主要參考學習資料:
《動手學深度學習》阿斯頓·張 等 著
【動手學深度學習 PyTorch版】嗶哩嗶哩@跟李沐學AI
目錄
- 目標檢測
- 錨框
- 交并比(IoU)
- 錨框標注
- 真實邊界框分配
- 偏移量計算
- 損失函數
- 非極大值抑制預測
- 多尺度目標檢測
- 單發多框檢測(SSD)
- 類別預測層
- 邊界框預測層
- 區域卷積神經網絡(R-CNN)
- R-CNN
- 選擇性搜索
- 支持向量機
- Fast R-CNN
- 興趣區域匯聚層
- Faster R-CNN
- YOLO
- 語義分割
- 轉置卷積
- 基本操作
- 填充、步幅和多通道
- 全卷積網絡(FCN)
- 風格遷移
在卷積神經網絡和現代卷積神經網絡兩章中,我們只介紹了圖像分類模型。由于深度神經網絡可以有效地表示多個層次的圖像,現今其已被成功應用于更多計算機視覺任務。本章將討論目標檢測、語義分割和風格遷移三種任務,在有限的篇幅內,重點介紹目標檢測部分基礎模型的設計思路,簡要介紹語義分割和風格遷移的基本原理。
目標檢測
圖像分類假定圖像中只有一個目標,我們只關注如何識別其類別。然而,很多時候圖像中有多個我們感興趣的目標,我們不僅想知道它們的類別,還想得到它們在圖像中的具體位置,這類任務稱為目標檢測。
在目標檢測中,我們通常使用邊界框來描述對象的空間位置。邊界框是矩形的,由左上角以及右下角的 x x x坐標或 y y y坐標確定,也可用邊界框中心的軸坐標 ( x , y ) (x,y) (x,y)以及框的寬度和高度表示。
下圖中狗和貓的邊界框左上角以及右下角的坐標分別為 [ ( 60 , 45 ) , ( 378 , 516 ) ] [(60,45),(378,516)] [(60,45),(378,516)]和 [ ( 400 , 112 ) , ( 655 , 493 ) ] [(400,112),(655,493)] [(400,112),(655,493)]
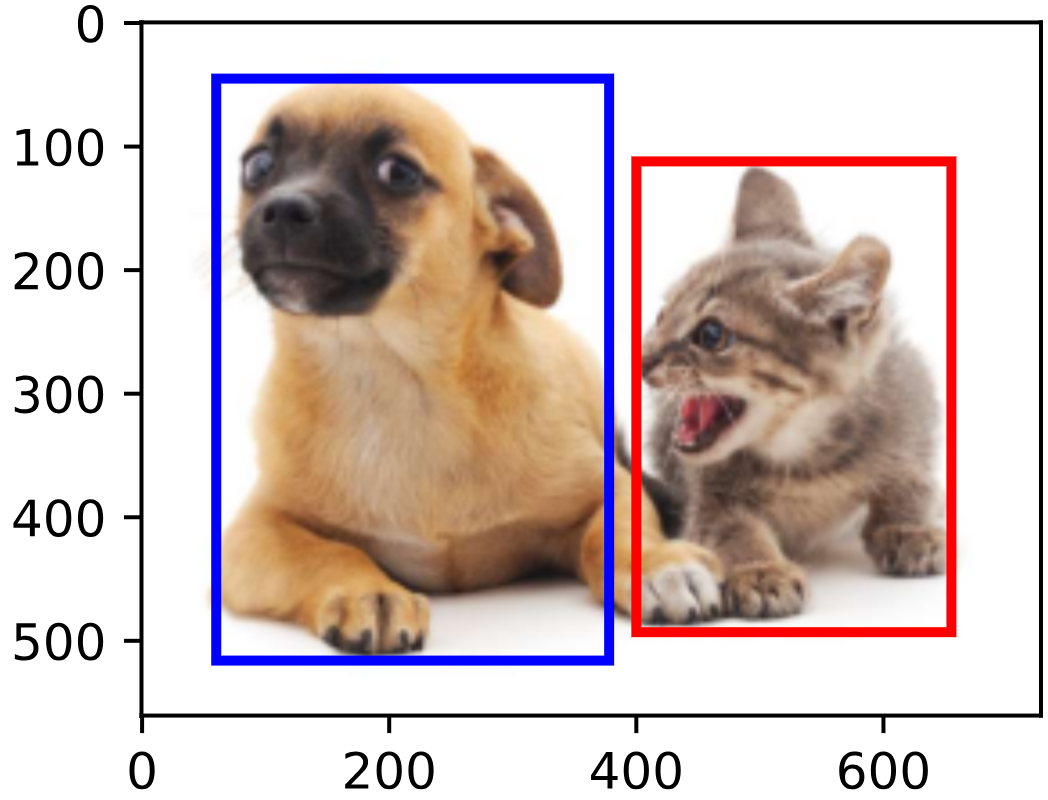
錨框
目標檢測算法通常會在輸入圖像中抽樣大量的區域,然后判斷這些區域中是否包含我們感興趣的目標,并調整區域邊界,從而更準確地預測目標的真實邊界框。其中一種方法是以每個像素為中心,生成多個縮放比和寬高比不同的邊界框,這些邊界框被稱為錨框(先驗框)。
基于錨框的目標檢測算法流程如下:
- 提出多個錨框區域;
- 預測每個錨框里是否含有關注的物體;
- 如果是,預測從這個錨框到真實邊緣框的偏移。
假設輸入圖像的高度為 h h h,寬度為 w w w。對于縮放比為 s ∈ ( 0 , 1 ] s\in(0,1] s∈(0,1]、寬高比為 r > 0 r>0 r>0的錨框,其寬度和高度分別為 h s r hs\sqrt r hsr?和 h s / r hs/\sqrt r hs/r?。我們只需設置一系列縮放比取值 s 1 , ? , s n s_1,\cdots,s_n s1?,?,sn?和寬高比取值 r 1 , ? , r m r_1,\cdots,r_m r1?,?,rm?,就能以每個像素為中心生成多個不同形狀的錨框。
但是如果將縮放比和寬高比的取值兩兩組合,將會在輸入圖像中生成 w ? h ? n ? m w\cdot h\cdot n\cdot m w?h?n?m個錨框,很容易導致過高的計算復雜度,在實踐中,我們只考慮包含 s 1 s_1 s1?或 r 1 r_1 r1?的組合
( s 1 , r 1 ) , ( s 1 , r 2 ) , ? , ( s 1 , r m ) , ( s 2 , r 1 ) , ( s 3 , r 1 ) , ? , ( s n , r 1 ) (s_1,r_1),(s_1,r_2),\cdots,(s_1,r_m),(s_2,r_1),(s_3,r_1),\cdots,(s_n,r_1) (s1?,r1?),(s1?,r2?),?,(s1?,rm?),(s2?,r1?),(s3?,r1?),?,(sn?,r1?)
