分布式 ID
- 當單機 MySQL 已經無法支撐系統的數據量時,就需要進行分庫分表(推薦 Sharding-JDBC)。在分庫之后, 數據遍布在不同服務器上的數據庫,數據庫的自增主鍵已經沒辦法滿足生成的主鍵全局唯一了。這個時候就需要生成分布式 ID了。
分布式 ID 應滿足的需求
- 一個最基本的分布式 ID 需要滿足下面這些要求:
- 全局唯一:ID 的全局唯一性肯定是首先要滿足的!
- 高性能:分布式 ID 的生成速度要快,對本地資源消耗要小。
- 高可用:生成分布式 ID 的服務要保證可用性無限接近于 100%。
- 有序遞增:如果要把 ID 存放在數據庫的話,ID 的有序性可以提升數據庫寫入速度。并且很多時候 ,我們還很有可能會直接通過 ID 來進行排序。
- 除了這些之外,一個比較好的分布式 ID 還應保證:
- 安全:ID 中不包含敏感信息。
- 方便易用:拿來即用,使用方便,快速接入!
- 有具體的業務含義:生成的 ID 如果能有具體的業務含義,可以讓定位問題以及開發更透明化(通過 ID 就能確定是哪個業務)。
- 獨立部署:也就是分布式系統單獨有一個發號器服務,專門用來生成分布式 ID。這樣就生成 ID 的服務可以和業務相關的服務解耦。不過,這樣同樣帶來了網絡調用消耗增加的問題。總的來說,如果需要用到分布式 ID 的場景比較多的話,獨立部署的發號器服務還是很有必要的。
分布式 ID 的生成策略
1)UUID
- UUID 是 Universally Unique Identifier(通用唯一標識符) 的縮寫。UUID 包含 32 個 16 進制數(8-4-4-4-12)。
- JDK 就提供了現成的生成 UUID 的方法,一行代碼就行了。
//輸出示例:cb4a9ede-fa5e-4585-b9bb-d60bce986eaa UUID.randomUUID() - 優點:生成速度通常比較快、簡單易用。
- 缺點:
- 存儲消耗空間大(32 個字符串,128 位)。
- 不安全(基于 MAC 地址生成 UUID 的算法會造成 MAC 地址泄露)。
- 無序(非自增)。
- 沒有具體業務含義。
