監聽式協議******:
思想:
每個Cache除了包含物理存儲器中塊的數據拷貝之外,也保存著各個塊的共享狀態信息。
Cache通常連在共享存儲器的總線上,當某個Cache需要訪問存儲器時,它會把請求放到總線上廣播出去,其他各個Cache控制器通過監聽總線(它們一直在監聽)來判斷它們是否有總線上請求的數據塊。如果有,就進行相應的操作。
3個關鍵:
1:處理器之間通過一個可以實現廣播的互連機制相連 (鏈接)
2:當一個處理器的Cache響應本地CPU的訪問時,如果它涉及全局操作,其Cache控制器就要在獲得總線的控制權后,在總線上發出相應的消息(發送者)
3:所有處理器都一直在監聽總線,它們檢測總線上的地址在它們的Cache中是否有副本。若有,則響應該消息,并進行相應的操作 。(接受者)
寫操作的串行化:由總線實現(獲取總線控制權的順序性)
發送到總線的信息:1-讀不命中 ;2-寫不命中
這個時候需要通過總線找到相應的數據塊的最新版本,然后調入本地的cache
(cache的種類:
寫直達Cache:因為所有寫入的數據都同時被寫回主存,所以從主存中總可以取到其最新值。
寫回Cache:得到數據的最新值會困難一些,因為最新值可能在某個Cache中,也可能在主存中。
)
我們就考慮難的!(簡單的也不出題)
有時候,還有多出來一個發送的消息:Invalidate消息,用來通知其他各處理器作廢其Cache中相應的副本。
(這個和WriteMiss是有區別的,WriteMiss是寫不命中,然后回去調取對應的塊,但是這個無效化不會)
下面我們先確定好一些概念:
概念;
Cache的標識(tag)可直接用來實現監聽。
作廢一個塊只需將其有效位置為無效。
給每個Cache塊增設一個共享位:為“1”:多個處理器所共享,為“0”:某個處理器所獨占
塊的擁有者:擁有該數據塊的唯一副本的處理器。
每個節點內部會有一個有限狀態的控制器;
無效(簡稱I):Cache中該塊的內容為無效。
共享(簡稱S):該塊可能處于共享狀態。(要求共享的塊的內容都要相同)
已修改(簡稱M):該塊已經被修改過,并且還沒寫入存儲器。(要確保這個獨占,全系統唯一)
所以我們現在來總體的考慮具體的情況*******;
I:請求來自處理器:(發送)
(
處理器可能會:讀命中,讀不命中,寫命中,寫不命中,
但是最后發出去的消息只可能是:讀寫不命中和Invalidate
cache可能是IMS,三個狀態之一
)
(注意這里都是針對的塊)
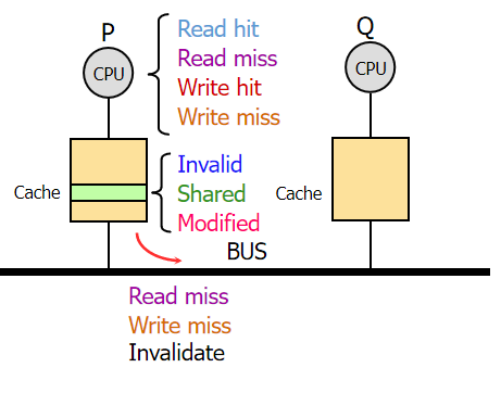
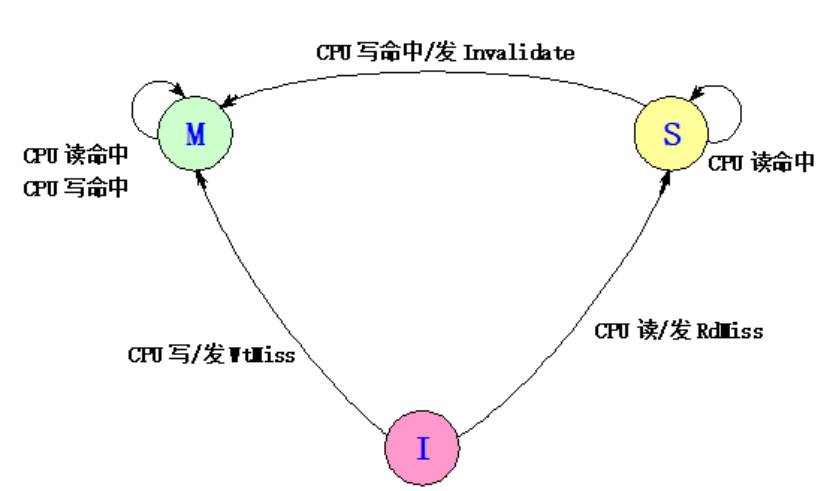
1:什么時候讀命中?