此時對于整個輸入圖像將生成 w h ( n + m ? 1 ) wh(n+m-1) wh(n+m?1)個錨框。
下圖以 ( 250 , 250 ) (250,250) (250,250)為中心生成了一系列不同縮放比和寬高比的錨框:
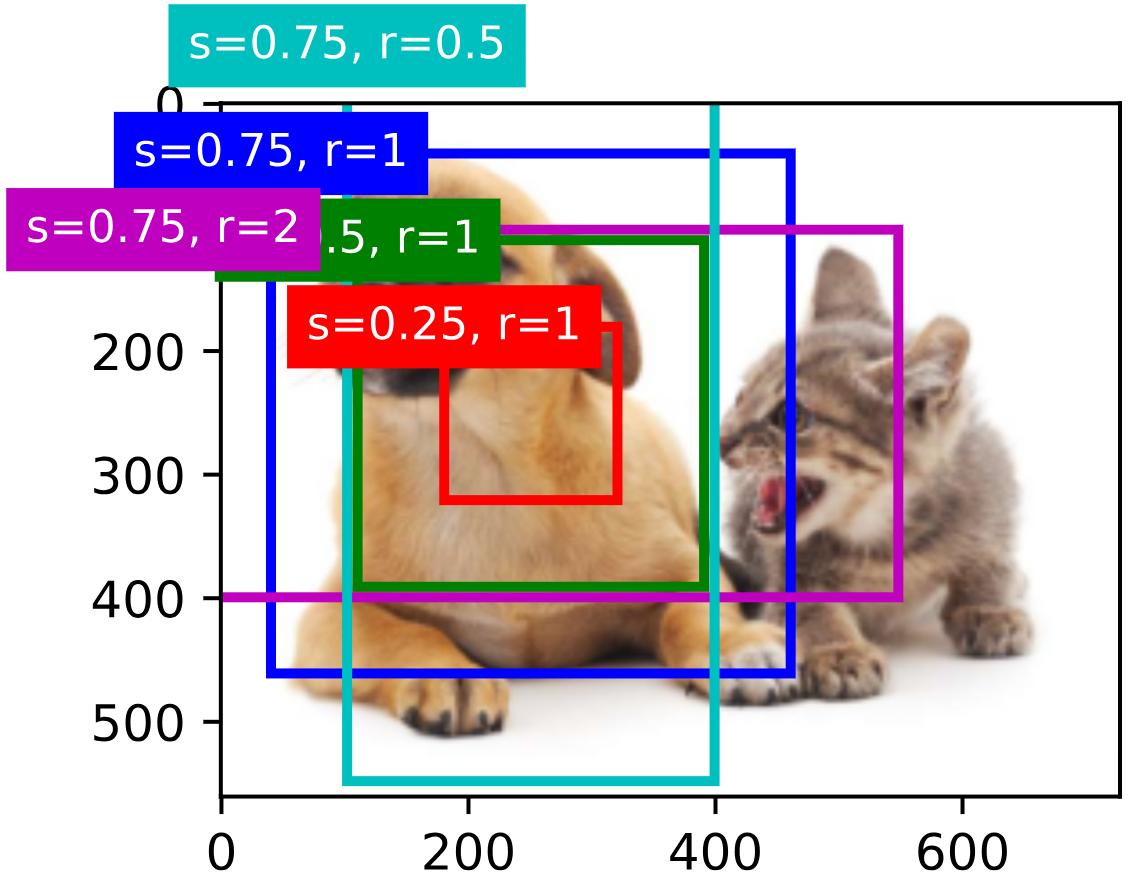
交并比(IoU)
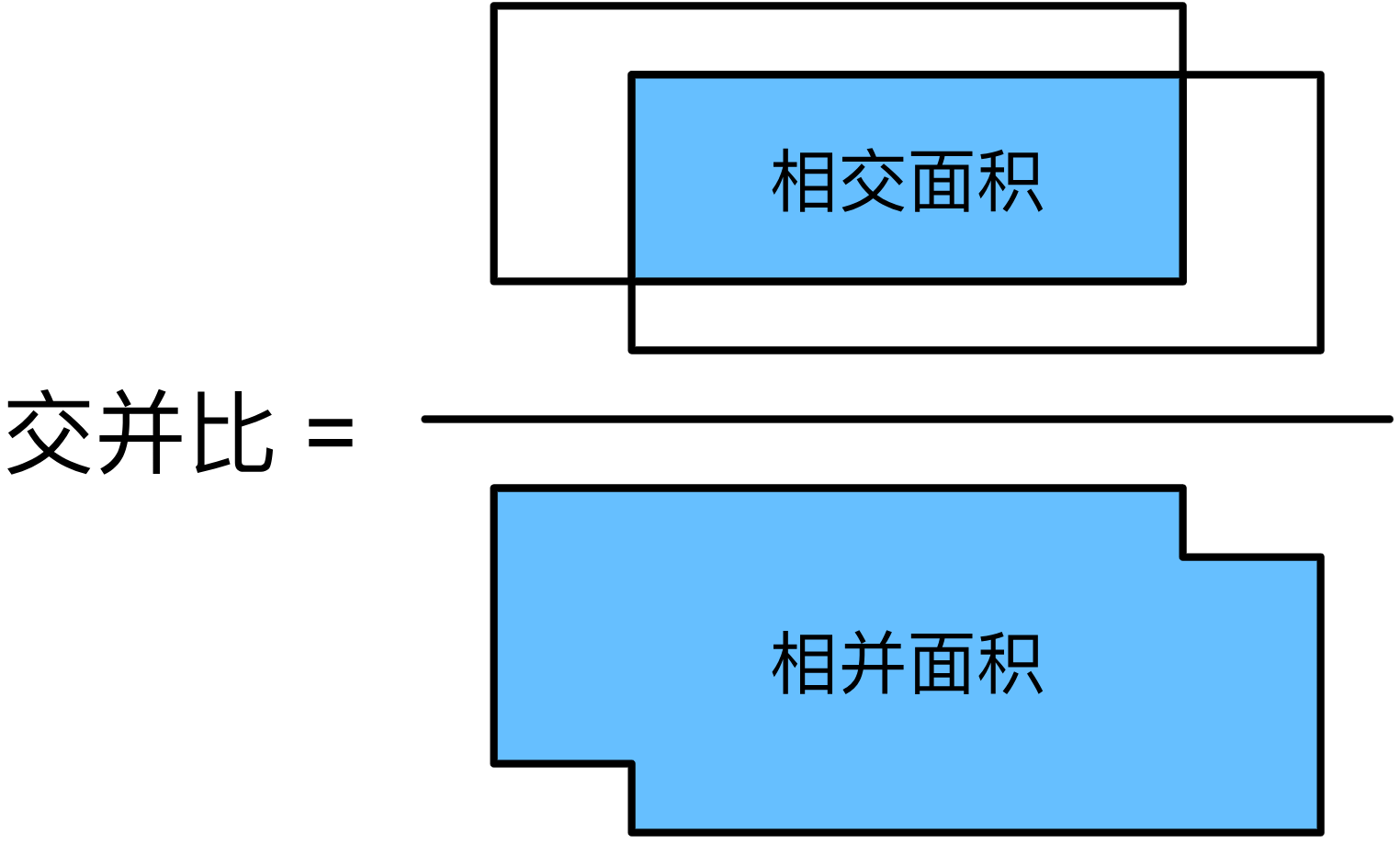
對于生成的錨框,如果已知目標的真實邊界框,我們需要度量二者之間的相似性。杰卡德指數可以度量兩個集合的相似性,給定集合 A A A和 B B B,它們的杰卡德指數是它們交集的大小除以它們并集的大小
J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ J(A,B)=\frac{|A\cap B|}{|A\cup B|} J(A,B)=∣A∪B∣∣A∩B∣?
