大家讀完覺得有幫助記得關注和點贊!!!
抽象
本研究使用 COCO 圖像語料庫的三類子集探索人類動作識別,對從簡單的全連接網絡到 transformer 架構的模型進行基準測試。二進制 Vision Transformer (ViT) 實現了 90% 的平均測試準確率,明顯超過卷積網絡等多類分類器 (≈35%)和基于?CLIP 的模型 (≈62-64%)。單因素方差分析 (F=61.37,p<0.001) 證實這些差異具有統計學意義。使用 SHAP 解釋器和 LeGrad 熱圖的定性分析表明,ViT?定位姿勢特定區域(例如,walking_running的下肢),而更簡單的前饋模型通常關注背景紋理,解釋它們的錯誤。這些發現強調了變壓器表示的數據效率以及可解釋性技術在診斷特定類故障中的重要性。
姿勢問題:評估視覺轉換器和 CNN 在小 COCO 子集上的人類動作識別
1介紹
自動識別人類粗略的動作,例如坐、站和walking_unning是行為監控的一項基本任務。盡管像 MSCOCO 這樣的大規模數據集提供了多樣化的場景,但其豐富的上下文雜波也對嚴格依賴局部感受野的傳統卷積網絡提出了挑戰。最近的 transformer 架構有望更好地進行全局上下文建模,但對小的、平衡的動作子集的系統比較仍然很少。因此,我們組裝了一個 285?張圖像、標簽驗證的 COCO 子集,并對經典前饋和卷積基線、更廣義的 CNN 變體、兩個 CLIP?傳輸管道以及二進制和多類 ViT(視覺轉換器)進行了廣泛的評估。通過將交叉驗證的性能指標與統計假設檢驗和事后可解釋性工具相結合,我們不僅旨在闡明哪個模型更優越,還旨在闡明為什么某些架構在有限的數據約束下會成功或失敗。
2數據和方法說明
2.1數據
COCO 基準測試的精選子集(Lin 等人,2015),其中每個條目最初都包含許可證代碼、文件名、COCO URL、Flickr URL、捕獲日期、圖像尺寸、唯一標識符和活動標簽(坐著、站著或 walking_running)。出于態勢分類的目的,僅保留了文件名、COCO URL、高度、寬度、唯一 ID 和活動標簽;自動生成的索引、許可元數據、冗余的 Flickr URL 和捕獲日期被丟棄。圖?1?顯示了每個類別的代表性圖像。隨后的手動審計揭示了不可分類數據的情況,例如,圖?6?描繪了一個馬桶,盡管它被注釋為 “站立的”,并且在模型訓練之前刪除了所有這些噪聲樣本,以防止虛假特征關聯的傳播。

圖 1:每個類的隨機樣本
為了表征我們精選的 COCO 子集的特性,我們首先進行了探索性數據分析。如圖?2(a)?所示,walking_running (n = 98)、坐著 (n = 95) 和站立 (n = 92) 這三個類別分別相差不超過 6 個樣本,因此證明采用未加權準確性作為我們的主要評估指標是合理的,而無需重新加權或過度采樣。圖?2(b)?描繪了每張圖像的原始高度和寬度,盡管分辨率各不相同,但絕大多數圖像都聚集在 640 張圖像附近×640 像素,只有少量圖像處于較高或較低尺寸。此聚類表示將大小統一調整為 224×224px 時,特定于類的失真將可以忽略不計。最后,圖?2(c)?中的縱橫比分布在≈1.0(正方形)與次級模式一起,大約為≈1.33 (4:3) 和≈1.50 (3:2).總的來說,這些分析為預處理管道提供了原則性的基礎,該管道為下游模型提供了均衡、成分一致的輸入。

