| 欄目 | 內容 |
|---|---|
| 論文標題 | 大型語言擴散模型 (Large Language Diffusion Models) |
| 核心思想 | 提出LLaDA,一種基于擴散模型的LLM,通過前向掩碼和反向預測過程建模語言分布,挑戰自回歸模型(ARM)在LLM領域的主導地位,并展示其在可擴展性、上下文學習、指令遵循和反向推理方面的強大能力。 |
| 模型名稱 | LLaDA (Large Language Diffusion with mAsking - 大型語言掩碼擴散模型) |
| 主要創新點 | 1. 新的LLM范式: 首次將掩碼擴散模型(MDM)從頭訓練到8B參數規模用于通用語言建模,證明其作為ARM替代方案的可行性。 2. 強大的綜合能力: LLaDA在預訓練后展現出與頂尖ARM(如LLaMA3 8B)相當的上下文學習能力,SFT后展現出優秀的指令遵循能力。 3. 解決“反轉詛咒”: LLaDA能有效處理需要反向推理的任務(如反向詩歌補全),表現優于GPT-40等強ARM。 4. 可擴展性驗證: 實驗證明LLaDA具備良好的可擴展性,性能隨計算資源增加而提升,與ARM基線具有競爭力。 5. 有原則的生成方法: 通過優化似然界限,為概率推斷提供了基于擴散的、有原則的生成途徑。 |
| 解決的問題 | 1. 挑戰“LLM必須是自回歸模型”的普遍觀念。 2. 探索克服ARM固有局限性(如順序生成成本高、左到右偏差導致的某些推理能力弱)的新途徑。 3. 為大型語言建模提供一種新的、有潛力的非自回歸架構。 |
| 關鍵技術 | 掩碼擴散模型(MDM)、前向掩碼過程(隨機比例掩碼)、反向去噪/預測過程(Transformer預測掩碼)、優化對數似然下界、監督微調(SFT)、低置信度重掩碼、半自回歸重掩碼。 |
| 實驗結果亮點 | LLaDA 8B Base在MMLU、GSM8K等基準上與LLaMA3 8B Base相當或更優;LLaDA 8B Instruct在多輪對話等指令任務上表現良好,并在反向詩歌補全任務中超越GPT-40。 |
| 未來展望 | 進一步擴大模型規模、探索多模態數據處理、集成提示調整技術、應用于基于Agent的系統、進行強化學習對齊等。 |
2)具體實現流程
LLaDA的實現流程主要包括預訓練、監督微調(SFT)和推理三個階段。
核心組件:掩碼預測器 (Mask Predictor)
- 這是一個標準的Transformer解碼器(但移除了因果掩碼,使其可以雙向關注上下文),用于根據部分掩碼的輸入序列
x_t來預測原始的、未掩碼的詞元x_0。
A. 預訓練 (Pre-training)
- 目標: 訓練掩碼預測器
p_θ以學習通用的語言表示和生成能力。 - 輸入:
- 大規模未標記文本語料庫 (例如,論文中使用了2.3萬億詞元)。
- 流程:
- 數據采樣: 從語料庫中隨機抽取一個干凈的文本序列
x_0。 - 時間步采樣: 隨機采樣一個時間步(掩碼比例)
t,其中t ~ Uniform(0, 1]。 - 前向掩碼過程 (Forward Masking Process):
- 對于
x_0中的每個詞元x_0^i,以概率t將其替換為特殊的[MASK]詞元,以概率1-t保持其不變,得到部分掩碼的序列x_t。 q(x_t | x_0):x_t^i = [MASK]with probt,x_t^i = x_0^iwith prob1-t.
- 對于
- 模型預測: 將部分掩碼的序列
x_t輸入到掩碼預測器p_θ(· | x_t)。 - 損失計算: 模型的目標是預測
x_t中所有被[MASK]替換的原始詞元。損失函數是只在被掩碼位置計算的交叉熵損失的負值(公式3)。這個損失是模型負對數似然的一個上界(公式4)。
L(θ) = -E_{t,x_0,x_t} [ (1/t) * (1/L) * Σ_{i=1}^{L} 1[x_t^i = M] log p_θ(x_0^i | x_t) ]
(其中1[x_t^i = M]是指示函數,表示x_t的第i個詞元是否為掩碼) - 優化: 通過梯度下降更新模型參數
θ以最小化損失L(θ)。
- 數據采樣: 從語料庫中隨機抽取一個干凈的文本序列
- 輸出:
- 預訓練好的掩碼預測器
p_θ(稱為 LLaDA Base 模型)。
- 預訓練好的掩碼預測器
B. 監督微調 (Supervised Fine-Tuning - SFT)
- 目標: 使預訓練的LLaDA模型具備遵循指令和特定任務的能力。
- 輸入:
- 高質量的指令-響應對數據
(prompt, response),即(p_0, r_0)。
- 高質量的指令-響應對數據
- 流程:
- 數據采樣: 從SFT數據集中獲取一個
(p_0, r_0)對。 - 條件掩碼: 保持提示
p_0不變。對響應r_0應用與預訓練類似的前向掩碼過程,得到掩碼后的響應r_t。 - 模型預測: 將提示
p_0和掩碼后的響應r_t一同(通常是拼接)輸入到預訓練好的掩碼預測器p_θ(· | p_0, r_t)。 - 損失計算: 模型的目標是預測
r_t中被掩碼的原始詞元。損失函數僅在響應r_t的掩碼位置計算交叉熵損失(公式5)。 - 優化: 更新模型參數
θ。
- 數據采樣: 從SFT數據集中獲取一個
- 輸出:
- 經過SFT的LLaDA Instruct模型。
C. 推理/采樣 (Inference/Sampling)
- 目標: 給定一個提示
p_0,生成連貫且相關的響應r_0。 - 輸入:
- 用戶提供的提示
p_0。 - 期望的生成長度
L_r(響應的長度)。 - 總采樣步數
N。
- 用戶提供的提示