- 需要解決重復 ID 問題(當機器時間不對的情況下,可能導致會產生重復 ID)。
2)Snowflake(雪花算法)
- Snowflake 是 Twitter 開源的分布式 ID 生成算法。Snowflake 由 64 bit 的二進制數字組成,這 64bit 的二進制被分成了幾部分,每一部分存儲的數據都有特定的含義:

sign(1bit):符號位(標識正負),始終為 0,代表生成的 ID 為正數。timestamp(41 bits):一共 41 位,用來表示時間戳,單位是毫秒,可以支撐 2 41 毫秒(約 69 年)。datacenter id+worker id(10 bits):一般來說,前 5 位表示機房 ID,后 5 位表示機器 ID(實際項目中可以根據實際情況調整),這樣就可以區分不同集群/機房的節點。sequence(12 bits):一共 12 位,用來表示序列號。 序列號為自增值,代表單臺機器每毫秒能夠產生的最大 ID 數(212 = 4096),也就是說單臺機器每毫秒最多可以生成 4096 個 唯一 ID。
- 優點:生成速度比較快、生成的 ID 有序遞增、比較靈活(可以對 Snowflake 算法進行簡單的改造比如加入業務 ID)。
- 缺點:
- 需要解決重復 ID 問題(ID 生成依賴時間,在獲取時間的時候,可能會出現時間回撥的問題,也就是服務器上的時間突然倒退到之前的時間,進而導致會產生重復 ID)。
- 依賴機器 ID 對分布式環境不友好(當需要自動啟停或增減機器時,固定的機器 ID 可能不夠靈活)。
3)Redis自增
- 為了增加ID的安全性,我們可以不直接使用Redis自增的數值,而是拼接一些其它信息:

- 符號位:1bit,永遠為0。
- 時間戳:31bit,以秒為單位,可以使用69年。
- 序列號:32bit,秒內的計數器,支持每秒產生232個不同ID。
鎖
悲觀鎖
- 悲觀鎖總是假設最壞的情況,認為共享資源每次被訪問的時候就會出現問題(比如共享數據被修改),所以每次在獲取資源操作的時候都會上鎖,這樣其他線程想拿到這個資源就會阻塞直到鎖被上一個持有者釋放。
- 也就是說,共享資源每次只給一個線程使用,其它線程阻塞,用完后再把資源轉讓給其它線程。
