前言
自從去年24年Q4,我司「七月在線」側重具身智能的場景落地與定制開發之后
- 去年Q4,每個月都會進來新的具身需求
- 今年Q1,則每周都會進來新的具身需求
- Q2的本月起,一周不止一個需求
特別是本周,幾乎每天都有國企、央企、民企通過我司找到我們,比如鋼筋綁扎等等各行各業
而之所以這么受歡迎,個人認為其中一個原因在于
我司不但給客戶解決實際業務場景的應用落地、定制開發
還幫助客戶成長 給他們技術、經驗、代碼,從而讓其從零起步,獲得中國具身入場券
使得我們,包括我自己沒有一刻停得下來,比如我個人的工作之一就是針對各種項目的各個場景尋找最優的解決方案
比如不在只是單純的上半身操作,或者下肢行走,而遇到了越來越多的loco-manipulation問題——既涉及運動控制 也涉及操作,最簡單的比如搬運箱子,以及從地面拾取物品
如此,不可避免的會關注CMU、UC San Diego、斯坦福等高校的各個團隊的最新前沿進展
UCSD的Xiaolong Wang團隊發布了最新的這個AMO工作《AMO: Adaptive Motion Optimization for Hyper-Dexterous Humanoid Whole-Body Control》——25年5.6日提交到的arXiv,個人覺得很有新意,故本文來解讀下,且還會順帶解讀另一個有些相似的動作:來自CMU的FALCON
第一部分
1.1 引言與相關工作
1.1.1 引言
如AMO論文所述,由于動態人形全身控制具有高維度、高度非線性以及豐富接觸的特性。傳統的基于模型的最優控制方法需要對機器人及環境進行精確建模,具備高計算能力,并且需要采用reduced-order模型以獲得可實現的計算結果,這對于在現實世界中利用過度驅動人形機器人全部自由度(29)的問題來說是不可行的
近年來,強化學習(RL)與仿真到現實(sim-to-real)技術的結合在實現現實世界中的人形機器人行走-操作(loco-manipulation)任務方面展現出巨大潛力 [42-Mobile-television]
盡管這些方法實現了高自由度(DoF)人形機器人的強健實時控制,但通常依賴于大量人類專業知識和獎勵函數的手動調整,以確保穩定性和性能
- 為了解決這一限制,研究人員將動作模仿框架與強化學習結合,利用重定向的人體動作捕捉(MoCap)軌跡來定義獎勵目標,引導策略學習 [10-Exbody,28-Omnih2o]
然而,這類軌跡通常在運動學上可行,卻未能考慮目標人形平臺的動態約束,從而在仿真動作與硬件可執行行為之間引入了體現差距(embodiment gap)
- 另一種方法則將軌跡優化(TO)與強化學習結合,以彌合這一差距
38-Reinforcement learning for robust parameterized locomotion control of bipedal robots
41-Opt2skill: Imitating dynamicallyfeasible whole-body trajectories for versatile humanoid
loco-manipulation
盡管上述這些方法推動了人形機器人行走-操作能力,當前的方法仍然局限于簡化的運動模式,而未能實現真正的全身靈巧性,原因在于
- 基于動作捕捉的方法存在固有的運動學偏差:其參考數據集主要包含雙足步態序列(如行走、轉向),卻缺乏對實現高度靈巧操作至關重要的手臂-軀干協調動作