- 反向去噪/生成過程 (Iterative Denoising/Generation Process):
- 初始化: 創建一個長度為
L_r的完全由[MASK]詞元組成的序列r_1(時間步t=1)。 - 迭代生成: 進行
N個采樣步驟。在每個步驟k(從1到N):
a. 當前時間步t_k = 1 - (k-1)/N,下一個時間步s_k = 1 - k/N。
b. 將當前提示p_0和部分掩碼的響應r_{t_k}輸入到訓練好的掩碼預測器p_θ。
c. 掩碼預測器輸出對r_{t_k}中所有[MASK]詞元的預測(通常是概率分布)。
d. 根據預測結果,填充這些[MASK]位置(例如,通過貪心采樣選擇最可能的詞元,或從分布中采樣),得到一個對原始響應的臨時估計r?_0。
e. 重掩碼 (Remasking): 為了過渡到下一個時間步s_k,需要對r?_0進行重掩碼,使其掩碼比例符合s_k。將r_{t_k}中未被掩碼的詞元保持不變,對于那些在r_{t_k}中被掩碼但在r?_0中被填充的詞元,根據目標掩碼比例s_k和當前比例t_k,按一定策略決定是保持填充的詞元,還是將其重新掩碼為[MASK],得到r_{s_k}。
* 常見重掩碼策略:
* 隨機重掩碼: 根據目標掩碼比例s_k隨機選擇詞元進行掩碼。
* 低置信度重掩碼: 優先將模型預測置信度最低的詞元重新掩碼,直到達到目標掩碼比例s_k。
* 半自回歸重掩碼: 將序列分成塊,從左到右依次生成每個塊。在塊內部,使用上述重掩碼策略之一。 - 最終輸出: 當所有
N步完成后 (即t趨近于0),得到的序列r_0即為最終生成的響應。
- 初始化: 創建一個長度為
- 輸出:
- 生成的文本響應。
D. 條件對數似然評估 (用于評估任務)
- 目標: 評估模型對于給定提示
p_0生成特定候選響應r_0的可能性。 - 流程:
- 多次重復以下操作 (Monte Carlo 估計):
a. 隨機選擇要掩碼的詞元數量l(從1到r_0的長度L'均勻采樣)。
b. 從r_0中隨機選擇l個詞元進行掩碼,得到r_l。
c. 將p_0和r_l輸入模型,計算模型對r_0中被掩碼的l個詞元進行正確預測的對數概率之和。 - 對所有重復的對數概率取平均,作為
log p_θ(r_0 | p_0)的估計。
- 多次重復以下操作 (Monte Carlo 估計):
這個流程概述了LLaDA如何從數據中學習,并最終生成文本或評估文本。核心在于迭代地掩碼和預測,通過擴散過程的思想來建模復雜的語言分布。
文章目錄
- 摘要
- 1. 引言
- 2. 方法
- 2.1. 概率公式
- 2.2. 預訓練
- 2.4. 推理
- 3. 實驗
- 3.1. LLaDA在語言任務上的可擴展性
- 3.2. 基準測試結果
- 3.3. 反向推理和分析
- 3.4. 案例研究
- 4. 相關工作
- 5. 結論與討論
摘要
自回歸模型(ARMs)被廣泛認為是大型語言模型(LLMs)的基石。我們通過引入LLaDA來挑戰這一觀念。LLaDA是一個在預訓練和監督微調(SFT)范式下從頭開始訓練的擴散模型。LLaDA模型通過前向數據掩碼過程和反向過程(由一個Vanilla Transformer參數化以預測掩碼詞元)來分布數據。通過優化似然界限,它為概率推斷提供了一種有原則的生成方法。在廣泛的基準測試中,LLaDA表現出強大的可擴展性,優于我們自建的ARM基線。值得注意的是,LLaDA 8B在上下文學習方面與像LLaMA3 8B這樣的強大LLM具有競爭力,并且在SFT之后,在多輪對話等案例研究中展現出令人印象深刻的指令遵循能力。此外,LLaDA解決了反轉詛咒問題,在反向詩歌補全任務中超越了GPT-40。我們的發現確立了擴散模型作為ARM的一種可行且有前景的替代方案,挑戰了上述關鍵LLM能力本質上與ARM相關的假設。項目頁面和代碼:https://ml-gsai.github.io/LLaDA-demo/。
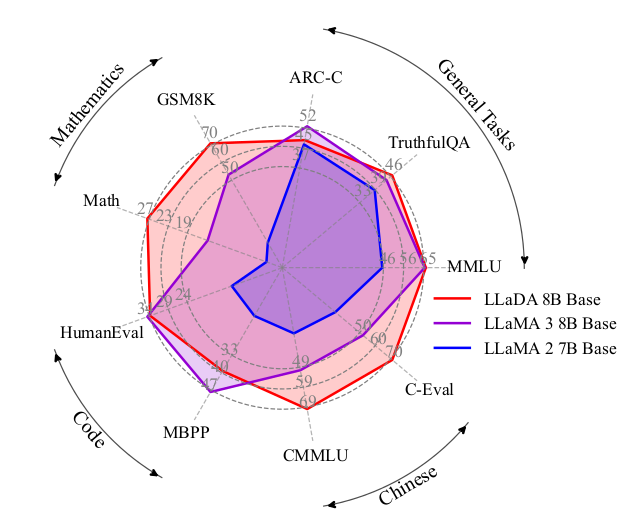
圖1. 零/少樣本基準測試。我們將LLaDA從頭開始擴展到前所未有的8B參數規模,在與強大LLM(Dubey等人,2024)的對比中取得了有競爭力的性能。圖表為一個雷達圖,中心有LLaDA 8B Base, LLaMA 3 8B Base, LLaMA 2 7B Base的圖例。坐標軸包括Mathematics (GSM8K, Math), Code (HumanEval, MBPP), Chinese (CMMLU, C-Eval), General Tasks (TruthfulQA, MMLU, ARC-C)。數據顯示LLaDA 8B Base(紅色)在多個任務上與LLaMA 3 8B Base(紫色)表現接近或更好,并優于LLaMA 2 7B Base(藍色)。
1. 引言
現在被證明的,曾經僅僅是想象。
——威廉·布萊克
大型語言模型(LLMs)(Zhao等人,2023)完全屬于生成建模的框架。具體來說,LLMs旨在通過優化模型分布pθ(·)來捕捉真實但未知的語言分布Pdata(·),方法是最大似然估計,或等效地最小化兩個分布之間的KL散度:

主要方法依賴于自回歸建模(ARM)——通常稱為下一詞元預測范式——來定義模型分布:
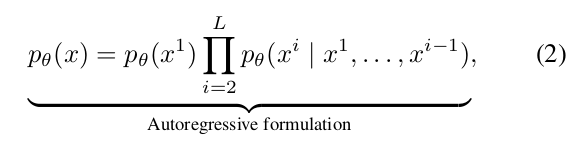
其中x是一個長度為L的序列,x?是第i個詞元。
這種范式已被證明非常有效(Radford,2018;Radford等人,2019;Brown,2020;OpenAI,2022),并已成為當前LLM的基礎。盡管其被廣泛采用,一個基本問題仍未得到解答:自回歸范式是實現LLM所展現智能的唯一可行路徑嗎?
