string
- 一. string 類型介紹
- 二. string 命令
- set、get
- mget、mset
- setnx、setex、psetex
- incr、incrby、decr、decrby、incrbyfloat
- append、getrange、setrange、strlen
- 三. string 命令小結
- 四. string 內部編碼方式
- 五. string 的應用場景
- 緩存功能
- 計數功能
- 共享會話
- 手機驗證碼
- 六. 什么是業務
一. string 類型介紹
- Redis 所有的 key 都是字符串,value 的類型是存在差異的。
- 由于 Redis 內部存儲字符串完全是按照二進制流的形式保存的,所以 Redis 不是不處理字符集編碼問題的,客戶端傳入的命令中使用的是什么字符集編碼,就存儲什么字符集編碼。
- 不僅僅可以存儲文本數據,還可以存整數、普通的文本字符串、JSON、XML、二進制數據 (圖片、音頻、視頻)
- 音頻、視頻體積可能會比較大,Redis 對于 string 類型,限制了大小最大是 512 M
- Redis 是單線程模型,希望進行的操作都能比較快速,如果存儲音頻、視頻可能處理的速度慢,導致 Redis 被阻塞了。
- MySQL 5.7 及以前版本,默認的字符集是拉丁文,插入中文就會失敗。
- Redis 一般來說,遇到亂碼問題的概率更小。
二. string 命令
set、get
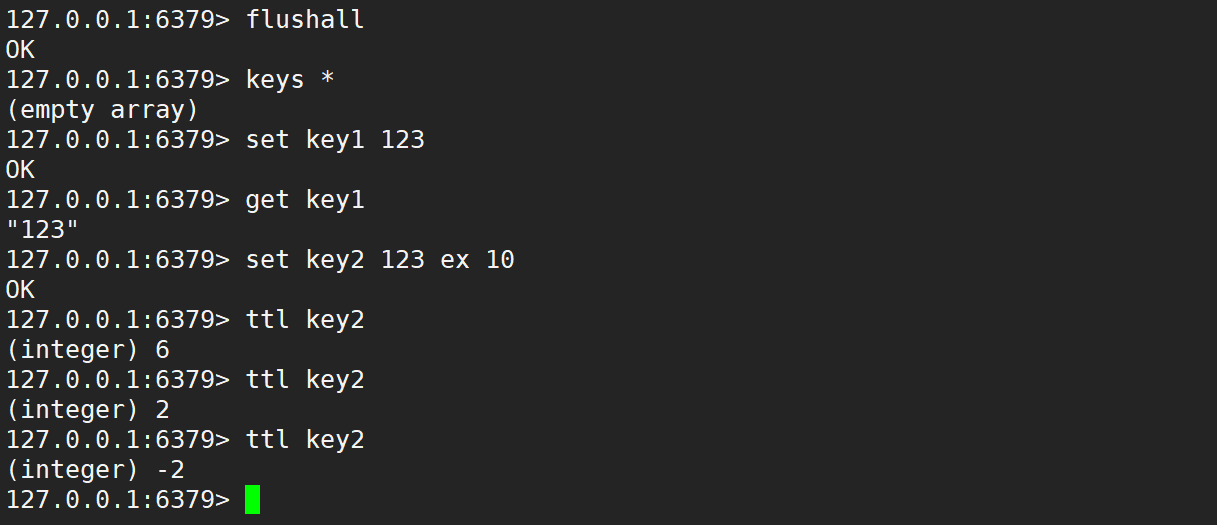
- set:將 string 類型的 value 設置到 key 中。如果 key 之前存在,則覆蓋,無論原來的數據類型是什么,之前關于此 key 的 TTL 也全部失效。
- 語法:
set key value [EX seconds|PX milliseconds|KEEPTTL] [NX|XX] - 時間復雜度:O(1)
set 命令支持多種選項來影響它的行為:
- EX seconds:使用秒作為單位設置 key 的過期時間。
- PX milliseconds:使用毫秒作為單位設置 key 的過期時間。
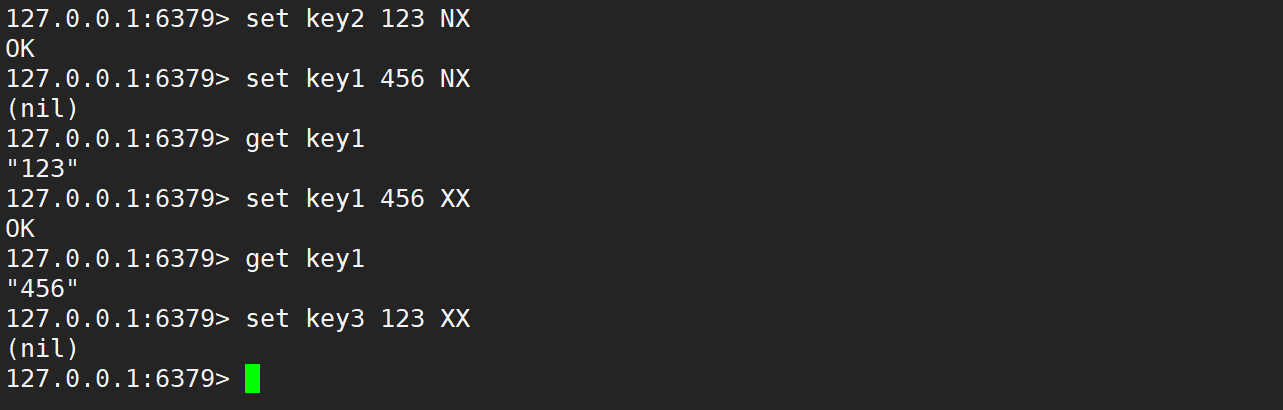
- NX:只在 key 不存在時才進行設置,即如果 key 之前已經存在,設置不執行。
- XX:只在 key 存在時才進行設置,即如果 key 之前不存在,設置不執行。
注意:
- Redis 文檔給出的語法說明格式:[] 相當于一個獨立的單元,表示可選項 (可有可無的),其中 | 表示或者的意思,多個只能出現一個,[] 和 [] 之間是可以同時存在的。
- 由于帶選項的 SET 命令可以被 SETNX、SETEX、PSETEX 等命令代替,所以之后的版本中,Redis 可能進行合并。
返回值:
- 如果設置成功,返回 OK
- 如果由于 SET 指定了 NX 或者 XX 但條件不滿足,SET 不會執行,并返回 nil
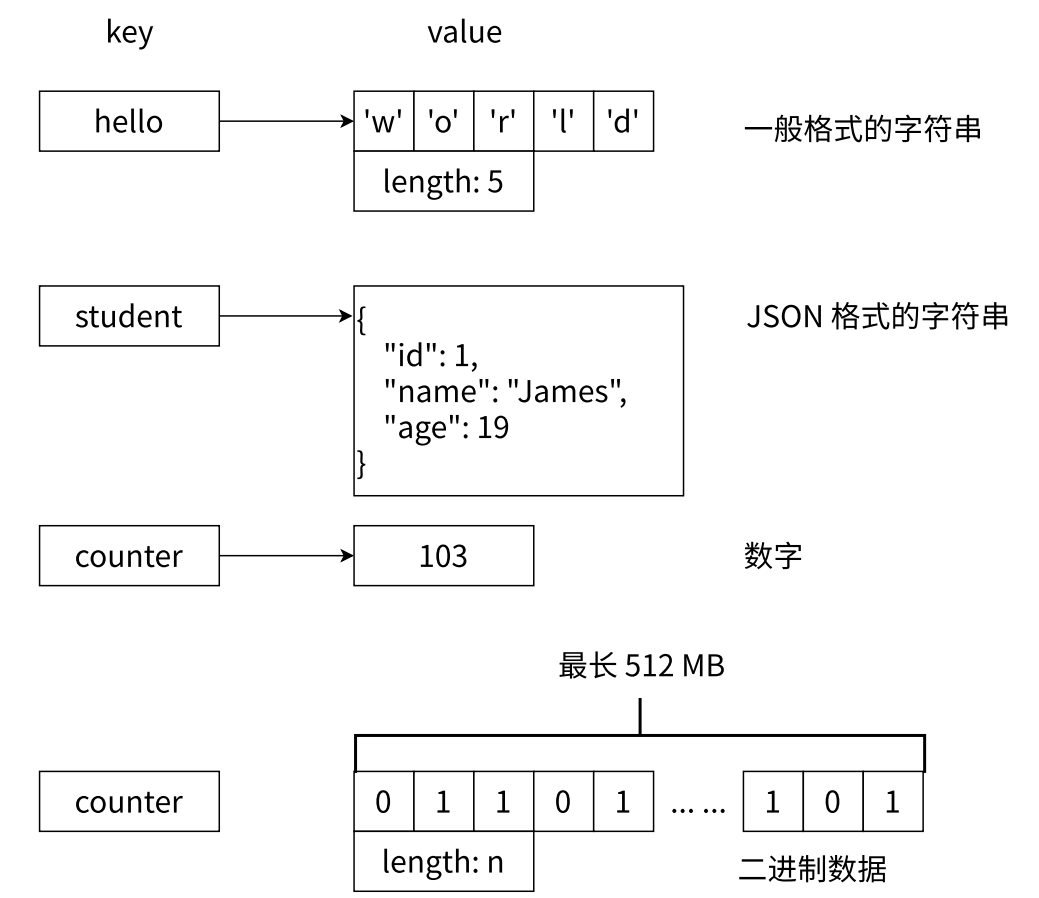
一個快速失去年終獎的小技巧:
- 清除 Redis 上所有的數據,刪庫,對于 MySQL 就是 drop database
- flushall 可以把 Redis 上的所有鍵值對都帶走。
- 以后在公司,尤其是生產環境的數據庫,千萬千萬不敢敲,當前學習階段,敲一敲倒無所謂。
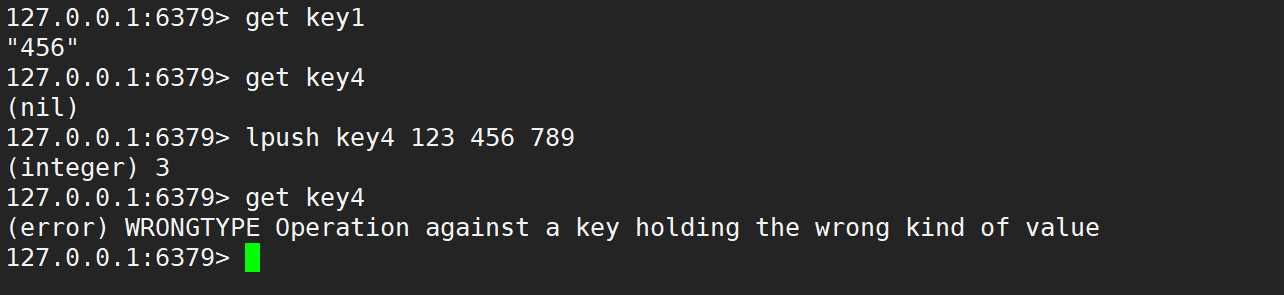
- get:獲取 key 對應的 value,如果 key 不存在,返回 nil,如果 value 的數據類型不是 string,會報錯。
- 語法:
get key - 時間復雜度:O(1)
- 返回值:當 key 存在時返回對應的 value,當 key 不存在時返回 nil
mget、mset
- mset:一次性設置多個 key 的值。
- 語法:
mset key value [key value ...] - 時間復雜度:O(N),N 是 要設置的 key 數量,一般設置不了太多,可以看作 O(1)
- 返回值:永遠是 OK
需要注意的是,如果一次性設置太多 key,例如 10w 個鍵值對,可能會導致 Redis 阻塞。

- mget:一次性獲取多個 key 的值,如果對應的 key 不存在或者對應的數據類型不是 string,返回 nil
- 語法:
get key [key ...] - 時間復雜度:O(N),N 是 要設置的 key 數量,一般設置不了太多,可以看作 O(1)
- 返回值:對應 value 的列表。

多次 get VS 單次 mget
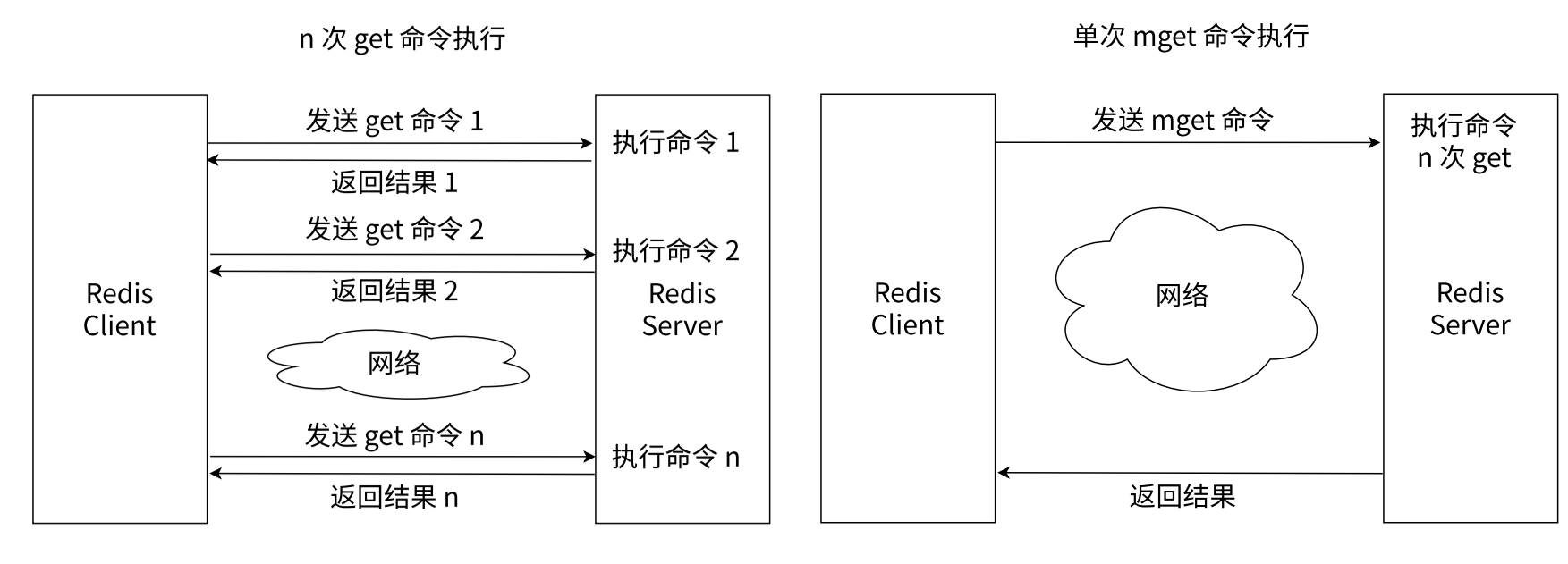
使用 mget/mset 由于可以有效地減少了網絡時間,所以性能相較更高。1000 次 get 和 1 次 mget 對比,如下表:

學會使用批量操作,可以有效提高業務處理效率,但是要注意,每次批量操作所發送的鍵的數量也不是無節制的,否則可能造成單一命令執行時間過長,導致 Redis 阻塞。
setnx、setex、psetex
- setnx:不存在才能設置,存在則設置失效。
- setex:設置 key 的過期時間,單位是秒。
- psetex:設置 key 的過期時間,單位是毫秒。
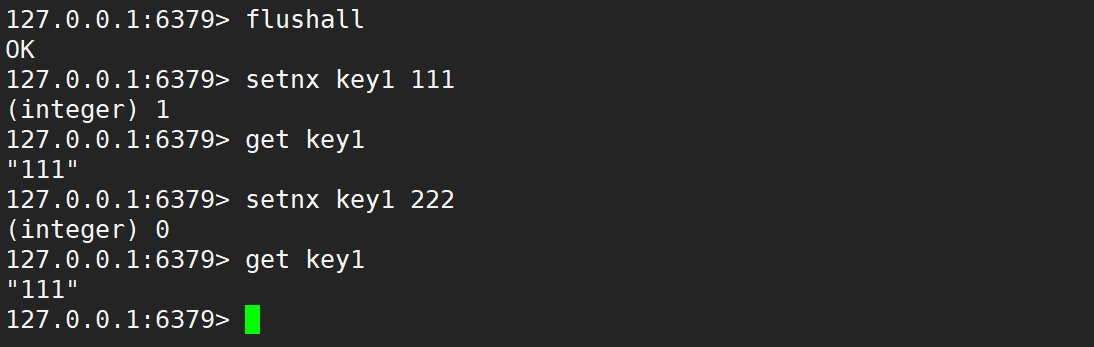
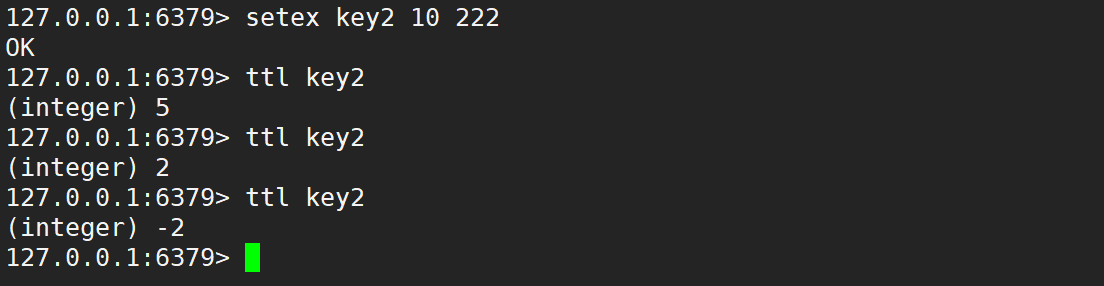
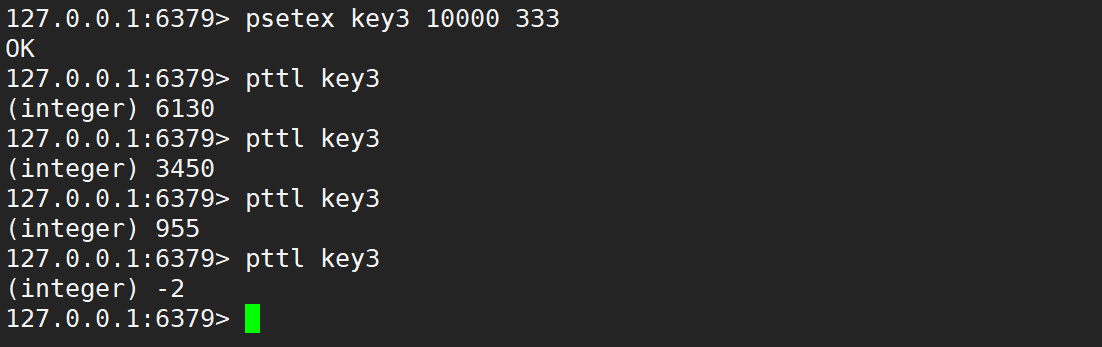
- 針對 set 一些的常用用法,進行了縮寫,之所以這樣搞,就是為了讓操作更符合人的直覺 (使用這的門檻越低,要背的東西就越少)
- 符合人的直覺,編程語言中,很多關鍵字都是和自然語言相關的。
- 后續我們去設計一些庫、工具,代碼給別人使用的時候,也盡量符合直覺,不要設計的 “反人類” / “反直覺”。
incr、incrby、decr、decrby、incrbyfloat
- incr:將 key 對應的 value 表示的數字加 1 操作,如果 key 不存在,則視為 key 對應的 value 是 0,如果 key 對應的 value 不是一個整型或者范圍超過了 64 位有符號整型 (long long),則報錯。