- 對于單機多線程來說,在 Java 中,我們通常使用
ReentrantLock類、synchronized關鍵字這類 JDK 自帶的本地鎖來控制一個 JVM 進程內的多個線程對本地共享資源的訪問。
樂觀鎖
- 樂觀鎖總是假設最好的情況,認為共享資源每次被訪問的時候不會出現問題,線程可以不停地執行,無需加鎖也無需等待,只是在提交修改的時候去驗證對應的資源是否被其它線程修改了(具體方法可以使用版本號機制或 CAS 算法)。
- 版本號機制
- 一般是在數據表中加上一個數據版本號 version 字段,表示數據被修改的次數。
- 當數據被修改時,version 值會+1。當線程 A 要更新數據值時,在讀取數據的同時也會讀取 version 值,在提交更新時,若剛才讀取到的 version 值為當前數據庫中的 version 值相等時才更新,否則重試更新操作,直到更新成功。
- CAS 算法
- CAS 的全稱是 Compare And Swap(比較與交換) ,用于實現樂觀鎖,被廣泛應用于各大框架中。CAS 的思想很簡單,就是用一個預期值和要更新的變量值進行比較,兩值相等才會進行更新。
- CAS 是一個原子操作,底層依賴于一條 CPU 的原子指令。
- 當多個線程同時使用 CAS 操作一個變量時,只有一個會勝出,并成功更新,其余均會失敗,但失敗的線程并不會被掛起,僅是被告知失敗,并且允許再次嘗試,當然也允許失敗的線程放棄操作。
- 問題:
- "ABA"問題:如果一個變量 V 初次讀取的時候是 A 值,并且在準備賦值的時候檢查到它仍然是 A 值,那我們就能說明它的值沒有被其他線程修改過了嗎?很明顯是不能的,因為在這段時間它的值可能被改為其他值,然后又改回 A,那 CAS 操作就會誤認為它從來沒有被修改過。
- 循環時間長開銷大:CAS 經常會用到自旋操作來進行重試,也就是不成功就一直循環執行直到成功。如果長時間不成功,會給 CPU 帶來非常大的執行開銷。
- 只能保證一個共享變量的原子操作:CAS 操作僅能對單個共享變量有效。當需要操作多個共享變量時,CAS 就顯得無能為力。
分布式鎖
- 通過加
