Pytorch知識點
- 1、官方教程
- 2、張量
- 🧱 0、數組概念
- 🧱 1. 創建張量
- 📐 2. 張量形狀與維度
- 🔢 3. 張量數據類型
- ? 4. 張量的數學與邏輯操作
- 🔄 5. 張量的就地操作
- 📦 6. 復制張量
- 🚀 7. 將張量移動到加速器(如 GPU)
- 🔄 8. 操作張量的形狀
- 🔗 9. PyTorch 與 NumPy 的橋接
- 張量匯總1
- 1. **張量基礎**
- 2. **張量屬性**
- 3. **張量操作**
- 4. **設備管理**
- 5. **形狀調整**
- 6. **與 NumPy 互操作**
- 7. **其他重要功能**
- 總結
- 張量匯總2
- **一、張量基礎**
- **二、內存布局(Strides)**
- **三、張量操作**
- **四、原地操作**
- **五、設備與加速**
- **六、自動求導(Autograd)**
- **七、與NumPy互操作**
- **八、最佳實踐**
- 3、數據集(PyTorch)
- 3.1 加載已有數據集格式
- 3.2 自定義數據集
- 3.3 變換(transforms)
- 4、構建神經網絡
- **1.核心類:`torch.nn.Module` 與 `torch.nn.Parameter`**
- **1. `torch.nn.Module`**
- **2. `torch.nn.Parameter`**(訪問參數)
- 3. torch.functional
- 4. torch.optim
- **2. 常用層類型**
- **線性層 (`torch.nn.Linear`)**
- **卷積層 (`torch.nn.Conv2d`)**
- **循環層 (`torch.nn.LSTM`, `torch.nn.GRU`)**
- **Transformer**
- **3. 其他重要層與函數**
- **數據操作層**
- **激活函數**
- **損失函數**
- **4. 模型訓練流程**
- **5. 模型保存與加載**
- **6. 關鍵技巧**
- 5、torch.autograd 自動微分
- 1.計算圖
- 2.grad_fn、grad
- 例子
- 3.backward()
- 4.grad_fn、grad和backward()
- **1. `grad_fn`**
- **2. `grad`**
- **3. `backward()`**
- **協同工作流程**
- **三者的關系**
- **常見問題**
- **Q1: 為什么非葉子節點的 `grad` 默認為空?**
- **Q2: 如何強制保留非葉子節點的梯度?**
- **Q3: 向量輸出如何調用 `backward()`?**
- **總結**
- 5.Autograd匯總
- **Autograd 的核心作用**
- **Autograd 的使用示例**
- **訓練中的 Autograd 實踐**
- **Autograd 的控制與優化**
- **總結**
- 6.動態圖
- 6、Python with 語句
- 一、`with` 語句的執行流程
- 二、`with` 語句的等價替換代碼
- 三、代碼示例:文件操作的展開對比
- 7、with torch.no_grad() 禁用梯度跟蹤
- 一、為什么需要 `torch.no_grad()`?
- 二、`with torch.no_grad():` 的具體行為
- 三、代碼示例:對比有無 `no_grad` 的差異
- 示例 1:禁用梯度后,新 Tensor 的 `requires_grad` 行為
- 示例 2:禁用梯度對內存和計算速度的影響(推理場景)
- 四、常見使用場景
- 五、注意事項
- 六、與 `model.eval()` 的關系
- 總結
- 8、model.train()和model.eval()
- 0.匯總
- 1. **`model.train()`**
- 2. **`model.eval()`**
- 3. **`model.test()`(自定義方法)**
- 4.關鍵區別總結
- 5.最佳實踐
- 9、設置訓練設備accelerator
- 10、優化器(torch.optim)
- **1. 核心功能**
- **2. 常見優化器**
- **2.1 SGD(隨機梯度下降)**
- **2.2 Adam(自適應矩估計)**
- **2.3 RMSprop**
- **2.4 Adagrad**
- **3. 優化器核心操作**
- **3.1 初始化優化器**
- **3.2 `zero_grad()`**
- **3.3 `loss.backward()`**
- **3.4 `step()`**
- **3.5 `state_dict()` 和 `load_state_dict()`**
- **4. 學習率調整(`lr_scheduler`)**
- **4.1 StepLR**
- **4.2 ReduceLROnPlateau**
- **4.3 CosineAnnealingLR**
- **5. 完整訓練流程示例**
- **6. 高級用法**
- **6.1 為不同參數組設置不同超參數**
- **6.2 添加鉤子(Hook)**
- **7. 總結**
- 11、TensorBoard 可視化模型、數據和訓練
- 12、Captum(次要)
- 13、深度學習書籍
- 14、入門實戰示例
- 1、TorchVision-FashionMNIST
- 2、TorchText--NLP
- 3、強化學習
- 4、秘籍--PyTorch 代碼示例集
1、官方教程
官方的三部教程:

閱讀循序:
1.使用 PyTorch 進行深度學習:60 分鐘閃電戰
https://pytorch.ac.cn/tutorials/beginner/deep_learning_60min_blitz.html
2.學習基礎知識
https://pytorch.ac.cn/tutorials/beginner/basics/intro.html
3.PyTorch 入門 - YouTube 系列
https://pytorch.ac.cn/tutorials/beginner/introyt/introyt_index.html
官方教程:
中文:
https://pytorch.ac.cn/
https://pytorch.ac.cn/tutorials/beginner/basics/quickstart_tutorial.html
https://pytorch.ac.cn/tutorials/beginner/basics/tensorqs_tutorial.html
https://github.com/pytorch/tutorials.git
其他:https://www.runoob.com/pytorch/pytorch-datasets.html
英文:
https://pytorch.org/
https://docs.pytorch.org/tutorials/
快速入門參考:https://blog.csdn.net/weixin_44986037/article/details/129843027
2、張量
參考:
https://pytorch.ac.cn/tutorials/beginner/introyt/tensors_deeper_tutorial.html#
https://pytorch.ac.cn/tutorials/beginner/blitz/tensor_tutorial.html
《深入理解 PyTorch 張量教程》是 PyTorch 官方提供的一篇詳細教程,旨在幫助初學者深入理解 torch.Tensor 類的核心概念和操作。以下是該教程的中文總結:
(注意,view 是 PyTorch 中的版本,對應于 Numpy 的 reshape)
🧱 0、數組概念
詳細請參考:鏈接https://blog.csdn.net/weixin_44986037/article/details/148317613?
在 NumPy 中,維數(Dimensions)=維度(Dimensions)=秩(Rank)、軸(Axis)、形狀(Shape) 是描述數組結構的關鍵概念。它們相互關聯但側重點不同,以下是詳細解釋和對比:
總結關系
- 秩 = 軸的數量 = 維數(維度數);
- 形狀描述各軸的長度,其元組長度等于秩;
- 軸用于指定操作的方向(如
axis=0表示行方向)。
例如,一個形狀為 (3, 4, 5) 的數組:
- 秩為 3(3 個軸);
- 軸 0 長度為 3,軸 1 長度為 4,軸 2 長度為 5 。
概念解釋
- 維數 / 維度 (Dimensions)=秩(Rank):指數組存在的方向數量(即數組是幾維的),指的是數組的秩(rank)即數組的
軸(axis)數量,也就是數組嵌套的層數。例如,一維數組的維度是1,二維數組的維度是2,以此類推。 - 軸(Axes):軸是數組的一個特定方向,
每個維度對應一個軸,軸從外向內編號(從0開始)。在一維數組中,只有一個軸(軸0);在二維數組中,有兩個軸,軸0表示行,軸1表示列;在三維數組中,軸0通常表示深度,軸1表示行,軸2表示列。三維數組:軸0是最外層(如多個二維數組堆疊),軸1是行方向,軸2是列方向。 - 形狀(Shape):形狀是描述數組在
每個維度上元素數量的元組,其長度等于秩。描述每個維度的大小的元組,形狀的元素數 = 維數/秩。形狀是一個元組,它表示數組在每個軸上的大小。例如, 一維數組[1, 2, 3]的形狀為(3,)(1 個軸,長度為 3);二維數組[[1, 2], [3, 4]]的形狀為(2, 2)(2 個軸,每個軸長度為 2);三維數組[[[1, 2], [3, 4]], [[5, 6], [7, 8]]]的形狀為(2, 2, 2)(3 個軸,每個軸長度為 2)。
🧱 1. 創建張量
- 基礎創建:使用
torch.empty()創建一個未初始化的張量。
x = torch.empty(3, 4)print(x)
這將創建一個形狀為 3x4 的張量,內容為未初始化的值。
-
常見初始化方法:
-
torch.zeros(2, 3):創建一個 2x3 的零張量。 -
torch.ones(2, 3):創建一個 2x3 的全一張量。 -
torch.rand(2, 3):創建一個 2x3 的隨機浮點數張量,值在 [0, 1) 之間。
-
-
隨機種子:使用
torch.manual_seed()設置隨機種子,確保結果可復現。
torch.manual_seed(1729)random_tensor = torch.rand(2, 3)print(random_tensor)
📐 2. 張量形狀與維度
- 查看形狀:使用
.shape屬性查看張量的形狀。
x = torch.empty(2, 2, 3)print(x.shape)
輸出:torch.Size([2, 2, 3])
- 與其他張量相同形狀:使用
torch.*_like()方法創建與另一個張量相同形狀的張量。([PyTorch 文檔][1])
zeros_like_x = torch.zeros_like(x)print(zeros_like_x.shape)
🔢 3. 張量數據類型
- 指定數據類型:在創建張量時使用
dtype參數指定數據類型。
a = torch.ones((2, 3), dtype=torch.int16)print(a)
- 類型轉換:使用
.to()方法將張量轉換為其他數據類型。
b = a.to(torch.float32)print(b)
? 4. 張量的數學與邏輯操作
- 常見操作:對張量進行加、減、乘、除、指數等操作。
ones = torch.ones(2, 2)twos = ones * 2fours = twos ** 2print(fours)
- 廣播機制:當進行操作的兩個張量形狀不同時,PyTorch 會自動擴展其中一個張量的維度,使其與另一個張量匹配,這稱為廣播機制。
rand = torch.rand(2, 4)doubled = rand * (torch.ones(1, 4) * 2)print(doubled)
🔄 5. 張量的就地操作
- 就地操作:使用帶有
_后綴的方法,如.add_()、.mul_(),可以直接修改原張量的值,而不是返回一個新的張量。
a = torch.ones(2, 2)b = torch.rand(2, 2)a.add_(b)print(a)
- 注意:就地操作會影響計算圖,可能會影響梯度計算。
📦 6. 復制張量
- 復制張量:使用
.clone()方法創建張量的副本。
a = torch.ones(2, 2)b = a.clone()print(b)
- 分離計算圖:使用
.detach()方法從計算圖中分離張量。
c = a.detach()print(c)
🚀 7. 將張量移動到加速器(如 GPU)
- 檢查加速器:使用
torch.cuda.is_available()檢查是否有可用的 GPU。
if torch.cuda.is_available():device = torch.device("cuda")else:device = torch.device("cpu")
- 移動張量:使用
.to(device)方法將張量移動到指定設備。
tensor = tensor.to(device)
🔄 8. 操作張量的形狀
- 添加維度:使用
.unsqueeze()方法在指定位置添加一個維度。([arxiv.org][2])
a = torch.rand(3, 226, 226)b = a.unsqueeze(0)print(b.shape)
- 移除維度:使用
.squeeze()方法移除維度為 1 的維度。
c = torch.rand(1, 20)d = c.squeeze(0)print(d.shape)
- 重塑形狀:使用
.reshape()方法改變張量的形狀。
output3d = torch.rand(6, 20, 20)input1d = output3d.reshape(6 * 20 * 20)print(input1d.shape)
🔗 9. PyTorch 與 NumPy 的橋接
- 從 NumPy 轉換為 PyTorch 張量:使用
torch.from_numpy()方法將 NumPy 數組轉換為 PyTorch 張量。
import numpy as npnumpy_array = np.ones((2, 3))pytorch_tensor = torch.from_numpy(numpy_array)print(pytorch_tensor)
- 從 PyTorch 張量轉換為 NumPy 數組:使用
.numpy()方法將 PyTorch 張量轉換為 NumPy 數組。
numpy_array = pytorch_tensor.numpy()print(numpy_array)
張量匯總1
以下是 PyTorch 官方教程 張量簡介 的核心內容匯總:
1. 張量基礎
- 定義:張量是 PyTorch 的核心數據抽象,類似于 NumPy 的多維數組,但支持 GPU 加速和自動梯度計算 。
- 創建方法:
torch.empty():分配內存但不初始化。torch.zeros()、torch.ones()、torch.rand():分別創建全零、全一、隨機值(0-1 之間)的張量。torch.tensor(data):直接從 Python 列表/元組創建,支持嵌套結構。- 示例:
x = torch.rand(2, 3) # 創建 2x3 的隨機張量 some_constants = torch.tensor([[3.14, 2.7], [1.6, 0.007]]) # 從數據直接創建
2. 張量屬性
- 形狀(Shape):通過
.shape查看維度,如x.shape返回torch.Size([2, 3])。 - 數據類型(Dtype):默認為
torch.float32,可通過dtype參數指定,如:a = torch.ones((2, 3), dtype=torch.int16) # 創建 16 位整數類型張量 - 設備(Device):默認在 CPU 上,可通過
device參數指定 GPU,如:if torch.cuda.is_available():gpu_tensor = torch.rand(2, 2, device="cuda") # 移動到 GPU