我們認為答案并非簡單的“是”。先前被忽略的關鍵洞察在于:是生成建模原理(即公式(1)),而非自回歸公式(即公式(2))本身,從根本上支撐了LLM的基本屬性,如下文詳述。然而,LLM的某些固有局限性可以直接追溯到其自回歸特性。
特別地,我們認為可擴展性主要是Transformers(Vaswani,2017)、模型和數據規模以及由公式(1)中的生成原理引導的Fisher一致性1(Fisher,1922)之間相互作用的結果,而非ARM的獨特成果。擴散Transformer(Bao等人,2023;Peebles & Xie,2023)在視覺數據(Brooks等人,2024)上的成功支持了這一論點。
此外,指令遵循和上下文學習(Brown,2020)的能力似乎是所有結構一致的語言任務上合適的條件生成模型的內在屬性,而非ARM的專屬優勢。另外,雖然ARM可以被解釋為無損數據壓縮器(Deletang等人;Huang等人,2024b),任何充分表達的概率模型都可以實現類似的能力(Shannon,1948)。
然而,LLM的自回歸特性帶來了顯著的挑戰。例如,逐個詞元順序生成會產生高計算成本,而從左到右的建模限制了其在反向推理任務中的有效性(Berglund等人,2023)。這些固有的局限性約束了LLM處理更長和更復雜任務的能力。
受這些洞察的啟發,我們引入LLaDA(Large Language Diffusion with mAsking,大型語言掩碼擴散模型),以研究LLM所展現的能力是否可以從公式(2)之外的生成建模原理中產生,從而解決前面提出的基本問題。與傳統ARM不同,LLaDA利用掩碼擴散模型(MDM)(Austin等人,2021a;Lou等人,2023;Shi等人,2024;Sahoo等人,2024;Ou等人,2024),該模型包含一個離散隨機掩碼過程,并訓練一個掩碼預測器來近似其逆過程。這種設計使LLaDA能夠構建具有雙向依賴性的模型分布,并優化其對數似然的下界,為現有LLM提供了一種未被探索且有原則的替代方案。
我們采用數據準備、預訓練、監督微調(SFT)和評估的標準流程,將LLaDA擴展到前所未有的8B規模的語言擴散模型。具體來說,LLaDA 8B在2.3萬億詞元上從頭開始預訓練,使用了0.13百萬H800 GPU小時,然后在450萬對數據上進行SFT。在包括語言理解、數學、代碼和中文在內的各種任務中,LLaDA展示了以下貢獻:
可擴展性。 LLaDA有效地擴展到1023 FLOPs的計算預算,在六個任務(如MMLU和GSM8K)上,其結果與在相同數據上訓練的自建ARM基線相當。
上下文學習。 值得注意的是,LLaDA 8B在幾乎所有15個標準的零/少樣本學習任務上都超過了LLaMA2 7B(Touvron等人,2023),同時與LLaMA3 8B(Dubey等人,2024)表現相當。
指令遵循。 LLaDA在SFT后顯著增強了遵循指令的能力,如在多輪對話等案例研究中所示。
反向推理。 LLaDA有效地打破了反轉詛咒(Berglund等人,2023),在前向和反向任務中表現出一致的性能。值得注意的是,它在反向詩歌補全任務中優于GPT-40。
2. 方法
在本節中,我們介紹LLaDA的概率公式2,以及預訓練、監督微調和推理過程,如圖2所示。
2.1. 概率公式
與公式(2)中的ARM不同,LLaDA通過前向過程和反向過程(Austin等人,2021a;Ou等人,2024)定義模型分布pθ(x?)。前向過程逐漸獨立地掩碼x?中的詞元,直到在t=1時序列完全被掩碼。對于t ∈ (0,1),序列x?部分被掩碼,每個詞元以概率t被掩碼,或以概率1-t保持未掩碼。反向過程通過在t從1向0移動時迭代預測掩碼詞元來恢復數據分布。
LLaDA的核心是一個掩碼預測器,一個參數模型pθ(x?|x?),它以x?為輸入并同時預測所有掩碼詞元(表示為M)。它使用僅在掩碼詞元上計算的交叉熵損失進行訓練:
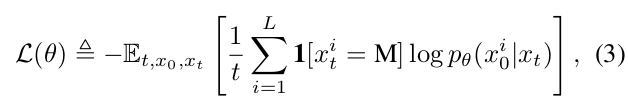
其中x?從訓練數據中采樣,t從[0,1]中均勻采樣,x?從前向過程中采樣。指示函數1[·]確保損失僅在掩碼詞元上計算。
一旦訓練完成,我們可以模擬一個由掩碼預測器參數化的反向過程(詳見2.4節),并將模型分布pθ(x?)定義為邊際分布。
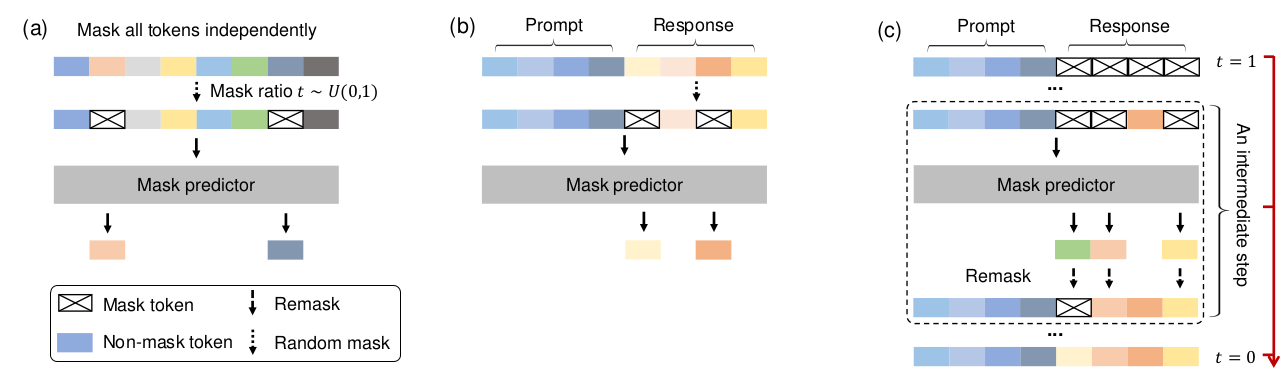
