Transformer出現的背景
- CNN 的全局關聯缺陷卷積神經網絡(CNN)通過多層堆疊擴大感受野,但在自然語言處理中存在本質局限:
- 局部操作的語義割裂:每個卷積核僅處理固定窗口(如 3-5 詞),需 12 層以上網絡才能覆蓋 50 詞以上序列
- 位置信息的間接表征:依賴人為設計的位置嵌入(如 Word2Vec 的滑動窗口),無法直接建模非連續詞間的語義關聯
- RNN/LSTM 的序列依賴困境循環神經網絡(RNN)及其改進版本(LSTM/GRU)在處理長序列時存在兩大核心問題:
- 時序處理的串行化限制:依賴隱狀態逐層傳遞,無法并行計算,訓練效率隨序列長度呈線性下降
- 長距離依賴衰減:即使引入門控機制,梯度消失問題仍導致超過 200 詞的序列出現顯著語義損耗
- 前向和反向傳播:RNN 需要按時間步展開,前向和反向傳播計算更加復雜,而 Transformer 則因其結構使得前向和反向傳播更加高效和簡潔
Transformer的結構解釋
任務 處理災區求救信號,生成救援指令:
輸入信號(Encoder):
“山區公路積雪3米,斷電,50人被困,急需發電機和醫療隊”
輸出指令(Decoder):
“派3臺除雪車至A7公路,醫療隊隨行,協調電力公司恢復供電”
1. Encoder-Decoder 結構
Transformer 包含編碼器和解碼器兩個主要部分。編碼器負責接收輸入序列,提取特征,生成一系列向量表示,解碼器則根據這些向量表示生成輸出序列。
Encoder-Decoder 結構 → 指揮中心與執行部門
- Encoder(情報分析組):
負責解讀所有求救信息,提煉關鍵情報(積雪深度、斷電位置、人數)。
就像指揮部里的地圖標記員,把雜亂信息轉化成標準標簽。
- 輸入:原始求救信號 “山區公路積雪3米,斷電,50人被困,急需發電機和醫療隊”
- 處理流程:
- 多頭注意力:
- 交通組發現"積雪3米"和"公路"強相關 → 標記為道路封鎖
- 醫療組關聯"50人被困"和"醫療隊" → 標記為大規模傷員
- FFN深化處理:
- 輸入"積雪3米" → 匹配預案庫 → 輸出"需重型除雪車"
- 輸出:一組帶有完整語義的向量(即情報地圖):
{ “位置”: “山區A7公路”, “災情”: [“道路封鎖-重型”, “電力中斷”, “50人-緊急醫療”] }
- Decoder(救援調度組):
根據Encoder的情報+已派出的救援記錄(如"已派2臺除雪車"),動態生成新指令。
就像調度主任,邊看地圖邊拿對講機指揮。
- 輸入:Encoder的情報地圖 + 已生成的指令前綴(逐步生成)
- 分步生成示例:
- 初始輸入:[開始]
- Decoder查詢情報地圖,發現最高優先級是"道路封鎖" → 生成"派3臺除雪車"
- 輸入:[開始] + “派3臺除雪車”
- 結合"位置:山區A7公路" → 生成"至A7公路"
- 輸入:[開始] + “派3臺除雪車至A7公路”
- 檢查"50人-緊急醫療" → 追加"醫療隊隨行"
- 最終輸出:
“派3臺除雪車至A7公路,醫療隊隨行,協調電力公司恢復供電”
2. 多頭自注意力機制(Multi-head Self-Attention)
這是 Transformer 的核心技術,允許模型在計算每個單詞的表示時,同時關注輸入序列中的不同位置。這種機制通過多個’頭’(head)并行計算注意力(attention),然后將它們的結果合并,既增強了模型的表達能力,又保留了位置信息。
多頭自注意力 → 多部門交叉驗證情報
自注意力機制的作用是讓模型動態計算句子中每個詞與其他詞的關系權重,從而決定在處理當前詞時應該“關注”哪些其他詞。
在上述示例中,假設是你來撥打報警電話(輸入pompt)那么可能是這樣的:
“你好,110嗎,我在路上遭遇了雪災,雪已經可以完全蓋住我開的車了,現在車已經熄火了,溫度太低基本上已經沒電了,我附近大概有50個人左右,可能已經有人被埋了,你們快來救人”
比較上述示例: “山區公路積雪3米,斷電,50人被困,急需發電機和醫療隊” 在我們自己描述這一問題時,會引入一些人的表達習慣,信息密度較低
- 多頭自注意力:
- 交通組同時分析"積雪3米"和"公路"→ 需要除雪車
- 醫療組關聯"50人被困"和"醫療隊"→ 需增派醫生 就像多個專家小組用不同視角分析同一份數據,避免片面決策。
