1. Oracle高可用和ob高可用,和他們的實現方式?
2.ob的三副本了解嗎,ob的三副本怎么保障強一致的?
3.三副本能實現強一致嗎?
4.了解ob的數據協調協議嗎?說說原理
5.聊聊Oracle,講一些SQL調優的實際案例?
6.剛才聊到了分區表的分區裁剪,假如不調整謂詞條件的情況下,有什么方法也能加速SQL?
7.并行了解嗎,說一下并行的機制,怎么使用的?
8.為什么生產環境不推薦使用并行?主要對哪些資源有壓力
9.redo是用來做什么的?Oracle select會寫redo嗎?
10.Oracle寫入數據,講一下數據落盤的過程。
11.RAC集群數據落盤的過程。
12.假如兩個節點的RAC,比如一節點寫了1,二節點會有什么操作?操作的順序了解嗎
13.介紹一下實習經歷
14.OB三個節點如果宕機一個影響使用嗎?宕機的過程中會有什么樣的表現?
15.只有三個機器,一臺宕機了,unit能遷移走嗎?
16.現在正在往集群里面寫入數據,宕機了一臺,在業務端看來會有什么樣的表現?
答案
1.Oracle高可用和ob高可用,和他們的實現方式?
?
| 數據庫 | 高可用方案 | 實現原理 |
|---|---|---|
| Oracle | RAC | 多節點共享存儲,通過Cache Fusion同步內存數據。故障時秒級切換,應用透明。 |
| OceanBase | 分布式Paxos協議 | 數據分片(Partition)+三副本,基于Paxos協議實現多副本強一致,無共享架構。 |
2.ob的三副本了解嗎,ob的三副本怎么保障強一致的?
每個數據分片(Partition)包含3個副本(Leader/Follower/Follower)。
寫入流程:
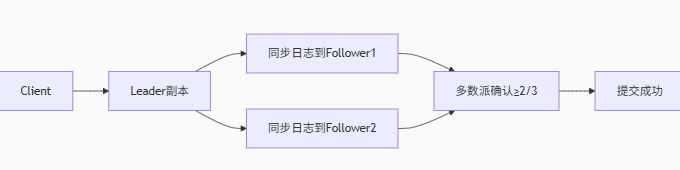
強一致保證:僅當多數副本(≥2)持久化日志后,才向客戶端返回成功。
3.三副本能實現強一致嗎?
能,通過Paxos協議約束: 任何寫入需多數副本確認(如3副本需≥2個確認)。網絡分區時,少數派副本自動拒絕寫入,避免腦裂。
4.了解ob的數據協調協議嗎?說說原理
Multi-Paxos優化:
-
Leader選舉: 通過Paxos協議選舉唯一Leader處理寫入。
-
日志復制:Leader生成Redo日志并廣播給Followers。
-
Followers持久化日志后返回ACK。
-
收到多數ACK后,Leader提交并應用日志。
-
日志回放: 所有副本按相同順序應用日志,保障狀態機一致性。
5.聊聊Oracle,講一些SQL調優的實際案例?
SELECT?*?FROM?sales?WHERE?TO_CHAR(sale_date,'YYYY-MM')?=?'2023-10';?--?函數導致裁剪失效
優化:
SELECT?*?FROM?sales?WHERE?sale_date?BETWEEN?DATE'2023-10-01'?AND?DATE'2023-10-31';?--?直接范圍查詢
6.剛才聊到了分區表的分區裁剪,假如不調整謂詞條件的情況下,有什么方法也能優化SQL?
-
全局索引: 避免分區鍵限制。
-
本地索引分區: 每個分區獨立索引,加速掃描。
-
統計信息更新: DBMS_STATS.GATHER_TABLE_STATS確保優化器準確選擇分區。
-
SQL Profile: 使用SQL Tuning Advisor固定高效執行計劃。
7.并行了解嗎,說一下并行的機制,怎么使用的?
啟用并行:
ALTER?SESSION?ENABLE?PARALLEL?DML;
SELECT?/*+?PARALLEL(emp,?4)?*/?*?FROM?emp;?--?強制4個并行進程
資源控制:
PARALLEL_DEGREE_POLICY:?控制并行度策略(AUTO/MANUAL)。
PARALLEL_SERVERS_TARGET:?限制并行服務器數。
8.生產環境不推薦并行的原因
-
CPU: 并行進程爭搶CPU,導致系統負載飆升。
-
I/O: 大量并行掃描引發存儲吞吐瓶頸。
主要原因是CPU和IO,內存方面不是主要原因。
-
內存: 每個并行進程消耗PGA內存,可能觸發ORA-4030。
-
鎖競爭: 并行DML加劇鎖沖突(如TX鎖)。
