1. 哈希:

之前我們的紅黑數的查找是由于左邊小右邊大的原則可以快速的查找,我們這里的哈希表呢?
這里是用過哈希函數把關鍵字key和存儲位置建立一個關聯的映射。
直接定址法(函數函數定義的其中一種):
直接定址法是我們設置哈希函數的第一種方法:
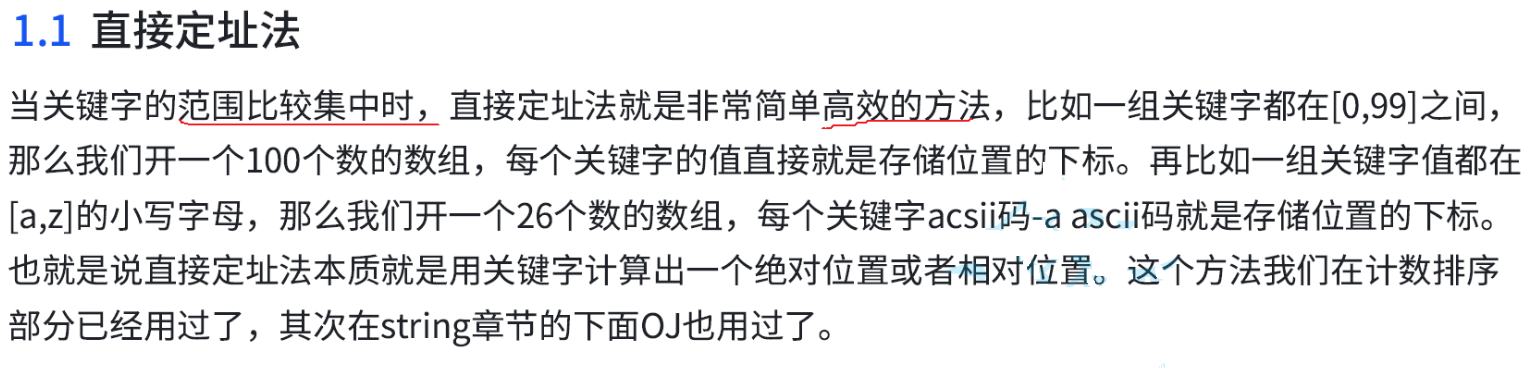
直接定址法的限制就是適用范圍比較集中的時候,如果范圍不集中的話,我們就不能使用直接定址法。
負載因子:

負載因子其實表示的哈希表的空間的利用率,負載因子越大的時候,空間利用率就越大,哈希沖突的概率就越大,負載因子越小的時候,空間利用率越小,哈希沖突的概率就越小。
要注意這里是概率,不是一定的沖突就大或者小,有可能這批數據剛好比較合適就沒有啥沖突。
哈希沖突:

直接定址法是不會有哈希沖突的,直接定址法適用于數據范圍比較集中,直接定址法是會給每個值都分配一個空間的。所以不會有哈希沖突。
但是直接定址法的話,我們當然不能一直使用這個,當我們的其他的環境下,我們的數據并不集中的話,我們其實常常使用的是其他的構建哈希函數的方法,他可能會導致幾個數據映射到同一個位置上去,導致哈希沖突。
哈希函數:

我們接下來看定義我們的哈希函數的方法:
除法散列法/除留余數法:

除留余數法,我們要讓所有的值都映射到M個空間里面,M是哈希表的大小,我們就讓關鍵值key取模M,那么他取模得到的值一定是M-1這個范圍里面的某一個,這就映射出了一個位置。
我們看上面的圖片,我們看第二點,他說我們的哈希表的大小M要盡量避免2的冪和10的冪。因為我們要計算數據映射的位置的時候,我們是要使用數據來除以哈希表的大小M來得到的。如果使用他們的話就會導致沖突比較大。
除留余數法的話就比直接定址法好多了,我們不需要管數據的范圍的大小,我們只要開比數據個數要大的空間就可以。

這就是除留余數法(M是哈希表的大小),19%M得到8,19就映射到8這個位置,然后其他的數據也是一樣的,取模M得到一個映射的位置,但是我們的看到30取模M的結果得到的也是8,這個就是我們的哈希沖突。
哈希沖突是不可避免的,我們接下來要講解如果處理哈希沖突;
我們還有其他的構建哈希函數的方法,乘法散列法和全域散列法,這兩個的話我們知道了解一下就行,不進行細講。
處理哈希沖突:


開放定址法:
當?個關鍵字key?哈希函數計算出的位置沖突了,則按照某種規則找到?個沒有存儲數據的位置進?存儲。簡單的說就是我們的這個數據映射出的位置被別人占了,我們就找一個新的位置占上。
這個找新位置的規則我們分成三種:線性探測,二次探測,雙重探測。
我們主要學的是線性探測。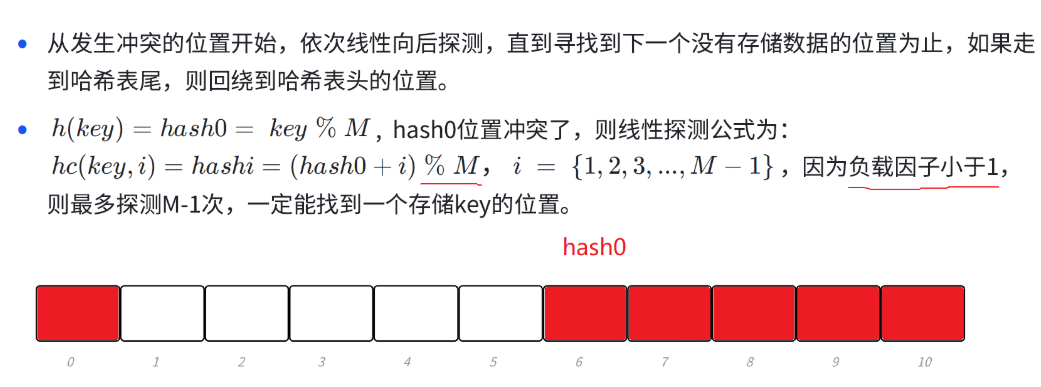
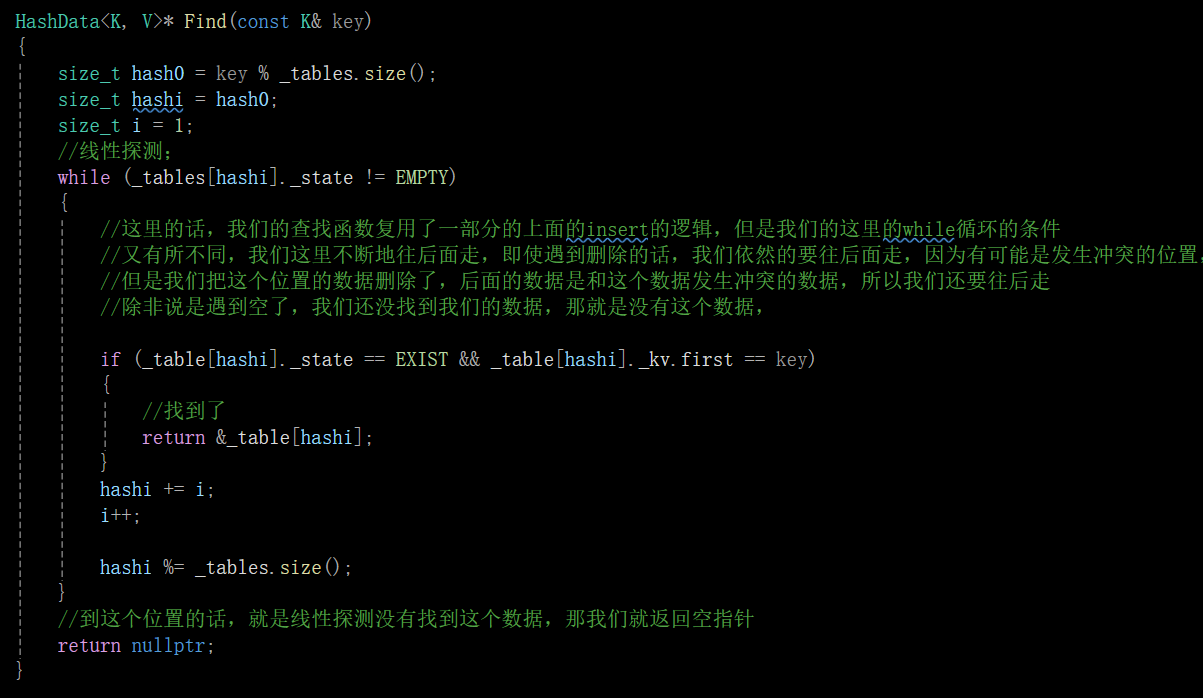
線性探測就是映射到這個位置但是這個位置被占了,我們就從這個發生沖突的位置開始,我們就依次的往后走,直到遇到一個空的位置,我們就占到這個位置上(如果走到哈希表的尾了,我們就繞到頭上去)。
