消費者
Kafka消費方式:采用pull(拉)的方式,消費者從broker中主動拉去數據。使用pull的好處就是消費者可以根據自身需求,進行拉取數據,但是壞處就是如果Kafka沒有數據,那么消費者可能會陷入循環中,一直返回空數據。
消費者與消費者之間是獨立的,一個消費者可以消費多個分區數據。但是消費組不同,每個分區的數據只能由消費者組中的一個消費者消費,避免重復消費導致數據重復。
消費者組:
- 消費者組由多個consumer組成,形成一個消費者組的條件,是所有消費者的groupid相同。消費者組內每個消費者負責消費不同分區的數據,一個分區只能由一個組內消費者消費。
- 消費者組之間互不影響,所有的消費者都屬于某個消費者組,即消費者組是邏輯上的一個訂閱者。
消費者組初始化流程:
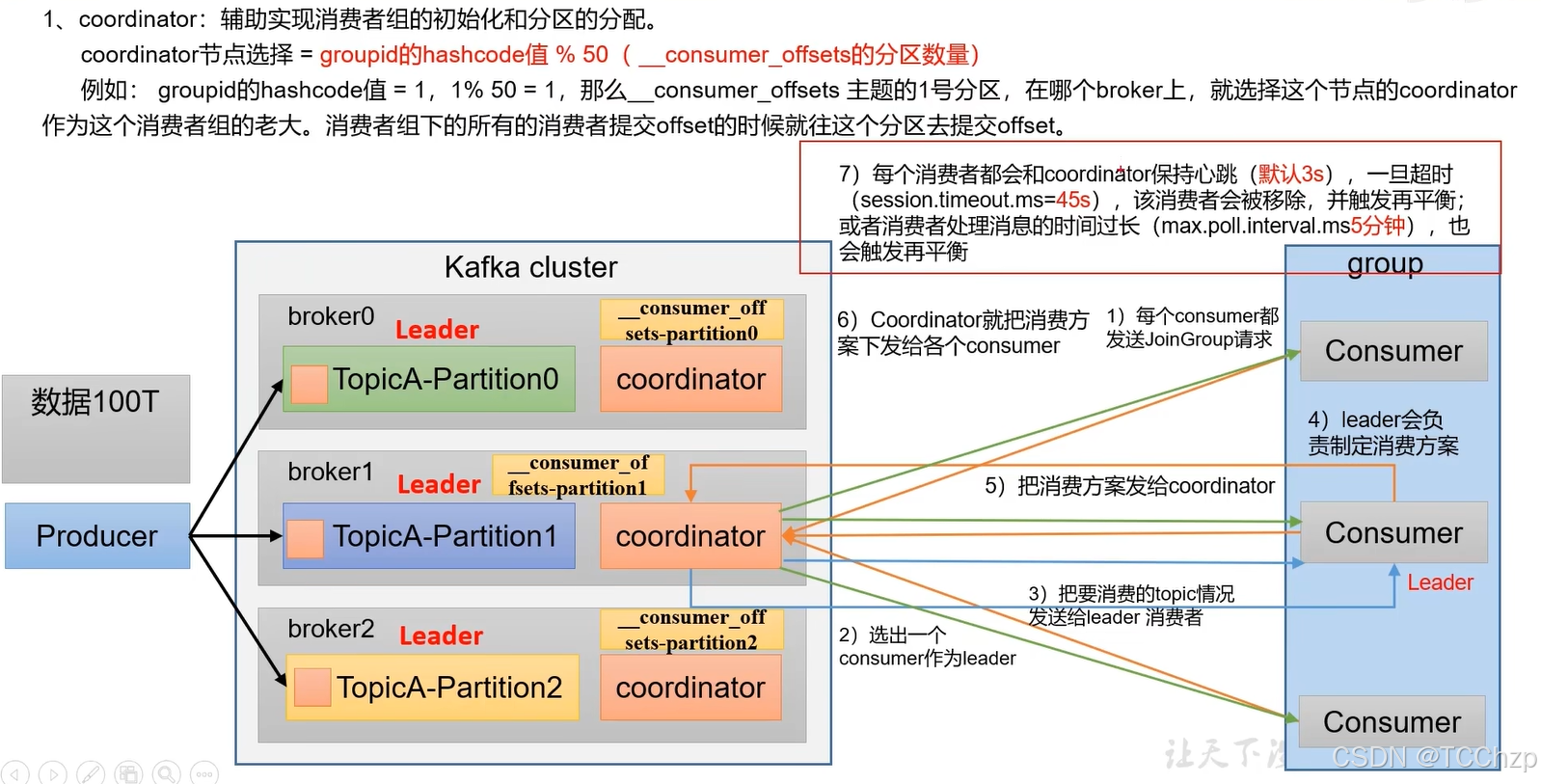
消費者組詳細消費流程
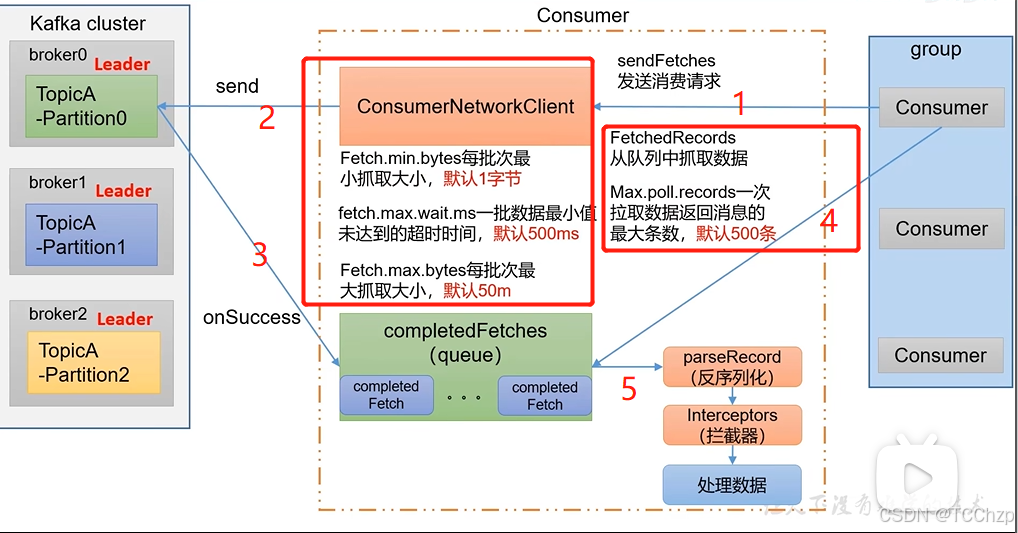
Java創建消費者
注意:在消費者API代碼中必須配置消費者組id。命令行啟動消費者不需要填寫是因為id被自動填寫為隨機的消費者組id。
通過API消費一個主題的數據
