

????🔥個人主頁:?中草藥
🔥專欄:【中間件】企業級中間件剖析
一、冪等性保障
什么是冪等性?
????????冪等性是指對一個系統進行重復調用(相同參數),無論同一操作執行多少次,這些請求對系統的影響都是相同的效果,結果都與執行一次相同。
????????消息可能因網絡重傳、消費者異常重啟、消息重復投遞等導致重復消費,需確保多次處理不會產生副作用。
RabbitMQ 重復消息的來源
| 場景 | 原因 |
|---|---|
| 生產者重復發送 | 生產者未收到 Broker 的 ACK,觸發重試機制(如網絡抖動、Broker 未及時響應) |
| 消費者重復消費 | 消費者處理消息后未及時 ACK,消息重新入隊(如消費者崩潰、處理超時) |
| Broker 消息堆積 | 消息因隊列配置(如死信隊列、TTL)被多次重新投遞 |

MQ的冪等性保障
對于 MQ 而言,冪等性是指同一條消息,多次消費,對系統的影響是相同的。
一般消息中間件的消息傳輸保障分為三個層級。
- At most once: 最多一次。消息可能會丟失,但絕不會重復傳輸.
- At least once: 最少一次。消息絕不會丟失,但可能會重復傳輸.
- Exactly once: 恰好一次。每條消息肯定會被傳輸一次且僅傳輸一次.
????????RabbitMQ 支持 "最多一次" 和 "最少一次"。對于 "恰好一次", 目前 RabbitMQ 還做不到,不僅是 RabbitMQ, 目前市面上主流的消息中間件,都做不到這一點.
實現方案
1、唯一標識 + 去重表
原理:為每條消息分配唯一 ID(如 UUID、業務主鍵),消費前檢查該 ID 是否已處理。
實現步驟:
生產者:在消息頭(Header)中添加唯一標識(如?message_id)。
消費者:
????????消費前查詢去重表(如 Redis 或數據庫),判斷?message_id?是否存在。
????????若不存在,處理消息并寫入去重表;若存在,直接 ACK 消息。
優化:
????????去重表設計:可以使用 Redis 的原子性操作 setnx 來保證冪等性,將唯一 ID 作為 key 放到 redis 中(SETNX messageID 1). 返回 1,說明之前沒有消費過,正常消費。返回 0,說明這條消息之前已消費過,拋棄.
????????過期時間:為去重表記錄設置 TTL,避免數據無限膨脹。
2、業務邏輯判斷
在業務邏輯層面實現消息處理的冪等性。
例如: 通過檢查數據庫中是否已存在相關數據記錄,或者使用樂觀鎖機制來避免更新已被其他事務更改的數據,再或者在處理消息之前,先檢查相關業務的狀態,確保消息對應的操作尚未執行,然后才進行處理,具體根據業務場景來處理
二、順序性保障
????????在分布式系統中,消息的順序性保障是確保消息按照生產者發送的先后順序被消費者處理的機制。RabbitMQ 作為消息中間件,默認不提供嚴格的全局順序保證,但可通過特定設計和配置實現部分場景下的順序性。
順序性問題的根源
RabbitMQ 默認無法保證全局順序性的原因:
-
多消費者并行消費:一個隊列綁定多個消費者時,消息可能被無序處理。
-
消息重試與重新入隊:消費者處理失敗的消息重新入隊后,可能插入到隊列中間。
-
交換機路由策略:使用?
direct、topic?或?headers?交換機時,消息可能分散到不同隊列。 -
網絡延遲與分區:網絡抖動可能導致消息到達 Broker 的順序與發送順序不一致。
順序性保障方案
1、單一隊列 + 單一消費者
-
原理:同一隊列僅綁定一個消費者,串行處理消息。
-
適用場景:低吞吐量但對順序性要求極高的場景(如金融交易)。
-
實現:
-
生產者將所有消息發送到同一隊列。
-
隊列僅允許一個消費者連接(設置?
prefetch_count=1)。 -
消費者禁用自動 ACK,處理完一條消息后手動確認。
-
2、分區消費
????????單個消費者的吞吐太低了,當需要多個消費者以提高處理速度時,可以使用分區消費,把一個隊列分割成多個分區,每個分區由一個消費者處理,以此來保持每個分區內消息的順序性.
Rabbitmq本身并不支持分區消費,需要業務邏輯去實現,或者借助spring-cloud-stream來實現
Partitioning with the RabbitMQ Binder :: Spring Cloud Stream
實現效果演示
3、消息確認機制
????????使用手動消息確認機制,消費者在處理完一條消息后,顯式地發送確認,這樣RabbitMQ才會移除并繼續發送下一條消息.
4、業務邏輯控制
????????在某些情況下,即使消息亂序到達,也可以在業務邏輯層面實現順序控制,比如通過在消息中嵌入序列號,并在消費時根據這些信息來處理
由于RabbitMO本身并不保證全局的嚴格順序性,所以以上所提供的方案往往需要搭配混合使用,特別是在分布式系統中,在實際應用開發中,根據具體的業務需求,需要結合多種策略來實現所需要的順序保證.
三、消息積壓
常見原因
1、消息生產過快:在高流量或者高負載的情況下,生產者以極高的速率發送消息,超過了消費者的處理能力,包括一些流量激增的情況(活動促銷)
2、消費者處理能力不足:消費者處理處理消息的速度跟不上消息生產的速度,也會導致消息在隊列中積壓,可能原因有:
- 消費端業務邏輯復雜,耗時長
- 消費端代碼性能低
- 系統資源限制,如 CPU、內存、磁盤 I/O 等也會限制消費者處理消息的效率.
