
文章目錄
- 前言
- 一、從生活場景到架構原理,看懂管道 - 過濾器的核心邏輯
- (一)什么是管道 - 過濾器架構?
- (二)核心組件拆解
- 二、架構設計圖:一圖看懂管道 - 過濾器架構全貌
- 三、Java 示例代碼:手把手教你實現管道 - 過濾器架構
- (一)定義過濾器接口
- (二)實現具體過濾器
- (三)實現管道類
- (四)使用示例
- 四、管道 - 過濾器架構的優勢與適用場景
- (一)核心優勢
- (二)適用場景
- 五、使用管道 - 過濾器架構的注意事項
- 總結
前言
在互聯網技術的高速發展中,系統架構的設計直接影響著軟件的性能與可維護性。當你在使用 ETL 工具處理海量數據,或是在編譯器中實現代碼的層層解析時,背后往往都有一個低調卻強大的架構風格在支撐 —— 管道 - 過濾器架構。作為一個在系統架構領域摸爬滾打多年的老濕機,今天就來和大家深度剖析這個 “數據處理利器”,帶你從理論到實踐吃透它!
一、從生活場景到架構原理,看懂管道 - 過濾器的核心邏輯
(一)什么是管道 - 過濾器架構?
**管道 - 過濾器架構,顧名思義,其靈感來源于現實生活中的流水線作業。**想象一下工廠里的汽車組裝流水線,每個工位的工人負責特定的組裝步驟,零件依次從一個工位傳遞到下一個工位,最終完成汽車的組裝。
在軟件架構中,“過濾器” 就如同流水線上的工位工人,負責對數據進行特定處理;“管道” 則是連接這些工位的傳送帶,負責將數據從一個過濾器傳輸到下一個過濾器。
每個過濾器都有明確的輸入和輸出,它們相互獨立,只專注于自己的處理任務,如數據清洗、格式轉換、邏輯校驗等。數據通過管道在各個過濾器之間流動,形成一條完整的數據處理鏈路。
例如,在一個日志分析系統中,數據首先經過 “日志采集過濾器” 收集原始日志,然后通過管道傳遞給 “日志清洗過濾器” 去除無效信息,接著再傳遞給 “日志分析過濾器” 提取關鍵數據,最后輸出分析結果。

(二)核心組件拆解
過濾器(Filter):過濾器是無狀態的處理單元,它只根據輸入數據產生輸出,不會受到其他過濾器或系統狀態的影響。比如在編譯器中,“詞法分析過濾器” 會將源代碼分解成一個個單詞,不依賴后續的語法分析過程。
管道(Pipe):管道負責數據的傳輸,它可以是同步傳輸,也可以是異步傳輸,甚至支持數據緩沖。像 Unix 系統中的管道符 “|”,就是典型的管道實現,它能將一個命令的輸出作為另一個命令的輸入。在軟件系統中,消息隊列(如 Kafka)也可以充當管道的角色,實現數據在不同過濾器之間的異步傳遞。
數據流(Data Flow):數據流決定了數據在過濾器之間的流動方向和順序。它支持增量處理,即前一個過濾器無需完全處理完所有數據,就可以將部分結果傳遞給下一個過濾器,從而提高整體處理效率。
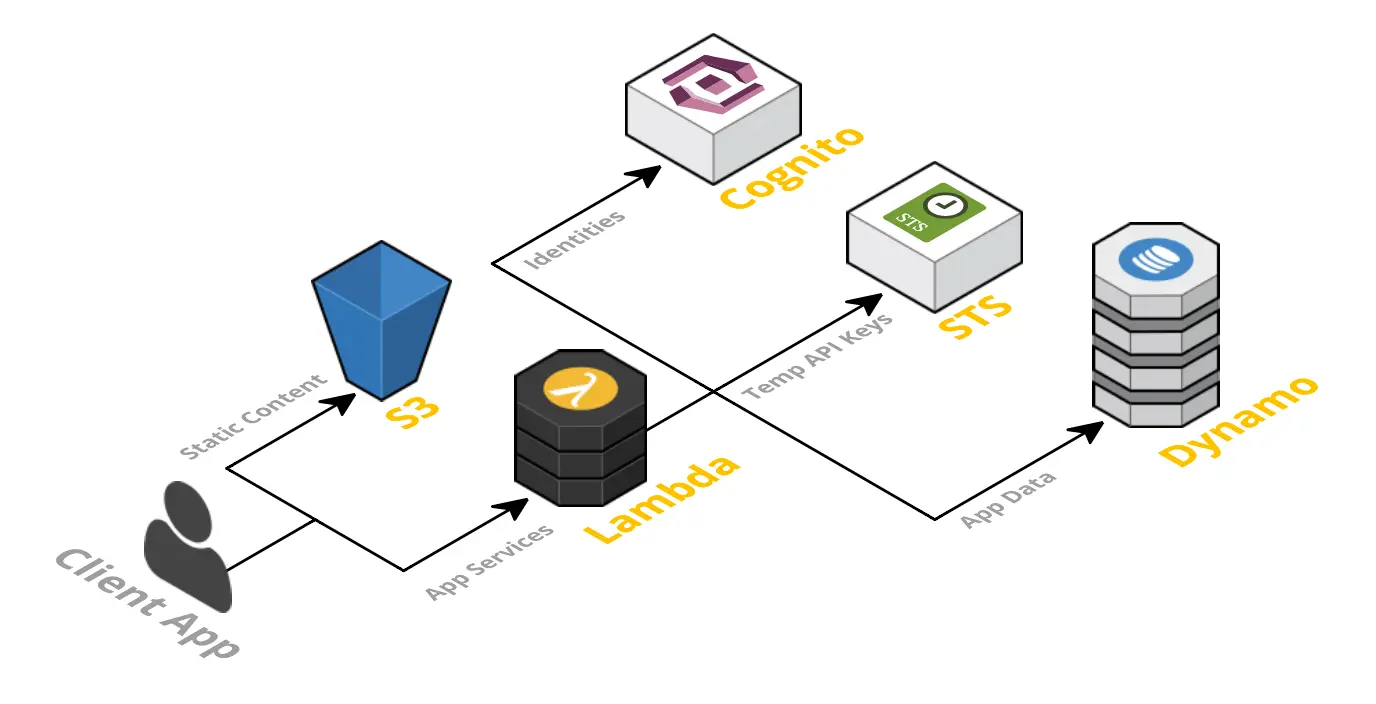
二、架構設計圖:一圖看懂管道 - 過濾器架構全貌