3. 張量操作
- 數學運算:
- 支持標量和逐元素運算(加減乘除、冪等),如:
ones = torch.zeros(2, 2) + 1 # 全零張量加 1 twos = torch.ones(2, 2) * 2 # 全一張量乘 2 - 廣播機制:允許形狀不同的張量進行運算,規則與 NumPy 一致。例如:
rand = torch.rand(2, 4) doubled = rand * (torch.ones(1, 4) * 2) # 1x4 張量廣播至 2x4
- 支持標量和逐元素運算(加減乘除、冪等),如:
- 就地操作:通過下劃線
_后綴修改原張量,如:a = torch.tensor([1, 2]) a.add_(torch.tensor([3, 4])) # a 現在為 [4, 6]
4. 設備管理
- 檢查設備可用性:
if torch.cuda.is_available(): # 或 torch.mps.is_available()(Mac)device = torch.device("cuda") else:device = torch.device("cpu") - 張量移動:使用
.to(device)在 CPU/GPU 間切換:tensor = tensor.to("cuda") # 移動到 GPU
5. 形狀調整
- 增減維度:
unsqueeze(dim):增加指定維度(大小為 1)。squeeze(dim):刪除指定維度(大小必須為 1)。- 示例:
img = torch.rand(3, 226, 226) # 單張圖像 batch_img = img.unsqueeze(0) # 添加批次維度 -> [1, 3, 226, 226]
- 重塑形狀:
reshape()改變張量形狀但保留元素數量:output3d = torch.rand(6, 20, 20) input1d = output3d.reshape(6*20*20) # 轉為一維
6. 與 NumPy 互操作
- 雙向轉換:
torch.from_numpy():從 NumPy 數組創建張量。.numpy():將張量轉換為 NumPy 數組。
- 共享內存:轉換后的對象共享底層內存,修改會互相影響:
numpy_array = np.ones((2, 3)) pytorch_tensor = torch.from_numpy(numpy_array) numpy_array[1, 1] = 23 # pytorch_tensor 的對應值也會變為 23
7. 其他重要功能
- 隨機種子:通過
torch.manual_seed()確保結果可復現。 - 克隆與分離:
clone():復制張量及其梯度計算歷史。detach():分離張量以停止梯度跟蹤(用于推理階段)。
- 內存優化:使用
out參數指定輸出張量,避免重復分配內存:result = torch.zeros(2, 2) torch.add(a, b, out=result) # 結果直接寫入 result
總結
該教程詳細介紹了 PyTorch 張量的創建、操作、設備管理及與 NumPy 的交互,是理解 PyTorch 基礎運算的關鍵資源。完整示例代碼可通過頁面鏈接下載 。
張量匯總2
以下是PyTorch官方教程《深入理解張量》(https://pytorch.ac.cn/tutorials/beginner/introyt/tensors_deeper_tutorial.html) 的核心內容匯總:
一、張量基礎
-
創建張量
- 直接創建:
torch.tensor([[1, 2], [3, 4]]) - 初始化方法:
torch.zeros()(全零)torch.ones()(全1)torch.rand()(隨機值)torch.randn()(標準正態分布)
- 從NumPy轉換:
torch.from_numpy(numpy_array)
- 直接創建:
-
關鍵屬性
- 數據類型:
.dtype(如torch.float32) - 維度:
.shape或.size() - 存儲設備:
.device(CPU/GPU) - 布局:
.layout(默認為torch.strided)
- 數據類型:
二、內存布局(Strides)
-
核心概念
- Strides表示沿每個維度移動時內存中需跳過的元素數量。
- 示例:張量
shape=(3,4)的默認 strides 為(4,1),即:- 沿行移動:跳4個元素(到下一行)
- 沿列移動:跳1個元素(到下一列)
-
內存視圖
tensor.storage()展示底層一維數據存儲。- 轉置操作(如
tensor.T)不復制數據,僅修改strides(例:轉置后 strides 變為(1,4))。
三、張量操作
-
索引與切片
- 類NumPy語法:
tensor[:, 1:3] - 高級索引:
tensor[[0, 2], [1, 3]]
- 類NumPy語法:
-
形狀操作
- 重塑:
.view()(需連續內存)和.reshape()(自動處理非連續) - 壓縮/擴展維度:
.squeeze()/.unsqueeze()
- 重塑:
-
數學運算
- 逐元素運算:
+,*,torch.sin() - 矩陣乘法:
torch.matmul()或@ - 聚合操作:
.sum(),.mean()
- 逐元素運算:
-
廣播機制
- 自動擴展不同形狀張量(如
(3,1) * (1,4)→(3,4))。
- 自動擴展不同形狀張量(如
四、原地操作
- 標識
- 后綴下劃線(如
.add_())表示原地修改。
- 后綴下劃線(如
- 注意事項
- 節省內存但破壞計算圖歷史,不推薦在梯度計算中使用。
五、設備與加速
- 設備遷移
- 顯式指定:
tensor.to(device='cuda') - 跨設備復制:
.cpu()/.cuda()
- 顯式指定:
- 性能優勢
- GPU并行加速大規模計算。
六、自動求導(Autograd)
- 梯度跟蹤
requires_grad=True啟用梯度計算(如torch.tensor(..., requires_grad=True))。
- 計算梯度
.backward()自動計算梯度并存儲于.grad屬性。
- 分離計算圖
.detach()或with torch.no_grad():禁止梯度跟蹤。
七、與NumPy互操作
- 無縫轉換
torch.from_numpy(np_array)→ 張量tensor.numpy()→ NumPy數組
- 內存共享
- 轉換后的對象共享底層內存(修改一方影響另一方)。
八、最佳實踐
- 優先向量化操作(避免Python循環)
- 警惕原地操作(尤其在Autograd中)
- 利用設備遷移(將計算密集型任務移至GPU)
- 注意內存連續性(影響
view()等操作)
該教程通過代碼示例詳細解釋了張量的底層原理(如內存布局)及高效操作技巧,是深入理解PyTorch核心數據結構的必備內容。
3、數據集(PyTorch)
參考:
https://pytorch.ac.cn/tutorials/beginner/basics/data_tutorial.html
https://pytorch.ac.cn/tutorials/beginner/basics/quickstart_tutorial.html
https://github.com/pytorch/tutorials/blob/main/beginner_source/basics/data_tutorial.py
https://pytorch.ac.cn/tutorials/beginner/nn_tutorial.html#mnist-data-setup
數據集:
https://pytorch.ac.cn/vision/stable/datasets.html
PyTorch 提供特定領域的庫,例如 TorchText、TorchVision 和 TorchAudio,所有這些庫都包含數據集。在本教程中,我們將使用 TorchVision 數據集。
torchvision.datasets 模塊包含許多真實世界視覺數據的 Dataset 對象,例如 CIFAR、COCO(完整列表在此)。在本教程中,我們使用 FashionMNIST 數據集。每個 TorchVision Dataset 都包含兩個參數:transform 和 target_transform,分別用于修改樣本和標簽。
3.1 加載已有數據集格式
處理數據樣本的代碼可能會變得雜亂且難以維護;理想情況下,我們希望將數據集代碼與模型訓練代碼解耦,以提高可讀性和模塊化。PyTorch 提供了兩種數據原語:torch.utils.data.DataLoader 和 torch.utils.data.Dataset,它們允許您使用預加載的數據集以及您自己的數據。Dataset 存儲樣本及其對應的標簽,而 DataLoader 則在 Dataset 周圍封裝了一個迭代器,以便于訪問樣本。
PyTorch 領域庫提供了許多預加載的數據集(例如 FashionMNIST),這些數據集繼承自 torch.utils.data.Dataset 并實現了特定于特定數據的功能。它們可用于原型設計和模型基準測試。您可以在此處找到它們:圖像數據集、文本數據集和音頻數據集
代碼參考:
-
Dataset
我們使用以下參數加載 FashionMNIST Datasettraining_data = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor(), )例如: import torch from torch.utils.data import Dataset from torchvision import datasets from torchvision.transforms import ToTensor import matplotlib.pyplot as plttraining_data = datasets.FashionMNIST(root="/Users/umr/MyData/vspro/data_set",train=True,download=True,transform=ToTensor() )test_data = datasets.FashionMNIST(root="/Users/umr/MyData/vspro/data_set",train=False,download=True,transform=ToTensor() )# 返回的格式: return image, labelroot是下載到的文件夾
train 是否是訓練數據, 否則就是測試數據
download是否要進行下載root 是訓練/測試數據存儲的路徑,
train 指定訓練或測試數據集,
download=True 會在 root 路徑下數據不存在時從互聯網下載。
transform 和 target_transform 指定特征和標簽變換使用 DataLoaders 準備數據進行訓練
Dataset 一次檢索一個樣本的數據集特征和標簽。在訓練模型時,我們通常希望以“迷你批量”的形式傳遞樣本,在每個 epoch 重新打亂數據以減少模型過擬合,并使用 Python 的 multiprocessing 來加速數據檢索。DataLoader 是一個迭代器,它通過簡單的 API 為我們抽象了這種復雜性。
from torch.utils.data import DataLoadertrain_dataloader = DataLoader(training_data, batch_size=64, shuffle=True) test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True) -
遍歷 DataLoader
我們已將數據集加載到 DataLoader 中,并可以根據需要遍歷數據集。下面的每次迭代都會返回一批 train_features 和 train_labels(分別包含 batch_size=64 個特征和標簽)。因為我們指定了 shuffle=True,所以在遍歷所有批量后,數據會被打亂(如需對數據加載順序進行更精細的控制,請參閱采樣器 (Samplers))。# Display image and label. train_features, train_labels = next(iter(train_dataloader)) print(f"Feature batch shape: {train_features.size()}") print(f"Labels batch shape: {train_labels.size()}") img = train_features[0].squeeze() label = train_labels[0] plt.imshow(img, cmap="gray") plt.show() print(f"Label: {label}")
3.2 自定義數據集
為您的文件創建自定義數據集
自定義 Dataset 類必須實現三個函數:init、len 和 getitem。請看這個實現;FashionMNIST 圖像存儲在目錄 img_dir 中,而它們的標簽則單獨存儲在 CSV 文件 annotations_file 中。
在接下來的部分,我們將詳細介紹這些函數中的每一個。
#################################################################
# Creating a Custom Dataset for your files
# ---------------------------------------------------
#
# A custom Dataset class must implement three functions: `__init__`, `__len__`, and `__getitem__`.
# Take a look at this implementation; the FashionMNIST images are stored
# in a directory ``img_dir``, and their labels are stored separately in a CSV file ``annotations_file``.
#
# In the next sections, we'll break down what's happening in each of these functions.import os
import pandas as pd
from torchvision.io import read_imageclass CustomImageDataset(Dataset):def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):self.img_labels = pd.read_csv(annotations_file)self.img_dir = img_dirself.transform = transformself.target_transform = target_transformdef __len__(self):return len(self.img_labels)def __getitem__(self, idx):img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])image = read_image(img_path)label = self.img_labels.iloc[idx, 1]if self.transform:image = self.transform(image)if self.target_transform:label = self.target_transform(label)return image, labelinit
init 函數在實例化 Dataset 對象時運行一次。我們初始化包含圖像的目錄、標注文件以及兩個變換(將在下一節詳細介紹)。
labels.csv 文件如下所示
tshirt1.jpg, 0
tshirt2.jpg, 0
......