- 相反,基于軌跡優化TO的方法則面臨互補的局限性——它們依賴于有限的運動基元庫,并且在實時應用中的計算效率低下,阻礙了策略的泛化能力。這在需要對非結構化輸入做出快速適應的動態場景中(如反應式遠程操作或環境擾動)嚴重制約了實際部署
為彌合這一差距,作者提出了自適應運動優化(AMO)——一種用于人形機器人實時全身控制的分層框架,通過兩項協同創新實現:
- 混合運動合成:通過融合來自動作捕捉數據的手臂軌跡與概率采樣的軀干朝向,構建混合上半身指令集,從系統上消除訓練分布中的運動學偏差
這些指令驅動具備動力學感知的軌跡優化器,生成既滿足運動學可行性又滿足動力學約束的全身參考動作,從而構建了AMO數據集——首個專為靈巧行走操作設計的人形機器人動作庫 - 可泛化策略訓練:雖然直接將指令映射到動作的離散查找表是一種簡單的解決方案,但此類方法本質上僅限于離散的、分布內場景
AMO網絡則學習連續映射,實現了在連續輸入空間及分布外(O.O.D)遠程操作指令之間的穩健插值,同時保持實時響應能力
在部署過程中,作者首先從VR遠程操作系統中提取稀疏姿態,并通過多目標逆向運動學輸出上半身目標。訓練好的AMO網絡和RL策略共同輸出機器人的控制信號
1.1.2 相關工作
第一,對于人形機器人全身控制
由于人形機器人具有高自由度和非線性,全身控制依然是一個具有挑戰性的問題
- 此前,這一問題主要通過動力學建模和基于模型的控制方法實現
14-?The mit humanoid robot: Design,motion planning, and control for acrobatic behaviors
16-Synchronized humanhumanoid motion imitation. IEEE Robotics and Automation Letters
18-Whole body humanoid control from human motion descriptors
19-Wholebody geometric retargeting for humanoid robots
31-The development of honda humanoid robot
32-Anymal-a highly mobile and dynamic quadrupedal robot
34-A simple modeling for a biped walking pattern generation
35-Development of wabot 1
51-Dynamic walk of a biped
52-Whole-body control of humanoid robots
56-A multimode teleoperation framework for humanoid loco-manipulation: An application for the icub robot
72-Hybrid zero dynamics of planar biped walkers
75-Simbicon: Simple biped locomotion control - 近年來,深度強化學習方法已在實現足式機器人魯棒行走性能方面展現出潛力
3-Legged locomotion in challenging terrains using egocentric vision