- 語法:
incr key - 時間復雜度:O(1)
- 返回值:value 加完后的數值。
注意:如果 incr 操作的 key 不存在,就會把這個 key 的 value 當做 0 來使用。
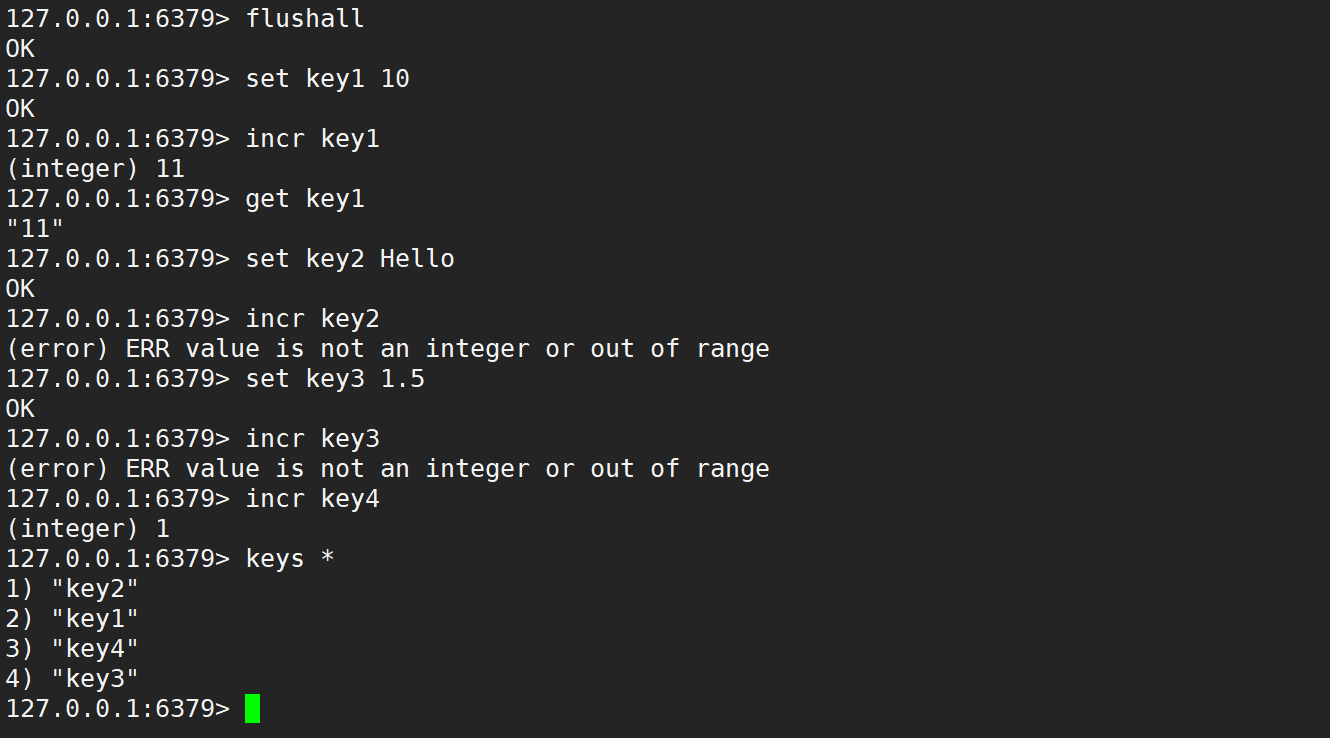
- incrby:將 key 對應的 value 表示的數字加 n 操作。
- 語法:
incrby key increment - decr:將 key 對應的 value 表示的數字減 1 操作。
- 語法:
decr key - decrby:將 key 對應的 value 表示的數字減 n 操作。
- 語法:
decrby key decrement - incrbyfloat:將 key 對應的 value 表示的數字加一個浮點數操作。
- 語法:
incrbyfloat key increment- incrbyfloat 只能用加上負數的形式,充當減法操作。
- 雖然此處沒有提供減法版本的命令,但是使用 Redis 進行的計數操作,一般都是針對整數進行操作的。
- 上述操作的時間復雜度都是 O(1),功能都是類似的。
- 由于 Redis 處理命令的時候,是單線程模型,多個客戶端同時針對同一個 key 進行 incr 操作,不會引起類似 “線程安全” 的問題。
- 很多存儲系統和編程語言內部使用 CAS 制實現計數功能,會有一定的 CPU 開銷,但在 Redis 中完全不存在這個問題,因為 Redis 是單線程架構,任何命令到了 Redis 服務端都要順序執行。
append、getrange、setrange、strlen
字符串,也支持一些常用的操作,例如:拼接、獲取、修改字符串的部分內容,獲取字符串的長度。
append
- append:如果 key 已經存在,并且對應的 value 是一個字符串,命令會將新增的字符串追加到有字符串的后邊,如果 key 不存在,則效果等同于 set 命令。
- 語法:
append key value - 時間復雜度:O(N)。追加的字符串一般長度較短,可以視為 O(1)。
- 返回值:追加完成之后的字符串的長度。
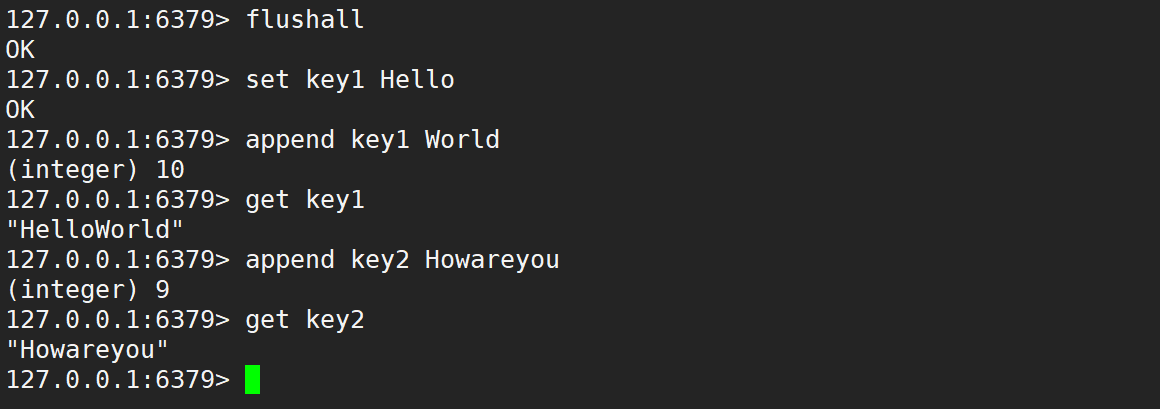

- append 的返回值,長度的單位是字節,Redis 的字符串,不會對字符編碼做任何處理 (不認字符,只認字節)
- 當前我們的 XShell 終端默認的編碼是 utf8,在終端中輸入漢字之后,也就是按照 utf8 編碼的,一個漢字在 utf8 字符集中,通常是 3 個字節。
- 拋開編碼方式,談一個漢字所占的字節數,都是扯蛋。
- 使用 get 獲取 key 對應的 value 為漢字的字符串時,獲取到的是 utf8 編碼,對應的十六進制的方式表現出來。
- 你好,這兩個漢字的 utf8 編碼是:E4BDA0E5A5BD

- 在啟動 Redis 客戶端的時候,加上一個 --raw 這樣的選項,就可以是 Redis 客戶端能夠自動把二進制數據嘗試翻譯。
- 這里退出 Redis 客戶端的方式是:Ctrl + d,或者 quit