(一)標簽

(二)散布圖

(三)縱橫比
圖 2:(a) 圖像標簽的分布 (b) 按類劃分的高度與寬度散點圖 (c) 縱橫比直方圖
| 特征 | 計數 | 意味 著±性病 | 中位數 | 四分位線 | 范圍 |
|---|---|---|---|---|---|
| 寬度 | 285 | 565.74±99.17 | 640 | 480–640 | 300–640 |
| 高度 | 285 | 499.44±100.48 | 480 | 427–640 | 240–640 |
| 縱橫比 | 285 | 1.195±0.350 | 1.333 | 0.75–1.499 | 0.601–2.025 |
表 1:圖像尺寸的描述性統計量,包括標準±平均值、中位數、四分位數范圍和全范圍。
2.2模型/算法
我們評估了各種架構,包括全連接 FNN、三層 CNN 和廣義 CNN,以及兩種基于 transformer 的方法(ViT 和 CLIP 嵌入,有和沒有余弦相似性特征)。
2.2.1CNN 和 FNN
CNN 由三個卷積塊 (32→64→128 個過濾器,每個過濾器后跟 ReLU 激活和 2 個×2 max-pooling)、一個展平層、一個 256 個單位的 ReLU 激活的密集隱藏層以及 n 個類的 softmax 輸出。選擇這種設計是因為卷積層可以有效地捕獲圖像中的局部空間模式。相比之下,FNN 使 224×224×3 輸入到向量中,并將其通過兩個密集層 (128→64 單位) 在最終 softmax 之前(普里亞,2023).我們將 FNN 作為對照“僅像素”基線,以衡量 CNN 的空間歸納偏差提供了多少好處。
2.2.2CNN_gen
這種廣義 CNN 建立在我們的基礎 CNN 之上,通過結合更強的正則化和廣泛的增強來改進我們小的 MS COCO 子集的泛化。每個卷積塊 (32→64→128 個過濾器)用途L2權重衰減1e?4)和批量歸一化,然后是 ReLU 和 SpatialDropout2D(0.2),以防止過度依賴任何單個特征圖。然后,GlobalAveragePooling2D 層替換一個大型的扁平化和密集塊,以減少參數并強制執行平移不變性(Li 等人,2024).在訓練期間,我們應用了激進的增強 - 隨機旋轉 (±25°)、移位 (±20%)、切變、縮放、翻轉、亮度抖動 (0.8-1.2×) 和通道偏移 - 通過 ImageDataGenerator,有效地將我們的少數圖像擴展為更豐富、更多樣化的語料庫。
2.2.3維特
為了研究 Vision Transformers (ViT) 用于姿勢識別的泛化能力,我們微調了一個預先訓練的 ViT 模型(斯里坎特,2024)在 COCO 派生的圖像子集上,×按照Steiner 等人 (2022)并分為 80% 的訓練集、10% 的驗證集和 10% 的測試集。分類頭首先適用于二元坐walking_running任務,隨后擴展到五次獨立運行的三類坐姿、行走和跑步公式,采用具有權重衰減和提前停止的 Adam 優化器。通過利用 ViT 的自我注意機制來捕獲長期依賴關系和全局上下文,我們的目標是證明與基于卷積的替代方案相比,它在相對較小的、多樣化的圖像數據集上的卓越泛化性。
2.2.4夾
接下來,我們利用 OpenAIRadford 等人 (2021)的 CLIP 預訓練視覺編碼器作為固定特征提取器,并且僅在頂部訓練一個輕量級多層感知器。我們首先加載 openai/clip-vit-base-patch32 及其處理器,將每個 224×224 RGB 圖像通過 get_image_features 生成 512 維嵌入,然后將其收集到設計矩陣 X 和標簽向量 y 中。隨后,我們將數據拆分為 (80/20)% 的訓練/測試拆分,定義一個五層 MLP (512→256→128→64→num_classes) 在每個隱藏層之后應用 BatchNorm 和 Dropout,使用 Adam 和稀疏分類交叉熵對其進行編譯,并訓練最多 30 個 epoch,并根據驗證損失提前停止。之所以選擇這種方法,是因為 CLIP 的自我監督、多模態預訓練產生了語義豐富且線性可分離的圖像表示,非常適合我們的小 MS COCO 子集,而淺層 MLP 頭需要最少的數據和計算資源進行微調。
2.2.5CLIP 余弦
我們通過余弦距離特征將 CLIP 圖像嵌入的語義對齊顯式編碼到每個類標簽,從而進一步豐富了 CLIP 圖像嵌入。首先,我們使用相同的 CLIP 處理器和 get_text_features API 為每個標簽計算固定的文本嵌入。然后,對于每個圖像的 512-D 視覺嵌入,我們計算它與每個標簽嵌入的余弦相似性,從而生成一個 N 維“相似性向量”,其中 N 是類的數量。我們將這個向量連接到原始圖像嵌入,從而將特征大小加倍,并訓練一個輕量級的五層 MLP(512→256→128→64→num_classes) 在增強的表示上,再次使用批量規范化、dropout 和 Early Stopping。通過結合直接的圖像-文本對齊分數,該模型利用 CLIP 的多模態預訓練將視覺特征置于類語義中,從而提高了對 MSCOCO 子集進行微調時的線性可分離性和穩健性。
2.3實驗方法
我們在 Google Colab 中使用固定 (80/10/10)% 分層訓練/驗證/測試拆分和全局隨機種子進行所有實驗以實現可重復性。對于每種架構 - CNN 、 FNN 、 廣義 CNN 、微調 ViT 、 CLIP 嵌入 MLP 和 CLIP+余弦 MLP - 我們運行了 5 個獨立的訓練試驗(種子 42-46),提前停止 (耐心 = 5) 收斂,記錄每次運行的測試準確性,然后對每個模型的這 5 個準確性值執行單向方差分析,以比較它們的平均性能。
3結果
| 型 | 準確性 | 精度 | 召回 | F1 分數 |
|---|---|---|---|---|
| CNN_base | 0.343±0.074 | 0.300±0.157 | 0.343±0.074 | 0.261±0.107 |
| FNN_base | 0.407±0.029 | 0.501±0.100 | 0.407±0.029 | 0.366±0.042 |
| CNN_gen | 0.350±0.027 | 0.263±0.146 | 0.350±0.027 | 0.211±0.050 |
| 夾 | 0.639±0.085 | 0.742±0.037 | 0.639±0.085 | 0.606±0.115 |
| CLIP 余弦 | 0.618±0.089 | 0.743±0.028 | 0.618±0.089 | 0.576±0.126 |
| ViT 多類 | 0.572±0.064 | 0.585±0.057 | 0.572±0.064 | 0.568±0.061 |
| ViT 二進制文件 | 0.900±0.000 | 0.912±0.010 | 0.900±0.000 | 0.901±0.000 |
表 2:模型性能 (平均值性病±超過 5 次運行)
表?2?顯示了平均測試準確度、精密度、召回率和 F1 分數 (±標準差)進行 7 次獨立運行。
3.1準確性
兩個基于二進制視覺 transformer 的模型的性能大大優于所有卷積基線。ViT Binary 實現了 90% (±0.0),在運行之間表現出很好的一致性。CLIP 和 CLIP 余弦緊隨其后,平均精度為 63.9% (±8.5%)和 61.8% (±8.9%)。相比之下,CNN_base 和 CNN_gen 型號獲得 34.3% (±7.4%)和 35% (±2.7%),而FNN_base達到 40.7% (±2.9%).多類 ViT 產生中等性能,平均準確率為 57.2% (±6.4%).
3.2精度、召回率和 F1 分數
精度與精度趨勢密切相關。ViT Binary 再次以 91.2% 的精度領先 (±1%),其次是 CLIP 余弦,占 74.3% (±2.8%)和 CLIP 為 74.2% (±3.7%).FNN_base 實現了令人驚訝的 50.1% (±10%),盡管其整體準確性仍然很低。CNN_base 和 CNN_gen 兩種 CNN 模型的精度較低,分別為 30% 和 26.3%,表明誤報率較高。召回率和 F1 分數反映了類似的模式——transformer 模型在這兩個指標上都占主導地位,而密集和卷積基線則滯后。
3.3運行之間的可變性
標準差突出穩定性 - ViT Binary 的方差為零,表示在固定種子值下的確定性行為。兩種 CLIP 模型都表現出更高的可變性 (±8-9%),可能是由于隨機拆分和下游分類器訓練。CNN_gen 模型顯示準確率的可變性較低 (±2.7%),但其平均性能仍低于 CNN_base (±7.4%).這表明 CNN_gen 中額外的正則化和增強提高了一致性,但并沒有提高整體準確性。

