx 中配置示例
- 減少域名數量
- Gzip 及資源壓縮配置
- Keep-Alive 配置
- SpringBoot 容器調優
- 自定義嵌入式 Tomcat
- 替換 Undertow
- JVM 參數回顧
- 應用性能監控與分布式追蹤
- SkyWalking 集成
- 各層優化思路
- Controller 層
- Service 層
- 傳統事務 vs 柔性事務
- DAO 層
- 緩存優化
- 資源與線程管理
- 端到端測試與壓測
- 小結

Pre
性能優化 - 理論篇:常見指標及切入點
性能優化 - 理論篇:性能優化的七類技術手段
性能優化 - 理論篇:CPU、內存、I/O診斷手段
性能優化 - 工具篇:常用的性能測試工具
性能優化 - 工具篇:基準測試 JMH
性能優化 - 案例篇:緩沖區
性能優化 - 案例篇:緩存
性能優化 - 案例篇:數據一致性
性能優化 - 案例篇:池化對象_Commons Pool 2.0通用對象池框架
性能優化 - 案例篇:大對象的優化
性能優化 - 案例篇:使用設計模式優化性能
性能優化 - 案例篇:并行計算
性能優化 - 案例篇:多線程鎖的優化
性能優化 - 案例篇:CAS、樂觀鎖、分布式鎖和無鎖
性能優化 - 案例篇: 詳解 BIO NIO AIO
性能優化 - 案例篇: 19 條常見的 Java 代碼優化法則
性能優化 - 案例篇:JVM垃圾回收器
性能優化 - 案例篇:JIT
性能優化 - 案例篇:11種優化接口性能的通用方案
性能優化 - 高級進階:JVM 常見優化參數
引言:為何提前暴露指標與分析的重要性
在正式進行性能優化之前,必須先“看得到”系統運行狀況:緩存命中率、數據庫連接池使用情況、響應時長分布、CPU/內存消耗、垃圾回收停頓等。只有掌握真實數據,才能有針對性地優化;盲目調整往往事倍功半,甚至適得其反。
指標暴露與監控接入
Prometheus 集成
-
Maven 依賴
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId> </dependency> <dependency><groupId>io.micrometer</groupId><artifactId>micrometer-core</artifactId> </dependency> <dependency><groupId>io.micrometer</groupId><artifactId>micrometer-registry-prometheus</artifactId> </dependency> -
application.properties / application.yml 配置