自注意力機制會自動學習這些關聯權重,而不是依賴固定規則。
自注意力通過Query(Q)、Key(K)、Value(V)三個矩陣運算來計算詞與詞之間的相關性:
- Query(Q):當前詞(如 “積雪3米”)的“提問”,表示它想關注哪些信息。
- Key(K):所有詞的“索引”,用于匹配Query。
- Value(V):所有詞的“實際內容”,用于加權求和。
2.1 計算過程
- 相似度計算(Q·K):計算當前詞(Q)與其他詞(K)的關聯程度。
- 例如,“積雪3米” 的Query 和 “公路” 的Key 會有較高的點積值(因為它們相關)。
- Softmax歸一化:轉換成概率分布(權重)。
- 加權求和(Attention Output):用權重對Value(V)進行加權,得到當前詞的最終表示。
公式:

2.2 通俗理解-并行計算
單頭自注意力就像一個專家分析災情,可能只關注某一方面(如交通)。而多頭自注意力相當于多個專家團隊(交通組、醫療組、電力組)同時分析同一份數據,各自關注不同方面的關聯,最后匯總結果。
救災示例:
- 交通組(Head 1):關注 “積雪3米” 和 “公路” → 計算除雪車需求
- 醫療組(Head 2):關注 “50人被困” 和 “山區” → 計算醫療隊規模
- 電力組(Head 3):關注 “斷電” 和 “發電機” → 計算電力恢復方案
最后,所有組的結論拼接(Concatenate)起來,形成更全面的決策。
2.3 學術視角
- 多頭拆分:
- 輸入的Q、K、V 被線性投影到多個(如8個)不同的子空間(使用不同的權重矩陣 WiQ,WiK,WiV)。
- 每個頭獨立計算注意力:
![[圖片]](https://i-blog.csdnimg.cn/direct/f2b92604db8c499aaa38f7ca9d604f2a.png)
- 多頭合并:
- 所有頭的輸出拼接后,再經過一次線性變換得到最終結果:
![[圖片]](https://i-blog.csdnimg.cn/direct/09c43a046a904f5e986ec8f245902af2.png)
2.4 在示例中的完整流程
假設輸入句子:
“山區公路積雪3米,斷電,50人被困”
(1) 單頭自注意力(簡化版)
- 計算Q、K、V:
- 對每個詞(如 “積雪3米”)生成Query、Key、Value。
- 計算注意力權重:
- “積雪3米” 的Query 會和 “公路” 的Key 計算高分值(強相關)。
- “積雪3米” 和 “斷電” 的關聯可能較低。
- 加權求和:
- “積雪3米” 的新表示 = 0.6 * “公路” + 0.3 * “山區” + 0.1 * “斷電” (2)多頭自注意力
- Head 1(交通視角):
- “積雪3米” 關注 “公路” → 輸出 “需除雪車”
- Head 2(醫療視角):
- “50人被困” 關注 “山區” → 輸出 “需大規模醫療隊”
- Head 3(電力視角):
- “斷電” 關注 “發電機” → 輸出 “需緊急供電”
最終拼接:
Output=Concat(“需除雪車”,“需醫療隊”,“需供電”)→綜合決策Output=Concat(“需除雪車”,“需醫療隊”,“需供電”)→綜合決策
3. 位置編碼(Positional Encoding)
由于 Transformer 是無序列化的(no recurrence),需要通過加入位置編碼來引入位置信息,使模型能夠區分序列中不同位置的元素。位置編碼一般是基于正弦和余弦函數的,為每個位置生成獨特的編碼。
位置編碼 → 災情坐標標簽 即使求救信號亂序: “斷電,山區50人被困,積雪…”
通過位置編碼(像給災情GPS打坐標),模型仍知道"山區"是核心位置,"斷電"是附屬狀態。
3.1 為什么需要位置編碼
自注意力的缺陷:排列不變性
自注意力機制(Self-Attention)在計算時,詞的順序不影響其權重計算。也就是說,以下兩個句子在自注意力看來是等價的:
- “公路積雪3米”
- “積雪3米公路”
但在現實中,詞序至關重要(如 “先救援再評估” vs “先評估再救援” 完全不同)。
救災示例:
- 輸入 “A區雪崩,B區塌方” 和 “B區塌方,A區雪崩” 在自注意力看來是相同的,但實際上救援優先級完全不同!
