基礎
Java Kafka消費者主要通過以下核心類實現:
- KafkaConsumer:消費者的核心類,用于創建消費者對象進行數據消費1
- ConsumerConfig:獲取各種配置參數,如果不配置就使用默認值1
- ConsumerRecord:每條數據都要封裝成一個ConsumerRecord對象才可以進行消費1
偏移量(Offset)的含義
- Offset 是 Kafka 分區內部的消息序號,唯一標識一條消息在分區內的位置。
- 對于 consumer,offset 代表“下一個要消費的消息”。
- 提交 offset 是容錯的關鍵,當 consumer 崩潰/重啟/再均衡后,能從正確位置恢復消費。
- 如果 offset 提交得過早,可能會丟消息;如果太晚,可能會重復消費。
Kafka提供兩種主要的消費方式:
(1)手動提交offset方式
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-1:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); // 關閉自動提交
props.put(ConsumerConfig.GROUP_ID_CONFIG, "csdn");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("testKafka"));while (true) {ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records) {System.out.println("topic = " + record.topic() + " offset = " + record.offset() + " value = " + record.value());}consumer.commitAsync(); // 異步提交// 或者使用 consumer.commitSync(); // 同步提交
}
(2)自動提交offset方式
Properties props = new Properties();
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true"); // 開啟自動提交
props.put("auto.commit.interval.ms", "1000"); // 自動提交時間間隔while (true) {ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records) {System.out.println("topic = " + record.topic() + " offset = " + record.offset() + " value = " + record.value());}// 不需要手動提交offset
}
手動提交offset有兩種具體實現:
- commitSync():同步提交,會失敗重試,一直到提交成功1
- commitAsync():異步提交,沒有失敗重試機制,但延遲較低1
消費者組(Consumer Group)
// 通過group.id配置指定消費者組
props.put(ConsumerConfig.GROUP_ID_CONFIG, "experiment");
消費者組的特性:
- 同一個組中的consumer訂閱同樣的topic,每個consumer接收topic一些分區中的消息4
- 同一個分區不能被一個組中的多個consumer消費4
Broker連接
// 指定Kafka集群的broker地址
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
偏移量(Offset)管理
// 記錄分區的offset信息
Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();// 在處理消息時更新offset
currentOffsets.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1, "no metadata")
);// 提交特定的偏移量
consumer.commitAsync(currentOffsets, null);
消費者通過pull(拉)模式從broker中讀取數據:
-
輪詢機制:通過