7-Legs as manipulator: Pushing quadrupedal agility beyond locomotion
8-Extreme parkour with legged robots
20-Learning vision-based bipedal locomotion for challenging terrain
21-Adversarial motion priors make good substitutes for complex reward functions
22-?Learning deep sensorimotor policies for vision-based autonomous drone racing
23-Minimizing energy consumption leads to the emergence of gaits in legged robots
26-Opt-mimic: Imitation of optimized trajectories for dynamic quadruped behaviors
37-Rma: Rapid motor adaptation for legged robots
38-Reinforcement learning for robust parameterized locomotion control of bipedal robots
39-Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control
40-Berkeley humanoid: A research platform for learning-based control
46-?Learning to jump from pixels
47-Rapid locomotion via reinforcement learning
61-?Learning humanoid locomotion with transformers
67-Blind bipedal stair traversal via sim-to-real reinforcement learning
73-Generalized animal imitator: Agile locomotion with versatile motion prior
74-Neural volumetric memory for visual locomotion control
79-?Robot parkour learning
總之,研究者們已經針對四足機器人
[7,8,22,27-Umi on legs: Making manipulation policies mobile with manipulation-centric whole-body controllers]
和人形機器人 [9-Exbody,24-Humanplus,29-H2O,33-?Exbody2],從高維輸入出發研究了全身控制
當然了,其中的
[24-Humanplus] 分別訓練了一個 transformer 用于控制,另一個用于模仿學習
[9-Exbody] 僅鼓勵上半身模仿動作,而下半身控制則被解耦
[29-H2O] 針對下游任務訓練了目標條件策略
所有 [9,24,29] 僅展示了有限的全身控制能力,其約束讓人形機器人保持軀干和骨盆靜止
