DeepSpeed是由微軟開發的開源深度學習優化框架,專注于大規模模型的高效訓練與推理。其核心目標是通過系統級優化技術降低顯存占用、提升計算效率,并支持千億級參數的模型訓練。
官網鏈接:deepspeed
訓練代碼下載:git代碼
一、DeepSpeed的核心作用
-
顯存優化與高效內存管理
-
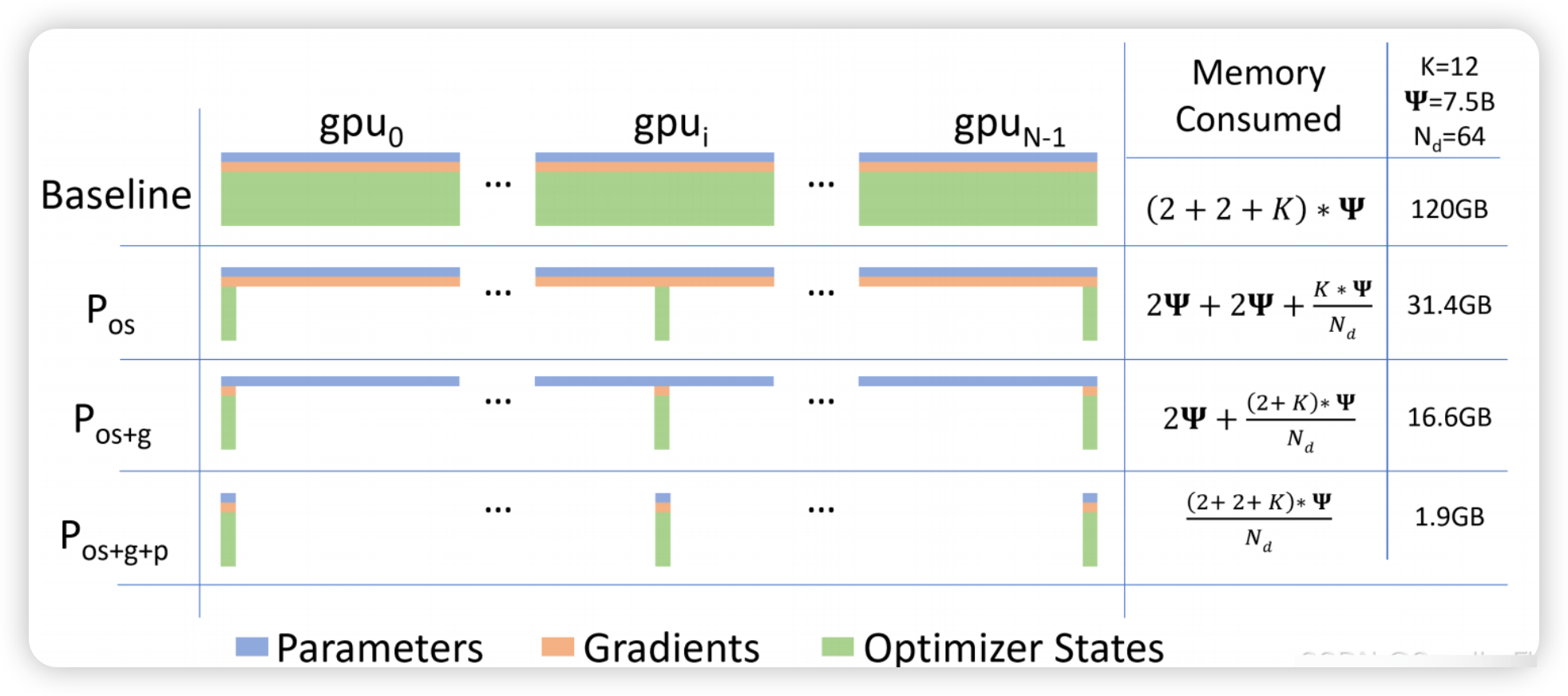
ZeRO(Zero Redundancy Optimizer)技術:通過分片存儲模型狀態(參數、梯度、優化器狀態)至不同GPU或CPU,顯著減少單卡顯存占用。例如,ZeRO-2可將顯存占用降低8倍,支持單卡訓練130億參數模型。
-
Offload技術:將優化器狀態卸載到CPU或NVMe硬盤,擴展至TB級內存,支持萬億參數模型訓練。
-
激活值重計算(Activation Checkpointing):犧牲計算時間換取顯存節省,適用于長序列輸入。
-
-
靈活的并行策略
-
3D并行:融合數據并行(DP)、模型并行(張量并行TP、流水線并行PP),支持跨節點與節點內并行組合,適應不同硬件架構。
-
動態批處理與梯度累積:減少通信頻率,支持超大Batch Size訓練。
-
-
訓練加速與混合精度支持
-
混合精度訓練:支持FP16/BF16,結合動態損失縮放平衡效率與數值穩定性。
-
稀疏注意力機制:針對長序列任務優化,執行效率提升6倍。
-
通信優化:支持MPI、NCCL等協議,降低分布式訓練通信開銷。
-
-
推理優化與模型壓縮
-
低精度推理:通過INT8/FP16量化減少模型體積,提升推理速度。
-
模型剪枝與蒸餾:壓縮模型參數,降低部署成本。
-
二、與pytorch 對比分析
1. 優勢
-
顯存效率:相比PyTorch DDP,單卡80GB GPU可訓練130億參數模型(傳統方法僅支持約10億)。
-
并行靈活性:支持3D并行組合,優于Horovod(側重數據并行)和Megatron(側重模型并行)。
-
生態集成:與Hugging Face Transformers、PyTorch無縫兼容,簡化現有項目遷移。
-
全流程覆蓋:同時優化訓練與推理,而vLLM僅專注推理優化。
2. 局限性
-
配置復雜度:分布式訓練需手動調整通信策略和分片參數,學習曲線陡峭(需編寫JSON配置文件)。
-
硬件依賴:部分高級功能(如ZeRO-Infinity)依賴NVMe硬盤或特定GPU架構。
-
推理效率:純推理場景下,vLLM的吞吐量更高(連續批處理優化更專精)。
三、訓練用例
1、ds_config.json(deepspeed執行訓練時,使用的配置文件)
- deepspeed訓練模型時,不需要在代碼中定義優化器,只需要在 json 文件中進行配置即可, json文件內容如下:
{"train_batch_size": 128, //所有GPU上的 單個訓練批次大小 之和"gradient_accumulation_steps": 1, //梯度累積 步數"optimizer": {"type": "Adam", //選擇的 優化器"params": {"lr": 0.00015 //相關學習率大小}},"zero_optimization": { //加速策略"stage":2}
}2、訓練函數
- 將模型包裝成 deepspeed 形式
#將模型 包裝成 deepspeed 形式
model_engine, _, _, _ = deepspeed.initialize(args=args,model=model,model_parameters=model.parameters())
- 使用 deepspeed 包裝后的模型 進行 反向傳播和梯度更新
#使用 deepspeed 進行 反向傳播和梯度更新
#反向傳播
model_engine.backward(loss)#梯度更新
model_engine.step()
- 完整訓練代碼如下:
'''
使用命令行進行啟動啟動命令如下:
deepspeed ds_train.py --epochs 10 --deepspeed --deepspeed_config ds_config.json
'''import argparse
import torch
import torchvision
import deepspeed