通過將任何邊界框的像素區域視為像素的集合,我們可以通過其像素集的杰卡德指數來度量兩個邊界框的相似性。通常兩個邊界框的杰卡德指數被稱為交并比(IoU),即兩個邊界框相交面積與相并面積之比。交并比的范圍在 0 0 0到 1 1 1之間,交并比越大,兩個邊界框重合面積占比越大,相似性越高。
錨框標注
在開始訓練之前,我們需要為訓練集進行標注,每個錨框都是訓練集的一個訓練樣本。樣本的標簽包括類別和偏移量。標注的流程大致如下:
- 根據IoU為每個錨框分配一個真實邊界框,或視為背景,不分配真實邊界框。
- 根據真實邊界框的分配情況為每個錨框打上類別標簽,非背景錨框被稱為正類錨框,并且被打上其對應真實邊界框的類別,而背景錨框被稱為負類錨框。
- 對于非背景錨框,計算并標注其與對應真實邊界框之間的偏移量。
真實邊界框分配
下面介紹分配真實邊界框的一種方法。
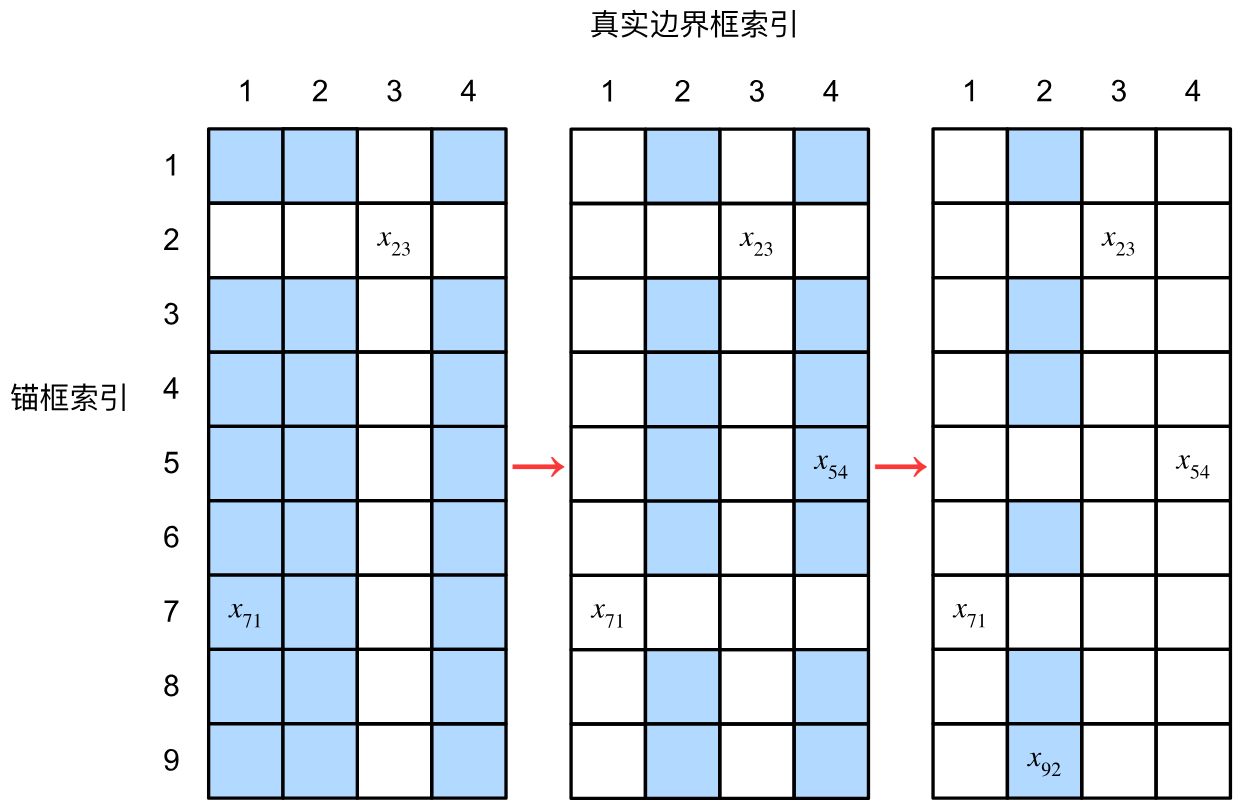
給定圖像,假設錨框為 A 1 , A 2 , ? , A n a A_1,A_2,\cdots,A_{n_a} A1?,A2?,?,Ana??,真實邊界框為 B 1 , B 2 , ? , B n b B_1,B_2,\cdots,B_{n_b} B1?,B2?,?,Bnb??,其中 n a ? n b n_a\geqslant n_b na??nb?,則分配真實邊界框的步驟為:
- 遍歷并計算所有錨框與真實邊界框之間的IoU,得到一個矩陣 X ∈ R n a × n b X\in\mathbb R^{n_a\times n_b} X∈Rna?×nb?,其中第 i i i行、第 j j j列的元素 x i j x_{ij} xij?是錨框 A i A_i Ai?和真實邊界框 B j B_j Bj?的IoU。
- 保證 n b n_b nb?個真實邊界框都至少被分配到一個錨框。
- 在矩陣 X X X中找到最大的元素,其行索引和列索引記為 i 1 i_1 i1?和 j 1 j_1 j1?,然后將真實邊界框 B j 1 B_{j_1} Bj1??分配給錨框 A i 1 A_{i_1} Ai1??,并丟棄矩陣中第 i 1 i_1 i1?行和第 j 1 j_1 j1?列中的所有元素(防止錨框和真實邊界框被重復分配)。
- 在矩陣 X X X的剩余元素中找到最大的元素,其行索引和列索引記為 i 2 i_2 i2?和 j 2 j_2 j2?,然后采取同樣的操作。
- 延續上述操作,直至矩陣 X X X中的所有元素都被丟棄,此時 n b n_b nb?個真實邊界框都被分配到了一個錨框。
- 遍歷并分配剩余的 n a ? n b n_a-n_b na??nb?個錨框。對于錨框 A i A_i Ai?,在矩陣 X X X的第 i i i行中找到與 A i A_i Ai?的IoU最大的真實邊界框 B j B_j Bj?,如果這個IoU大于預定義的閾值,則將 B j B_j Bj?分配給 A i A_i Ai?,否則將 A i A_i Ai?視為背景。
下圖展示了第二大步的操作,藍色格子為剩余的元素,標記出的元素為被分配的錨框-真實邊界框:
偏移量計算
給定錨框 A A A和真實邊界框 B B B,它們的中心坐標分別為 ( x a , y a ) (x_a,y_a) (xa?,ya?)和 ( x b , y b ) (x_b,y_b) (xb?,yb?),寬度分別為 w a w_a wa?和 w b w_b wb?,高度分別為 h a h_a ha?和 h b h_b hb?,則 A A A的偏移量 ( Δ x , Δ y , Δ w , Δ h ) (\Delta x,\Delta y,\Delta w,\Delta h) (Δx,Δy,Δw,Δh)為
( x b ? x a w a ? μ x σ x , y b ? y a h a ? μ y σ y , log ? w b w a ? μ w σ w , log ? h b h a ? μ h σ h , ) \left(\frac{\displaystyle\frac{x_b-x_a}{w_a}-\mu_x}{\sigma_x},\frac{\displaystyle\frac{y_b-y_a}{h_a}-\mu_y}{\sigma_y},\frac{\log\displaystyle\frac{w_b}{w_a}-\mu_w}{\sigma_w},\frac{\log\displaystyle\frac{h_b}{h_a}-\mu_h}{\sigma_h},\right) ?σx?wa?xb??xa???μx??,σy?ha?yb??ya???μy??,σw?logwa?wb???μw??,σh?logha?hb???μh??, ?
四個數值分別衡量 A A A與 B B B的橫坐標偏移、縱坐標偏移、寬度比和高度比。 μ \mu μ和 σ \sigma σ用于規范化,其默認值為 μ x = μ y = μ w = μ h = 0 \mu_x=\mu_y=\mu_w=\mu_h=0 μx?=μy?=μw?=μh?=0, σ x = σ y = 0.1 \sigma_x=\sigma_y=0.1 σx?=σy?=0.1, σ w = σ h = 0.2 \sigma_w=\sigma_h=0.2 σw?=σh?=0.2。
損失函數
錨框的損失函數 L L L由類別標簽的分類損失 L c l s L_{cls} Lcls?和偏移量標簽的回歸損失 L r e g L_{reg} Lreg?組成,可計算如下
L = L c l s + λ L r e g L=L_{cls}+\lambda L_{reg} L=Lcls?+λLreg?
分類損失可使用交叉熵損失計算,回歸損失可使用平滑L1損失計算。
非極大值抑制預測
在預測時,我們先為圖像生成多個錨框,再為這些錨框一一預測類別。如果錨框被預測為非背景錨框,則進一步計算它的偏移量,并根據偏移量對錨框進行偏移得到真正的預測框。對于錨框 A A A的初始位置和大小 ( x a , y a , w a , h a ) (x_a,y_a,w_a,h_a) (xa?,ya?,wa?,ha?)及其偏移量 ( Δ x , Δ y , Δ w , Δ h ) (\Delta x,\Delta y,\Delta w,\Delta h) (Δx,Δy,Δw,Δh),調整后的預測框位置和大小計算如下
x = x a + w a Δ x y = y a + h a Δ y w = w a e Δ w h = h a e Δ h \begin{split} x&=x_a+w_a\Delta x\\ y&=y_a+h_a\Delta y\\ w&=w_ae^{\Delta w}\\ h&=h_ae^{\Delta h} \end{split} xywh?=xa?+wa?Δx=ya?+ha?Δy=wa?eΔw=ha?eΔh?
