文章目錄
- Pre
- 引言
- 1. 緩存基本概念
- 2. Guava 的 LoadingCache
- 2.1 引入依賴與初始化
- 2.2 手動 put 與自動加載(CacheLoader)
- 2.2.1 示例代碼
- 2.3 緩存移除與監聽(invalidate + removalListener)
- 3. 緩存回收策略
- 3.1 基于容量的回收(LRU)
- 3.2 基于時間的回收
- 3.3 基于 JVM GC 的回收
- 3.3.1 GC 回收引發的緩存顛簸問題
- 4. 常見緩存算法簡介
- 4.1 FIFO(先進先出)
- 4.2 LRU(最近最少使用)
- 4.3 LFU(最近最不常用)
- 5. 簡易 LRU 實現——LinkedHashMap
- 5.1 功能局限與線程安全
- 6. 操作系統層面的預讀與文件緩存
- 7. 緩存優化的一般思路
- 8. 緩存應用案例
- 9. 小結

Pre
性能優化 - 理論篇:常見指標及切入點
性能優化 - 理論篇:性能優化的七類技術手段
性能優化 - 理論篇:CPU、內存、I/O診斷手段
性能優化 - 工具篇:常用的性能測試工具
性能優化 - 工具篇:基準測試 JMH
性能優化 - 案例篇:緩沖區
- 引言:解釋緩存與緩沖的區別及緩存在性能優化中的重要性;
- 緩存基本概念:緩存的本質、應用場景、進程內 vs 進程外緩存;
- Guava LoadingCache(LC)示例:
3.1 引入依賴與初始化配置;
3.2 手動 put 與自動加載(CacheLoader)模式;
3.3 緩存容量、初始大小與并發級別設置;
3.4 緩存移除與監聽(invalidate + removalListener); - 緩存回收策略:
4.1 基于容量的回收(LRU);
4.2 基于時間的回收(expireAfterWrite / expireAfterAccess);
4.3 基于 JVM GC 的回收(weakKeys / weakValues / softValues);
4.4 GC 回收引發的緩存顛簸問題與解決思路; - 緩存算法簡述:FIFO、LRU、LFU 三種常見策略;
- 用 LinkedHashMap 實現簡易 LRU:
6.1 LinkedHashMap 構造參數與訪問順序;
6.2 覆蓋 removeEldestEntry 實現容量控制;
6.3 線程安全與功能局限性說明; - 操作系統層面的預讀與文件緩存:readahead 機制、完全加載策略;
- 緩存優化一般思路:何時用緩存、容量與命中率考量;
- 緩存的一些注意事項與示例:HTTP 304、CDN;
引言
在性能優化 - 案例篇:緩沖區中,介紹了“緩沖”這一優化手段——通過將數據暫存到內存緩沖區,批量順序讀寫來緩解設備間的速度差異。與緩沖相伴隨的“孿生兄弟”就是緩存(Cache)。緩存將常用數據放到相對高速的存儲層(如內存)中,從而在后續訪問時實現瞬時讀取,顯著提升性能。
舉例而言:
- 瀏覽熱門頁面時,只要緩存中已有渲染結果,就可以實現“秒開”;
