文章目錄
- 分布假設學習筆記
- 自然語言處理中的分布假設
- 應用場景
- 適用范圍
- Word2vec、BERT和GPT
- Word2vec
- BERT
- GPT
- 假設成立嗎
分布假設學習筆記
自然語言處理中的分布假設
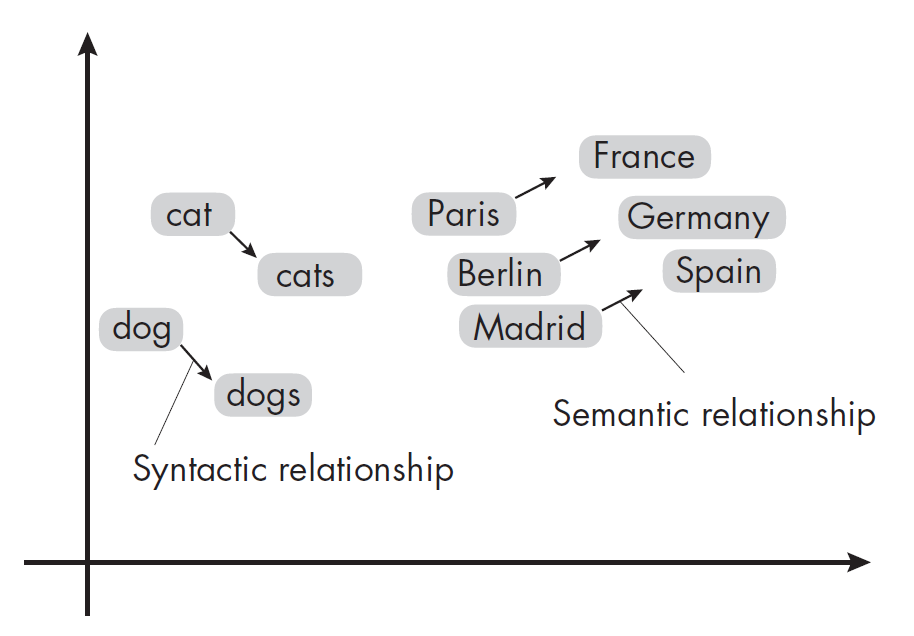
分布假設(Distributional Hypothesis)是指:詞語在相似上下文中出現,其意義也相似。換句話說,如果兩個詞在文本中經常出現在相似的環境中,那么它們的語義也很可能相近。
應用場景
- 詞向量學習:如Word2Vec、GloVe等模型,利用分布假設通過上下文信息學習詞的向量表示。
- 詞義消歧:通過分析上下文,判斷多義詞的具體含義。
- 文本聚類與分類:基于詞的分布特征對文本進行聚類或分類。
- 信息檢索與推薦:根據詞或短語的分布相似性改進檢索和推薦效果。
適用范圍
分布假設廣泛適用于大多數自然語言處理任務,尤其是在無監督或弱監督學習中。它對低資源語言、專業領域文本等也有一定適用性,但對于需要深層語義理解或常識推理的任務,分布假設的能力有限,需結合其他方法提升效果。
Word2vec、BERT和GPT
Word2vec
Word2vec 通過一個簡單的兩層神經網絡,將詞語編碼為嵌入向量,確保相似詞語的嵌入向量在語義和句法上也相近。訓練Word2vec模型有兩種方式:
-
CBOW(continuous bag-of-words,連續詞袋)模型:Word2vec依據上下文中的詞預測當前詞。
-
跳字(skip-gram)模型:與CBOW相反,在跳字模型中,Word2vec根據選定的詞來預測上下文詞語。盡管跳字模型對于不常見的詞更為有效,但CBOW模型通常訓練速度更快。