圖2. LLaDA概念概覽。(a) 預訓練。LLaDA在文本上進行訓練,文本中的所有詞元以相同比例 t ~ U[0, 1] 獨立隨機掩碼。(b) SFT。僅響應詞元可能被掩碼。? 采樣。LLaDA模擬一個從t=1(完全掩碼)到t=0(未掩碼)的擴散過程,在每個步驟中同時預測所有掩碼,并采用靈活的重掩碼策略。圖(a)顯示一個序列,所有詞元獨立掩碼,掩碼比例t從U(0,1)采樣,然后通過掩碼預測器。圖(b)顯示提示和響應,只有響應部分可能被掩碼,然后通過掩碼預測器。圖?顯示一個從t=1開始的迭代過程,通過掩碼預測器和重掩碼步驟,逐步去掩碼直到t=0,其中包含一個中間步驟的示意。
在t=0時誘導產生。值得注意的是,公式(3)中的損失已被證明是模型分布負對數似然的一個上界(Shi等人,2024;Ou等人,2024):
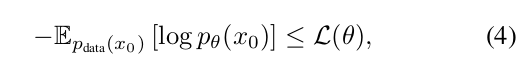
使其成為生成建模的一個有原則的目標。
值得注意的是,LLaDA采用在0和1之間隨機變化的掩碼比例,而掩碼語言模型(Devlin,2018)使用固定的比例。這些細微的差異具有顯著的影響,尤其是在大規模情況下:如公式(4)所示,LLaDA是一個有原則的生成模型,具有自然執行上下文學習的潛力,類似于LLM。此外,其生成視角確保了在極端情況下的Fisher一致性(Fisher,1922),表明其在大數據和模型方面的強大可擴展性。
2.2. 預訓練
LLaDA采用Transformer(Vaswani,2017)作為掩碼預測器,其架構類似于現有的LLM。然而,LLaDA不使用因果掩碼,因為其公式允許它看到整個輸入進行預測。
我們訓練了兩種不同大小的LLaDA變體:10億(B)和8B。我們在此總結了LLaDA 8B和LLaMA3 8B(Dubey等人,2024)的模型架構,并在附錄B.2中提供了詳細信息。我們確保了大多數超參數的一致性,同時進行了一些必要的修改。為簡單起見,我們使用標準的自注意力機制而非分組查詢注意力(Ainslie等人,2023),因為LLaDA與KV緩存不兼容,導致鍵和值頭的數量不同。因此,注意力層有更多參數,我們減少了FFN維度以保持相當的模型大小。此外,由于對我們的數據調整了分詞器(Brown,2020),詞匯表大小略有不同。
LLaDA模型在一個包含2.3萬億(T)詞元的數據集上進行預訓練,遵循與現有大型語言模型(LLM)(Touvron等人,2023;Chu等人,2024)緊密一致的數據協議,未加入任何特殊技術。數據來源于在線語料庫,通過手動設計的規則和基于LLM的方法過濾低質量內容。除了通用文本外,數據集還包含高質量的代碼、數學和多語言數據。數據源和領域的混合由縮小規模的ARM指導。預訓練過程使用固定的4096詞元序列長度,總計算成本為0.13百萬H800 GPU小時,與相同規模和數據集大小的ARM相似。
對于一個訓練序列x?,我們隨機采樣t ∈ [0,1],以相同的概率t獨立掩碼每個詞元得到x?(見圖2(a)),并通過蒙特卡洛方法估計公式(3)進行隨機梯度下降訓練。此外,遵循Nie等人(2024)的方法,為了增強LLaDA處理可變長度數據的能力,我們將1%的預訓練數據設置為從范圍[1, 4096]中均勻采樣的隨機長度。
我們采用Warmup-Stable-Decay(Hu等人,2024)學習率調度器來監控訓練過程,而不中斷連續訓練。具體來說,我們在最初的2000次迭代中將學習率從0線性增加到4 × 10??,并將其保持在4 × 10??。在處理了1.2T詞元后,我們將學習率衰減到1 × 10??,并在接下來的0.8T詞元中保持不變以確保穩定訓練。最后,在最后的0.3T詞元中,我們將學習率從1 × 10??線性降低到1 × 10??。此外,我們使用了AdamW優化器(Loshchilov,2017),權重衰減為0.1,批量大小為1280,每個GPU的本地批量大小為4。8B實驗執行了一次,沒有任何超參數調整。
2.3. 監督微調
我們通過使用配對數據(p?, r?)進行監督微調(SFT)來增強LLaDA遵循指令的能力,其中p?是提示,r?表示響應。這是LLM最簡單和最基本的后訓練方法。技術上,這需要在預訓練中建模條件分布pθ(r?|p?)而非pθ(x?)。
實現與預訓練類似。如圖2(b)所示,我們保持提示不變,并獨立地掩碼響應中的詞元,如同對x?所做的那樣。然后,我們將提示和掩碼后的響應r?都輸入到預訓練的掩碼預測器中,以計算SFT的損失:
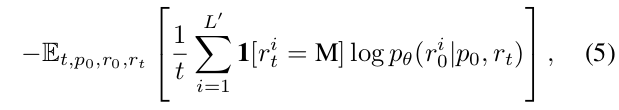
其中L’表示稍后指定的動態長度,所有其他符號與之前相同。
注意,這種方法與預訓練完全兼容。本質上,p?和r?的串聯可以被視為干凈的預訓練數據x?,而p?和r?的串聯則作為掩碼版本x?。該過程與預訓練相同,唯一的區別是所有掩碼詞元都恰好出現在r?部分。
LLaDA 8B模型在一個包含450萬對數據的數據集上進行SFT。與預訓練過程一致,數據準備和訓練都遵循現有LLM中使用的SFT協議(Chu等人,2024;Yang等人,2024),沒有引入任何額外的技術來優化LLaDA的性能。數據集涵蓋多個領域,包括代碼、數學、指令遵循和結構化數據理解。我們在每個小批量中的短對末尾附加|EOS|詞元,以確保所有數據的長度相等。我們在訓練期間將|EOS|視為普通詞元,并在采樣期間將其移除,從而使LLaDA能夠自動控制響應長度。
我們在SFT數據上訓練3個周期,使用與預訓練階段類似的調度。學習率在最初50次迭代中從0線性增加到2.5 × 10??,然后保持不變。在最后10%的迭代中,它線性降低到2.5 × 10??。此外,我們將權重衰減設置為0.1,全局批量大小為256,每個GPU的本地批量大小為2。SFT實驗執行了一次,沒有任何超參數調整。
2.4. 推理
作為一個生成模型,LLaDA既能采樣新文本,也能評估候選文本的似然。
我們從采樣開始。如圖2?所示,給定一個提示p?,我們離散化反向過程以從模型分布pθ(r?|p?)中采樣,從完全掩碼的響應開始。總采樣步數是一個超參數,這自然為LLaDA提供了效率和樣本質量之間的權衡,如3.3節所分析。我們默認使用均勻分布的時間步。此外,生成長度也被視為一個超參數,指定采樣過程開始時完全掩碼句子的長度。如附錄B.4詳述,由于預訓練和SFT都是在可變長度的數據集上進行的,最終結果對這個長度超參數不敏感。
在從時間t ∈ (0,1]到s ∈ [0,t)的中間步驟中,我們將p?和r?都輸入掩碼預測器,并同時預測所有掩碼詞元。隨后,我們期望地對預測的詞元進行重掩碼以獲得r?,確保反向過程的轉換與前向過程對齊以進行準確采樣(Austin等人,2021a)。
原則上,重掩碼策略應該是純隨機的。然而,受LLM采樣中退火技巧(Holtzman等人,2019;Brown,2020)的啟發,我們探索了兩種確定性但有效的重掩碼策略。具體來說,類似于Chang等人(2022),我們基于預測的置信度,重掩碼預測詞元中置信度最低的那些,稱為低置信度重掩碼。此外,對于SFT后的LLaDA,我們可以將序列分成幾個塊,并從左到右生成它們,稱為半自回歸重掩碼。在每個塊內,我們應用反向過程進行采樣。我們在附錄B.3中提供了更多細節和消融研究。
對于條件似然評估,我們可以自然地利用公式(5)中的上界。然而,我們發現以下等效形式(Ou等人,2024)表現出更低的方差并且評估更穩定:
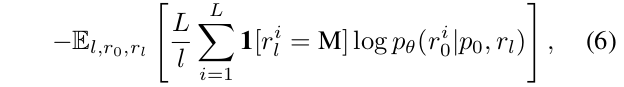
其中l從{1, 2, …, L’}中均勻采樣,r?是通過從r?中無放回地均勻采樣l個詞元進行掩碼得到的。此外,我們采用了無監督的分類器無關引導(Nie等人,2024)。我們請讀者參閱附錄A.2了解更多細節。
我們在附錄A中介紹了訓練、采樣和似然評估算法,以及理論細節。
3. 實驗
我們在標準基準上評估LLaDA的可擴展性、指令遵循和上下文學習能力,隨后在更受控的數據集上進行分析和案例研究,以提供全面的評估。
3.1. LLaDA在語言任務上的可擴展性
我們首先研究LLaDA在下游任務上與我們構建的ARM基線的可擴展性比較。
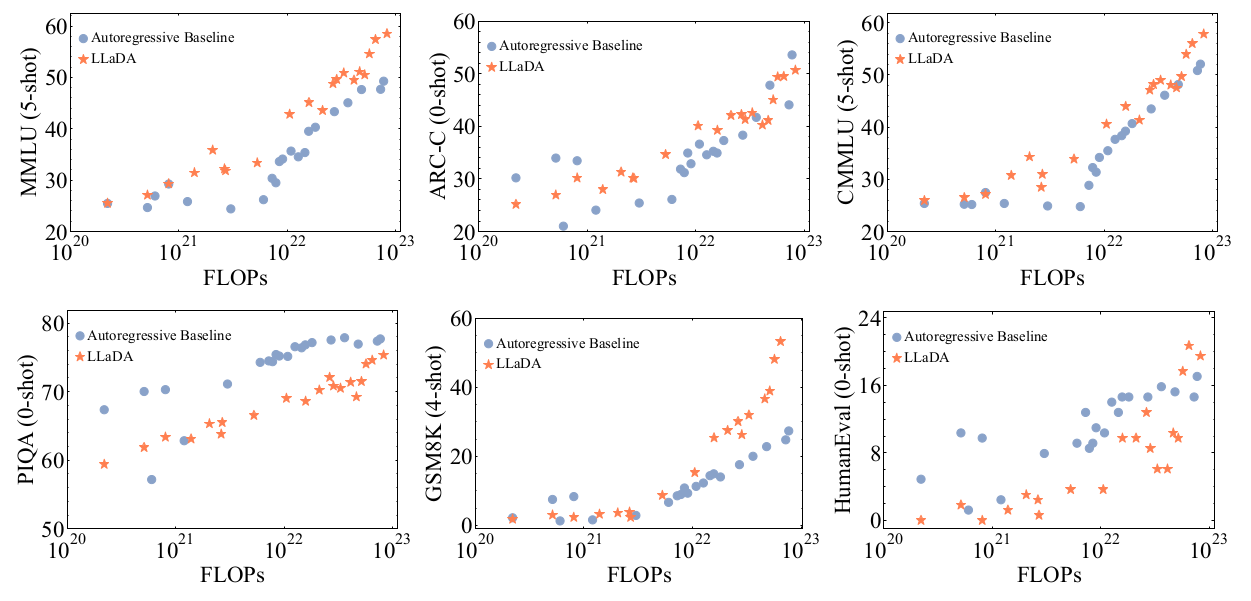
圖3. LLaDA的可擴展性。我們評估了LLaDA和我們在相同數據上訓練的ARM基線在計算FLOPs增加時跨六個任務的性能。LLaDA表現出強大的可擴展性,在六個任務上的整體性能與ARM相當。圖表包含六個子圖,分別對應MMLU (5-shot), ARC-C (0-shot), CMMLU (5-shot), PIQA (0-shot), GSM8K (4-shot), HumanEval (0-shot)。每個子圖的X軸是FLOPs (從102?到1023),Y軸是對應任務的得分。圖例顯示“? Autoregressive Baseline”和“★ LLaDA”。在MMLU和GSM8K上,LLaDA(橙色星號)的趨勢線似乎比自回歸基線(藍色圓點)略陡峭,表明更好的可擴展性。在其他任務上,兩者趨勢相似或LLaDA略遜一籌但差距隨FLOPs增加而縮小。