當我們的映射的這個位置發生沖突被別的數據占據了之后,我們的公式就是給哈希這個位置+1然后繼續取模往后走,走到哈希表的尾了,但是我們是取模進行移動的,比如圖中的,hash0+i從10變成11的時候,他取模的到的結果就可以跳轉回到頭部。
開放定址法代碼實現:
insert():
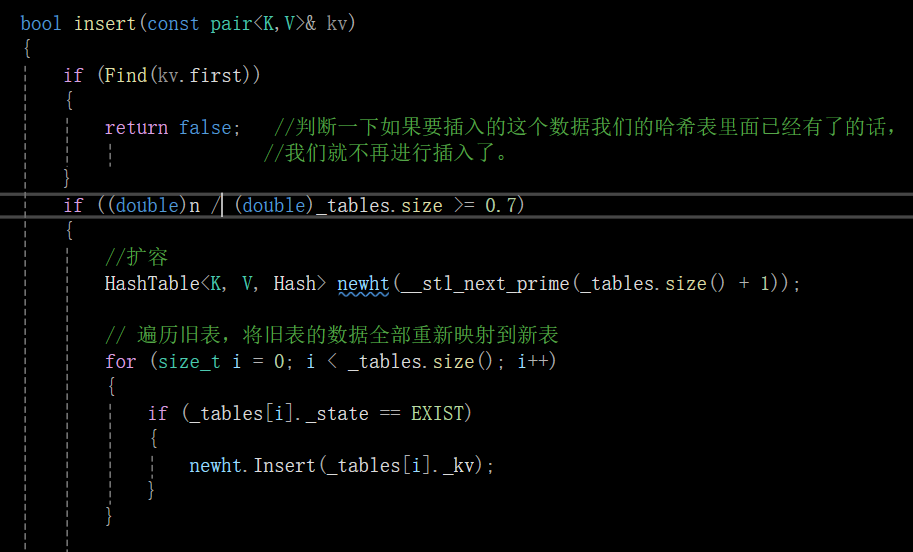
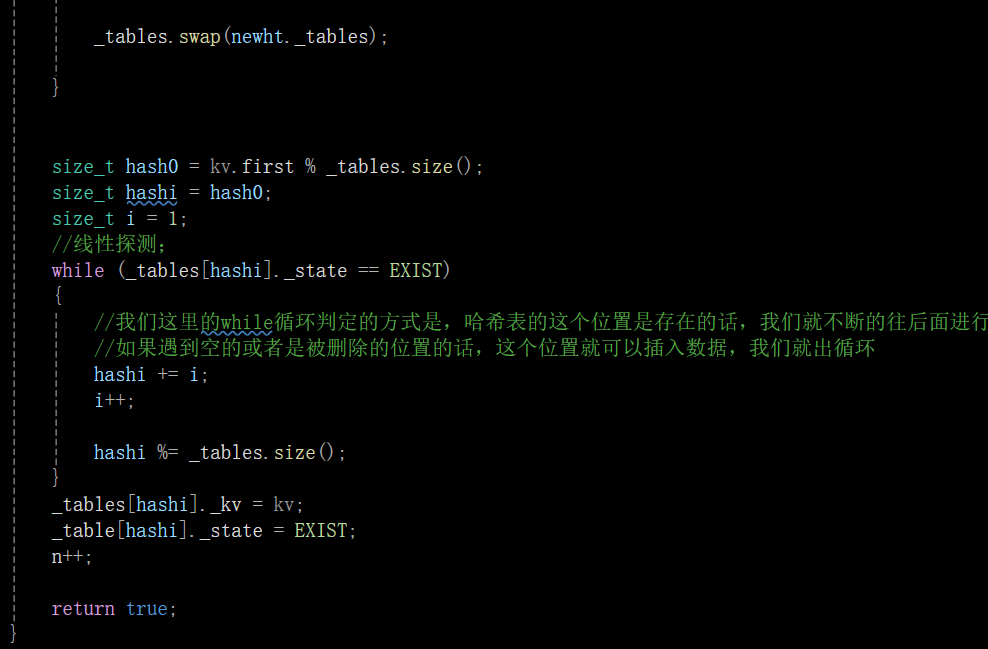
Find():
Erase():