要不cache對應的塊是S要不就是M,如果是I的話就是讀不命中了
(表格,狀態機,圖例如下)
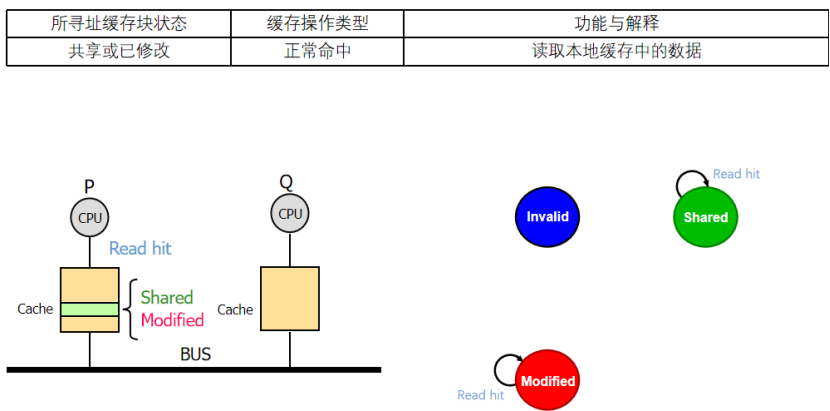
2:什么時候讀不命中
我們的cache塊是失效I的,我們需要把讀不命中放在總線去
我們的cache塊雖然是S,但是地址不對,我們也需要把讀不命中放在總線
我們的cache塊雖然是M,但是地址不對,我要先寫回這個塊,然后再去把讀不命中放總線
對于第一種情況,讀入的就是共享的數據了(不管是來自其他的cache還是存儲器),所以I->S,這里的S強調一致性,cache和存儲的一致性
第二種得到數據后也是share,只是對應的地址塊不同了
第三種會把M->S,然后回顯寫回塊,然后再去替換
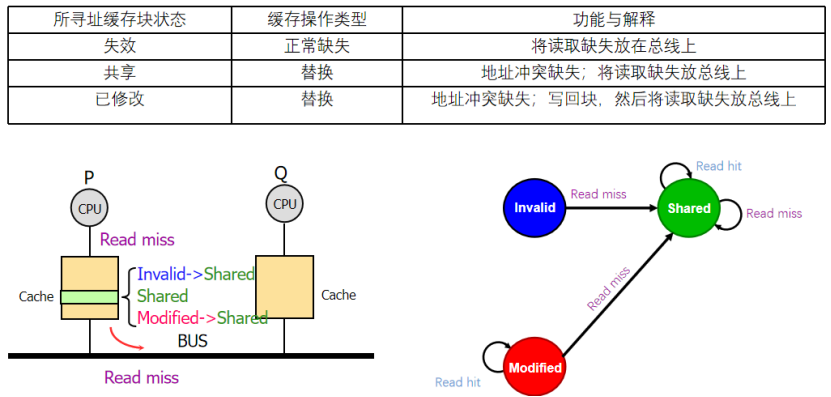
3:什么時候寫命中?
