原文鏈接:布隆過濾器和布谷鳥過濾器
布隆過濾器
介紹
布隆過濾器(Bloom Filter)是 1970 年由布隆提出的。它實際上是一個很長的二進制向量和一系列隨機映射函數,檢查值是“可能在集合中”還是“絕對不在集合中”
- 空間效率高:通常比精確數據結構占用更少的空間
- 查詢速度快:常數時間復雜度 O(1)
- 誤報率可控:通過調整哈希函數的數量和布隆過濾器的大小可控制誤報率
- 不能刪除元素:一旦向布隆過濾器中添加了元素,則不能從中刪除
原理
本質是由長度為 m 的向量或列表(僅包含 0、1),最初所有值均設為 0

為了將數據添加到布隆過濾器中,會提供 K 個不同的哈希函數,并將結果位置上對應位置設為“1”,使用多(此處假設為 3 個)個哈希函數得到多個索引值,如輸入“semlinker”時,預計得到 2、4、6,將相應位置設為 1
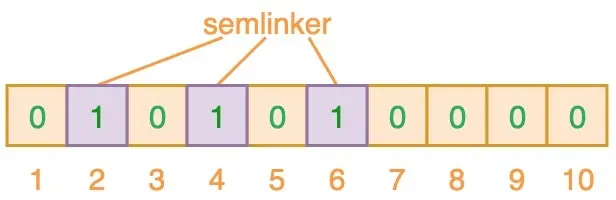
再輸入“kakuqo”時,哈希得到 3、4、7,此刻的 4 被標記了兩次
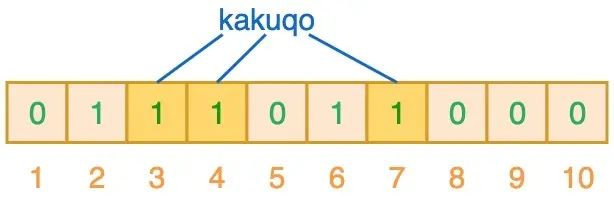
當我們對值進行搜索時,先使用 3 個哈希函數對搜索值進行哈希運算,例如輸入“fullstack”時,得到 2、3、7,相應位置都為 1,意味著可能已經插入到集合了。
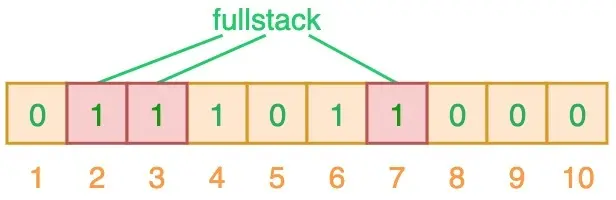
布隆過濾器的誤判率
- n:已經添加的元素
- k:哈希次數
- m:布隆過濾器長度
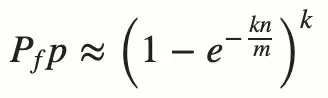
應用場景
- 網頁爬蟲對 URL 去重,避免爬取相同 URL
- 反辣椒郵件,從數十億個辣椒郵件列表中判斷某郵箱是否為垃圾郵箱
- Google BigTable,Apache HBbase 和 Apache Cassandra 使用布隆過濾器減少對不存在的行和列的查找
代碼實現
package com.yingzi.data_structure;import java.util.BitSet;
import java.util.Random;public class BloomFilter {private final BitSet bitSet;private final int[] hashFunctions;public BloomFilter(int expectedElements, double falsePositiveRate) {// 計算位數組大小int bits = _optimalSize_(expectedElements, falsePositiveRate);// 創建位數組this.bitSet = new BitSet(bits);// 計算所需的哈希函數數量int hashCount = _optimalHashCount_(expectedElements, bits);this.hashFunctions = generateHashFunctions(hashCount);}private static int optimalSize(int expectedElements, double falsePositiveRate) {return (int) (-expectedElements * Math._log_(falsePositiveRate) / (Math._log_(2) * Math._log_(2)));}private static int optimalHashCount(int expectedElements, int bits) {return (int) (bits / expectedElements * Math._log_(2));}private int[] generateHashFunctions(int hashCount) {Random random = new Random();int[] hashes = new int[hashCount];for (int i = 0; i < hashCount; i++) {hashes[i] = random.nextInt();}return hashes;}public void add(String item) {for (int hash : hashFunctions) {int index = Math._abs_(hash ^ item.hashCode()) % bitSet.size();bitSet.set(index);}}public boolean mightContain(String item) {for (int hash : hashFunctions) {int index = Math._abs_(hash ^ item.hashCode()) % bitSet.size();if (!bitSet.get(index)) {return false;}}return true;}