synchronized鎖可以解決在單機情況下的一人一單等安全問題,但是在集群模式下就不行了。 - 分布式系統下,不同的服務/客戶端通常運行在獨立的 JVM 進程上。如果多個 JVM 進程共享同一份資源的話,使用本地鎖就沒辦法實現資源的互斥訪問了。于是,分布式鎖就誕生了。
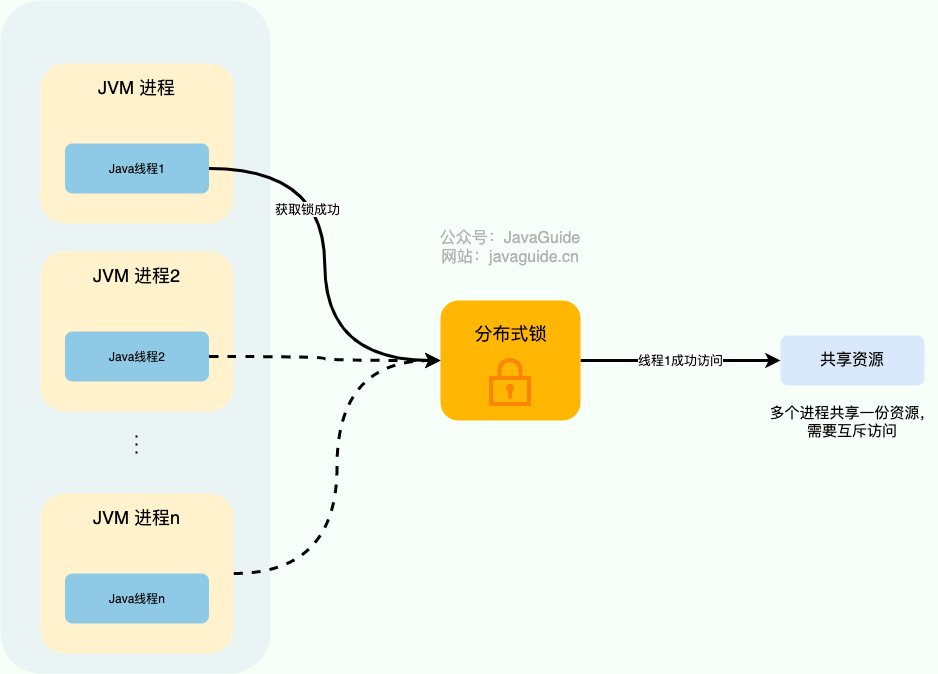
分布式鎖應滿足的需求
- 一個最基本的分布式鎖需要滿足:
- 互斥:任意一個時刻,鎖只能被一個線程持有。
- 高可用:鎖服務是高可用的,當一個鎖服務出現問題,能夠自動切換到另外一個鎖服務。并且,即使客戶端的釋放鎖的代碼邏輯出現問題,鎖最終一定還是會被釋放,不會影響其他線程對共享資源的訪問。這一般是通過超時機制實現的。
- 可重入:一個節點獲取了鎖之后,還可以再次獲取鎖。
- 除了上面這三個基本條件之外,一個好的分布式鎖還需要滿足下面這些條件:
- 高性能:獲取和釋放鎖的操作應該快速完成,并且不應該對整個系統的性能造成過大影響。
- 非阻塞:如果獲取不到鎖,不能無限期等待,避免對系統正常運行造成影響。
分布式鎖實現方案
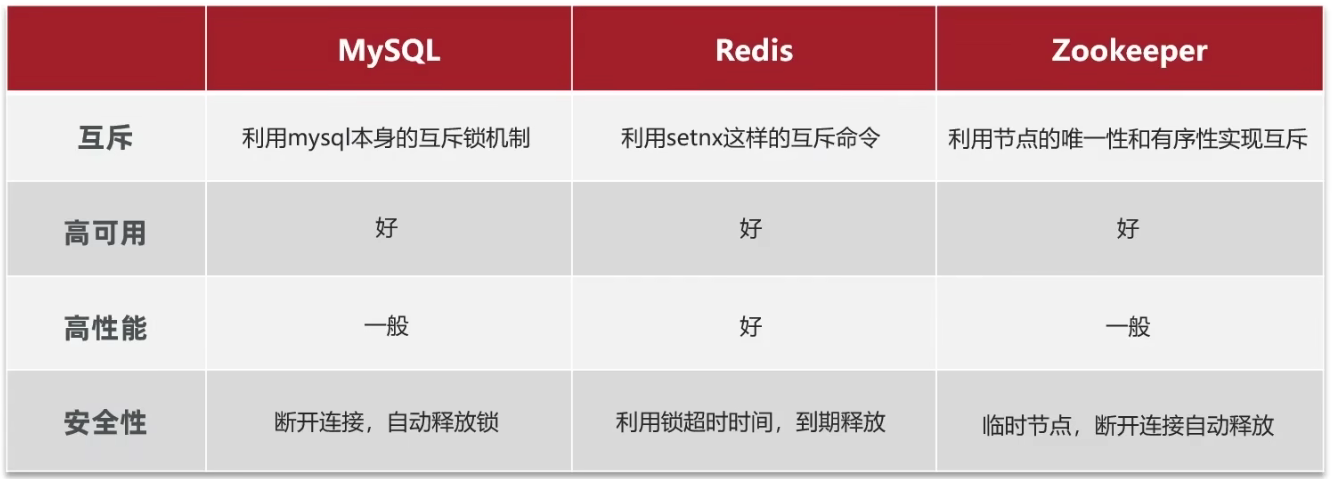
基于 Redis 實現分布式鎖
- 在 Redis 中,
SETNX命令是可以幫助我們實現互斥。SETNX即SET if Not eXists(對應 Java 中的setIfAbsent方法),如果 key 不存在的話,才會設置 key 的值。如果 key 已經存在, SETNX 啥也不做。 - 為了避免鎖無法被釋放,我們可以給這個 key(也就是鎖) 設置一個過期時間 。一定要保證設置指定 key 的值和過期時間是一個原子操作!!! 不然的話,依然可能會出現鎖無法被釋放的問題。
127.0.0.1:6379> SET lockKey uniqueValue EX 3 NX OK - 釋放鎖的話,直接通過
DEL命令刪除對應的 key 即可。 - 為了防止誤刪其他的鎖,這里我們建議使用 Lua 腳本通過 key 對應的 value(唯一值)來判斷。選用 Lua 腳本是為了保證解鎖操作的原子性。因為 Redis 在執行 Lua 腳本時,可以以原子性的方式執行,從而保證了鎖釋放操作的原子性。