management.endpoint.metrics.enabled=true management.endpoint.prometheus.enabled=true management.endpoints.web.exposure.include=health,info,prometheus,metrics management.metrics.export.prometheus.enabled=true management.endpoint.health.show-details=always # 可根據需要開放其他端點,如 httptrace、threaddump -
啟動與訪問
-
啟動后,訪問
http://<host>:<port>/actuator/prometheus可看到所有默認與自定義指標。 -
配置 Prometheus server 抓取該 endpoint,例如在 prometheus.yml:
scrape_configs:- job_name: 'springboot-app'metrics_path: '/actuator/prometheus'static_configs:- targets: ['app-host:port']
-
-
自定義業務指標示例
@RestController public class TestController {private final MeterRegistry registry;public TestController(MeterRegistry registry) {this.registry = registry;}@GetMapping("/test")public String test() {registry.counter("app_test_invocations", "from", "127.0.0.1", "method", "test").increment();return "ok";} }- 在 Prometheus 中可見指標如
app_test_invocations_total{from="127.0.0.1",method="test"} 5.0
- 在 Prometheus 中可見指標如
-
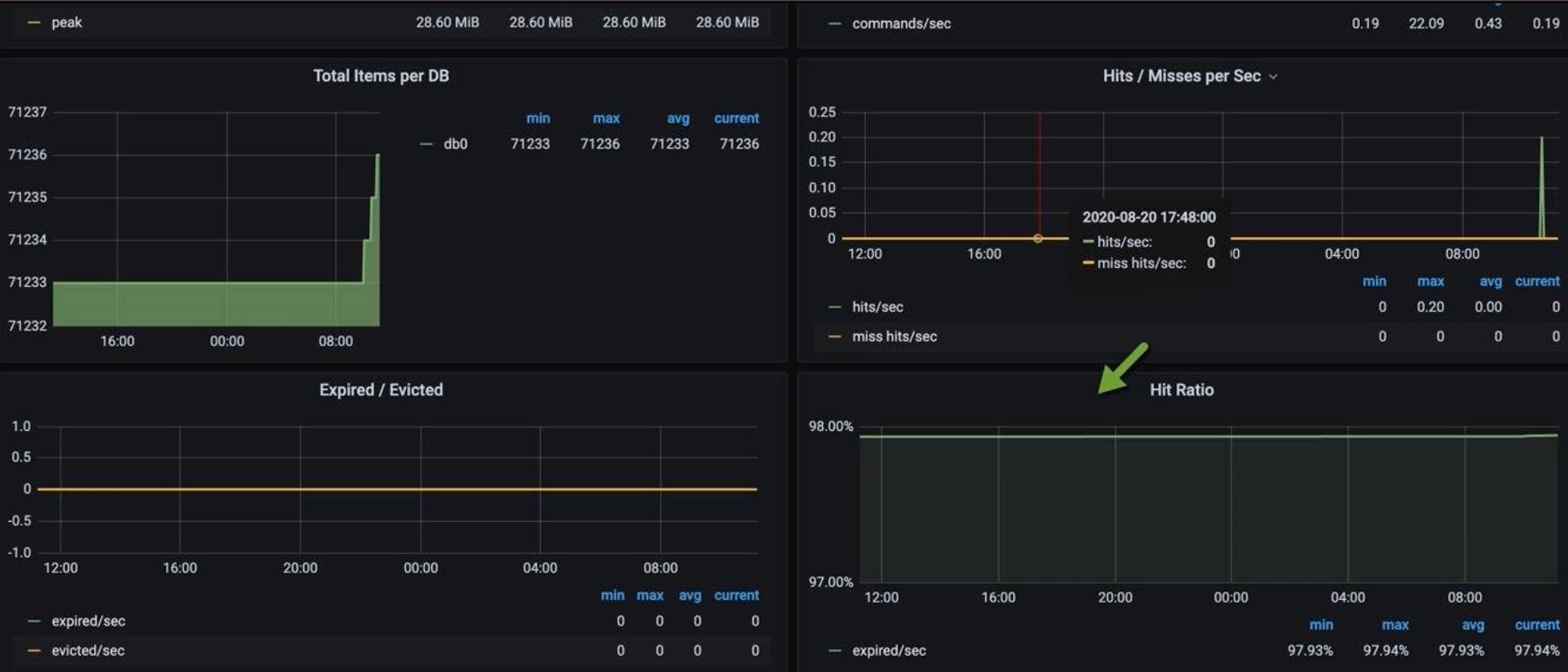
對于緩存命中率,可在緩存攔截或 CacheManager 事件中注冊 Counter/Gauge,例如:
Cache<Object, Object> cache = ...; // 若使用 Caffeine,可 attach 監聽 // 當命中時 registry.counter("cache_hit", "cache", "myCache").increment(); // 當未命中時 registry.counter("cache_miss", "cache", "myCache").increment();