- 異常處理處理不當。消費者在處理消息時出現異常,導致消息無法被正確處理和確認.
3、網絡問題:因為網絡延遲或不穩定,消費者無法及時接收或確認消息,最終導致消息積壓
4、RabbitMQ 服務器配置問題
- 未設置合理的?
prefetch count:消費者一次拉取過多消息,導致內存壓力。 - 隊列未持久化:重啟后消息丟失,需重新處理積壓。
- 未使用惰性隊列(Lazy Queue):高吞吐場景下內存不足。
解決方案
1)提高消費者效率
????????a. 增加消費者實例數量,比如新增機器
????????b. 優化業務邏輯,比如使用多線程來處理業務
????????c. 設置 prefetchCount, 當一個消費者阻塞時,消息轉發到其他未阻塞的消費者.
????????d. 消息發生異常時,設置合適的重試策略,或者轉入到死信隊列
2)限制生產者速率。比如流量控制,限流算法等
????????a. 流量控制:在消息生產者中實現流量控制邏輯,根據消費者處理能力動態調整發送速率
????????b. 限流:使用限流工具,為消息發送速率設置一個上限
????????c. 設置過期時間。如果消息過期未消費,可以配置死信隊列,以避免消息丟失,并減少對主隊列的壓力
3)資源與配置優化? ?比如升級 RabbitMQ 服務器的硬件,調整 RabbitMQ 的配置參數等
在選擇策略的時候需要實際考慮業務的需求和系統的實際承載能力
四、Raft算法
????????Raft 是一種專為?分布式一致性?設計的共識算法。其核心目標是通過?強可理解性?解決傳統 Paxos 算法的復雜性,同時保證分布式系統的?高可用性?和?數據一致性。
分解問題
將共識問題拆分為三個子問題:
領導人選舉(Leader Election):系統中僅有一個 Leader 負責處理客戶端請求。