ankleboot999.jpg, 9
len
len 函數返回數據集中樣本的數量。
示例
def __len__(self):return len(self.img_labels)
getitem
getitem 函數加載并返回給定索引 idx 處的數據集樣本。根據索引,它確定圖像在磁盤上的位置,使用 read_image 將其轉換為張量,從 self.img_labels 中的 csv 數據檢索相應標簽,對其調用變換函數(如果適用),并以元組形式返回張量圖像和相應標簽。
return image, label
3.3 變換(transforms)
數據并不總是以機器學習算法訓練所需的最終處理形式出現。我們使用 變換(transforms) 對數據進行一些處理,使其適合訓練。
所有 TorchVision 數據集都有兩個參數 -transform 用于修改特征,target_transform 用于修改標簽 - 它們接受包含變換邏輯的可調用對象。 torchvision.transforms 模塊提供了幾個常用的現成變換。
FashionMNIST 特征采用 PIL Image 格式,標簽是整數。為了訓練,我們需要將特征轉換為歸一化張量,將標簽轉換為獨熱編碼張量。為了實現這些變換,我們使用 ToTensor 和 Lambda。
import torch
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambdads = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor(),target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=1))
)
4、構建神經網絡
參考:
https://pytorch.ac.cn/tutorials/beginner/basics/buildmodel_tutorial.html
https://pytorch.ac.cn/tutorials/beginner/introyt/modelsyt_tutorial.html
https://pytorch.ac.cn/tutorials/beginner/nn_tutorial.html
在本教程開始時,我們承諾將通過示例解釋 torch.nn、torch.optim、Dataset 和 DataLoader。現在我們總結一下我們所學到的:
參考:https://pytorch.ac.cn/tutorials/beginner/nn_tutorial.html
-
torch.nn:Module:創建一個可調用對象,其行為類似函數,但也可以包含狀態(如神經網絡層的權重)。它知道自己包含哪些Parameter,可以將其所有梯度清零,遍歷它們進行權重更新等。Parameter:一個張量的包裝器,它告訴Module它擁有在反向傳播期間需要更新的權重。只有設置了requires_grad屬性的張量才會被更新。functional:一個模塊(通常按慣例導入到F命名空間中),包含激活函數、損失函數等,以及卷積層和線性層等無狀態版本的層。
-
torch.optim:包含優化器,例如SGD,它們在反向傳播步驟中更新Parameter的權重。 -
Dataset:具有__len__和__getitem__方法的對象的抽象接口,包括 PyTorch 提供的類,如TensorDataset。 -
DataLoader:接受任何Dataset并創建一個迭代器,該迭代器返回批次數據。
神經網絡由對數據執行操作的層/模塊組成。torch.nn 命名空間提供了構建自己的神經網絡所需的所有構建塊。PyTorch 中的每個模塊都繼承自 nn.Module。神經網絡本身就是一個由其他模塊(層)組成的模塊。這種嵌套結構使得構建和管理復雜的架構變得容易。
定義類
我們通過繼承 nn.Module 來定義我們的神經網絡,并在 init 中初始化神經網絡層。每個 nn.Module 子類都在 forward 方法中實現對輸入數據的操作。
要使用模型,我們將輸入數據傳遞給它。這將執行模型的 forward 方法,以及一些后臺操作。不要直接調用 model.forward()!
在輸入上調用模型會返回一個二維張量,其中 dim=0 對應于每個類別的 10 個原始預測值,dim=1 對應于每個輸出的單個值。通過將其傳遞給 nn.Softmax 模塊的一個實例,我們可以獲得預測概率。dim 參數表示值必須沿哪個維度求和為 1。
mport os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms#############################################
# Get Device for Training
# -----------------------
# We want to be able to train our model on an `accelerator <https://pytorch.org/docs/stable/torch.html#accelerators>`__
# such as CUDA, MPS, MTIA, or XPU. If the current accelerator is available, we will use it. Otherwise, we use the CPU.device = torch.accelerator.current_accelerator().type if torch.accelerator.is_available() else "cpu"
print(f"Using {device} device")##############################################
# Define the Class
# -------------------------
# We define our neural network by subclassing ``nn.Module``, and
# initialize the neural network layers in ``__init__``. Every ``nn.Module`` subclass implements
# the operations on input data in the ``forward`` method.class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.linear_relu_stack = nn.Sequential(nn.Linear(28*28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10),)def forward(self, x):x = self.flatten(x)logits = self.linear_relu_stack(x)return logits##############################################
# We create an instance of ``NeuralNetwork``, and move it to the ``device``, and print
# its structure.model = NeuralNetwork().to(device)
print(model)##############################################
# To use the model, we pass it the input data. This executes the model's ``forward``,
# along with some `background operations <https://github.com/pytorch/pytorch/blob/270111b7b611d174967ed204776985cefca9c144/torch/nn/modules/module.py#L866>`_.
# Do not call ``model.forward()`` directly!
#
# Calling the model on the input returns a 2-dimensional tensor with dim=0 corresponding to each output of 10 raw predicted values for each class, and dim=1 corresponding to the individual values of each output.
# We get the prediction probabilities by passing it through an instance of the ``nn.Softmax`` module.X = torch.rand(1, 28, 28, device=device)
logits = model(X)
pred_probab = nn.Softmax(dim=1)(logits)
y_pred = pred_probab.argmax(1)
print(f"Predicted class: {y_pred}")1.核心類:torch.nn.Module 與 torch.nn.Parameter
1. torch.nn.Module
- 定位:PyTorch 中所有神經網絡模型的基類,用于封裝模型組件(如層)及其行為(如參數管理、前向傳播)。
- 關鍵特性:
- 參數注冊:自動跟蹤子模塊(如
Linear、Conv2d層)的可學習參數。 - 層次化結構:支持嵌套子模塊,可通過
model.layer_name訪問任意層。 - 前向傳播:需自定義
forward()方法定義計算邏輯,backward()由 Autograd 自動處理。 - torch.nn.Module
所有神經網絡模塊的基類,用于封裝模型結構和行為。
子類需定義 init()(聲明層)和 forward()(計算邏輯)。
- 參數注冊:自動跟蹤子模塊(如
2. torch.nn.Parameter(訪問參數)
- 定位:
torch.Tensor的子類,用于表示模型的可學習參數(如權重、偏置)。 - 關鍵特性:
- 自動注冊:當作為
Module的屬性賦值時(如self.weight = nn.Parameter(torch.randn(3, 2))),會自動添加到Module.parameters()列表中。 - 梯度跟蹤:默認啟用
requires_grad=True,自動參與反向傳播。 - torch.nn.Parameter
Tensor 的子類,表示可學習參數(如權重、偏置)。
當賦值給 Module 屬性時,自動注冊到模型參數列表中,可通過 parameters() 訪問。
常見層類型
- 自動注冊:當作為
以下為 PyTorch 官方教程 中關于 構建深度學習模型 的核心內容匯總:
模型基礎結構
torch.nn.Module是所有 PyTorch 模型的基類,用于封裝模型組件及其參數。torch.nn.Parameter是Tensor的子類,表示可學習的參數。當分配為Module的屬性時,會自動加入模型參數列表,可通過model.parameters()訪問。- 模型需定義兩個核心方法:
__init__():初始化層(如線性層、卷積層等)。forward():定義數據流向(如輸入經過各層的計算過程)。
- 示例代碼:定義了一個簡單模型
TinyModel,包含兩個線性層和激活函數,并展示了參數訪問方法 (https://pytorch.ac.cn/tutorials/beginner/introyt/modelsyt_tutorial.html)。
3. torch.functional
在 PyTorch 中,torch.nn.functional(通常簡寫為 F)是一個包含各種無狀態函數的重要模塊,用于實現神經網絡操作。它與 torch.nn 模塊(包含有狀態的類)相互補充,共同構建神經網絡。以下是核心要點:
1. 核心概念
- 無狀態函數:不包含可學習參數(如權重/偏置),僅實現計算操作
- 純函數:相同輸入 → 相同輸出,無內部狀態
- 使用場景:
- 激活函數(ReLU, sigmoid)
- 池化操作(max_pool, avg_pool)
- 損失函數(cross_entropy, mse_loss)
- 標準化(dropout, layer_norm)
實現無需學習參數的層或操作:
- 激活函數:
F.relu(),F.sigmoid(),F.tanh(),F.softmax() - 池化操作:
F.max_pool2d(),F.avg_pool2d() - 正則化:
F.dropout(),F.batch_norm()(需手動傳入 weight/bias) - 損失函數:
F.cross_entropy(),F.mse_loss(),F.l1_loss()
2. 與 torch.nn 模塊的區別
| 特性 | torch.nn.functional (F) | torch.nn 模塊 |
|---|---|---|
| 狀態 | 無狀態(無參數) | 有狀態(包含可訓練參數) |
| 使用方式 | 直接函數調用 F.relu(x) | 類實例化 nn.ReLU() |
| 參數存儲 | 不管理參數 | 自動管理參數(通過 parameters()) |
| 典型用途 | 簡單操作/自定義層 | 標準網絡層(卷積/線性層等) |
4. torch.optim
torch.optim 是 PyTorch 中用于優化神經網絡模型參數的核心模塊,它實現了多種優化算法(如 SGD、Adam、RMSprop 等),通過計算損失函數對參數的梯度并更新模型權重,以最小化損失函數。以下是關于 torch.optim 的詳細解析:
核心功能**
- 優化算法實現:提供多種優化算法(如 SGD、Adam、Adagrad、RMSprop 等)。
- 動態學習率調整:支持學習率調度器(如
lr_scheduler)動態調整學習率。 - 參數更新:通過梯度反向傳播更新模型參數。
核心作用