consumer.poll(timeout)方法輪詢獲取消息 -
批量處理:poll方法返回的是一批數據,不是單條
-
心跳維護:消費者通過向GroupCoordinator發送心跳來維持和群組以及分區的關系
在生產環境中,一般使用手動提交offset方式,因為:
- 手動提交offset取到的數據是可控的
- 可以通過控制提交offset和消費數據的順序來保證數據的可靠性
- 雖然commitAsync沒有失敗重試機制,但實際工作中用它比較多,因為延遲較低
?KafkaConsumer?類分析
KafkaConsumer 是 Kafka 的客戶端核心類之一,用于消費 Kafka 集群中的消息。它支持高可靠的消息消費、自動容錯、分區分配與再均衡、消費組(Consumer Group)等機制。
主要成員
- delegate:
KafkaConsumer實際的大部分操作都委托給內部的ConsumerDelegate對象。 - CREATOR:用于創建
ConsumerDelegate的工廠。
主要構造方法
-
支持多種方式初始化 Consumer(通過 Properties、Map,及自定義反序列化器)。
-
構造過程會初始化配置、反序列化器、底層網絡客戶端等。
主要方法
- subscribe/assign/unsubscribe:主題和分區的訂閱與管理。
- poll:拉取消息的核心方法。
- commitSync/commitAsync:手動或自動提交消費位移(offset)。
- seek/seekToBeginning/seekToEnd:手動控制消費位移。
- position/committed/beginningOffsets/endOffsets:查詢當前偏移量、提交的偏移量、起始/末尾偏移量等。
- close/wakeup:關閉消費者、喚醒阻塞的 poll 等。
關鍵代碼與核心算法
2.1 訂閱與分區分配
-
subscribe(Collection<String> topics, ConsumerRebalanceListener listener)
- 通過訂閱主題,KafkaConsumer 會自動和 Broker 進行“組協調”,由服務器端分配分區。
- 可指定回調監聽分區分配及撤銷(ConsumerRebalanceListener)。
-
assign(Collection<TopicPartition> partitions)
- 手動指定消費哪些分區,此時不參與組協調(不屬于消費組)。
2.2 拉取消息
- poll(Duration timeout)
- 這是消息獲取的核心方法。內部流程大致是:
- 檢查當前分區分配、偏移量狀態,自動心跳維護。
- 向 Broker 發送 Fetch 請求,獲取分配分區的消息數據。
- 更新本地偏移量、緩存消息,返回給用戶。
- 處理組再均衡及回調。
poll同時承擔了心跳(維持消費組成員關系)、數據拉取、再均衡等多項職責。
- 這是消息獲取的核心方法。內部流程大致是:
2.3 偏移量管理
-
commitSync/commitAsync
- 將消費到的 offset 提交到 Kafka 的 __consumer_offsets 主題。
- commitSync 為同步,commitAsync 為異步,有回調。
-
offsetsForTimes、seek、position、committed
- 提供了豐富的偏移量控制與查詢能力。比如按時間查 offset、手動指定 offset、獲取當前 offset、已提交 offset 等。
2.4 消費組與再均衡
- KafkaConsumer 通過 group.id 配置參與消費組。
- 在訂閱/拉取數據時自動和 Broker 協作,進行分區分配(GroupCoordinator/PartitionAssignor)。
- 當消費組成員變動(增減、訂閱主題變更、分區數變更等)時,自動觸發 group rebalance。
核心數據結構
3.1 SubscriptionState
-
跟蹤當前訂閱主題、分區、偏移量等。
3.2 ConsumerConfig
-
消費者的配置參數。
3.3 ConsumerRecords、ConsumerRecord
-
消費到的數據結構(批量和單條消息)。
3.4 TopicPartition
-
主題 + 分區的封裝對象。
3.5 OffsetAndMetadata
- 偏移量及其元數據,用于提交/查詢 offset。
與 Broker 的交互流程
-
啟動/訂閱