如果是I,那就是寫不命中了,因為這個數據塊無效的,不會發生寫命中
如果是S,將其修改為M,然后發出I消息,作廢這個塊上的其他版本(命中==地址是對的)
如果是M,我們會把自然的寫入數據(不會寫回存儲器,因為最新版本都在他自己身上)
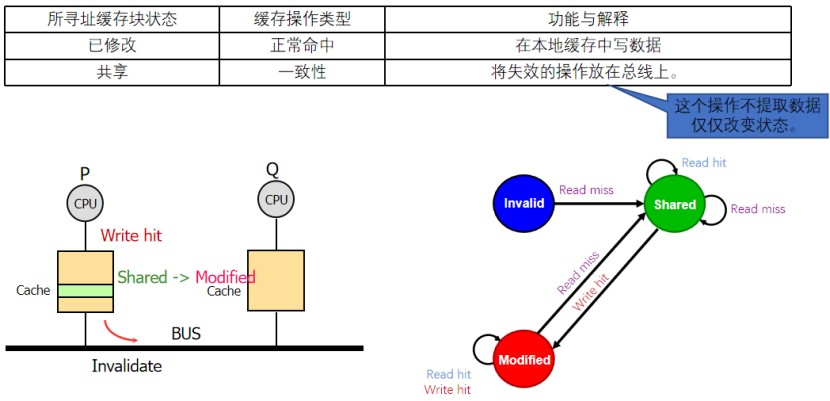
4:什么時候寫不命中?
如果我們對應的塊是I,可能是不命中了,發出寫不命中的消息,嘗試讓別人提供給他目標的塊,然后去寫入
如果對應的塊是S,但是不是對應的地址,把寫不命中放在總線上,嘗試讓別人去提供目標塊,然后去寫入對應的位置
如果對應的塊是M,但是地址不對應,就會先寫回這里的地址,然后把寫不命中發出,讓別人給他這個目標快,然后去寫入
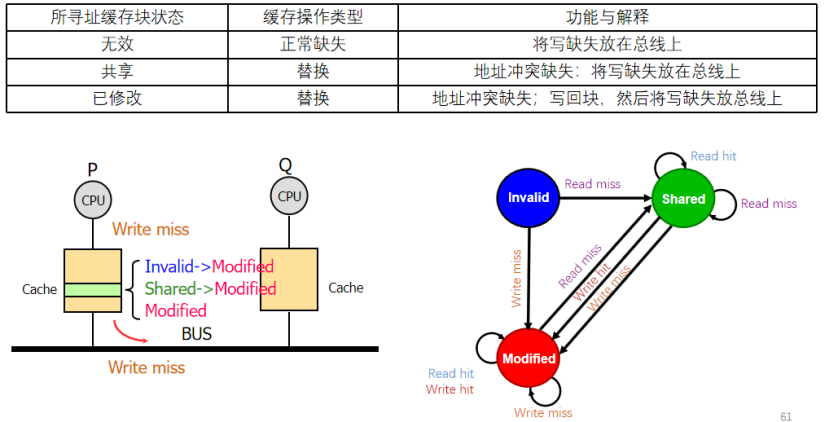
(在這可以思考下,如果是S的其他處理器收到了對應塊位置的寫不命中消息,會干甚?是不是地址不對了,對應記錄的數據就無效了?讓我們接下來看看)
II:請求來自總線(接收)
(
總線會發來:兩個不命中和Invalidate3個信息
我們的caceh狀態可能是IMS3個中的一個
)
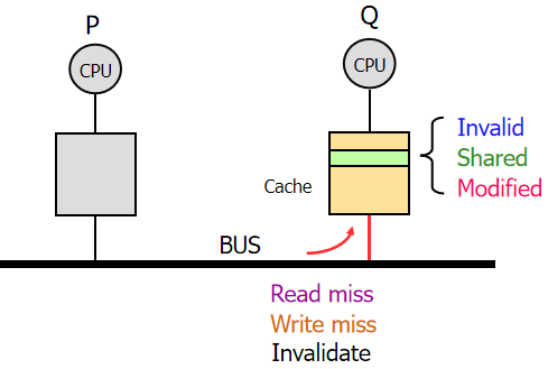
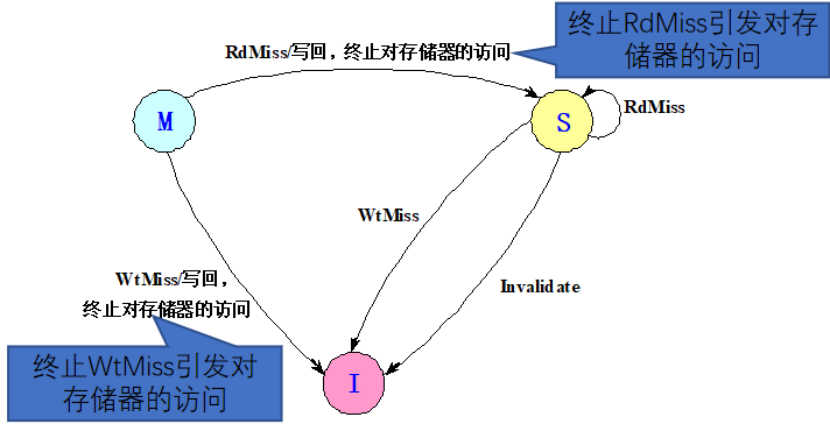
1:收到讀不命中怎么辦?