//配置Properties properties = new Properties();//連接集群properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.27.101:9092,192.168.27.102:9092");//反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());//消費者組idproperties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");//1.創建一個消費者KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);//2.定義主題ArrayList<String> topics = new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);//3.消費數據while (true){//拉取的間隔時間ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> record : records) {System.out.println(record);}}
消費者消費指定分區
需要指定分區只需要在定義主題時,使用定義主題以及分區方法
//2.定義主題以及分區ArrayList<TopicPartition> topicPartitions = new ArrayList<>();topicPartitions.add(new TopicPartition("first",0));kafkaConsumer.assign(topicPartitions);
消費者組案例
創建三個消費者,進行消費不同分區
直接復制上面消費主題的代碼,因為設置的groupid都是test,因此會自動成為一個消費者組。運行消費者組test內的三個消費者,然后運行生產者對每個分區進行發送消息,可以看到每個消費者都只消費了一個分區的消息。
注意:消費者組內的消費者在底層進行了編號,跟java類取名無關。
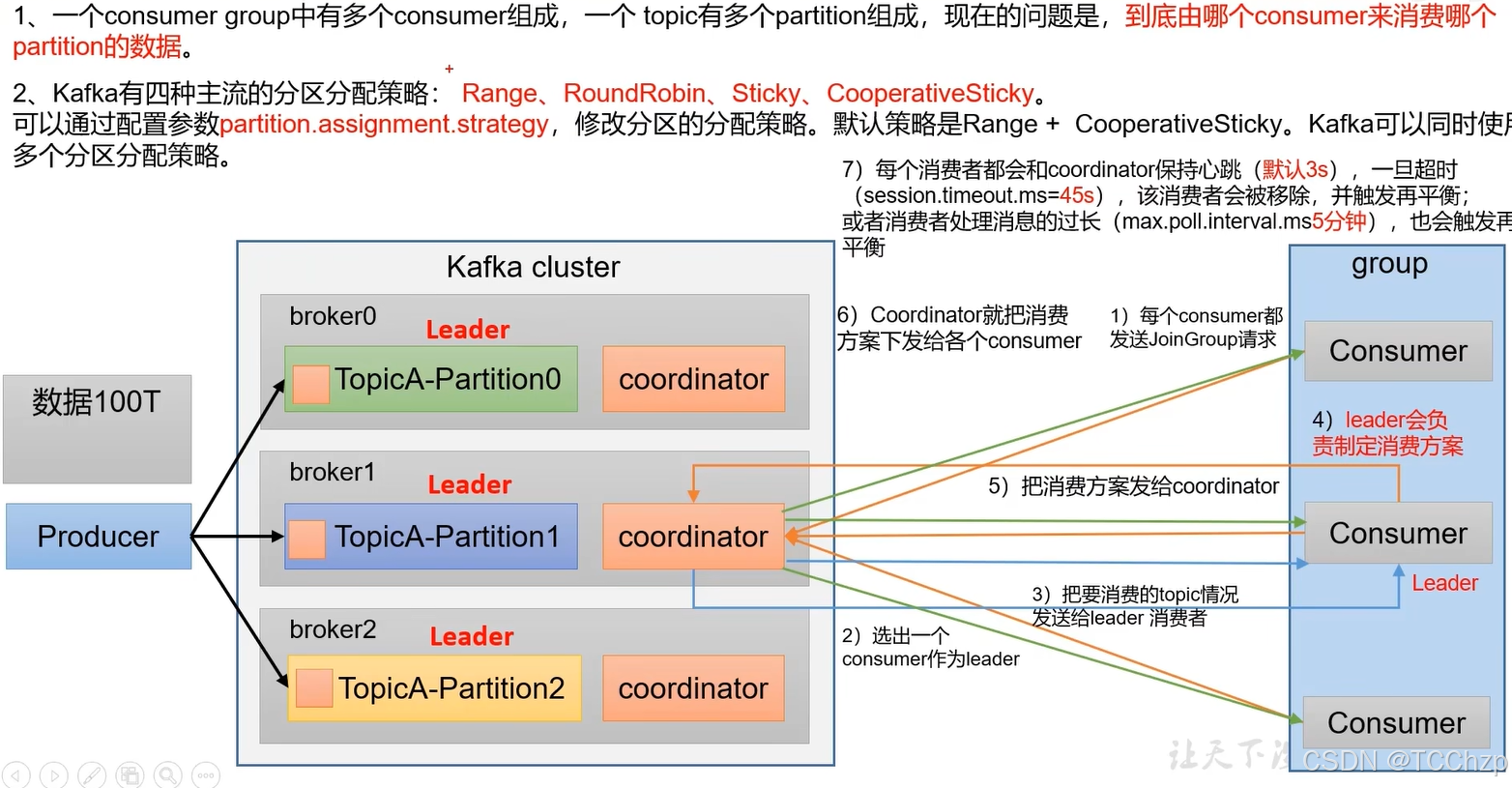
分區的分配以及再平衡
消費者組有多個消費者,而一個topic又有多個分區,那么應該由哪個消費者消費哪個分區呢?