BERT
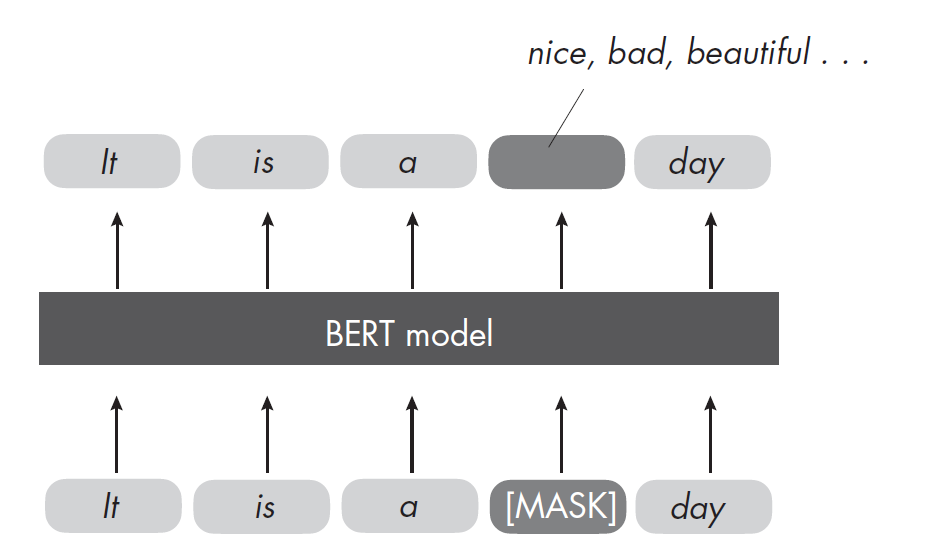
BERT(Bidirectional Encoder Representations from Transformers)是一種基于Transformer結構的預訓練語言模型。它通過雙向編碼器同時關注上下文的左右信息,能夠更好地理解詞語在句子中的含義。BERT在大規模語料上進行預訓練,然后通過微調應用于各種下游任務,如文本分類、問答和命名實體識別等,顯著提升了自然語言處理的效果。
GPT
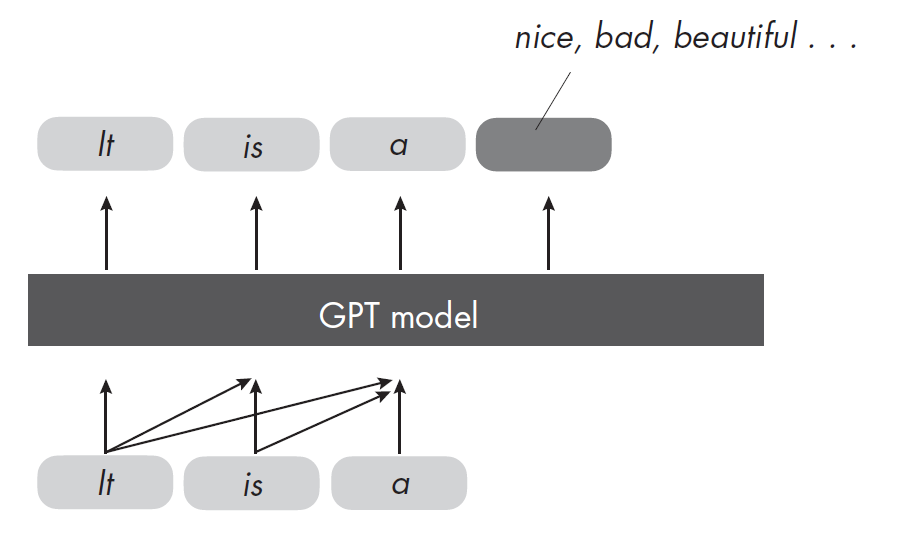
GPT(Generative Pre-trained Transformer)是一種基于Transformer架構的生成式預訓練語言模型。GPT通過在大規模文本數據上進行自回歸訓練,學習根據已有文本生成下一個詞,從而掌握語言的結構和語義。與BERT不同,GPT主要采用單向(從左到右)建模方式,擅長文本生成、對話系統、自動摘要等任務。經過預訓練后,GPT可以通過微調適應各種自然語言處理應用。
假設成立嗎
分布假設在大多數自然語言處理場景下是成立的,尤其是在大規模語料和統計學習方法中表現良好。它為詞向量、文本聚類等任務提供了理論基礎。然而,分布假設也有局限性:它主要關注詞的表面共現關系,難以捕捉深層語義、常識推理或上下文依賴極強的語言現象。因此,現代NLP模型(如BERT、GPT)在分布假設基礎上,結合了更復雜的結構和預訓練目標,以提升對語言的理解和生成能力。
盡管存在一些分布假設不適用的反例,但它仍然是一個非常有用的概念,構成了今天語言類Transformer模型的基石。
)



)





一面面經)
)
)




超詳細)