- consumer 通過 group.id 加入消費組,向 Broker 發送 JoinGroup 請求。
- Broker 分配分區,返回 Assignment。
- consumer 通過 Fetch 請求拉取分配到的分區數據。
-
心跳與再均衡
- consumer 定期發送心跳(Heartbeat)給 Broker,維持消費組成員關系。
- 發生成員變更時,Broker 發起再均衡,consumer 收到分區分配變化的通知。
-
拉取消息
- consumer 向分區主副本 broker 發送 Fetch 請求,拉取新消息。
-
提交偏移量
- consumer 通過 OffsetCommit 請求,將消費進度(offset)提交到 __consumer_offsets 主題。
- 下次重啟或再均衡后,會以 committed offset 作為消費起點。
消費組(Consumer Group)機制與關聯
- 消費組:同一個 group.id 的多個消費者共同組成消費組。
- 一個分區只能被一個消費組內的 consumer 消費。
- 消費組間互不影響,可以實現廣播(多個 group 消費同一 topic)。
- 分區分配算法:Kafka 內置多種分配策略(如 RangeAssignor、RoundRobinAssignor),也支持自定義。
- 組協調器(GroupCoordinator):消費組內所有成員和 broker 的協調節點,負責分配分區和管理組成員狀態。
- 組再均衡:消費組成員變動(上線、下線、訂閱變更)時,broker 會觸發 rebalance,重新分配分區。
總結
KafkaConsumer封裝了和 Kafka broker 的全部交互,包括組管理、分區分配、消息拉取、偏移量提交等。- 關鍵流程:訂閱分區 → 拉取消息 → 提交偏移量 → 處理再均衡。
- 數據結構如 TopicPartition、OffsetAndMetadata 貫穿分區與 offset 的管理。
- 消費組機制保證了分布式消費的高可用、橫向擴展性和容錯。
網絡連接分析
1. 消費組與 Broker 的連接與交互
1.1 消費組與 Broker 的網絡連接
- KafkaConsumer 實際的網絡連接是通過底層的
KafkaClient(如NetworkClient)實現的。 - 每一個 KafkaConsumer 對象會維護一組 TCP 連接,這些連接包括:
- 與每個被消費分區的 leader broker 的連接:用于拉取數據(Fetch)。
- 與 GroupCoordinator(消費組協調者)的連接:用于管理 group membership、分區再均衡、offset 提交等。
KafkaConsumer→ConsumerDelegate→KafkaConsumerDelegate→KafkaClient(通常是NetworkClient)- 構造器中初始化 client
連接建立流程
- 啟動時,通過
bootstrap.servers配置連接部分 broker,自動發現集群。 - 加入消費組時,向 GroupCoordinator 發送 JoinGroup、SyncGroup、Heartbeat 等請求,維持“組”狀態。
2. 拉取數據的批量處理機制
拉取數據不是“一條一條”
- KafkaConsumer 一次 poll 拉取的是一批 record,而非單個。
- 批量拉取由參數控制:
fetch.min.bytes:每次最少拉取的字節數fetch.max.bytes:單次最大拉取的字節數max.poll.records:每次 poll 返回的最大消息數
這樣做的原因:
- 批量拉取能極大提升吞吐量,減少網絡和序列化開銷。
- 只有在消息極少/網絡慢時,才可能一次只拉一個 record,實際場景幾乎不會。
關鍵源碼位置
- 拉取主邏輯在
KafkaConsumer.poll(),內部委托到ConsumerNetworkClient→NetworkClient。 - 數據結構:
ConsumerRecords<K, V>(批量記錄集合) - 相關參數解析見 KafkaConsumerConfig
數據拉取的底層流程
- poll() 方法被調用
- 根據分區分配情況,構造 FetchRequest
- 通過
NetworkClient向每個 leader broker 發送 FetchRequest - Broker 返回批量數據
- 反序列化為
ConsumerRecords<K, V>,返回給用戶