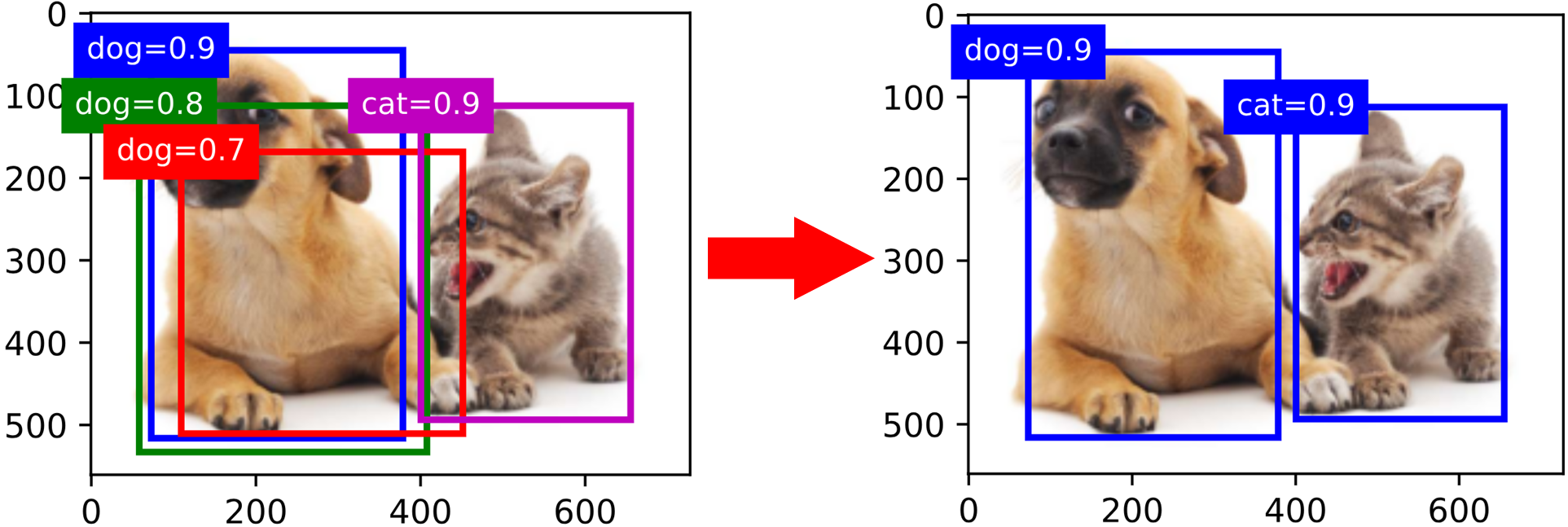
最終,模型可能會輸出許多相似的具有明顯重疊的預測框,它們都圍繞同一個目標。為了簡化輸出,我們可以使用非極大值抑制合并屬于同一目標的相似的預測框,其步驟如下:
- 對每個預測框 B B B,取其對每個類別預測概率的最大值 p p p作為其置信度,該概率對應的類別即為預測類別。
- 將所有預測框根據置信度按降序排序,生成列表 L L L。
- 從 L L L中選取置信度最高的預測框 B 1 B_1 B1?作為基準,將所有與 B 1 B_1 B1?的IoU超過預定閾值 ? \epsilon ?的預測框從 L L L中移除,即移除了與 B 1 B_1 B1?相似但置信度低于 B 1 B_1 B1?的預測框。
- 從 L L L中選取置信度次高的預測框 B 2 B_2 B2?作為基準,然后采取同樣的操作。
- 重復上述過程,直至 L L L中剩余的預測框都曾被選為基準,此時 L L L中任意一對預測框的IoU都小于閾值 ? \epsilon ?,即沒有一對預測框過于相似。
- 輸出 L L L中的所有預測框。
下圖展示了非極大值抑制的操作效果:
多尺度目標檢測
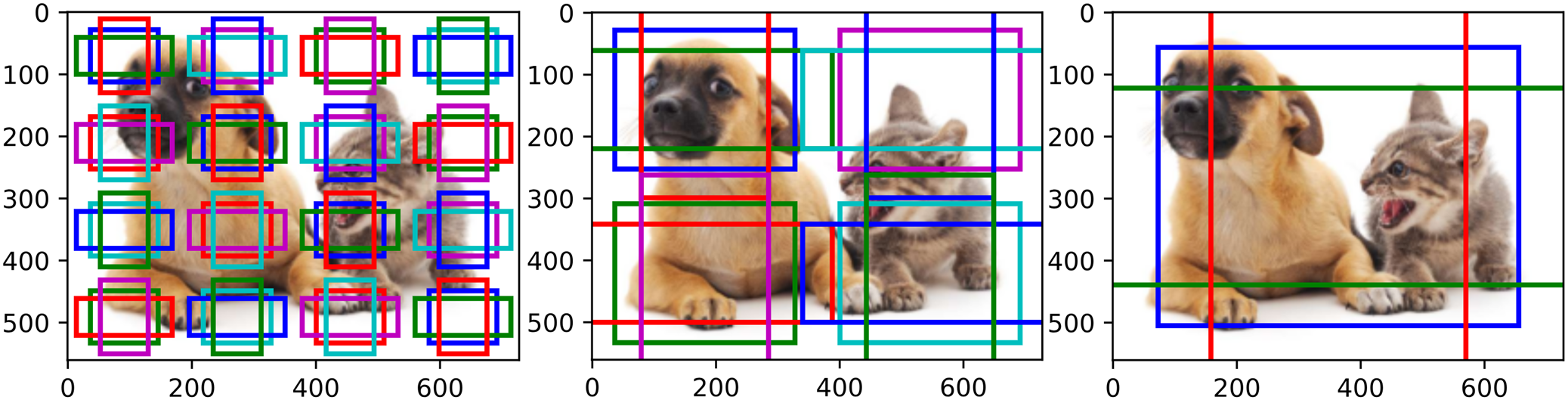
即使我們已經縮減了錨框縮放比和高寬比的組合,但是為每個像素都生成錨框仍會導致過大的計算量。一個進一步減少圖像上錨框數量的方法是多尺度錨框。
多尺度錨框考慮到,在不同尺度下,較小的目標相對于較大的目標在圖像上出現的可能性更為多樣,例如在一張 2 × 2 2\times2 2×2像素的圖像中, 1 × 1 1\times1 1×1像素、 1 × 2 1\times2 1×2像素和 2 × 2 2\times2 2×2像素的目標可以分別以 4 4 4種、 2 2 2種和 1 1 1種可能的方式出現。因此,當使用較小的錨框檢測較小的目標時,我們可以抽樣較多的取區域,而對于較大的目標,我們可以抽樣較少的區域。
一種控制不同尺度抽樣數量的方法是對于不同的尺度,根據尺度的大小在圖像上選取一系列均勻分布的像素點作為錨框中心,并生成該尺度下一系列高寬比的錨框。
下圖分別展示了尺度 s s s為 0.15 0.15 0.15、 0.4 0.4 0.4和 0.8 0.8 0.8時選取的像素中心及生成的錨框:
基于卷積神經網絡的多尺度目標檢測方法通常不直接在輸入圖像上生成不同尺度的錨框,而是利用卷積層提取輸入圖像不同尺度的特征,相應的特征輸出被稱為特征圖。越靠后的卷積層輸出的特征圖的每個單元在輸入圖像上具有更大的感受野,因此不同特征圖的一個單元就對應著輸入圖像上不同尺度的錨框。
單發多框檢測(SSD)