-
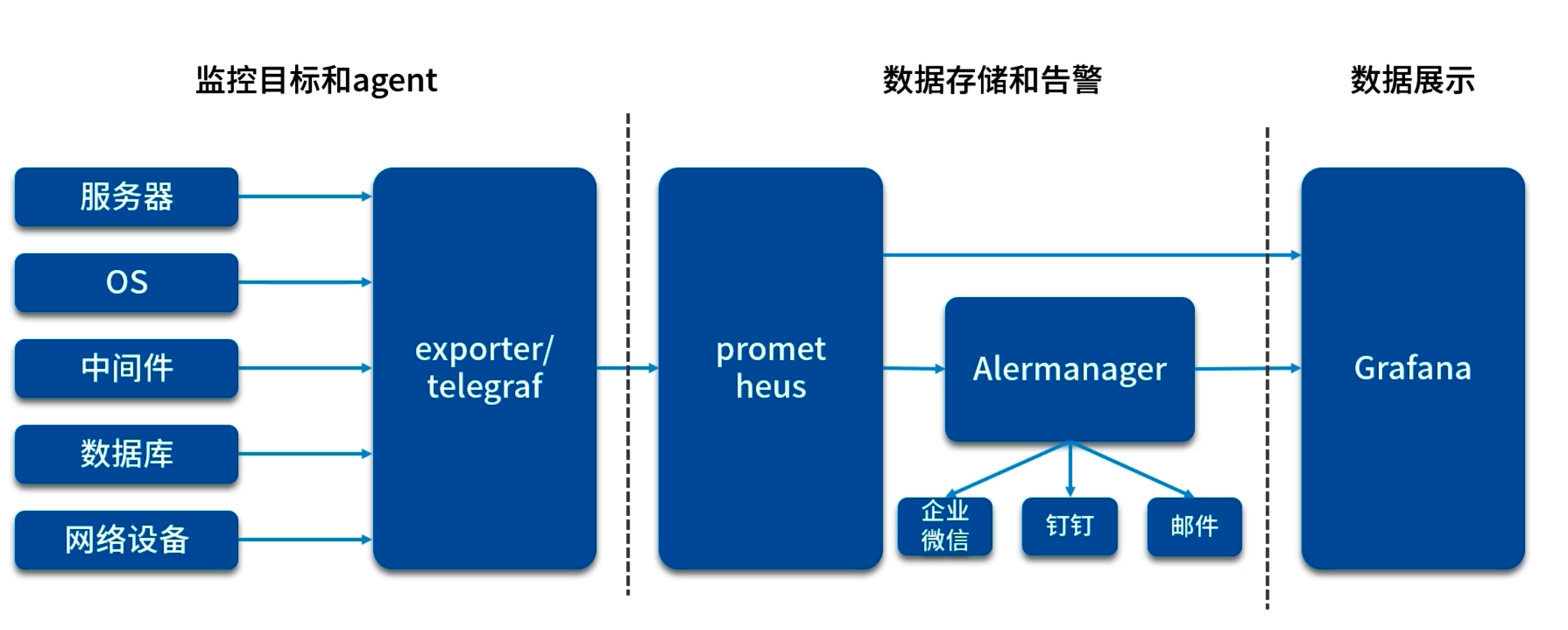
Grafana 可視化與 AlertManager
-
在 Grafana 中配置 Prometheus 數據源,創建 Dashboard 展示:
- JVM 內存、GC 停頓、線程數
- HTTP 請求速率、延遲分布(可借助 Histogram/Summary)
- 緩存命中率:hit/(hit+miss)
- 數據庫連接池使用率:活躍連接數 vs 最大連接數
-
AlertManager 配置告警規則,例如:
- 95% 延遲超過閾值
- GC 停頓時長過長
- 連接池耗盡告警
-
此部分可參考 Prometheus 與 Grafana 官方文檔,自行搭建實驗環境。
-
性能剖析工具:火焰圖與 async-profiler
async-profiler 下載與使用
-
從 GitHub 下載 async-profiler release 包,解壓至服務器目錄,如
/opt/async-profiler。 -
啟動 SpringBoot 應用時,添加 javaagent 參數:
java -agentpath:/opt/async-profiler/build/libasyncProfiler.so=start,svg,file=profile.svg -jar your-app.jar -
運行一段業務場景(壓測或真實流量),然后停止進程或通過 async-profiler 提供的 CLI 停止采樣:
# 若不想重啟,可 attach 模式: ./profiler.sh -d 30 -f profile.svg <pid> -
查看生成的
profile.svg,用瀏覽器打開:
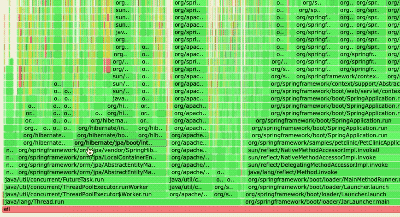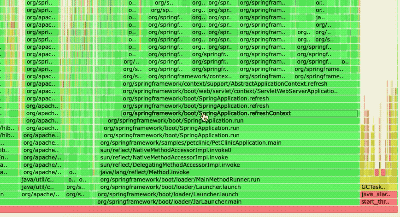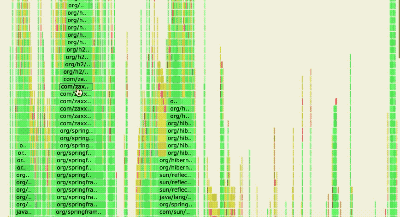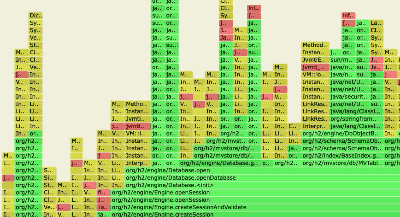
- 橫軸表示消耗的采樣比例,寬度越大表示更耗時的方法。
- 縱向為調用棧層級。
- 從最寬處逐層向下分析,找到熱點方法,結合源代碼定位優化點。
結合 Flame 圖優化示例
- 若熱點在某個慢方法,可查看方法內部邏輯:是否存在不必要的循環、I/O 阻塞,或可并行優化。
- 若熱點在序列化/反序列化,可考慮更高效的庫或減小返回對象結構。
- 若大量時間在 GC,可結合 GC 日志分析堆配置是否合理。
HTTP 及 Web 層優化