- 參數優化:自動更新模型權重以最小化損失函數
- 梯度管理:高效計算和應用梯度
- 學習率控制:支持動態學習率調整
- 算法實現:提供多種優化算法(SGD, Adam 等)
- 狀態維護:跟蹤優化器內部狀態(如動量緩存)
優化算法實現
| 優化器 | 適用場景 | 特點 |
|---|---|---|
SGD | 基礎優化任務 | 支持動量(momentum)、Nesterov加速 |
Adam | 深度學習主流選擇 (默認推薦) | 自適應學習率,結合動量 |
AdamW | 帶權重衰減的優化 | 修復標準Adam中權重衰減實現問題(更好泛化) |
RMSprop | RNN/LSTM | 自適應調整學習率(每個參數單獨調整) |
Adagrad | 稀疏數據特征學習 | 為頻繁特征分配小學習率 |
Adadelta | 替代Adagrad | 無需初始學習率 |
LBFGS | 小規模全批處理 | 準牛頓方法(內存消耗大但收斂快) |
2. 常用層類型
線性層 (torch.nn.Linear)
- 實現全連接操作:輸入與權重矩陣相乘并加偏置。
- 參數:
in_features(輸入特征數)、out_features(輸出特征數)、bias(是否啟用偏置)。 - 示例:
Linear(3, 2)表示輸入維度為3,輸出維度為2的線性變換 (https://pytorch.ac.cn/tutorials/beginner/introyt/modelsyt_tutorial.html)。
卷積層 (torch.nn.Conv2d)
- 用于處理具有空間相關性的數據(如圖像)。
- 參數:
in_channels(輸入通道數)、out_channels(輸出通道數)、kernel_size(卷積核大小)。 - 示例:
Conv2d(1, 6, 5)表示輸入為1通道(灰度圖),輸出6個特征圖,卷積核大小5x5 (https://pytorch.ac.cn/tutorials/beginner/introyt/modelsyt_tutorial.html)。 - 典型流程:卷積 → 激活(如ReLU) → 池化(如最大池化)。
循環層 (torch.nn.LSTM, torch.nn.GRU)
- 處理序列數據(如文本、時間序列)。
- 示例:
LSTMTagger模型用于詞性標注,包含嵌入層、LSTM層和線性分類層 (https://pytorch.ac.cn/tutorials/beginner/introyt/modelsyt_tutorial.html)。
Transformer
- 支持自注意力機制,適用于自然語言處理(NLP)任務。
- PyTorch 提供
torch.nn.Transformer及其組件(如編碼器、解碼器層),可靈活構建模型(如BERT)(https://pytorch.ac.cn/tutorials/beginner/introyt/modelsyt_tutorial.html)。
3. 其他重要層與函數
數據操作層
- 最大池化 (
MaxPool2d):通過取局部最大值減少張量尺寸。 - 歸一化層 (
BatchNorm1d):標準化中間張量,加速訓練并允許使用更高學習率。 - Dropout 層:訓練時隨機屏蔽部分輸入,防止過擬合。
激活函數
- 非線性函數(如 ReLU、Sigmoid、Softmax)使模型能擬合復雜函數。
- 示例:
F.relu()、F.softmax()。
損失函數
- 常見類型:均方誤差(MSE)、交叉熵損失(CrossEntropyLoss)、負對數似然損失(NLLLoss)。
4. 模型訓練流程
- 訓練循環步驟:
- 從
DataLoader獲取數據。 - 將優化器梯度歸零。
- 前向傳播(推理預測結果)。
- 計算損失。
- 反向傳播(
loss.backward())。 - 更新參數(
optimizer.step())(https://pytorch.ac.cn/tutorials/beginner/introyt/modelsyt_tutorial.html)。
- 從
5. 模型保存與加載
- 保存模型:
torch.save(model.state_dict(), "model.pth")。 - 加載模型:先實例化模型結構,再調用
model.load_state_dict(torch.load("model.pth"))(https://pytorch.ac.cn/tutorials/beginner/introyt/modelsyt_tutorial.html)。
6. 關鍵技巧
- 參數初始化:合理設置權重初始化方法(如 Xavier、Kaiming)可改善訓練效果。
- 設備遷移:通過
model.to(device)將模型移至 GPU(device="cuda")或 CPU(device="cpu")。 - 模型評估模式:調用
model.eval()禁用 Dropout 和 BatchNorm 的訓練行為 (https://pytorch.ac.cn/tutorials/beginner/introyt/modelsyt_tutorial.html)。
以上內容總結了 PyTorch 構建深度學習模型的核心概念與代碼實踐,適合初學者快速掌握模型定義、訓練及優化方法。
5、torch.autograd 自動微分
參考:
https://pytorch.ac.cn/tutorials/beginner/basics/autogradqs_tutorial.html
https://pytorch.ac.cn/tutorials/beginner/introyt/autogradyt_tutorial.html#what-do-we-need-autograd-for
對于一個小的兩層網絡來說,手動實現后向傳播并不是什么大問題,但對于大型復雜網絡來說,這很快就會變得非常麻煩。值得慶幸的是,我們可以使用 自動微分 來自動化神經網絡中后向傳播的計算。PyTorch 中的 autograd 包正是提供了這個功能。使用 autograd 時,網絡的前向傳播將定義一個 計算圖 ;圖中的節點是張量,邊是根據輸入張量生成輸出張量的函數。然后,通過這個圖進行反向傳播,你可以輕松地計算梯度。在底層,每個原始的 autograd 算子實際上是作用于張量的兩個函數。forward 函數根據輸入張量計算輸出張量。backward 函數接收輸出張量關于某個標量值的梯度,并計算輸入張量關于同一標量值的梯度。參考
1.計算圖
https://pytorch.ac.cn/tutorials/beginner/blitz/autograd_tutorial.html
訓練神經網絡時,最常用的算法是反向傳播。在該算法中,根據損失函數相對于給定參數的梯度來調整參數(模型權重)。
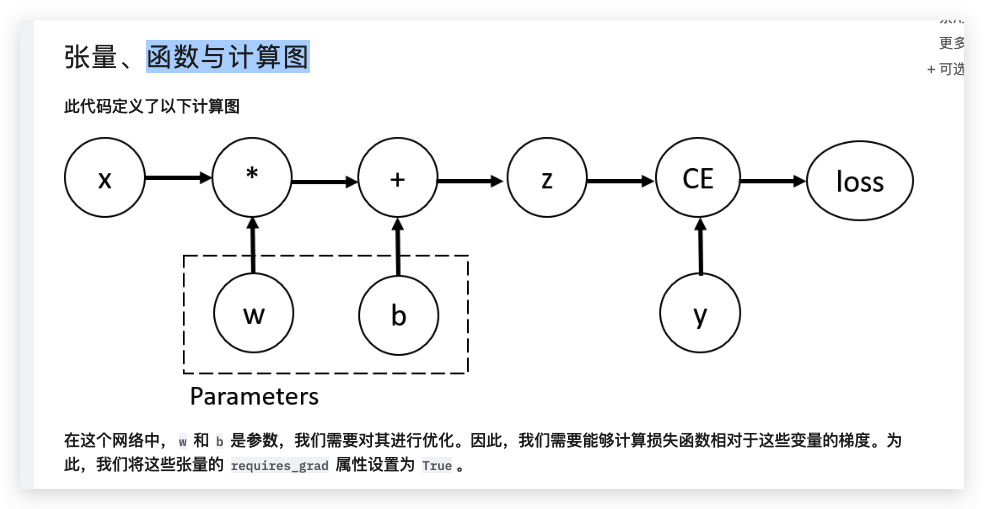
注意:Parameters參數
你可以在創建張量時設置 requires_grad 的值,也可以稍后使用 x.requires_grad_(True) 方法設置。
x = torch.ones(5) # input tensor
w = torch.randn(5, 3, requires_grad=True)我們只能獲取計算圖葉子節點的 grad 屬性,
這些葉子節點的 requires_grad 屬性設置為 True。
對于圖中所有其他節點,梯度將不可用。出于性能考慮,我們只能在給定圖上使用 backward 進行一次梯度計算。
如果我們需要在同一個圖上進行多次 backward 調用,
我們需要將 retain_graph=True 傳遞給 backward 調用。我們應用于張量以構建計算圖的函數實際上是 Function 類的一個對象。此對象知道如何執行函數在前向方向的計算,以及如何在反向傳播步驟中計算其導數。對反向傳播函數的引用存儲在張量的 grad_fn 屬性中。你可以在文檔中找到更多關于 Function 的信息。

請注意,只有計算圖的葉子節點才會計算梯度。例如,如果你嘗試 print(c.grad),你會得到 None。在這個簡單的例子中,只有輸入是葉子節點,因此只有它計算了梯度。
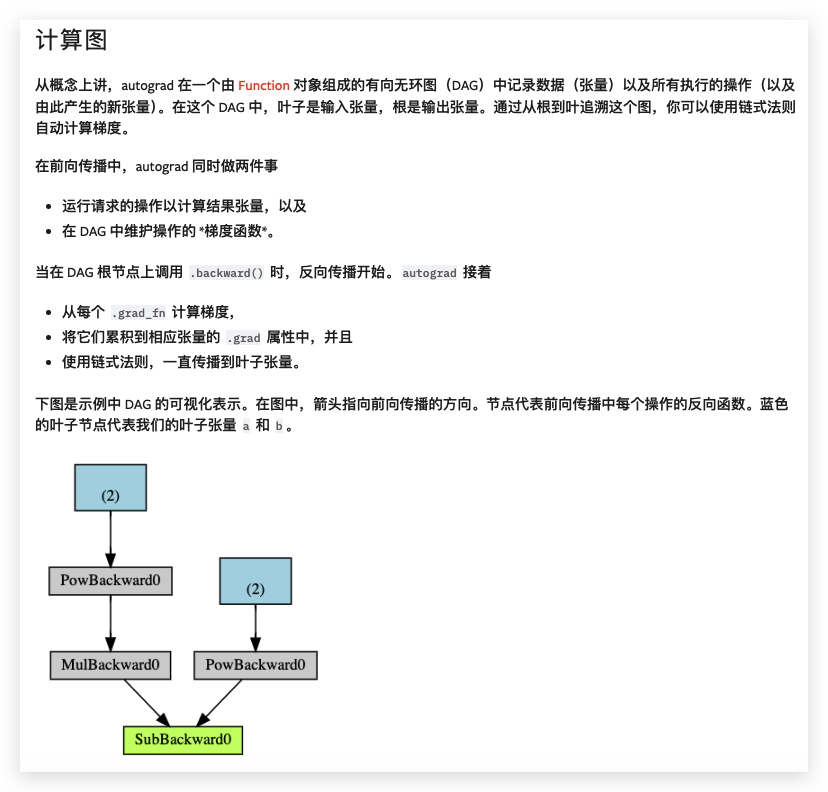
注意
PyTorch 中的 DAG 是動態的 需要注意的一點是,圖是每次從頭開始重新創建的;在每次調用 .backward() 后,autograd 開始填充一個新的圖。這正是允許你在模型中使用控制流語句的原因;如果需要,你可以在每次迭代時改變形狀、大小和操作。
2.grad_fn、grad
每個與我們的張量一起存儲的 grad_fn 都可以讓你通過其 next_functions 屬性一直回溯到其輸入。我們可以看到,對 d 的此屬性進行深入探究,會顯示所有先前張量的梯度函數。注意,a.grad_fn 報告為 None,表明這是函數的輸入,本身沒有歷史記錄。
有了所有這些機制,我們如何獲取導數呢?你可以在輸出上調用 backward() 方法,并檢查輸入的 grad 屬性以查看梯度。
請注意,只有計算圖的葉子節點才會計算梯度。例如,如果你嘗試 print(c.grad),你會得到 None。在這個簡單的例子中,只有輸入是葉子節點,因此只有它計算了梯度。
a = torch.linspace(0., 2. * math.pi, steps=25, requires_grad=True)
print(a)b = torch.sin(a)
print(b)c = 2 * b
print(c)d = c + 1
print(d)
out = d.sum()
print(out)# **********************rint('d:')
print(d.grad_fn)
print(d.grad_fn.next_functions)
print(d.grad_fn.next_functions[0][0].next_functions)
print(d.grad_fn.next_functions[0][0].next_functions[0][0].next_functions)
print(d.grad_fn.next_functions[0][0].next_functions[0][0].next_functions[0][0].next_functions)
print('\nc:')
print(c.grad_fn)
print('\nb:')
print(b.grad_fn)
print('\na:')
print(a.grad_fn)# ***************************
out.backward()
print(a.grad)輸出:
tensor([0.0000, 0.2618, 0.5236, 0.7854, 1.0472, 1.3090, 1.5708, 1.8326, 2.0944,2.3562, 2.6180, 2.8798, 3.1416, 3.4034, 3.6652, 3.9270, 4.1888, 4.4506,4.7124, 4.9742, 5.2360, 5.4978, 5.7596, 6.0214, 6.2832],requires_grad=True)
tensor([ 0.0000e+00, 2.5882e-01, 5.0000e-01, 7.0711e-01, 8.6603e-01,9.6593e-01, 1.0000e+00, 9.6593e-01, 8.6603e-01, 7.0711e-01,5.0000e-01, 2.5882e-01, -8.7423e-08, -2.5882e-01, -5.0000e-01,-7.0711e-01, -8.6603e-01, -9.6593e-01, -1.0000e+00, -9.6593e-01,-8.6603e-01, -7.0711e-01, -5.0000e-01, -2.5882e-01, 1.7485e-07],grad_fn=<SinBackward0>)
tensor([ 0.0000e+00, 5.1764e-01, 1.0000e+00, 1.4142e+00, 1.7321e+00,1.9319e+00, 2.0000e+00, 1.9319e+00, 1.7321e+00, 1.4142e+00,1.0000e+00, 5.1764e-01, -1.7485e-07, -5.1764e-01, -1.0000e+00,-1.4142e+00, -1.7321e+00, -1.9319e+00, -2.0000e+00, -1.9319e+00,-1.7321e+00, -1.4142e+00, -1.0000e+00, -5.1764e-01, 3.4969e-07],grad_fn=<MulBackward0>)
tensor([ 1.0000e+00, 1.5176e+00, 2.0000e+00, 2.4142e+00, 2.7321e+00,2.9319e+00, 3.0000e+00, 2.9319e+00, 2.7321e+00, 2.4142e+00,2.0000e+00, 1.5176e+00, 1.0000e+00, 4.8236e-01, -3.5763e-07,-4.1421e-01, -7.3205e-01, -9.3185e-01, -1.0000e+00, -9.3185e-01,-7.3205e-01, -4.1421e-01, 4.7684e-07, 4.8236e-01, 1.0000e+00],grad_fn=<AddBackward0>)
tensor(25., grad_fn=<SumBackward0>)
d:
<AddBackward0 object at 0x1075ee920>
((<MulBackward0 object at 0x1075ee950>, 0), (None, 0))
((<SinBackward0 object at 0x1075ee950>, 0), (None, 0))
((<AccumulateGrad object at 0x1075ee920>, 0),)
()c:
<MulBackward0 object at 0x1075ee950>b:
<SinBackward0 object at 0x1075ee950>a:
None
有了所有這些機制,我們如何獲取導數呢?