素數表:
我們之前說我們要使用素數來設置哈希表的大小,但是如果這個哈希表滿了以后,我們需要擴容的時候,我們一般都會給這個哈希表*2來進行擴容,這時候的到的就不是一個素數,可能會導致哈希沖突變大。
我們的庫里面就給出了一個不太接近2的素數表。
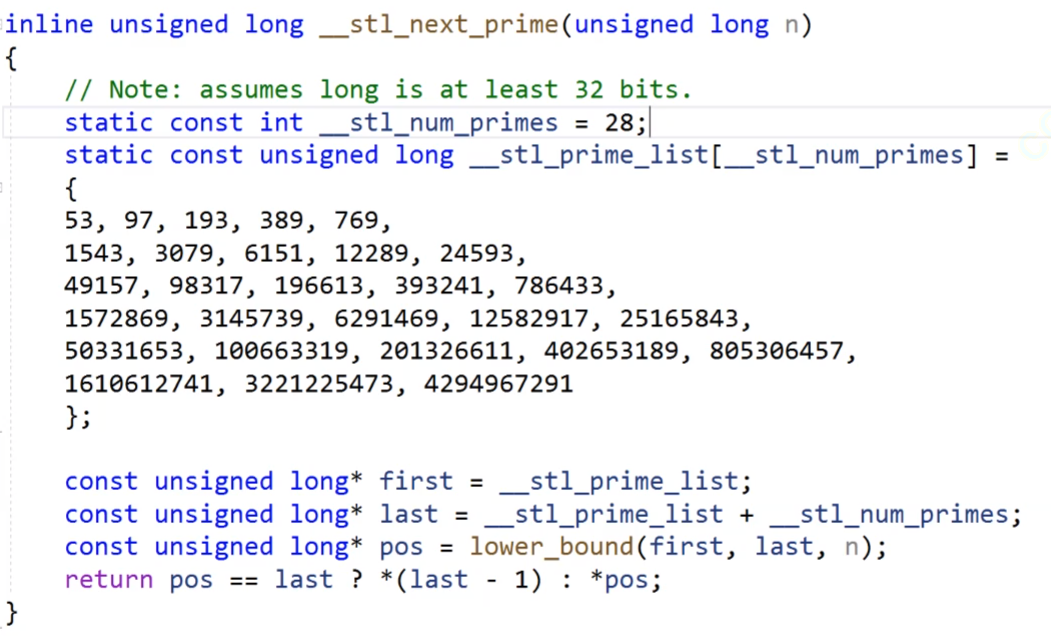
你看下面的那個是一個lower_bound的函數,這個就是找大于等于的,我們在下面的擴容里面實現的話,我們就可以調用這個素數表的函數,他每次擴容的話,就走到了下一個素數的位置。
![]()
當前的size()+1的話,里面的lower_bound是會給你找比這個大或者相等的數據的,假如現在的size()是53,你給他+1,得到54,那么他就會找比54大的數據來進行的。
key不能取模的問題:
我們這里還有一個問題那就是key如果不是我們的int類型的時候,我們建立哈希函數的話,我們是必須要使用除留余數法的,但是如果key不是int類型的,那怎么取模呢?

