HTTP常用狀態碼及含義?

301和302區別?
- 301:永久性移動,請求的資源已被永久移動到新位置。服務器返回此響應時,會返回新的資源地址。
- 302:臨時性性移動,服務器從另外的地址響應資源,但是客戶端還應該使用這個地址。
HTTP有哪些請求方式?

PUT是新建或替換指定資源?
GET可以實現寫操作嗎?
可以但不建議,可能會導致嚴重的安全問題,如跨站請求偽造(CSRF)。
開發過程中杜絕使用GET,并在接口上明確規定使用哪種請求方式,請求方式錯誤會返回405
什么是冪等,冪等方式有哪些?
無論操作執行多少次,,對服務器狀態產生的影響是相同的。
在正確實現的條件下,GET、HEAD、PUT 和 DELETE 等方法都是冪等的,而 POST 方法不是。
GET和POST的區別
傳參方式/是否緩存:GET的參數明文放在URL中(告訴服務器自己要找哪些資源),來做一些簡單的請求資源操作,可能被瀏覽器緩存,不安全;POST將請求數據放在請求體中而不是URL中,讓服務器來處理這些數據,如果用HTTPS的話請求體是加密的,更加安全,并且一般不會被緩存。
冪等性:GET請求是冪等的,不會改變服務器的狀態;POST不是冪等的,會對服務器的數據有影響
GET的長度限制?
GET是通過URL 傳遞數據,但是URL本身不限長度,所以對GET做出長度限制的其實是瀏覽器。
例如 IE 瀏覽器對 URL 的最大限制是 2000 多個字符,大概 2kb 左右,像 Chrome、Firefox 等瀏覽器支持的 URL 字符數更多,其中 FireFox 中 URL 的最大長度限制是 65536 個字符,Chrome 則是 8182 個字符。
這個長度限制也不是針對數據部分,而是針對整個 URL。
HTTP請求的過程和原理
HTTP是基于TCP/IP的應用層協議,使用TCP作為傳輸層協議,通過建立TCP連接來傳輸數據。HTTP遵循標準的客戶端-服務端模型。
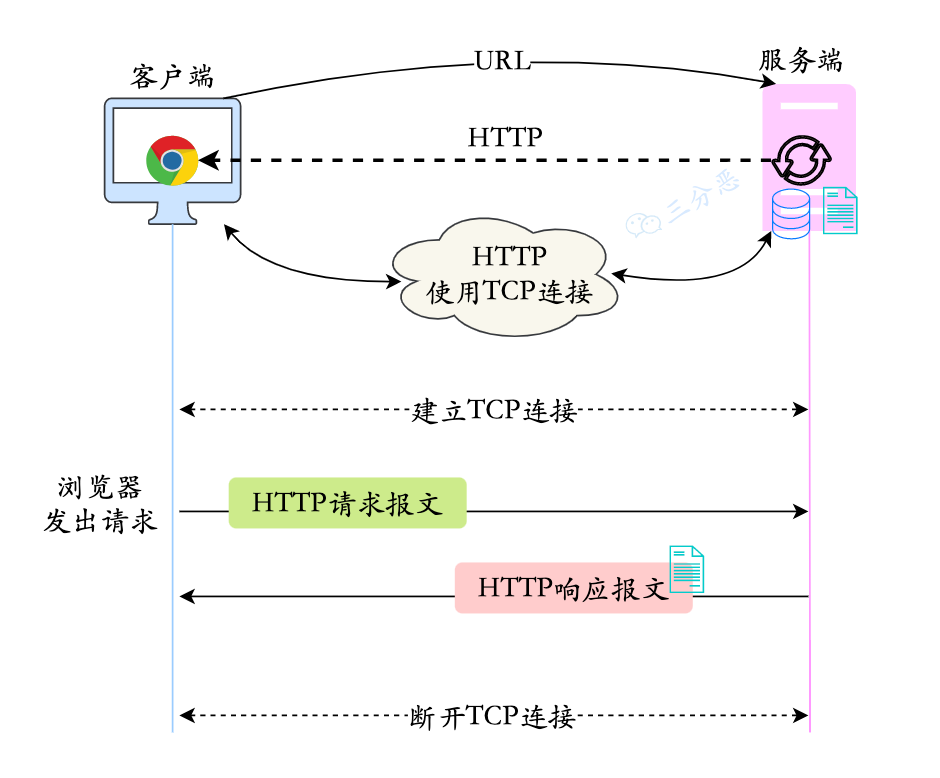
?DNS解析、TCP連接、HTTP請求、服務器處理響應、斷開TCP連接。
客戶端發送一個請求到服務器,服務器處理請求并返回一個響應。這個過程是同步的,也就是說,客戶端在發送請求后必須等待服務器的響應。在等待響應的過程中,客戶端不會發送其他請求。
怎么利用多線程下載一個數據??