具體來說,在1B規模上,我們確保LLaDA和ARM共享相同的架構、數據和所有其他配置。在更大規模上,由于資源限制,我們還報告了LLaDA和ARM模型在略有不同大小、但在相同數據上訓練的結果,詳見附錄B.2。我們使用計算成本作為統一的擴展度量。評估時,我們關注六個標準且多樣化的任務。
如圖3所示,LLaDA表現出令人印象深刻的可擴展性,其總體趨勢與ARM高度競爭。值得注意的是,在MMLU和GSM8K等任務中,LLaDA表現出更強的可擴展性。即使在PIQA等性能落后的任務上,LLaDA在更大規模時也縮小了與ARM的差距。為了解釋異常值的顯著影響,我們選擇不擬合定量的擴展曲線,避免潛在的誤解。盡管如此,結果清楚地證明了LLaDA的可擴展性。
Nie等人(2024)指出,MDM需要比ARM多16倍的計算才能達到相同的似然。然而,有一些關鍵差異使得本研究的結論更具普適性。特別地,似然對于下游任務性能而言是一個相對間接的度量,并且擴散模型優化的是似然的一個界限,使其不能直接與ARM比較。此外,我們將Nie等人(2024)中的擴展范圍從101? ~ 102?擴展到本工作中的102? ~ 1023。
3.2. 基準測試結果
為了全面評估LLaDA 8B的上下文學習和指令遵循能力,我們與現有類似規模的LLM(Touvron等人,2023;Dubey等人,2024;Chu等人,2024;Yang等人,2024;Bi等人,2024;Jiang等人,2023)進行了詳細比較。任務的選擇和評估協議與現有研究一致,涵蓋了通用任務、數學、代碼和中文領域的15個流行基準。更多細節在附錄B.5中提供。為了更直接的比較,我們在我們的實現中重新評估了代表性的LLM(Touvron等人,2023;Dubey等人,2024)。
如表1所示,在2.3T詞元上預訓練后,LLaDA 8B表現出卓越的性能,在幾乎所有任務上都超過了LLaMA2 7B,并且總體上與LLaMA3 8B具有競爭力。LLaDA在數學和中文任務上顯示出優勢。我們推測其優勢與在某些任務上表現相對較弱的原因相同——數據質量和分布的差異,這很大程度上是由于LLM數據集的閉源情況。
值得注意的是,我們通過以GSM8K為例仔細排除了數據泄露的可能性。首先,如圖3所示,LLaDA在GSM8K方面優于ARM基線。此外,結論在一個完全未見的類似GSM8K的任務(Ye等人,2024)上仍然成立,詳見附錄B.7。
此外,表2比較了LLaDA 8B Instruct與現有LLM的性能。我們觀察到SFT提高了LLaDA在大多數下游任務上的性能。一些指標,如MMLU,有所下降,我們推測這可能是由于SFT數據質量欠佳所致。總體而言,由于我們沒有進行強化學習(RL)對齊,我們的結果略遜于LLaMA3 8B Instruct,盡管許多指標的差距仍然很小。值得注意的是,即使僅通過SFT,LLaDA也展現出令人印象深刻的。
表1. 預訓練LLM的基準測試結果。 * 表示LLaDA 8B Base、LLaMA2 7B Base和LLaMA3 8B Base在相同協議下評估,詳見附錄B.5。?和?標記的結果分別來源于Chu等人(2024);Yang等人(2024)和Bi等人(2024)。括號中的數字表示評估使用的shot數。“-”表示未知數據。
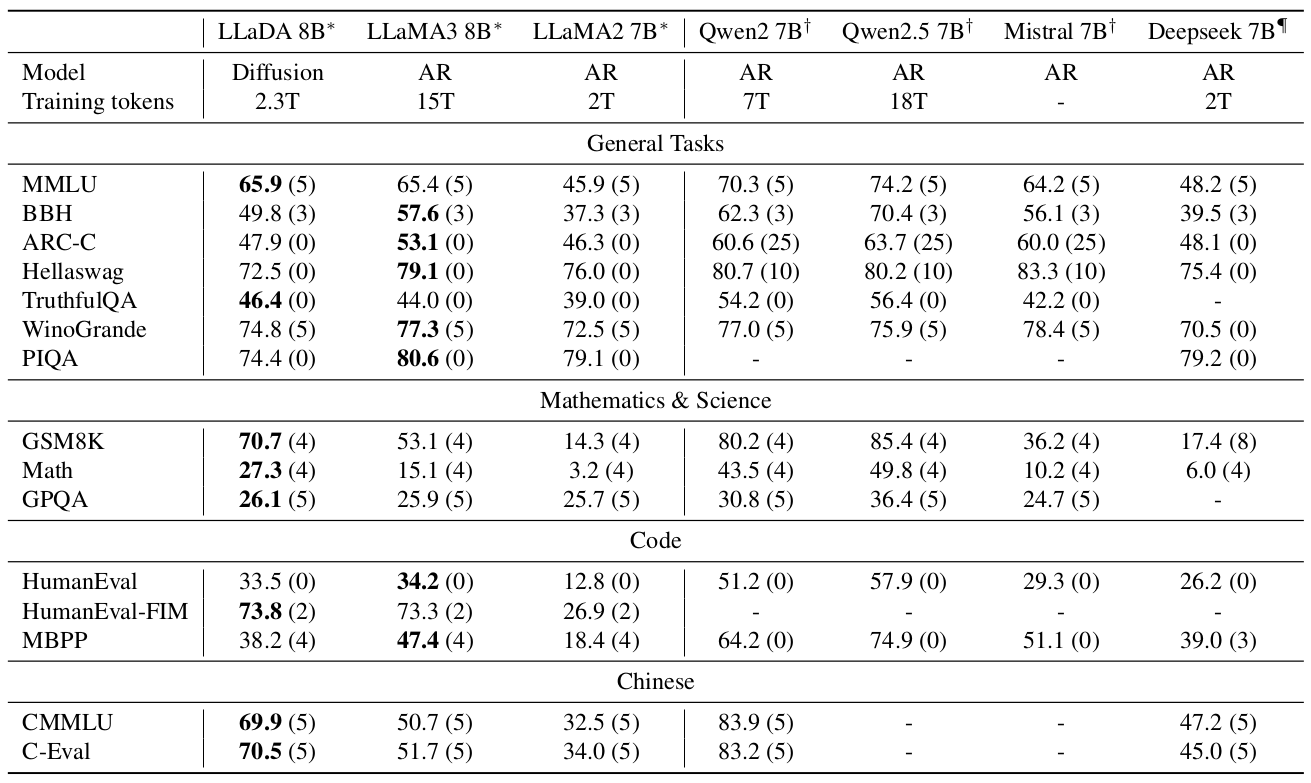
表2. 后訓練LLM的基準測試結果。 LLaDA僅采用SFT程序,而其他模型有額外的強化學習(RL)對齊。* 表示LLaDA 8B Instruct、LLaMA2 7B Instruct和LLaMA3 8B Instruct在相同協議下評估,詳見附錄B.5。?和?標記的結果分別來源于Yang等人(2024)和Bi等人(2024)。括號中的數字表示上下文學習使用的shot數。“-”表示未知數據。
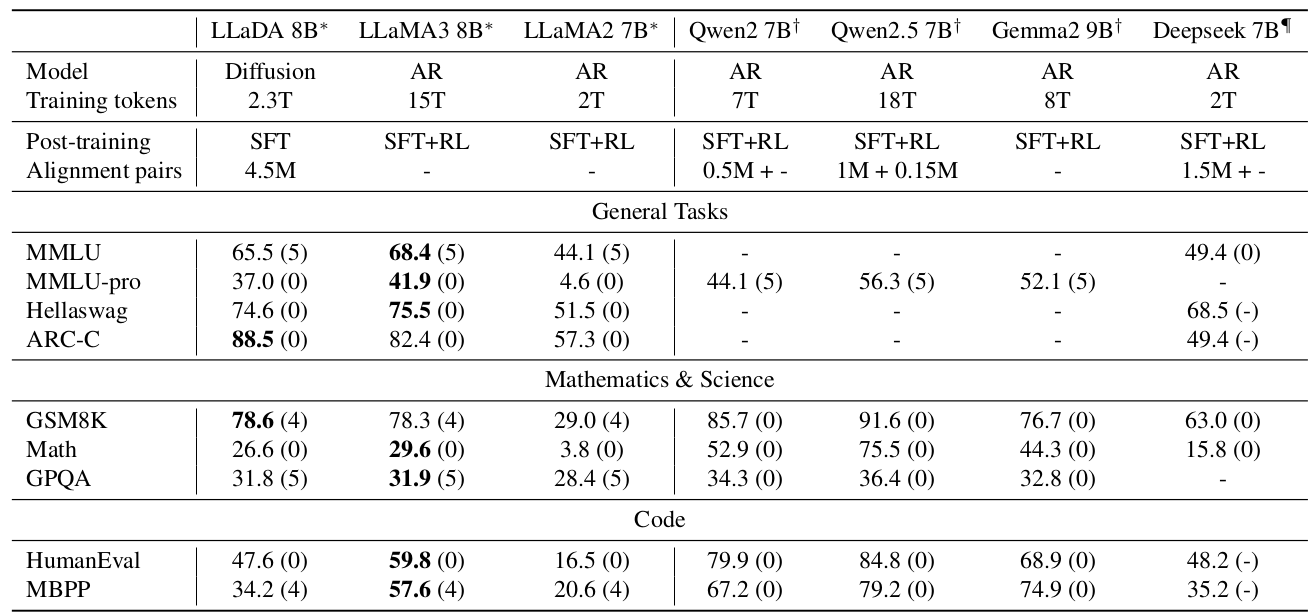
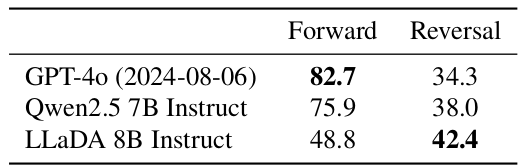
表3. 詩歌補全任務中的比較。
指令遵循能力,詳見3.4節。我們將基于RL的對齊留作未來工作。
總的來說,盡管數據透明度不足,我們已盡一切努力采用標準化程序并引入多樣化的任務,我們相信它們足以證明LLaDA的非凡能力,據我們所知,這是唯一具有競爭力的非自回歸模型。