你可以在輸出上調用 backward() 方法,
并檢查輸入的 grad 屬性以查看梯度out.backward()
print(a.grad)
plt.plot(a.detach(), a.grad.detach())
tensor([ 2.0000e+00, 1.9319e+00, 1.7321e+00, 1.4142e+00, 1.0000e+00,5.1764e-01, -8.7423e-08, -5.1764e-01, -1.0000e+00, -1.4142e+00,-1.7321e+00, -1.9319e+00, -2.0000e+00, -1.9319e+00, -1.7321e+00,-1.4142e+00, -1.0000e+00, -5.1764e-01, 2.3850e-08, 5.1764e-01,1.0000e+00, 1.4142e+00, 1.7321e+00, 1.9319e+00, 2.0000e+00])[<matplotlib.lines.Line2D object at 0x7f12e5cc5240>]
例子
參考:https://pytorch.ac.cn/tutorials/beginner/introyt/autogradyt_tutorial.html#what-do-we-need-autograd-for
BATCH_SIZE = 16
DIM_IN = 1000
HIDDEN_SIZE = 100
DIM_OUT = 10class TinyModel(torch.nn.Module):def __init__(self):super(TinyModel, self).__init__()self.layer1 = torch.nn.Linear(DIM_IN, HIDDEN_SIZE)self.relu = torch.nn.ReLU()self.layer2 = torch.nn.Linear(HIDDEN_SIZE, DIM_OUT)def forward(self, x):x = self.layer1(x)x = self.relu(x)x = self.layer2(x)return xsome_input = torch.randn(BATCH_SIZE, DIM_IN, requires_grad=False)
ideal_output = torch.randn(BATCH_SIZE, DIM_OUT, requires_grad=False)model = TinyModel()##########################################################################
print(model.layer2.weight[0][0:10]) # just a small slice
print(model.layer2.weight.grad)##########################################################################
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)prediction = model(some_input)loss = (ideal_output - prediction).pow(2).sum()
print(loss)######################################################################
loss.backward()
print(model.layer2.weight[0][0:10])
print(model.layer2.weight.grad[0][0:10])########################################################################
optimizer.step()
print(model.layer2.weight[0][0:10])
print(model.layer2.weight.grad[0][0:10])######################################################################
print(model.layer2.weight.grad[0][0:10])for i in range(0, 5):prediction = model(some_input)loss = (ideal_output - prediction).pow(2).sum()loss.backward()print(model.layer2.weight.grad[0][0:10])optimizer.zero_grad(set_to_none=False)print(model.layer2.weight.grad[0][0:10])
如果我們查看模型的層,可以檢查權重的數值,并驗證尚未計算任何梯度
print(model.layer2.weight[0][0:10]) # just a small slice
print(model.layer2.weight.grad)
tensor([ 0.0920, 0.0916, 0.0121, 0.0083, -0.0055, 0.0367, 0.0221, -0.0276,-0.0086, 0.0157], grad_fn=<SliceBackward0>)
None
現在,讓我們調用 loss.backward(),看看會發生什么
loss.backward()
print(model.layer2.weight[0][0:10])
print(model.layer2.weight.grad[0][0:10])
tensor([ 0.0920, 0.0916, 0.0121, 0.0083, -0.0055, 0.0367, 0.0221, -0.0276,-0.0086, 0.0157], grad_fn=<SliceBackward0>)
tensor([12.8997, 2.9572, 2.3021, 1.8887, 5.0710, 7.3192, 3.5169, 2.4319,0.1732, -5.3835])
我們可以看到,每個學習權重的梯度都已計算出來,但權重保持不變,因為我們還沒有運行優化器。優化器負責根據計算出的梯度更新模型權重。
optimizer.step()
print(model.layer2.weight[0][0:10])
print(model.layer2.weight.grad[0][0:10])
tensor([ 0.0791, 0.0886, 0.0098, 0.0064, -0.0106, 0.0293, 0.0186, -0.0300,-0.0088, 0.0211], grad_fn=<SliceBackward0>)
tensor([12.8997, 2.9572, 2.3021, 1.8887, 5.0710, 7.3192, 3.5169, 2.4319,0.1732, -5.3835])
你應該看到 layer2 的權重已經改變了。
關于這個過程,重要的一點是:在調用 optimizer.step() 后,你需要調用 optimizer.zero_grad(),否則每次運行 loss.backward() 時,學習權重的梯度都會累積
print(model.layer2.weight.grad[0][0:10])
for i in range(0, 5):
prediction = model(some_input)
loss = (ideal_output - prediction).pow(2).sum()
loss.backward()
print(model.layer2.weight.grad[0][0:10])
optimizer.zero_grad(set_to_none=False)
print(model.layer2.weight.grad[0][0:10])
tensor([12.8997, 2.9572, 2.3021, 1.8887, 5.0710, 7.3192, 3.5169, 2.4319,0.1732, -5.3835])
tensor([ 19.2095, -15.9459, 8.3306, 11.5096, 9.5471, 0.5391, -0.3370,8.6386, -2.5141, -30.1419])
tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
運行上面的單元格后,你應該會看到,在多次運行 loss.backward() 后,大多數梯度的幅度會大得多。如果在運行下一個訓練批次之前未能將梯度歸零,將導致梯度以這種方式爆炸,從而導致錯誤和不可預測的學習結果。
3.backward()
通過調用backward(),我們可以對某個Variable(譬如說y)進行一次自動求導,但如果我們再對這個Variable進行一次backward()操作,會發現程序報錯。這是因為PyTorch默認做完一次自動求導后,就把計算圖丟棄了。我們可以通過設置retain_graph來實現多次求導。
backward &retain_graph時:
注意,當我們第二次使用相同參數調用 backward 時,梯度的值是不同的。這是因為在進行 backward 傳播時,PyTorch 會累加梯度,即計算出的梯度值會添加到計算圖所有葉子節點的 grad 屬性中。如果你想計算正確的梯度,你需要先將 grad 屬性清零。在實際訓練中,優化器會幫助我們完成此操作。參考:https://pytorch.ac.cn/tutorials/beginner/basics/autogradqs_tutorial.html
inp = torch.eye(4, 5, requires_grad=True)
out = (inp+1).pow(2).t()
out.backward(torch.ones_like(out), retain_graph=True)
print(f"First call\n{inp.grad}")
out.backward(torch.ones_like(out), retain_graph=True)
print(f"\nSecond call\n{inp.grad}")
inp.grad.zero_()
out.backward(torch.ones_like(out), retain_graph=True)
print(f"\nCall after zeroing gradients\n{inp.grad}")
輸出
First call
tensor([[4., 2., 2., 2., 2.],[2., 4., 2., 2., 2.],[2., 2., 4., 2., 2.],[2., 2., 2., 4., 2.]])Second call
tensor([[8., 4., 4., 4., 4.],[4., 8., 4., 4., 4.],[4., 4., 8., 4., 4.],[4., 4., 4., 8., 4.]])Call after zeroing gradients
tensor([[4., 2., 2., 2., 2.],[2., 4., 2., 2., 2.],[2., 2., 4., 2., 2.],[2., 2., 2., 4., 2.]])
優化器:

4.grad_fn、grad和backward()
在 PyTorch 中,grad_fn、grad 和 backward() 是 torch.autograd 模塊的核心組成部分,用于實現自動求導和反向傳播。以下是它們的詳細說明:
grad_fn 構建計算圖(張量計算方式),backward() 觸發求導計算,grad 存儲結果,共同實現高效的梯度計算。
1. grad_fn
作用:
grad_fn 是一個張量的屬性(Tensor.grad_fn),用于記錄該張量的梯度計算方式(即它是通過什么操作生成的)。
- 非葉子節點:由用戶定義的操作(如加法、乘法等)生成的張量會有一個
grad_fn,指向具體的梯度計算函數(如AddBackward0、MulBackward0等)。 - 葉子節點:用戶直接創建的張量(如模型參數)或不需要梯度的張量,其
grad_fn為None。
示例:
x = torch.tensor(2.0, requires_grad=True) # 葉子節點
y = x ** 2 + 3 * x + 1 # 非葉子節點
print(y.grad_fn) # 輸出: <PowBackward0 object at 0x...>
y的grad_fn是PowBackward0,表示它是通過冪運算生成的。
- 定義:
grad_fn是張量的一個屬性,記錄了該張量的計算來源(即它是通過哪些操作生成的)。 - 作用:
- 構建動態計算圖,跟蹤張量之間的依賴關系,為反向傳播提供梯度計算路徑。
- 葉子節點(用戶手動創建的張量)的
grad_fn為None,而非葉子節點(通過運算生成的張量)的grad_fn會指向創建它的Function對象 。
- 示例:
x = torch.tensor([1.0, 2.0], requires_grad=True) # 葉子節點,grad_fn=None y = x * 3 # 非葉子節點,grad_fn=<MulBackward>
2. grad
作用:
grad 是一個張量的屬性(Tensor.grad),用于存儲該張量的梯度值。
- 葉子節點:如果張量是葉子節點(
is_leaf=True),則grad會保存反向傳播計算出的梯度。 - 非葉子節點:默認情況下,非葉子節點的梯度不會被保存(因為 PyTorch 會釋放計算圖以節省內存),但可以通過
.retain_grad()強制保留。
示例:
x = torch.tensor(2.0, requires_grad=True) # 葉子節點
y = x ** 2 + 3 * x + 1
y.backward() # 反向傳播
print(x.grad) # 輸出 dy/dx = 2x + 3 = 7
- 定義:
grad是張量的一個屬性,存儲其梯度值(即損失函數對該張量的偏導數)。 - 作用:
- 只有葉子節點且
requires_grad=True的張量才會存儲梯度,非葉子節點默認不保存梯度(除非顯式調用.retain_grad())。 - 調用
backward()后,grad會被填充為計算得到的梯度值 。
- 只有葉子節點且
- 注意事項:
- 多次調用
backward()會導致梯度累加,因此需要手動調用optimizer.zero_grad()或tensor.grad.zero_()清零 。
- 多次調用
3. backward()
作用:
backward() 是觸發反向傳播的方法,用于計算梯度。
- 調用方式:通常對損失函數(標量)調用
.backward(),PyTorch 會自動從輸出節點開始反向傳播,計算所有葉子節點的梯度。 - 向量/矩陣輸出:如果輸出不是標量,需要傳入
grad_tensors參數(一個與輸出形狀相同的張量),指定梯度權重。
關鍵行為:
- 動態計算圖:PyTorch 的計算圖是動態的(每次前向傳播會重新構建計算圖)。
- 梯度累加:默認情況下,多次調用
backward()會累加梯度(需手動調用.zero_grad()清零)。 - 內存釋放:默認在
backward()后釋放計算圖(通過retain_graph=False控制)。
示例:
x = torch.tensor(2.0, requires_grad=True)
y = x ** 2 + 3 * x + 1
y.backward() # 計算 dy/dx
print(x.grad) # 輸出 7.0
- 定義:
backward()是觸發反向傳播的函數,自動計算梯度并填充到對應的grad屬性中。 - 作用:
- 從當前張量(通常是損失值)出發,沿著計算圖回溯,利用鏈式法則計算所有葉子節點的梯度 。
- 僅計算滿足以下條件的張量梯度:
- 是葉子節點;
requires_grad=True;- 依賴于當前張量 。
- 注意事項:
backward()不返回梯度值,而是直接修改grad屬性;若需要返回梯度值,可使用torch.autograd.grad()。
協同工作流程
三者的協同工作流程
- 前向計算:
創建計算圖,非葉子節點記錄grad_fn(如AddBackward,MulBackward)。 - 反向傳播:
調用loss.backward(),從loss開始回溯計算圖,計算所有葉子節點的梯度并存儲到grad中 。 - 優化更新:
使用優化器(如SGD)根據grad更新模型參數,隨后清零梯度以避免累加 。
示例:
x = torch.tensor([1.0, 2.0], requires_grad=True)
y = x * 3
z = y.sum()
z.backward() # 計算梯度
print(x.grad) # 輸出: tensor([3., 3.])
三者的關系
| 概念 | 作用 |
|---|---|
grad_fn | 記錄張量的梯度計算方式(如加法、乘法等),用于反向傳播時的鏈式法則。 |
grad | 存儲張量的梯度值,僅對葉子節點有效(非葉子節點默認不保存)。 |
backward() | 觸發反向傳播,利用 grad_fn 計算梯度,并將結果存儲在 grad 中(僅葉子節點)。 |
| 特性 | backward() | grad | grad_fn |
|---|---|---|---|
| 類型 | 方法 | 屬性 | 屬性 |
| 作用 | 啟動反向計算 | 存儲梯度值 | 記錄操作(張量計算方式:如加法、乘法等)歷史 |
| 存在位置 | 輸出張量調用 | 葉子節點張量 | 非葉子節點張量 |
| 內容 | N/A | 梯度值(Tensor) | 操作函數(Function) |
| 是否可寫 | 不可寫 | 可修改(謹慎!) | 只讀 |
常見問題
Q1: 為什么非葉子節點的 grad 默認為空?
A: 為了節省內存,PyTorch 默認只保留葉子節點的梯度。非葉子節點的梯度在反向傳播后會被釋放,除非調用 .retain_grad()。
Q2: 如何強制保留非葉子節點的梯度?
A: 調用 .retain_grad():
a = x ** 2 # 非葉子節點
a.retain_grad()
a.backward()
print(a.grad) # 輸出非空
Q3: 向量輸出如何調用 backward()?
