前言
深度學習并非總是解決問題的最佳方案:缺乏足夠數據時,深度學習難以施展;某些情況下,其他機器學習算法可能更為高效。
若初學者首次接觸的是深度學習,可能會形成一種偏見,視所有機器學習問題為深度學習可解決的“釘子”,而手中僅有深度學習這把“錘子”。要避免這種思維局限,關鍵在于廣泛了解并掌握其他機器學習方法,并在實際中適時應用。回顧機器學習方法的歷史背景,有助于理解深度學習的起源與重要性。
一、概率建模(樸素貝葉斯和邏輯回歸)
概率建模(probabilistic modeling)是什么?機器學習中的概率建模是利用概率理論對數據進行建模和分析,以揭示數據內在規律和進行預測的方法。
概率建模主要依賴于隨機變量的概率分布模型,這些模型描述了隨機變量可能取值的概率。在建立這些模型時,通常需要考慮數據的統計規律,并通過樣本分析來確定概率分布的具體形式。
“一圖 + 一句話”徹底搞懂概率建模。
“機器學習中,樸素貝葉斯和logistic回歸作為概率模型,通過計算概率進行分類。其中樸素貝葉斯分類器基于貝葉斯定理,通過計算給定觀測值屬于某個類別的概率來進行分類。邏輯回歸通過建立邏輯回歸模型,將線性回歸的結果映射到(0,1)的區間上,從而得到屬于某個類別的概率。”

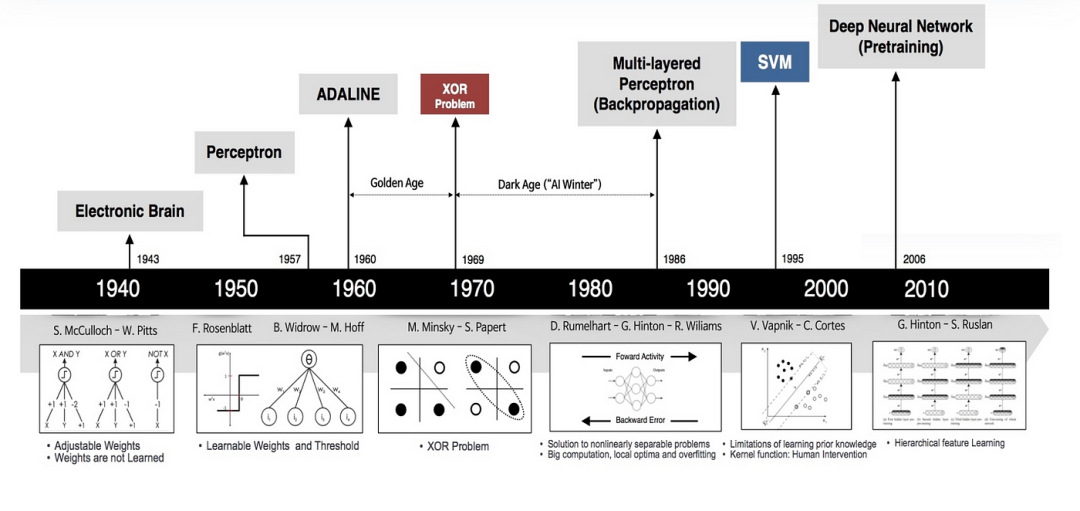
二、核方法(SVM)
核方法(kernel method)是什么?核方法是一類將非線性數據映射到高維空間以使其線性可分,并通過核函數簡化計算復雜度的模式識別算法。
核方法的核心在于無需直接計算數據點在高維空間中的坐標,而是通過核函數直接計算這些點在新空間中的距離或內積,從而簡化計算并避免高維空間的直接表示。
核函數是預先選擇的,用于將原始空間中的點映射到目標空間,而分類決策面(如SVM中的超平面)則是通過學習過程得到的。
“一圖 + 一句話”徹底搞懂核方法。
“SVM(支持向量機)是一種基于核方法的分類算法,它通過將數據映射到高維空間并利用核函數計算點之間的距離或內積,從而找到最大化間隔的決策邊界(超平面),實現對數據的分類。”
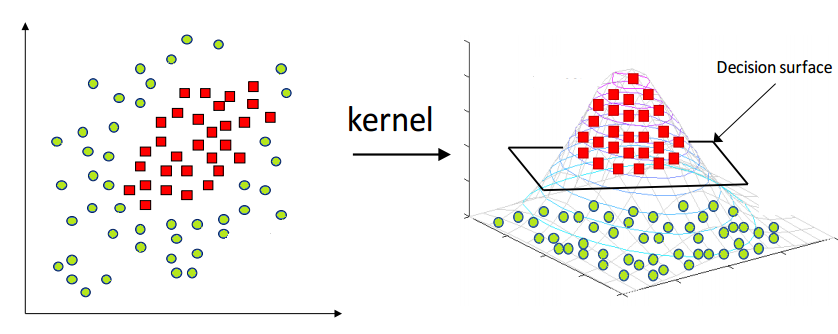
三、決策樹(隨機森林和梯度提升機)
決策樹(Decision Tree)是什么?決策樹(Decision Tree)是一種通過樹形結構模擬人類決策邏輯,由決策節點、方案節點、狀態節點、樹葉節點及連接它們的樹枝(包括方案枝和概率枝)構成,用于表示決策過程并得出最終決策結果或分類類別的模型。
隨機森林(Random Forest)和梯度提升(Gradient Boosting)都是基于決策樹的集成學習方法,但它們通過不同的策略來結合多個決策樹的輸出以提高預測性能。
“一圖 + 一句話”徹底搞懂隨機森林和梯度提升。
“隨機森林(Random Forest)是一種集成學習方法,通過構建多個決策樹并集成其輸出來提高模型的穩健性和準確性;梯度提升(Gradient Boosting)則通過迭代訓練新模型專門彌補隨機森林中原有模型的不足,從而在預測性能上實現優化。。”
?資料分享
為了方便大家學習,我整理了一份100G人工智能學習資料
包含數學與Python編程基礎、深度學習+機器學習入門到實戰,計算機視覺+自然語言處理+大模型資料合集,不僅有配套教程講義還有對應源碼數據集,更有零基礎入門學習路線,不論你處于什么階段,這份資料都能幫助你更好地入門到進階。
需要的兄弟可以按照這個圖的方式免費獲取









)



需二刷--Java版)