關鍵代碼入口
KafkaConsumer.poll()ConsumerDelegate.poll()Fetcher.fetchRecords()- 底層 socket 通信:
NetworkClient.send()
3. 多線程實現與線程安全
KafkaConsumer 并不是多線程的
- 它本身不是線程安全的,所有方法必須在同一個線程中調用,除了
wakeup()。 - 官方建議:一個線程一個 Consumer 實例,或者用單線程 poll,其他線程異步處理數據。
源碼注釋說明
-
KafkaConsumer.java 注釋:“The consumer is not thread-safe...”
多線程架構推薦
- 如果需要多線程消費,加一層 queue,把消息分發到多個工作線程,由 poll 線程專門負責與 broker 通信。
4. 復雜和有意思的實現分析
4.1 消費組協調與再均衡
- 消費組成員通過心跳(Heartbeat)、JoinGroup、SyncGroup 維護 membership。
- 分區分配算法在
ConsumerPartitionAssignor中實現(Range, RoundRobin, Sticky 等)。 - 再均衡期間,consumer 會暫停拉取、等待新分配。
代碼位置
org.apache.kafka.clients.consumer.internals.ConsumerCoordinatororg.apache.kafka.clients.consumer.internals.ConsumerNetworkClientorg.apache.kafka.clients.consumer.internals.Fetcher
4.2 批量拉取的背后——高效網絡 IO
- Kafka 的 Fetch API 支持“多分區合并拉取”,同一臺 broker 上的多個分區會合并在一次網絡請求里。
NetworkClient負責 socket 通信,異步 IO,支持高并發。Selector(NIO)負責事件分發,提高并發和效率。
代碼位置
org.apache.kafka.clients.NetworkClientorg.apache.kafka.common.network.Selector
4.3 Offset 管理的強一致性
- Offset 提交實際上是把偏移量寫入特殊的 topic(__consumer_offsets),由 GroupCoordinator 管理。
- 消費組內 offset 的一致性和再均衡機制確保了“至少一次”語義。
5. 直接源碼定位
| 功能 | 關鍵類或方法 |
|---|---|
| 網絡連接的建立 | KafkaConsumer → ConsumerDelegate → KafkaClient (NetworkClient) |
| 消費組協調 | ConsumerCoordinator、GroupCoordinator、JoinGroup/SyncGroup |
| 消息批量拉取 | KafkaConsumer.poll()、Fetcher.fetchRecords() |
| 多線程相關說明 | KafkaConsumer 注釋、wakeup() |
| Offset 管理 | commitSync/commitAsync、OffsetCommitRequest、__consumer_offsets |
| 負載均衡與再均衡 | ConsumerPartitionAssignor、ConsumerCoordinator |
小結
- 每個 Consumer 進程會與需要的 broker 建立 TCP 連接(1個消費組協調,N個分區 leader)。
- 每次 poll 拉取的是“批量數據”,不是一條!由參數決定批量大小。
- KafkaConsumer 本身不是多線程的,多線程要用 queue 解耦。
- 復雜邏輯:消費組協調、分區分配、批量拉取、offset 強一致性,源碼分布見上表。
協作
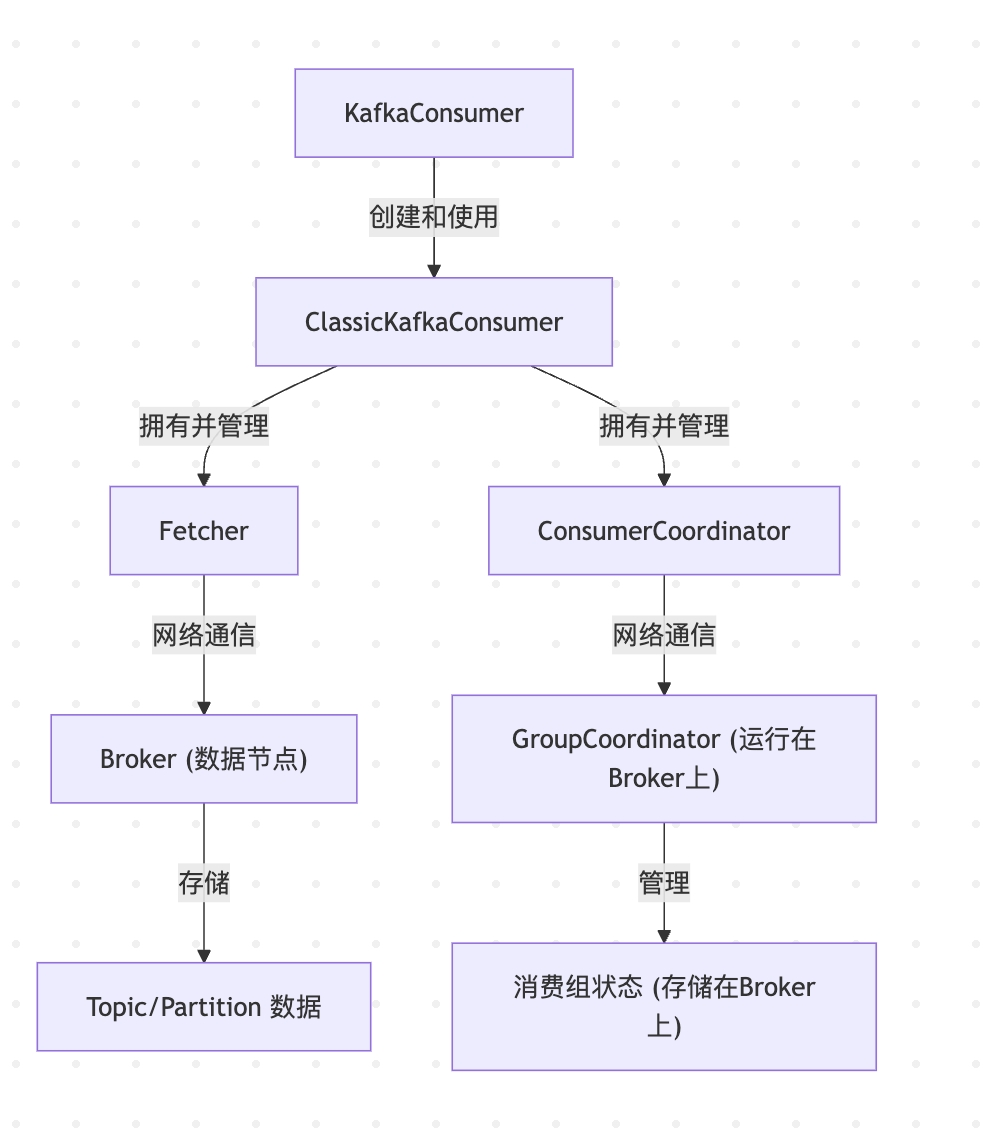
詳細說明各個組件及其關系:
-
ClassicKafkaConsumer<K, V>?(客戶端)- 角色: 這是用戶應用程序直接與之交互的 Kafka 消費者高級 API 的一個實現(遵循經典組協議)。它封裝了消費消息的整個生命周期,包括連接到 Kafka 集群、加入消費組、分配分區、拉取消息、提交位移等。
- 主要職責:
- 管理消費者的配置。
- 協調內部組件如?