- 對數據庫而言,引入緩存后,頻繁查詢熱點記錄可以直接命中緩存,數據庫幾乎無需負載。
緩存幾乎是軟件中最常見的優化技術。從 CPU L1/L2/L3 緩存到 Redis、Memcached 這樣的分布式緩存,無不圍繞“速度差異協調”這一核心展開。
接下來我們主要聚焦于進程內緩存——堆內緩存,以 Guava 的 LoadingCache 為示例講解堆內緩存設計思路、常見回收策略和算法實現。
1. 緩存基本概念
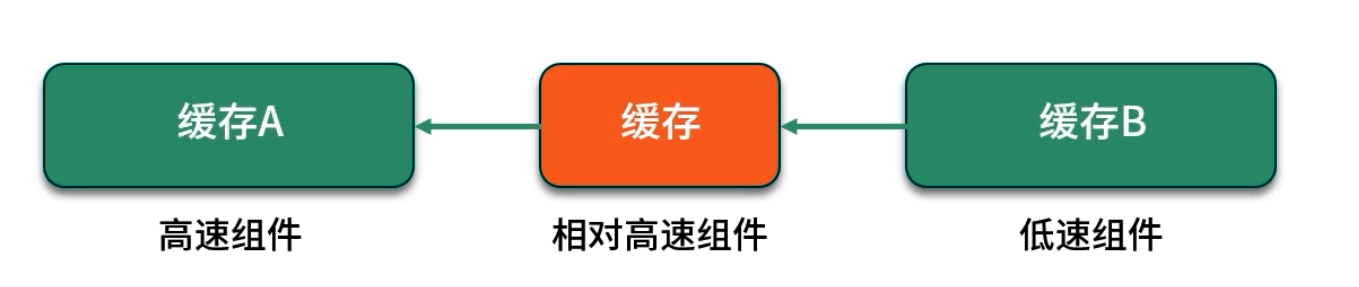
緩存的核心作用,是在兩個速度差異巨大的組件之間增加一層高速存儲:
- 速度慢組件:如數據庫、文件存儲,訪問一次可能耗費幾毫秒或更長;
- 速度快組件:如 CPU 寄存器、內存讀寫,只需幾十納秒;
- 緩存層(中間層):通常部署在內存中,通過哈希映射、LRU 回收等策略,只要緩存命中就能以幾百納秒返回結果。
根據緩存所在的物理位置,可將其分為:
- 進程內緩存(堆內緩存):直接存放在 JVM 堆里,訪問速度最快,但容量受限于可用堆內存;
- 進程外緩存(進程間或分布式緩存):如 Redis、Memcached,通常運行在獨立進程或集群里,通過網絡訪問,雖然速度比數據庫快許多,但仍比堆內緩存慢一個數量級;
接下來重點講解 進程內緩存,常見實現包括 Guava Cache、Caffeine、Ehcache、JCache 等。它們都提供了基于內存分片、高并發訪問、靈活回收策略和統計監控的堆內緩存解決方案。
2. Guava 的 LoadingCache
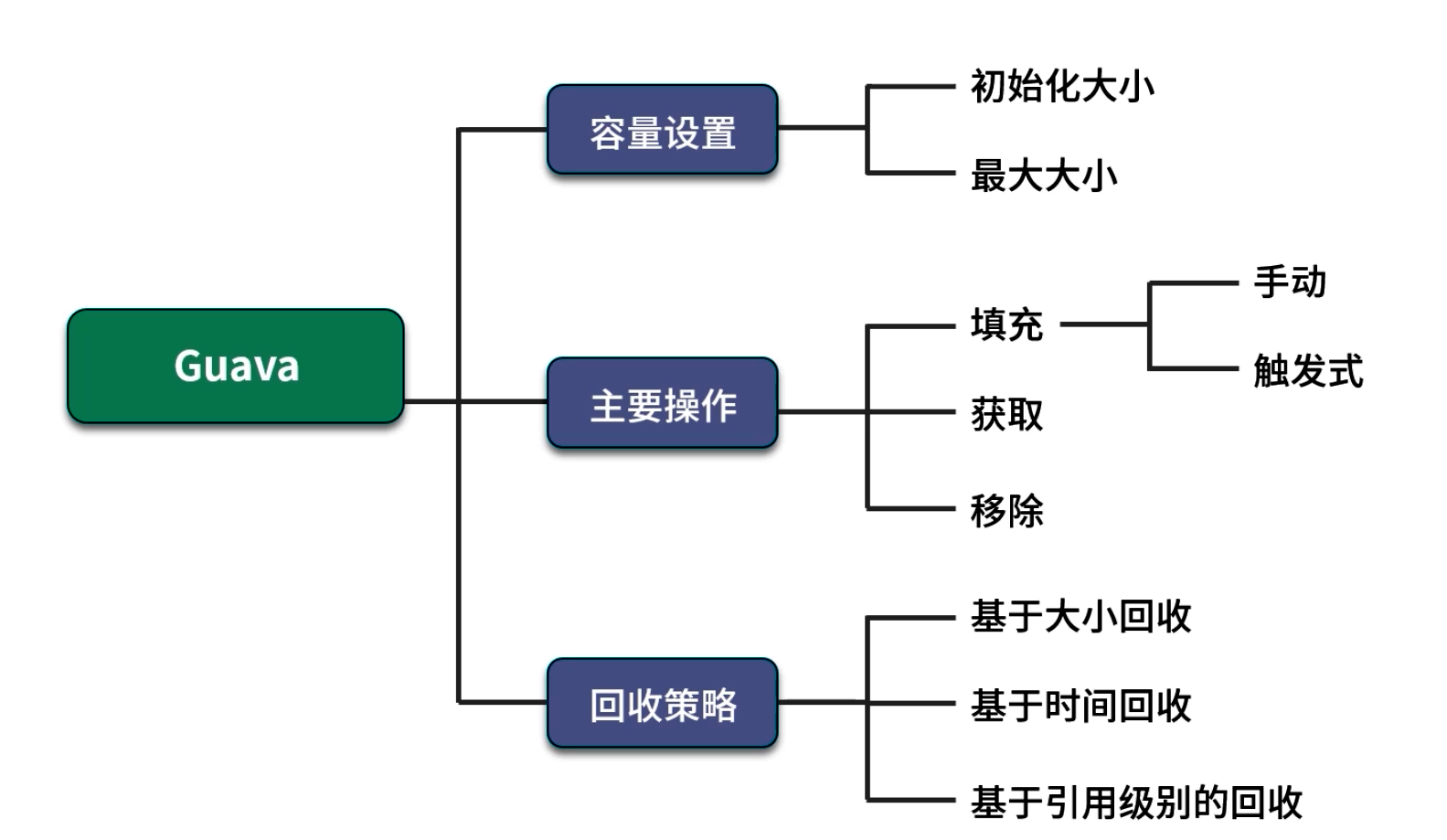
Guava 提供了功能強大的 Cache 接口和 LoadingCache 實現,既支持手動存入(put()),也支持在緩存未命中時“自動加載”(CacheLoader)。下面通過示例逐步介紹其用法與內部配置要點。
2.1 引入依賴與初始化
首先,通過 Maven 將 Guava 庫加入項目:
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>29.0-jre</version>
</dependency>
然后,使用 CacheBuilder 來創建一個 LoadingCache:
LoadingCache<String, String> lc = CacheBuilder.newBuilder()// 設置最大緩存容量:達到上限后回收其他元素.maximumSize(1000)// 設置初始容量:底層 Hash 表的初始大小為 16(默認).initialCapacity(16)// 設置并發級別:將緩存分片成 4 個 segment,提升并發讀寫性能.concurrencyLevel(4).build(new CacheLoader<String, String>() {@Overridepublic String load(String key) throws Exception {// 緩存未命中時,自動調用 slowMethod 從外部數據源加載return slowMethod(key);}});