單發多框檢測(SSD)是一種簡單、快速且被廣泛使用的目標檢測模型,其主要由一個基礎網絡塊和若干多尺度特征塊組成:
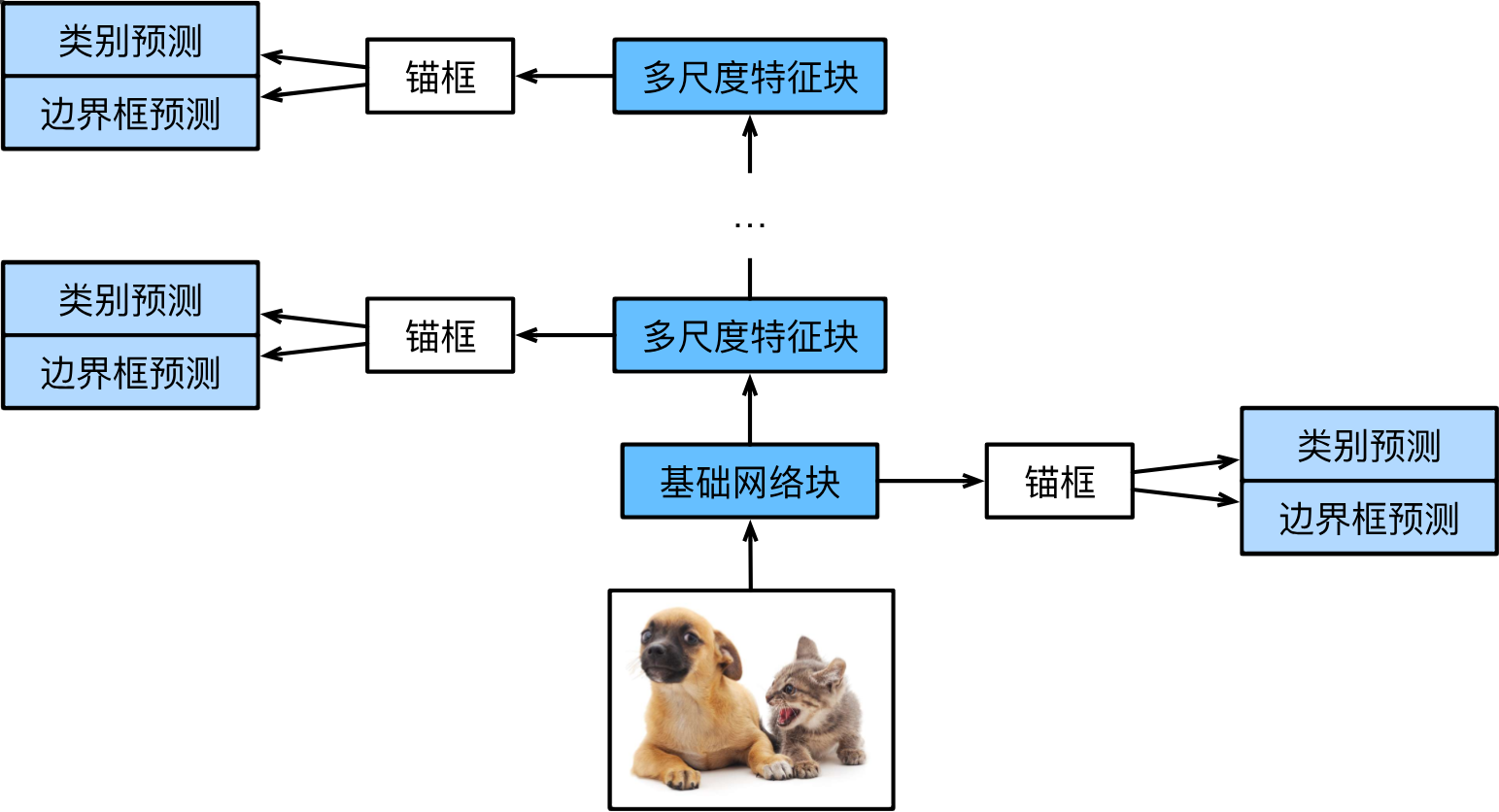
基礎網絡塊用于從輸入圖像中提取特征,因此可以使用深度卷積神經網絡(其設計者使用VGG塊,現在也常用ResNet塊)。基礎網絡塊的輸出將設置較大的高和寬,以便生成更多的錨框用于檢測較小的目標。接下來的每個多尺度特征塊將上一層提供的特征圖的高和寬縮小,使得特征圖中每個單元在輸入圖像上的感受野變大,從而檢測更大的目標。
類別預測層
假設特征圖的高和寬分別為 h h h和 w w w,以其中每個單元為中心生成 a a a個錨框,則我們需要對 h w a hwa hwa個錨框進行分類。又假設目標類別的數量為 q q q,則加上背景類別 0 0 0,錨框共有 q + 1 q+1 q+1個類別。如果使用全連接層分類很容易導致龐大的參數,因此我們使用NiN提供的思路(參見現代卷積神經網絡一章),將通道維度視為特征維度,使用卷積層分類。卷積層要求輸入和輸出的特征圖大小一致,以保證二者的坐標一一對應,而輸出特征圖上坐標 ( x , y ) (x,y) (x,y)的通道將包含以輸入特征圖上坐標 ( x , y ) (x,y) (x,y)為中心生成的 a a a個錨框關于 q + 1 q+1 q+1個類別的預測,因此輸出通道數為 a ( q + 1 ) a(q+1) a(q+1),其中第 i ( q + 1 ) + j ( 0 ? j ? q ) i(q+1)+j(0\leqslant j\leqslant q) i(q+1)+j(0?j?q)個通道代表第 i i i個錨框被預測為類別 j j j的概率。
邊界框預測層
邊界框預測層的設計與類別預測層類似,只是其輸出通道是對每個錨框的四個偏移量的預測,因此輸出通道數為 4 a 4a 4a。
簡而言之,SSD的預測過程如下:
- 輸入圖像經基礎網絡塊和一系列多尺度特征塊,得到一系列不同尺度的輸出特征圖。
- 在每個輸出特征圖上以每個單元為中心生成 a a a個錨框,并對這些錨框進行類別和偏移量預測得到一系列預測框。
- 對所有預測框進行非極大值抑制處理,得到最終輸出的預測框。
區域卷積神經網絡(R-CNN)
R-CNN及其一系列改進方法是將深度模型應用于目標檢測的另一個開創性工作。限于篇幅本節對部分方法只作簡要解釋。
R-CNN
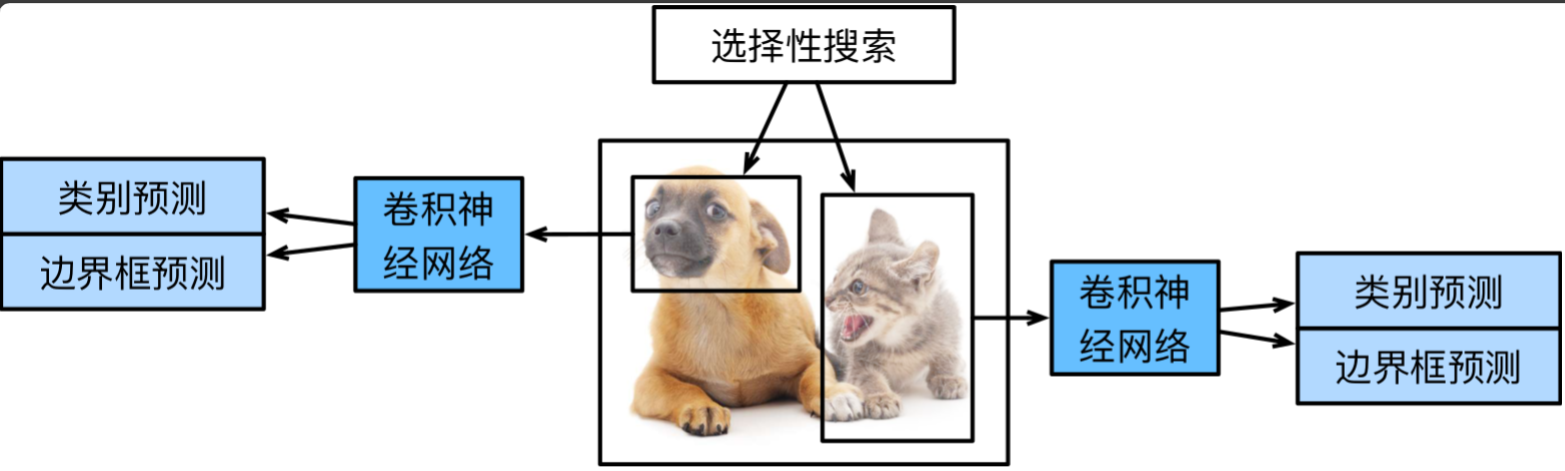
R-CNN的預測過程如下:
- 對輸入圖像使用選擇性搜索選取多個高質量的提議區域。
- 通過各向異性縮放(直接拉伸)或各向同性縮放(先填充再按比例拉伸)將提議區域縮放為固定大小。
- 選擇一個預訓練的卷積神經網絡,提取每個提議區域的特征。