先想想什么時候別人的cache會發送讀不命中,是不是IMS都有可能!
想想什么時候我們的cache會收到影響?什么時候我們會去響應這個信號!!我們有對應的數據(SM),嘗試去共享!!!
如果我們是I或者是和我們的地址不對應,肯定不會響應的,因為我干不了什么事情
如果我們是匹配的S,我們就是不是可能嘗試去共享這個數據給發送者(也可能對方更快的找到了存儲器,因為數據是一致的)!!!
如果我們是匹配的M,我們是不是也會嘗試去共享,但是注意!!!!!!共享之后我們的狀態還是獨占嗎?不是了,所以要先寫回數據,并且中止他對存儲器的訪問,因為存儲器的數據錯誤!!!!!然后去共享數據,把M->S
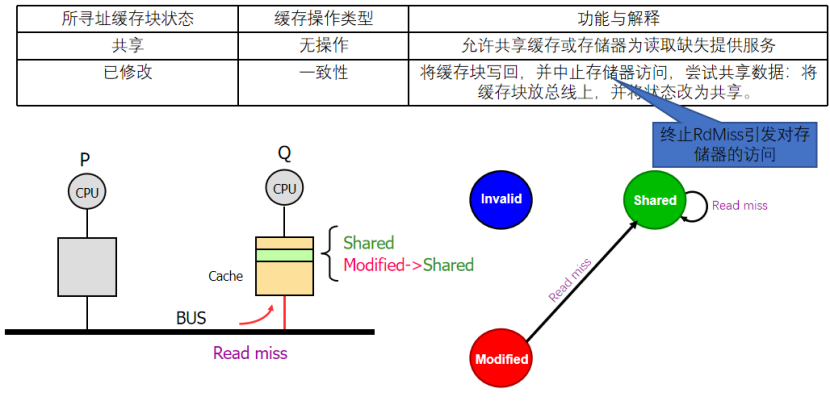
2 :? 什么時候會收到寫不命中??
首先,對方寫不命中,之后肯定會寫入到cache中,并做一個獨占是吧,所以為什么我們會響應這個寫不命中尼?是不是就是要去寫的就是我們現在擁有的那個,所以我們可能是SM
首先,可能是地址匹配我才會去管是吧,然后如果本來就是I就不用管,其他的S,M都要變成I
(但是由于設計的原因,發送方需要把數據得到后再去寫入,所以這里的S可以嘗試共享,M就要同時提供給發送發和存儲器)
為什么要這么設計???
因為我們的cache里面是存的是cache塊,里面不是一個數據,是一堆數據,只是里面的部分數據修改了,所以不能夠發送方直接拿著自己的塊就開始寫,顯然是不對的,所以需要拿到整個塊(包括修改部分的相鄰數據),然后再去寫里面對應的地方
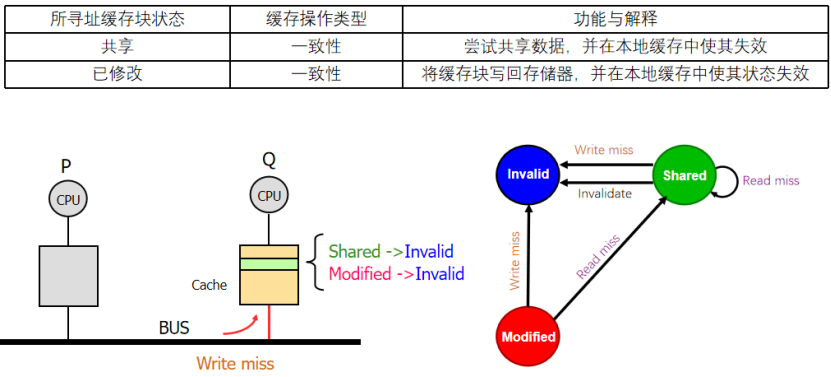
3:什么時候會收到失效?