Fetcher?和?ConsumerCoordinator?的工作。 - 向用戶應用程序提供?
poll()?方法來獲取消息。 - 處理用戶發起的位移提交請求。
- 管理消費者的生命周期(如?
subscribe(),?assign(),?close())。
- 與?
Fetcher?的關系:?ClassicKafkaConsumer?擁有并管理一個?Fetcher?實例。當?poll()?方法被調用時,如果需要拉取數據,ClassicKafkaConsumer?會委托?Fetcher?來執行實際的數據拉取操作。 - 與?
ConsumerCoordinator?的關系:?ClassicKafkaConsumer?擁有并管理一個?ConsumerCoordinator?實例(前提是配置了?group.id)。ConsumerCoordinator?負責所有與消費組協調相關的任務。
-
Fetcher<K, V>?(客戶端)- 角色: 負責從 Kafka Broker 拉取實際的消息數據。
- 主要職責:
- 根據當前分配給消費者的分區,構建?
FetchRequest。 - 執行請求合并: 將發往同一個 Broker 的多個分區的拉取請求合并成一個網絡請求。
- 通過?
ConsumerNetworkClient?(網絡客戶端的底層實現) 將?FetchRequest?發送給相應的 Broker。 - 接收?
FetchResponse,解析消息數據。 - 對消息進行反序列化。
- 管理拉取會話 (Fetch Session) 以優化拉取效率 (KIP-227)。
- 將拉取到的數據緩沖起來,供?
ClassicKafkaConsumer?的?poll()?方法消費。
- 根據當前分配給消費者的分區,構建?
- 與?
ClassicKafkaConsumer?的關系:?Fetcher?是?ClassicKafkaConsumer?的一個內部組件,由?ClassicKafkaConsumer?創建和控制。 - 與 Broker 的關系:?
Fetcher?直接與存儲 Topic/Partition 數據的?Broker?進行網絡通信,發送拉取請求并接收數據。
-
ConsumerCoordinator?(客戶端)- 角色: 負責代表消費者與 Kafka 集群中的?
GroupCoordinator?(運行在某個 Broker 上) 進行交互,以管理消費者在消費組中的成員資格和分區分配。 - 主要職責:
- 發現 GroupCoordinator: 找到負責當前消費組的?
GroupCoordinator?Broker。 - 加入消費組 (JoinGroup): 發送?
JoinGroupRequest?給?GroupCoordinator,表明消費者希望加入該組。 - 同步消費組 (SyncGroup): 在?
JoinGroup?成功后(通常由 leader 消費者執行),發送?SyncGroupRequest?以獲取分配給該消費者的分區列表。非 leader 消費者也發送?SyncGroupRequest?來獲取分配結果。 - 心跳 (Heartbeat): 定期向?
GroupCoordinator?發送心跳,以表明消費者仍然存活,并維持其在消費組中的成員資格以及對所分配分區的占有。 - 位移提交 (OffsetCommit): 將消費者處理過的消息的位移提交給?
GroupCoordinator?進行存儲。 - 位移拉取 (OffsetFetch): 從?
GroupCoordinator?獲取已提交的位移。 - 處理 Rebalance 相關的回調(通過?
ConsumerRebalanceListener)。
- 發現 GroupCoordinator: 找到負責當前消費組的?
- 與?
ClassicKafkaConsumer?的關系:?ConsumerCoordinator?是?ClassicKafkaConsumer?的一個內部組件,由?ClassicKafkaConsumer?創建和控制(如果配置了?group.id)。 - 與?
GroupCoordinator?(Broker 端) 的關系:?ConsumerCoordinator?通過網絡與運行在某個?Broker?上的?GroupCoordinator?服務進行通信。
- 角色: 負責代表消費者與 Kafka 集群中的?
-
GroupCoordinator?(服務端,運行在 Broker 上)- 角色: Kafka Broker 上的一個服務,負責管理一個或多個消費組。每個消費組都有一個對應的?
GroupCoordinator。 - 主要職責:
- 處理來自?
ConsumerCoordinator?(客戶端) 的請求,如?JoinGroup,?SyncGroup,?Heartbeat,?OffsetCommit,?OffsetFetch?等。 - 維護消費組的元數據,包括組成員列表、每個成員的訂閱信息、當前的分區分配方案、已提交的位移等。這些信息通常存儲在內部的?