- 采用分塊下載,通過設置 HTTP 請求頭的 Range 字段指定下載的字節區間。例如,
Range: bytes=0-1023?表示下載文件的前 1024 字節。 - 首先通過HEAD請求獲取文件的總大小,然后根據文件大小和線程數對文件進行切割「connection.setRequestProperty("Range", "bytes=" + start + "-" + end);」,每個線程都獲取一個輸入流,負責一個特定范圍的文件下載(本地待寫入的RandomAccessFile文件從start開始:file.seek(start))。
- 最后啟動多線程下載。
說一下HTTP的報文結構?
HTTP報文分為請求報文和相應報文,都包含了起始行、頭部和消息正文
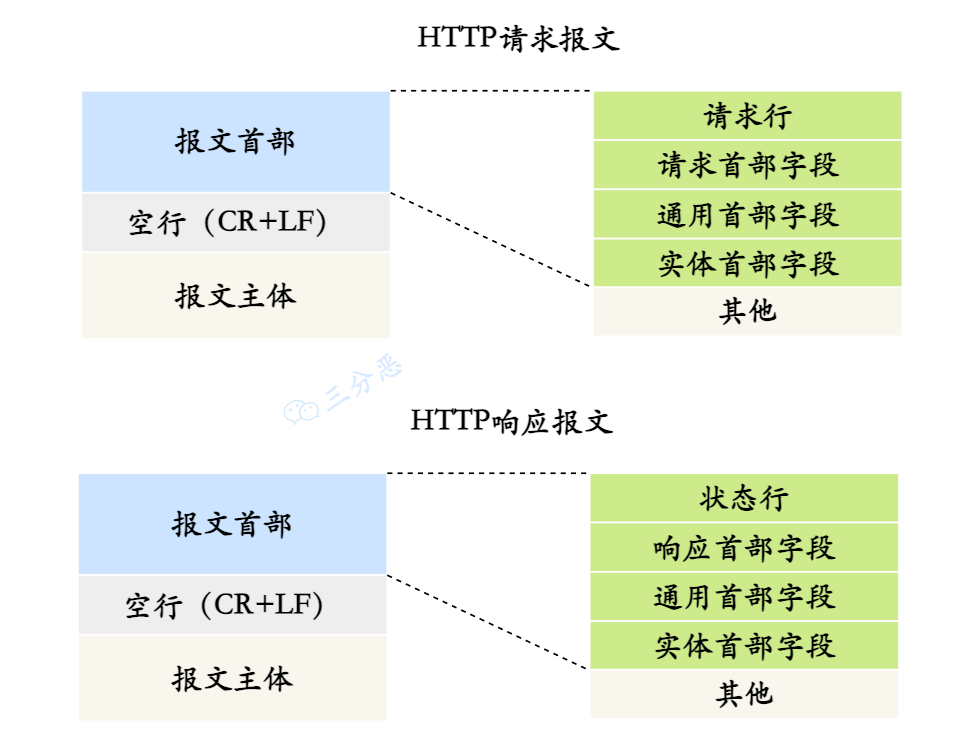 HTTP請求報文的結構
HTTP請求報文的結構
由請求行,請求頭和消息正文(請求體)組成
GET?/index.html?HTTP/1.1 //請求行包括請求方法、請求 URL 和 HTTP 協議的版本
Host:?www.javabetter.cn //請求頭包括主機名、可接受媒體類型、瀏覽器類型,請求內容的范圍等
Accept:?text/html
User-Agent: AppleWebKit/537.36?(KHTML,?like?Gecko)?Chrome/58.0.3029.110?Safari/537.3
請求頭部和消息正文之間有一個空行,表示請求頭部結束。
消息正文是可選的,POST 請求中的表單數據;GET 請求中沒有消息正文
HTTP響應報文的結構
由狀態行、響應頭和消息征文(響應體)組成
HTTP/1.0?200?OK //狀態行包括HTTP的版本、狀態碼、狀態信息
Content-Type:?text/plain //響應頭包括響應數據類型、響應數據長度、資源過期時間、資源最后修改時間、服務器類型和版本
Content-Length:?137582
Expires:?Thu,?05?Dec?1997?16:00:00?GMT
Last-Modified:?Wed,?5?August?1996?15:55:28?GMT
Server:?Apache?0.84
空行
// 響應體也是可選的,通常是HTML頁面,也可能是?204 No Content 狀態碼的響應。
<html>
??<body>Java八股</body>
</html>
URI和URL區別
- URI:統一資源標識符(Uniform Resource Identifier),標識的是Web上每一種可用資源,比如HTML文檔、圖像、視頻片段、程序等都是由URI標識等