Kafka有三種主流的分區分配策略,可以通過配置參數partiton.assignment.strategy修改分配策略,默認的策略是Range+CooperativeSticky。Kafka可以同時使用多個分區分配策略。
//設置分區分配策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.RoundRobinAssignor");
再平衡:相當于原有分區的消費者突然發送意外,不能再進行消費,重新分配該分區給其他消費者;或者消費者組中新增了消費組,需要重新分配分區。
-
Range
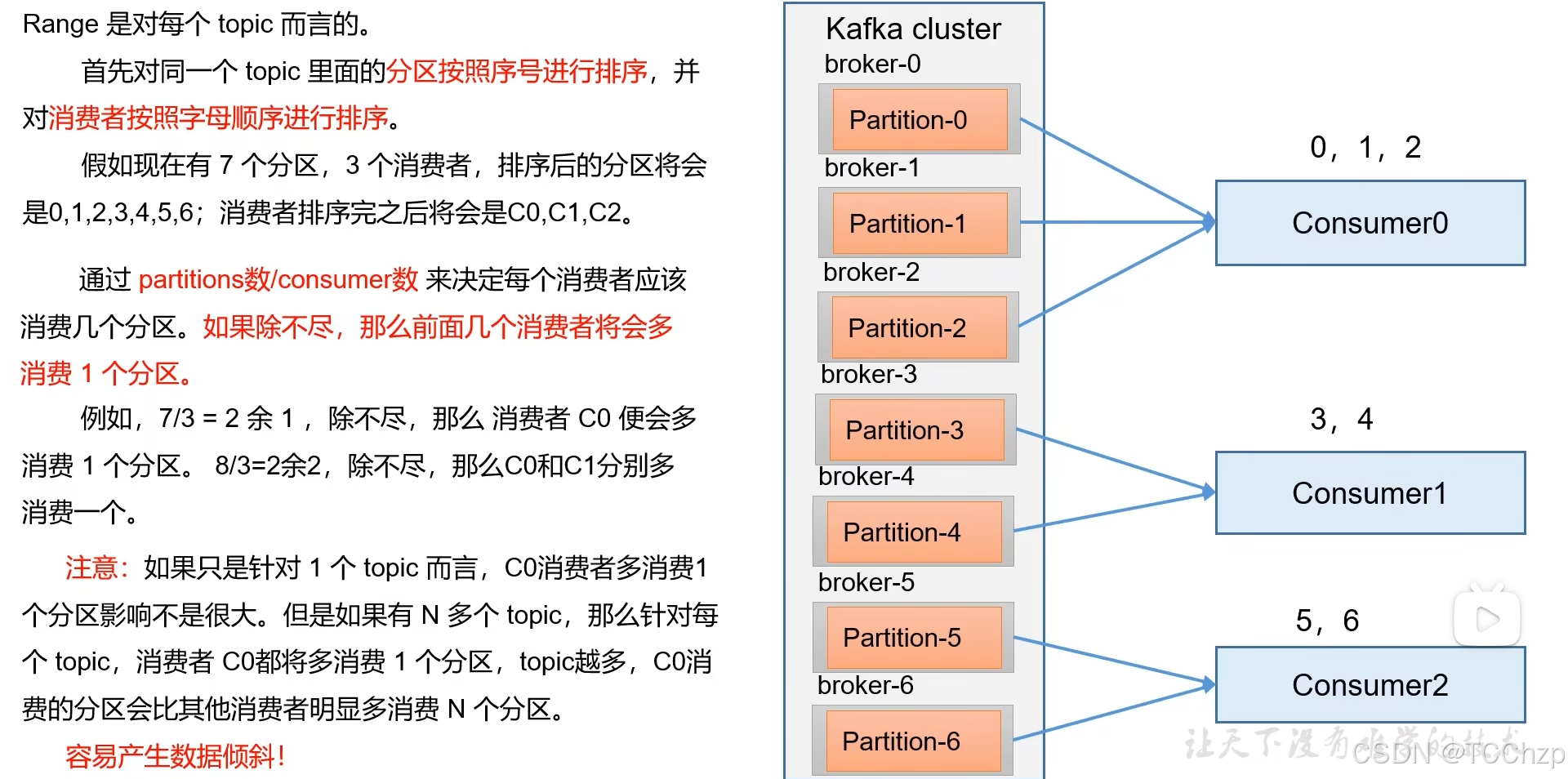
Range的再平衡,會將原消費者負責的分區一次性全部交給剩下的某一個消費者
-
RoundRobin
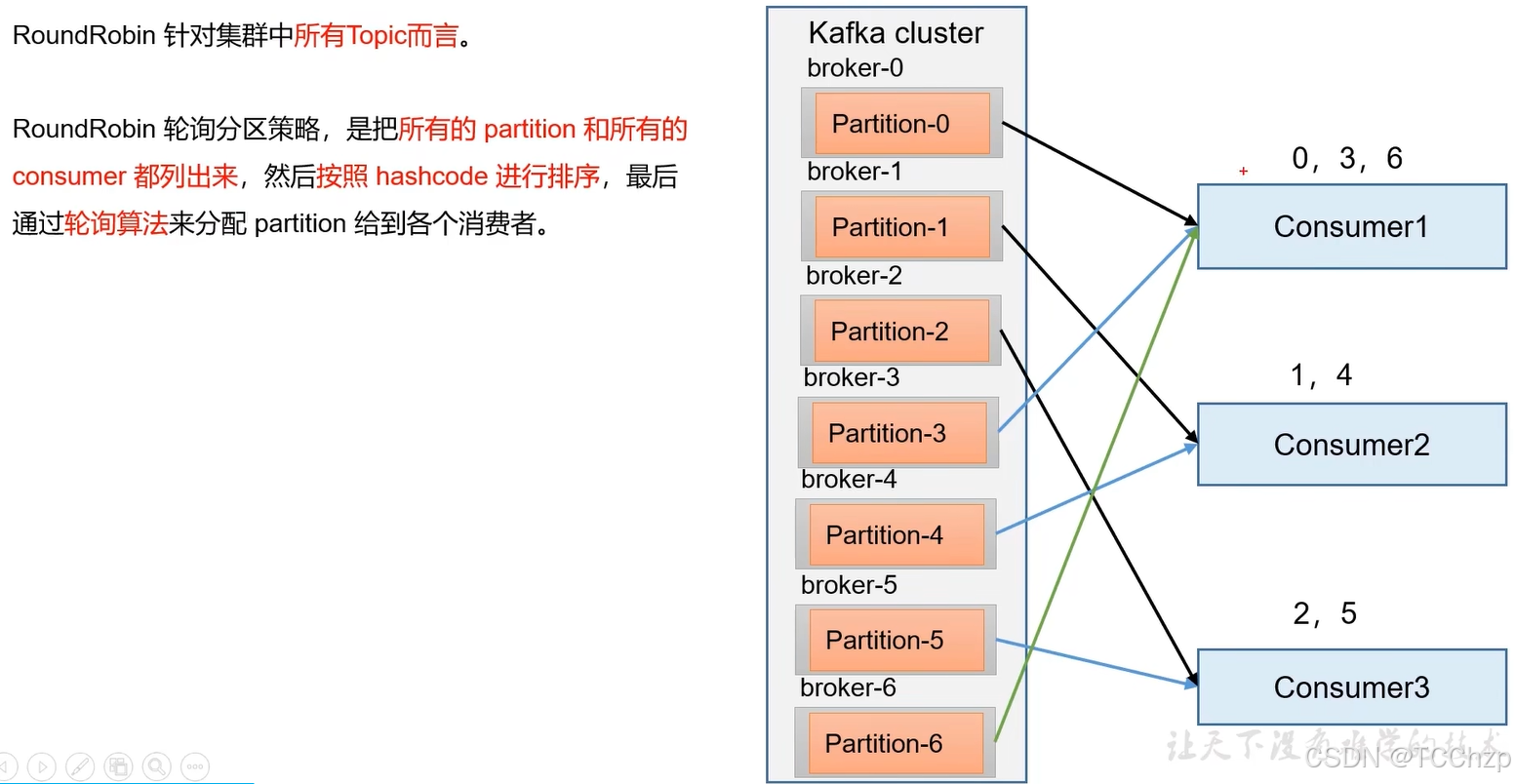
當觸發再分配時,會將原消費者負責的分區按照RoundRobin一樣進行重新分發
-
Sticky
Sticky也是針對所有topic的策略,黏性分區是一種均勻隨機的分配策略,會在執行一次新的分配之前,考慮上一次的分配結果,盡量少的調整分配的變動,可以節省開銷。首先會盡量均衡的分配分區給消費者,在同一組內的消費者出現問題,也會盡量保持原有分配的分區不發送變化。但是在發生再平衡時,所有的消費者需要先放棄當前持有的分區資源,等待重新分配。
-
CooperativeSticky
CooperativeSticky是2.4版本新增的策略,在原有Sticky策略上,將原本大規模的再平衡操作,拆分成了多次小規模的再平衡,直到平衡完成。