而[33-Exbody2] 展示了人形機器人的富有表現力的全身動作,但并未強調利用全身控制來擴展機器人行走-操作任務空間
第二,對于人形機器人的遠程操作
人形機器人的遠程操作對于實時控制和機器人數據采集至關重要
此前在人形機器人遠程操作方面的工作包括 [11,24,28,29,42,64]
- 例如
24-Humanplus
29-H2O
使用第三人稱RGB相機獲取人類操作員的關鍵點。有些工作使用虛擬現實VR為操作員提供以自我為中心的觀察視角 - [11] 利用 AppleVisionPro 控制帶有靈巧手的主動頭部和上半身
- [42] 使用 Vision Pro 控制頭部和上半身,同時通過踏板進行行走控制。人形機器人的全身控制要求遠程操作員為機器人提供物理可實現的全身坐標
第三,行走操作模仿學習
模仿學習已被研究用于幫助機器人自主完成任務。現有的工作可根據演示來源分為
- 從真實機器人專家數據學習
4-RT-1
5-RT-2
12-diffusion policy
13-UMI
25-Mobile ALOHA
36-Droid: A large-scale in-thewild robot manipulation dataset
54-Openx-embodiment
55-The surprising effectiveness of representation learning for visual imitation
65-Yell at your robot
66-Perceiver-actor
76-?3d diffusion policy
78-ALOHA ACT - 從游戲數據學習
15-From play to policy:Conditional behavior generation from uncurated robot data
50-Alan : Autonomously exploring robotic agents in the real world
70-?Mimicplay: Long-horizon imitation learning by watching human play - 從人類演示學習
9-Exbody
21-Adversarial motion priors make good substitutes for complex reward functions
24-Humanplus
26-Opt-mimic
29-H2O
57-Learning agile robotic locomotion skills by imitating animals
58-AMP: adversarial motion priors for stylized physics-based character control
71-Unicon: Universal neural controller for physicsbased character motion
73-Generalized animal imitator: Agile locomotion with versatile motion prior
這些模仿學習研究主要局限于操作技能,而針對行走操作的模仿學習研究非常少。[25]研究了基于輪式機器人的行走操作模仿學習
本文利用模仿學習使人形機器人能夠自主完成行走操作任務
1.2?自適應運動優化