- URL:統一資源定位符(Uniform Resource Location)是URI的子集,主要作用是提供資源的路徑。
主要區別在于URL除了提供了資源的標識,還提供了資源的訪問方式,所有能夠唯一標識一個資源的字符串就是URI,但是只有指明了如何定位或訪問這個資源的URI才是URL
HTTP 1.0和HTTP2.0的區別??
HTTP 1.0默認是短連接,HTTP 1.1默認是長連接,HTTP 2.0默認是多路復用
說下HTTP 1.0
- 非持久連接:每個HTTP響應對之后TCP都會關閉連接,每次相同的請求也要重新建立TCP連接,可以設置Connection: keep alive開啟長連接
- 無狀態協議:HTTP 1.0是無狀態的,每次請求是獨立的,服務器不保存任何請求的狀態信息
說下HTTP 1.1
- 持久連接:HTTP 1.1默認情況下是持久連接,請求完成后不會立即關閉連接,可以在一個連接上發送多次請求和響應,減輕了TCP連接的開銷。
- 流水線處理:HTTP 1.1支持客戶端在請求還未返回響應時發送下一個請求,但服務器必須按照接收到請求的順序依次返回響應。
說下HTTP 2.0
目前使用最廣泛的HTTP版本
- 二進制協議:HTTP 2.0采用二進制而不是文本格式來傳輸數據,解析更高效
- 多路復用:一個TCP連接上可以同時進行多個HTTP請求/響應,解決了頭阻塞的問題
- 頭部壓縮:HTTP協議不帶狀態,所以每次請求都要附上全部信息。HTTP 2.0引入了頭部壓縮機制,可以使用gzip或compress壓縮之后再發送,減少了冗余的頭部信息。
- 服務器推送:服務器可以向客戶端主動推送信息,而不需要客戶端請求。
HTTP/3了解嗎?
HTTP2雖然邏輯上各個流之間相互獨立,但是在傳輸的過程中,如果某個流的數據有丟包,其后的流仍然會阻塞,HTTP/3采用的是QUIC,快速UDP連接,相比于采用TCP連接的HTTP2,HTTP3能夠實現各個流之間的完全獨立,互不干擾。同時QUIC協議能夠實現在傳輸過程中就完成了TLS加密握手,更直接了。
HTTP長連接什么時候會超時?
可以在HTTP方面或TCP方面設置
HTTP有一個守護進程httpd,其中可以設置keep-alive timeout,也可以在header中設置超時時間
TCP的keep-alive包含三個參數,在系統內核的net.ipv4里設置,如果TCP閑置時間超過了tcp_keepalive_time,就會發送偵測包,并每隔tcp_keepalive_intvl發送一次,一共發送tcp_keepalive_probes后如果還沒有收到客戶端的ACK,就會關閉連接
tcp_keepalive_intvl?=?15
tcp_keepalive_probes?=?5
tcp_keepalive_time?=?1800
HTTP與HTTPS的區別?