A: 需要傳入 grad_tensors 參數(權重):
x = torch.tensor([1.0, 2.0], requires_grad=True)
y = x ** 2 # y 是向量 [1, 4]
y.backward(torch.tensor([1.0, 1.0])) # 等價于求 dy[0]/dx[0] + dy[1]/dx[1]
print(x.grad) # 輸出 [2.0, 4.0]
總結
grad_fn:記錄梯度計算方式,是反向傳播的“路徑”。grad:存儲梯度值,僅葉子節點可用。backward():觸發反向傳播,根據grad_fn計算梯度并填充到grad中。
通過這三者的協作,PyTorch 實現了高效的自動微分機制,簡化了深度學習模型的訓練過程。
5.Autograd匯總
以下是網址內容的匯總,結合知識庫信息整理而成:
Autograd 的核心作用
-
動態計算與梯度追蹤
PyTorch 的torch.autograd是其自動微分引擎,通過動態記錄計算過程(如張量操作)構建計算圖,支持在復雜模型(如包含分支或循環的模型)中高效計算梯度。這種動態機制相比靜態圖框架(如 TensorFlow 1.x)提供了更高的靈活性 。 -
梯度計算原理
Autograd 基于鏈式法則自動計算損失函數對模型參數的偏導數(梯度),這是神經網絡反向傳播的核心。例如,若模型輸出 y = M ( x ) y = M(x) y=M(x),損失函數 L ( y ) L(y) L(y) 的梯度 ? L ? x \frac{\partial L}{\partial x} ?x?L? 會通過鏈式法則分解為局部導數的乘積 。- 核心概念
??Autograd 作用??:
自動計算神經網絡中的梯度(偏導數)
支持動態計算圖,允許模型有決策分支/循環
是反向傳播和模型訓練的核心機制 - ??工作原理??:
張量設置 requires_grad=True 時跟蹤計算歷史
每個操作記錄在 grad_fn 屬性中
調用 .backward() 時反向傳播計算梯度
- 核心概念
Autograd 的使用示例
-
張量與
requires_grad標志
需要計算梯度的張量需設置requires_grad=True。例如,創建輸入張量a = torch.linspace(0, 2π, steps=25, requires_grad=True),后續操作(如b = torch.sin(a))會記錄梯度函數grad_fn。 -
反向傳播與梯度獲取
通過調用.backward()計算梯度,葉子節點(如輸入張量a)的.grad屬性存儲梯度值。例如,對d = c.sum()調用d.backward(),可獲取a.grad,其值與理論導數 $ 2\cos(a) $ 一致 。 -
非葉子節點的梯度限制
中間張量(如c或b)默認不存儲梯度,需顯式調用.retain_grad()才能訪問其梯度 。
訓練中的 Autograd 實踐
-
模型參數的梯度計算
在torch.nn.Module中定義的層(如Linear)會自動追蹤權重梯度。例如,模型輸出后通過loss.backward()計算所有參數的梯度,并利用優化器(如 SGD)更新權重 。 -
梯度累積與清零
多次調用.backward()會導致梯度累加,需在每次優化前調用optimizer.zero_grad()避免梯度爆炸。例如,重復 5 次反向傳播后,梯度值會顯著增大,歸零后恢復初始狀態 。
Autograd 的控制與優化
-
啟用/禁用 Autograd
- 直接修改張量的
requires_grad標志 。 - 使用
torch.no_grad()上下文管理器或裝飾器臨時禁用梯度計算(如推理階段)。 - 通過
detach()創建無梯度歷史的副本,用于脫離計算圖(如可視化或數據轉換)。
- 直接修改張量的
-
就地操作(In-place Operations)的限制
Autograd 禁止對需要梯度的葉子張量執行就地操作(如torch.sin_()),以避免破壞計算歷史導致梯度計算錯誤 。 -
性能分析工具
Autograd 內置性能分析器(torch.autograd.profiler),可記錄張量操作的時間開銷(如 CPU/GPU 上的耗時),幫助優化模型 。
總結
Autograd 通過動態計算圖和自動微分機制,簡化了復雜模型的梯度計算,成為 PyTorch 構建高效機器學習項目的核心工具。其靈活性(如支持動態控制流)和易用性(如自動參數追蹤)顯著降低了實現神經網絡的門檻 。
6.動態圖
關鍵行為:
- 動態計算圖:PyTorch 的計算圖是動態的(每次前向傳播會重新構建計算圖)。
- 梯度累加:默認情況下,多次調用
backward()會累加梯度(需手動調用.zero_grad()清零)。 - 內存釋放:默認在
backward()后釋放計算圖(通過retain_graph=False控制)。
6、Python with 語句
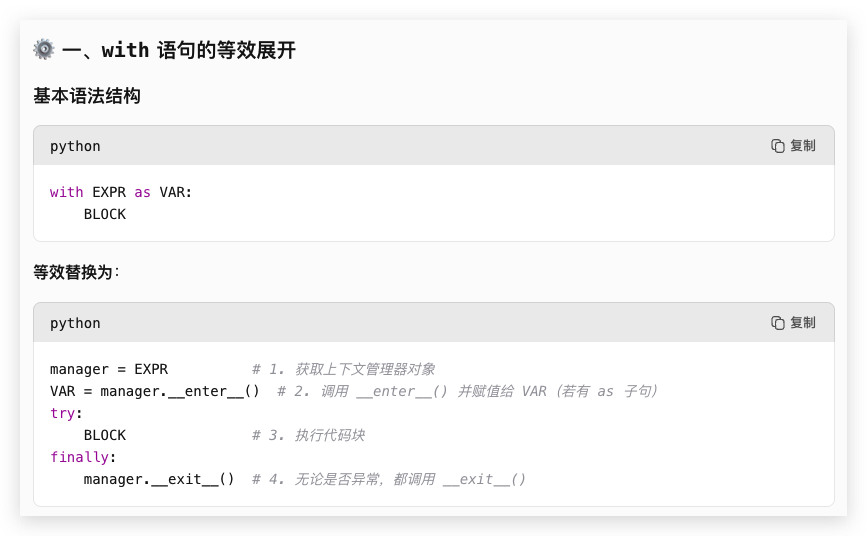

Python 的 with 語句本質是通過**上下文管理器(Context Manager)**自動管理資源的語法糖。其底層邏輯可通過手動調用上下文管理器的 __enter__ 和 __exit__ 方法,并結合 try...finally 塊實現等價替換。以下是詳細的展開邏輯和代碼示例:
Python 中的 with 語句是一種用于資源管理的語法糖,核心作用是確保在代碼塊執行前后,資源能被正確獲取和釋放。它的本質依賴「上下文管理器(Context Manager)」,能自動處理資源的分配與清理,避免因忘記釋放資源(如文件未關閉、網絡連接未斷開)導致的程序錯誤或性能問題。
一、with 語句的執行流程
with 語句的完整執行流程可分解為以下 5 步(假設代碼為 with A() as B: C):
- 執行
A()創建上下文管理器對象(記為cm)。 - 調用
cm.__enter__()方法,返回值賦給變量B(即as后的變量)。 - 執行代碼塊
C(即with縮進內的代碼)。 - 無論代碼塊
C是否拋出異常,最終都會調用cm.__exit__(exc_type, exc_val, exc_tb)方法:exc_type:異常類型(無異常時為None)。exc_val:異常對象(無異常時為None)。exc_tb:異常追蹤信息(無異常時為None)。
- 若
__exit__返回True,則抑制代碼塊中的異常(不向外傳播);若返回False,則異常會繼續向上拋出。
二、with 語句的等價替換代碼
根據上述流程,with 語句可手動展開為以下結構(完全等價):
# 原始 with 語句
with context_expr as var:block# 等價的手動展開代碼
cm = context_expr # 1. 創建上下文管理器對象
var = cm.__enter__() # 2. 調用 __enter__,賦值給 var
try:block # 3. 執行代碼塊
finally:# 4. 無論是否異常,調用 __exit__exc_type, exc_val, exc_tb = sys.exc_info() # 獲取異常信息(若有)# 調用 __exit__,并處理異常抑制邏輯suppress = cm.__exit__(exc_type, exc_val, exc_tb)# 若 __exit__ 返回 True,則抑制異常(不拋出)if suppress:exc_type = exc_val = exc_tb = None# 否則,異常會被自動拋出(由 finally 后的代碼處理)
三、代碼示例:文件操作的展開對比
# 傳統寫法(需手動關閉)
file = open("test.txt", "r")
try:content = file.read()
finally:file.close() # 必須手動關閉,否則可能占用資源# with 寫法(自動關閉)
with open("test.txt", "r") as file:content = file.read() # 代碼塊結束后,file 會自動關閉
原始 with 寫法
with open("test.txt", "r") as f:content = f.read() # 代碼塊執行
# 代碼塊結束后,f 自動關閉(由 __exit__ 處理)
手動展開后的等價代碼
import sys# 1. 創建上下文管理器(文件對象)
cm = open("test.txt", "r")
try:# 2. 調用 __enter__,返回文件對象并賦值給 ff = cm.__enter__()try:# 3. 執行代碼塊content = f.read()finally:# 4. 無論是否異常,調用 __exit__ 關閉文件exc_type, exc_val, exc_tb = sys.exc_info()# 調用文件對象的 __exit__(內部調用 f.close())suppress = cm.__exit__(exc_type, exc_val, exc_tb)# 若 __exit__ 返回 True,抑制異常if suppress:exc_type = exc_val = exc_tb = None
finally:# 確保上下文管理器對象被清理(如文件未關閉時強制關閉)pass
7、with torch.no_grad() 禁用梯度跟蹤
參考:https://pytorch.ac.cn/tutorials/beginner/basics/autogradqs_tutorial.html
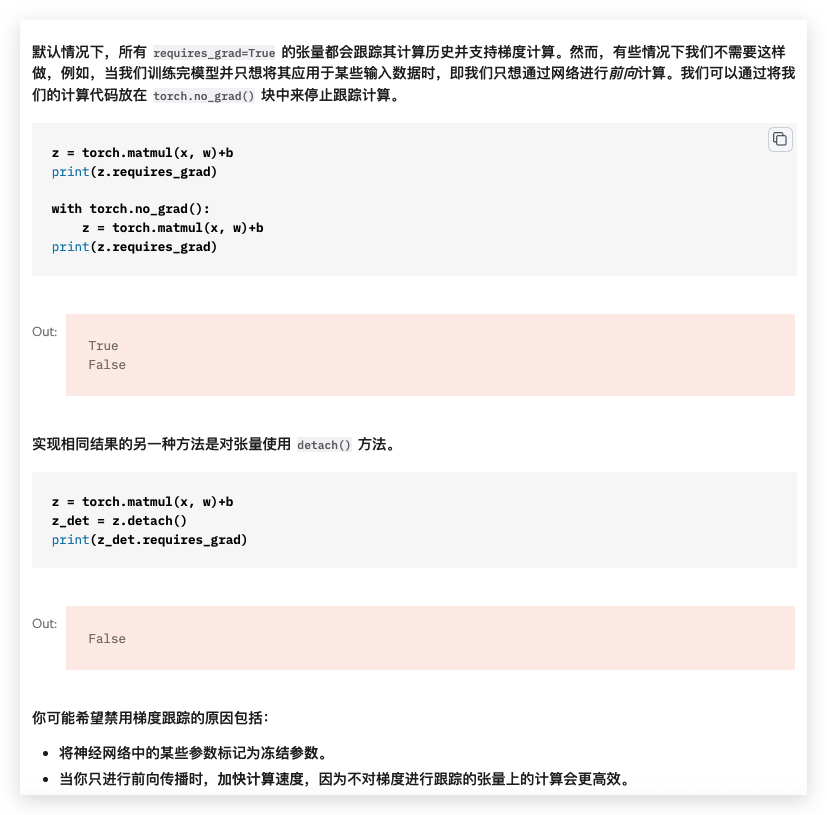
with torch.no_grad(): 是 PyTorch 中用于臨時禁用自動梯度計算的上下文管理器,核心作用是在代碼塊執行期間關閉梯度記錄,從而減少內存消耗并提升計算速度。它是 PyTorch 自動微分(AutoGrad)機制的重要工具,常見于模型推理(預測)、數據預處理等不需要梯度更新的場景。
一、為什么需要 torch.no_grad()?