- 類別預測:為每個類別(除了背景類別)訓練一個二分類支持向量機,使用每個支持向量機根據提議區域的特征判斷其是否屬于某個類別。
- 邊界框預測:使用線性回歸模型根據提議區域的特征預測每個提議區域的偏移量,進而得到每個提議區域的預測框。
- 對所有預測框進行非極大值抑制處理,得到最終輸出的預測框。
選擇性搜索
選擇性搜索是一種傳統計算機視覺算法,其目標是生成可能包含物體的候選區域。選擇性搜索的過程為:
- 使用Felzenswalb圖像分割算法(基于圖像邊緣信息)將圖像分割為超像素(像素集),得到一系列初始區域的集合 R = { r 1 , r 2 , ? , r n } R=\{r_1,r_2,\cdots,r_n\} R={r1?,r2?,?,rn?}。
- 對每個相鄰區域 ( r i , r j ) (r_i,r_j) (ri?,rj?),分別計算它們的顏色、紋理、大小和形狀相似度。
- 每次迭代選擇綜合相似度最高的區域將相鄰區域合并為新區域并更新新區域的特征,直到整張圖像成為一個區域。
- 在合并過程中記錄所有中間區域的邊界框作為候選區域,最后使用非極大值抑制移除高度重疊的冗余框(通常保留約2000個候選區域)。
支持向量機
支持向量機是一種非神經網絡的機器學習分類模型,其原理為:
- 通過核函數將數據集映射到高維空間,使之線性可分(能用一個超平面將不同類別的特征分割)。
- 找到一個超平面將兩類特征分開,并最大化支持向量(距離超平面最近的樣本點)到超平面的距離。
- 使用超平面作為決策邊界對輸入進行分類。
Fast R-CNN
R-CNN的缺點在于,其第二步的卷積神經網絡對每個提議區域獨立處理,因此對于提議區域中相互重疊的部分會重復計算。Fast R-CNN采取的改進是通過直接對整張圖像進行處理來減少不必要的計算,其步驟如下:
- 對輸入圖像使用選擇性搜索生成多個提議區域。
- 將整個輸入圖像作為卷積神經網絡的輸入提取共享特征。
- 由提議區域在共享特征上標出一系列興趣區域,使用興趣區域匯聚層將其處理為固定形狀。
- 通過全連接層進一步調整形狀后進行預測。
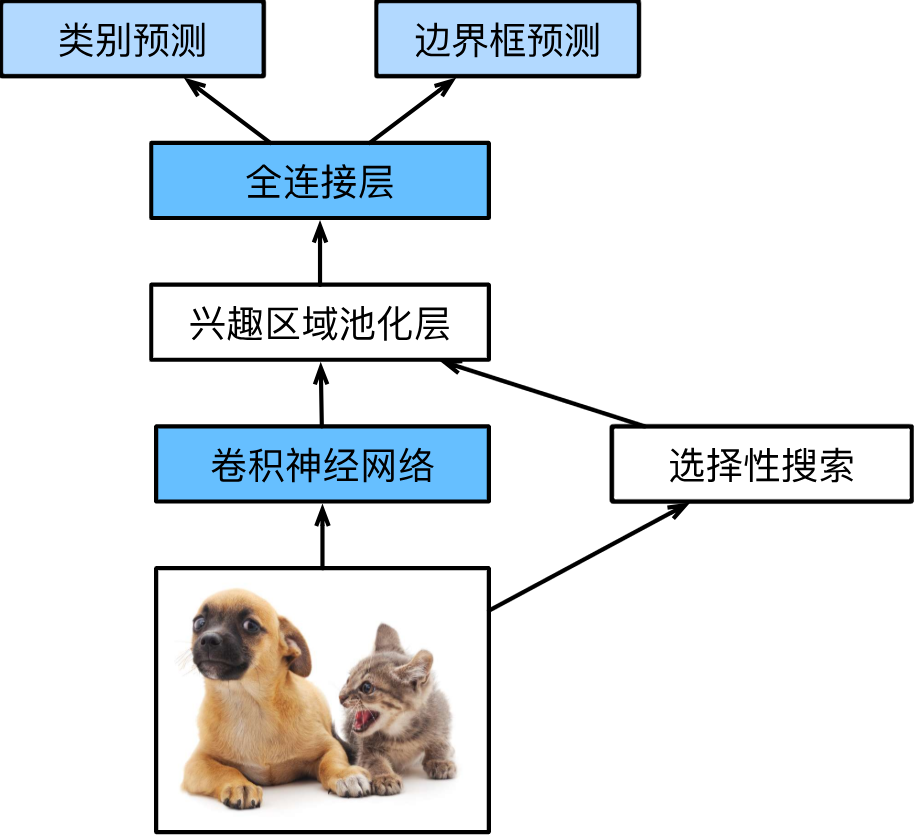
興趣區域匯聚層
興趣區域匯聚層接收整張圖像的特征和候選區域為輸入,輸出固定大小的候選區域特征,其步驟如下:
- 將候選區域按坐標比例縮放后投影到特征圖上,選出共享特征中與候選區域對應的部分。
- 將投影區域平均劃分為 m × n m\times n m×n的網格。
- 每個網格進行最大匯聚操作(取最大值作為輸出),得到 m × n m\times n m×n的固定形狀輸出。

Faster R-CNN