}
- 構造函數 (
BloomFilter): 接收期望的元素數量和期望的誤報率。根據這些信息計算出合適的位數組大小和哈希函數數量。 optimalSize方法: 根據公式計算最優的位數組大小。optimalHashCount方法: 根據公式計算最優的哈希函數數量。generateHashFunctions方法: 生成指定數量的哈希函數。add方法: 將元素添加到布隆過濾器中。對于每個哈希函數,計算出一個索引并設置該位。mightContain方法: 檢查一個元素是否可能存在于布隆過濾器中。對于每個哈希函數,檢查相應的位是否被設置。如果所有相關的位都被設置,則認為該元素可能存在于布隆過濾器中。
public class BloomFilterExample {public static void main(String[] args) {// 假設我們期望有 1000 個元素,希望誤報率小于 0.1%BloomFilter bloomFilter = new BloomFilter(1000, 0.001);// 添加一些元素String[] elementsToAdd = {"hello", "world", "java", "programming"};for (String element : elementsToAdd) {bloomFilter.add(element);}// 檢查一些元素是否存在System._out_.println("Does 'hello' exist? " + bloomFilter.mightContain("hello")); // trueSystem._out_.println("Does 'world' exist? " + bloomFilter.mightContain("world")); // trueSystem._out_.println("Does 'nonexistent' exist? " + bloomFilter.mightContain("nonexistent")); // false}
}
變體
在海量數據處理的場景中,我們往往無法預測數據的規模,而重建過濾器的開銷又過大,因此需要一個支持刪除元素的過濾器,根據不同的實現方法,衍生以下變體
計數布隆過濾器:不再使用一個計數器,而是使用一個計數器,刪除一個元素時將對應位置的計數減 1,當計數為零時代表元素不存在,該方法雖然支持了刪除,但空間隨著計數器大小成倍增加阻塞布隆過濾器:多層級的布隆過濾器(類似 CPU 的多級緩沖),將集合分為多個布隆過濾器(每個過濾器相互獨立,哈希函數也不同),首先決定哈希到哪個布隆過濾器,再在對應的布隆過濾器中使用對應的哈希函數進行插入,該方法的空間利用率高且假陽率低,實現較復雜,且需要手動調整塊大小和哈希函數,否則會因為某個小布隆過濾器負載不均衡導致假陽率增加動態左計數布隆過濾器:結合計數、阻塞的思想。將集合分為多個小布隆過濾器,并且每個塊中的每個位置都會維護一個計數器。該方法比起計數布隆過濾器,空間利用率更高,但在分布式場景下和布計數器的開銷也會嚴重增加商過濾器:將集合劃分為多個桶,每個桶中保存一個元素和一個余數。對元素哈希得到一個整數值,整數值的高位為桶的下標,地位代表余數,通過對比對應下表的余數是否相同來判斷元素存在,該方法的缺點在于需要使用額外的元數據來管理每個元素,桶數需要為 2 的冪次方
在所有變體中,應用最廣泛、效果最好的是布谷鳥過濾器
布谷鳥過濾器
介紹
基于布谷鳥哈希算法實現的過濾器,存儲了哈希值的布谷鳥哈希表
相比布隆過濾器的優點
-
支持新增和刪除元素
-
更節省空間
- 哈希表跟家緊湊
- 在錯誤率小于 3% 的時候空間性能優于布隆過濾器
- 空間節省 40% 多
-
查詢效率高
- 一次哈希
- 而布隆過濾要采用多種哈希函數進行多次哈希
原理
最簡單的布谷鳥哈希結構為一維數組結構,會有兩個 hash 算法將新來的元素映射到數組的兩個位置。若兩個位置中有一個位置為空,則將元素直接放進去,若兩個位置都滿了,就【鳩占鵲巢】隨機踢走一個,然后自己霸占該位置
- 保存元素(位置都沒有被占):新來元素 a 經過 hash 為(A2,B1)的位置,由于 A2 還沒有元素 a,直接落入 A2

- 保存元素(其中一個位置被占):新來元素 b 的 hash 為(A2,B3),由于 A2 已經被 a 占了,所以 b 會落在 b3
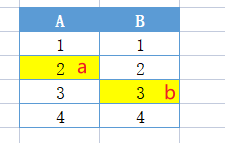
- 保存元素(兩個位置都占):新來元素 c 的 hash 為(A2,B3),它會隨機將一個元素擠走,這里擠走了 a
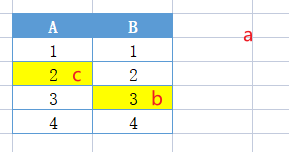
- 被擠掉的元素重新找位置:a 會重新進行 hash,找到還未被占的 B1 位置

問題:若數組太擁擠,將導致連續踢了若干次還未停止,嚴重影響插入效率。布谷鳥哈希設置一個閾值,當連續占巢行為超出了某個閾值,就認為數組幾乎滿了,這時需要對它進行擴容
