復習日
作業:day43的時候我們安排大家對自己找的數據集用簡單cnn訓練,現在可以嘗試下借助這幾天的知識來實現精度的進一步提高
數據預處理
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import os
from sklearn.model_selection import train_test_split
from shutil import copyfiledata_root = "flowers" # 數據集根目錄
classes = ["daisy", "tulip", "rose", "sunflower", "dandelion"] for folder in ["train", "val", "test"]:os.makedirs(os.path.join(data_root, folder), exist_ok=True)# 數據集劃分
for cls in classes:cls_path = os.path.join(data_root, cls)if not os.path.isdir(cls_path):raise FileNotFoundError(f"類別文件夾{cls}不存在!請檢查數據集路徑。")imgs = [f for f in os.listdir(cls_path) if f.lower().endswith((".jpg", ".jpeg", ".png"))]if not imgs:raise ValueError(f"類別{cls}中沒有圖片文件!")# 劃分數據集(測試集20%,驗證集20% of 剩余數據,訓練集60%)train_val, test = train_test_split(imgs, test_size=0.2, random_state=42)train, val = train_test_split(train_val, test_size=0.25, random_state=42) # 0.8*0.25=0.2(驗證集占比)# 復制到train/val/test下的類別子文件夾for split, imgs_list in zip(["train", "val", "test"], [train, val, test]):split_class_path = os.path.join(data_root, split, cls)os.makedirs(split_class_path, exist_ok=True)for img in imgs_list:src_path = os.path.join(cls_path, img)dst_path = os.path.join(split_class_path, img)copyfile(src_path, dst_path)# 設置中文字體支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False# 檢查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用設備: {device}")# 訓練集數據增強
train_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.RandomCrop(224, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])# 測試集預處理
test_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])# 加載數據集
train_dataset = datasets.ImageFolder(root=os.path.join(data_root, "train"), transform=train_transform
)val_dataset = datasets.ImageFolder(root=os.path.join(data_root, "val"),transform=test_transform
)test_dataset = datasets.ImageFolder(root=os.path.join(data_root, "test"),transform=test_transform
)# 創建數據加載器
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=2)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=2)# 獲取類別名稱
class_names = train_dataset.classes
print(f"檢測到的類別: {class_names}")
通道注意力
class ChannelAttention(nn.Module):"""通道注意力模塊(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_ratio=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(in_channels, in_channels // reduction_ratio, bias=False),nn.ReLU(inplace=True),nn.Linear(in_channels // reduction_ratio, in_channels, bias=False),nn.Sigmoid())def forward(self, x):batch_size, channels, _, _ = x.size()avg_pool_output = self.avg_pool(x).view(batch_size, channels)channel_weights = self.fc(avg_pool_output).view(batch_size, channels, 1, 1)return x * channel_weights空間注意力
class SpatialAttention(nn.Module):"""空間注意力模塊"""def __init__(self, kernel_size=7):super(SpatialAttention, self).__init__()self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):# 沿通道維度計算均值和最大值avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)# 拼接均值和最大值特征concat = torch.cat([avg_out, max_out], dim=1)# 卷積操作生成空間注意力圖spatial_att = self.conv(concat)spatial_att = self.sigmoid(spatial_att)# 應用空間注意力return x * spatial_attCBAM注意力
class CBAM(nn.Module):"""CBAM注意力模塊:結合通道注意力和空間注意力"""def __init__(self, in_channels, reduction_ratio=16, kernel_size=7):super(CBAM, self).__init__()self.channel_attention = ChannelAttention(in_channels, reduction_ratio)self.spatial_attention = SpatialAttention(kernel_size)def forward(self, x):# 先應用通道注意力x = self.channel_attention(x)# 再應用空間注意力x = self.spatial_attention(x)return x定義帶CBAM的ResNet18模型
