點一下關注吧!!!非常感謝!!持續更新!!!
Java篇:
- MyBatis 更新完畢
- 目前開始更新 Spring,一起深入淺出!
大數據篇 300+:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 數據挖掘(已更完)
- Prometheus(已更完)
- Grafana(已更完)
- 離線數倉(已更完)
- 實時數倉(正在更新…)
- Spark MLib (正在更新…)
背景情況
在以往的開發任務中,我們發現隨著項目規模的擴大,AI 模型容易出現“前后不一致”的問題:它在處理后續邏輯時,常常遺忘前面的上下文,從而引發新的 Bug。
本質上,這是因為模型的上下文窗口存在限制。早期 GPT-4 僅支持 4K 上下文,后來 GPT-4 Turbo 提升到了 128K,而如今部分前沿模型已支持高達 1M 的上下文長度。
當前,行業內的技術演進主要集中在兩個方向:一是不斷擴展上下文長度,二是持續增加模型參數量。但無論上下文有多大,總會有裝不下的內容;即便模型參數再龐大,也依然可能生成不準確、不連貫的結果。
因此,為了解決這一類“遺忘”問題,社區逐步發展出一系列策略:從擴大上下文窗口,到引入 RAG(Retrieval-Augmented Generation)與摘要機制;從 Step-by-Step 的逐步推理,到 Chain-of-Thought(思維鏈)等更復雜的推理結構。這些方法的共同目標,都是延長模型的思考過程、緩存關鍵信息,以對抗其作為概率模型帶來的推理局限。
恰巧在上周的分享會上,有人提到在 AI 協助開發的過程中,經常會遇到“遺忘”或“執行偏差”的問題。我當時也簡單分享了幾個應對思路。借這個機會,順便整理一下目前社區中較為標準的解決方案。