Faster R-CNN在Fast R-CNN的基礎上,將生成提議區域的方法由選擇性搜索替換為區域提議網絡(RPN),進一步減少了提議區域生成的數量,并確保目標檢測的精確度。
RPN本質上是一個輕量級目標檢測模型,以更低的計算成本快速對可能包含物體的區域進行粗篩(只對是否包含物體進行二元分類),相當于在仔細觀察之前先進行了一次掃視。
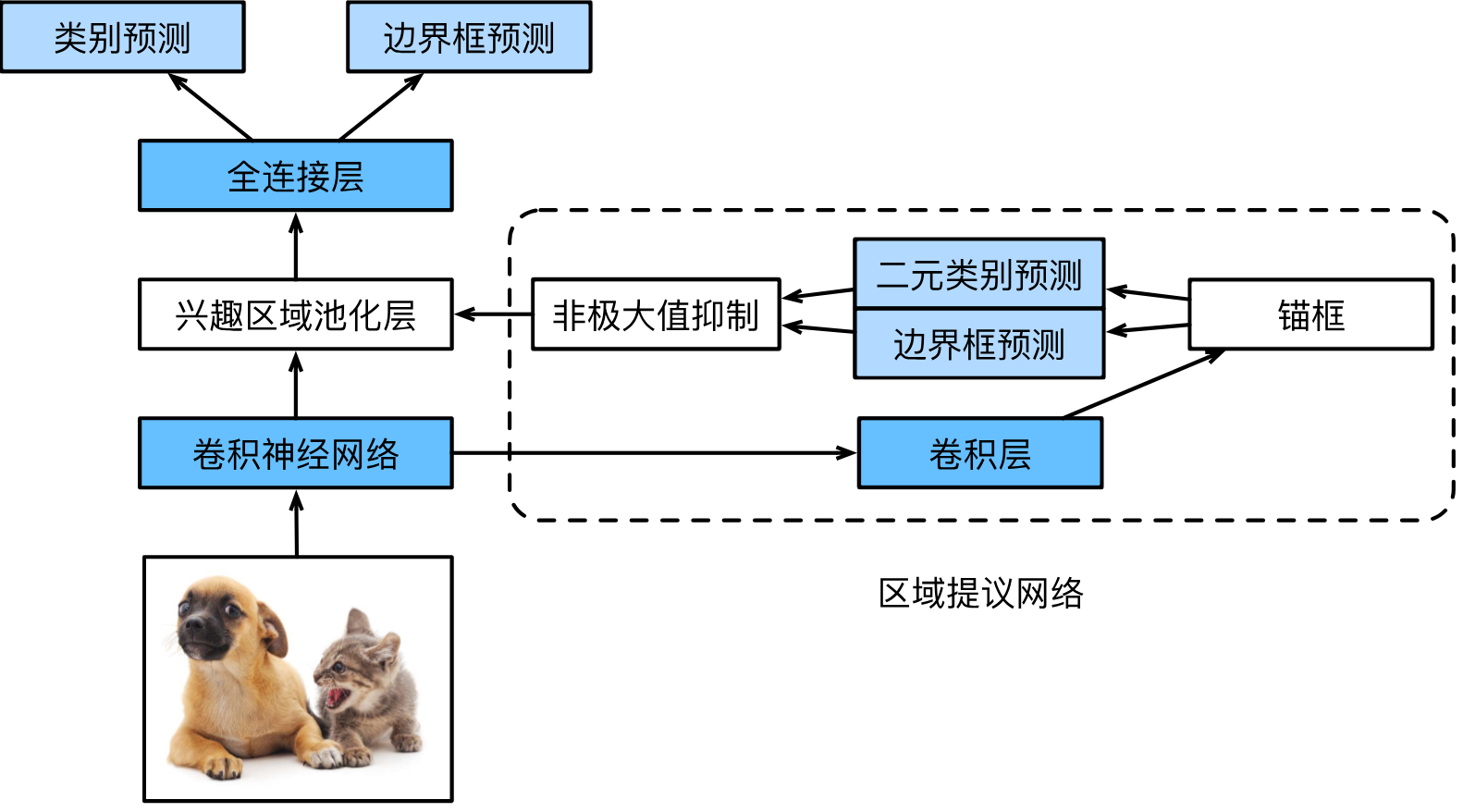
使用RPN讓R-CNN更加近似地實現了端到端的學習范式,即從輸入到輸出由統一的模型完成,所有模塊可以聯合訓練。而在R-CNN和Fast R-CNN中,選擇性搜索、支持向量機模塊脫離了神經網絡,都需要獨立訓練。除此之外,神經網絡相較其他方式可以利用GPU實現高效計算,運行在CPU的選擇性搜索算法生成2000個候選框需要約2秒,而RPN僅需約10ms。
YOLO
YOLO是目標檢測領域最具影響力的算法之一,以極快的速度和端到端的設計著稱。和R-CNN系列的雙階段檢測不同,YOLO將檢測任務視為單次回歸問題,直接在圖像上預測邊界框和類別,實現了真正的實時檢測。
YOLO的核心思路為將圖像劃分為 S × S S\times S S×S的網格,每個網格負責預測中心落在該區域的目標,直接生成 B B B個預測框的坐標和置信度,無需生成候選框。YOLO經過數年迭代,融入許多改進點,其系列已演進到YOLOv8,本文暫不深入展開。
語義分割
語義分割重點關注如何將圖像分割成屬于不同語義類別的區域。與目標檢測不同,語義分割可以識別并理解圖像中每個像素的內容,其語義區域的標注和預測是像素級的。

轉置卷積
我們目前介紹的卷積神經網絡層通常會減少下采樣輸入圖像的空間維度(高和寬),如果輸入圖像和輸出圖像的空間維度相同,在以像素級分類的語義分割中將會很方便。轉置卷積可以逆轉下采樣導致的空間維度減小,增加上采樣中間層特征圖的空間維度。
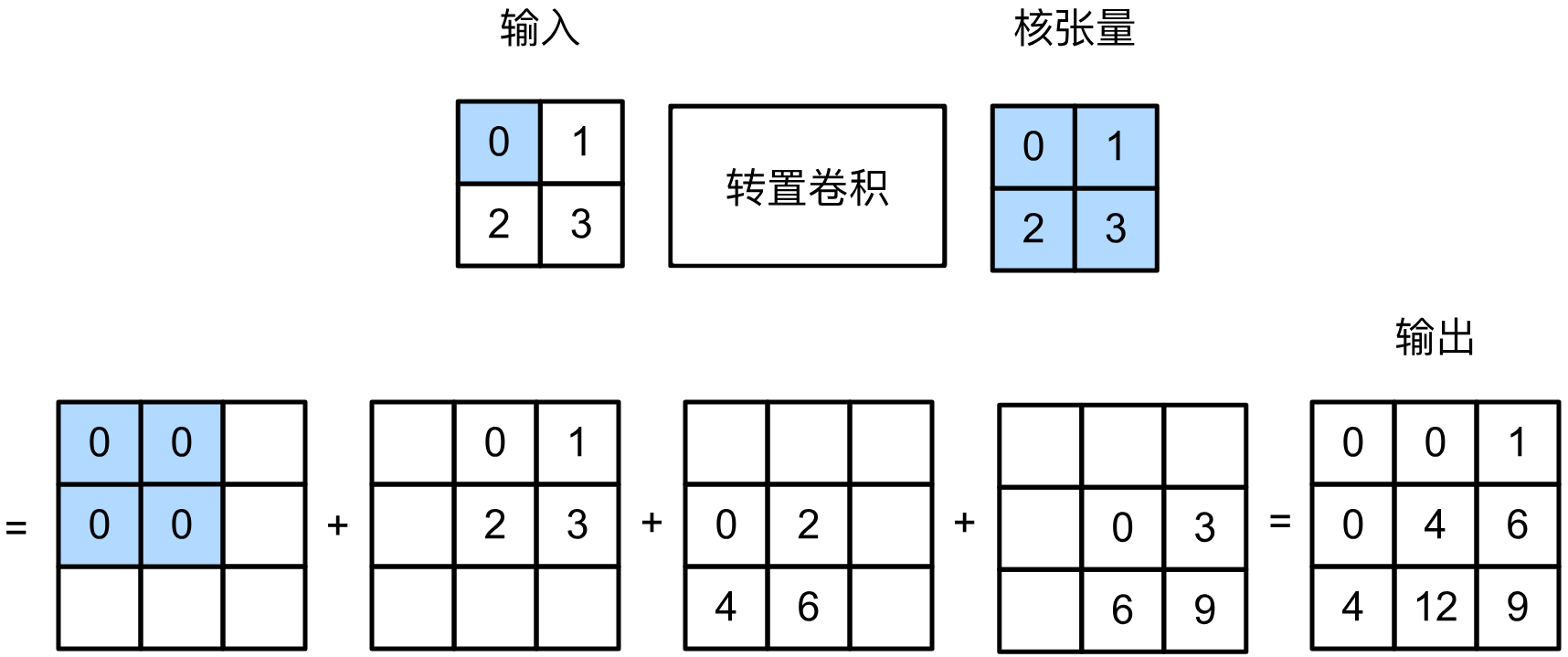
基本操作
轉置卷積可以理解為卷積的逆操作。在轉置卷積中,卷積核并不是和輸入圖像上與之形狀相同的區域做按元素乘法并求和的運算,而是每次選中一個元素,該元素分別和卷積核的每個元素做乘法得到和卷積核形狀相同的輸出。將輸入圖像中每個元素和卷積核運算的輸出按步幅疊加即可得到放大的輸出。
填充、步幅和多通道
與常規卷積不同,轉置卷積的填充被應用于輸出,且填充操作實際上是裁剪輸出邊緣對應數量的行和列,這也可以從卷積的逆操作來理解。
同樣地,步幅也是為輸出而非輸入指定的,其表示每次卷積核操作之后輸出位置的滑移量,下圖展示了步幅為2的轉置卷積:
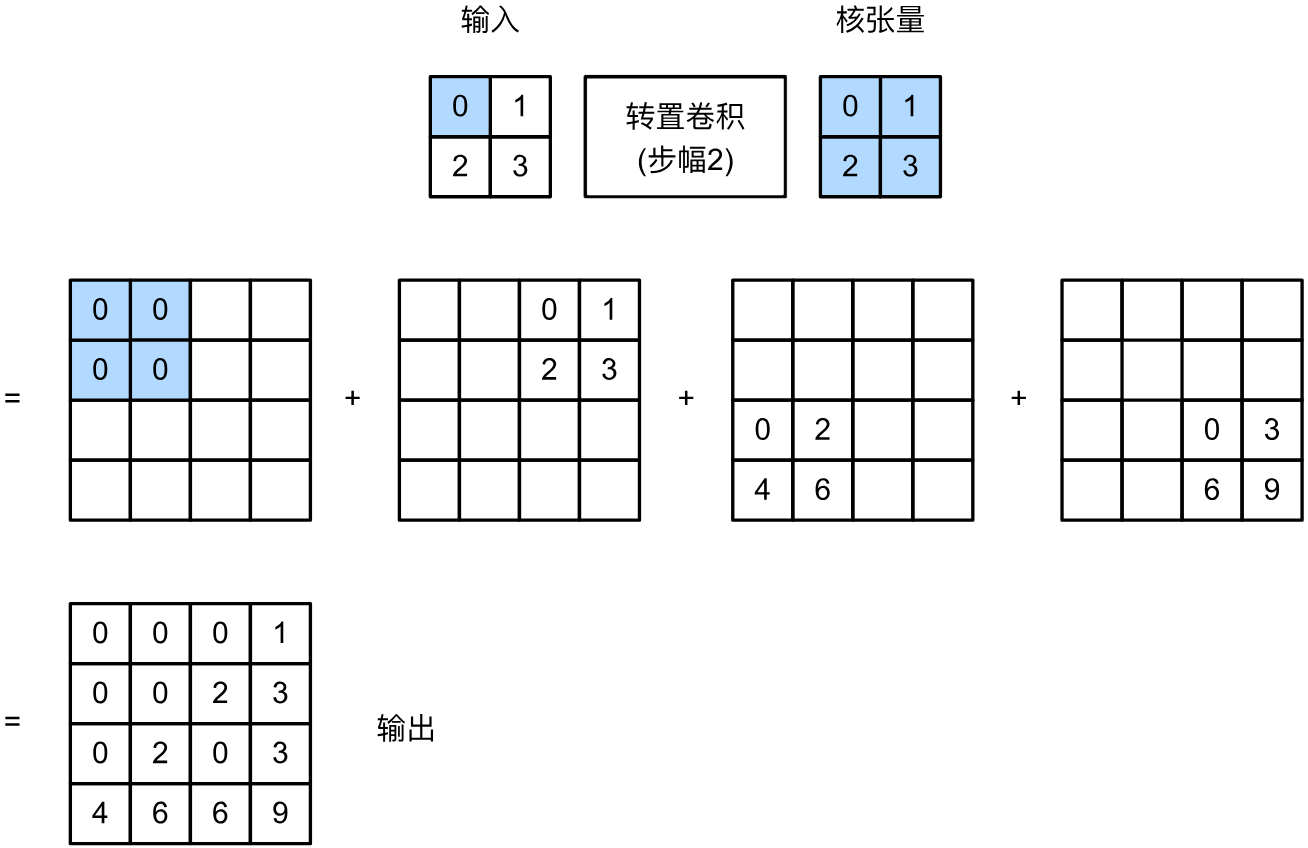