HTTPS是加密的,在HTTP基礎上加入了SSL/TSL協議。
HTTP 的默認端?號是 80,URL 以http://開頭;HTTPS 的默認端?號是 443,URL 以https://開頭。
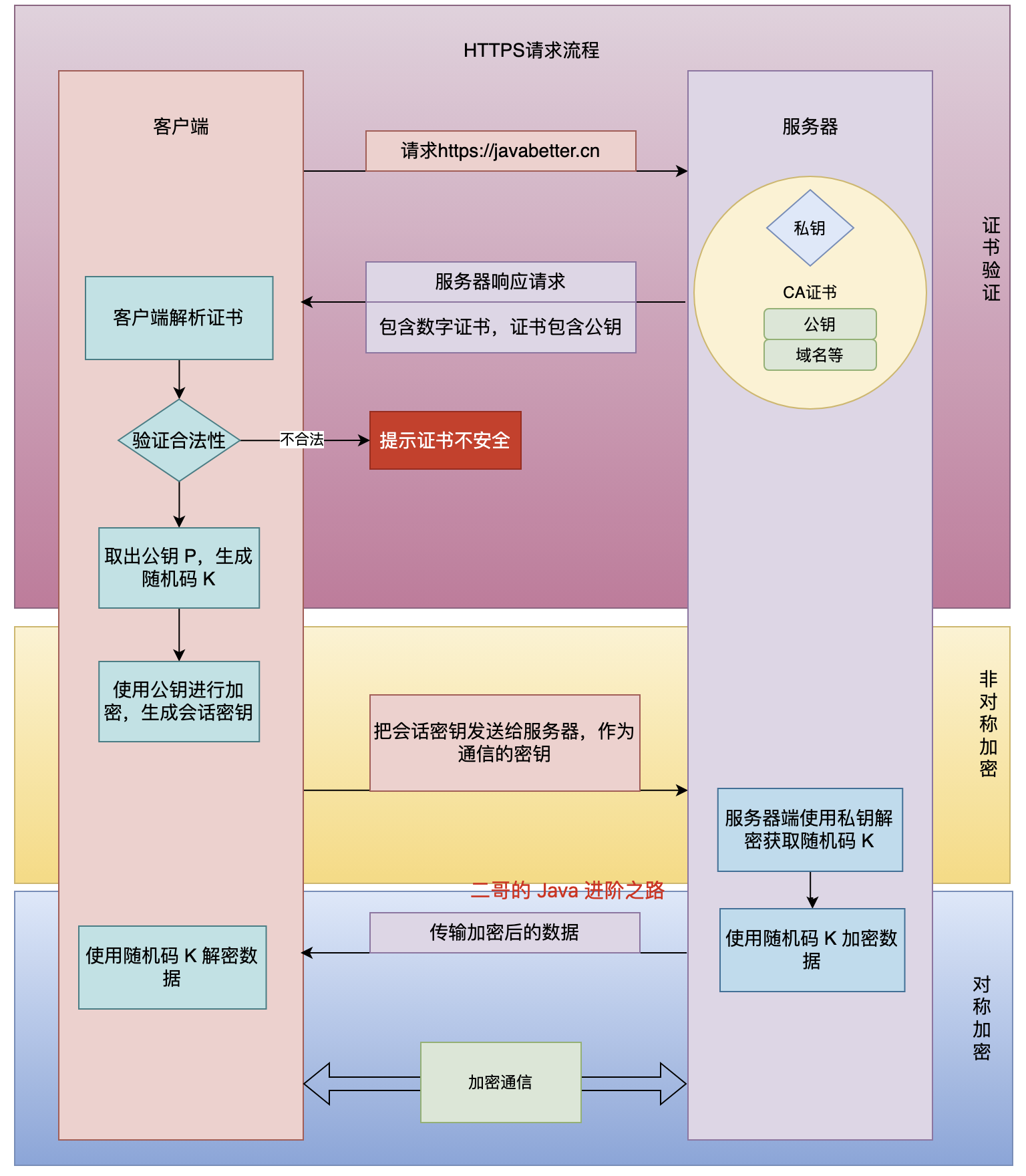
為什么要使用HTTPS?
