Redis是以鍵值對進行數據存儲的,添加數據和查找數據最常用的2個指令就是set和get。
- set:set指令用來添加數據。把key和value存儲進去。
- get:get指令用來查找相應的鍵所對應的值。根據key來取value。
首先,我們先進入到redis客戶端。然后使用set和get。
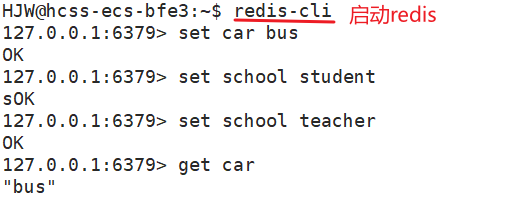
對于這里的key和value,不需要加上引號,就可以表示字符串的類型。如果要是給key和value加上引號也是可以的(單引號或雙引號都可以)。redis中的命令不區分大小寫。
如果get到一個不存在的key,那么就會顯示(nil),這個意思與NULL一樣,表示找不到,為空。
Redis全局命令
Redis支持很多種數據結構,整體來說,Redis是鍵值對結構,key只能是字符串,value實際上有很多種類型,比如說,字符串、哈希表、列表、集合、有序集合等等,操作不同的數據結構就會有不同的命令。
所以,全局命令,就是能夠搭配任意一個數據結構來使用的命令。
keys
- keys:返回所有滿足樣式(pattern)的 key。?持如下統配樣式。
語法:KEYS pattern
h?llo匹配hello,hallo和hxllo。匹配任意一個字符h*llo匹配 hllo 和 heeeello。匹配0個或多個任意字符h[ae]llo匹配 hello 和 hallo 但不匹配 hillo。即匹配包含a或e的鍵h[^e]llo匹配 hallo , hbllo , … 但不匹配 hello。即除了包含e的不符合,其它都符合。h[a-b]llo匹配 hallo 和 hbllo。匹配a到b這個范圍內的字符,包含兩側邊界。
命令有效版本:1.0.0 之后
時間復雜度: O ( N ) O(N) O(N)
返回值:匹配 pattern 的所有 key。
示例:
// 創建key
redis 127.0.0.1:6379> SET runoob1 redis
OK
redis 127.0.0.1:6379> SET runoob2 mysql
OK
redis 127.0.0.1:6379> SET runoob3 mongodb
OK// 查找以 runoob 為開頭的 key:
redis 127.0.0.1:6379> KEYS runoob*
6) "runoob3"
7) "runoob1"
8) "runoob2"//獲取 redis 中所有的 key 可用使用 *。
redis 127.0.0.1:6379> KEYS *
9) "runoob3"
10) "runoob1"
11) "runoob2"
在生產環境中,一般都會禁止使用keys命令,尤其是keys *:查詢redis中所有的key。
EXISTS
這個命令是判斷某個值是否存在。
語法:EXISTS key [key ...]
命令有效版本:1.0.0 之后
時間復雜度:O(1)
返回值:key 存在的個數。
示例:
127.0.0.1:6379> set hello 111
OK
127.0.0.1:6379> set hallo 222
OK
127.0.0.1:6379> set haxxllo 333
OK
127.0.0.1:6379> keys *
1) "hello"
2) "hallo"
3) "school"
4) "car"
5) "haxxllo"
6) "test"
127.0.0.1:6379> exists hello car
(integer) 2
127.0.0.1:6379> exists hello
(integer) 1
127.0.0.1:6379> exists car
(integer) 1
用exists判斷的時候,一次判斷和分開判斷時是有區別的。因為redis是一個客戶端、服務器結構的程序。客戶端和服務器之間通過網絡來進行通信。一次判斷完的話,只會產生一次請求和響應。而用兩次判斷的話,會多增加一次請求和響應。分開的寫法,會產生更多輪次的網絡通信。所以能一次查找最好。
DEL
刪除指定的 key。
語法:DEL key [key ...]