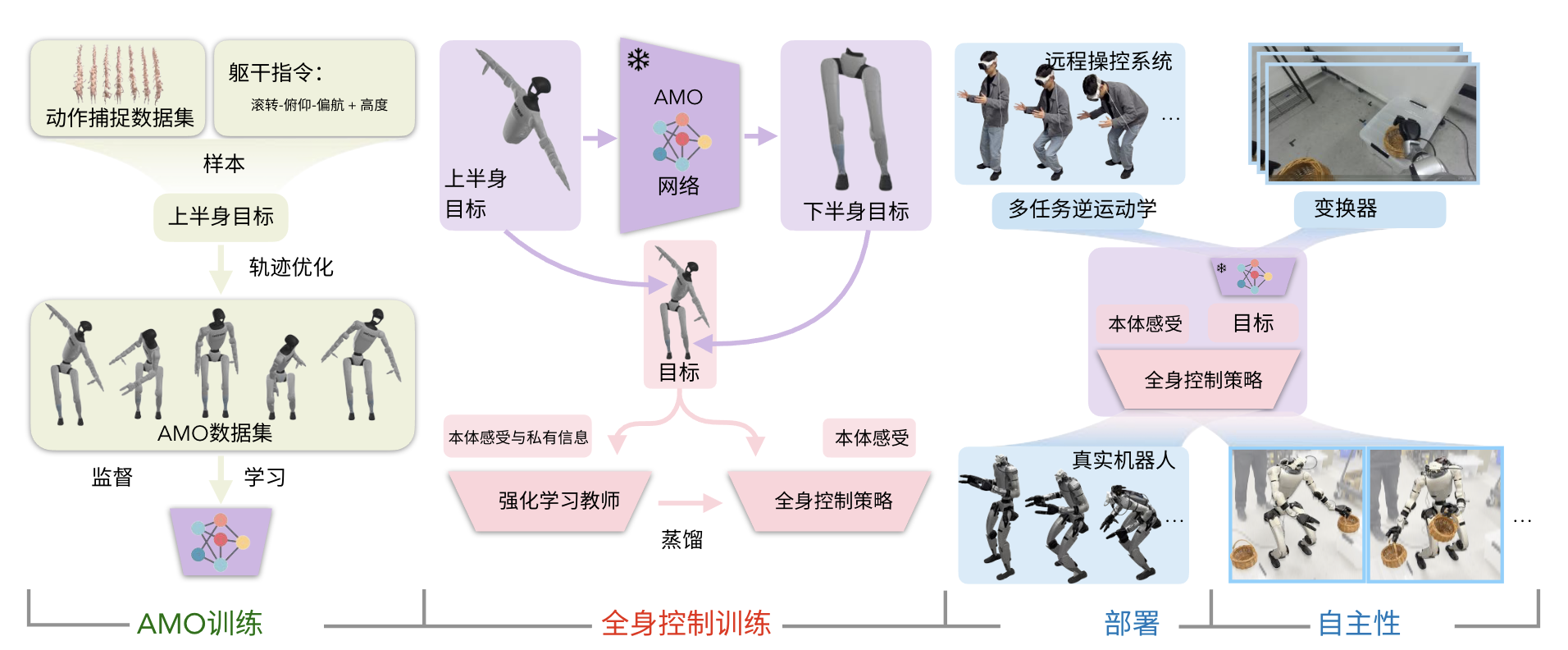
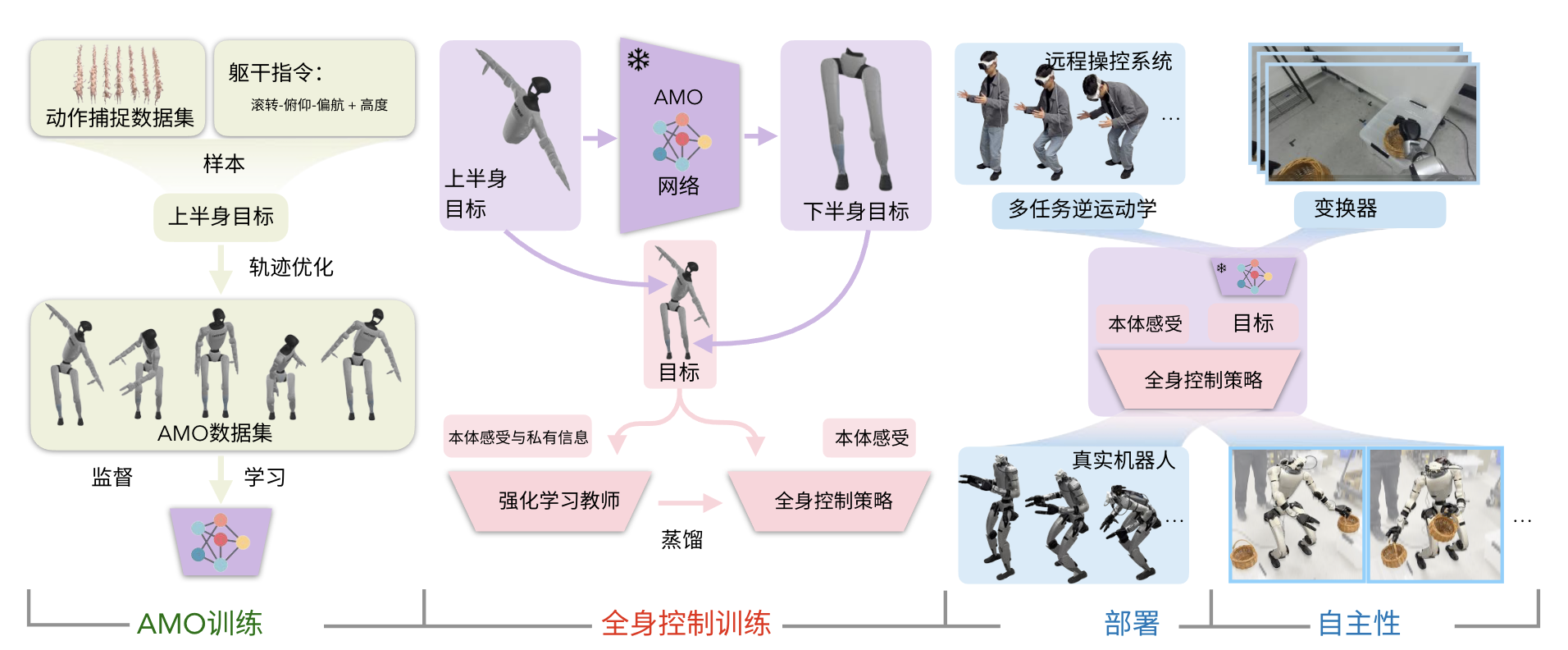
AMO定位于自適應運動優化,是一個實現無縫全身控制的框架,如圖2所示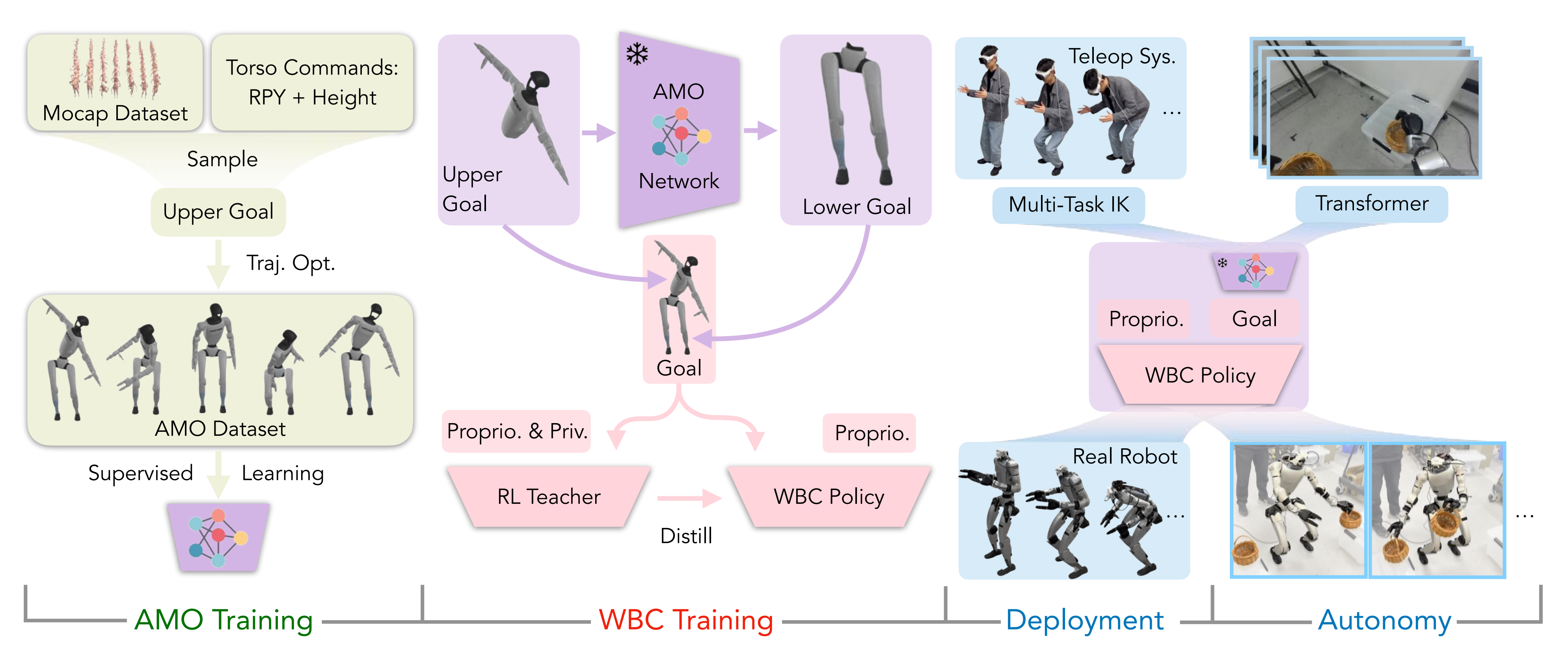
系統被分解為四個階段:
- 通過軌跡優化收集AMO數據集進行AMO模塊訓練
- 通過在仿真中采用師生蒸餾進行強化學習(RL)策略訓練
- 通過逆運動學(IK)和重定向實現真實機器人遠程操作
- 結合transformer,通過模仿學習(IL)進行真實機器人自主策略訓練
1.2.0 問題表述與符號定義
作者針對人形機器人全身控制的問題,重點關注兩種不同的設置:遠程操作和自主控制
- 在遙操作環境中,整體控制問題被表述為學習一個目標條件策略
,其中
?表示目標空間
表示觀測空間
?表示動作空間
? 目標條件遙操作策略接收來自遙操作員的控制信號
,其中
表示操作員的頭部和手部關鍵點姿態
而指定底座速度
包括視覺和本體感覺數據:
由上半身和下半身的關節角度指令組成:
進一步講,目標條件化策略采用分層設計:
- 上層策略
輸出上半身的動作,以及中間控制信號
,其中?
指令軀干方向,
指令基座高度
- 下層策略
利用此中間控制信號、速度指令和本體感覺觀測生成下半身的動作
- 在自主環境中,學習到的策略
僅基于觀測生成動作,無需人為輸入
進一步而言,自主策略與遙操作策略采用相同的分層設計
下層策略是相同的:
而上層策略則獨立于人類輸入生成動作和中間控制
1.2.1 適應模塊預訓練
在AMO的系統規范中,下層策略遵循形式為的指令。跟隨速度指令
的運動能力可以通過在仿真環境中隨機采樣定向向量,并采用與[8, 9-Exbody] 相同的策略輕松學習
然而,學習軀干和高度跟蹤技能則并非易事,因為它們需要全身協調。與運動任務不同,在運動任務中可以基于Raibert 啟發式[62]設計足部跟蹤獎勵以促進技能學習,而對于引導機器人完成全身控制,則缺乏類似的啟發式方法
一些工作[28-Omnih2o, 33-Exbody2]通過跟蹤人類參考來訓練此類策略。然而,他們的策略并未在人體姿態與全身控制指令之間建立聯系
為了解決這個問題,作者提出了一種自適應運動優化(adaptive motion optimization,簡稱AMO)模塊
AMO 模塊表示為。當接收到來自上層的全身控制指令
,
后,它將這些指令轉換為所有下肢執行器的關節角參考值,供下層策略顯式跟蹤

為了訓練這個自適應模塊
- 首先,通過隨機采樣上層指令并執行基于模型的軌跡優化來收集AMO 數據集,以獲得下肢關節角
軌跡優化可以被表述為一個多接觸最優控制問題(MCOP),其代價函數如下
其中包括對狀態和控制
的正則化、目標跟蹤項Lrpy 和Lh,以及用于在進行全身控制時確保平衡的質心(CoM)正則化項
- 在收集數據集時,作者
由于作者沒有考慮行走場景,機器人的雙腳都被認為與地面接觸
參考數據被通過 Crocoddyl [48,49] 使用受控制約的可行性驅動微分動態規劃(BoxFDDP)生成
1.2.2 底層策略訓練
使用大規模并行仿真在IsaacGym[44] 中訓練他們的低層策略。低層策略旨在跟蹤和
,同時利用本體感覺觀測
,其定義如下
- 上述公式包含了基座朝向
、基座角速度
、當前位置、速度和上一次的位置目標
- 值得注意的是,下層策略的觀測包括了上半身執行器的狀態,以實現更好的上下半身協調