日志復制(Log Replication):Leader 將操作日志同步到所有 Follower 節點。
安全性(Safety):確保所有節點最終狀態一致,避免數據沖突。
核心機制
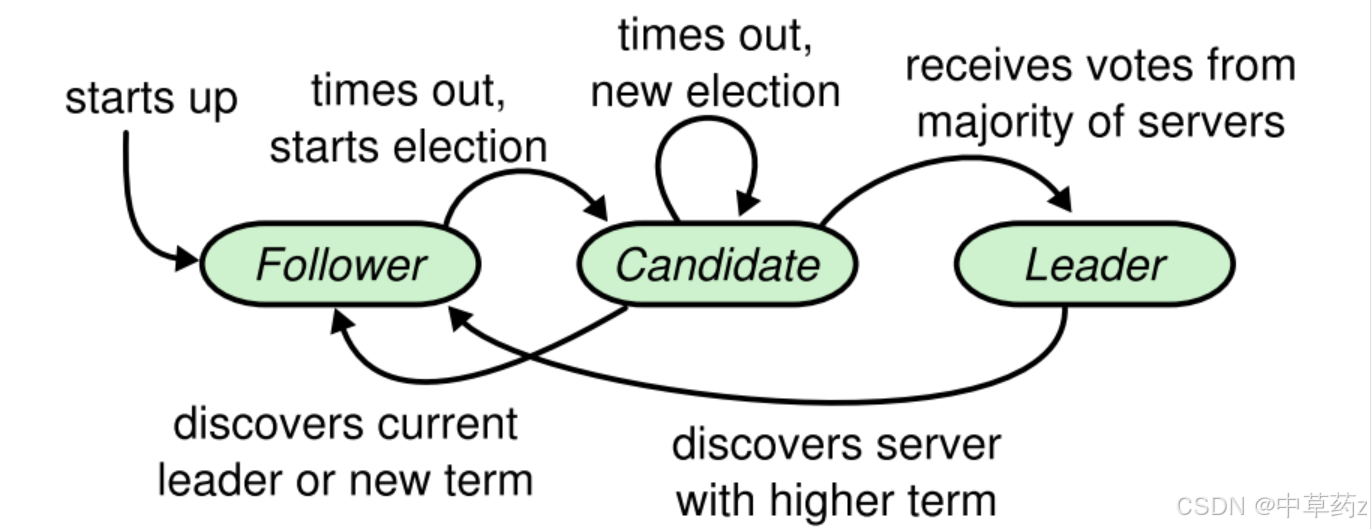
節點角色
-
Leader:唯一處理客戶端請求的節點,負責日志復制和心跳維持。
-
Follower:被動接收 Leader 的日志和心跳,不主動響應客戶端,不直接處理客戶端請求。
-
Candidate:選舉過程中的臨時角色(Follower 超時未收到心跳后成為 Candidate,開始嘗試通過 投票過程成為新的Leader)。
正常的情況下,集群中只有一個Leader,剩下的節點都是follower
任期(Term)
-
全局單調遞增的整數(類似“邏輯時鐘”),每個任期至多一個 Leader。
-
節點間通信攜帶 Term,用于檢測過期信息(如舊 Leader 的請求會被拒絕)。
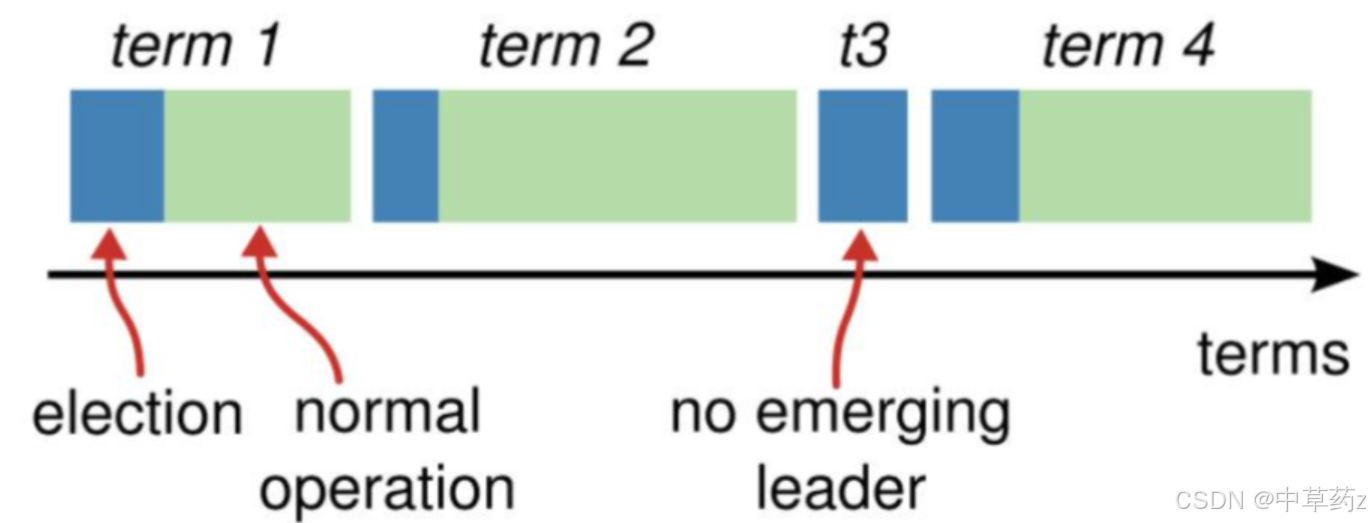
????????Raft 將時間劃分成任意長度的任期(term).每一段任期從一次選舉開始,在這個時候會有一個或者多個candidate 嘗試去成為leader,在成功完成一次leaderelection之后,一個leader就會一直節管理集群直到任期結束,在某些情況下,一次選舉無法選出 leader,這個時候這個任期會以沒有leader 而結束(如下圖t3).同時一個新的任期(包含一次新的選舉)會很快重新開始
通信
Raft算法中的服務器節點之間采用RPC進行通信,主要由兩類RPC請求:
-
RequestVote RPCs: 請求投票,由 candidate 在選舉過程中發出
-
AppendEntries RPCs: 追加條目,由leader 發出,用來做日志復制和提供心跳機制
