一、音量增強
音量增強,顧名思義就是音量的調大和調小,通過對音量進行增強可以使得模型更好的泛化。防止數據只有小音量時,當有大音量傳入時模型不能很好的進行識別。
下面是我對音量增強生成頻譜圖進行可視化的結果
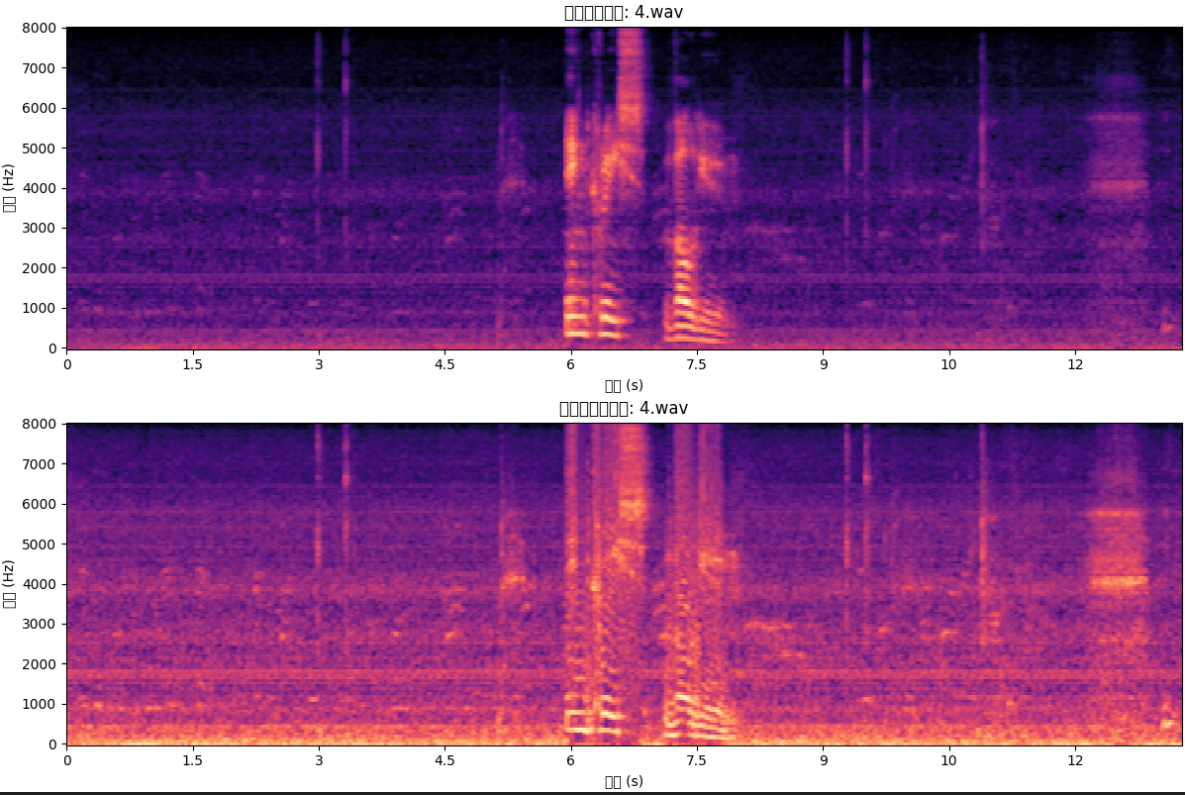
上面的一個圖片是音量增強前的頻譜圖,下面是音量增加50dB(分貝)的結果。由圖可知音量的增加使得頻譜圖更亮。
#對音量增強進行可視化
import os
from pydub import AudioSegment
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt# 音頻路徑
audio_path = ""
output_path = ""# 創建輸出目錄
os.makedirs(output_path, exist_ok=True)def volume_boost(audio, gain_db):"""音量增強"""return audio + gain_dbdef plot_combined_spectrogram(original_samples, boosted_samples, sample_rate, title, output_file):"""繪制原始和增強后的頻譜圖在同一張圖片中"""# 轉換為浮點型并歸一化original_samples = original_samples.astype(np.float32) / np.max(np.abs(original_samples))boosted_samples = boosted_samples.astype(np.float32) / np.max(np.abs(boosted_samples))# 使用 librosa 計算頻譜S_original = librosa.feature.melspectrogram(y=original_samples, sr=sample_rate, hop_length=256)S_original_db = librosa.power_to_db(S_original, ref=np.max)S_boosted = librosa.feature.melspectrogram(y=boosted_samples, sr=sample_rate, hop_length=256)S_boosted_db = librosa.power_to_db(S_boosted, ref=np.max)# 繪制頻譜圖fig, axs = plt.subplots(2, 1, figsize=(12, 8), constrained_layout=True)# 原始頻譜圖librosa.display.specshow(S_original_db, sr=sample_rate, hop_length=256, x_axis='time', y_axis='hz', cmap='magma', ax=axs[0])axs[0].set_title(f"原始音頻頻譜: {title}")axs[0].set_ylabel("頻率 (Hz)")axs[0].set_xlabel("時間 (s)")# 