是步態循環信號,其定義方式與[45, 77] 類似
是由AMO 模塊生成的下半身參考關節角度
下層動作空間是一個15 維向量,由雙腿的2 ?6個目標關節位置和腰部電機的3 個目標關節位置組成
作者選擇使用教師-學生框架來訓練他們的低層策略
- 首先訓練一個能夠在仿真中觀察特權信息的教師策略,使用現成的PPO[63]
進一步而言,教師策略可以表述為
額外的特權觀測定義如下
其中包括如下真實值:
基座速度
軀干姿態
以及基座高度
而在跟蹤其對應目標時,這些值在現實世界中并不容易獲得
?是腳與地面之間的接觸信號。教師RL訓練過程詳見原論文的附錄B
- 然后,通過監督學習將教師策略蒸餾到學生策略中。學生策略僅觀察現實中可用的信息,可以用于遠程操作和自主任務
進一步而言,學生策略可以寫成
為了用現實世界中可獲取的觀察結果來補償,學生策略利用了 25 步的本體感覺觀察歷史作為額外的輸入信號:
1.2.3?遙操作高層策略實現
遠程操作上層策略為全身控制生成一系列指令,包括手臂和手的運動、軀干方向以及底座高度
作者選擇采用基于優化的方法來實現該策略,以達到操作任務所需的精度
- 具體來說,手部運動通過重定向生成,而其他控制信號則通過逆運動學(IK)計算
他們的手部重定向實現基于 dex-retargeting [60]。關于重定向公式的更多細節見附錄A
在他們的全身控制框架中,他們將傳統的逆運動學(IK)擴展為多目標加權逆運動學,通過最小化與三個關鍵目標(頭部、左手腕和右手腕)的6維距離,實現對這些目標的精確控制——機器人調動所有上半身執行器,同時對齊這三個目標
形式化地,目標是
- 如下圖圖3所示
優化變量?包含了機器人上半身所有驅動自由度(DoFs):
、
和
。除了電機指令外,還會求解一個中間指令以實現全身協調:用于軀干姿態和高度控制的
為了確保上半身控制的平滑性,姿態代價在優化變量的不同組成部分上賦予了不同的權重:
這鼓勵策略優先使用上半身驅動器來完成較簡單的任務
然而,對于需要全身運動的任務,如彎腰拾取或夠取遠處目標,會生成額外的控制信號并發送給下層策略
下層策略協調其電機角度以滿足上層策略的要求,實現全身目標到達。他們的IK實現采用了Levenberg-Marquardt(LM)算法[68],并基于Pink[6]
1.2.4?自主上層策略訓練:基于模仿學習
作者通過模仿學習來訓練自主上層策略
- 首先,人類操作員對機器人進行遠程操作——使用目標條件策略,記錄觀測和動作作為示范
- 然后采用以DinoV2 [17, 53] 視覺編碼器為策略骨干的ACT [78]。視覺觀測包括兩張立體圖像
和
DinoV2 將每張圖片分割為16 × 22 個patch,并為每個patch 生成一個384 維的視覺token,得到的組合視覺token 形狀為2 × 16 × 22 × 384
該視覺token 與通過投影獲得的狀態token 拼接在一起
其中,是上半身本體感覺觀測,
構成了上一次發送給下層策略的指令
由于作者的解耦系統設計,上層策略觀測到的是這些下層策略指令,而不是直接的下半身本體感覺
策略的輸出表示為
包括所有上半身關節角度以及下層策略的中間控制信號
1.3 評估
在本節中,作者旨在通過在仿真和現實世界中的實驗來回答以下問題:
- AMO 在跟蹤運動指令和軀干指令(rpy, h)方面的表現如何?
- AMO 與其他 WBC 策略相比如何?
- AMO系統在真實環境中的表現如何?