為了提高空間利用率,降低碰撞概率,布谷鳥過濾器在布谷鳥哈希上做了改進, 將其從一維擴展為二維(每個桶存儲的元素從 1 個變為 n 個),且每個位置中只存儲幾個 bit 的指紋,而非完整的元素
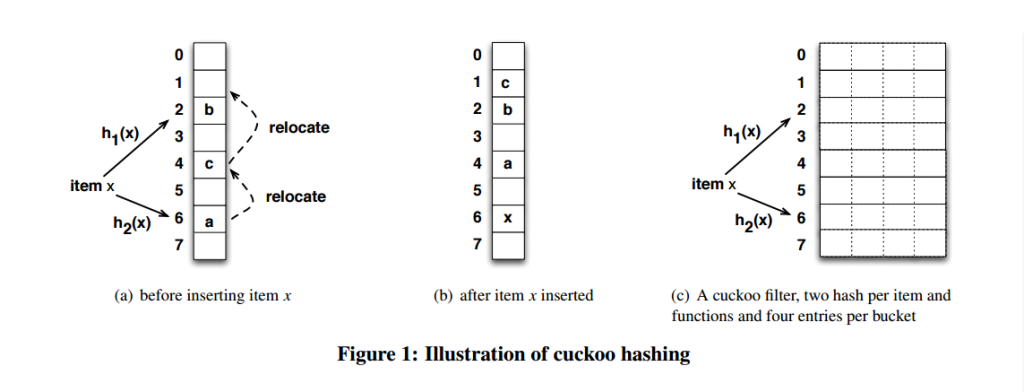
每個桶中存儲了 4 個 slot,只有當一個桶中的所有 slot 都被填滿的時候,才會使用替換的策略。這里的桶結構使用了一個二維數組來表示
應用場景
布谷鳥過濾器適用于需要支持動態數據集的應用場景,特別是需要支持刪除的情況,具體應用場景包括但不限于
緩存系統:用于緩存熱點數據,減少后端系統的負載數據庫:在數據庫中作為索引結構,提高查詢效率網絡路由:在網絡設備中用于快速查找路由表惡意軟件檢測:快速檢測已知的惡意軟件簽名分布式系統:一致性檢查,確保數據的一致性
代碼實現
package com.yingzi;import java.util.Random;public class cuckooFilter {static final int _MAXIMUM_CAPACITY _= 1 << 30;//最大的踢出次數private final int MAX_NUM_KICKS = 500;//桶的個數private int capacity;//存入元素個數private int size = 0;//存放桶的數組private Bucket[] buckets;private Random random;//構造函數public cuckooFilter(int capacity) {capacity = _tableSizeFor_(capacity);this.capacity = capacity;buckets = new Bucket[capacity];random = new Random();for (int i = 0; i < capacity; i++) {buckets[i] = new Bucket();}}/** 向布谷鳥過濾器中插入一個元素** 插入成功,返回true* 過濾器已滿或插入數據為空,返回false*/public boolean insert(Object o) {if (o == null)return false;/** 當我們知道 f 和 i1,就可以直接算出 i2,同樣如果我們知道 i2 和 f,也可以直接算出 i1 (對偶性)* 所以我們根本不需要知道當前的位置是 p1 還是 p2,* 只需要將當前的位置和 hash(o) 進行異或計算就可以得到對偶位置。* 而且只需要確保 hash(o) != 0 就可以確保 i1 != i2,* 如此就不會出現自己踢自己導致死循環的問題。*/byte f = fingerprint(o);int i1 = hash(o);int i2 = i1 ^ hash(f);if (buckets[i1].insert(f) || buckets[i2].insert(f)) {//有空位置size++;return true;//插入成功}//沒有空位置,relocate再插入return relocateAndInsert(i1, i2, f);}_/**_
_ * 對插入的值進行校驗,只有當未插入過該值時才會插入成功_
_ * 若過濾器中已經存在該值,會插入失敗返回false_
_ */_
_ _public boolean insertUnique(Object o) {if (o == null || contains(o))return false;return insert(o);}_/**_
_ * 隨機在兩個位置挑選一個將其中的一個值標記為舊值,_
_ * 用新值覆蓋舊值,舊值會在重復上面的步驟進行插入_
_ */_
_ _private boolean relocateAndInsert(int i1, int i2, byte f) {boolean flag = random.nextBoolean();int itemp = flag ? i1 : i2;for (int i = 0; i < MAX_NUM_KICKS; i++) {//在桶中隨機找一個位置int position = random.nextInt(Bucket._BUCKET_SIZE_);//踢出f = buckets[itemp].swap(position, f);itemp = itemp ^ hash(f);if (buckets[itemp].insert(f)) {size++;return true;}}//超過最大踢出次數,插入失敗return false;}_/**_
_ * 如果此過濾器包含對象的指紋,返回true_
_ */_
_ _public boolean contains(Object o) {if(o == null)return false;byte f = fingerprint(o);int i1 = hash(o);int i2 = i1 ^ hash(f);return buckets[i1].contains(f) || buckets[i2].contains(f);}_/**_