__consumer_offsets?topic 中。 - 選舉 Leader Consumer: 在消費組內選舉一個 Leader Consumer,由 Leader Consumer 負責計算分區分配方案。
- 觸發和協調 Rebalance: 當消費組成員發生變化(加入/離開)、訂閱的 Topic 分區發生變化時,
GroupCoordinator?會啟動 Rebalance 過程。 - 存儲和管理消費位移。
- 處理來自?
- 與?
ConsumerCoordinator?(客戶端) 的關系:?GroupCoordinator?是?ConsumerCoordinator?(客戶端) 的服務端對應組件,接收并處理來自客戶端的協調請求。 - 與 Broker 的關系:?
GroupCoordinator?是?Broker?進程內的一個模塊/服務。
- 角色: Kafka Broker 上的一個服務,負責管理一個或多個消費組。每個消費組都有一個對應的?
-
Broker (服務端)
- 角色: Kafka 集群中的一個服務器節點。
- 主要職責:
- 存儲數據: 存儲 Topic 的 Partition 數據(消息日志)。
- 處理生產請求: 接收來自生產者的消息并寫入相應的 Partition。
- 處理拉取請求: 響應來自?
Fetcher?(消費者客戶端) 的數據拉取請求,從磁盤讀取消息并返回。 - 運行?
GroupCoordinator?服務: 部分 Broker 會運行?GroupCoordinator?服務來管理消費組。 - 副本管理: 參與 Partition 的副本同步和 Leader 選舉。
- 元數據管理: 維護集群元數據的一部分。
- 與?
Fetcher?的關系:?Fetcher?從 Broker 拉取消息數據。 - 與?
GroupCoordinator?的關系:?GroupCoordinator?服務運行在 Broker 內部。
Fetcher
sendFetches 實現了基本發送請求
/*** Set up a fetch request for any node that we have assigned partitions for which doesn't already have* an in-flight fetch or pending fetch data.* @return number of fetches sent*/public synchronized int sendFetches() {final Map<Node, FetchSessionHandler.FetchRequestData> fetchRequests = prepareFetchRequests();sendFetchesInternal(fetchRequests,(fetchTarget, data, clientResponse) -> {synchronized (Fetcher.this) {handleFetchSuccess(fetchTarget, data, clientResponse);}},(fetchTarget, data, error) -> {synchronized (Fetcher.this) {handleFetchFailure(fetchTarget, data, error);}});return fetchRequests.size();}總結一下合并的流程:
-
準備階段 (
prepareFetchRequests()?- 位于?AbstractFetch?類中):Fetcher?(通過繼承的?prepareFetchRequests?方法) 遍歷所有當前消費者訂閱的、并且已經分配給此消費者的、并且已經知道 leader broker 的分區。- 對于每個這樣的分區,它會確定其 leader broker (即?
Node)。 - 它將所有需要從同一個?
Node?拉取數據的分區信息收集起來,形成一個?FetchSessionHandler.FetchRequestData?對象。 - 最終,
prepareFetchRequests()?返回一個?Map<Node, FetchSessionHandler.FetchRequestData>。這個 Map 的結構本身就體現了合并:每個?Node?(Broker) 對應一個?FetchRequestData,這個?FetchRequestData?聚合了發往該 Broker 的所有分區的拉取需求。
-
發送階段 (
sendFetchesInternal()?- 位于?Fetcher?類中):sendFetchesInternal?方法接收這個?Map。- 它遍歷 Map 中的每一個?
Node?(Broker)。 - 對于每一個?
Node,它使用對應的?FetchSessionHandler.FetchRequestData?來創建一個?FetchRequest.Builder?實例。這個?Builder?會被配置為包含該?FetchRequestData?中指定的所有 TopicPartition 的拉取信息。 - 然后,為每個?
Node?發送一個(且僅一個)FetchRequest。
合并的本質是將發往同一個 Broker 的多個分區的拉取操作打包到一個網絡請求中。?這樣做的好處是:
- 減少網絡開銷: 顯著減少了客戶端和 Broker 之間的網絡往返次數。
- 提高吞吐量: Broker 可以一次性處理來自一個消費者的多個分區的請求,提高了處理效率。
- 降低延遲: 減少了等待多個獨立請求響應的時間。

![一[3]、ubuntu18.04環境 利用 yolov8 訓練開源列車數據集,并實現列車軌道檢測](http://pic.xiahunao.cn/一[3]、ubuntu18.04環境 利用 yolov8 訓練開源列車數據集,并實現列車軌道檢測)






)




—— 2. 攝像機標定)



?)