from model_definition import load_data, CustomModelif __name__ == '__main__':#讀取命令行 傳遞的參數parser = argparse.ArgumentParser()parser.add_argument("--local_rank", help = "local device id on current node", type = int, default=0)parser.add_argument("--epochs", type = int, default=1)parser = deepspeed.add_config_arguments(parser)args = parser.parse_args()#獲取數據集train_loader, test_loader = load_data() #數據集加載器中的 batch_size的大小 = (ds_config.json中 train_batch_size/gpu數量)#獲取原始模型model = CustomModel().cuda()#將模型 包裝成 deepspeed 形式model_engine, _, _, _ = deepspeed.initialize(args=args,model=model,model_parameters=model.parameters())loss_fn = torch.nn.CrossEntropyLoss().cuda() # 損失函數(分類任務常用)for i in range(args.epochs):for inputs, labels in train_loader:#前向傳播inputs = inputs.cuda()labels = labels.cuda()outputs = model_engine(inputs)loss = loss_fn(outputs, labels)#使用 deepspeed 進行 反向傳播和梯度更新#反向傳播model_engine.backward(loss)#梯度更新model_engine.step()model_engine.save_checkpoint('./ds_models', i)#模型保存torch.save(model_engine.module.state_dict(),'deepspeed_train_model.pth')3、模型評估
import argparse
import torch
import torchvision
import deepspeed
from model_definition import load_data, CustomModel
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import numpy as np
import matplotlib.pyplot as plt# 1. 定義數據轉換(預處理)
transform = transforms.Compose([transforms.ToTensor(), # 轉為Tensor格式(自動歸一化到0-1)transforms.Normalize((0.1307,), (0.3081,)) # 標準化(MNIST的均值和標準差)
])test_data = datasets.MNIST(root='./data',train=False, # 測試集transform=transform)#獲取數據集
train_loader, test_loader = load_data()model = CustomModel()
model.load_state_dict(torch.load('deepspeed_train_model.pth'))#評估
model.eval() # 設置為評估模式
correct = 0
total = 0with torch.no_grad(): # 不計算梯度(節省內存)for images, labels in test_loader:images, labels = images, labelsoutputs = model(images)_, predicted = torch.max(outputs.data, 1) # 取概率最大的類別total += labels.size(0)correct += (predicted == labels).sum().item()print(f"測試集準確率: {100 * correct / total:.2f}%")# 隨機選擇一張測試圖片
index = np.random.randint(0,1000) # 可以修改這個數字試不同圖片
test_image, true_label = test_data[index]
test_image = test_image.unsqueeze(0) # 增加批次維度# 預測
with torch.no_grad():output = model(test_image)
predicted_label = torch.argmax(output).item()print(f"預測: {predicted_label}, 真實: {true_label}")# 顯示結果
plt.imshow(test_image.cpu().squeeze(), cmap='gray')
plt.title(f"預測: {predicted_label}, 真實: {true_label}")
plt.show()

兼顧可行性和動力學約束)




)








統計數據,以及過濾同時為0的數據)



Anaconda詳細安裝教程Anaconda3 最新版安裝教程)