maximumSize(int):指定 緩存中可保留條目的最大數量,一旦超過,將根據回收策略(默認 LRU)移除舊元素;initialCapacity(int):指定底層哈希表初始大小(bucket 數量),避免在緩存初始化時反復擴容;concurrencyLevel(int):指定并發寫的“分段”數,Guava 會將內部數據結構拆分為concurrencyLevel個部分,以減少并發沖突;
2.2 手動 put 與自動加載(CacheLoader)
LoadingCache 支持兩種獲取方式:
-
手動
put():lc.put("key1", "value1"); String v = lc.getIfPresent("key1"); // 立即返回 "value1"在這種模式下,開發者負責將外部數據同步寫入緩存。
-
自動加載
get():
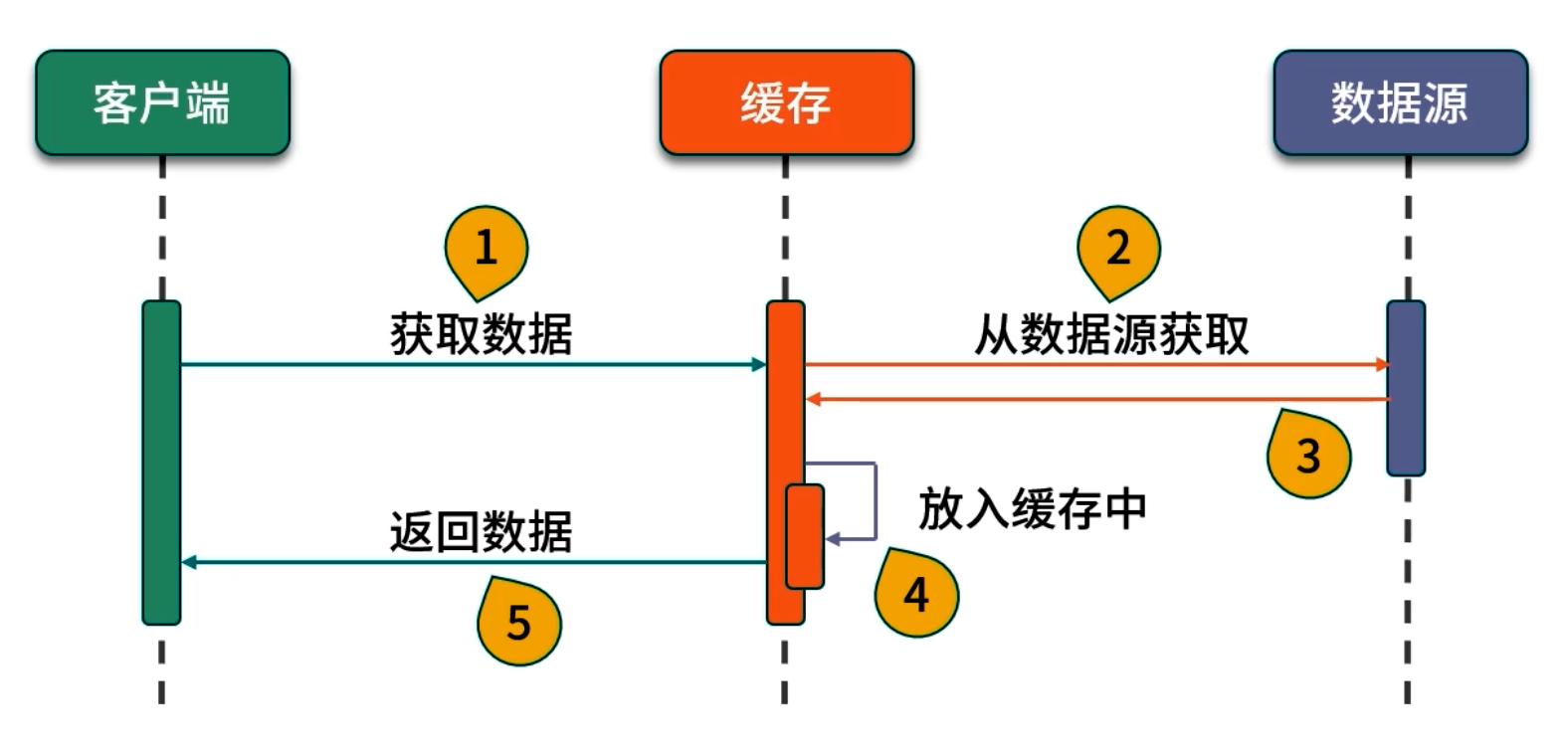
// 第一次調用:緩存中無 key "a",觸發 CacheLoader.load("a")
long start = System.nanoTime();
String result1 = lc.get("a"); // slowMethod("a") 需 1s
System.out.println("第一次調用耗時: " + (System.nanoTime() - start));
// 第二次調用:緩存命中,迅速返回
long start2 = System.nanoTime();
String result2 = lc.get("a");
System.out.println("第二次調用耗時: " + (System.nanoTime() - start2));
其中 load(String key) 方法可同步加載所需數據(如從數據庫或外部 API 拉取),并在返回值后自動存入緩存。
2.2.1 示例代碼
public class GuavaCacheDemo {// 模擬一個緩慢方法:睡眠 1 秒后返回結果static String slowMethod(String key) throws Exception {Thread.sleep(1000);return key + ".result";}public static void main(String[] args) throws Exception {LoadingCache<String, String> lc = CacheBuilder.newBuilder().maximumSize(1000).initialCapacity(16).concurrencyLevel(4).recordStats() // 開啟統計信息收集.build(new CacheLoader<String, String>() {@Overridepublic