- Transformer需要額外信息來感知詞序,這就是位置編碼的作用。 學術視角:序列建模的挑戰 傳統RNN/LSTM通過遞歸計算隱式編碼位置信息(第t個詞的隱藏狀態依賴第t?1個詞)。但Transformer的自注意力是并行計算的,沒有天然的順序概念,因此必須顯式注入位置信息。
3.2 位置編碼的解決方案
基本思路
在輸入詞嵌入(Word Embedding)上直接疊加位置信息,使得模型能區分:
- “公路(位置1)積雪(位置2)3米(位置3)”
- “積雪(位置1)公路(位置2)3米(位置3)”
兩種主流方法
- 可學習的位置編碼(Learned Positional Embedding)
- 直接訓練一個位置嵌入矩陣(類似詞嵌入)。
- 缺點:難以泛化到比訓練更長的序列。
- 固定公式的位置編碼(Sinusoidal Positional Encoding)
- 使用正弦/余弦函數生成位置編碼(Transformer論文采用的方法)。
- 優點:可以擴展到任意長度序列。
計算公式

- 不同頻率的正弦/余弦函數:低頻(長周期)編碼粗粒度位置,高頻(短周期)編碼細粒度位置。
![[圖片]](https://i-blog.csdnimg.cn/direct/e4e71f5caf9b494a90851da59fdf426b.png)
4. 前饋神經網絡(Feed-Forward Neural Networks) FFN
每個編碼器和解碼器層中都有一個基于位置的前饋神經網絡,通常由兩個全連接層組成,能夠自動調整其參數,如加深網絡學習更復雜的模式。
前饋神經網絡 → 專業處置預案
Encoder提煉的情報(如"積雪3米"),會交給FFN這個預案庫匹配具體行動:
- 輸入:積雪深度3米
- 輸出:需派出重型除雪車(輕型只能處理1米積雪)
就像預存的救災手冊,把抽象數據轉化成具體設備型號。
4.1 基本定義
- FFN是Transformer中每個Encoder/Decoder層的核心組件之一,接收自注意力層的輸出,進行非線性變換。其結構非常簡單:
![[圖片]](https://i-blog.csdnimg.cn/direct/08c1ffe8de1144429c3ad0cf1ecc48fa.png)
- 輸入:自注意力輸出的單個位置的向量(如 “積雪3米” 的編碼向量)。
- 輸出:同一位置的增強版表示。
- 關鍵特點
- 逐位置獨立計算:每個詞的FFN計算互不干擾(與自注意力的全局交互互補)。
- 兩層全連接+ReLU:引入非線性,擴展模型容量。
- 維度變化:通常中間層維度更大(如輸入512維→中間2048維→輸出512維)。
- 為什么需要FFN
- 自注意力是線性變換+加權求和,缺乏復雜非線性映射能力。
- FFN通過ReLU激活函數和隱藏層,賦予模型分層次處理特征的能力(類似CNN中的卷積核堆疊)。
FFN就像救災指揮中心的標準化預案執行器:
- 輸入:自注意力分析的災情摘要(如"積雪3米+公路")。
- 處理:通過非線性變換匹配具體行動(“派重型除雪車”)。
- 輸出:機器可執行的精準指令,確保救援措施不偏離實際需求。
RNN用于處理序列數據的時間依賴關系,而FFN則用于對RNN的輸出進行進一步的特征提取和分類
拓展:為什么都說Transformer的核心是self-attachment,而不是FFN?
![[圖片]](https://i-blog.csdnimg.cn/direct/3388a1f00d1943d58fe977bd92f463d3.png)
4.2 技術細節
- 維度擴展設計
- 典型配置:輸入512維 → 中間2048維 → 輸出512維。
- 為什么擴展維度? 更大的中間層可以學習更復雜的特征組合(如積雪深度+公路類型+溫度的綜合判斷)。
- 與殘差連接的協作
FFN通常與殘差連接(Add & Norm)配合:
![[圖片]](https://i-blog.csdnimg.cn/direct/73069fc520a545748f0031e620a02254.png)
- 殘差連接:防止梯度消失,保留原始信息(如確保"積雪"的語義不丟失)。
- LayerNorm:穩定訓練,加速收斂。
4.3 完整示例
輸入句子:“山區公路積雪3米,斷電”
- 自注意力層:
- 計算"積雪3米"與"公路"的高權重,輸出關聯向量。
- FFN處理"積雪3米":
- 第一層:ReLU(0.3深度 + 0.7類型 - 0.2*海拔) → 激活值=1.2
- 第二層:1.2 * [重型設備權重] → 輸出"重型除雪車"編碼。
- 殘差連接:
- 原始"積雪3米"向量 + FFN輸出 → 最終增強表示。
5. 殘差連接(Residual Connection)與層歸一化(Layer Normalization)
每一個子層(如自注意力層和前饋神經網絡層)之后都有一個殘差連接和層歸一化。這些技術可以加速網絡的訓練并提高模型的穩定性和收斂速度。
殘差連接 → 抗通訊干擾 指揮中心電臺可能受暴風雪干擾,導致指令斷斷續續。殘差連接確保: 原始信號(“斷電”) →
干擾后(“電…斷”) → 仍能還原關鍵信息 就像通訊員重復確認:“您是說電力中斷對嗎?”