增強后頻譜圖librosa.display.specshow(S_boosted_db, sr=sample_rate, hop_length=256, x_axis='time', y_axis='hz', cmap='magma', ax=axs[1])axs[1].set_title(f"音量增強后頻譜: {title}")axs[1].set_ylabel("頻率 (Hz)")axs[1].set_xlabel("時間 (s)")# 保存圖片plt.savefig(output_file)plt.close()# 遍歷目錄中的音頻文件
for file_name in os.listdir(audio_path):if file_name.endswith(".wav"):file_path = os.path.join(audio_path, file_name)audio = AudioSegment.from_file(file_path)# 獲取原始音頻的時域數據original_samples = np.array(audio.get_array_of_samples())sample_rate = audio.frame_rate# 音量增強audio_volume_boosted = volume_boost(audio, gain_db=50)volume_boosted_samples = np.array(audio_volume_boosted.get_array_of_samples())# 保存原始和增強后頻譜圖到同一張圖片combined_spectrum_file = os.path.join(output_path, f"{file_name}_combined_spectrum.png")plot_combined_spectrogram(original_samples, volume_boosted_samples, sample_rate, file_name, combined_spectrum_file)print(f"保存頻譜圖到: {combined_spectrum_file}")
二、EQ增強
EQ增強,首先應該了解什么是EQ?
EQ,全稱Equalizer,中文稱為均衡器,也常簡稱為“均衡”或“均衡調節”。它是一種音頻處理工具,通過對不同頻率段的音量進行獨立增強或削弱,以達到改善或修飾聲音色彩、平衡音色的作用。
通俗的講:想象聲音是一張由低音、中音、高音組成的圖片。EQ就像調節圖片每個色調的明暗,可以讓低音更渾厚、高音更明亮、中音更突出,或者把某些不需要的頻段衰減掉讓聲音更清晰。
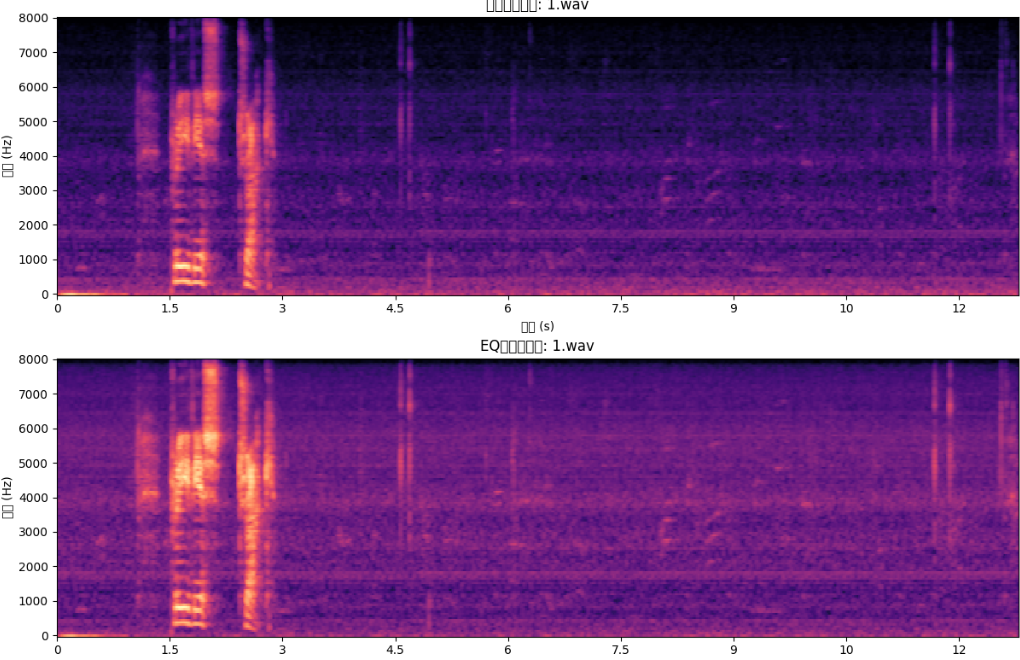
下面圖是EQ增強前的頻譜圖和對低頻5000hz進行了20dB的增益的頻譜圖,發現在高頻的亮度有明顯的提升。
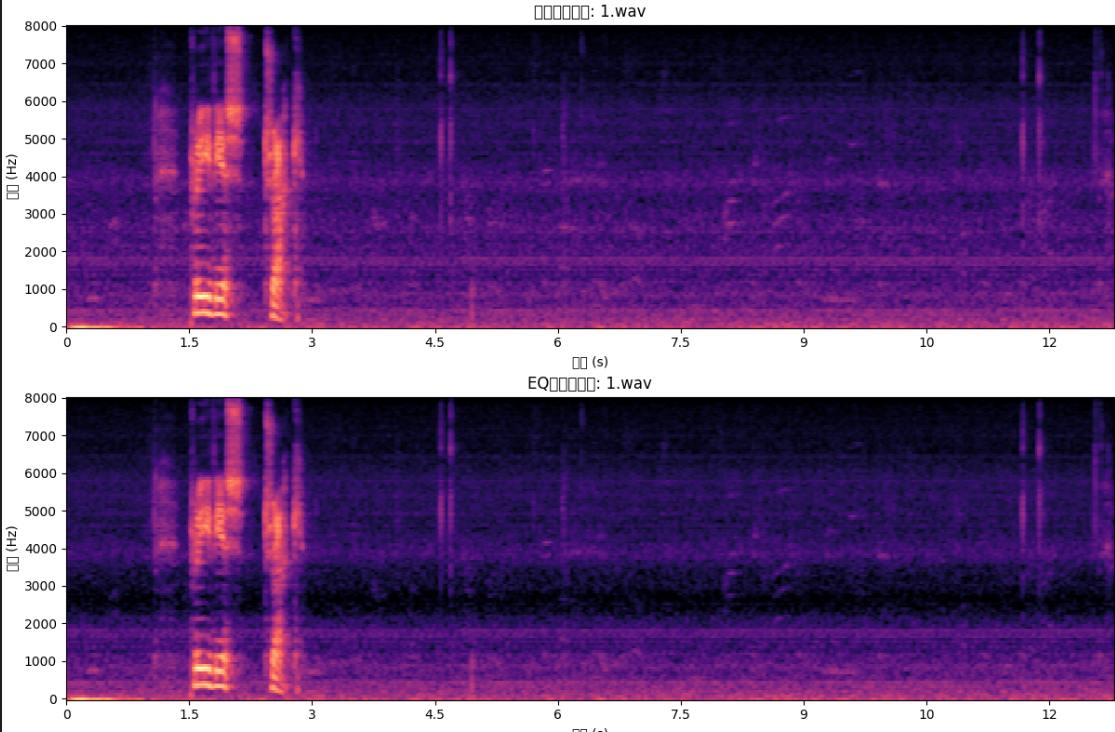
下面圖是EQ增強前的頻譜圖和對低頻1000hz進行了-20dB的增益的頻譜圖,發現亮度有明顯的下降。
#對EQ增強進行可視化
import os
from pydub import AudioSegment
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt
import scipy.signalaudio_path = ""
output_path = ""os.makedirs(output_path, exist_ok=True)def db_to_linear(gain_db):"""dB增益轉線性倍數"""return 10 ** (gain_db / 20)def apply_eq(samples, sample_rate, eq_settings):"""簡易EQ增強,對多個頻段峰值調節:param samples: 一維int16/float音頻數據:param sample_rate: 采樣率:param eq_settings: [{'freq': center_freq, 'gain_db': gain, 'q': Q}, ...]:return: 增強后樣本(int16)"""y = samples.astype(float)for eq in eq_settings:f0 = eq['freq']gain_db = eq['gain_db']Q = eq.get('q', 1.0)# 設計二階峰值濾波器b, a = scipy.signal.iirpeak(w0=f0/(sample_rate/2), Q=Q)filtered = scipy.signal.lfilter(b, a, y)linear_gain = db_to_linear(gain_db)y += (linear_gain - 1) * filtered# 防止溢出并轉換回int16y = np.clip(y, -32768, 32767)return y.astype(np.int16)def plot_combined_spectrogram(original_samples, boosted_samples, sample_rate, title, output_file):"""繪制原始和增強后的頻譜圖在同一張圖片中"""# 轉換為浮點型并歸一化original_samples = original_samples.astype(np.float32) / np.max(np.abs(original_samples))boosted_samples = boosted_samples.astype(np.float32) / np.max(np.abs(boosted_samples))# 使用 librosa 計算頻譜S_original = librosa.feature.melspectrogram(y=original_samples, sr=sample_rate, hop_length=256)S_original_db = librosa.power_to_db(S_original, ref=np.max)S_boosted = librosa.feature.melspectrogram(y=boosted_samples, sr=sample_rate, hop_length=256)S_boosted_db = librosa.power_to_db(S_boosted, ref=np.max)# 繪制頻譜圖fig, axs = plt.subplots(2, 1, figsize=(12, 8), constrained_layout=True)# 