我們看這個函數,他是絕對插入不到我們的哈希表里面去的,我們的insert函數,我們是要使用到dict.first進行判斷的。(這里編譯就會報錯);
那我們這里怎么解決呢?
我們這里就要走兩層映射,首先把string映射成int類型的,然后把int映射到哈希表的位置上。
那怎么把string類型的映射成int類型的數據呢?我們可以把string里面的每一個字母的ASCII值加起來,這個邏輯還比較合適。
那實現怎么來實現呢?
我們就實現一個仿函數來進行我們的轉化,
我們先看下面的這個圖片:
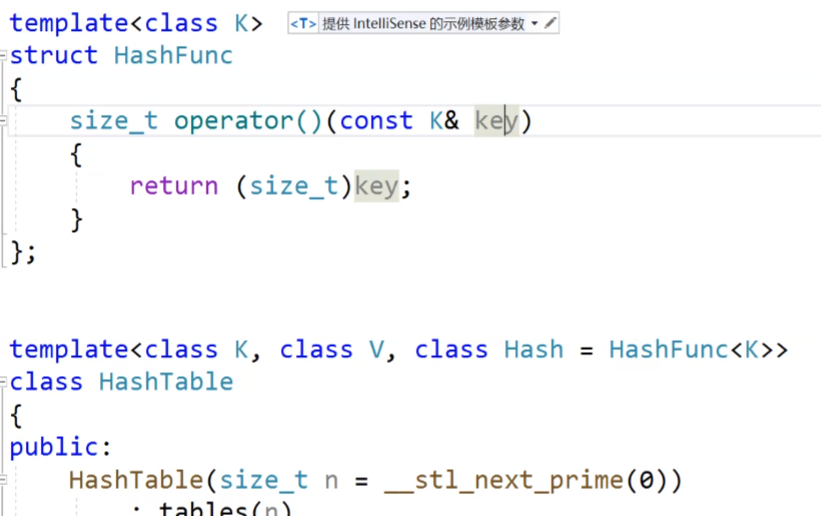
我們給我們的模板的第三個參數是我們的Hash仿函數,我們給他傳一個默認的缺省函數HashFunc函數,這個函數的話,我們會把傳進來的類型轉為size_t類型的數據,但是有的類型他是轉換不成size_t類型的數據的,這時候我們就要自己來手動的實現一個仿函數來進行轉換。
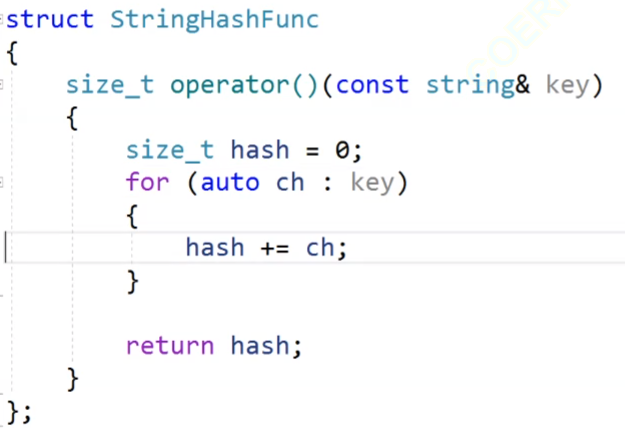
這個就是我們實現的仿函數,我們把這個仿函數傳進去。