3.3. 反向推理和分析
為了量化模型的反向推理能力(Berglund等人,2023),我們遵循Allen-Zhu & Li(2023)建立的協議。具體來說,我們構建了一個包含496對著名中國古詩句的數據集。給定一首詩中的一句,模型任務是生成下一句(正向)或前一句(反向),無需額外微調。示例可在附錄B.8中找到。與以往研究(Nie等人,2024;Kitouni等人,2024)相比,此設置提供了更直接和更現實的評估。
如表3所示,LLaDA有效地解決了反轉詛咒(Berglund等人,2023),在正向和反向任務中均表現出一致的零樣本性能。相比之下,Qwen 2.5和GPT-40在這兩者之間都表現出顯著的差距。正向生成的結果證實了這兩個ARM都很強大,受益于遠大于LLaDA的數據集和計算資源。然而,LLaDA在反向任務中大幅優于兩者。
我們強調,我們沒有為反向任務設計任何特殊的東西。直觀地說,LLaDA統一對待詞元而沒有歸納偏置,從而導致平衡的性能。更多細節請參見附錄A.2。
我們還在附錄B.3和附錄B.6中分析了重掩碼策略和采樣步驟的影響。
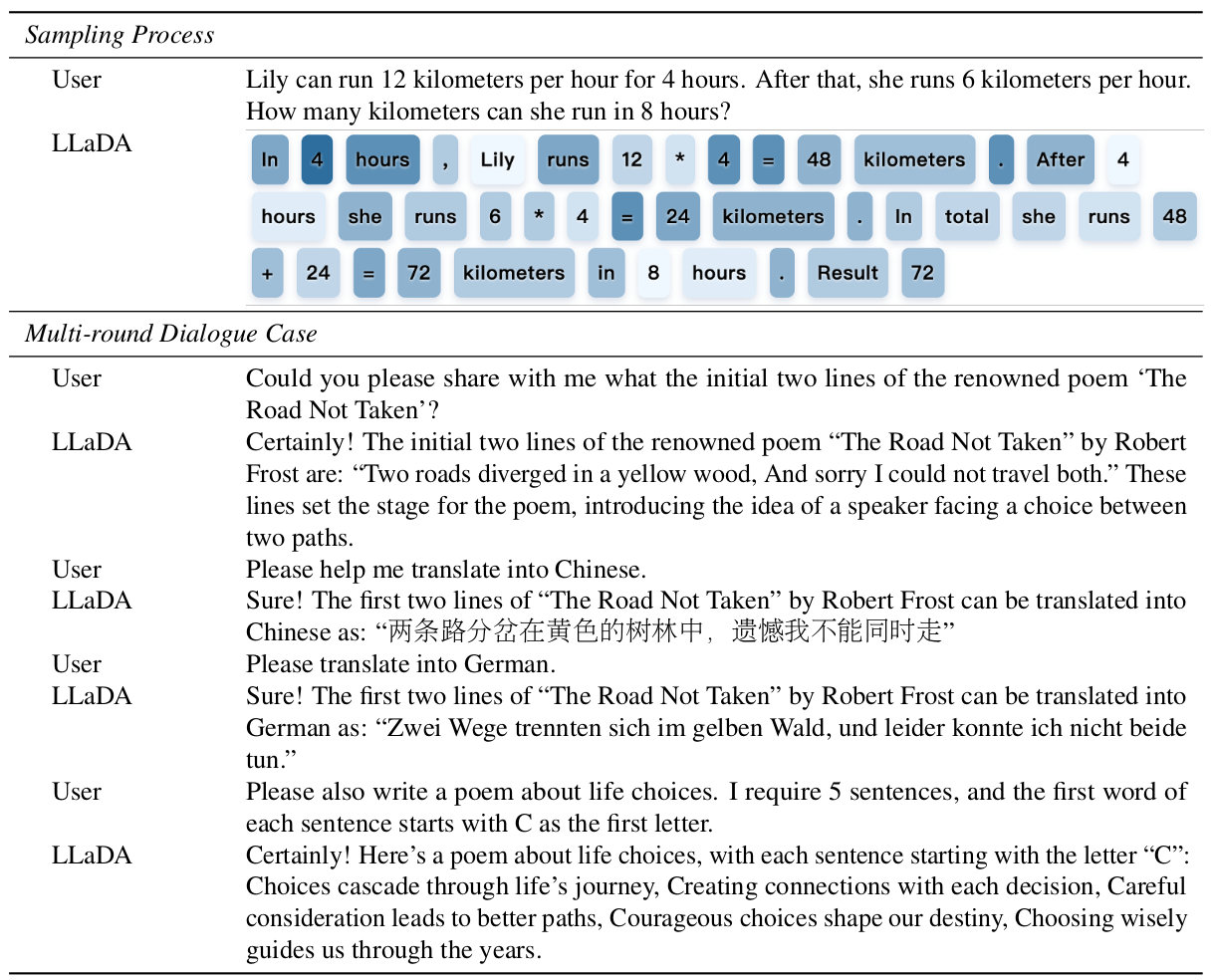
3.4. 案例研究
我們在表4中展示了LLaDA 8B Instruct生成的樣本,展示了其指令遵循能力。首先,該表說明了LLaDA以非自回歸方式生成連貫、流暢和擴展文本的能力。其次,它突出了模型的多輪對話能力,能夠跨多種語言有效地保留對話歷史并產生上下文適當的響應。LLaDA的這種聊天能力令人印象深刻,因為據我們所知,這是它首次偏離傳統ARM。更多關于重掩碼和推理任務的案例研究見附錄B.9。
4. 相關工作
擴散模型(Sohl-Dickstein等人,2015;Ho等人,2020;Song等人,2020)在視覺領域表現出色,但盡管付出了大量努力,在LLM方面仍未得到驗證。
一種簡單的方法是將文本數據連續化并直接應用擴散模型(Li等人,2022;Gong等人,2022;Han等人,2022;Strudel等人,2022;Chen等人,2022;Dieleman等人,2022;Richemond等人,2022;Wu等人,2023;Mahabadi等人,2024;Ye等人,2023b)。或者,一些方法轉而對離散分布的連續參數進行建模(Lou & Ermon,2023;Graves等人,2023;Lin等人,2023;Xue等人,2024)。然而,可擴展性仍然是一個挑戰,因為一個1B參數模型需要ARM 64倍的計算才能達到相當的性能(Gulrajani & Hashimoto,2024)。
另一種方法是用具有新的前向和反向動態的離散過程取代連續擴散(Austin等人,2021a),從而產生了許多變體(Hoogeboom等人,2021b;a;He等人,2022;Campbell等人,2022;Meng等人,2022;Reid等人,2022;Sun等人,2022;Kitouni等人,2023;Zheng等人,2023;Chen等人,2023;Ye等人,2023a;Gat等人,2024;Zheng等人,2024;Sahoo等人,2024;Shi等人,2024)。值得注意的是,Lou等人(2023)表明,掩碼擴散作為離散擴散的一種特殊情況,在GPT-2規模上實現了與ARM相當或超過ARM的困惑度。Ou等人(2024)建立了基本的理論結果,這啟發了我們的模型設計、訓練和推理(見附錄A)。Nie等人(2024)探索了如何在GPT-2規模上利用MDM進行語言任務,如問答。Gong等人(2024)在MDM公式中微調ARM。然而,改進僅限于某些指標,并且尚不清楚這種方法是否能在全面評估下產生與強大LLM相當的基礎模型。
相比之下,本研究將MDM從頭開始擴展到前所未有的8B參數規模,實現了與LLaMA 3等領先LLM相當的性能。
此外,圖像生成方面的一系列并行工作(Chang等人,2022;2023)與MDM在文本數據上的應用非常吻合。此外,MDM在蛋白質生成等領域也顯示出潛力(Wang等人,2024b;c),并取得了有希望的結果。值得注意的是,Kou等人(2024);Xu等人(2025)展示了使用蒸餾加速MDM采樣的潛力,進一步提高其效率。
表4. 采樣過程和生成的多輪對話可視化。 在LLaDA的響應中,較深的顏色表示在采樣后期預測的詞元,而較淺的顏色對應于較早的預測。
5. 結論與討論
困難之中蘊藏機遇。