Offset位移
offset的默認維護位置
Offset,消息位移,它表示分區中每條消息的位置信息,是一個單調遞增且不變的值。換句話說,offset可以用來唯一的標識分區中每一條記錄。消費者消費完一條消息記錄之后,需要提交offset來告訴Kafka Broker自己消費到哪里了。
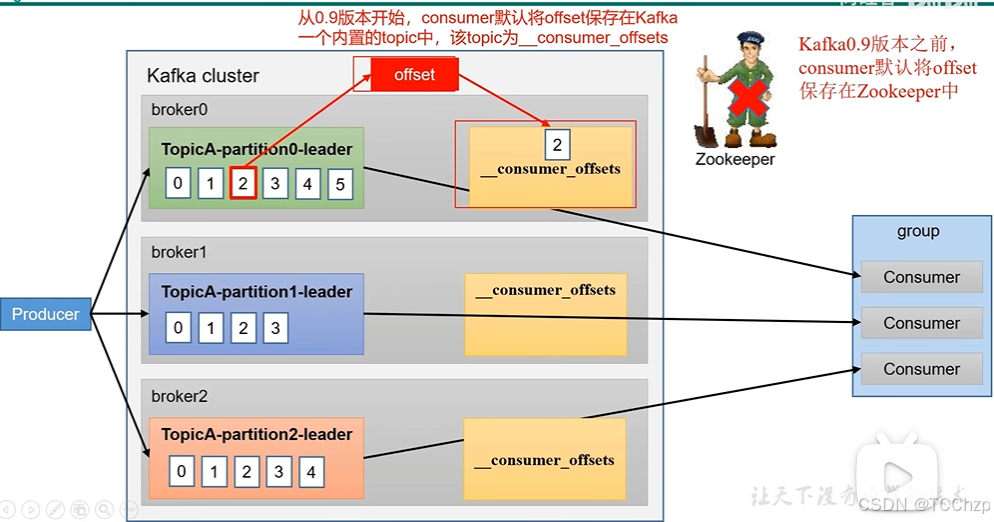
_consumer_offsets主題采用key和value的方式存儲數據,key是group.id+topic+分區號,value就是當前offset的值,每隔一段時間,kafka內部會對這個topic進行compact,也就是每個key都保留最新數據。
默認情況下,是不允許查看消費系統主題數據的,如果需要查看該系統主題數據,要設置config/consumer.properties中添加配置exclude.internal.topics=false。默認是true,表示不能看系統相關信息。
自動提交offset
為了讓用戶更專注于自己的業務邏輯,Kafka提供了自動提交offset的功能,一段時間后自動提交offset。相關參數:
enable.auto.commit 是否開啟自動提交offset功能,默認為true
auto.commmit.intervalms 自動提交offset分時間間隔,默認是5s。
//自動提交properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);//提交時間間隔properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,1000);