在這張架構設計圖中,最上方的 A 節點代表數據源,數據從這里開始進入處理流程。緊接著是一系列的過濾器(B - F),每個過濾器負責不同的數據處理任務。數據通過管道(管道 1 - 管道 3)在過濾器之間有序流動,最終到達數據目標 G,完成整個數據處理過程。通過這張圖,我們可以清晰地看到管道 - 過濾器架構中各組件之間的關系和數據的流向。
三、Java 示例代碼:手把手教你實現管道 - 過濾器架構
(一)定義過濾器接口
public interface Filter<T> {//對輸入數據進行處理并返回處理結果T process(T input);
}
這里定義了一個泛型接口Filter,它只有一個方法process,用于對輸入數據進行處理并返回處理結果。
(二)實現具體過濾器
以一個簡單的文本處理為例,我們實現兩個過濾器:“文本大寫轉換過濾器” 和 “文本添加前綴過濾器”。
// 文本大寫轉換過濾器
public class UppercaseFilter implements Filter<String> {@Overridepublic String process(String input) {return input.toUpperCase();}
}// 文本添加前綴過濾器
public class PrefixFilter implements Filter<String> {@Overridepublic String process(String input) {return "處理后: " + input;}
}
(三)實現管道類
import java.util.ArrayList;
import java.util.List;public class Pipeline<T> {private final List<Filter<T>> filters = new ArrayList<>();//向管道中添加過濾器public Pipeline<T> addFilter(Filter<T> filter) {this.filters.add(filter);return this;}//按照順序依次調用每個過濾器的process方法,對輸入數據進行處理public T execute(T input) {T output = input;for (Filter<T> filter : filters) {output = filter.process(output);}return output;}
}
在Pipeline類中,我們使用一個List來存儲過濾器。addFilter方法用于向管道中添加過濾器,execute方法則按照順序依次調用每個過濾器的process方法,對輸入數據進行處理。
(四)使用示例
public class Main {public static void main(String[] args) {Pipeline<String> pipeline = new Pipeline<>();pipeline.addFilter(new UppercaseFilter()).addFilter(new PrefixFilter());String input = "hello world";String result = pipeline.execute(input);System.out.println(result);}
}
在main方法中,我們創建了一個Pipeline對象,并向其中添加了兩個過濾器。然后輸入一段文本 “hello world”,經過管道處理后,最終輸出 “處理后: HELLO WORLD”。

四、管道 - 過濾器架構的優勢與適用場景
(一)核心優勢
高內聚低耦合:每個過濾器獨立完成自己的任務,與其他過濾器之間的耦合度極低。例如在電商系統的訂單處理中,“庫存檢查過濾器” 和 “支付處理過濾器” 可以獨立開發和維護,一個過濾器的修改不會影響到另一個。
可擴展性強:當業務需求發生變化,需要增加新的數據處理邏輯時,只需新增一個過濾器并將其添加到管道中即可,無需對整個系統進行大規模改動。
支持并行處理:多個過濾器可以并行運行,提高數據處理效率。比如在圖像處理系統中,“圖像縮放過濾器” 和 “圖像色彩調整過濾器” 可以同時對圖像進行處理。

(二)適用場景
數據處理系統:如 ETL(Extract - Transform - Load)工具,用于從不同數據源提取數據,進行轉換后加載到數據倉庫中。
編譯器:編譯器的各個階段(詞法分析、語法分析、語義分析等)可以看作是過濾器,通過管道依次處理源代碼。
Web 應用中間件:在 Web 應用中,請求處理過程可以使用管道 - 過濾器架構,例如通過過濾器實現請求日志記錄、身份認證、參數校驗等功能。

五、使用管道 - 過濾器架構的注意事項
雖然管道 - 過濾器架構有諸多優勢,但也并非適用于所有場景。在使用時需要注意:
數據格式一致性:各個過濾器之間的數據格式需要保持一致,否則在管道傳輸過程中可能會出現問題。這就要求在設計過濾器時,明確輸入和輸出的數據格式標準。
性能開銷:如果管道中過濾器數量過多,數據在管道中的傳輸和處理可能會帶來一定的性能開銷。因此需要合理規劃過濾器的數量和處理邏輯,避免性能瓶頸。
錯誤處理:由于過濾器之間相互獨立,當某個過濾器出現錯誤時,需要有完善的錯誤處理機制,確保不會影響整個系統的穩定性。
總結
管道 - 過濾器架構它就像一把 “瑞士軍刀”,在數據處理領域有著廣泛的應用和強大的能力。無論是在實際項目中,還是在技術學習過程中,掌握這種架構風格都能為我們帶來更多的思路和解決方案。
圖片來源網絡

![polarctf-web-[簡單rce]](http://pic.xiahunao.cn/polarctf-web-[簡單rce])

)
)
openjdk17 c++源碼垃圾回收安全點信號函數處理線程阻塞)










)


