介紹
Elasticsearch , 簡稱 ES ,它是個開源分布式搜索引擎,它的特點有:分布式,零配置,自動發現,索引自動分片,索引副本機制,restful 風格接口,多數據源,自動搜索負載等。它可以近乎實時的存儲、檢索數據;本身擴展性很好,可以擴展到上百臺服務器,處理 PB 級別的數據。 es 也使用 Java 開發并使用 Lucene 作為其核心來實現所有索引和搜索的功能,但是它的目的是通過簡單的 RESTful API 來隱藏 Lucene 的復雜性,從而讓全文搜索變得簡單。
Elasticsearch 是面向文檔 (document oriented) 的,這意味著它可以存儲整個對象或文檔 。然而它不僅僅是存儲,還會索引 (index) 每個文檔的內容使之可以被搜索。在 Elasticsearch 中,你可以對文檔(而非成行成列的數據)進行索引、搜索、排序、過濾。
安裝
安裝?Elasticsearch
# 添加倉庫秘鑰
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
# 上邊的添加方式會導致一個 apt-key 的警告,但是不影響# 添加鏡像源倉庫
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elasticsearch.list
# 更新軟件包列表
sudo apt update
# 安裝 es
sudo apt-get install elasticsearch=7.17.21
# 啟動 es
sudo systemctl start elasticsearch
# 安裝 ik 分詞器插件
sudo /usr/share/elasticsearch/bin/elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/7.17.21
重新啟動 elasticsearch,查看其是否正常運行
sudo systemctl start elasticsearch
sudo systemctl status elasticsearch.service
設置外網訪問:如果新配置完成的話,默認只能在本機進行訪問。
sudo vim /etc/elasticsearch/elasticsearch.yml 新增配置
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"] 瀏覽器訪問 http://自己主機的ip:9200/
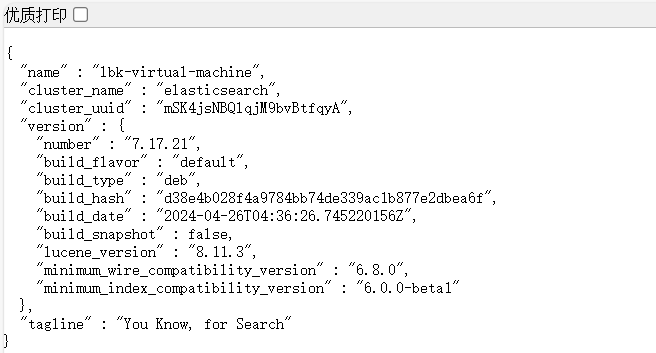
安裝 Kibana
Kibana 是 Elasticsearch 的官方數據可視化和管理工具,通常與 Elasticsearch 配合使用。以下是關于它的核心解釋和常見使用場景:
Kibana 的核心作用
-
數據可視化:通過圖表、儀表盤(Dashboards)展示 Elasticsearch 中的索引數據,支持柱狀圖、折線圖、地圖、詞云等多種可視化形式。
-
數據探索:使用?Discover?功能直接搜索和過濾 Elasticsearch 中的數據,支持全文搜索、字段過濾、時間范圍篩選等。
-
索引管理:在?Management?中管理 Elasticsearch 的索引、設置索引生命周期(ILM)、定義字段映射(Mapping)等。
-
監控與告警:監控 Elasticsearch 集群的健康狀態(如節點狀態、分片分布),配置告警規則(Alerting),例如磁盤空間不足時觸發通知。
-
開發工具:內置?Dev Tools,可直接編寫和執行 Elasticsearch 的 REST API 請求(如?