原始頻譜圖librosa.display.specshow(S_original_db, sr=sample_rate, hop_length=256, x_axis='time', y_axis='hz', cmap='magma', ax=axs[0])axs[0].set_title(f"原始音頻頻譜: {title}")axs[0].set_ylabel("頻率 (Hz)")axs[0].set_xlabel("時間 (s)")# 增強后頻譜圖librosa.display.specshow(S_boosted_db, sr=sample_rate, hop_length=256, x_axis='time', y_axis='hz', cmap='magma', ax=axs[1])axs[1].set_title(f"EQ增強后頻譜: {title}")axs[1].set_ylabel("頻率 (Hz)")axs[1].set_xlabel("時間 (s)")# 保存圖片plt.savefig(output_file)plt.close()eq_settings = [{'freq': 1000, 'gain_db': -20, 'q': 1.0},
]for file_name in os.listdir(audio_path):if file_name.endswith(".wav"):file_path = os.path.join(audio_path, file_name)audio = AudioSegment.from_file(file_path)original_samples = np.array(audio.get_array_of_samples())sample_rate = audio.frame_rateeq_samples = apply_eq(original_samples, sample_rate, eq_settings)combined_spectrum_file = os.path.join(output_path, f"{file_name}_eq_combined_spectrum.png")plot_combined_spectrogram(original_samples, eq_samples, sample_rate, file_name, combined_spectrum_file)print(f"保存頻譜圖到: {combined_spectrum_file}")
EQ增強和普通音量增強的區別
音量增強:是所有頻率都等比例放大(比如整體變大聲)。
EQ增強:只針對某些頻率增強或削弱(如只讓高頻變大聲、低頻變安靜),整體音量未必變化很大,而是“音色、清晰度”變化。
三、RIR增強
RIR增強,首先應該了解什么是RIR?
舉個例子:
比如你錄一段“你好”,在干凈錄音棚是很干凈的,沒有任何回聲。
你把這段語音和一個會議室的RIR做卷積,這段錄音就像是在會議室里說的,帶有真實的混響、空間感。
如果用浴室的RIR,那就像你在浴室說話,回聲很大。
————————————————————————————后續會更新
)
Android官方調試工具及常用命令)



)
)




)



)