String load(String key) throws Exception {return slowMethod(key);}});// 第一次 get,會調用 slowMethodlong t1 = System.nanoTime();String v1 = lc.get("a");long elapsed1 = System.nanoTime() - t1;System.out.println("第一次 get 用時: " + elapsed1 + " ns");// 第二次 get,立即返回long t2 = System.nanoTime();String v2 = lc.get("a");long elapsed2 = System.nanoTime() - t2;System.out.println("第二次 get 用時: " + elapsed2 + " ns");// 輸出命中率與加載次數等統計System.out.println("Cache Stats: " + lc.stats());}
}
recordStats():開啟緩存統計功能,可用于后續分析hitRate()、loadSuccessCount()等指標;CacheLoader.load():當 key 未命中時,自動調用并將結果寫回緩存;
2.3 緩存移除與監聽(invalidate + removalListener)
-
手動刪除:
lc.invalidate("a"); // 移除 key "a" 對應的緩存項 -
監聽刪除事件:
LoadingCache<String, String> lc2 = CacheBuilder.newBuilder().removalListener(notification -> {System.out.println("移除: " + notification.getKey() + " 因為 " + notification.getCause());}).maximumSize(100).build(new CacheLoader<>() {@Overridepublic String load(String key) { return slowMethod(key); }});當緩存項因為容量、過期、顯式
invalidate()等原因被移除時,監聽器會收到回調,可用于日志、監控或二次清理。
3. 緩存回收策略
在緩存容量有限的前提下,需設計合適的回收策略來剔除“冷”或不再需要的數據,以保證“熱點”數據得到優先保留。Guava 原生支持多種回收方式:
3.1 基于容量的回收(LRU)
maximumSize(long):當超過指定數量時,按照“最近最少使用(LRU)”策略移除最舊項;- LRU 意味著:每次緩存命中(
get())或寫入(put())時,該條目被標記為“最近被使用”;容量滿時,優先移除最久未被訪問的條目; - 這是默認的回收策略,適合大多數“熱點覆蓋度有限”的場景。
3.2 基于時間的回收