GET /_cat/indices)。
使用 apt 命令安裝 Kibana 。
sudo apt install kibana 配置 Kibana (可選):
根據需要配置 Kibana。配置文件通常位于 /etc/kibana/kibana.yml。可能需要設置如服務器地址、端口、Elasticsearch URL 等。
sudo vim /etc/kibana/kibana.yml
#添加以下配置
elasticsearch.host: "http://localhost:9200"
server.port: 5601
server.host: "0.0.0.0"
重新啟動 Kibana
sudo systemctl restart kibana
sudo systemctl enable kibana
sudo systemctl status kibana 訪問 Kibana :
在瀏覽器中訪問 Kibana ,通常是 http://<your-ip>:5601
ES 客戶端的安裝
代碼: https://github.com/seznam/elasticlient
官網: https://seznam.github.io/elasticlient/index.html
ES C++ 的客戶端選擇并不多, 我們這里使用 elasticlient 庫 , 下面進行安裝。
# 克隆代碼
git clone https://github.com/seznam/elasticlient
# 切換目錄
cd elasticlient
# 更新子模塊
git submodule update --init --recursive
# 編譯代碼
mkdir build
cd build
# 需要安裝 MicroHTTPD 庫
sudo apt-get install libmicrohttpd-dev
cmake -DCMAKE_INSTALL_PREFIX=/usr ..
make
# 安裝
make install
ES 核心概念
索引(Index)
一個索引就是一個擁有幾分相似特征的文檔的集合,類似數據庫中的“庫” 。比如說,你可以有一個客戶數據的索引,一個產品目錄的索引,還有一個訂單數據的索引。一個索引由一個名字來標識(必須全部是小寫字母的),并且當我們要對應于這個索引中的文檔進行索引、搜索、更新和刪除的時候,都要使用到這個名字。在一個集群中,可以定義任意多的索引。
類型(Type)
在一個索引中,你可以定義一種或多種類型。一個類型是你的索引的一個邏輯上的分類/分區,其語義完全由你來定,類似數據庫中的“表” 。通常,會為具有一組共同字段的文檔定義一個類型。比如說,我們假設你運營一個博客平臺并且將你所有的數據存儲到一個索引中。在這個索引中,你可以為用戶數據定義一個類型,為博客數據定義另一個類型,為評論數據定義另一個類型。不過在? 7.x 版本后已棄用。
字段(Field)
字段相當于是數據表的字段,對文檔數據根據不同屬性進行的分類標識。

| 分類 | 類型 | 備注 |
| 字符串 | text, keyword | text 會被分詞生成索引,keyword 不會被分詞生成索引,只能精確值搜索 |
| 整形 | integer, long, short, byte | |
| 浮點 | double , float | |
| 邏輯 | boolean | true 或 false |
| 日期 | date, date_nanos | “2018-01-13” 或 “2018-01-13 12:10:30” 或者時間戳,即 1970 到現在的秒數 / 毫秒數 |
| 二進制 | binary | 二進制通常只存儲,不索引 |
| 范圍 | range |
映射(mapping)
映射是在處理數據的方式和規則方面做一些限制,如某個字段的數據類型、默認值、分析器、是否被索引等等,這些都是映射里面可以設置的,其它就是處理 es 里面數據的一些使用規則設置也叫做映射,按著最優規則處理數據對性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能對性能更好。
| 名稱 | 數值 | 備注 |
| enabled | true(默認) | false | 是否僅作存儲,不做搜索和分析 |
| index | true( 默認 ) | false | 是否構建倒排索引(決定了是否分詞,是否被索引) |
| index_option | ||
| dynamic | true(默認)| false | 控制 mapping 的自動更新 |
| doc_value | true(默認) | false | 是否開啟 doc_value ,用戶聚合和排序分析,分詞字段不能使用 |
| fielddata | fielddata: {"format": "disabled"} | 是否為 text 類型啟動 fielddata,實現排序和聚合分析。針對分詞字段,參與排序或聚合時能提高性能,不分詞字段統一建議使用 doc_value。 |
| store | true | false(默認) | 是否單獨設置此字段的存儲而從 _source 字段中分離,只能搜索,不能獲取值 |
| coerce | true(默認) | false | 是否開啟自動數據類型轉換功能,比如:字符串轉數字,浮點轉整型 |
| analyzer | "analyzer": "ik" | 指定分詞器,默認分詞器為 standard?analyzer |
| boost | "boost": 1.23 | 字段級別的分數加權,默認值是 1.0 |
| fields | "fields": { ????????"raw": { ????????????????"type":"text", ????????????????"index":"not_analyzed" ????????????????} ????????} | 對一個字段提供多種索引模式,同一個字段的值,一個分詞,一個不分詞 |
