🔥個人主頁🔥:孤寂大仙V
🌈收錄專欄🌈:計算機網絡
🌹往期回顧🌹: 【計算機網絡】應用層協議Http——構建Http服務服務器
🔖流水不爭,爭的是滔滔不息
- 一、UDP協議
- 二、UDP特點
- 面向數據報
- 三、UDP緩沖區
- 四、基于UDP的應用層協議
- 五、報文理解
一、UDP協議
UDP(User Datagram Protocol,用戶數據報協議)是一種無連接的傳輸層協議,提供簡單的、不可靠的數據傳輸服務。與TCP不同,UDP不保證數據包的順序、可靠性或流量控制,但具有低延遲和高效率的特點,適用于實時性要求高但允許少量丟包的應用場景。
UDP協議端格式
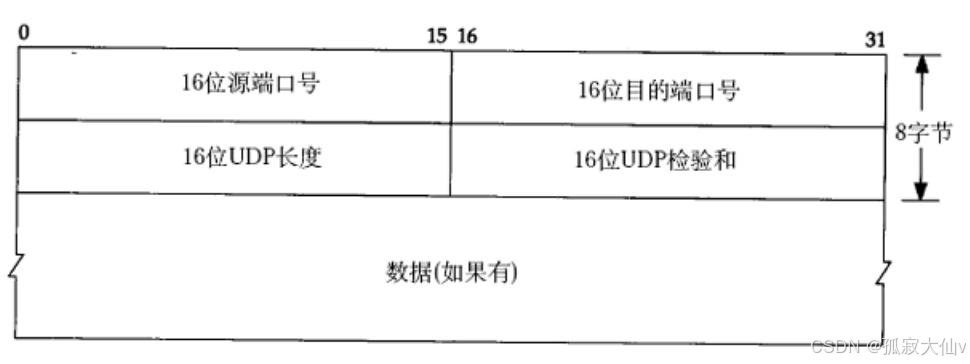
UDP 報文其實很簡單,它的格式是 “定長報頭 + 不定長數據”。如圖上面8字節是報頭大小,下面數據是有效載荷。UDP報頭是定長報頭,所以每個報文交付給上層報頭都是確定的。UDP報文分離的時候,直接把定長的報頭和有效載荷分離就好了,分用根據目的端口號去完成。UDP報文和報文之間都有有邊界的,所以不用像TCP傳輸那樣還要自定義協議區區分報頭。16位源端口號是表示報文是從哪發的,16位目的端口號是表示報文要發到哪里。端口號設計為16位的,是因為內核協議是16位的。報頭是固定的,每個報文的有效載荷能和報頭分明的區分,且報文和報文之間有邊界,這就是用戶數據報最大的特點。16 位 UDP 長度, 表示整個數據報(UDP 首部+UDP 數據)的最大長度;如果校驗和出錯, 就會直接丟棄;
為什么說UDP簡單?