expireAfterWrite(long duration, TimeUnit unit):在緩存項被寫入后,若在duration時間內未被訪問,自動過期移除;expireAfterAccess(long duration, TimeUnit unit):在緩存項最后一次訪問后,若超過duration,自動過期移除;- 這兩種策略可以組合使用,用于場景如“用戶會話緩存”、“短期熱點數據”。
3.3 基于 JVM GC 的回收
-
Guava 提供了
weakKeys(),weakValues(),softValues()等方法,利用不同強度的引用進行回收:weakKeys():將緩存 key 按弱引用存放,若 key 對象僅被緩存引用,則可隨時被 GC 回收,相應條目自動失效;weakValues():將緩存 value 按弱引用存放,若 value 對象不再被強引用,則可被 GC 回收;softValues():將 value 以軟引用存放,當 JVM 內存不足時,GC 會優先回收這些軟引用對象;
-
典型語法:
Cache<String, byte[]> cache = CacheBuilder.newBuilder().maximumSize(1000).weakValues().build(); -
面試高頻:若同時設置
weakKeys()與weakValues(),則當 key 或 value 都失去任何強引用后,該條目會被 GC 回收。
3.3.1 GC 回收引發的緩存顛簸問題
當緩存條目使用弱引用或軟引用,一旦 JVM 觸發 GC,就可能一次性清空大批緩存數據。若該緩存頻繁被訪問,緩存將被迅速重新加載,導致連續觸發多次 GC 和緩存“嘩啦啦回補”的現象——CPU 消耗驟增,卻無法留住數據。
解決思路:
- 僅對內存占用較大的非熱點對象使用
softValues(),而不是對所有緩存。一旦發現緩存顛簸,可考慮放寬 GC 壓力或降低緩存容量; - 盡量使用基于容量+時間的回收,避免過度依賴 JVM GC;
- 在緩存加載邏輯中加入適當延遲,防止短時間內同一批 key 被重復加載。
4. 常見緩存算法簡介
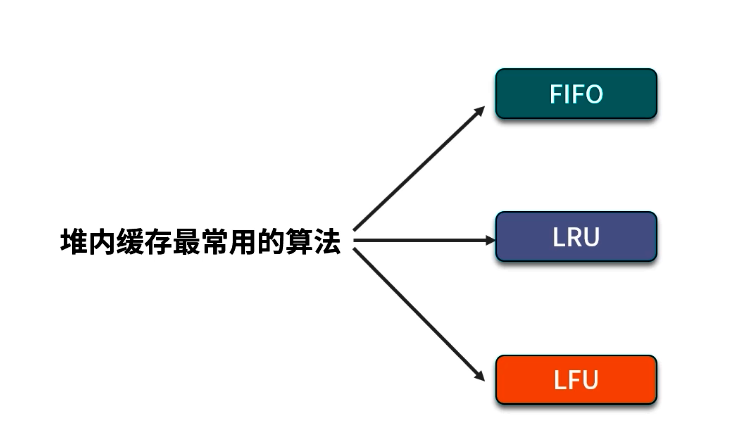
除了 Guava 提供的默認 LRU,緩存領域常見還有兩種算法:
4.1 FIFO(先進先出)
-
按“插入順序”回收:
- 緩存滿時,移除最早插入的條目;
- 結構簡單,但不考慮條目熱度;
- 適用于“日志隊列”、“任務處理隊列”這類只關心先來先服務的場景。
4.2 LRU(最近最少使用)
-
按“訪問順序”回收:
- 每次
get()或put()時,將條目移至最近位置; - 滿載時移除最久未被訪問的條目;
- 適用于“熱點數據需長時間保留”的場景,是一般緩存中最為常見的策略。
- 每次
4.3 LFU(最近最不常用)
-
按“訪問頻率”回收:
- 維護每個條目的訪問計數;
- 緩存滿時,移除訪問計數最少的條目;若存在多項訪問計數相同,則移除“最久未使用”者;