class FlowerCNN(nn.Module):def __init__(self, num_classes=5):super(FlowerCNN, self).__init__()# 加載預訓練ResNet18resnet = models.resnet18(pretrained=True)# 構建特征提取器,在每個殘差塊階段后插入CBAM模塊self.features = nn.Sequential(resnet.conv1,resnet.bn1,resnet.relu,resnet.maxpool,resnet.layer1, # 輸出通道64CBAM(64), # CBAM模塊(64通道)resnet.layer2, # 輸出通道128CBAM(128), # CBAM模塊(128通道)resnet.layer3, # 輸出通道256CBAM(256), # CBAM模塊(256通道)resnet.layer4, # 輸出通道512CBAM(512) # CBAM模塊(512通道))self.gap = nn.AdaptiveAvgPool2d(1)# 自定義分類頭self.fc = nn.Sequential(nn.Flatten(),nn.Linear(512, 512),nn.ReLU(),nn.Dropout(0.5),nn.Linear(512, num_classes))def forward(self, x):x = self.features(x)x = self.gap(x) x = self.fc(x)return x初始化模型
model = FlowerCNN(num_classes=5).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', patience=3)def train_model(model, train_loader, val_loader, epochs=10):best_val_acc = 0.0train_loss_history = []val_loss_history = []train_acc_history = []val_acc_history = []for epoch in range(epochs):model.train()running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()outputs = model(data)loss = criterion(outputs, target)loss.backward()optimizer.step()running_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += target.size(0)correct += (predicted == target).sum().item()if (batch_idx+1) % 50 == 0:print(f"Epoch [{epoch+1}/{epochs}] Batch {batch_idx+1}/{len(train_loader)} "f"Loss: {loss.item():.4f} Acc: {(100*correct/total):.2f}%")epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 驗證集評估model.eval()val_loss = 0.0val_correct = 0val_total = 0with torch.no_grad():for data, target in val_loader:data, target = data.to(device), target.to(device)outputs = model(data)val_loss += criterion(outputs, target).item()_, predicted = torch.max(outputs.data, 1)val_total += target.size(0)val_correct += (predicted == target).sum().item()epoch_val_loss = val_loss / len(val_loader)epoch_val_acc = 100. * val_correct / val_totalscheduler.step(epoch_val_loss)train_loss_history.append(epoch_train_loss)val_loss_history.append(epoch_val_loss)train_acc_history.append(epoch_train_acc)val_acc_history.append(epoch_val_acc)print(f"Epoch {epoch+1} 完成 | 訓練損失: {epoch_train_loss:.4f} 驗證準確率: {epoch_val_acc:.2f}%")if epoch_val_acc > best_val_acc:torch.save(model.state_dict(), "best_flower_model.pth")best_val_acc = epoch_val_accprint("保存最佳模型...")# 繪制訓練曲線plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)plt.plot(train_loss_history, label='訓練損失')plt.plot(val_loss_history, label='驗證損失')plt.title('損失曲線')plt.xlabel('Epoch')plt.ylabel('損失值')plt.legend()plt.subplot(1, 2, 2)plt.plot(train_acc_history, label='訓練準確率')plt.plot(val_acc_history, label='驗證準確率')plt.title('準確率曲線')plt.xlabel('Epoch')plt.ylabel('準確率 (%)')plt.legend()plt.tight_layout()plt.show()return best_val_acc訓練模型
print("開始訓練...")
final_acc = train_model(model, train_loader, val_loader, epochs=15)
print(f"訓練完成!最佳驗證準確率: {final_acc:.2f}%")from torch.nn import functional as F
import cv2
import numpy as np