_ * 從布谷鳥過濾器中刪除元素_
_ * 為了安全地刪除,此元素之前必須被插入過_
_ */_
_ _public boolean delete(Object o) {if(o == null)return false;byte f = fingerprint(o);int i1 = hash(o);int i2 = i1 ^ hash(f);return buckets[i1].delete(f) || buckets[i2].delete(f);}_/**_
_ * 過濾器中元素個數_
_ */_
_ _public int size() {return size;}//過濾器是否為空public boolean isEmpty() {return size == 0;}//得到指紋private byte fingerprint(Object o) {int h = o.hashCode();h += ~(h << 15);h ^= (h >> 10);h += (h << 3);h ^= (h >> 6);h += ~(h << 11);h ^= (h >> 16);byte hash = (byte) h;if (hash == Bucket._NULL_FINGERPRINT_)hash = 40;return hash;}//哈希函數public int hash(Object key) {int h = key.hashCode();h -= (h << 6);h ^= (h >> 17);h -= (h << 9);h ^= (h << 4);h -= (h << 3);h ^= (h << 10);h ^= (h >> 15);return h & (capacity - 1);}//hashMap的源碼 有一個tableSizeFor的方法,目的是將傳進來的參數轉變為2的n次方的數值static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= _MAXIMUM_CAPACITY_) ? _MAXIMUM_CAPACITY _: n + 1;}static class Bucket {public static final int _FINGERPINT_SIZE _= 1;//桶大小為4public static final int _BUCKET_SIZE _= 4;public static final byte _NULL_FINGERPRINT _= 0;private final byte[] fps = new byte[_BUCKET_SIZE_];//在桶中插入public boolean insert(byte fingerprint) {for (int i = 0; i < fps.length; i++) {if (fps[i] == _NULL_FINGERPRINT_) {fps[i] = fingerprint;return true;}}return false;}//在桶中刪除public boolean delete(byte fingerprint) {for (int i = 0; i < fps.length; i++) {if (fps[i] == fingerprint) {fps[i] = _NULL_FINGERPRINT_;return true;}}return false;}//桶中是否含此指紋public boolean contains(byte fingerprint) {for (int i = 0; i < fps.length; i++) {if (fps[i] == fingerprint)return true;}return false;}public byte swap(int position, byte fingerprint) {byte tmpfg = fps[position];fps[position] = fingerprint;return tmpfg;}}public static void main(String args[]){cuckooFilter c=new cuckooFilter(100);c.insert("西游記");c.insert("水滸傳");c.insert("三國演義");System._out_.println(c.contains("水滸傳"));}
}
參考資料
高級數據結構與算法 | 布谷鳥過濾器(Cuckoo Filter):原理、實現、LSM Tree 優化
Redis–布谷鳥過濾器–使用/原理/實例
布谷鳥過濾器的簡單 Java 實現
【大數據管理】Java 實現布谷鳥過濾器(CF)







TCP、UDP協議)


)
-004)

)