Sequential Thinking
項目地址
https://github.com/modelcontextprotocol/servers/tree/main/src/sequentialthinking
能夠將復雜的問題拆分成一個個可管理的小步驟,讓 AI 可以逐步進行分析和處理。例如,在處理一個復雜的編程任務時,它會把任務分解為多個子任務,如先確定算法框架,再處理數據輸入輸出,最后進行代碼優化等。
配置方式
MCP的配置方式老生常談了,全部略過。
npx -y @modelcontextprotocol/server-sequential-thinking
JSON內容如下:
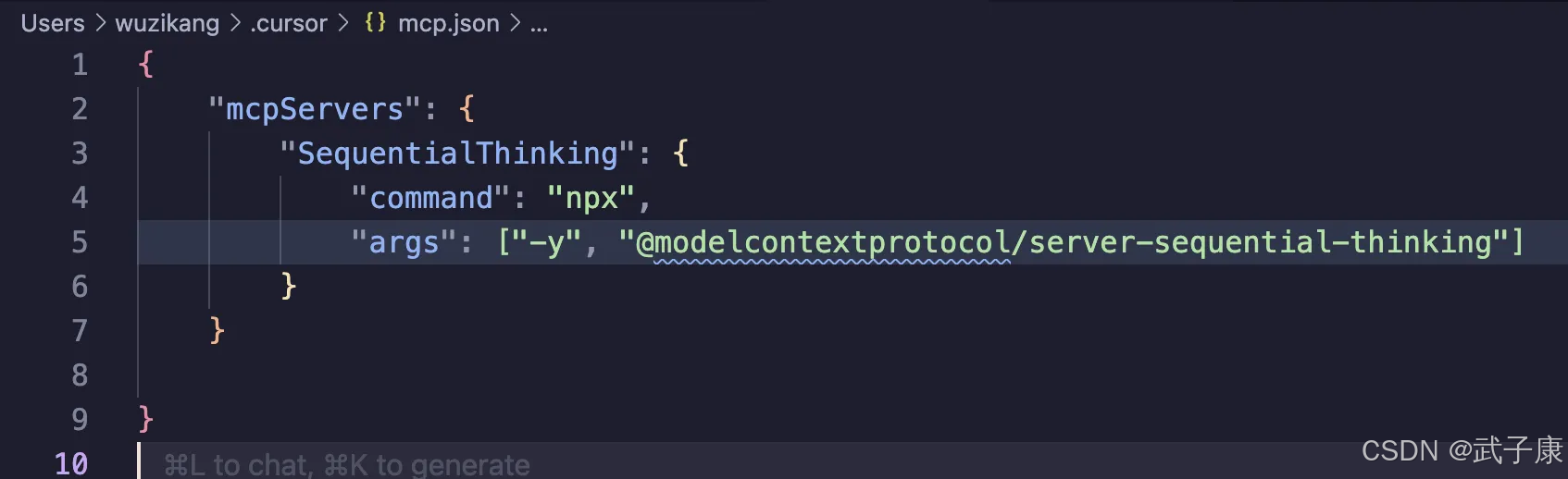
{"mcpServers": {"SequentialThinking": {"command": "npx","args": ["-y", "@modelcontextprotocol/server-sequential-thinking"] }}
}
配置結果如下:
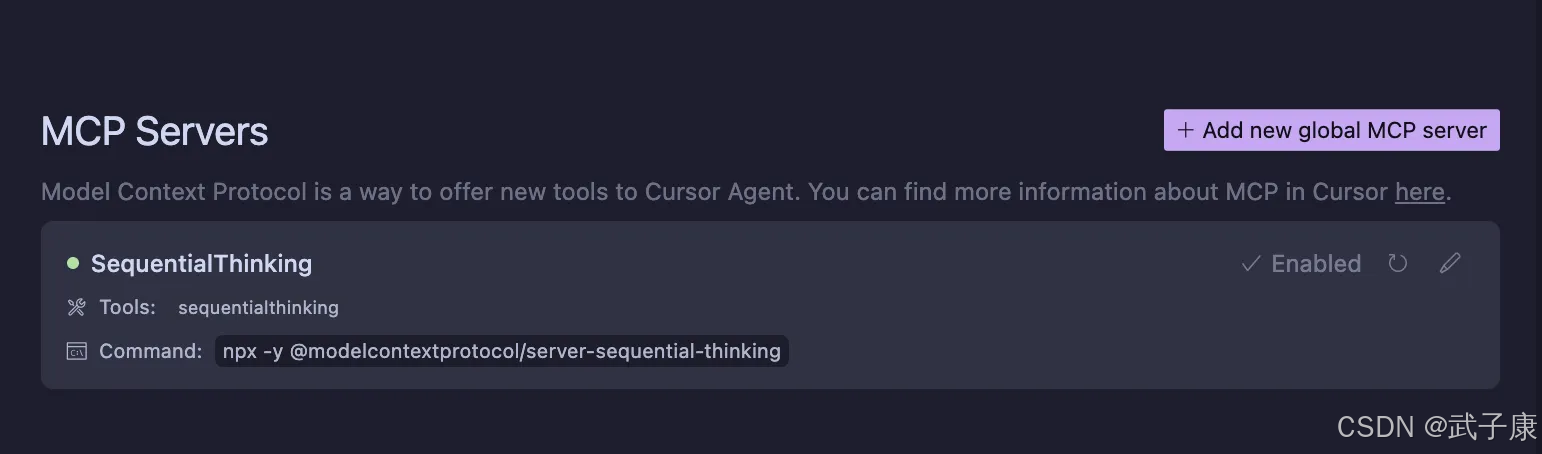
確保Cursor中的狀態是正常的:
使用方式
對于一些復雜問題,可以使用Sequential Thinking服務,將復雜問題分解為小的問題,逐個解決。同時每調用一次,都可以從thought中獲取到LLM當前的思考過程以及采取的方法,有時還會提供多種方案,我們可以通過再次提問,實現對于方案的選取以及之前思考過程的調整。
請你使用思考能力,完成XXXXXXX的任務。
這樣會調用 Sequential Thinking,對任務進行詳細的拆解,避免出現比如:“實現一個購物系統”,這樣寬泛的需求而大模型無法理解的問題。