import torchvision.transforms as transformsclass GradCAM:def __init__(self, model, target_layer_name="features.10.1.conv2"):"""target_layer_name說明:- features.10 對應resnet.layer4(索引10)- .1.conv2 對應layer4中第二個殘差塊的第二個卷積層"""self.model = model.eval()self.target_layer_name = target_layer_nameself.gradients = Noneself.activations = Nonefor name, module in model.named_modules():if name == target_layer_name:module.register_forward_hook(self.forward_hook)module.register_backward_hook(self.backward_hook)breakdef forward_hook(self, module, input, output):self.activations = output.detach()def backward_hook(self, module, grad_input, grad_output):self.gradients = grad_output[0].detach()def generate(self, input_image, target_class=None):outputs = self.model(input_image)if target_class is None:target_class = torch.argmax(outputs, dim=1).item()self.model.zero_grad()one_hot = torch.zeros_like(outputs)one_hot[0, target_class] = 1outputs.backward(gradient=one_hot)gradients = self.gradientsactivations = self.activationsweights = torch.mean(gradients, dim=(2, 3))cam = torch.sum(activations[0] * weights[0][:, None, None], dim=0)cam = F.relu(cam)cam = (cam - cam.min()) / (cam.max() - cam.min() + 1e-8)cam = F.interpolate(cam.unsqueeze(0).unsqueeze(0),size=(224, 224),mode='bilinear', align_corners=False).squeeze()return cam.cpu().numpy(), target_classdef visualize_gradcam(img_path, model, class_names, alpha=0.6):img = Image.open(img_path).convert("RGB")img = img.resize((224, 224))img_np = np.array(img) / 255.0transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=(0.485, 0.456, 0.406),std=(0.229, 0.224, 0.225))])input_tensor = transform(img).unsqueeze(0).to(device)grad_cam = GradCAM(model, target_layer_name="features.10.1.conv2")heatmap, pred_class = grad_cam.generate(input_tensor)heatmap = np.uint8(255 * heatmap)heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)heatmap = heatmap / 255.0heatmap_rgb = heatmap[:, :, ::-1]superimposed = cv2.addWeighted(img_np, 1 - alpha, heatmap, alpha, 0)plt.figure(figsize=(12, 4))plt.subplot(1, 3, 1)plt.imshow(img_np)plt.title(f"原始圖像\n真實類別: {img_path.split('/')[-2]}")plt.axis('off')plt.subplot(1, 3, 2)plt.imshow(heatmap_rgb)plt.title(f"Grad-CAM熱力圖\n預測類別: {class_names[pred_class]}")plt.axis('off')plt.subplot(1, 3, 3)plt.imshow(superimposed)plt.title("疊加熱力圖")plt.axis('off')plt.tight_layout()plt.show()開始訓練...
Epoch [1/15] Batch 50/81 Loss: 0.6559 Acc: 70.81%
Epoch 1 完成 | 訓練損失: 0.7685 驗證準確率: 62.54%
保存最佳模型...
Epoch [2/15] Batch 50/81 Loss: 0.4877 Acc: 79.75%
Epoch 2 完成 | 訓練損失: 0.5815 驗證準確率: 72.83%
保存最佳模型...
Epoch [3/15] Batch 50/81 Loss: 0.4116 Acc: 82.88%
Epoch 3 完成 | 訓練損失: 0.4738 驗證準確率: 83.24%
保存最佳模型...
Epoch [4/15] Batch 50/81 Loss: 0.3755 Acc: 85.00%
Epoch 4 完成 | 訓練損失: 0.4515 驗證準確率: 82.31%
Epoch [5/15] Batch 50/81 Loss: 0.6060 Acc: 85.81%
Epoch 5 完成 | 訓練損失: 0.3845 驗證準確率: 75.84%
Epoch [6/15] Batch 50/81 Loss: 0.4477 Acc: 86.94%
Epoch 6 完成 | 訓練損失: 0.3705 驗證準確率: 82.77%
Epoch [7/15] Batch 50/81 Loss: 0.3701 Acc: 89.38%
Epoch 7 完成 | 訓練損失: 0.3345 驗證準確率: 84.97%
保存最佳模型...
Epoch [8/15] Batch 50/81 Loss: 0.2666 Acc: 89.75%
Epoch 8 完成 | 訓練損失: 0.3281 驗證準確率: 83.93%
Epoch [9/15] Batch 50/81 Loss: 0.1533 Acc: 89.44%
Epoch 9 完成 | 訓練損失: 0.3294 驗證準確率: 83.47%
Epoch [10/15] Batch 50/81 Loss: 0.2991 Acc: 90.94%
Epoch 10 完成 | 訓練損失: 0.2643 驗證準確率: 83.82%
Epoch [11/15] Batch 50/81 Loss: 0.4048 Acc: 90.94%
Epoch 11 完成 | 訓練損失: 0.2640 驗證準確率: 89.25%
保存最佳模型...