選舉過程
可以通過此網站動畫來理解投票選舉過程Raft Consensus Algorithm
????????Raft 采用一種心跳機制來觸發 leader 選舉,當服務器啟動的時候,都是follow狀態.如果follower在election timeout內沒有收到來自leader的心跳(可能沒有選出leader,也可能leader掛了,或者leader與follower之間網絡故障),則會主動發起選舉.
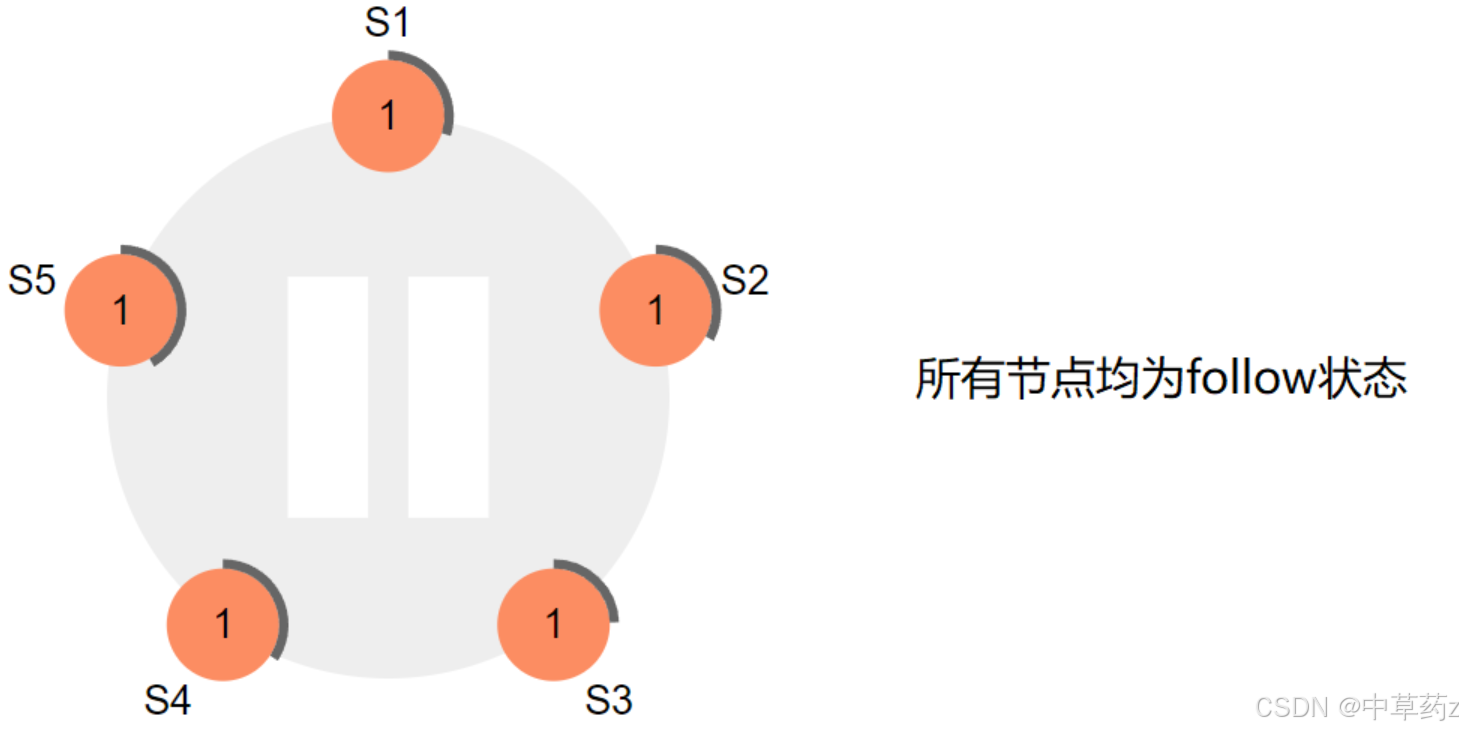
步驟如下:
1、率先超時的節點,自增當前任期號然后切換為 candidate 狀態,并投自己一票
2、以并行的方式發送一個 RequestVote RPCs 給集群中的其他服務器節點(企圖得到它們的投票)
3、等待其他節點的回復

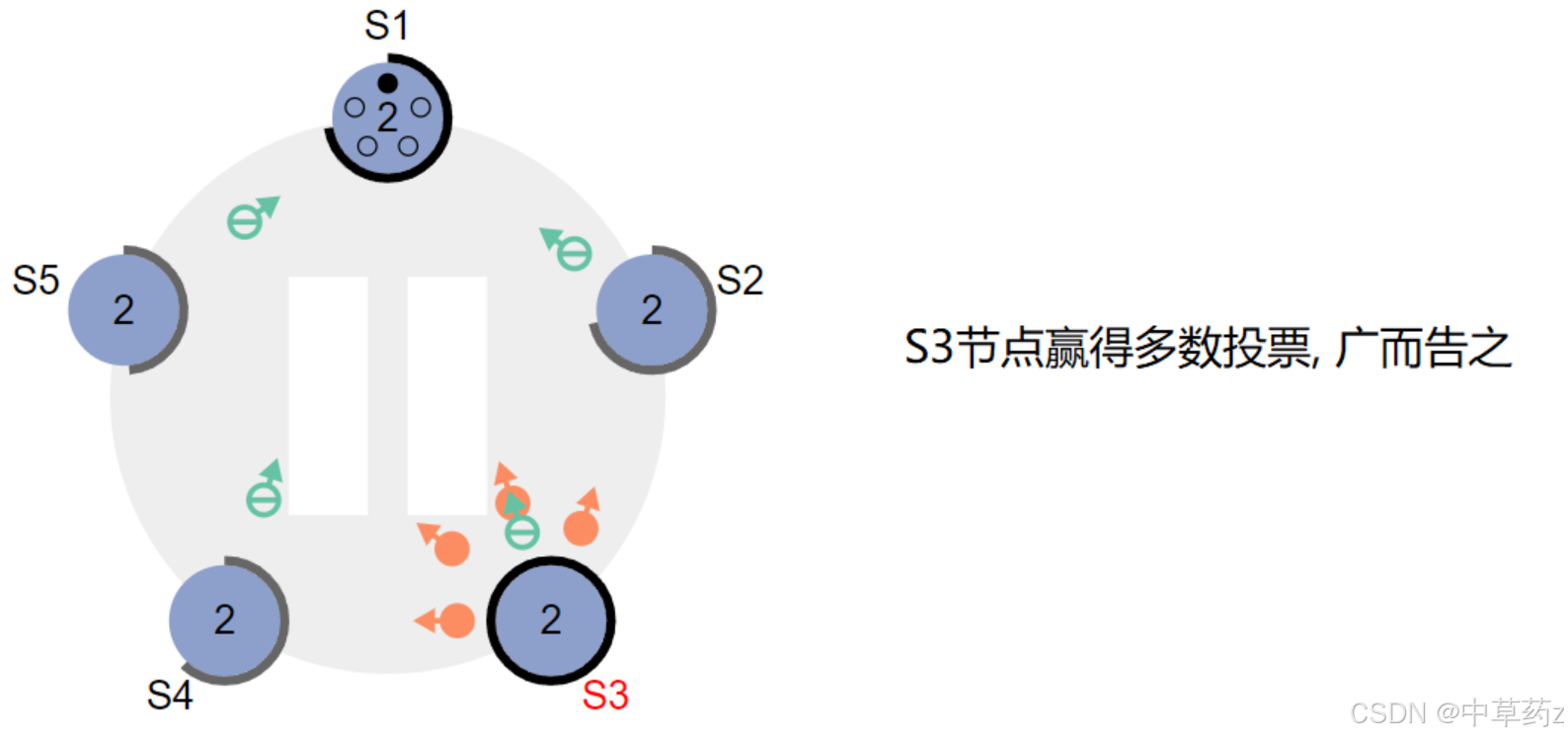
此時可能會出現三種結果
a、贏得選舉,自己成為Leader(包括自己的一票),新的Leader會給其他節點發布消息,避免其余節點觸發新的選舉
b、其他節點贏得了選舉,未成功選舉的節點在接受到消息時,會自動轉化為follower

c、一段時間內沒有收到majority投票,保持candidate狀態,重新發出選舉
????????沒有任何節點獲得majority投票.比如所有的 follower 同時變成 candidate,然后它們都將票投給自己,那這樣就沒有 candidate 能得到超過半數的投票了.當這種情況發生的時候,每個candidate 都會進行一次超時響應,然后通過自增任期號來開啟一輪新的選舉,并啟動另一輪的RequestVote RPCs.如果沒有額外的措施,這種無結果的投票可能會無限重復下去.