| data_detection | true( 默認 ) | false | 是否自動識別日期類型 |
文檔 (document)
一個文檔是一個可被索引的基礎信息單元。比如,你可以擁有某一個客戶的文檔,某一個產品的一個文檔或者某個訂單的一個文檔。文檔以 JSON ( Javascript Object Notation)格式來表示,而 JSON 是一個到處存在的互聯網數據交互格式。在一個 index/type 里面,你可以存儲任意多的文檔。一個文檔必須被索引或者賦予一個索引的 type 。
Elasticsearch 與傳統關系型數據庫相比如下:
ES 客戶端的使用示例
在瀏覽器中訪問 Kibana,通常是 http://<your-ip>:5601,在工具頁面進行編碼,使用以下語句:
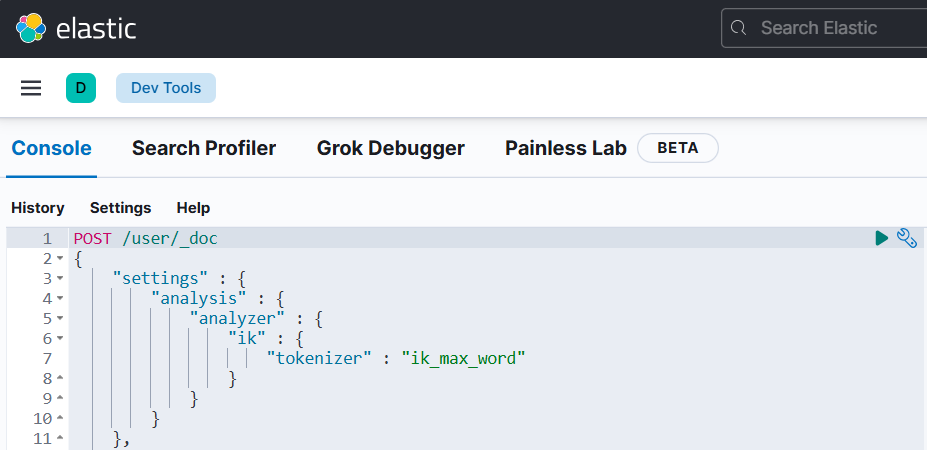
#創建索引并配置字段和映射
POST /user/_doc
{"settings" : {"analysis" : {"analyzer" : {"ik" : {"tokenizer" : "ik_max_word"}}}},"mappings":{"dynamic" : true,"properties":{"nickname" : {"type" : "text","analyzer" : "ik_max_word"},"user_id" : {"type" : "keyword","analyzer" : "standard"},"phone" : {"type" : "keyword","analyzer" : "standard"},"description" : {"type" : "text","enabled" : false},"avatar_id":{"type" : "keyword","enabled" : false}}}
}#新增數據
POST /user/_doc/_bulk
{"index":{"_id":"1"}}
{"user_id" : "USER4b862aaa-2df8654a-7eb4bb65-e3507f66","nickname" : "昵稱 1","phone" : "手機號 1","description" : "簽名 1","avatar_id" : "頭像 1"}
{"index":{"_id":"2"}}
{"user_id" : "USER14eeeaa5-442771b9-0262e455-e4663d1d","nickname" : "昵稱 2","phone" : "手機號 2","description" : "簽名 2","avatar_id" : "頭像 2"}
{"index":{"_id":"3"}}
{"user_id" : "USER484a6734-03a124f0-996c169d-d05c1869","nickname" : "昵稱 3","phone" : "手機號 3","description" : "簽名 3","avatar_id" : "頭像 3"}
{"index":{"_id":"4"}}
{"user_id" : "USER186ade83-4460d4a6-8c08068f-83127b5d","nickname" : "昵稱 4","phone" : "手機號 4","description" : "簽名 4","avatar_id" : "頭像 4"}
{"index":{"_id":"5"}}
{"user_id" : "USER6f19d074-c33891cf-23bf5a83-57189a19","nickname" : "昵稱 5","phone" : "手機號 5","description" : "簽名 5","avatar_id" : "頭像 5"}
{"index":{"_id":"6"}}
{"user_id" : "USER97605c64-9833ebb7-d0455353-35a59195","nickname" : "昵稱 6","phone" : "手機號 6","description" : "簽名 6","avatar_id" : "頭像 6"}
main.cc
#include <elasticlient/client.h>
#include <cpr/cpr.h>
#include <iostream>
int main()
{// 1. 構建ES客戶端elasticlient::Client client({"http://127.0.0.1:9200/"});// 2. 發起搜索請求try{auto rsp = client.search("user", "_doc", "{\"query\":{\"match_all\":{}}}");std::cout << rsp.status_code << std::endl;std::cout << rsp.text << std::endl;}catch (const std::exception &e){std::cerr << "請求失敗:" << e.what() << '\n';return -1;}return 0;
}makefile
main : main.ccg++ -o $@ $^ -std=c++17 -lcpr -lelasticlientES 客戶端 API 二次封裝
封裝客戶端 api 主要是因為,客戶端只提供了基礎的數據存儲獲取調用功能,無法根據我們的思想完成索引的構建,以及查詢正文的構建,需要使用者自己組織好 json 進行序列化后才能作為正文進行接口的調用。而封裝的目的就是簡化用戶的操作,將索引的 json 正文構造,以及查詢搜索的正文構造操作給封裝起來,使用者調用接口添加字段就行,不用關心具體的 json 數據格式。
封裝內容:
- 索引構造過程的封裝:索引正文構造過程,大部分正文都是固定的,唯一不同的地方是各個字段不同的名稱以及是否只存儲不索引這些選項,因此重點關注以下幾個點即可:
- 字段類型:type : text / keyword (目前只用到這兩個類型)
- 是否索引:enable : true/false
- 索引的話分詞器類型: analyzer : ik_max_word / standard
- 新增文檔構造過程的封裝:新增文檔其實在常規下都是單條新增,并非批量新增,因此直接添加字段和值就行
- 文檔搜索構造過程的封裝:搜索正文構造過程,我們默認使用條件搜索,我們主要關注的兩個點:
- 應該遵循的條件是什么:should 中有什么
- 條件的匹配方式是什么:match 還是 term/terms,還是 wildcard
- 過濾的條件字段是什么:must_not 中有什么
- 過濾的條件字段匹配方式是什么:match 還是 wildcard,還是 term/terms
整個封裝的過程其實就是對 Json::Value 對象的一個組織的過程,并無太大的難點。
#pragma once
#include <elasticlient/client.h>
#include <json/json.h>
#include <iostream>
#include <memory>
#include <sstream>
#include <cpr/cpr.h>
#include "logger.hpp"bool Serialize(const Json::Value &val, std::string &dst)
{// 先定義Json::StreamWriter 工廠類 Json::StreamWriterBuilderJson::StreamWriterBuilder swb;swb.settings_["emitUTF8"] = true;std::unique_ptr<Json::StreamWriter> sw(swb.newStreamWriter());// 通過Json::StreamWriter中的write接口進行序列化std::stringstream ss;int ret = sw->write(val, &ss);if (ret != 0){std::cout << "Json反序列化失敗!\n";return false;}dst = ss.str();return true;
}
bool UnSerialize(const std::string &src, Json::Value &val)
{Json::CharReaderBuilder crb;crb.settings_["emitUTF8"] = true;std::unique_ptr<Json::CharReader> cr(crb.newCharReader());std::string error;bool ret = cr->parse(src.c_str(), src.c_str() + src.size(), &val, &error);if (ret == false){std::cout << "json反序列化失敗: " << error << std::endl;return false;}return true;
}
class ESIndex
{
public:ESIndex(std::shared_ptr<elasticlient::Client> &client,const std::string &name, const std::string &type = "_doc") : _name(name), _type(type), _client(client){Json::Value analysis;Json::Value analyzer;Json::Value ik;Json::Value tokenizer;tokenizer["tokenizer"] = "ik_max_word";ik["ik"] = tokenizer;analyzer["analyzer"] = ik;analysis["analysis"] = analyzer;_index["settings"] = analysis;}ESIndex &append(const std::string &key, const std::string &type = "text",const std::string &analyzer = "ik_max_word", bool enabled = true){Json::Value fields;fields["type"] = type;fields["analyzer"] = analyzer;if (enabled == false)fields["enabled"] = false;_properties[key] = fields;return *this;}bool create(const std::string &index_id = "default_index_id"){Json::Value mappings;mappings["dynamic"] = true;mappings["properties"] = _properties;_index["mappings"] = mappings;std::string body;bool ret = Serialize(_index, body);if (ret == false){LOG_ERROR("索引序列化失敗!");return false;}LOG_DEBUG("{}", body);try{auto rsp = _client->index(_name, _type, index_id, body);if (rsp.status_code < 200 || rsp.status_code >= 300){LOG_ERROR("創建ES索引{}失敗,響應狀態碼異常:{}", _name, rsp.status_code);return false;}}catch (const std::exception &e){LOG_ERROR("創建ES索引{}失敗:{}", _name, e.what());return false;}return true;}private:std::shared_ptr<elasticlient::Client> _client;std::string _name;std::string _type;Json::Value _index;Json::Value _properties;