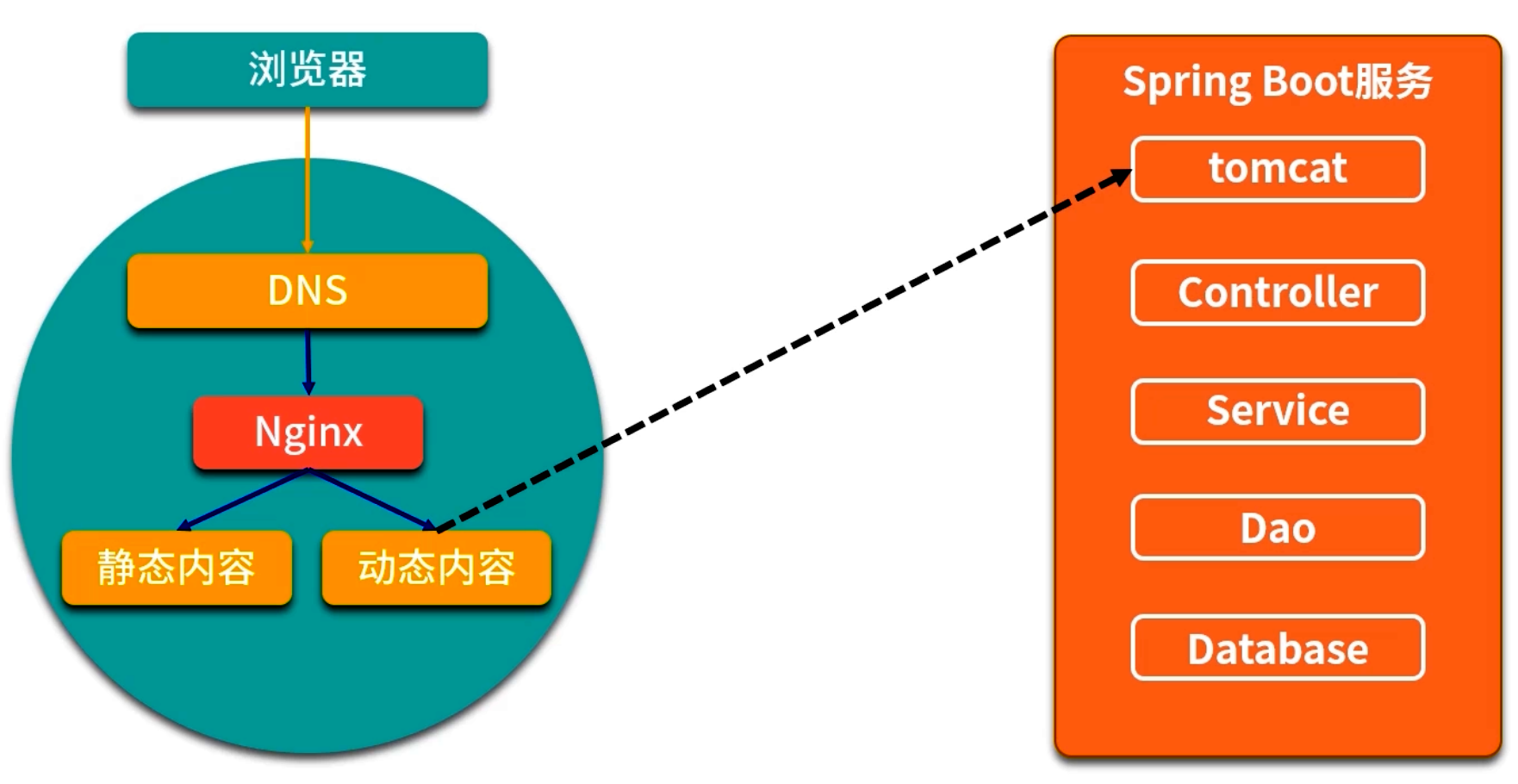
CDN 與靜態資源加速
- 將常用靜態資源(JS、CSS、圖片)托管于 CDN,減輕后端壓力;用戶訪問時由地理就近節點提供。
- 對第三方庫可使用公共 CDN;自有資源可上傳到 CDN 或靜態文件服務器。
Cache-Control/Expires 在 Nginx 中配置示例
location ~* \.(ico|gif|jpg|jpeg|png|css|js)$ {add_header Cache-Control "max-age=31536000, immutable";
}
- 根據資源更新策略設置版本號或文件指紋,保證緩存命中又可及時更新。
減少域名數量
- 將靜態資源和 API 接口合理合并域名;避免過多不同子域導致 DNS 查詢延遲。
- 可啟用 HTTP/2 時,多路復用可減少域名依賴,但 HTTP/2 支持需服務器和客戶端皆啟用。
Gzip 及資源壓縮配置
gzip on;
gzip_min_length 1k;
gzip_buffers 4 16k;
gzip_comp_level 6;
gzip_http_version 1.1;
gzip_types text/plain application/javascript text/css application/json;
- 確保對動態 JSON 接口開啟 gzip,減小響應體體積。
- 對大型靜態文件可在構建時先行壓縮(如 Brotli),結合 Nginx 支持。
Keep-Alive 配置
-
客戶端與 Nginx:
http {keepalive_timeout 60s 60s;keepalive_requests 10000; } -
Nginx 與 SpringBoot 后端長連接:
location / {proxy_pass http://backend;proxy_http_version 1.1;proxy_set_header Connection ""; } -
SpringBoot/Tomcat 默認支持 Keep-Alive;可通過自定義 Connector 調整超時。
SpringBoot 容器調優
自定義嵌入式 Tomcat
如果項目并發量比較高,想要修改最大線程數、最大連接數等配置信息,可以通過自定義Web 容器的方式,代碼如下所示。
@SpringBootApplication(proxyBeanMethods = false)