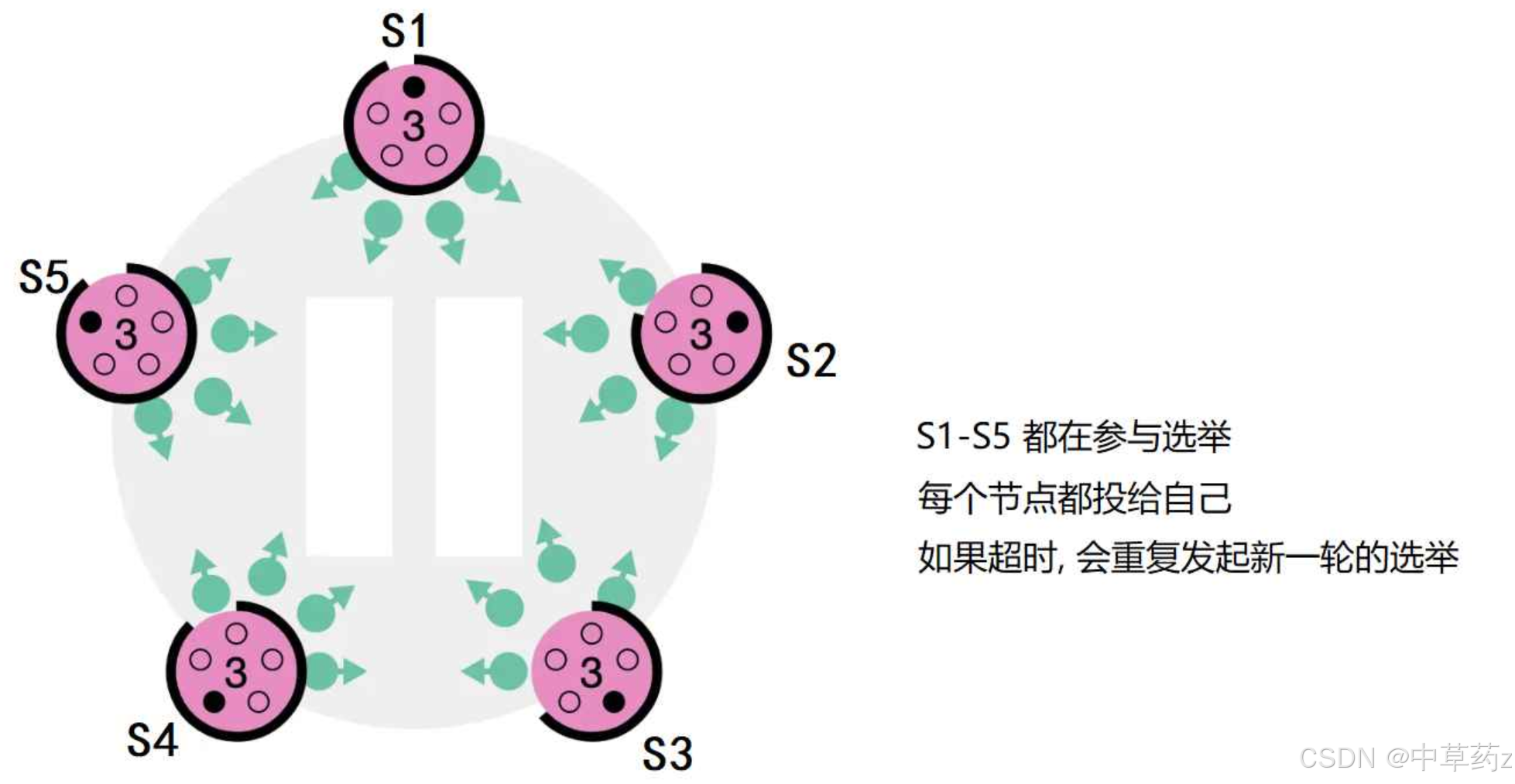
????????為了解決上述問題,Raft 采用 隨機選舉超時時間(randomized election timeouts)來確保很少產生無結果的投票,并且就算發生了也能很快地解決。為了防止選票一開始就被瓜分,選舉超時時間是從一個固定的區間(比如,150-300ms)中隨機選擇。這樣可以把服務器分散開來以確保在大多數情況下會只有一個服務器率先結束超時,那么這個時候,它就可以贏得選舉并在其他服務器結束超時之前發送心跳。
五、仲裁隊列
????????RabbitMQ 的?仲裁隊列(Quorum Queues)?是 RabbitMQ 3.8 版本引入的一種新型隊列類型,專為?高可用性和數據一致性?場景設計。它基于 Raft 一致性協議實現,替代了傳統的鏡像隊列(Mirrored Queues),在節點故障時能更可靠地保證數據安全。
? ? ? ? 在集群環境之中,如果某一節點宕機故障,其中原本的信息也會發生丟失,仲裁隊列可以在rabbitmq之間進行隊列數據的復制,保障集群系統的高可用性。
節點宕機之前

節點宕機后,消息丟失了?