9.redo是用來做什么的?Oracle select會寫redo嗎?
核心功能: 記錄所有數據變更(DML/DDL),用于故障恢復。
SELECT語句不會直接生成redo日志,因為它們不修改數據庫內容。但在維護讀一致性、使用直接路徑讀取、執行遞歸SQL以及觸發PL/SQL函數或數據庫觸發器時,可能會間接產生redo日志。
具體原因參考文章: select會寫redo嗎
10.Oracle寫入數據,講一下數據落盤的過程。
-
用戶提交DML。
-
日志寫入Log Buffer。
-
LGWR將Log Buffer刷新到Redo Log文件(優先保證日志落盤)。
-
DBWR將臟塊從Buffer Cache寫入數據文件(異步進行)。
11.RAC集群數據落盤的過程。
| 階段 | 關鍵組件 | 工作流程設計目標設計目標 | 設計目標 |
|---|---|---|---|
| 1. 數據塊傳遞 | Cache Fusion | 1. 節點A修改數據塊時,通過私網(Interconnect)將塊副本傳輸給請求節點B2. GCS 跟蹤塊狀態(CR/XD 模式)3. 塊在內存間直接傳遞,避免磁盤 I/O | 減少共享存儲訪問提升并發性能 |
| 2. Redo 日志落盤 | ASM 存儲 | 1. 每個節點獨立寫入本地 Redo 日志線程2. 日志寫入共享存儲(ASM 磁盤組)3. 提交時強制刷盤(Commit = Log Written) | 確保事務持久性節點故障時恢復 |
| 3. 臟塊寫入 | DBWR 進程 | 1. GCS 協調臟塊刷盤順序2. 持有最新版本的節點執行寫盤3. 寫入共享數據文件(ASM) | 保證數據一致性減少寫沖突 |
| 4. 全局一致性 | GCS + GES | 1. GES 管理全局鎖(如 TX 鎖)2. GCS 協調塊訪問權3. 通過塊版本號解決沖突 | 跨節點讀一致性 寫操作串行化 |
12.假如兩個節點的RAC,比如一節點寫了1,二節點會有什么操作?操作的順序了解嗎
?
場景:節點1寫入數據塊A(值為1)
-
節點1持有A的Exclusive鎖。
-
節點2請求修改A:
-
通過GCS向節點1請求塊副本。
-
節點1將A的當前版本+鎖信息傳遞給節點2。
-
節點2在本地緩存中修改A,生成Redo日志并落盤。
-
節點2通過GCS廣播塊變更信息。
13.介紹一下實習經歷
省略
14.OB三個節點如果宕機一個影響使用嗎?宕機的過程中會有什么樣的表現?
?
-
宕機一個節點:
無影響: 剩余2節點滿足多數派(2/3),服務正常。
Leader切換: 宕機節點若含Leader副本,5秒內自動選舉新Leader。
-
宕機過程表現:
客戶端連接該節點的會話斷開(需重試)。 其他節點短暫寫入延遲(Paxos重新協商)。
1.如果是三個單zone單observer是一份數據。如果某OBServer掛掉了,且超過 server_permanent_offline_time時間限制會永久下線,需要把這個單zone單observer下掉。重新部署上去。
2.如果是三個單zone多observer,且primary_zone 為 RANDOM 時,ob數據是以分布式存儲的(以分區形式來的,按分區的粒度自動均衡到不同的OBServer節點,打散數據)
15.只有三個機器,一臺宕機了,unit能遷移走嗎?
?
-
當某個OBServer節點掛掉時:
多副本機制:ob通常會在不同的OBServer上存儲數據的多個副本(通常是3個副本)。這意味著即使一個節點失敗,其他節點上仍然有數據的副本。
數據同步:在節點恢復后,ob會自動同步該節點上的數據,確保所有節點上的數據副本保持一致。
在官網論壇上找到的,所以結論應該是沒有遷移走。。
16.現在正在往集群里面寫入數據,宕機了一臺,在業務端看來會有什么樣的表現?
?
-
客戶端視角:
短時報錯(如Connection reset),持續約1-5秒。
自動恢復: OBProxy 自動重試請求到新Leader。
-
數據一致性:
已提交的數據不丟失(多數副本已持久化)。
未提交的事務自動回滾。
)
)




超詳細)



和 `logits`(原始預測分數)是什么)



)

基于Pytorch手搓RNN參考)


