文章目錄
- 使用ragas做評估
- 在自己的數據集上評估
- 完整代碼
- 代碼講解
- 1. RAG系統構建
- 核心組件初始化
- 文檔處理流程
- 2. 評估數據集構建
- 3. RAGAS評估實現
- 1. 評估數據集創建
- 2. 評估器配置
- 3. 執行評估
本系列閱讀:
理論篇:RAG評估指標,檢索指標與生成指標①
實踐篇:利用ragas在自己RAG上實現LLM評估②
首先我們可以共識LLM的評估最好/最高效的方式就是再利用LLM的強大能力,而不是用傳統指標。
假設我們不用LLM評估我們只有兩條方式可實現:
- 傳統指標,如Bleu。需輸入標準答案(通常也是人工審核答案是不是標準的,或者是人工制造標準答案),缺點是效果有限,用了都知道效果慘不忍睹。
- 純人工打分。缺點是耗時,帶有主觀性。
使用ragas做評估
推薦一個包ragas。但是它的教程文檔確實寫得不太好,可能是jupyter格式,直接在py中運行,總是會報少變量之類。我這邊都改動了下,確保我們py文件可以運行。
ragas(Retrieval Augmented Generation Assessment)是社區最著名的評估方案,內置了我們常見的評估指標。
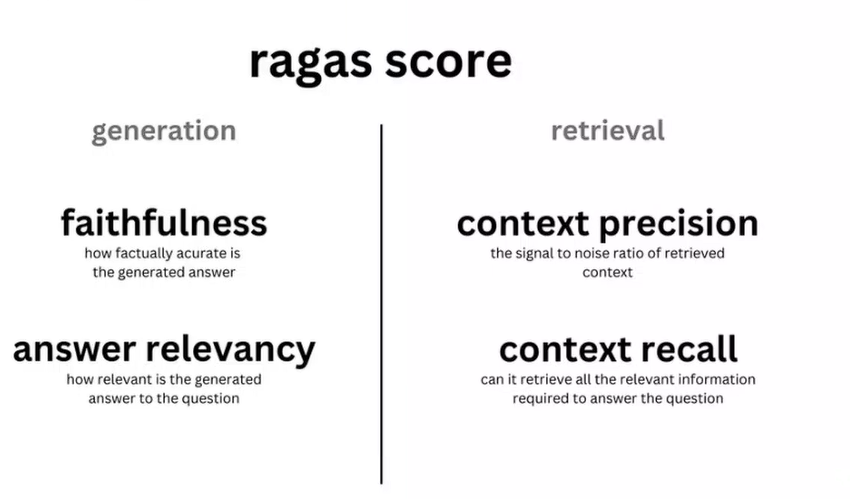
利用了LLM評估,因此不需要人工打標。其出名是因為封裝了LLM做評估,簡單易用(當然其實這些也是我們可以造輪子實現的~)。
代碼鏈接https://github.com/blackinkkkxi/RAG_langchain/blob/main/learn/evaluation/RAGAS-langchian.ipynb
在自己的數據集上評估
完整可運行的代碼見本文的完整代碼小節,代碼可運行。而1~3我們會拆開完整代碼講解,代碼主要用于講解完整代碼,可能不能運行。
完整代碼
在使用我的代碼你只需要把deepseekapi換成你自己的即可。
import os
import re
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
from langchain.chat_models import init_chat_model
from ragas import evaluate
from ragas.llms import LangchainLLMWrapper
from ragas import EvaluationDataset
from ragas.metrics import LLMContextRecall, Faithfulness, FactualCorrectnessclass RAG:def __init__(self, api_key=None):"""使用DeepSeek模型和BGE嵌入初始化RAG系統"""# 設置環境變量os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'# 初始化對話模型self.llm = init_chat_model(model="deepseek-chat",api_key=api_key,api_base="https://api.deepseek.com/",temperature=0,model_provider="deepseek",)# 初始化嵌入模型self.embedding_model = HuggingFaceEmbeddings(model_name="BAAI/bge-large-zh-v1.5")# 初始化文本分割器self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=50)# 初始化向量存儲和檢索器self.vectorstore = Noneself.retriever = Noneself.qa_chain = None# 設置提示模板self.template = """根據以下已知信息,簡潔并專業地回答用戶問題。如果無法從中得到答案,請說"我無法從已知信息中找到答案"。已知信息:{context}用戶問題:{question}回答:"""self.prompt = PromptTemplate(template=self.template,input_variables=["context", "question"])def load_documents_from_url(self, url, persist_directory="./chroma_db"):"""從網頁URL加載文檔并創建向量存儲"""# 從網頁加載文檔loader = WebBaseLoader(url)documents = loader.load()# 將文檔分割成塊chunks = self.text_splitter.split_documents(documents)# 創建向量存儲self.vectorstore = Chroma.from_documents(documents=chunks,embedding=self.embedding_model,persist_directory=persist_directory)# 創建檢索器self.retriever = self.vectorstore.as_retriever()# 創建問答鏈self.qa_chain = RetrievalQA.from_chain_type(llm=self.llm,chain_type="stuff",retriever=self.retriever,chain_type_kwargs={"prompt": self.prompt})print(f"成功從 {url} 加載并處理文檔")def ask(self, question):"""便捷的提問方法"""result = self.qa_chain.invoke({"query": question})return result["result"]def relevant_docs_with_scores(self, query, k=1):"""計算相關文檔及其相似度分數,返回處理后的文檔信息"""docs_with_scores = self.vectorstore.similarity_search_with_score(query, k=k)# 處理文檔內容processed_docs = []for i, (doc, score) in enumerate(docs_with_scores, 1):# 清理文檔內容content = doc.page_content.strip()# 去除回車符、換行符和多余的空白字符content = content.replace('\n', ' ').replace('\r', ' ').replace('\t', ' ')# 合并多個連續空格為單個空格content = re.sub(r'\s+', ' ', content)processed_docs.append({'index': i,'score': score,'content': content})return processed_docs# 使用示例
if __name__ == "__main__":api_key = "X"queries = ["為什么Transformer需要位置編碼?","QKV矩陣是怎么得到的?","注意力機制的本質是什么?","對于序列長度為n的輸入,注意力機制的計算復雜度是多少?","在注意力分數計算中,為什么要除以√d?","多頭注意力機制的主要作用是什么?","解碼器中的掩碼自注意力是為了什么?","編碼器-解碼器注意力中,Query來自哪里?","GPT系列模型使用的是哪種架構?","BERT模型適合哪類任務?"]# 初始化RAGrag = RAG(api_key)# 從URL加載文檔rag.load_documents_from_url("https://blog.csdn.net/ngadminq/article/details/147687050")expected_responses = ["Transformer的輸入是并行處理的,不像RNN有天然的序列關系,因此需要位置編碼來為模型提供詞元在序列中的位置信息,確保模型能理解詞的先后順序。","QKV矩陣通過將輸入向量分別與三個不同的權重矩陣W_q、W_k、W_v進行線性投影得到,這三個權重矩陣是模型的可學習參數,在訓練過程中不斷優化。","注意力機制的本質是為序列中的每個詞找到重要的上下文信息,通過計算詞與詞之間的相關性分數,實現對重要信息的聚焦和整合。","注意力機制的計算復雜度是O(n2),因為序列中每個詞都需要與所有其他詞計算注意力分數,形成n×n的注意力矩陣。","除以√d是為了提升訓練穩定性,防止注意力分數過大導致softmax函數進入飽和區,確保梯度能夠有效傳播。","多頭注意力機制可以從多個角度捕捉不同類型的詞間關聯,比如語義關系、句法關系等,增強了模型的表達能力和理解能力。","解碼器中的掩碼自注意力是為了防止當前位置關注未來位置的信息,確保在自回歸生成過程中每個位置只能看到當前及之前的信息。","在編碼器-解碼器注意力中,Query來自解碼器的前一層輸出,而Key和Value來自編碼器的最終輸出,這樣解碼器就能利用編碼器處理的源序列信息。","GPT系列模型使用僅解碼器架構,專門針對文本生成任務設計,通過掩碼自注意力機制實現從左到右的序列生成。","BERT模型適合分類和理解類任務,如文本分類、命名實體識別、情感分析、問答等,因為它使用雙向編碼器可以同時關注上下文信息。"]dataset = []for query, reference in zip(queries, expected_responses):# 獲取相關文檔及分數并打印relevant_docs = rag.relevant_docs_with_scores(query)relevant_docs = relevant_docs[0]['content']response = rag.ask(query)dataset.append({"user_input": query,"retrieved_contexts": [relevant_docs],"response": response,"reference": reference})evaluation_dataset = EvaluationDataset.from_list(dataset)llm = init_chat_model(model="deepseek-chat",api_key=api_key,api_base="https://api.deepseek.com/",temperature=0,model_provider="deepseek",)evaluator_llm = LangchainLLMWrapper(llm)result = evaluate(dataset=evaluation_dataset, metrics=[LLMContextRecall(), Faithfulness(), FactualCorrectness()],llm=evaluator_llm)print(result)以下是運行的結果:
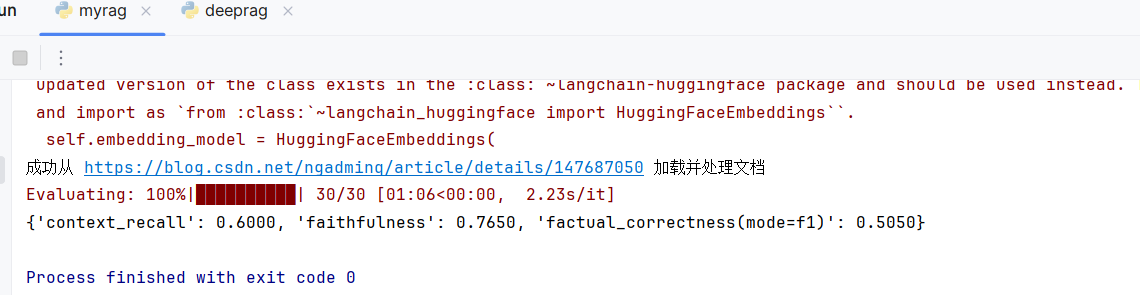
根據我們的結果指標可以針對指標有優化方向
代碼講解
1. RAG系統構建
核心組件初始化
class RAG:def __init__(self, api_key=None):# DeepSeek聊天模型self.llm = init_chat_model(model="deepseek-chat",api_key=api_key,api_base="https://api.deepseek.com/",temperature=0,model_provider="deepseek",)# BGE中文嵌入模型self.embedding_model = HuggingFaceEmbeddings(model_name="BAAI/bge-large-zh-v1.5")# 文本分割器self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=50)
技術要點:
- 使用DeepSeek作為生成模型,temperature=0確保輸出穩定性
- BGE-large-zh-v1.5是目前中文嵌入效果較好的開源模型
- 文本分塊策略:500字符塊大小,50字符重疊防止信息丟失
文檔處理流程
def load_documents_from_url(self, url, persist_directory="./chroma_db"):# 1. 網頁內容加載loader = WebBaseLoader(url)documents = loader.load()# 2. 文檔分塊chunks = self.text_splitter.split_documents(documents)# 3. 向量化存儲self.vectorstore = Chroma.from_documents(documents=chunks,embedding=self.embedding_model,persist_directory=persist_directory)# 4. 構建檢索鏈self.qa_chain = RetrievalQA.from_chain_type(llm=self.llm,chain_type="stuff",retriever=self.retriever,chain_type_kwargs={"prompt": self.prompt})
2. 評估數據集構建
數據集需要包含四個核心要求
dataset.append({"user_input": str, # 用戶查詢,即我們備好的一系列問題"retrieved_contexts": [str,str], # 檢索到的上下文,list格式"response": str, # 系統回答"reference": str # 標準答案,人工制造,我這里使用cluade生成的
})
3. RAGAS評估實現
1. 評估數據集創建
from ragas import EvaluationDataset
evaluation_dataset = EvaluationDataset.from_list(dataset)
2. 評估器配置
from ragas.llms import LangchainLLMWrapper
evaluator_llm = LangchainLLMWrapper(llm)
關鍵點: RAGAS使用LLM作為評估器,需要將LangChain模型包裝成RAGAS兼容格式
3. 執行評估
代碼使用了三個核心評估指標:
LLMContextRecall(上下文召回率)
- 作用: 評估檢索到的上下文是否包含回答問題所需的信息
- 計算方式: 通過LLM判斷標準答案中的信息有多少能在檢索上下文中找到
- 公式: Context Recall = 可在上下文中找到的標準答案句子數 / 標準答案總句子數
Faithfulness(忠實度)
- 作用: 衡量生成回答與檢索上下文的一致性,防止幻覺
- 計算方式: 檢查回答中的每個聲明是否能在提供的上下文中得到支持
- 公式: Faithfulness = 有上下文支持的聲明數 / 總聲明數
FactualCorrectness(事實正確性)
- 作用: 評估生成回答的事實準確性
- 計算方式: 將生成回答與標準答案進行事實層面的比較
- 評估維度: 包括事實的正確性、完整性和相關性
from ragas.metrics import LLMContextRecall, Faithfulness, FactualCorrectnessresult = evaluate(dataset=evaluation_dataset, metrics=[LLMContextRecall(), Faithfulness(), FactualCorrectness()],llm=evaluator_llm
)

)




)





用法詳解)
詳解文檔)

Win系統如何將Redis配置為開機自啟的服務)



結構體的進階應用)