- 適用于需要保留“高訪問頻次”數據的場景,但實現較復雜,需要額外維護計數與優先級隊列。
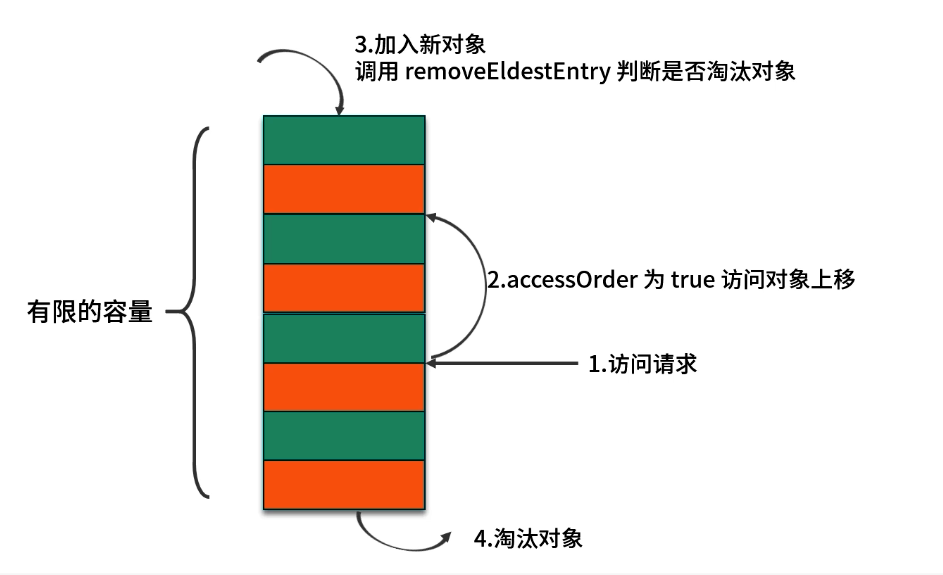
5. 簡易 LRU 實現——LinkedHashMap
在 Java 中,要實現一個輕量級的 LRU 緩存,最便捷的方式是利用 LinkedHashMap 提供的“訪問順序”功能:
public class LRUCache<K, V> extends LinkedHashMap<K, V> {private final int capacity;public LRUCache(int capacity) {// 初始容量 16,負載因子 0.75,accessOrder=true 表示按訪問順序排列super(16, 0.75f, true);this.capacity = capacity;}// 當 put 后,自動調用此方法判斷是否需要移除最老條目@Overrideprotected boolean removeEldestEntry(Map.Entry<K, V> eldest) {return size() > capacity;}
}
-
構造參數說明:
initialCapacity:初始哈希表桶數,默認 16;loadFactor:負載因子(0.75f);accessOrder=true:按照“訪問順序”保持雙向鏈表;
-
removeEldestEntry:在每次put()后自動調用,若返回true,則移除“最久未訪問”者,即 LRU 算法的核心。
5.1 功能局限與線程安全
-
優勢:代碼簡潔,無需自行維護優先級隊列或計數器;
-
局限:
- 僅基于“條目數量”控制容量,不能指定基于“內存占用大小”回收;
- 無法設置“基于時間過期”或“基于訪問次數”回收;
-
線程安全:
LinkedHashMap本身并非線程安全,如需并發訪問,應加鎖或改用ConcurrentLinkedHashMap/ Guava Cache / Caffeine。
6. 操作系統層面的預讀與文件緩存
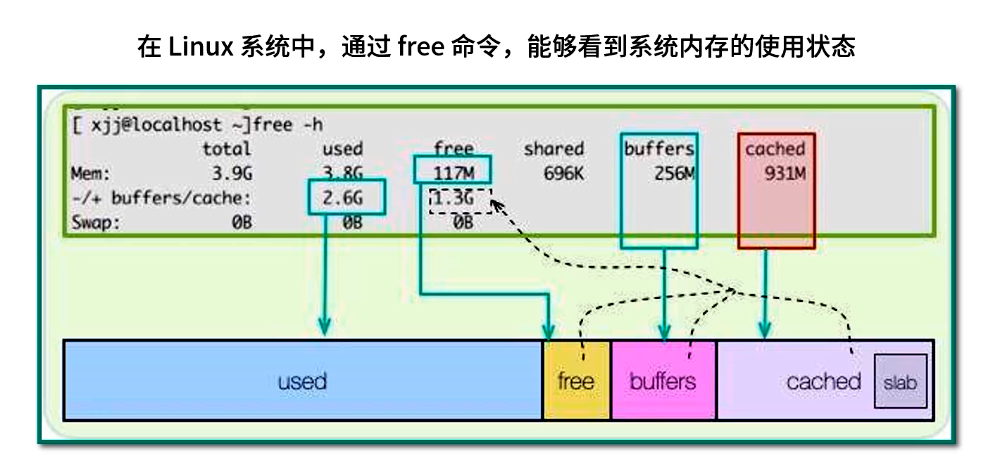
在操作系統層面,對文件 I/O 緩存設計也非常智能,進一步支撐了高性能緩存架構。Linux 下可以通過 free 命令查看內存狀態,其中 cached 區域往往十分龐大:
$ free -htotal used free shared buff/cache available
Mem: 16Gi 4.2Gi 2.5Gi 128Mi 9.4Gi 11Gi
Swap: 2.0Gi 512Mi 1.5Gi
buff/cache:表示操作系統將磁盤塊緩存在內存中的容量,包括文件系統頁緩存、目錄緩存等;- Readahead(預讀):當進程順序讀取文件時,內核會自動嘗試以“頁面”為單位預讀后續若干頁面,以減少隨機讀時的磁盤尋道開銷。

例如,若應用以 4KB 為單位讀取大型文件,內核可能在后臺提前載入 128KB 或更多連續頁面,由此實現“順序讀取性能≈內存讀取性能”的效果。