public class App implements WebServerFactoryCustomizer<ConfigurableServletWebServerFactory> {public static void main(String[] args) {SpringApplication.run(App.class, args);}@Overridepublic void customize(ConfigurableServletWebServerFactory factory) {if (factory instanceof TomcatServletWebServerFactory) {TomcatServletWebServerFactory f = (TomcatServletWebServerFactory) factory;f.setProtocol("org.apache.coyote.http11.Http11Nio2Protocol");f.addConnectorCustomizers(c -> {Http11NioProtocol protocol = (Http11NioProtocol) c.getProtocolHandler();protocol.setMaxConnections(200);protocol.setMaxThreads(200);protocol.setConnectionTimeout(30000);// protocol.setSelectorTimeout(3000); // NIO2 可選項});}}
}
- 設置協議為 NIO2 可在高并發 I/O 場景下提升性能;需基準測試驗證。
setMaxThreads和setMaxConnections值根據服務器硬件資源與業務并發調整,可在壓測環境多次嘗試并觀察響應延遲、CPU 利用率、線程使用情況。

替換 Undertow
-
在
pom.xml中排除 Tomcat 并引入 Undertow:<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><exclusions><exclusion><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-tomcat</artifactId></exclusion></exclusions> </dependency> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-undertow</artifactId> </dependency> -
Undertow 線程模型和資源占用一般較輕;需要在業務場景中壓測對比。
-
注意部分 Tomcat 特有配置不適用,需調整監控指標對應項。
JVM 參數回顧
-
結合性能優化 - 高級進階:JVM 常見優化參數