因為HTTP是明文傳輸的,存在數據竊聽、數據篡改和數據偽造等,HTTP引入了SSL/TSL解決了這些問題。
SSL/TSL加密過程中涉及到兩種加密方法:
對稱加密:雙方用會話密鑰加密通信內容。
非對稱加密:
- 服務器身份驗證: 客戶端通過服務器發送的數字證書(由CA簽發,內含服務器公鑰)來驗證服務器身份。客戶端使用預裝的CA公鑰驗證證書簽名。
- 客戶端生成預主密鑰: 客戶端生成一個隨機的預主密鑰。
- 客戶端加密預主密鑰: 客戶端使用從服務器證書中獲得的服務器公鑰來加密這個預主密鑰。
- 客戶端發送加密數據: 客戶端將加密后的預主密鑰發送給服務器。
- 服務器解密預主密鑰: 服務器使用自己的私鑰解密收到的數據,得到預主密鑰。
- 雙方派生會話密鑰: 客戶端和服務器現在都擁有了相同的預主密鑰、以及之前交換的Client Random和Server Random。它們各自使用這些信息通過密鑰派生函數計算出相同的對稱會話密鑰(通常包括用于加密的密鑰和用于消息認證碼MAC的密鑰)。
- 安全通信: 之后,雙方使用這個派生出的對稱會話密鑰進行加密和解密實際的HTTP應用數據。
HTTPS是怎么建立連接的?
握手階段和數據傳輸階段。
HTTPS會加密URL嗎?
HTTPS會加密整個報文,URL是報文的一部分,所以也會被加密,但因為涉及SSL握手的過程,所以域名信息會被暴露出來,完整的URL也有可能會在日志中被記錄,這些日志可能是明文的。
所以即使使用HTTPS,敏感信息也不要寫入URL
什么是中間人攻擊?
MITM,攻擊者可以在通信雙方的中間插入自己。
SSL 協議就是通過驗證服務器的數字證書是否是由 CA(權威的受信任的數字證書認證機構)簽發來防止中間人攻擊的。
HTTPS怎么保證建立的信道是安全的?
主要通過 SSL/TLS 協議的多層次安全機制,首先在握手階段,客戶端和服務器使用得是非對稱加密,生成的會話密鑰只有服務器的私鑰才能解密,而私鑰只有服務器持有。
在數據傳輸階段,即使攻擊者攔截了通信數據,沒有會話密鑰也無法解密。
HTTP可以被抓包嗎?
可以,但是信息是加密的,如果中間人通過偽造CA證書騙取客戶端信任,那么就有可能得到會話密鑰,再偽裝客戶端和服務器通信,服務器的響應轉發給客戶端,完成中間人攻擊。
常用的抓包工具有 Wireshark、Fiddler、Charles 等。
CA證書的簽發過程?
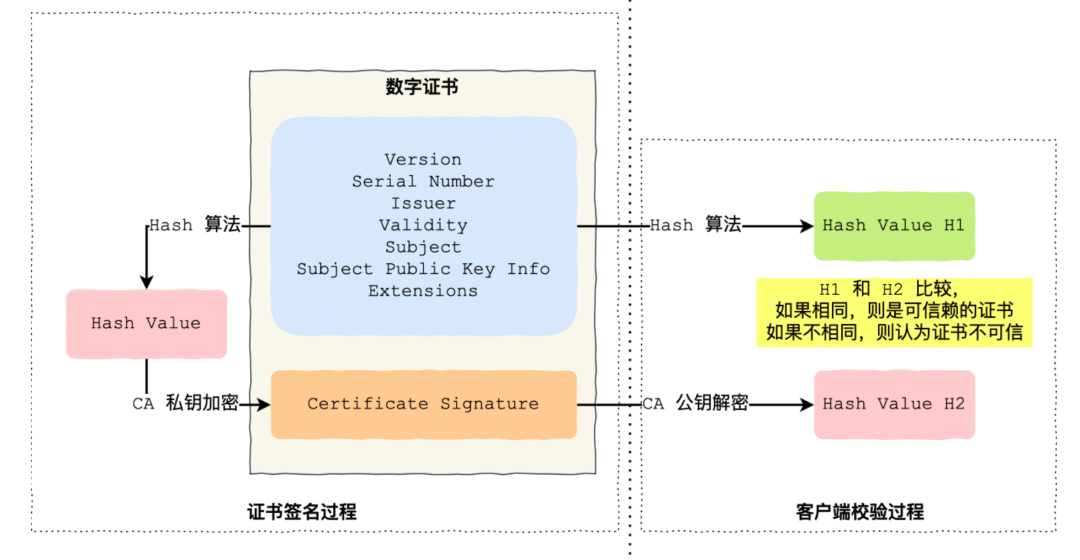
CA將申請方的公鑰,域名,證書過期時間,證書頒發方、簽名算法標識符等信息打成一個包(證書),然后進行Hash值計算,然后通過CA的私鑰加密這個Hash值,生成簽名,最后把簽名放入證書中。
客戶端如何校驗證書的合法性?