使用仲裁隊列
@Bean("quorumQueue")
public Queue quorumQueue() {return QueueBuilder.durable("quorum_queue").quorum().build();
}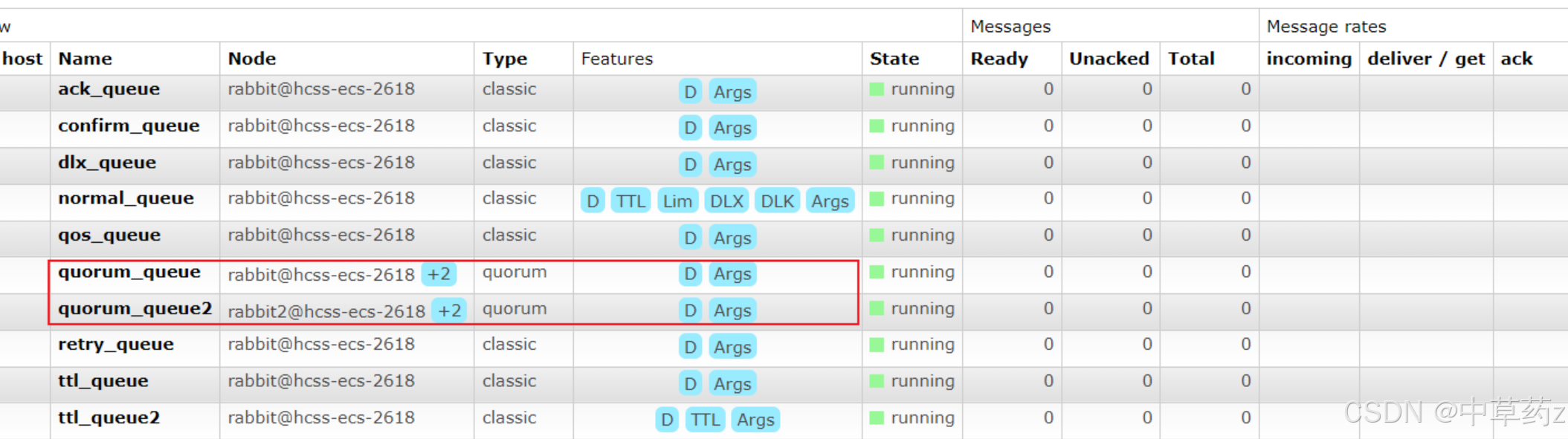
可以觀察到,仲裁隊列后面有一個+2,表示隊列中有兩個鏡像節點,點進去可以看到隊列詳細
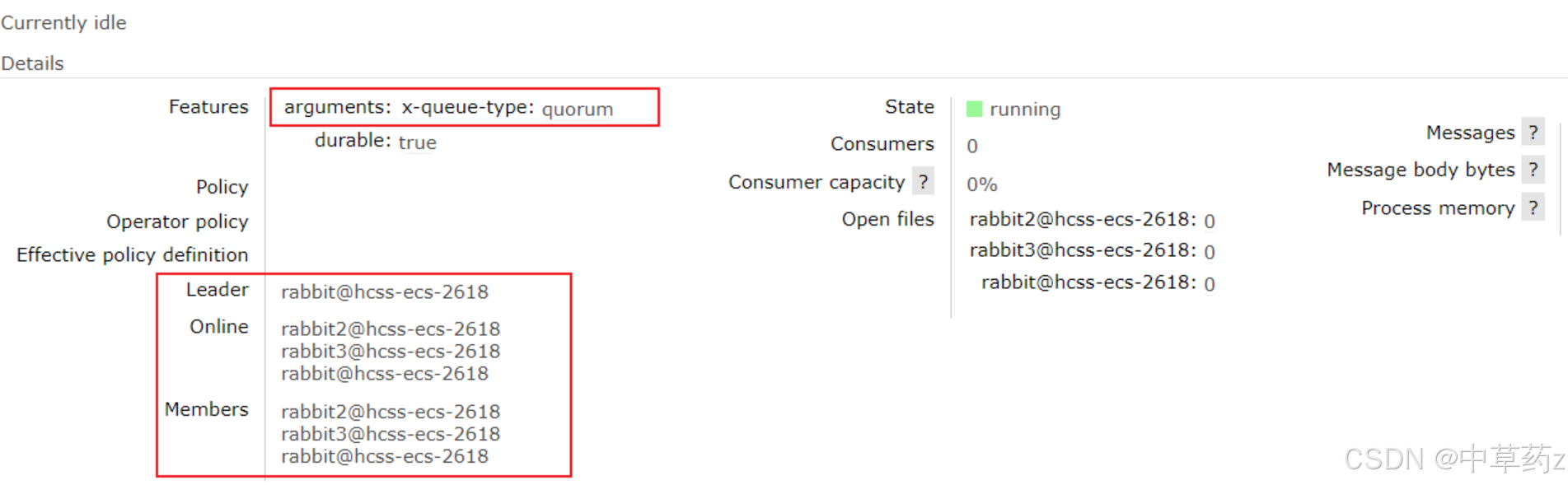
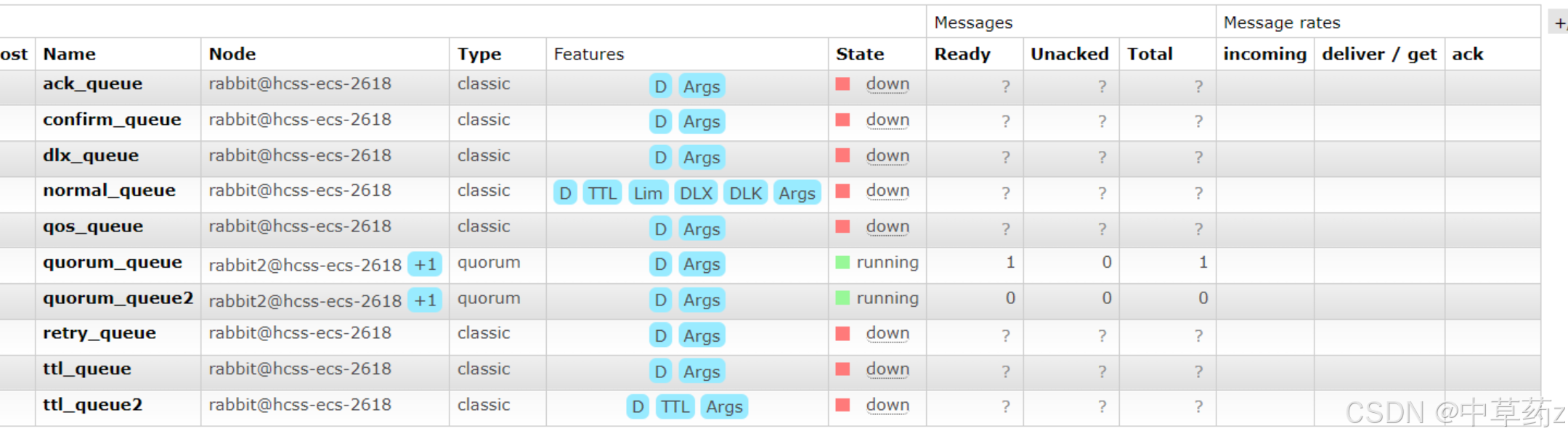
此時如果發生單個節點宕機,隊列里的消息不會丟失
六、HAProxy負載均衡
????????面對大量的業務訪問,高并發請求,試想如果一個集群中有3個節點,我們在寫代碼時,訪問哪個節點呢?
答案是訪問任何一個節點都可以.
這時候就存在兩個問題:
1、如果我們訪問的是node1,但是node1掛了,咱們的程序也會出現問題,所以最好是有一個統一的入口,一個節點故障時,流量可以及時轉移到其他節點.
2、如果所有的客戶端都與node1建議連接,那么node1的網絡負載必然會大大增加,而其他節點又由于沒有那么多的負載而造成硬件資源的浪費.
? ? ? ? 這時,負載均衡顯得尤為重要,HAProxy(High Availability Proxy)是一款開源的?高性能TCP/HTTP負載均衡器?和?反向代理,廣泛用于分發流量、提升系統可用性和擴展性。