——阿爾伯特·愛因斯坦
我們引入LLaDA,一種基于擴散模型的、有原則且先前未被探索的大型語言建模方法。LLaDA在可擴展性、上下文學習和指令遵循方面表現出強大的能力,實現了與強大LLM相當的性能。此外,LLaDA提供了獨特的優勢,如雙向建模和增強的魯棒性,有效地解決了現有LLM的一些固有局限性。我們的發現不僅確立了擴散模型作為一種可行且有前景的替代方案,而且挑戰了這些基本能力本質上與ARM相關的普遍假設。
盡管前景看好,擴散模型的全部潛力仍有待充分探索。這項工作的幾個局限性為未來的研究提供了重要機會。
由于計算限制,LLaDA和ARM之間的直接比較——例如在相同數據集上訓練——被限制在小于1023 FLOPs的計算預算內。為了分配資源訓練盡可能大的LLaDA模型并展示其潛力,我們未能將ARM基線擴展到相同程度。此外,沒有為LLaDA設計專門的注意力機制或位置嵌入,也沒有應用任何系統級的架構優化。在推理方面,我們對引導機制(Dhariwal & Nichol,2021;Ho & Salimans,2022)的探索仍處于初步階段,LLaDA目前對推理超參數表現出敏感性。此外,LLaDA尚未經歷與強化學習的對齊(Ouyang等人,2022;Rafailov等人,2024),這對于提高其性能和與人類意圖的對齊至關重要。
展望未來,LLaDA的規模仍小于領先的對應模型(Achiam等人,2023;Dubey等人,2024;Google,2024;Anthropic,2024;Yang等人,2024;Liu等人,2024),這突出表明需要進一步擴展以全面評估其能力。此外,LLaDA處理多模態數據的能力仍未被探索。LLaDA對提示調整技術(Wei等人,2022)的影響及其與基于代理的系統(Park等人,2023;Wang等人,2024a)的集成尚待充分理解。最后,對LLaDA進行系統的后訓練研究可能有助于開發類O1系統(OpenAI,2024;Guo等人,2025)。
算法1 LLaDA的預訓練
需要: 掩碼預測器 pθ, 數據分布 Pdata
1: repeat
2: x? ~ Pdata, t ~ U(0, 1] # 以1%的概率,x?的序列長度遵循U[1, 4096]
3: x? ~ q?|?(x?|x?) # q?|? 定義在公式(7)
4: 計算 L = - (1/(t*L)) * Σ_{i=1}^{L} 1[x?? = M] log pθ(x??|x?) # L是x?的序列長度
5: 計算 ?θL 并運行優化器。
6: until 收斂
7: Return pθ
算法2 LLaDA的監督微調
需要: 掩碼預測器 pθ, 配對數據分布 Pdata
1: repeat
2: p?, r? ~ Pdata, t ~ U(0, 1] # SFT數據處理詳情請參閱附錄B.1
3: r? ~ q?|?(r?|r?) # q?|? 定義在公式(7)
4: 計算 L = - (1/(t*L’)) * Σ_{i=1}^{L’} 1[r?? = M] log pθ(r??|p?, r?) # L’是r?的序列長度
5: 計算 ?θL 并運行優化器。
6: until 收斂
7: Return pθ
算法3 LLaDA的條件對數似然評估
需要: 掩碼預測器 pθ, 提示 p?, 響應 r?, 蒙特卡洛估計次數 nmc
1: log_likelihood = 0
2: for i ← 1 to nmc do
3: l ~ {1, 2, …, L} # L是r?的序列長度
4: 通過從r?中無放回地均勻采樣l個詞元進行掩碼得到r?
5: log_likelihood = log_likelihood + (1/l) * Σ_{j=1}^{L} 1[r?? = M] log pθ(r??|p?, r?)
6: end for
7: log_likelihood = log_likelihood / nmc
8: Return log_likelihood






string的模擬實現)
![學習筆記(24): 機器學習之數據預處理Pandas和轉換成張量格式[2]](http://pic.xiahunao.cn/學習筆記(24): 機器學習之數據預處理Pandas和轉換成張量格式[2])
)




)
![[概率論基本概念4]什么是無偏估計](http://pic.xiahunao.cn/[概率論基本概念4]什么是無偏估計)