命令有效版本:1.0.0 之后
時間復雜度:O(1)
返回值:刪除掉的 key 的個數。
示例:
127.0.0.1:6379> keys *
1) "hello"
2) "hallo"
3) "school"
4) "car"
5) "haxxllo"
6) "test"
127.0.0.1:6379> del car
(integer) 1
127.0.0.1:6379> del hallo
(integer) 1
127.0.0.1:6379> keys *
1) "hello"
2) "school"
3) "haxxllo"
4) "test"
EXPIRE
為指定的 key 添加秒級的過期時間(Time To Live TTL)
語法:EXPIRE key seconds
命令有效版本:1.0.0 之后
時間復雜度:O(1)
返回值:1 表示設置成功。0 表示設置失敗。
這個的場景會用在驗證碼或者優惠券在指定時間之前有效等等。
示例:
127.0.0.1:6379> keys *
1) "hello"
2) "school"
3) "haxxllo"
4) "test"
127.0.0.1:6379> expire hello 10
(integer) 1
127.0.0.1:6379> get hello
"111"
127.0.0.1:6379> get hello
"111"
127.0.0.1:6379> get hello
"111"
127.0.0.1:6379> get hello
(nil)
TTL
獲取指定 key 的過期時間,秒級。
語法:TTL key
命令有效版本:1.0.0 之后
時間復雜度:O(1)
返回值:剩余過期時間。-1 表示沒有關聯過期時間,-2 表示 key 不存在。
示例:
127.0.0.1:6379> keys *
1) "school"
2) "haxxllo"
3) "test"
127.0.0.1:6379> expire school 10
(integer) 1
127.0.0.1:6379> ttl school
(integer) 6
127.0.0.1:6379> ttl school
(integer) 3
127.0.0.1:6379> ttl school
(integer) -2
[!note] 注意
EXPIRE 和 TTL 命令都有對應的支持毫秒為單位的版本:PEXPIRE 和 PTTL,詳細?法就不再介紹了。
TYPE
返回 key 對應的值的數據類型。
語法:TYPE key
命令有效版本:1.0.0 之后
比特就業課時間復雜度:O(1)
返回值: none , string , list , set , zset , hash 和stream(用于消息隊列和日志存儲,支持消息的持久化和時間排序) 。
示例:
redis> SET key1 "value"
"OK"
redis> LPUSH key2 "value"
(integer) 1
redis> SADD key3 "value"
(integer) 1
redis> TYPE key1
"string"
redis> TYPE key2
"list"
redis> TYPE key3
"set
FLUSHALL
這個命令用于清除所有的鍵,相當于MySQL中的drop dataname,這個命令不能隨便使用。開玩笑來說這個命令是“刪庫跑路”。
語法:flushall
127.0.0.1:6379> keys *
1) "key1"
2) "key2"
3) "key3"
127.0.0.1:6379> flushall
OK
127.0.0.1:6379> keys *
(empty array)
數據類型與內部編碼
Redis 針對每種數據結構都有??的底層內部編碼實現,而且是多種實現,這樣 Redis 會在合適的場景選擇合適的內部編碼。
| 數據類型 | 說明 |
|---|---|
| string(字符串) | 基本的數據存儲單元,可以存儲字符串、整數或者浮點數 |
| hash(哈希) | 一個鍵值對的集合,可以存儲多個字段 |
| list(列表) | 一個簡單的列表,可以存儲一系列的字符串元素 |
| set(集合) | 一個無序集合,可以存儲不重復的字符串元素 |
| zset(有序集合) | 類似于集合,但是每個元素都有一個分數(權重)與之關聯 |
| Bitmaps(位圖) | 基于字符串類型,可以對每個位進行操作 |
| Stream(流) | 用于消息隊列和日志存儲,支持消息的持久化和時間排序 |
還有其它的數據類型,不過最常用的就是前5種。其它的數據類型也某些特定的場景下才會用到。
Redis在底層實現上述數據結構的時候,會在源碼層面,針對上述實現進行特定的優化,來節省時間/空間的效果,其中特定的優化就是編碼方式。