- 操作 Linux 的時候,千萬要注意,不要亂按 Ctrl + s,否則在 XShell 中會 “凍結當前畫面”,需要 Ctrl + q,“解除凍結”。
getrange
- getrange:返回 key 對應的 value 字符串的子串,由 start 和 end 確定 (左閉右閉),可以使用負數表示倒數,-1 代表倒數第一個字符,-2 代表倒數第二個,其他的與此類似,超過范圍的偏移量會根據字符串的長度調整成正確的值。
- 語法:
getrange key start end - 時間復雜度:O(N)。N 為 [start,end] 區間的長度,由于字符串通常比較短,可以視為是 O(1)。
- 返回值:string 類型的子串。
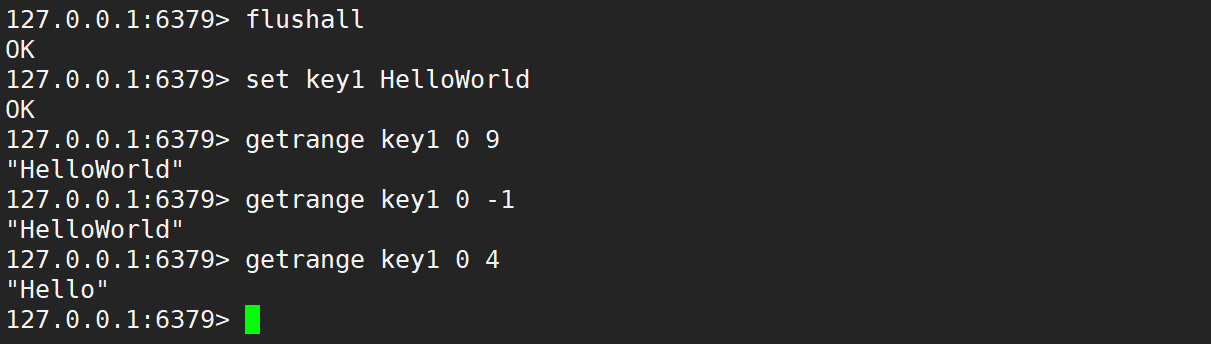
- 編程這個大圈子中,區間大多數都是 “左閉右開”,但是確實有特殊情況,例如就是 Redis
- 與 C++ 一樣的是,第一個字符的下標是 0
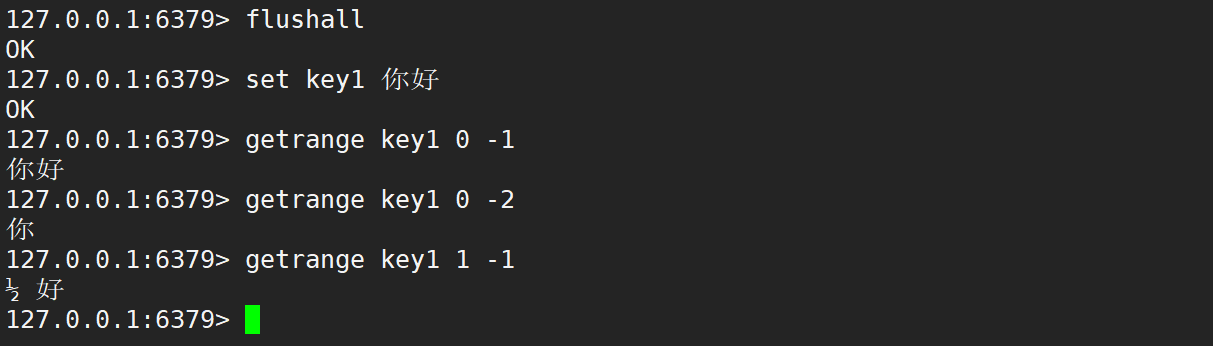
- 如果字符串中保存的是漢字,此時進行子串切分,很可能切出來的就不是完整的漢字了,切出的結果在 utf8 碼表中不知道能查出什么了。
- 上述的問題,在 C++ 中也同樣存在,因為字符串的基本單位都是字節,C++ 這里頭對于漢字的處理是沒那么完善的,就需要程序員手動處理了,在 utf8 編碼中需要按照 3 個字節處理。
- 在 Java 就沒事,因為字符串的基本單位都是字符 (占 2 個字節),Java 中的 String 幫我們把漢字的編碼轉換都處理好了。
setrange
- setrange:從指定的偏移開始,覆蓋 key 對應的 value 字符串的?部分。
- 語法:
setrange key offset value - 時間復雜度:O(N)。N 為 value 的長度,由于一般給的 value 比較短,通常視為 O(1)。
- 返回值:替換后的字符串的長度。

- 如果當前我們的 value 是一個中文字符串,那么進行 setrange 的時候,是可能會搞出問題的。
- setrange 針對不存在的 key 也是可以操作的,不過會把 offset 之前的內容填充成 0x00
- 憑空生成的一個字節,這個字節里面的內容就是 0x00,aaa 被追加到 0x00 后面了,如下:

strlen
- strlen:獲取 key 對應的 value 字符串的長度,當 key 存放的不是字符串時,報錯。
- 語法:
strlen key - 時間復雜度:O(1)
- 返回值:字符串的長度,或者當 key 不存在時,返回 0
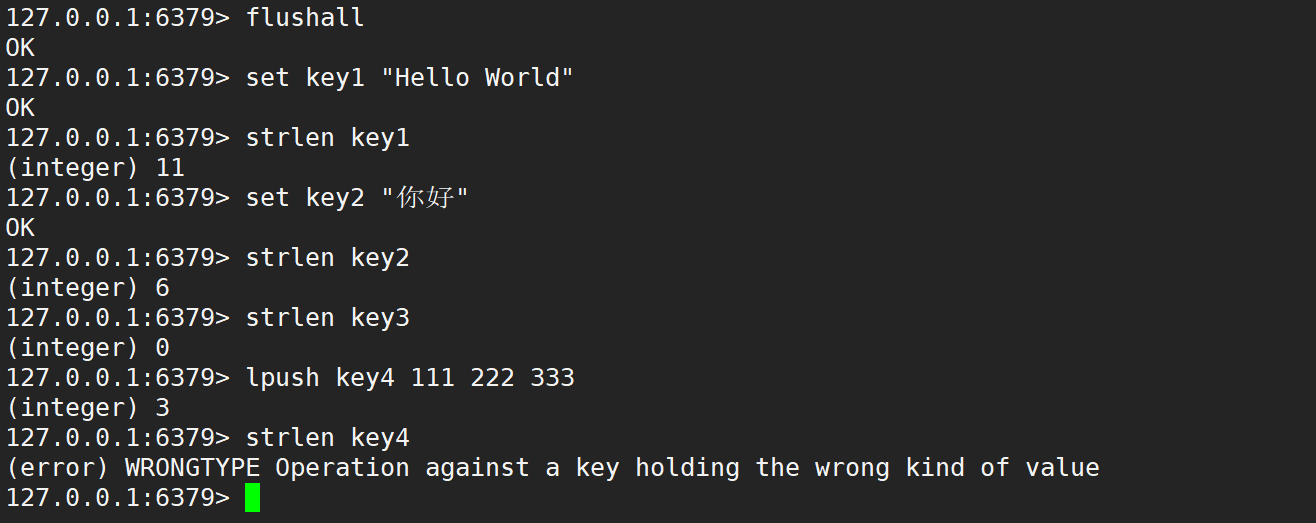
- Redis 中的 strlen 獲取字符串的長度,單位是字節。
- MySQL 中的 varchar(N) 數據類型是按照字符為單位的,MySQL 中的字符,也是完整的漢字,這樣的一個字符,有可能是多個字節。
- C++ 中,字符串長度的本身使用字節為單位的。
- Java 中,字符串長度的本身使用字符為單位的。