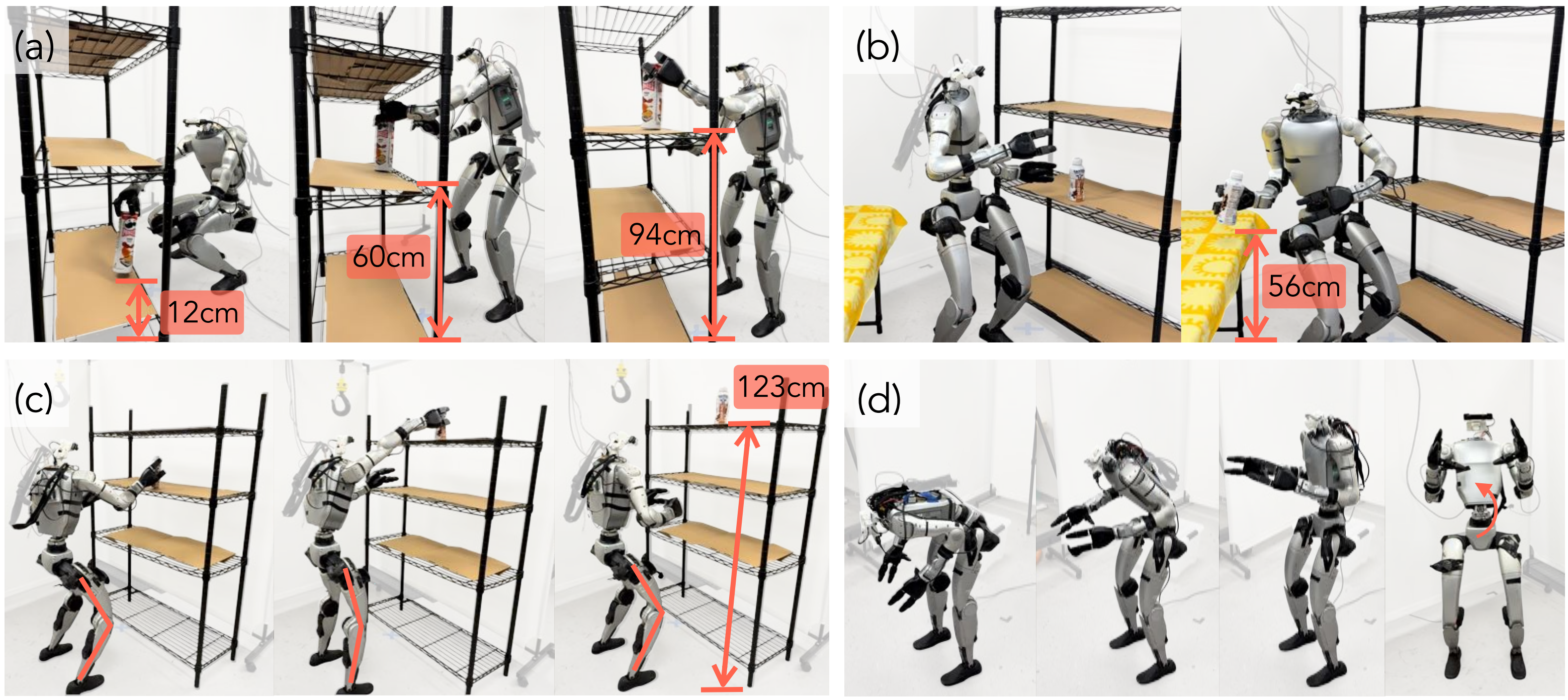
作者在IsaacGym仿真器[44]中進行了模擬實驗。真實機器人搭建如圖3所示『遙操作系統概覽。操作員提供三個末端執行器目標:頭部、左手腕和右手腕的位姿。多目標逆運動學(IK)通過同時匹配三個加權目標來計算上層目標和中間目標。中間目標(rpy,h)被輸入到AMO,并轉換為下層目標』
- 該機器人是在Unitree G1[1]基礎上改裝,并配備了兩個Dex3-1靈巧手。該平臺具有29個全身自由度,每只手有7個自由度
- 且作者定制了一個帶有三個驅動自由度的主動頭部,用于映射人類操作員的頭部運動,并安裝了一臺ZED Mini[2]相機用于立體視覺流傳輸
1.3.1?AMO在跟蹤運動指令和軀干指令rpy, h方面的表現如何?
表II展示了AMO性能的評估,并將其與以下基線方法進行了比較:
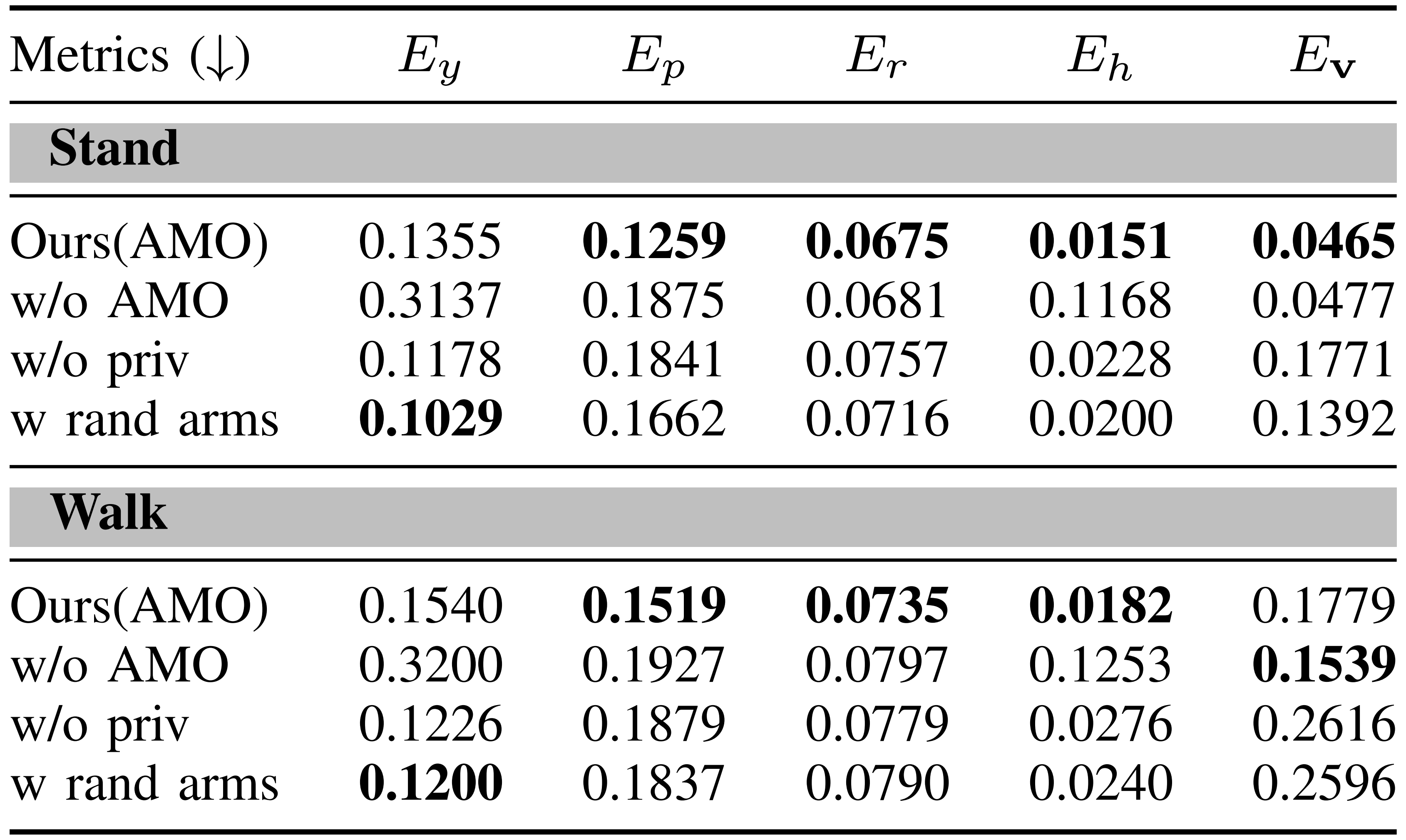
- w/o AMO:該基線遵循與Ours(AMO) 相同的強化學習訓練方案,但有兩個關鍵修改
首先,它在觀察空間中排除了AMO 輸出
其次,它不是對偏離 - w/o priv:該基線在訓練時不包含額外的特權觀測
- w rand arms:在該基線中,手臂關節角度不是通過從MoCap 數據集中采樣的人體參考設置的,而是在各自的關節限制范圍內均勻隨機采樣賦值
性能評估采用以下指標:
- 軀干方向追蹤精度
軀干方向追蹤通過,