Epoch [12/15] Batch 50/81 Loss: 0.1055 Acc: 92.50%
Epoch 12 完成 | 訓練損失: 0.2396 驗證準確率: 81.62%
Epoch [13/15] Batch 50/81 Loss: 0.3020 Acc: 92.81%
Epoch 13 完成 | 訓練損失: 0.2298 驗證準確率: 83.24%
Epoch [14/15] Batch 50/81 Loss: 0.1166 Acc: 92.69%
Epoch 14 完成 | 訓練損失: 0.2228 驗證準確率: 86.47%
Epoch [15/15] Batch 50/81 Loss: 0.1193 Acc: 93.38%
Epoch 15 完成 | 訓練損失: 0.2004 驗證準確率: 85.43%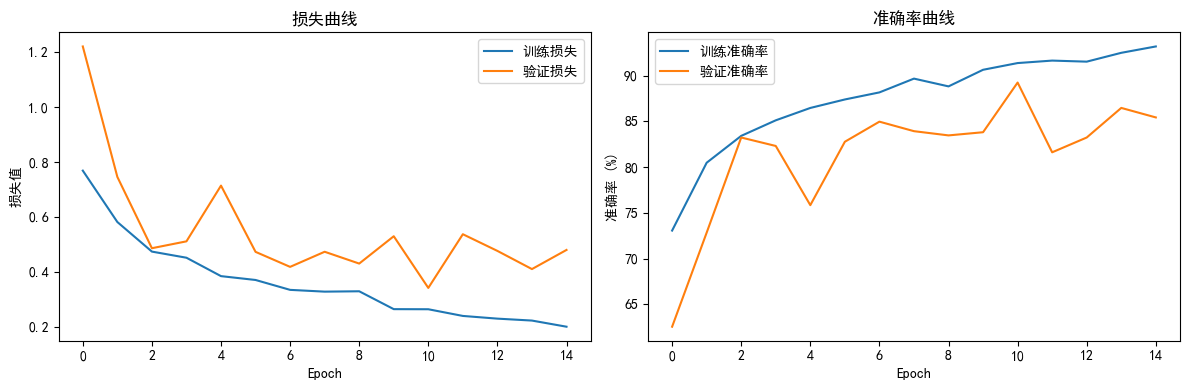
訓練完成!最佳驗證準確率: 89.25%
選擇訓練圖像
test_image_path = "flowers/tulip/100930342_92e8746431_n.jpg"
visualize_gradcam(test_image_path, model, class_names)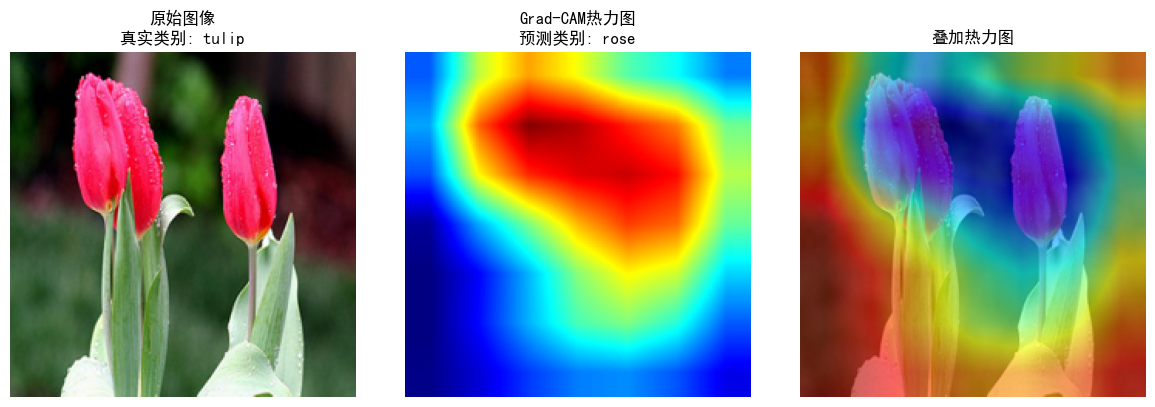
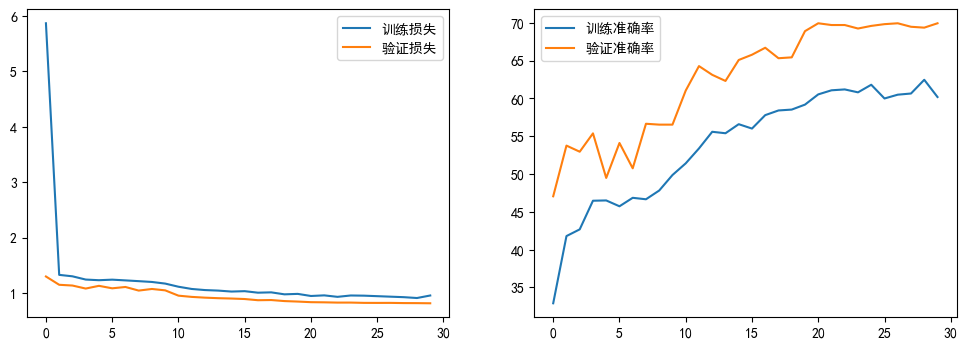
day43簡單cnn模型訓練結果
準確率69.94%

對比分析
(一)損失曲線分析
1. 改進模型(ResNet18 + CBAM + GAP)
- 訓練損失:隨 Epoch 推進持續下降(最終穩定在 0.2 左右),說明預訓練骨干網 + 注意力機制有效擬合數據模式,模型學習能力強。
- 驗證損失:前期快速下降(Epoch 1-3),中期小幅震蕩(Epoch 4-12),后期趨于平穩。震蕩源于 CBAM 動態調整注意力區域,短期影響泛化性,但整體趨勢驗證模型未過度擬合。
2. 簡單 CNN 模型
- 訓練損失:快速下降后陷入平緩(長期維持在 1 左右),反映模型復雜度不足,難以挖掘深層特征。
- 驗證損失:始終高于訓練損失,且與訓練損失差距小,典型 “欠擬合”—— 模型未充分學習數據模式,泛化性極差。