- Java 中的 char,使用的是 unicode 編碼,一個漢字等價于 2 個字節。
- Java 中的 String,使用的是 utf8 編碼,一個漢字等價于 3 個字節。
- Java 的標準庫內部,在進行上述的操作時,程序員一般是感知不到編碼方式的變換的。
三. string 命令小結
| 命令 | 執行效果 | 時間復雜度 |
|---|---|---|
| set key value | 設置 key 的值是 value | O(1) |
| get key | 獲取 key 的值 value | O(1) |
| del key [key …] | 刪除指定的 key | O(k),k 是鍵的個數 |
| mset key value [key value …] | 批量設置指定的 key 和 value | O(k),k 是鍵的個數 |
| mget key [key …] | 批量獲取 key 的值 | O(k),k 是鍵的個數 |
| incr key | 指定的 key 的值 + 1 | O(1) |
| decr key | 指定的 key 的值 - 1 | O(1) |
| incrby key n | 指定的 key 的值 + n | O(1) |
| decrby key n | 指定的 key 的值 - n | O(1) |
| incrbyfloat key n | 指定的 key 的值 + n | O(1) |
| append key value | 指定的 key 的值追加 value | O(1) |
| strlen key | 獲取指定 key 的值 value 的長度 | O(1) |
| getrange key start end | 獲取指定 key 的從 start 到 end 的部分字符串 | O(n),n 是字符串長度 |
| setrange key offset value | 覆蓋指定 key 的從 offset 開始的部分字符串 | O(n),n 是字符串長度 |
- 字符串類型命令的效果、時間復雜度,開發人員可以參考此表,結合自身業務需求和數據大小選擇合適的命令。
- 上面的 getrange 和 setrange,由于字符串一般都比較短,通常視為 O(1)。
四. string 內部編碼方式
string 內部有 3 中編碼方式:
- int:64 比特位 / 8個字節,的長整型。
- embstr:壓縮字符串,適用于表示,小于等于 39 個字節的字符串。
- raw:普通字符串,適用于表示,大于 39 個字節的字符串,只是單純的持有字節數組。
Redis 會根據當前值的類型和長度動態決定使用哪種內部編碼實現,可以通過 object encoding key 來查看具體的編碼方式。
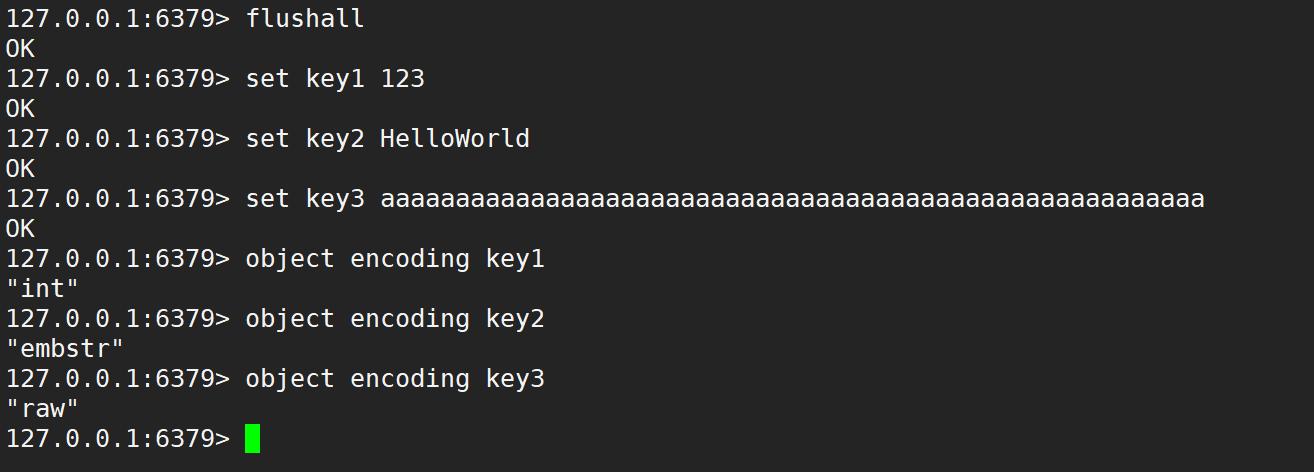
- 不建議大家去記,長度大于 39 這樣的數字,若某個業務場景,有很多很多的 key,類型都是 string,但是每個 value 的 string 長度都是 100 左右。
- 更關注與整體的內存空間,因此,這樣的字符串使用 embstr 來存儲也不是不能考慮,上述的效果,具體怎么實現呢?