,
進行測量
結果表明
AMO 在橫滾和俯仰方向上實現了更高的追蹤精度。在俯仰追蹤方面的提升最為顯著,其他基線方法難以保持精度,而AMO顯著降低了追蹤誤差
w rand arms 表現出最低的偏航追蹤誤差,這可能是因為隨機手臂運動使機器人能夠探索更廣泛的姿態范圍
然而,AMO 在偏航追蹤方面并不一定表現突出,因為與橫滾和俯仰相比,軀干偏航旋轉引起的質心位移較小。因此,偏航追蹤精度可能無法充分反映AMO 在生成自適應和穩定姿態方面的能力
盡管如此,值得注意的是,w/o AMO 在偏航追蹤方面表現不佳,這表明AMO 為實現穩定的偏航控制提供了關鍵的參考信息 - 高度跟蹤精度
結果顯示,AMO 實現了最低的高度跟蹤誤差。值得注意的是,w/oAMO 報告的誤差顯著高于所有其他基線,表明其幾乎無法跟蹤高度指令
與軀干跟蹤不同,軀干跟蹤中至少有一個腰部電機角度與指令成正比,而高度跟蹤則需要多個下肢關節的協調調整
缺乏來自 AMO 的參考信息,策略無法學習高度指令與相應電機角度之間的變換關系,從而難以掌握這一技能 - 線速度跟蹤精度
AMO模塊基于雙支撐姿態下的全身控制生成參考姿態,這意味著它未考慮行走過程中因擺腳產生的姿態變化
盡管存在這一限制,AMO仍能實現穩定的行走,并保持較低的跟蹤誤差,展現出其魯棒性
// 待更




)








統計數據,以及過濾同時為0的數據)



Anaconda詳細安裝教程Anaconda3 最新版安裝教程)
)