5.1 殘差連接(Residual Connection)
(1) 核心思想:信息高速公路
學術定義:將模塊的輸入直接加到輸出上,形成“短路”連接:
![[圖片]](https://i-blog.csdnimg.cn/direct/b3dab2e59c98450486b096e67bf07462.png)
(其中SubLayer可以是自注意力或FFN)
救災類比:
假設指揮中心處理災情報告時:
- 原始報告(輸入x):“A區積雪3米”
- 分析結果(SubLayer(x)):“需派除雪車”
- 殘差輸出:“A區積雪3米 + 需派除雪車” 為什么重要?
- 防止信息在深層網絡中丟失(如“積雪3米”這一關鍵數據被誤刪)。
- 讓梯度可以直接回傳,緩解梯度消失問題。
(2) 數學性質
- 梯度傳導:反向傳播時,梯度可通過殘差路徑“無損”回傳:
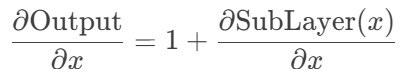
- 即使SubLayer的梯度趨近于0,總梯度仍能保持≥1。
(3) 救災示例
- 無殘差連接: 多次分析后,原始信息可能被覆蓋: “積雪3米” → “需除雪” → “調車輛” → “協調司機”(最終丟失了關鍵數字“3米”)
- 有殘差連接: 每步保留原始信息: “積雪3米” → [“積雪3米” + “需除雪”] → [“積雪3米” + “調3噸車”]
5.2 層歸一化(Layer Normalization)
(1) 核心思想:穩定信號強度
學術定義:對單樣本所有特征維度做歸一化:
![[圖片]](https://i-blog.csdnimg.cn/direct/1d3c2613d9b54de4bbe655ef85ae7616.png)
- μ,σ:該樣本所有維度的均值/方差
- γ,β:可學習的縮放和偏移參數
救災類比:
- 問題:不同災情報告的數值尺度差異大(如積雪深度=3米 vs 被困人數=50人)。
- 解決:歸一化到同一尺度,避免某些特征(如人數)主導模型。
- 結果:"積雪3米"和"50人"被統一到[-1,1]范圍,模型更穩定。
(2) 與BatchNorm的區別
(3) 救災示例
- 輸入:[積雪深度=3, 斷電電壓=0, 被困人數=50]
- 計算:
![[圖片]](https://i-blog.csdnimg.cn/direct/d83db79656054204b48c8243d2c898ac.png)
總結
- Encoder-Decoder結構
Encoder將輸入序列(如求救信號)壓縮為高維語義向量,Decoder基于該向量逐步生成目標序列(如救援指令),實現「情報分析」到「任務執行」的分工協作。 - 多頭自注意力(Multi-Head Attention)
通過多組并行注意力機制(如交通組、醫療組、電力組)同時分析輸入的不同關聯模式,提升模型對復雜語義的捕捉能力。 - 位置編碼(Positional Encoding)
為詞嵌入添加正弦/余弦位置信號,使模型感知詞序(如災情報告的優先級),解決自注意力機制的排列不變性問題。 - 前饋神經網絡(FFN)
對自注意力輸出做非線性變換(如匹配救災預案),將抽象特征轉化為具體指令(如“積雪3米→派重型除雪車”)。 - 殘差連接(Residual Connection)
將模塊輸入直接疊加到輸出上(如保留原始災情描述),防止深層網絡中的信息丟失和梯度消失。 - 層歸一化(Layer Normalization)
對單樣本所有特征做歸一化(如統一“積雪深度”和“被困人數”的數值范圍),穩定訓練并加速收斂。


)






)



)
連接mysql數據庫,寫入計算結果)

)