// 釋放鎖時,先比較鎖對應的 value 值是否相等,避免鎖的誤釋放 if redis.call("get",KEYS[1]) == ARGV[1] thenreturn redis.call("del",KEYS[1]) elsereturn 0 end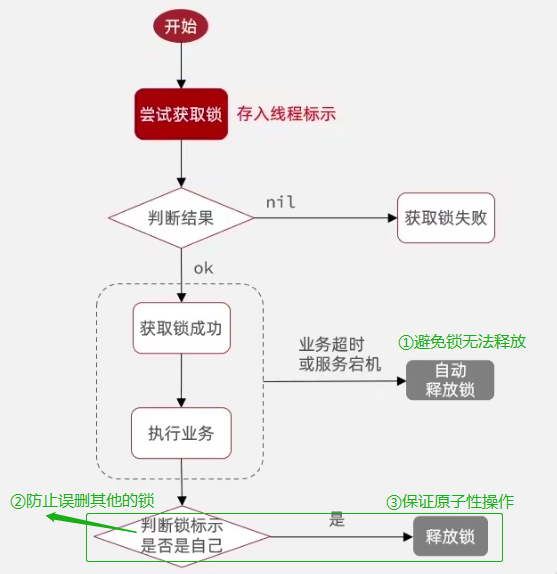
基于 Redis 的分布式鎖存在的問題
- 不可重入
- 同一個線程無法多次獲取同一把鎖。
- 解決:利用hash結構,記錄線程標示和重入次數。
- 不可重試
- 獲取鎖只嘗試一次就返回false,沒有重試機制。
- 解決:利用信號量控制鎖重試
- 超時釋放
- 雖然可以避免死鎖,但如果業務執行耗時較長,也會導致鎖釋放,存在安全隱患。
- 解決:Watch Dog
- 主從一致性
- 如果 Redis 提供了主從集群,主從同步存在延遲,當主宕機時,如果并未同步主中的鎖數據,則會出現鎖失效。
- 解決:Redisson 的 multiLock,多個獨立的 Redis 節點,必須在所有節點都獲取重入鎖,才算獲取鎖成功。
Redisson
- Redisson 是一個開源的 Java 語言 Redis 客戶端,提供了很多開箱即用的功能,不僅僅包括多種分布式鎖的實現。并且,Redisson 還支持 Redis 單機、Redis Sentinel、Redis Cluster 等多種部署架構。
- Redisson 中的分布式鎖自帶自動續期機制,使用起來非常簡單,原理也比較簡單,其提供了一個專門用來監控和續期鎖的 Watch Dog( 看門狗),如果操作共享資源的線程還未執行完成的話,Watch Dog 會不斷地延長鎖的過期時間,進而保證鎖不會因為超時而被釋放。
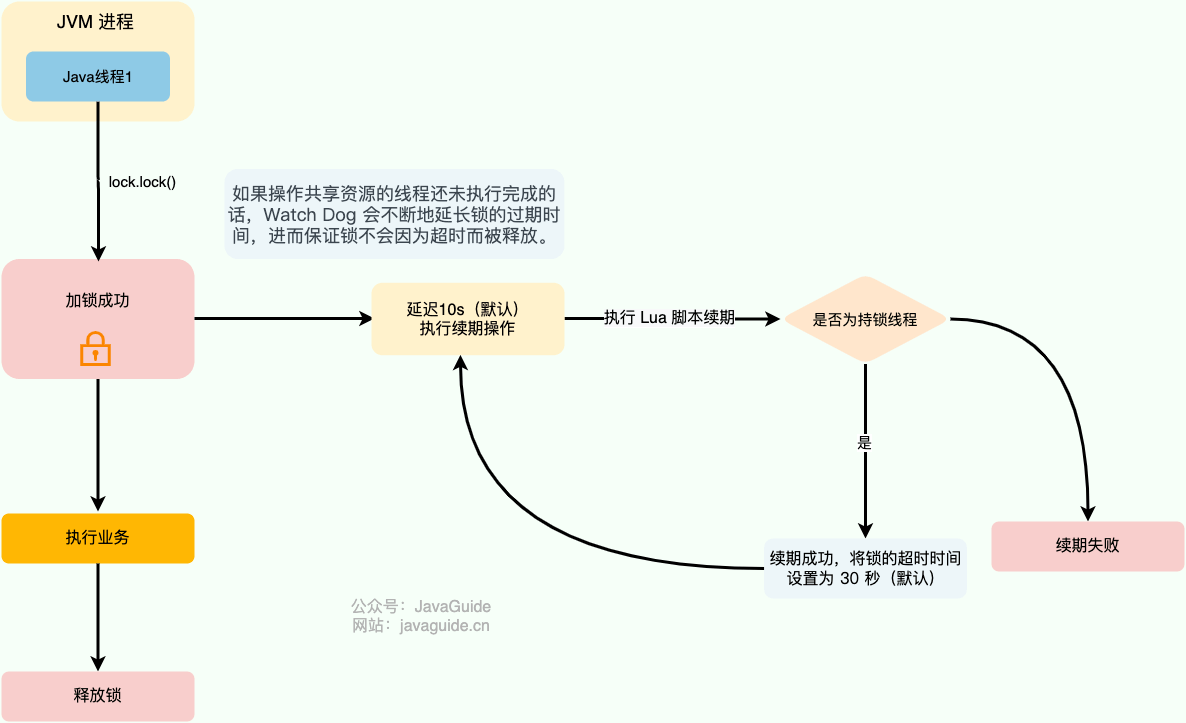
- 默認情況下,每過 10 秒,看門狗就會執行續期操作,將鎖的超時時間設置為 30 秒。看門狗續期前也會先判斷是否需要執行續期操作,需要才會執行續期,否則取消續期操作。



)



)
連接mysql數據庫,寫入計算結果)

)