,可啟動時傳入:-XX:+UseG1GC -Xms2048m -Xmx2048m -XX:+AlwaysPreTouch -XX:MaxMetaspaceSize=256m -XX:ReservedCodeCacheSize=240m -XX:MaxDirectMemorySize=512m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path/to/dumps -XX:ErrorFile=/path/to/hs_err_pid%p.log -Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=5,filesize=100m -
根據硬件和應用特點調整堆大小;若GC停頓問題突出,可結合 async-profiler 和 GC 日志深入分析。
應用性能監控與分布式追蹤
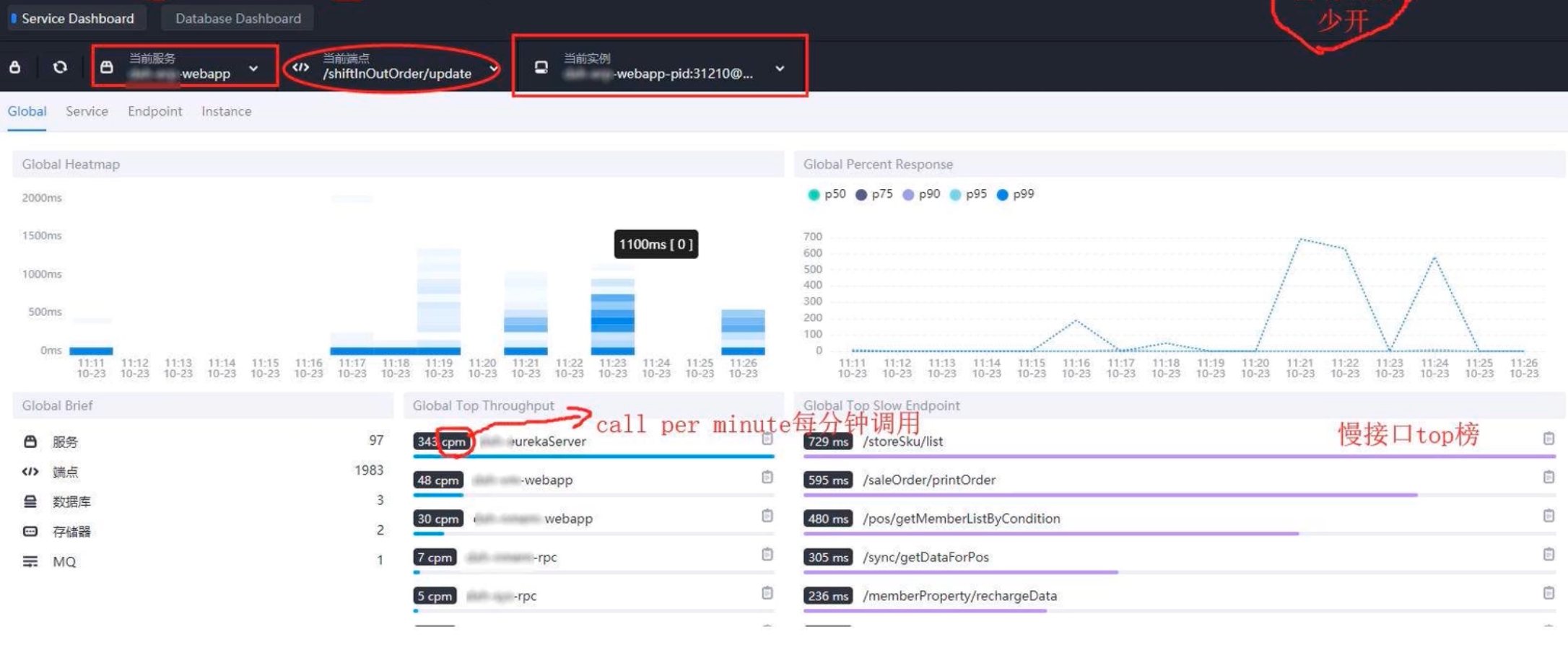
SkyWalking 集成
-
下載與部署
- 下載 SkyWalking Agent 和后端服務(按存儲類型,如 Elasticsearch 存儲版)。
- 部署 SkyWalking 后端:配置 Storage、UI、Collector。
-
啟動應用時添加 Agent
java -javaagent:/opt/skywalking-agent/skywalking-agent.jar \-Dskywalking.agent.service_name=your-service-name \-Dskywalking.collector.backend_service=collector-host:11800 \-jar your-app.jar -
查看調用鏈與指標
- 訪問 SkyWalking UI,可看到每次請求的調用鏈圖、各段耗時、數據庫/HTTP 調用詳情、JVM 指標、GC 指標。
- 結合 Prometheus 等指標,綜合判斷:若某接口響應慢,可查看是哪一段(查詢、序列化、遠程調用等)成為瓶頸。
-
報警與自動化
- 可結合 SkyWalking 的告警和 Prometheus AlertManager 設置閾值告警。
- 定期分析熱點接口和突發異常請求流,制定優化計劃。
各層優化思路
Controller 層
- DTO 精簡與分頁:避免一次性返回過大結果集;對列表數據使用分頁或流式方式(如 Spring MVC StreamingResponseBody)。
- JSON 序列化優化:選擇高性能序列化庫(Jackson 已較快,可開啟 Afterburner 模塊),避免將不必要字段序列化。
- 輸入校驗與限流:對異常或惡意請求提前攔截,減少無效處理。
- 冪等性與緩存:對可緩存接口,如 GET 查詢,結合 HTTP 緩存頭或后端緩存減少重復計算。