對于多輸入輸出通道,轉置卷積與常規卷積以相同的方式操作,即每個輸入通道都會被分配與輸出通道數目相同的卷積核,每個卷積核負責一個輸入通道到一個輸出通道的計算。
全卷積網絡(FCN)
全卷積網絡(FCN)通過引入轉置卷積,采用卷積神經網絡實現了從圖像像素到像素類別的轉換。FCN開創了全卷積架構的先河,奠定了現代分割網絡的基礎。
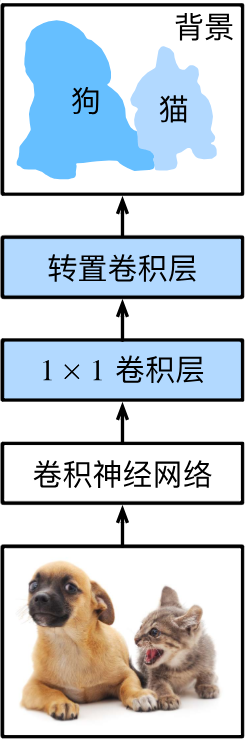
FCN的核心改進在于將傳統卷積神經網絡的全連接層替換為了轉置卷積層。FCN先使用卷積神經網絡提取圖像特征,然后通過 1 × 1 1\times1 1×1卷積層將通道數轉換為類別數,再通過轉置卷積層將特征圖的高和寬轉換為輸入圖像的大小,而每個像素的每個輸出通道表示該像素被預測為對應類別的概率。
風格遷移
風格遷移是一種將藝術風格與圖像內容相結合的計算機視覺技術,它接收兩張圖像作為輸入,一張是內容圖像,另一張是風格圖像。模型將修改內容圖像,使其在風格上接近風格圖像。

一種基于卷積神經網絡的風格遷移模型如下圖所示,實線箭頭和虛線箭頭分別表示前向傳播和反向傳播:
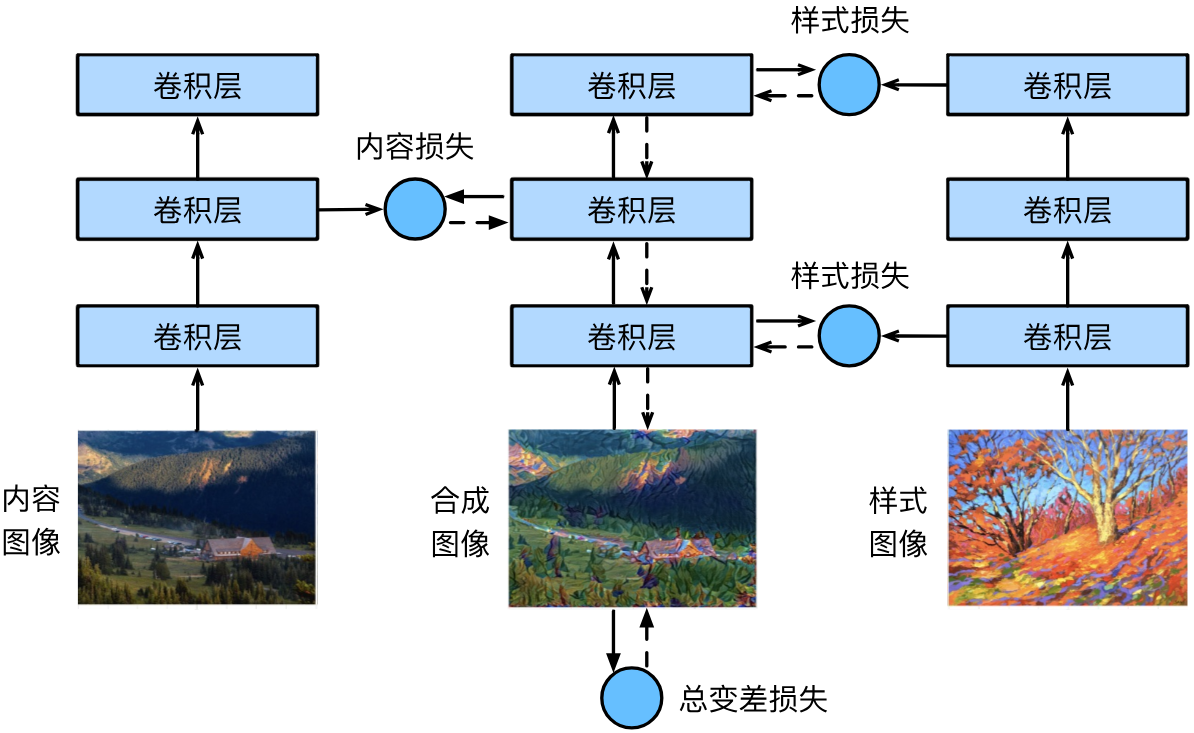
該模型中,每個圖像都由一個預訓練好的卷積神經網絡處理,在訓練中無需更新。該卷積神經網絡憑借多個層逐級提取圖像的特征,其中某些層被指定輸出內容特征或風格特征。
模型在風格遷移過程中所需迭代的模型參數即合成圖像,其迭代流程如下:
- 初始化合成圖像,通常使用內容圖像,合成圖像將在內容圖像的基礎上不斷演進。
- 使用卷積神經網絡提取內容圖像和風格圖像的內容特征和風格特征。
- 迭代合成圖像:
- 使用卷積神經網絡提取合成圖像的內容特征和風格特征。
- 計算合成圖像與內容圖像之間的內容損失、合成圖像與風格圖像之間的風格損失和合成圖像的全變分損失(總變差損失)。
- 三個損失通過反向傳播對合成圖像進行優化。
- 重復上述操作。
- 迭代一定次數后得到最終的合成圖像。
其中,內容(風格)損失均通過平方誤差函數度量合成圖像與內容(風格)圖像在特征上的差異得到。而全變分損失度量鄰近像素值的差異,用于去除合成圖像中大量的高頻噪點,即特別亮或特別暗的像素。假設 x i , j x_{i,j} xi,j?表示坐標 ( i , j ) (i,j) (i,j)處的像素值,則全變分損失計算如下:
∑ i , j ∣ x i , j ? x i + 1 , j ∣ + ∣ x i , j ? x i , j + 1 ∣ \sum_{i,j}|x_{i,j}-x_{i+1,j}|+|x_{i,j}-x_{i,j+1}| i,j∑?∣xi,j??xi+1,j?∣+∣xi,j??xi,j+1?∣





)



)
連接mysql數據庫,寫入計算結果)

)