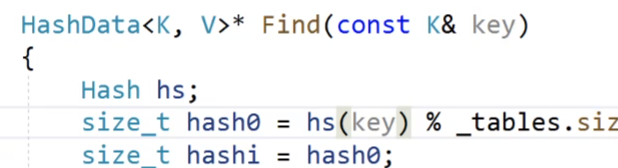
還記得我們之前的仿函數是怎樣使用的呢?
我們的仿函數實例化出的對象我們可以直接當作函數來進行使用,看上面Hash仿函數實例化對象hs以后,hs(key)這個就是直接調用仿函數,把key數據轉換成int類型的可以取模的數據。
這時候看我們的pair鍵值對的類型是string類型的,這個類型轉成int類型的話,我們就要傳我們的自己的仿函數進去才行。

你傳其他類型的key也能用,但是的話,你要配一個仿函數類幫助他可以進行取模(必須要能取模,這是構建哈希函數的必要途徑)。
我們繼續往下看:
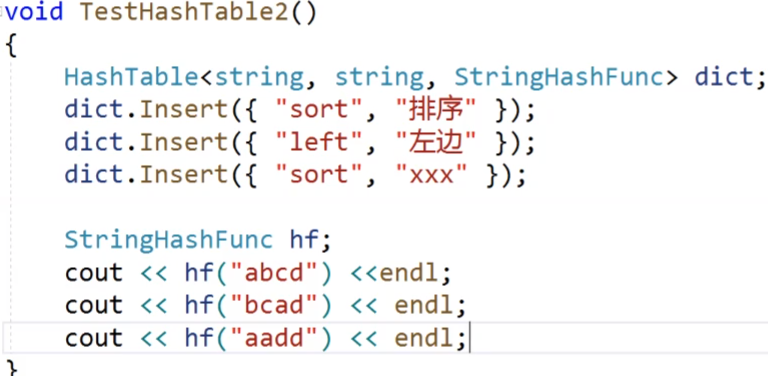
我們看,我們剛才自己實現的string轉換為int的仿函數,我們是讓所有的字母的ASCII加起來,但是這樣的話,我們看上面的圖片,這三個string的順序不一樣,但是他們的ASCII是一樣的,最后導致他們映射的int是同一個,這就導致了沖突,那我們的這個仿函數是不是就顯得沒有那么好呢?
那有沒有剛好的方法來實現這個仿函數,有的,有人提出了BKDRHash方法來進行:
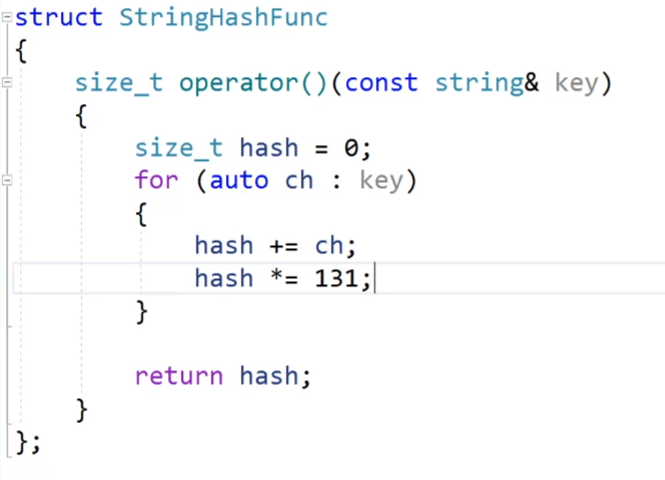
這樣我們加起來的ASCII相同的不同順序的字符串,除非是這兩個ASCII值相等的字符串順序都一樣,不然最后計算得到的結果不可能一樣。
我們繼續往下看:

當我們的容器是我們的unordered_map,這個容器的底層是哈希表實現的,我們給他的key傳上string的時候,它不需要仿函數就可以通過運行,但是我們的HashTables我們就要加上仿函數才可以。
要知道我們的string是要經常使用的,經常使用的話,我們想辦法讓key默認的支持string轉化,我們可以使用一個特化來實現。

這個就是特化的實現,當我們的key是string類型的時候,他就是走特化,就不需要仿函數,我們的unordered_map使用的是庫里面的,他的底層是由哈希表封裝的,庫里面已經把這個string的特化實現過了,我們這里調用unordered_map給key傳string的話,他就不需要仿函數。
但是我們的這里的哈希表是我們自己在進行實現,我們沒有實現特化,我們就要仿函數。
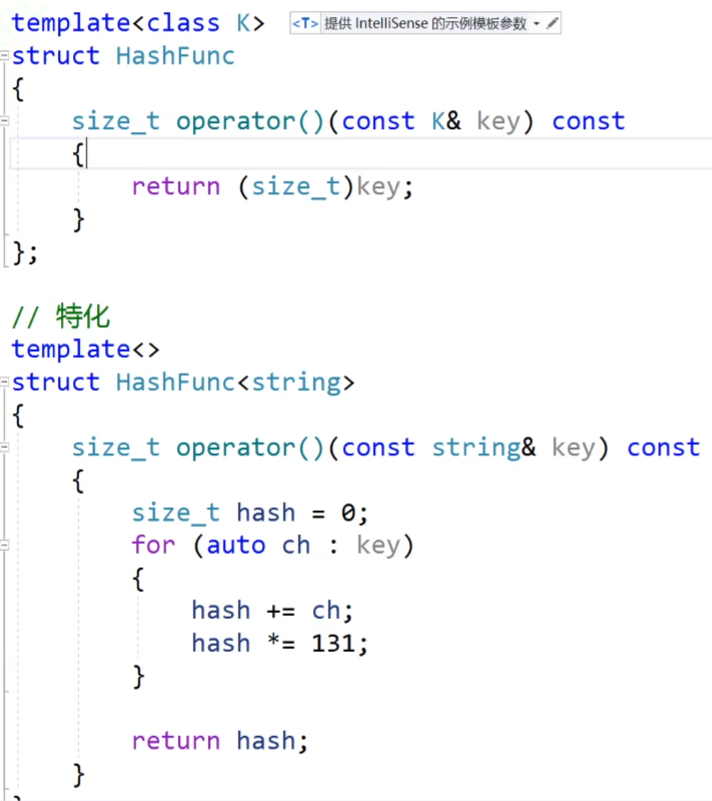
我們看這個特化,特化的上面是我們的仿函數,我們的哈希表可以傳各種類型的數據進來,然后我們傳仿函數,把各種類型轉換為size_t類型的。也可以不傳仿函數,把string的特化出來,我們傳string類型的數據進來后就直接調用特化的模板了。