肯定是有處理器嘗試去寫入共享塊,才會發出一個信息讓共享塊失效,所以我們回一下,是不是只有寫命中的S會發出這個信號!!!!(寫命中的M不會發出,反正都是他自己獨占)
那么對應的,會收到影響的是不是也就只是對應地址的S狀態!!!!
(M收不到,因為如果一個塊唄獨占了,外面不會發生命中)
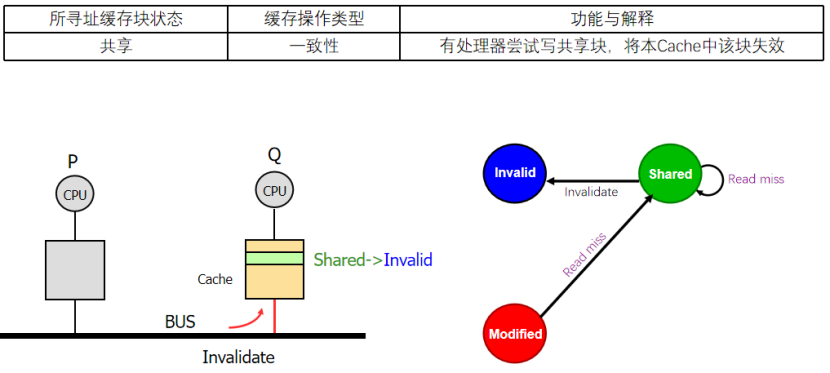
好了,這樣的話,我們就算是梳理完成了
整理一下
相應(接收)請求的狀態機
(開始回憶,什么時候收到失效?我們做出了什么狀態的變化?什么時候收到讀不命中?我們會做出什么變化?什么時候回收到寫不命中?我們的那些狀態改變了?中間我們做了哪些事情?)
發出請求的時候的狀態機:
(我們有哪4種情況?會發出哪3個消息,每個不同的情況我們會做什么?什么時候讀命中?針對我們自己那些狀態會改變?什么時候讀不命中?我們的那些狀態會改變?什么時候回寫命中?我們的那些狀態會改變?什么時候寫不命中?我們的狀態會發生什么改變?
)
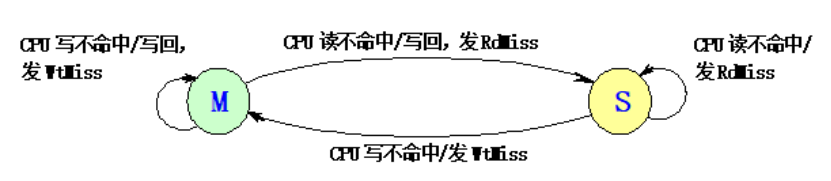
發生替換時:
如果發生替換的話:
總結一下問題:
1:并發問題,因為這個都是假定的每個操作具有原子性,但是實際不是的,可能會有死鎖,競爭,可以通過發送Invalidate的cpu占用總線來解決
2:一個塊一開始不在cache中,讀取的時候會變成share(他是唯一的緩存副本,但是還是會按照多個版本的去處理)
進一步的優化:加入一個狀態表示數據是干凈的 or owned
string的模擬實現)
![學習筆記(24): 機器學習之數據預處理Pandas和轉換成張量格式[2]](http://pic.xiahunao.cn/學習筆記(24): 機器學習之數據預處理Pandas和轉換成張量格式[2])
)




)
![[概率論基本概念4]什么是無偏估計](http://pic.xiahunao.cn/[概率論基本概念4]什么是無偏估計)