PyTorch 的自動梯度(AutoGrad)機制會在每次 Tensor 操作時記錄計算圖(Computation Graph),用于后續反向傳播(Backward)時計算梯度。但在以下場景中,梯度計算是冗余的:
- 模型推理(預測):只需前向傳播得到輸出,無需更新模型參數。
- 數據預處理/中間計算:例如特征提取、歸一化等輔助操作,不涉及模型訓練。
- 節省內存:梯度計算需要存儲中間結果(如各節點的梯度值),關閉梯度可顯著減少內存占用(尤其是大模型或批量數據場景)。
二、with torch.no_grad(): 的具體行為
當進入 with torch.no_grad(): 代碼塊時,PyTorch 會臨時禁用自動梯度計算,具體表現為:
-
新創建的 Tensor 默認
requires_grad=False
塊內新建的 Tensor(如x = torch.tensor([1.0]))會被自動標記為不需要梯度(x.requires_grad為False)。 -
已有 Tensor 的梯度計算被跳過
即使塊外的 Tensor 原本requires_grad=True(如模型參數),塊內對其的操作也不會記錄梯度(即不會構建計算圖)。 -
反向傳播(
backward())被禁用
若在塊內嘗試調用loss.backward(),會直接報錯(因無梯度信息可計算)。
三、代碼示例:對比有無 no_grad 的差異
以下通過具體代碼演示 torch.no_grad() 的效果:
示例 1:禁用梯度后,新 Tensor 的 requires_grad 行為
import torch# 塊外:默認 requires_grad=False(普通 Tensor)
x = torch.tensor([2.0])
print(x.requires_grad) # 輸出:False# 塊外:模型參數(通常 requires_grad=True)
w = torch.tensor([3.0], requires_grad=True)
print(w.requires_grad) # 輸出:True# 進入 no_grad 塊
with torch.no_grad():# 塊內新建 Tensor:自動 requires_grad=Falsey = torch.tensor([4.0])print(y.requires_grad) # 輸出:False# 塊內操作已有 Tensor(w):不記錄梯度z = w * x # 等價于 z = w.mul(x)print(z.requires_grad) # 輸出:False(因無梯度記錄)# 塊外:w 的 requires_grad 恢復為 True(不受塊影響)
print(w.requires_grad) # 輸出:True
示例 2:禁用梯度對內存和計算速度的影響(推理場景)
import torch
from time import time# 模擬一個大模型(如 ResNet)
model = torch.nn.Sequential(torch.nn.Linear(1000, 2000),torch.nn.ReLU(),torch.nn.Linear(2000, 1000)
)
input_data = torch.randn(1000, 1000) # 批量數據(1000 樣本)# 無 no_grad:需要記錄梯度(內存占用高,速度慢)
start = time()
output = model(input_data)
loss = output.sum()
loss.backward() # 反向傳播(假設誤操作)
print(f"無 no_grad 耗時:{time()-start:.4f}s")# 有 no_grad:禁用梯度(內存占用低,速度快)
start = time()
with torch.no_grad():output = model(input_data) # 前向傳播不記錄梯度
# 嘗試反向傳播會報錯(因無梯度信息)
# loss = output.sum()
# loss.backward() # 報錯:Trying to backward through a tensor that does not require gradients
print(f"有 no_grad 耗時:{time()-start:.4f}s")
輸出(示意):
無 no_grad 耗時:0.1234s # 耗時更長,內存占用更高
有 no_grad 耗時:0.0456s # 耗時更短,內存占用更低
實現機制圖解
普通前向傳播:
輸入 → [計算圖構建] → 輸出? 保存中間變量用于反向傳播no_grad 模式:
輸入 → [純計算] → 輸出? 不構建計算圖,不保存中間結果
四、常見使用場景
with torch.no_grad(): 主要用于以下不需要梯度計算的場景:
-
模型推理(預測)
部署模型時,只需前向傳播得到預測結果,無需反向更新參數。例如:model.eval() # 切換到推理模式(關閉 Dropout/BatchNorm 等) with torch.no_grad():for batch in test_dataloader:outputs = model(batch)predictions = torch.argmax(outputs, dim=1) -
數據預處理/特征提取
例如從原始數據中提取特征(如用預訓練模型提取圖像特征),不需要梯度:with torch.no_grad():features = pretrained_model(raw_data) # 提取特征 -
梯度驗證或調試
臨時禁用梯度,驗證模型前向計算是否正常(避免反向傳播干擾)。
五、注意事項
- 不影響已有 Tensor 的
requires_grad屬性:no_grad僅臨時禁用梯度計算,不會修改塊外 Tensor 的requires_grad標記(塊外 Tensor 仍保持原有狀態)。 - 與
model.eval()的區別:model.eval()用于切換模型狀態(如關閉 Dropout、固定 BatchNorm 統計量),而no_grad()用于禁用梯度計算,二者常配合使用(推理時既需要模型狀態正確,也需要禁用梯度)。 - 反向傳播必須在塊外:若需要計算梯度(如訓練時),需確保
backward()在no_grad塊外調用。
六、與 model.eval() 的關系
| 操作 | 作用 | 是否互斥 |
|---|---|---|
with torch.no_grad() | 禁用梯度計算 | × |
model.eval() | 關閉Dropout/BatchNorm等特殊層 | × |
最佳實踐:通常同時使用二者
model.eval() with torch.no_grad():# 執行推理或評估
with torch.no_grad(): 是 PyTorch 中的一個上下文管理器,用于臨時禁用梯度計算,具體作用如下:
-
禁用梯度跟蹤
在with torch.no_grad():包裹的代碼塊中,所有張量操作都不會記錄梯度(即不會構建計算圖),即使輸入張量的requires_grad=True,輸出張量的requires_grad也會被強制設為False。這避免了反向傳播所需的內存開銷,顯著減少顯存占用并加速計算 。 -
適用場景
主要用于模型推理(如預測階段)或模型評估(如驗證集測試),因為這些場景不需要梯度計算 。此外,在更新模型參數時(如手動優化器步驟),也可通過此上下文管理器避免梯度被意外跟蹤 。 -
與
@torch.no_grad()的關系
with torch.no_grad():是上下文管理器形式,作用范圍僅限代碼塊;而@torch.no_grad()是裝飾器形式,作用于整個函數或方法 。兩者功能相同,均通過局部禁用梯度計算優化資源 。 -
注意事項
- 不會影響模型參數的
requires_grad屬性(即可訓練參數集合不變)。 - 若需切換模型到評估模式(如關閉 Dropout 或 BatchNorm 的訓練行為),需額外調用
model.eval()。
示例代碼:
model = MyModel().eval() # 切換評估模式 with torch.no_grad(): # 禁用梯度計算output = model(input_tensor) # 推理過程無需構建計算圖 - 不會影響模型參數的
總結
with torch.no_grad(): 本質是:
臨時關閉autograd引擎 → 執行代碼 → 恢復原狀態
它是PyTorch的推理加速器,通過避免不必要的梯度計算
with torch.no_grad(): 是 PyTorch 中控制自動梯度的核心工具,通過臨時關閉梯度計算,能有效減少內存消耗并提升計算效率,是模型推理、數據預處理等場景的“性能優化利器”。理解其行為和適用場景,能幫助你更高效地編寫 PyTorch 代碼。
8、model.train()和model.eval()
0.匯總
Dropout 層通過在 訓練期間 隨機設置輸入張量的部分來工作——Dropout
層在推理時總是關閉的。這迫使模型針對這個掩蔽或縮減的數據集進行學習。 (請注意,我們在訓練前總是調用參考:https://pytorch.ac.cn/tutorials/beginner/introyt/modelsyt_tutorial.html
model.train(),在推理前調用 model.eval(),因為這些函數會被 nn.BatchNorm2d 和 nn.Dropout
等層使用,以確保它們在不同階段的正確行為。)參考
(注意,view 是 PyTorch 中的版本,對應于 Numpy 的 reshape)
model.train()、model.eval()和mode.test
-
模型的訓練模式(train mode):
model.train():在使用 pytorch 構建神經網絡的時候,訓練過程中會在程序上方添加一句model.train( ),作用是啟用 batch normalization 和 dropout 。如果模型中有BN層(Batch Normalization)和 Dropout ,需要在訓練時添加 model.train( )。model.train( ) 是保證 BN 層能夠用到每一批數據的均值和方差。對于 Dropout,model.train( ) 是隨機取一部分網絡連接來訓練更新參數。
-
模型評估方法有兩種:
-
model.eval():將模型設置為評估模式,用于在驗證集或測試集上評估模型性能。在評估模式下,模型會將dropout和batch normalization等層設置為不工作,這樣可以保證每次評估得到的結果是一致的。同時,評估模式下還可以通過設置torch.no_grad()來禁用梯度計算,避免浪費計算資源。 -
model.test():該方法在pytorch中并不存在,可能是因為評估模式下已經能夠滿足測試需求。在一些框架中,test模式通常用于模型的推理階段,即將模型應用到真實數據上進行預測。與評估模式類似,test模式也會將dropout和batch normalization等層設置為不工作,以保證每次預測結果一致。但是,test模式通常需要考慮一些其他因素,例如數據增強(data augmentation)、模型融合(model ensemble)等。
-
訓練模式與評估模式的區別
在Pytorch中,模型的訓練模式(train mode)和評估模式(eval mode)之間有幾個關鍵區別。
- Batch Normalization和Dropout層的行為不同:在訓練模式下,Batch Normalization和Dropout被啟用,能夠提高模型的泛化能力。而在評估模式下,他們被禁用,以確保模型的輸出穩定和可重復。
- 梯度計算和權重更新不同:在訓練模式下,模型會自動計算每個參數的梯度,并通過優化器進行權重更新。而在評估模式下,模型只進行前向傳播,并不進行梯度計算和權重更新。
- 總結與對比
- 如果模型中有 BN 層(Batch Normalization)和 Dropout,需要在訓練時添加 model.train(),在測試時添加 model.eval( )。
- 其中
model.train( ) 是保證 BN 層用每一批數據的均值和方差,而 model.eval( ) 是保證 BN 用全部訓練數據的均值和方差; - 而對于 Dropout,model.train( ) 是隨機取一部分網絡連接來訓練更新參數,而 model.eval( ) 是利用到了所有網絡連接。
獲取當前模式的方法:
在Pytorch中,可以通過以下兩種方法來檢查模型的當前模式
- 通過model.training屬性來檢查:model.training屬性返回一個布爾值,表示當前模型是否處于訓練模式。如果返回True,則表示模型處于訓練模式;如果返回False,則表示模型處于評估模式。
- 通過model.mode屬性來檢查:model.mode是Pytorch中自定義的模型屬性,用于表示模型的模式。可以通過自定義的model.set_mode()方法來設置模型的模式。在set_mode()方法中,可以根據需要設置model.training屬性,并更新model.mode屬性。通過model.get_mode()方法可以獲取當前模型的模式。
在深度學習框架(如PyTorch)中,model.train()、model.eval() 和自定義的 model.test() 用于控制模型在不同階段的行為。以下是詳細解釋:
1. model.train()
model.train() 的作用是將模型設置為訓練模式。此時,模型中的某些層(如 Dropout、BatchNorm 等)會啟用與訓練相關的特性:
-
Dropout 層:會隨機“關閉”部分神經元(按設定的概率),防止過擬合。
-
BatchNorm 層:會根據當前批次數據的均值和方差計算歸一化參數,并更新全局的均值/方差統計量(通過移動平均)。
-
作用:
將模型設置為訓練模式,啟用訓練相關的特定行為。 -
關鍵影響:
- Dropout層:按照設定的概率隨機丟棄神經元,防止過擬合。
- Batch Normalization層:使用當前批次的均值和方差進行歸一化,并更新全局統計量(移動平均)。
-
使用場景:
在訓練循環中調用,確保模型以訓練模式處理數據。model.train() # 設置訓練模式 for data, labels in train_loader:outputs = model(data)loss = criterion(outputs, labels)loss.backward()optimizer.step()
2. model.eval()
model.eval() 的作用是將模型設置為評估模式(推理模式)。此時,模型中的訓練相關特性會被關閉:
- Dropout 層:不再隨機失活神經元(所有神經元保持激活),確保推理結果的穩定性。
- BatchNorm 層:不再更新全局統計量,而是使用訓練階段累積的均值/方差(如
running_mean和running_var)進行歸一化,避免推理時因批次數據波動導致結果不穩定。 - 作用:
將模型設置為評估模式,關閉訓練特有的行為。 - 關鍵影響:
- Dropout層:禁用隨機丟棄,使用所有神經元。
- Batch Normalization層:使用訓練階段積累的全局均值和方差(而非當前批次),保持輸出穩定。
- 自動梯度計算:通常與
torch.no_grad()配合使用,減少內存占用。
- 使用場景:
在驗證/測試/推理階段調用,確保結果可復現且一致。model.eval() # 設置評估模式 with torch.no_grad(): # 禁用梯度計算for data, labels in test_loader:outputs = model(data)accuracy = calculate_accuracy(outputs, labels)
3. model.test()(自定義方法)
PyTorch 等框架沒有內置的 model.test() 方法。它通常是用戶自定義的方法,用于實現測試階段的邏輯(如加載測試數據、計算指標等)。
- 注意:
PyTorch沒有內置的model.test()方法。這是一個用戶自定義的擴展,通常用于:- 封裝測試邏輯:計算指標(如準確率、F1分數)。
- 特殊測試行為:例如在特定數據集上評估模型。
- 典型實現:
class MyModel(nn.Module):def __init__(self):super().__init__()self.layer = nn.Linear(10, 2)def forward(self, x):return self.layer(x)def test(self, test_loader):self.eval() # 切換到評估模式total_correct = 0with torch.no_grad():for data, labels in test_loader:outputs = self(data)preds = outputs.argmax(dim=1)total_correct += (preds == labels).sum().item()accuracy = total_correct / len(test_loader.dataset)print(f"Test Accuracy: {accuracy:.4f}") - 調用方式:
model = MyModel() model.load_state_dict(torch.load("model.pth")) model.test(test_loader) # 執行自定義測試邏輯
4.關鍵區別總結
| 方法 | 模式 | Dropout/BN 行為 | 梯度計算 | 主要用途 |
|---|---|---|---|---|
model.train() | 訓練模式 | Dropout激活;BN用當前批次統計 | 啟用 | 訓練階段 |
model.eval() | 評估模式 | Dropout關閉;BN用全局固定統計 | 通常禁用 | 驗證/測試/推理 |
model.test() | 自定義邏輯 | 需手動調用 eval() | 通常禁用 | 封裝測試流程 |
5.最佳實踐
- 訓練階段:
model.train() # 明確設置訓練模式 # 訓練循環... - 測試階段:
model.eval() # 切換到評估模式 with torch.no_grad():# 測試循環... - 自定義測試:
在模型中實現test()方法,內部調用eval()和torch.no_grad(),并包含指標計算邏輯。
9、設置訓練設備accelerator
詳細參考:參考
我們希望能夠在 加速器 上訓練我們的模型,例如 CUDA、MPS、MTIA 或 XPU。如果當前加速器可用,我們將使用它。否則,我們使用 CPU。
參考:https://pytorch.ac.cn/tutorials/beginner/basics/buildmodel_tutorial.html
device = torch.accelerator.current_accelerator().type if torch.accelerator.is_available() else "cpu"
print(f"Using {device} device")
10、優化器(torch.optim)
torch.optim 是 PyTorch 中用于優化神經網絡模型參數的核心模塊,它實現了多種優化算法(如 SGD、Adam、RMSprop 等),通過計算損失函數對參數的梯度并更新模型權重,以最小化損失函數。以下是關于 torch.optim 的詳細解析:
1. 核心功能
- 優化算法實現:提供多種優化算法(如 SGD、Adam、Adagrad、RMSprop 等)。
- 動態學習率調整:支持學習率調度器(如
lr_scheduler)動態調整學習率。 - 參數更新:通過梯度反向傳播更新模型參數。
2. 常見優化器
2.1 SGD(隨機梯度下降)
- 特點:基礎優化算法,適用于大多數簡單任務。
- 公式:
θ t + 1 = θ t ? η ? ? θ J ( θ t ) \theta_{t+1} = \theta_t - \eta \cdot \nabla_\theta J(\theta_t) θt+1?=θt??η??θ?J(θt?) - 參數:
lr:學習率(控制步長)。momentum:動量因子(加速收斂,默認 0)。dampening:動量阻尼(默認 0)。nesterov:是否使用 Nesterov 動量(默認False)。
- 示例:
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
2.2 Adam(自適應矩估計)
- 特點:結合動量法和自適應學習率,適合大規模數據和復雜模型。
- 參數:
lr:學習率(默認 0.001)。betas:一階矩和二階矩的平滑系數(默認(0.9, 0.999))。eps:數值穩定性項(默認1e-8)。weight_decay:權重衰減(L2 正則化)。
- 示例:
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
2.3 RMSprop
- 特點:Adagrad 的改進版,解決學習率過早衰減的問題。
- 參數:
lr:學習率。alpha:平滑常數(默認 0.99)。eps:數值穩定性項。
- 示例:
optimizer = torch.optim.RMSprop(model.parameters(), lr=0.01)
2.4 Adagrad
- 特點:自適應優化算法,為每個參數分配不同的學習率。
- 參數:
lr:學習率。lr_decay:學習率衰減(默認 0)。
- 示例:
optimizer = torch.optim.Adagrad(model.parameters(), lr=0.01)
3. 優化器核心操作
3.1 初始化優化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
3.2 zero_grad()
- 功能:清除所有參數的梯度,避免梯度累積。
- 示例:
optimizer.zero_grad()
3.3 loss.backward()
- 功能:計算損失函數對參數的梯度(反向傳播)。
3.4 step()
- 功能:根據梯度更新參數。
- 示例:
optimizer.step()
3.5 state_dict() 和 load_state_dict()
- 功能:保存和加載優化器狀態(如動量、學習率等)。
- 示例:
# 保存狀態 torch.save(optimizer.state_dict(), "optimizer.pth") # 加載狀態 optimizer.load_state_dict(torch.load("optimizer.pth"))
4. 學習率調整(lr_scheduler)
4.1 StepLR
- 功能:按固定周期衰減學習率。
- 示例:
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
4.2 ReduceLROnPlateau
- 功能:根據驗證集性能動態調整學習率。
- 示例:
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=5)
4.3 CosineAnnealingLR
- 功能:余弦退火策略,周期性調整學習率。
- 示例:
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=50)
5. 完整訓練流程示例
import torch
import torch.nn as nn
import torch.optim as optim# 定義模型
class SimpleNet(nn.Module):def __init__(self):super().__init__()self.fc = nn.Linear(10, 2)def forward(self, x):return self.fc(x)model = SimpleNet()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 模擬數據
inputs = torch.randn(32, 10) # 32個樣本,10維特征
targets = torch.randint(0, 2, (32,)) # 32個標簽# 訓練循環
for epoch in range(10):optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, targets)loss.backward()optimizer.step()print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")
6. 高級用法
6.1 為不同參數組設置不同超參數
optimizer = optim.Adam([{'params': model.base.parameters(), 'lr': 1e-2},{'params': model.classifier.parameters(), 'lr': 1e-3}
], lr=1e-2) # 默認學習率
6.2 添加鉤子(Hook)
- 功能:在優化器狀態加載/保存前后插入自定義邏輯。
- 示例:
optimizer.register_load_state_dict_pre_hook(my_pre_hook) optimizer.register_load_state_dict_post_hook(my_post_hook)
7. 總結
- 選擇優化器:
- 簡單任務:SGD(可加動量)。
- 復雜任務:Adam(默認選擇)。
- 大規模數據:RMSprop 或 Adagrad。
- 調參建議:
- 學習率(
lr):通常在[1e-5, 1e-1]范圍內搜索。 - 動量(
momentum):SGD 中常用 0.9。 - 權重衰減(
weight_decay):防止過擬合,通常設為1e-4或1e-5。
- 學習率(
如果需要更具體的優化器配置或調度策略的示例,請告訴我!
11、TensorBoard 可視化模型、數據和訓練
https://pytorch.ac.cn/tutorials/intermediate/tensorboard_tutorial.html
https://pytorch.ac.cn/tutorials/beginner/introyt/tensorboardyt_tutorial.html
PyTorch 集成了 TensorBoard,這是一個專門用于可視化神經網絡訓練結果的工具。本教程將介紹 TensorBoard 的一些功能,使用 Fashion-MNIST 數據集,該數據集可以使用 torchvision.datasets 加載到 PyTorch 中。
在本教程中,我們將學習如何
-
讀取數據并進行適當的變換 (與之前的教程幾乎相同)。
-
設置 TensorBoard。
-
向 TensorBoard 寫入數據。
-
使用 TensorBoard 檢查模型架構。
-
使用 TensorBoard 創建我們在上一個教程中創建的可視化的交互式版本,并減少代碼量
12、Captum(次要)
參考:https://pytorch.ac.cn/tutorials/beginner/introyt/captumyt.html
Captum (在拉丁語中意為“理解”) 是一個構建于 PyTorch 之上的開源、可擴展的模型可解釋性庫。
隨著模型復雜性的增加以及由此導致的透明度不足,模型可解釋性方法變得越來越重要。模型理解既是一個活躍的研究領域,也是機器學習在各行各業實際應用的重點領域。Captum 提供了最先進的算法,包括集成梯度 (Integrated Gradients),為研究人員和開發者提供一種簡單的方式來理解哪些特征對模型的輸出有所貢獻。
完整的文檔、API 參考和針對特定主題的一系列教程可在 captum.ai 網站上找到。
引言
Captum 對模型可解釋性的方法基于歸因。Captum 中提供了三種類型的歸因
特征歸因 (Feature Attribution) 旨在根據生成特定輸出的輸入特征來解釋該輸出。解釋一篇影評是積極還是消極,通過影評中的某些詞語來理解,就是特征歸因的一個例子。
層歸因 (Layer Attribution) 檢查模型隱藏層在接收特定輸入后的活動情況。檢查卷積層對輸入圖像的空間映射輸出就是一個層歸因的例子。
神經元歸因 (Neuron Attribution) 類似于層歸因,但側重于單個神經元的活動。
13、深度學習書籍
https://course.fastai.net.cn/
我們首先只使用 PyTorch 張量操作創建一個模型。我們假設你已經熟悉神經網絡的基礎知識。(如果你不熟悉,可以在 course.fast.ai 上學習)。(參考:https://pytorch.ac.cn/tutorials/beginner/nn_tutorial.html)
面向初學者的 NLP 入門(fastai中的):https://www.kaggle.com/code/jhoward/getting-started-with-nlp-for-absolute-beginners
14、入門實戰示例
https://pytorch.ac.cn/tutorials/beginner/basics/quickstart_tutorial.html
https://pytorch.ac.cn/tutorials/beginner/nn_tutorial.html#mnist-data-setup
https://pytorch.ac.cn/pytorch-domains(PyTorch 提供特定領域的庫,例如 TorchText、TorchVision 和 TorchAudio)
1、TorchVision-FashionMNIST
FashionMNIST示例:
https://pytorch.ac.cn/tutorials/beginner/basics/quickstart_tutorial.html
https://github.com/pytorch/tutorials/blob/master/beginner_source/basics/quickstart_tutorial.py
數據集:TorchVision
https://pytorch.ac.cn/vision/stable/datasets.html
PyTorch 提供特定領域的庫,例如 TorchText、TorchVision 和 TorchAudio,所有這些庫都包含數據集。在本教程中,我們將使用 TorchVision 數據集。
torchvision.datasets 模塊包含許多真實世界視覺數據的 Dataset 對象,例如 CIFAR、COCO(完整列表在此)。在本教程中,我們使用 FashionMNIST 數據集。每個 TorchVision Dataset 都包含兩個參數:transform 和 target_transform,分別用于修改樣本和標簽。
2、TorchText–NLP
https://pytorch.ac.cn/text/stable/index.html
https://pytorch.ac.cn/text/stable/index.html (數據集)
本教程是一個三部分系列的一部分
- 從零開始學自然語言處理:使用字符級 RNN 對名字進行分類
- 從零開始學自然語言處理:使用字符級 RNN 生成名字
- 從零開始學自然語言處理:使用序列到序列網絡和注意力機制進行翻譯
RNN和LSTM原理參考
循環神經網絡令人驚嘆的有效性 展示了大量現實生活中的示例
理解 LSTM 網絡 專門關于 LSTM,但也提供關于 RNN 的通用信息
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
https://karpathy.github.io/2015/05/21/rnn-effectiveness/
3、強化學習
https://pytorch.ac.cn/tutorials/intermediate/reinforcement_q_learning.html
強化學習 (DQN) 教程
使用 TorchRL 的強化學習 (PPO) 教程
訓練玩馬里奧的 RL 智能體
Pendulum: 使用 TorchRL 編寫環境和變換
4、秘籍–PyTorch 代碼示例集
秘籍是短小精悍、可操作的示例,展示了如何使用特定的 PyTorch 功能,與我們的完整教程不同。
https://pytorch.ac.cn/tutorials/recipes/recipes_index.html
將動態量化應用于簡單的 LSTM 模型。
https://pytorch.ac.cn/tutorials/recipes/recipes/dynamic_quantization.html






)
)





)