手動提交offset
自動提交是基于時間提交,開發人員很難把握提交的時機,因此Kafka還提供了手動提交offset的API。
//設置手動提交(關閉自動)properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
手動提交分為同步提交和異步提交。兩者的共同點是都會將本次提交的一批數據最高的偏移量提交,不同的是同步提交阻塞當前線程,一直到提交成功,并且會自動失敗重試,而異步提交則沒有失敗重試機制,所有有可能提交失敗。
同步提交:必須等待offset提交完畢,再去消費下一批數據。
//手動提交(同步)kafkaConsumer.commitSync();
異步提交:發送完offset請求后,就開始消費下一批數據了。
//手動提交(異步)kafkaConsumer.commitAsync();
指定Offset消費
//指定位置進行消費,先獲取分區信息Set<TopicPartition> assignment = kafkaConsumer.assignment();//保證分區分配方案已經指定完畢,剛訂閱主題時不能立即獲取到分區信息while (assignment.size()==0){kafkaConsumer.poll(Duration.ofSeconds(1));assignment = kafkaConsumer.assignment();}for (TopicPartition topicPartition : assignment) {// 分區 指定offsetkafkaConsumer.seek(topicPartition,100);}
指定時間消費
//指定位置進行消費,先獲取分區信息Set<TopicPartition> assignment = kafkaConsumer.assignment();//保證分區分配方案已經指定完畢,剛訂閱主題時不能立即獲取到分區信息while (assignment.size()==0){kafkaConsumer.poll(Duration.ofSeconds(1));assignment = kafkaConsumer.assignment();}HashMap<TopicPartition, Long> topicPartitionLongHashMap = new HashMap<>();for (TopicPartition topicPartition : assignment) {//如果希望是一天前的當前時刻,那么就用當前時間減去一天間隔,單位為mstopicPartitionLongHashMap.put(topicPartition,System.currentTimeMillis()- 1 * 24 * 3600 * 1000);}//將時間轉換為對應的offsetMap<TopicPartition, OffsetAndTimestamp> topicPartitionOffsetAndTimestampMap = kafkaConsumer.offsetsForTimes(topicPartitionLongHashMap);for (TopicPartition