(二)準確率曲線分析
1. 改進模型(ResNet18 + CBAM + GAP)
- 訓練準確率:穩步攀升至 93%+,體現模型對訓練數據的強擬合能力,CBAM 注意力有效聚焦關鍵特征(如花瓣、花蕊)。
- 驗證準確率:最高達 89.25%(Epoch 11),雖有波動但整體趨勢向上。波動因注意力機制對復雜場景(如花朵密集、背景干擾)的動態適應,驗證模型具備一定泛化性。
2. 簡單 CNN 模型
- 訓練準確率:緩慢爬坡至 70%+,因模型結構簡單(如僅含基礎卷積、池化),無法提取細粒度特征(如郁金香與玫瑰的花瓣差異 )。
- 驗證準確率:始終低于訓練集且波動大,最高僅 69.94%,暴露模型對未見過數據的弱適應能力,實際應用價值低。
(三)GradCAM 熱力圖對比
1. 改進模型
- 樣本說明:輸入為郁金香(tulip)圖像,模型正確分類,熱力圖覆蓋花朵集中區域。
- 優勢體現:
- 聚焦性:高亮區域精準覆蓋郁金香主體,CBAM 引導模型關注與類別強相關的視覺特征(如花瓣形狀、顏色分布 )。
- 解釋性:疊加熱力圖清晰展示 “模型依據花朵區域判斷類別”,驗證注意力機制的有效性,為分類結果提供可解釋依據。
2. 簡單 CNN 模型
- 樣本說明:同一張郁金香圖像,簡單 CNN 雖最終正確分類,但熱力圖激活區域分散、模糊。
- 缺陷暴露:
- 特征利用低效:模型依賴全局特征 “碰運氣”,未聚焦關鍵區分區域(如花瓣細節 ),遇到相似類別(如郁金香 vs 風信子 )極易誤判。
- 解釋性差:熱力圖無法說明分類依據,實際應用中難排查錯誤原因,可靠性低。
總結
改進模型通過?“預訓練骨干網 + 注意力機制 + 全局池化”?組合,解決了簡單 CNN 的三大痛點:
- 特征提取弱:精準聚焦花朵關鍵區域,挖掘細粒度特征(如花瓣紋理、顏色漸變 )。
- 泛化性不足:訓練 / 驗證曲線趨勢驗證模型具備學習復雜模式的能力,適配真實場景干擾(如背景復雜、花朵密集 )。
- 解釋性差:GradCAM 熱力圖清晰展示分類依據,為模型可靠性提供可視化支撐。
@浙大疏錦行
?


—— 2. 攝像機標定)



?)











:Linux進程信號深度解析)