快速上手
Ubuntu安裝
#更新軟件包
sudo apt-get update#查找haproxy
sudo apt listlgrep haproxy#安裝haproxy
sudo apt-get install haproxy驗證安裝
#查看服務狀態
sudo systemctl status haproxy#查看版本
haproxy -v#如果要設置HAProxy服務開機自啟,可以使用
sudo systemctl enable haproxy?修改haproxy.cfg
vim /etc/haproxy/haproxy.cfg
# haproxy web 管理界面
listen stats #設置一個監聽器,統計HAProxy的統計信息bind *:8100 #指定了監聽器綁定到的IP地址和端口mode http #監聽器的工作模式為HTTPstats enable #啟用統計頁面stats realm Haproxy\ Statisticsstats uri /stats auth admin:admin #登錄賬號密碼
# 配置負載均衡
Listen rabbitmgbind *:5670mode tcp #Rabbitmq使用的AMQP協議是一個基于TCP的協議balance roundrobin #制定負載均衡策略為輪詢server rabbitmgl 127.0.0.1:5672 check inter 5000 rise 2 fall 3server rabbitmq2 127.0.0.1:5673 check inter 5000 rise 2 fall 3server rabbitmg3 127.0.0.1:5674 check inter 5000 rise 2 fall 3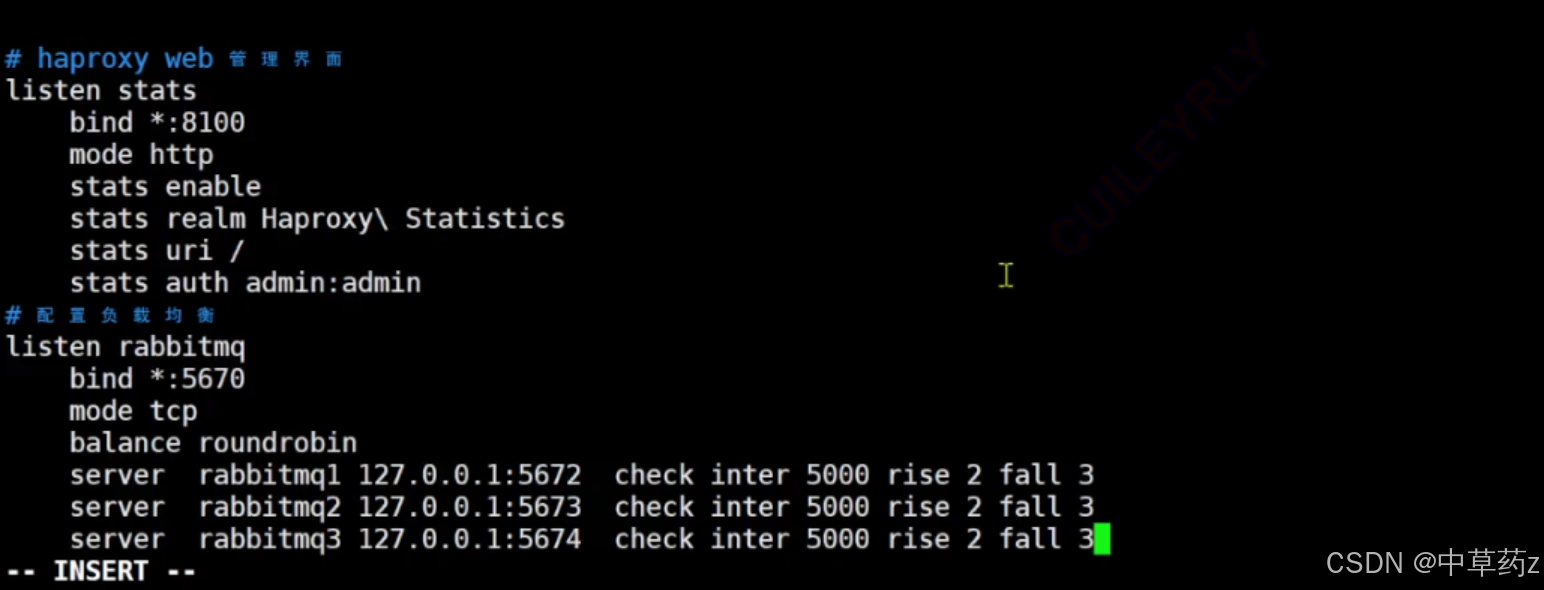
重啟HAProxy
sudo systemctl restart haproxy此時可以通過訪問 http://ip:8100/? 查看HAProxy
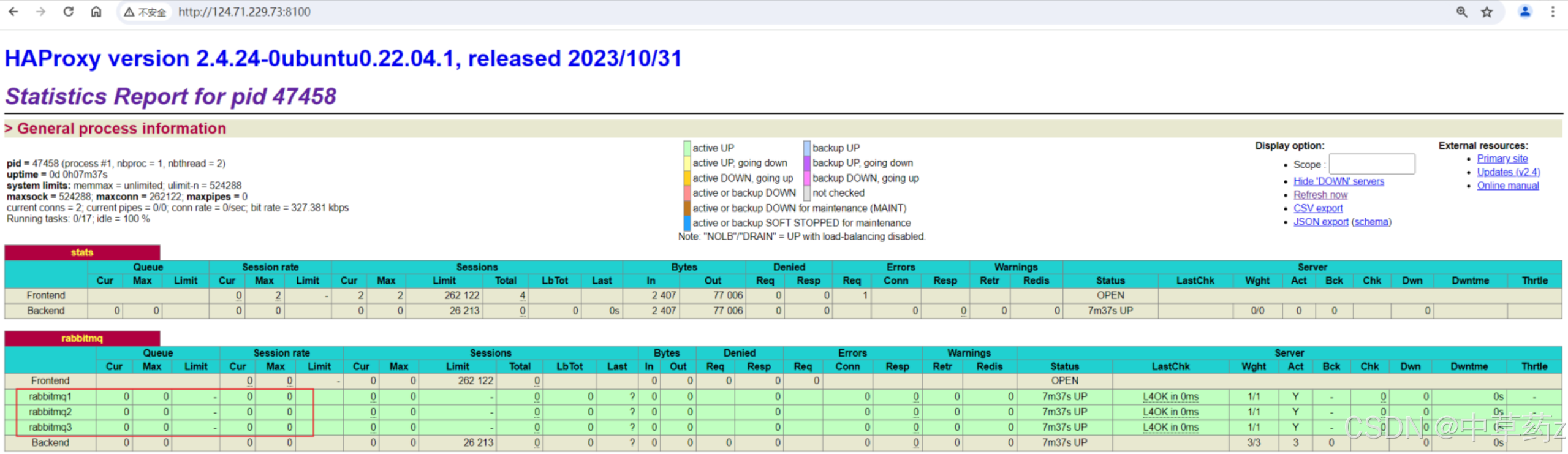
修改配置文件
spring:rabbitmq:addresses: amqp://study:study@ip:5670/Test此時成功實現了負載均衡,也實現了節點宕機后,流量的及時轉移
自信與驕傲有異:信者常沉著,而驕傲者常浮揚。? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ——梁啟超
🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀
以上,就是本期的全部內容啦,若有錯誤疏忽希望各位大佬及時指出💐
? 制作不易,希望能對各位提供微小的幫助,可否留下你免費的贊呢🌸?

)






實現原理和源碼細節是Java高并發面試和實戰開發的重點)




安裝與問題解決指南)
**和**轉換時機(Conversion Time),獲取數據的時機詳解)
)