另外Redis承諾,我這個哈希表,你在進行查詢、插入、刪除操作的時候,保證時間復雜度為O(1),但是這個背后的實現,不一定就是一個標準的哈希表。可能在特定的場景下,使用別的數據結構實現,但是仍然保證時間復雜度符合承諾。
每種數據類型,都可能會有多種實現方式,Redis稱其為編碼方式,常見編碼方式如下表:
| 數據類型 | 內部編碼 |
|---|---|
| string | raw int embstr |
| hash | hashtable ziplist |
| list | linkedlist ziplist |
| set | hashtable intset |
| zset | skiplist ziplist |
- string
- int:存儲的字符串是一個可以用64位有符號整數表示的數字時,會用int編碼。
- raw:存儲的字符串長度超過44字節時,會使用raw編碼。raw編碼需要兩次內存分配,分別用于存儲Redis對象頭和字符串數據。
- embstr:存儲的字符串長度小于等于44字節時,會使用embstr編碼。embstr編碼將redis對象頭和字符串數據連續存儲在一塊內存中,避免了多次內存分配,提高了內存使用效率和操作性能。
- hash
- hashtable:是一種標準的哈希表數據結構,支持快速的查找。插入和刪除操作,適合存儲大規模的哈希對象。
- ziplist:同時滿足2個條件,才會使用ziplist編碼。第一,哈希對象保存到鍵值對數量小于
hash-max-ziplist-entries(默認值是512);第二,哈希對象保存的所有鍵值對的鍵和值的字符串長度都小于hash - max - ziplist - value(默認值為 64)。ziplist是一種緊湊的、連續的內存數據結構,適合存儲小的哈希對象,可以節省內存。
- list
- linkedlist:是一種雙向鏈表數據結構,支持在列表的兩端快速插入和刪除元素,但內存開銷較大。
- set
- intset:當集合對象同時滿足以下兩個條件時,Redis 會使用
intset編碼。第一,集合對象保存的所有元素都是整數值。第二,集合對象保存的元素數量小于set - max - intset - entries(默認值為 512)。intset是一種緊湊的整數集合數據結構,適合存儲整數集合,可以節省內存。 - hashtable:當集合對象不滿足
intset編碼的條件時,Redis 會使用hashtable編碼。hashtable的鍵用于存儲集合元素,值都為NULL,支持快速的查找、插入和刪除操作。
- intset:當集合對象同時滿足以下兩個條件時,Redis 會使用
- zset
- ziplist:
ziplist編碼的有序集合將成員和分數依次存儲在ziplist中,并且按照分數從小到大排序,適合存儲小的有序集合。 - skiplist:
skiplist是一種跳躍表數據結構,它結合了鏈表和二分查找的思想,支持快速的插入、刪除和查找操作,同時還可以按照分數范圍進行快速遍歷。在 Redis 中,skiplist還會和hashtable結合使用,hashtable用于快速查找成員的分數,skiplist用于維護元素的有序性。
- ziplist:
示例:
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> lpush mylist a b c
(integer) 3
127.0.0.1:6379> object encoding hello
"embstr"
127.0.0.1:6379> object encoding mylist
"quicklist"
可以通過 object encoding 命令查詢內部編碼:
為什么可以看到每種數據結構都有至少兩種以上的內部編碼實現?Redis 這樣設計有兩個好處:
- 可以改進內部編碼,而對外的數據結構和命令沒有任何影響,這樣?旦開發出更優秀的內部編碼,?需改動外部數據結構和命令,例如 Redis 3.2 提供了 quicklist,結合了 ziplist 和 linkedlist 兩者的優勢,為列表類型提供了?種更為優秀的內部編碼實現,而對用戶來說基本無感知。
- 多種內部編碼實現可以在不同場景下發揮各自的優勢,例如 ziplist 比較節省內存,但是在列表元素比較多的情況下,性能會下降,這時候 Redis 會根據配置選項將列表類型的內部實現轉換為linkedlist,整個過程?戶同樣無感知。








的實戰教程)

混合云架構部署)

)
疾病識別與分割的個性化和區域適應性方法|文獻速遞-深度學習醫療AI最新文獻)





格式化串口輸出---Prj04)