圖 3:模型精度比較
圖?3?顯示了每個模型在五次運行中的每次運行測試準確性,證實了 ViT 二進制的完美穩定性和基于 CLIP 的分類器的可變性,以及連續運行中 CNN_base 和 CNN_gen 的性能下降漂移。
3.4統計分析
為了確認觀察到的平均檢驗準確性差異是否具有統計學意義,我們進行了單因素方差分析,比較了所有七個模型在五次運行中的準確性得分。分析結果是
| F=61.3706,p<0.001, |
表明模型的平均精度之間存在非常顯著的差異。此結果支持以下結論:至少有一個模型在具有統計意義的方式上優于其他模型。
4討論與結論
4.1可解釋的 AI
與簡單的分類器不同,神經網絡模型很復雜,這使得其預測的可解釋性極具挑戰性。了解影響每個預測的因素至關重要,即使模型獲得高準確率分數也是如此。因此,我們的研究采用了 SHAP 等可解釋性技術(Lundberg 和 Lee,2017)和 LeGrad(Bousselham 等人,2025)突出顯示驅動模型行為的輸入特征,并有助于調試由不良特征引起的錯誤預測。
如圖?7?所示,使用 LeGrad 獲得的經驗顯著性模式提供了一個明確的證據,表明我們的 ViT 動作探針將其預測建立在語義一致的姿勢特定區域。例如,使用 walking_running 標簽時,相關性始終集中在演員的下肢和近端運動線索上。相比之下,站立歸因圖傾向于垂直對齊的軀干和質心。相反,每當存在坐姿配置時,坐姿圖就會轉向長凳水平結構或受試者的彎曲臀部。此外,我們在上下文、非人類元素(例如第一行示例中的標志)上沒有發現零星的熱量,這表明模型能夠將其注意力限制在人類主體上。
使用 SHAP 將 FNN 和 CNN 分類器的 logit 分解為像素級貢獻,揭示了每種架構如何編碼姿勢語義。FNN 表現出的 SHAP 星等大約比圖?9?中觀察到的 CNN 中觀察到的急劇局部歸因小一個數量級,并且明顯更加分散。如圖?8?所示,這種色散反映了 FNN 的結構特性,其中沒有保持局部性的卷積核會稀釋任何單個像素的影響。總的來說,SHAP 分析證實,這兩個模型都依賴于語義上合理的姿勢提示,同時突出了 FNN 相對于其卷積對應物更粗糙的空間選擇性。
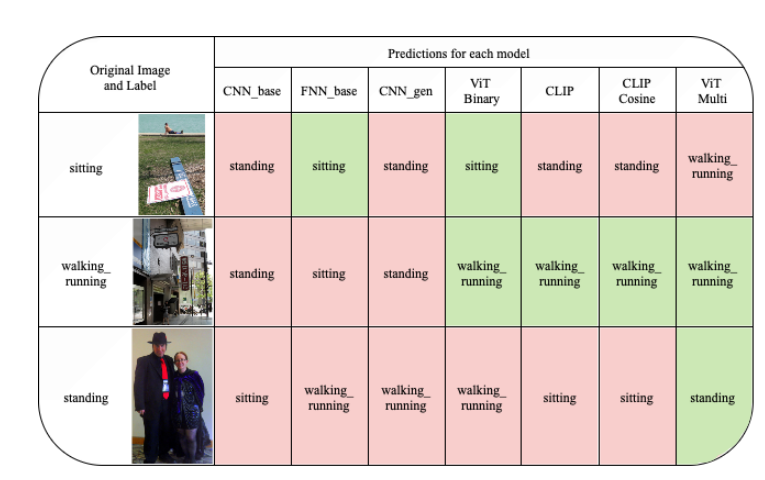
圖 4:用于誤差分析的模型預測
4.2誤差分析
為了更好地理解圖?4?所示模型中分類錯誤的原因,我們對每個動作類別(坐著、walking_running、站著)中的一個代表性示例進行了定性誤差分析。
實證評估表明,基線 CNN 和增強變體都屈服于過度擬合,主要是因為數據集尺寸過小Yamashita et al. (2018).由于獨立樣本少得多,網絡在幾個 epoch 后產生的驗證性能會停滯不前。然而,我們觀察到通過遷移學習模型實現了有意義的性能提升,因為這些模型已經在大型數據集上進行了預訓練。
盡管如此,二進制和三級性能之間的明顯差異凸顯了 Vision Transformer 傾向于描繪嚴重不同的運動模式,同時努力解決更精細的姿勢微妙之處。在二進制任務中,該模型 90.0% 的準確率證明了它能夠利用將靜止坐姿與動態步態模式分開的明顯時空線索;然而,當 “站立 ”作為一個中間類別被引入時,整體準確率下降到57.2%(±0.064),這表明與坐著和walking_running共享關鍵視覺特征的站立框架會引起混淆的自我注意激活。