Service 層
-
無狀態設計:Service Bean 默認單例無狀態,避免在 Bean 中維護請求級狀態。
-
合理拆分與職責分離:將復雜邏輯拆成小模塊,便于監控與優化。
-
異步與并行:對于可并行處理的子任務,可使用 CompletableFuture、異步消息隊列等;但要注意線程池配置與上下文傳遞。
-
緩存策略:
- 本地緩存(Caffeine):低延遲、減輕遠程調用壓力;監控命中率,避免緩存污染。
- 分布式緩存(Redis):適用于共享場景;注意 TTL 策略、防止緩存穿透(布隆過濾、請求預熱)、防止雪崩(加隨機過期)、防止擊穿(互斥鎖或預加載)。
-
避免重復計算與請求合并:對重復請求可合并或去重,減少下游壓力。
-
分布式事務討論:
- 兩階段提交、TCC、本地消息表、MQ事務消息等方案都會增加延遲與資源占用;僅在必要場景使用。
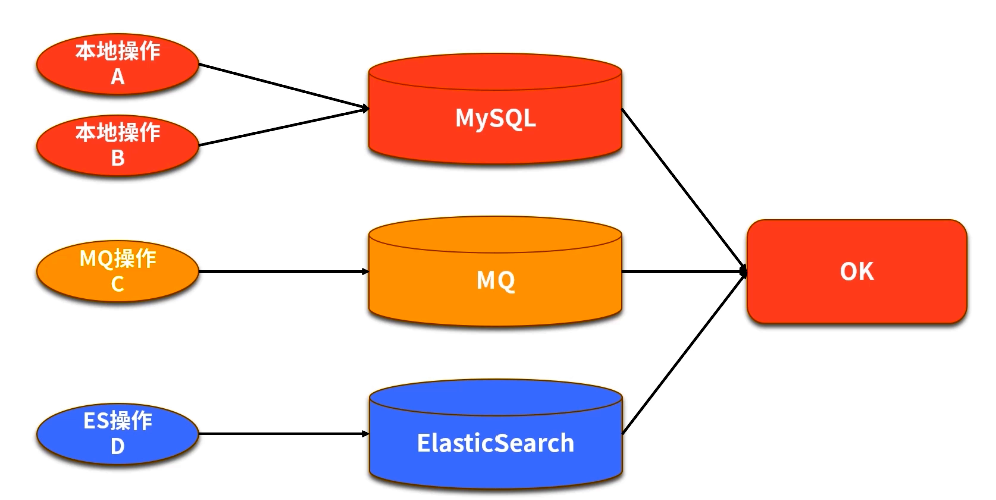
- 優先考慮補償事務與柔性事務,實現最終一致性;通過冪等設計與補償邏輯將風險和性能開銷控制在可接受范圍內。
如上圖,分布式事務要在改造成本、性能、時效等方面進行綜合考慮。有一個介于分布式事務和非事務之間的名詞,叫作柔性事務。柔性事務的理念是將業務邏輯和互斥操作,從資源層上移至業務層面。
傳統事務 vs 柔性事務
關于傳統事務和柔性事務,我們來簡單比較一下。
ACID
關系數據庫, 最大的特點就是事務處理, 即滿足 ACID。
-
原子性(Atomicity):事務中的操作要么都做,要么都不做。
-
一致性(Consistency):系統必須始終處在強一致狀態下。
-
隔離性(Isolation):一個事務的執行不能被其他事務所干擾。
-
持久性(Durability):一個已提交的事務對數據庫中數據的改變是永久性的。
BASE
BASE 方法通過犧牲一致性和孤立性來提高可用性和系統性能。
BASE 為 Basically Available、Soft-state、Eventually consistent 三者的縮寫,其中 BASE 分別代表:
-
基本可用(Basically Available):系統能夠基本運行、一直提供服務。
-
軟狀態(Soft-state):系統不要求一直保持強一致狀態。
-
最終一致性(Eventual consistency):系統需要在某一時刻后達到一致性要求。
互聯網業務,推薦使用補償事務,完成最終一致性。比如,通過一系列的定時任務,完成對數據的修復。
DAO 層
-
ORM 使用注意:
- 懶加載原則:避免無意觸發大量關聯查詢,合理使用 FetchType.LAZY,并在Service層通過顯式查詢或 DTO 投影避免 N+1。