UDP和TCP有一個最大的不同:UDP是有“邊界”的協議,每一個UDP報文本身就是獨立的一塊
內核收到一個UDP報文,直接把8字節頭部剝掉,剩下的數據送到應用層就行。
每一個recvfrom()調用,只會收到一個完整的UDP報文(不會拆開,也不會合并)。
不像TCP:TCP是“流”,沒有邊界,一個包可能拆成多個recv才收完,或者多個包粘在一起。所以TCP應用層必須“自己想辦法分包”,比如用自定義協議。
二、UDP特點
UDP 傳輸的過程類似于寄信。
- 無連接: 知道對端的 IP 和端口號就直接進行傳輸, 不需要建立連接;
- 不可靠: 沒有確認機制, 沒有重傳機制; 如果因為網絡故障該段無法發到對方,UDP 協議層也不會給應用層返回任何錯誤信息;
- 面向數據報: 不能夠靈活的控制讀寫數據的次數和數量;
面向數據報
應用層交給 UDP 多長的報文, UDP 原樣發送, 既不會拆分, 也不會合并;
用 UDP 傳輸 100 個字節的數據:如果發送端調用一次 sendto, 發送 100 個字節, 那么接收端也必須調用對應的一次 recvfrom, 接收 100 個字節; 而不能循環調用 10 次 recvfrom, 每次接收 10 個字節。
三、UDP緩沖區
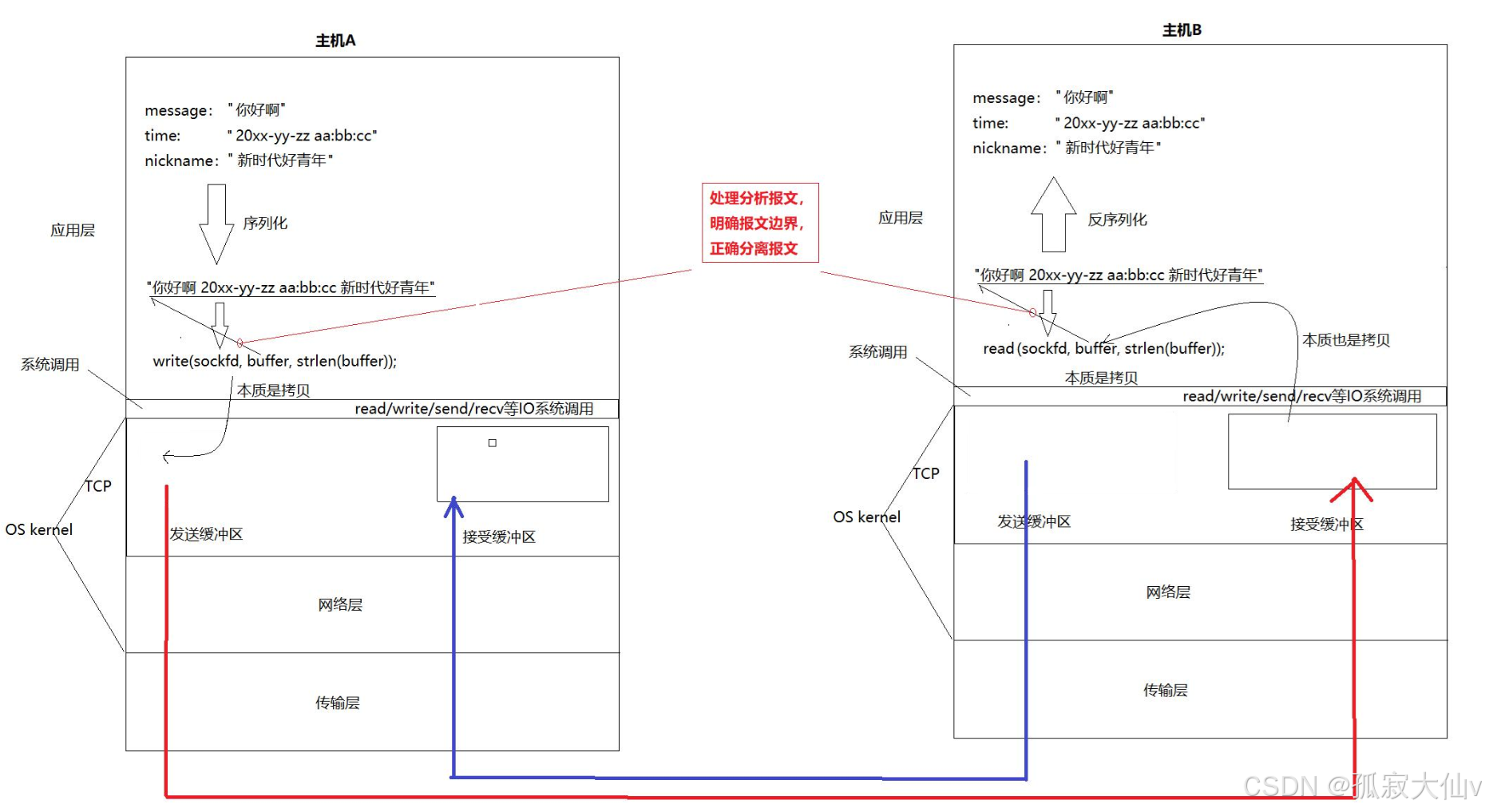
UDP 沒有真正意義上的 發送緩沖區. 調用 sendto 會直接交給內核, 由內核將數據傳給網絡層協議進行后續的傳輸動作;
UDP 具有接收緩沖區. 但是這個接收緩沖區不能保證收到的 UDP 報的順序和發送 UDP 報的順序一致; 如果緩沖區滿了, 再到達的 UDP 數據就會被丟棄;
UDP 的 socket 既能讀, 也能寫, 這個概念叫做 全雙工
因為UDP沒有發送緩沖區,所以如果報文在網絡傳輸的過程中丟包了,UDP 本身是“無連接 + 不可靠傳輸協議”,它不會確認你發出去了沒,也不會重傳,如果在網絡中丟了,那就真的丟了,服務器一無所知。
如果應用層正在進行報文的解析,不會影響OS從網絡中讀取報文
UDP使用注意事項
我們注意到, UDP 協議首部中有一個 16 位的最大長度. 也就是說一個 UDP 能傳輸的數據最大長度是 64K(包含 UDP 首部).。
然而 64K 在當今的互聯網環境下, 是一個非常小的數字,如果我們需要傳輸的數據超過 64K, 就需要在應用層手動的分包, 多次發送, 并在接收端手動拼裝。
四、基于UDP的應用層協議
- DNS(Domain Name System)
DNS用于將域名解析為IP地址。由于查詢通常只需一次請求-響應,UDP的輕量特性使其成為首選。默認使用端口53。 - DHCP(Dynamic Host Configuration Protocol)