圖 5:來自 “Sitting” 標簽的不良數據集注釋示例
示例圖像(圖?5)說明了注釋噪聲的典型實例,盡管主要受試者的直立姿勢表現為垂直軀干對齊。然而,該圖像仍然被錯誤地標記為“坐著”,表面上是由于背景中存在坐著的人物。這種令人困惑的注釋會破壞訓練過程中的特征-標簽映射,導致 CNN 模型內化虛假相關性,而不是真正的空間配置(布朗利,2022).因此,與更簡單的 FNN 模型相比,這些模型可能表現出較差的泛化,因為缺乏明確的空間先驗,因此不太容易受到背景驅動的標簽混淆的影響。此外,當這些嘈雜的注釋滲透到驗證集時,它們會侵蝕性能指標的有效性,從而破壞任何后續比較分析的可靠性。
4.3結論
我們的實驗表明,在二元分類設置中評估時,遷移學習轉換器,特別是以任務為中心的二元 ViT,在適度的三類 COCO 子集上提供了最先進的準確性。由于 “standing” 和 “walking_running” 之間的視覺特征相同,因此二進制模型比多職業設置有了顯著的改進。此外,基于顯著性的錯誤分析表明,這種優勢源于 ViT 能夠專注于語義相關的身體部位線索而不是偶然的風景,而 CLIP 的多模態嵌入提供了一種有競爭力但更具可變性的替代方案。相比之下,淺層或狹義正則化的 CNN 仍然容易受到背景偏差和數據稀缺的影響。未來的工作應該研究半監督增強以彌合多類 ViT 差距,結合時間上下文以進行細粒度的動作消歧,并擴展可解釋性審計以評估人口統計屬性的公平性。
)






全面解析與實踐指南)





)