- 先看 Redis 是否提供了對應的配置項,可以修改 39 這個數字。
- 如果沒有提供這樣的配置項,就需要針對 Redis 源碼進行魔改。
- 為什么很多大廠,往往是自己造輪子,而不是直接使用業界成熟的呢,例如:消息隊列,RPC 通信框架。
- 開源的組件,往往考慮的是通用性。
- 但是大廠往往會遇到一些極端業務場景,往往就需要根據當前的極端業務,針對上述開源組件進行定制化。
- 往上也經常有種說法,大廠造輪子,一般是為了 KPI
- 更關注與整體的內存空間,因此,這樣的字符串使用 embstr 來存儲也不是不能考慮,上述的效果,具體怎么實現呢?

- Redis 存儲小數,本質上還是當成字符串來存儲,這就和整數相比差別很大了,整數直接使用 long long 來存儲,比較方便進行算術運算的。
- 小數則是使用字符串來存儲,意味著每次進行算術運算,都需要把字符串轉換成小數,進行運算,結果在轉換成字符串進行保存。
五. string 的應用場景
緩存功能
比較典型的緩存使用場景,其中 Redis 作為緩沖層,MySQL 作為存儲層,絕大部分請求的數據都是從 Redis 中獲取,由于 Redis 具有支撐高并發的特性,所以緩存通常能起到加速讀寫和降低后端壓力的作用。
Redis + MySQL 組成的緩存存儲架構,圖如下:
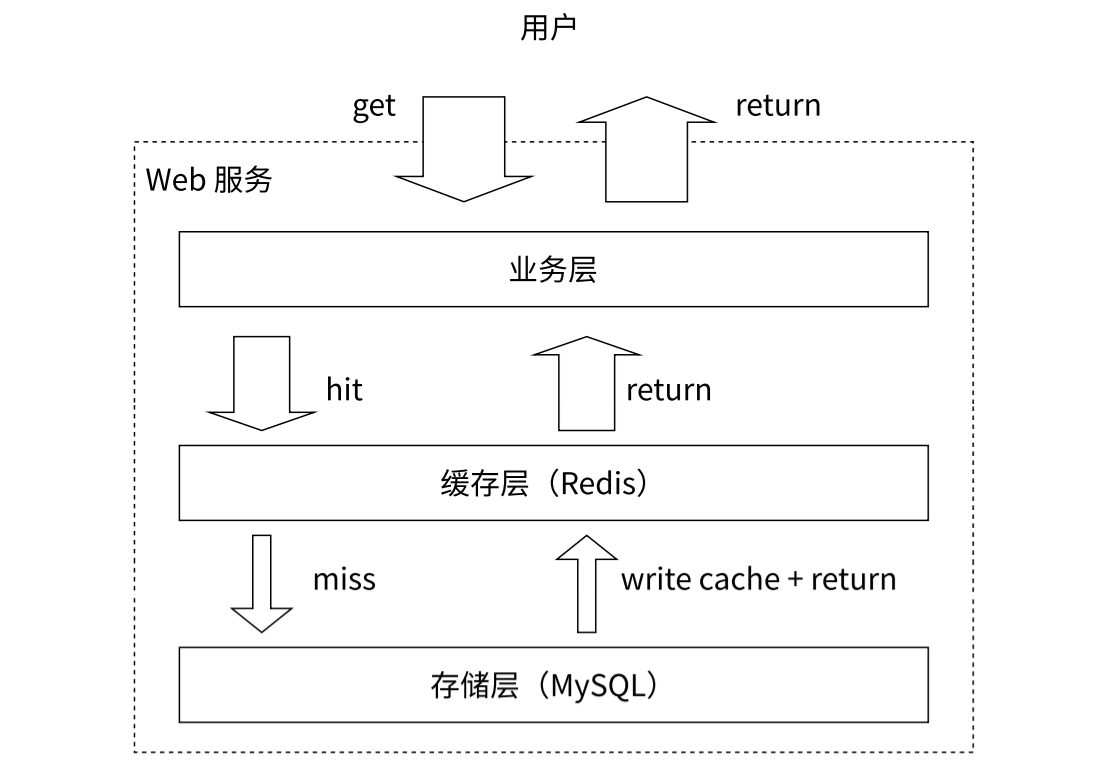
整體的思路:
- 應用服務器訪問數據的時候,先查詢 Redis。
- 如果 Redis 上的數據存在了,就直接從 Redis 上取數據交給應用服務器,不繼續訪問數據庫了。
- 如果 Redis 上的數據不存在,再讀取 MySQL 數據庫,把讀到的數據結果,返回給應用服務器,同時,把這個數據也寫入 Redis 中。
- Redis 這樣的緩存,經常用來存儲 “熱點數據”,高頻被使用的數據,這個定義方式,結合業務場景有很多種方式。
- 剛才上述描述的過程中,相當于是把最近使用到的數據作為熱點數據 (暗含了一種解設,某個數據一但被使用了,那么很可能在最近這段時間就會被反復使用到)
上述策略,存在一個明顯的問題,隨著時間的推移,肯定會有越來越多的 key 再 Redis 上訪問不到,從而從 MySQL 讀取并寫入 Redis 了,此時 Redis 中的數據不是就越來越多了嘛?
- 在把數據寫給 Redis 的同時,給這個 key 設置一個過期時間。
- Redis 在內存不足的時候,提供了 “淘汰策略”,后面再細說。
下面的偽代碼模擬了,業務數據訪問過程:
- 假設業務是根據用戶 uid 獲取用戶信息:
UserInfo getUserInfo(long uid) {// ...