首先檢查證書的頒發者(通過比對內置的CA列表)、所有者、頒發日期、是否被吊銷,持有方的域名。
檢查通過后,用內置的CA中的公鑰解密簽名的內容,得到一個Hash2。
用同樣的Hash算法獲取證書的Hash值Hash1,比較Hash1和Hash2,如果值相同則為可信賴的證書。
如何理解HTTP協議是無狀態的?
- 每個 HTTP 請求都包含了所有所必須的信息,服務器在處理當前請求時,不依賴于之前的任何請求信息。
- 服務器不會記錄任何客戶端請求的狀態,每次請求都像是第一次與服務器通信。
由于 HTTP 是無狀態的,像用戶的購物車狀態就必須通過其他方式來保持,如在每次請求中傳遞用戶的 ID,或者使用 Cookie 在客戶端保存購物車狀態。
有什么辦法記錄狀態?
Cookies:服務器通過Set-Cookies響應頭將狀態信息返回給客戶端,客戶端之后的請求就使用這些Cookies來維持狀態。
Session:服務器生成一個唯一的會話ID,存儲在Cookie中,并在服務器端維護該Session的狀態信息。每次請求都發送Cookie中的Session ID以便服務器獲取該會話之前的狀態。
Token:使用 JWT(JSON Web Token)等機制在客戶端存儲狀態信息,客戶端在每次請求中發送該 Token。?
Session和Cookie的區別和聯系
區別:
- 存儲位置:Session存儲在服務器,Cookie存儲在客戶端
- 存儲數據類型:Session可以存儲任意類型,Cookies只能存儲ASCII
- 有效期:Session一般有效期較短,客戶端關閉或者Session超時都會失效;Cookies可設置為長時間保持,比如默認登陸。
- 安全性:Session存儲在服務端較安全;Cookie存儲在客戶端容易被竊取
- 存儲大小:Session可存儲的數據容量較大,Cookies保存的數據不能超過4K
聯系:
- 用戶第一次請求服務器時,服務器會創建對應的Session及對應的ID用于唯一標識會話,將Session ID返回給客戶端,客戶端會把ID保存在Cookie中,同時用Cookies記錄該ID屬于哪個域名。
- 當用戶第二次訪問服務器時,請求會自動判斷此域名下是否存在 Cookie 信息,如果存在,則自動將 Cookie 信息也發送給服務端,服務端會從 Cookie 中獲取 SessionID,再根據 SessionID 查找對應的 Session 信息,如果沒有找到,說明用戶沒有登錄或者登錄失效,如果找到 Session 證明用戶已經登錄可執行后面操作。?
分布式環境下如何處理Session?
客戶端的不同請求經過負載均衡可能被分配到不同的服務器上,可以使用Redis分布式緩存來存儲Session,在多臺服務器共享。
客戶端無法使用Cookie怎么村Session ID?
可以使用客戶端的本地存儲,比如瀏覽器的sessionStorage。
然后把Session ID放在URL的請求參數里或者請求頭里。








實操案例1)





量子計算對密碼學的影響)

(幫你生成 模塊劃分+頁面+表設計、狀態機、工作流、ER模型))