topicPartition : assignment) {OffsetAndTimestamp offsetAndTimestamp = topicPartitionOffsetAndTimestampMap.get(topicPartition);kafkaConsumer.seek(topicPartition,offsetAndTimestamp.offset());}
消費者事務
在消費者消費的過程中會遇到重復消費和漏消費的情況發生。
漏消費:先提交offset后進行消費,有可能造成數據的漏消費
重復消費:已經消費數據,但是offset沒有提交
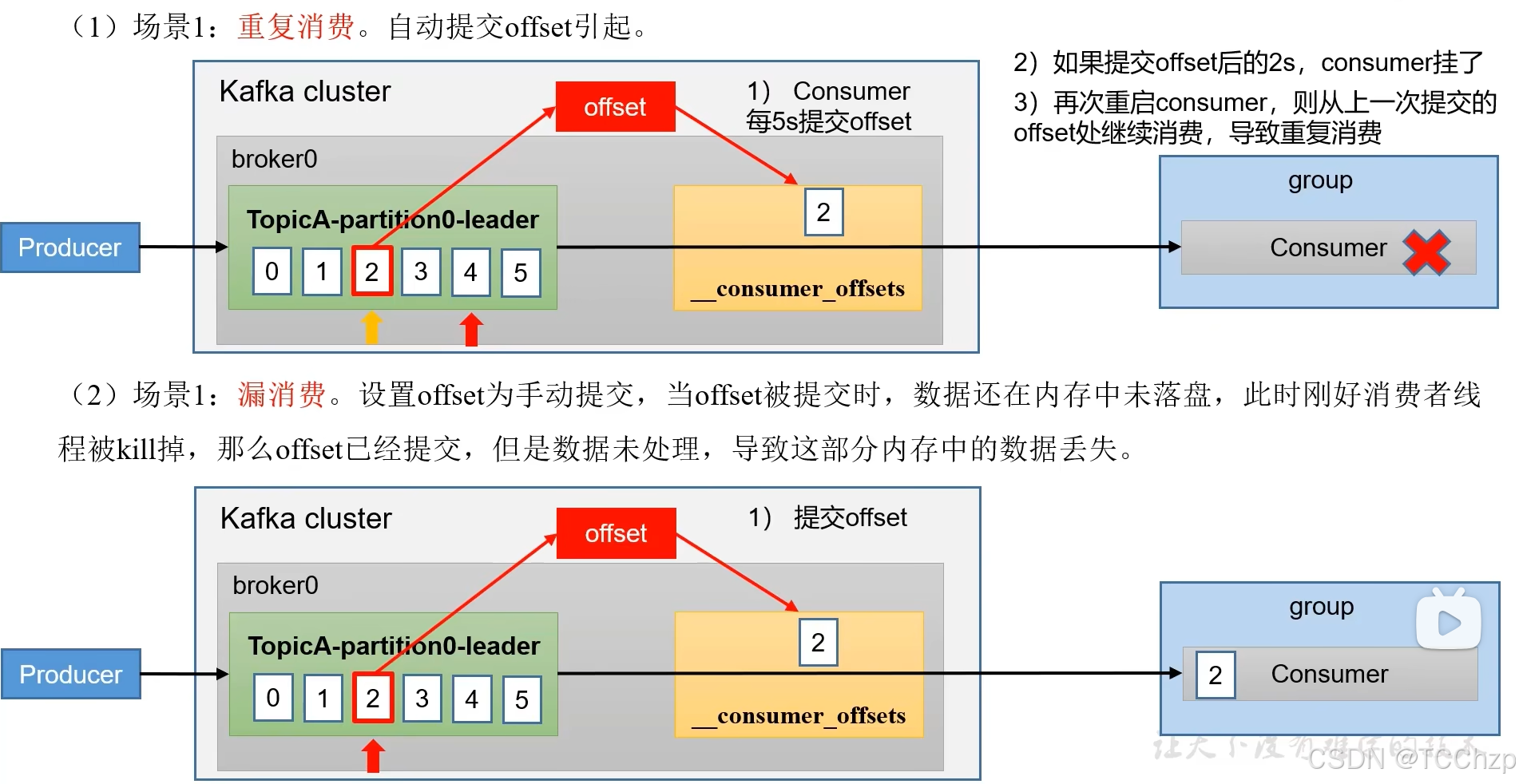
如果想精準的進行一次性消費,那么需要Kafka消費端將消費過程和提交offset過程做原子綁定。可以將Kafka的offset保存到支持事務的工具中。(比如MySQL)
數據積壓
默認日志存儲時間為7天,如果當消費速度低于消息的發送速度,那么就很可能造成數據積壓。
如果Kafka消費能力不足,那么可以增加Topic的分區數,并且同時提升消費者組的消費者數量,消費者數=分區數。
如果下游數據處理不及時,那么提高每批次拉取的數據量。批次拉取數據過少,使得處理的數據小于生產的數據,也會造成數據積壓。



![[10-2]MPU6050簡介 江協科技學習筆記(22個知識點)](http://pic.xiahunao.cn/[10-2]MPU6050簡介 江協科技學習筆記(22個知識點))


)









函數meanShiftProc())


)