現在我們這樣就沒事,就可以了,我們已經特化了string類型的數據,可以不傳仿函數。
我們繼續往下看:
我們看這個:
![]()
當我們的調用庫里面的unordered_map的時候,我們傳K傳pair<>鍵值對,這時候也是有問題的,庫里面沒有實現pair<>鍵值對的特化,如果想要這種的話,還是需要你手動的實現仿函數。
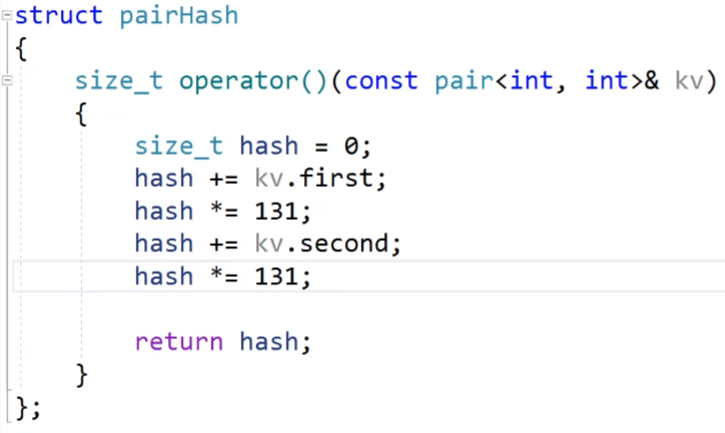
看這個特化,為了防止你1,3和3,1算出來的值是一樣的,減少哈希沖突的發生,使用BKDRHash來實現。

然后接著我們傳仿函數進去,然后我們的鍵值對存1,3和3,1兩個數據,實現哈希表的話,這兩個數據分別進行存儲,我們當然不想讓他產生哈希沖突,我們上面的仿函數就使用BKDRHash來實現。
我們看我們的f第二種解決哈希沖突的方法:
鏈地址法:
這個叫作拉鏈法,鏈地址法,這個是非常重要的解決哈希沖突的方法。
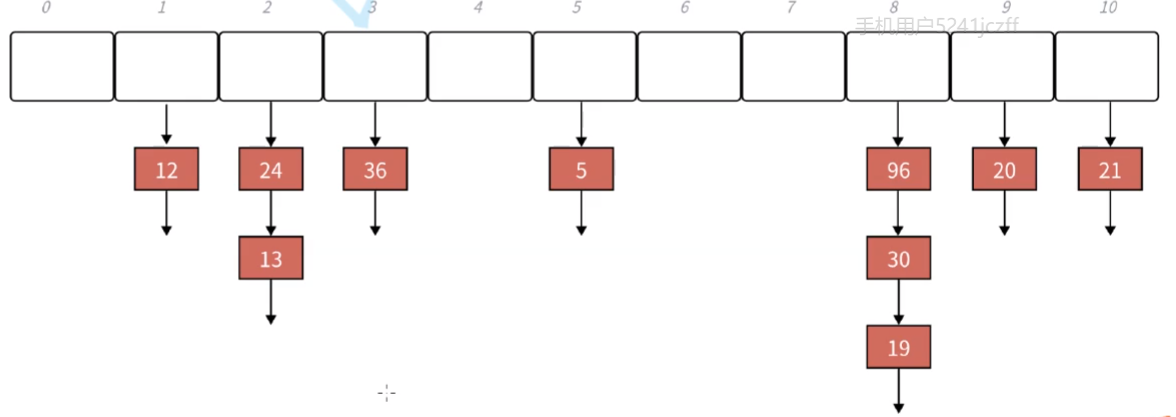




)











:0x2ECC ML307R 的 USB Product ID (PID):0x3012)