DHCP用于自動分配IP地址。UDP的廣播和多播支持使其適合局域網內的地址分配。客戶端使用端口68,服務器使用端口67。 - SNMP(Simple Network Management Protocol)
SNMP用于網絡設備監控和管理。UDP的簡單性適合頻繁的監控數據交換。默認使用端口161(查詢)和162(陷阱)。 - TFTP(Trivial File Transfer Protocol)
TFTP是簡單的文件傳輸協議,常用于網絡引導或設備固件更新。使用UDP端口69,實現比FTP更輕量。 - QUIC(Quick UDP Internet Connections)
QUIC是Google開發的傳輸協議,基于UDP實現類似TCP的可靠性,但減少握手延遲。HTTP/3基于QUIC,提升Web性能。 - VoIP(Voice over IP)
語音通話協議如RTP(Real-time Transport Protocol)通常基于UDP。實時性要求高,少量丟包對語音質量影響較小。
五、報文理解
Linux sk_buff源碼
struct sk_buff {union {struct {struct sk_buff *next;struct sk_buff *prev;union {struct net_device *dev;unsigned long dev_scratch;};};struct rb_node rbnode; // 用于紅黑樹};union {struct sock *sk;int ip_defrag_offset;};char cb[48]; // 控制緩沖區,協議層私有數據unsigned long _skb_refdst;unsigned int len, data_len;__u16 mac_len, hdr_len;__u16 queue_mapping;__u8 cloned:1, nohdr:1, fclone:2, peeked:1, head_frag:1;__u8 pfmemalloc:1, pp_recycle:1;__u16 tc_index; // 流量控制索引__u16 transport_header;__u16 network_header;__u16 mac_header;__u32 headers_end[0];void (*destructor)(struct sk_buff *skb);struct nf_conntrack *nfct;unsigned long nfct_reasm;__u32 secmark;unsigned int mark;__u16 vlan_proto;__u16 vlan_tci;union {__u32 inner_network_header;__u32 inner_network_header_offset;};__u32 inner_transport_header;__be16 protocol;__u16 transport_header_was;__u8 encapsulation:1;// 更多字段...unsigned char *head, *data, *tail, *end;
};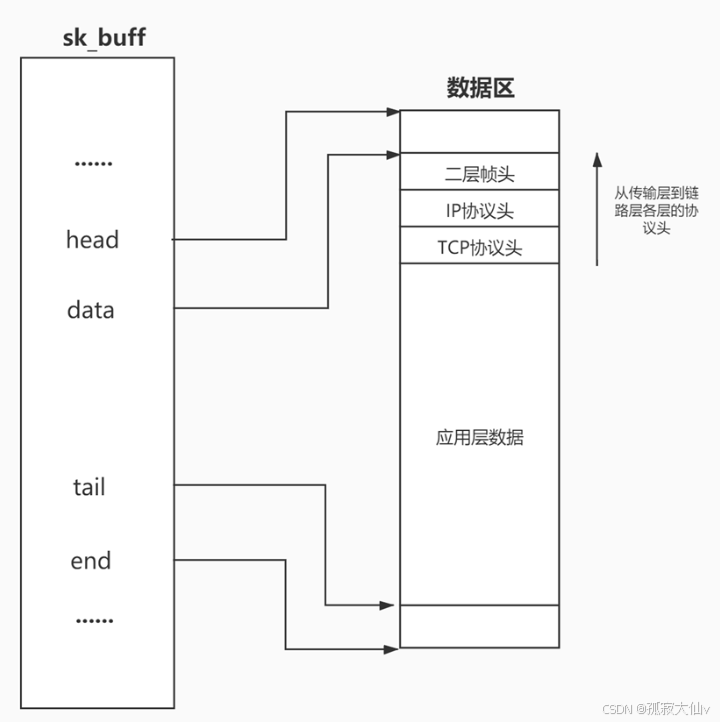
在操作系統內部,可能會同時存在大量的報文,操作系統必須管理這些報文。引入sk_buff(Socket Buffer)是 Linux 內核網絡協議棧中 收發數據的核心結構體,每當有網絡數據要處理,內核就會分配一個 sk_buff。
skb->head, skb->data, skb->tail, skb->end 是sk_buff內的指針。
- skb->head:指向整個緩沖區的起始位置(分配的整塊內存)
- skb->data:指向有效數據的起始位置(比如 IP 頭部開始)
- skb->tail:指向有效數據的結尾(可以向后追加數據)
- skb->end:指向緩沖區結尾(表示最多能寫到哪)
所謂封裝和解包,本質就是移動data指針在緩沖區中指向。
我們把data和tail想成一個"動態窗口",當我們的報完往下層協議封裝就要往前移動data指針,封裝報頭,當往后移動tail指針的時候是添加新的數據。
發送過程:從上層到下層
調用send()或者write()發送數據,數據經歷了用戶態->內核態->網絡層多次加工封裝。
發送數據,數據進入內核socket buffer,內核分配sk_buff,并把數據填進去(通常從skb->tail開始)。進去TCP層,加上TCP報頭skb->tail往前移動數據跟在TCP頭后面,設置TCP序號、校驗和等。進入IP層。加上IP層報頭,設置源IP、目的IP等。進入數據鏈路層加MAC頭,設置目標MAC、源MAC等。最后整個數據包都集中在skb->data和skb->tail之間->DMA拷貝給網卡發送過去。
接收過程:從底層到上層
網卡收到數據,觸發中斷。驅動將數據拷貝到sk_buff。skb->data指向以太網頭部。一層一層"剝皮"去掉報頭。最后skb->data指向payload(應用層數據)上交給socket buffer,再wake up用戶進程接收。
sk_buff 就是內核網絡協議棧用來“托運數據”的容器,skb->data 是快遞包裹的“當前開箱點”,從 TCP 到 IP 到 MAC,每一層往前預留一段頭,然后下發出去。



)








)
)





)