- 完全加載策略:若某一小文件(如幾 MB)訪問頻率極高,可在應用啟動時一次將整個文件
mmap()或read()到內存(posix_fadvise(..., POSIX_FADV_WILLNEED)),確保后續訪問都命中內核緩存;
7. 緩存優化的一般思路
在實際項目中,引入進程內緩存時,可根據以下幾個準則:
-
緩存目標場景:
- 存在穩定的數據熱點(某些 key 會被反復訪問);
- 讀操作遠多于寫操作;
- 下游服務(數據庫、遠程接口)性能低,成為瓶頸;
- 緩存一致性要求相對寬松,偶爾允許短暫的“陳舊”數據。
-
緩存大小與容量:
- 緩存容量過小,會導致“熱點”數據被頻繁淘汰,命中率低,性能提升有限;
- 緩存容量過大,會占用大量堆空間,增加 GC 頻率與時長;
- 通常通過監控緩存命中率(
cache.stats().hitRate())來調整容量,推薦至少達到 50% 的命中率,若低于 10% 就要重新評估是否需要緩存。
-
回收策略選擇:
- 默認使用 LRU,即
maximumSize(...); - 對于需要“短期熱點”或“超時失效”的數據,可結合
expireAfterWrite(...)與expireAfterAccess(...); - 若緩存數據對象非常大,且不想占用堆內存,可考慮
weakValues()或softValues(),但要避免“緩存顛簸”現象。
- 默認使用 LRU,即
-
監控與統計:
- 開啟
recordStats(),收集命中、加載、移除次數等數據; - 定期導出或打印
cache.stats(),分析緩存命中率(hitRate)與平均加載時間(averageLoadPenalty); - 若發現加載成本過高,可考慮加大緩存容量或優化加載算法;
- 開啟
-
緩存失效與一致性:
- 當緩存中數據與源數據庫數據不一致時,需要設計緩存更新/清理策略(如主動失效、定時刷新或消息通知觸發刷新);
- 對于對一致性要求極高場景,可使用“雙寫+事務+消息隊列+雙刪失效”等方案,見后續“緩存一致性”課時。
-
預加載 vs 惰性加載:
- 惰性加載(Lazy Loading):在第一次訪問時加載到緩存,常見于
LoadingCache; - 預加載(Preloading):在應用啟動時或定時調度時一次性加載所有熱點數據,減少首次訪問延遲;
- 若熱點集合較小且可預見,可采用預加載;若熱點動態且數據量大,優先使用惰性加載。
- 惰性加載(Lazy Loading):在第一次訪問時加載到緩存,常見于
8. 緩存應用案例
-
HTTP 304(Not Modified)緩存
- 瀏覽器發送條件性請求:帶上
If-Modified-Since或ETag; - 服務端判斷資源是否自上次修改以來未發生變化,若無改動則直接返回
304,讓瀏覽器使用本地緩存;否則返回200并攜帶新的資源與緩存頭; - 這樣可以在瀏覽器端節省一次完整的資源下載,并允許操作系統與瀏覽器在內存/硬盤層面做更深層次的緩存。