- 批量操作:對于大量寫場景,使用批量插入/更新。
-
SQL 優化與索引:分析慢查詢日志、使用 EXPLAIN 確認索引命中,避免全表掃描。
-
分庫分表注意:理解中間件實現原理,避免誤以為簡單 SQL 實現即高效;關注路由開銷與合并成本。
-
數據庫連接池:
- HikariCP 默認已非常高效,但仍需監控活躍連接數、等待時長;根據業務并發調整最大連接數,避免連接池耗盡或空閑過多浪費資源。
- 在 Prometheus 中可通過
HikariPool指標收集連接使用情況,適時調整。
緩存優化
-
Caffeine:適合本地緩存,低延遲;需監控緩存大小、命中率、加載延遲;避免過大導致內存占用過高。
-
Redis:
- 連接池配置:監控和調整 Lettuce/Redisson 連接數;注意阻塞或過度并發導致連接耗盡。
- 數據序列化:選擇高效序列化方式(如 JSON、Kryo、FST 等),兼顧可讀性與性能。
- 緩存策略:參見上文防護策略;結合業務場景設計合理 TTL。
-
二級緩存:對數據庫讀密集應用,可考慮本地+分布式二級緩存架構;注意緩存一致性。
資源與線程管理
-
線程池配置:
- 對于異步任務、自定義 Executor,設置合適的 core/max pool size、queue size;監控線程活躍度、隊列長度,防止任務堆積。
- 對于定時任務,避免過多定時線程爭搶資源。
-
非阻塞與異步:
- 若業務適合,可使用 WebFlux 或 Reactor,但需慎重考慮團隊熟悉度與實際場景;異步場景要注意線程切換開銷和上下文傳遞。
- 對外 HTTP 調用可使用異步 HTTP 客戶端(如 WebClient),避免阻塞線程。
端到端測試與壓測
- 壓測工具:wrk、JMeter、Locust 等
- 測前準備:確保監控、日志、profiling 準備完畢;在測試環境部署與生產相近的架構。
- 測試腳本設計:模擬真實業務流量,包括登錄、查詢、寫入等混合場景。
- 結果分析:結合 Prometheus/Grafana 監控數據和火焰圖,找出瓶頸;反復調優并回歸測試,評估改動效果。
- 負載模型:考慮漸增負載測試、穩定性測試、持久壓力測試,觀察資源消耗與響應曲線。
小結
- 指標采集—剖析—優化—驗證是閉環流程:始終保持對系統可觀測性。
- 漸進式改動:在非生產環境驗證,避免一次性大改帶來風險;生產環境小步部署與監控回滾準備。
- CI/CD 集成:可在持續集成/部署流程中集成簡單的健康檢查和性能基準測試。
- 定期回顧:定時檢查關鍵接口的性能指標,防止代碼或依賴升級帶來性能回退。
- 團隊協作:文檔化優化經驗,分享給團隊成員,形成共識和規范。







)
 時什么意思? 7,7又是什么意思?)

)