Server Memory
項目地址
https://github.com/modelcontextprotocol/servers/tree/main/src/memory
能夠讓 AI 記住之前的信息和交互內容,在處理后續任務時可以調用這些記憶,從而更連貫地進行分析和處理。例如,在進行多輪對話的編程對話時,AI 可以記住之前用戶提出的代碼問題和已解決的部分,在后續交流中基于這些記憶給出更合適的建議和指導。
配置方式
MCP配置略過
npx -y @modelcontextprotocol/server-memory
一般都是將思考和記憶放到一起使用,對應的JSON如下:
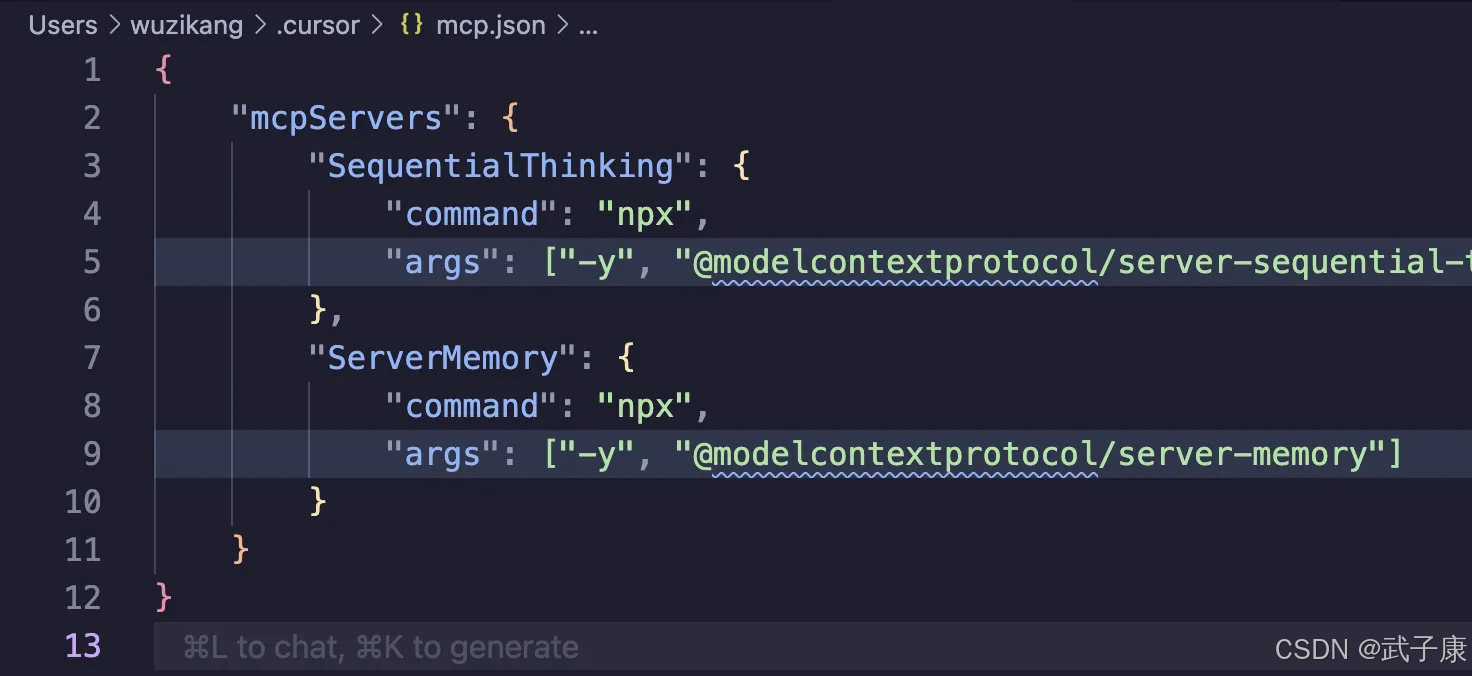
{"mcpServers": {"SequentialThinking": {"command": "npx","args": ["-y", "@modelcontextprotocol/server-sequential-thinking"] },"ServerMemory": {"command": "npx","args": ["-y", "@modelcontextprotocol/server-memory"]}}
}配置完的結果如下:
使用方式
對于一些需要多輪交互且依賴之前信息的復雜問題,可以使用 Server Memory 服務。比如在進行項目需求分析時,用戶不斷補充和修改需求,AI 能夠記住之前的需求內容,在后續分析中綜合考慮,給出更全面準確的分析結果。
隨便測試一個結果:

可以看到思考完成后,會進行緩存:


)



)
算法詳解)
)










”)