}
- 首先從 Redis 獲取用戶信息,我們假設用戶信息保存在
user:info:<uid>對應的鍵中:
// 根據 uid 得到 Redis 的鍵
String key = "user:info:" + uid;// 嘗試從 Redis 中獲取對應的值
String value = Redis 執?命令: get key;// 如果緩存命中(hit)
if (value != null) {// 假設我們的??信息按照 JSON 格式存儲UserInfo userInfo = JSON 反序列化(value);return userInfo;
}
- 如果沒有從 Redis 中得到用戶信息,及緩存 miss,則進一步從 MySQL 中獲取對應的信息,隨后寫入緩存并返回:
// 如果緩存未命中(miss)
if (value == null) {// 從數據庫中,根據 uid 獲取用戶信息UserInfo userInfo = MySQL 執? SQL: select * from user_info where uid = <uid>// 如果表中沒有 uid 對應的用戶信息if (userInfo == null) {響應 404return null;}// 將用戶信息序列化成 JSON 格式String value = JSON 序列化(userInfo);// 寫入緩存,為了防止數據腐爛(rot),設置過期時間為1小時(也就是3600秒)Redis 執?命令: set key value ex 3600// 返回用戶信息return userInfo;
}
通過增加緩存功能,在理想情況下,每個用戶信息,一個小時期間只會有一次 MySQL 查詢,極大地提升了查詢效率,也降低了 MySQL 的訪問數。

計數功能
許多應用都會使用 Redis 作為計數的基礎工具,它可以實現快速計數、查詢緩存的功能,同時數據可以異步處理或者落地到其他數據源。例如:視頻網站的視頻播放次數可以使用 Redis 來完成:用戶每播放一次視頻,相應的視頻播放數就會自增 1
記錄視頻播放次數,圖如下:
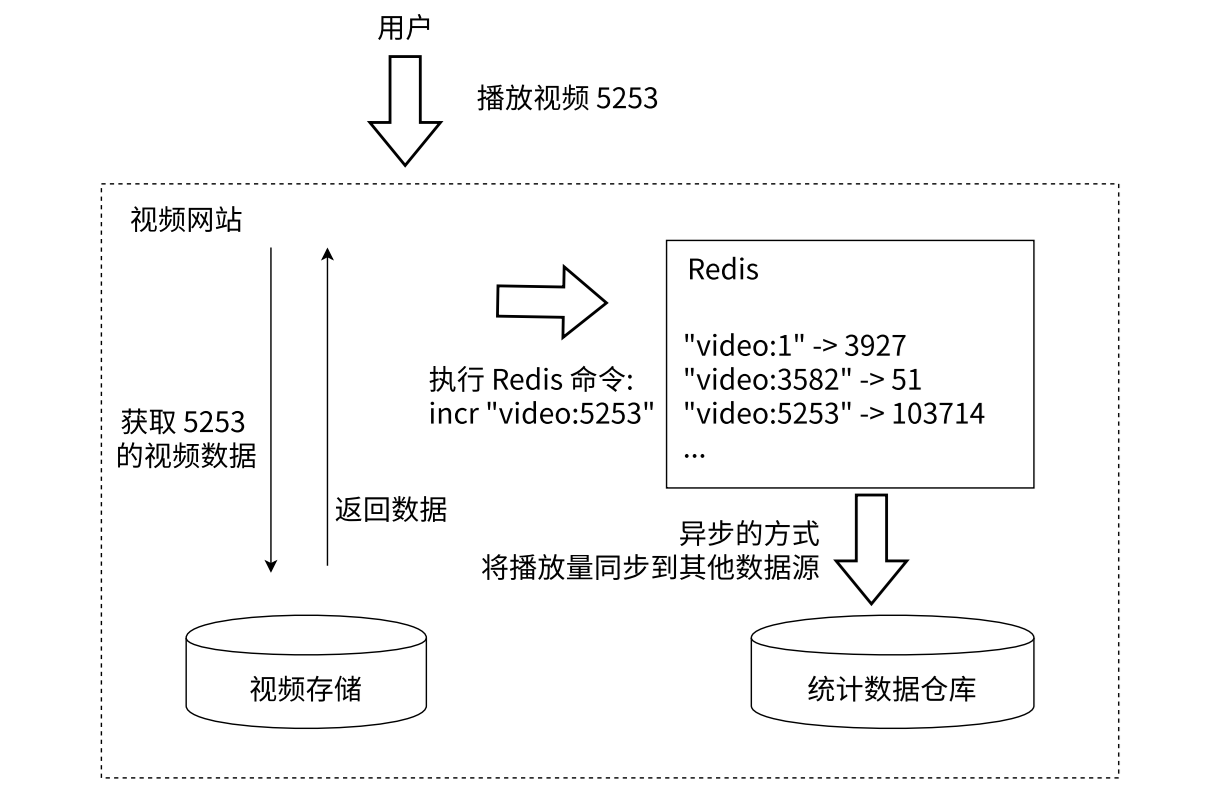
企業為什么老是樂意用戶的數據?
- 統計,為了進一步明確用戶的需求,根據需求來改進和迭代產品。
- Redis 并不擅長數據統計,例如:想統計播放量前 100 的視頻有哪些,基于 Redis 搞就很麻煩。
- 相比之下,如果是 MySQL 用來存儲上述的數據,一個 SQL 語句就能搞定。
- 這里寫入統計數據倉庫 (MySQL/HDFS) 的步驟,是異步的:
- 不是說來一個播放請求,就必須立即寫入一個數據,如果是這樣就會消耗更多的硬件資源,效率低。
- 寫入數據的速度可以慢一些,只需要保證最終將數據寫入即可,例如,每隔一段時間,該時間之內,播放了多少次,將最終的數據寫入。
// 在 Redis 中統計某視頻的播放次數
long incrVideoCounter(long vid) {key = "video:" + vid;long count = Redis 執?命令: incr keyreturn counter;
}

共享會話
Cookie:瀏覽器存儲數據的機制。
Session:服務器存儲數據的機制。
Session 分散存儲,圖如下:
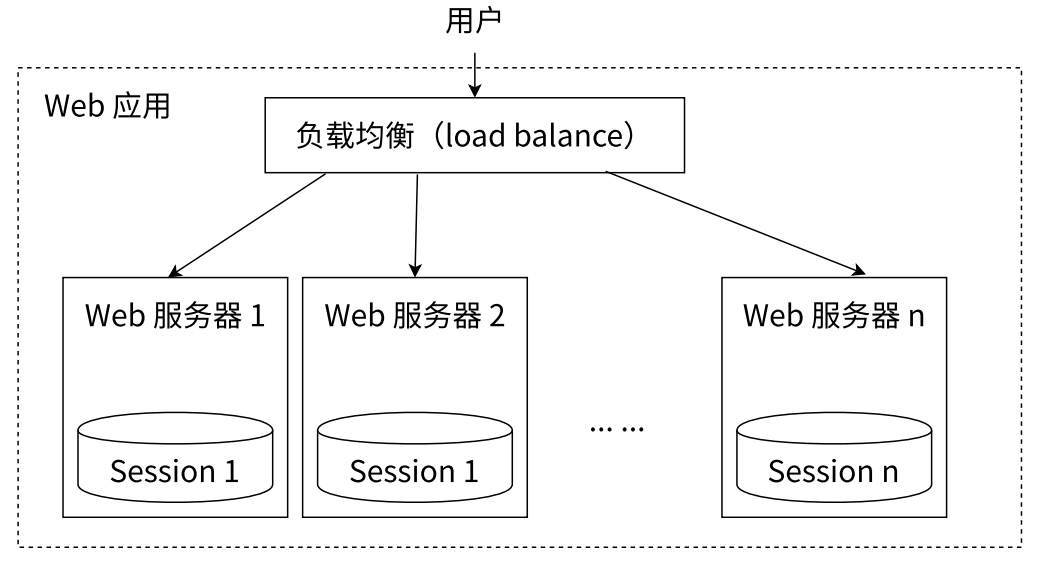
一個分布式 Web 服務將用戶的 Session 信息 (例如用戶登錄信息) 保存在各自的服務器中,但這樣會造成一個問題:出于負載均衡的考慮,分布式服務會將用戶的訪問請求均衡到不同的服務器上,并且通常無法保證用戶每次請求都會被均衡到同一臺服務器上,這樣當用戶刷新一次訪問是可能會發現需要重新登錄,這個問題是用戶無法容忍的。
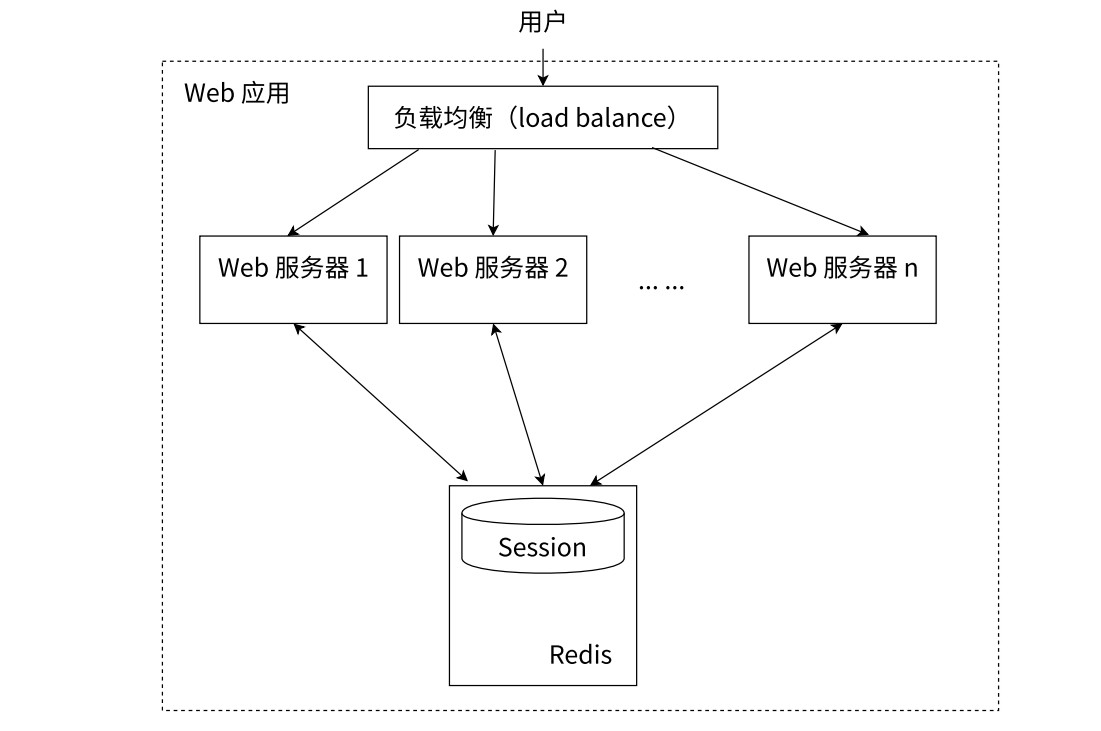
為了解決這個問題,可以使用 Redis 將用戶的 Session 信息進行集中管理,只要保證 Redis 是高可用和可擴展性的,無論用戶被均衡到哪臺 Web 服務器上,都集中從 Redis 中查詢、更新 Session 信息。如下圖:
手機驗證碼
很多應用出于安全考慮,會在每次進行登錄時,讓用戶輸入手機號并且配合給?機發送驗證碼,然后讓用戶再次輸入收到的驗證碼并進行驗證,從而確定是否是用戶本人。為了短信接口不會頻繁訪問,會限制用戶每分鐘獲取驗證碼的頻率,例如一分鐘不能超過 5 次,如下圖:

- 生成驗證碼。
- 用戶輸入一個手機號。
- 點擊獲取驗證碼,限制一分鐘之內,最多獲取 5 次驗證碼,或者獲取驗證碼必須間隔 30 秒,主要還是怕用戶頻繁獲取驗證碼,對于我們的服務器壓力過大。
- 檢查驗證碼。
- 把短信收到的驗證碼這一串數,提交到系統中。
- 系統進行判斷驗證碼是否正確。
- 像發送短信這樣的操作,都是有專門的 SDK 來實現的,也就是第三方提供的短信平臺。
此功能可以用以下偽代碼說明基本實現思路:
String 發送驗證碼(phoneNumber) {key = "shortMsg:limit:" + phoneNumber;// 設置過期時間為1分鐘(60秒)// 使? NX, 只在不存在 key 時才能設置成功bool r = Redis 執?命令: set key 1 ex 60 nxif (r == false) {// 說明之前設置過該手機的驗證碼了long c = Redis 執?命令: incr keyif (c > 5) {// 說明超過了一分鐘5次的限制了// 限制發送return null;}}// 說明要么之前沒有設置過手機的驗證碼, 要么次數沒有超過5次String validationCode = ?成隨機的6位數的驗證碼();validationKey = "validation:" + phoneNumber;// 驗證碼5分鐘(300秒)內有效Redis 執?命令: set validationKey validationCode ex 300;// 返回驗證碼,隨后通過手機短信發送給用戶return validationCode ;
}// 驗證用戶輸入的驗證碼是否正確
bool 驗證驗證碼(phoneNumber, validationCode) {validationKey = "validation:" + phoneNumber;String value = Redis 執?命令: get validationKey;if (value == null) {// 說明沒有這個手機的驗證碼記錄,驗證失敗return false;}if (value == validationCode) {return true;} else {return false;}
}
以上介紹了使用 Redis 的字符串數據類型可以使用的幾個場景,但其適用場景遠不止于此,開發人員可以結合字符串類型的特點以及提供的命令,充分發揮自己的想象力,在自己的業務中去找到合適的場景去使用 Redis 的字符串類型。
六. 什么是業務
- 業務:其實就是一個公司/一個產品,是任何解決一個/一系列問題的。
- 解決問題的過程,就可以稱為業務。
- 一個公司/產品想要生存,就得賺錢,就得幫助別人解決問題。
- 不同的公司,不同的產品,不同的業務,就需要不同的技術作為支撐。
- 業務是非常重要的,很多時候,優化技術解決不了的問題,可以通過優化業務來解決。
例如:培訓公司的業務
- 直播課程、錄播課程、日常跟進/作業批改、筆試強訓、項目翻轉、模擬面試。
- 校招跟進、offer 篩選、學長內推、租房信息分享。
- 解決的問題:都是為了學員更好的就業,獲取更好的 offer
例如:12306 買火車票。
- 這個網站背后技術的積累,可以說是全國甚至全世界,獨一檔的。
- 由于春運,這個網站支撐的業務是極其恐怖的,搶火車票,擁有超高的并發量。
- 雖然當時引入了非常多的技術,提高網站的訪問速度和可用性,但是在放票的時候,整體的壓力還是很大的,還是很容易出現問題的。
- 假設我要提前一周搶火車票,我就需要在當天 8:00 的時候準時登入 12306 測試買票。
- 在這個放票的一瞬間,因為搶票的人太多了,就會導致服務器的壓力一個就拉滿了。
- 通過一些常規技術手段,優化的效果并不明顯,于是有人提出方案:業務優化->分時段放票。
- 本來是 1 次放所有的票,現在是分 5 次放票,這樣就相當于把服務器的壓力降低到原來的五分之一了。
- 全國那么多車次,分 100 次放票,也很容易能做到。
實際開發過程中,必須要結合實際業務場景,做一些技術上的調整,不同的公司,不同的產品,都會有不同的業務,進入公司之后業務是學習的重點。














)