- 瀏覽器發送條件性請求:帶上
-
CDN(內容分發網絡)緩存
- 用戶訪問某個靜態資源時,會首先到就近的 CDN 節點請求;
- 若該節點已有緩存,直接返回給用戶;否則節點會向**源站(Origin)**拉取一份并緩存在本地;
- CDN 緩存策略包括 TTL(Time-To-Live)、LRU 或 LFU,來自不同運營商或網絡環境下的緩存命中率優化直接影響用戶體驗與帶寬成本。
-
數據庫二級緩存
- ORM 框架(如 Hibernate)常集成二級緩存,將熱點實體緩存在本地 heap 或分布式緩存中;
- 在事務提交或數據更新時,需要將對應緩存項失效或更新;
- 緩存失效策略與事務邊界息息相關,需要設計清晰的緩存注解或 AOP 攔截器。
9. 小結
進程內緩存(堆內緩存) 的設計思路與常見實現:
-
緩存本質與應用場景
- 緩存用于調和下游“慢”與上游“快”之間的速度差異;
- 典型場景包括:熱點數據查詢、配置讀取、會話管理、短期臨時數據。
-
Guava LoadingCache
CacheBuilder提供靈活配置:maximumSize、initialCapacity、concurrencyLevel;- 支持手動
put()與自動加載(CacheLoader)兩種模式; - 可通過
invalidate()手動移除,并通過removalListener監聽刪除事件; - 回收策略包括基于容量(LRU)、基于時間(
expireAfterWrite/Access)與 JVM 引用回收(weakKeys/weakValues/softValues); - 避免“軟引用緩存顛簸”帶來的頻繁 GC 問題。
-
常見緩存算法
- FIFO:先進先出,簡單但不考慮熱點;
- LRU:最近最少使用,當前最流行,保留熱點;
- LFU:最近最不常用,保留高頻訪問數據,支持頻次計數;
-
簡易 LRU 實現
- 利用
LinkedHashMap構造參數accessOrder=true,覆寫removeEldestEntry; - 整體邏輯簡單,但不支持過期時間與并發安全,需要在生產環境中慎用或加鎖。
- 利用
-
操作系統緩存與預讀
- Linux 內核會自動執行 readahead,預讀后續頁面到
cached區域; - 可手動使用
mmap()、posix_fadvise()等方式實現“完全加載”,適用于小文件的高頻訪問。
- Linux 內核會自動執行 readahead,預讀后續頁面到
-
緩存優化一般思路
- 在緩存容量、命中率與 JVM GC 之間做折中;
- CDC(緩存、數據庫、集群)技術棧常見組合;
- 監控
cache.stats()指標,命中率需 ≥ 50% 才有較好收益;若 < 10% 則應卸載或重構緩存策略。
-
示例應用
- HTTP 304、CDN 緩存;
- 數據庫二級緩存;
- Redis 作為分布式緩存,面向更大規模數據。








)


)







動手實現多層感知機:深度學習中的非線性建模實戰)