};class ESInsert
{
public:ESInsert(std::shared_ptr<elasticlient::Client> &client,const std::string &name, const std::string &type = "_doc") : _name(name), _type(type), _client(client){}template <typename T>ESInsert &append(const std::string &key, const T &val){_item[key] = val;return *this;}bool insert(const std::string id = ""){std::string body;bool ret = Serialize(_item, body);if (ret == false){LOG_ERROR("索引序列化失敗!");return false;}LOG_DEBUG("{}", body);try{auto rsp = _client->index(_name, _type, id, body);if (rsp.status_code < 200 || rsp.status_code >= 300){LOG_ERROR("新增數據{}失敗,響應狀態碼異常:{}", body, rsp.status_code);return false;}}catch (const std::exception &e){LOG_ERROR("新增數據{}失敗:{}", body, e.what());return false;}return true;}private:std::shared_ptr<elasticlient::Client> _client;std::string _name;std::string _type;Json::Value _item;
};class ESRemove
{
public:ESRemove(std::shared_ptr<elasticlient::Client> &client,const std::string &name, const std::string &type= "_doc"): _client(client), _name(name), _type(type){}bool remove(const std::string &id){try{auto rsp = _client->remove(_name, _type, id);if (rsp.status_code < 200 || rsp.status_code >= 300){LOG_ERROR("刪除數據{}失敗,響應狀態碼異常:{}", id, rsp.status_code);return false;}}catch (const std::exception &e){LOG_ERROR("刪除數據{}失敗:{}", id, e.what());return false;}return true;}private:std::shared_ptr<elasticlient::Client> _client;std::string _name;std::string _type;
};class ESSearch
{
public:ESSearch(std::shared_ptr<elasticlient::Client> &client,const std::string &name, const std::string &type= "_doc"): _client(client), _name(name), _type(type){}ESSearch &append_must_not_terms(const std::string &key, const std::vector<std::string> &vals){Json::Value fields;for (const auto &val : vals){fields[key].append(val);}Json::Value terms;terms["terms"] = fields;_must_not.append(terms);return *this;}ESSearch &append_must_term(const std::string &key, const std::string &val){Json::Value field;field[key] = val;Json::Value term;term["terms"] = field;_must.append(term);return *this;}ESSearch &append_must_match(const std::string &key, const std::string &val){Json::Value field;field[key] = val;Json::Value match;match["match"] = field;_must.append(match);return *this;}ESSearch &append_should_match(const std::string &key, const std::string &val){Json::Value field;field[key] = val;Json::Value match;match["match"] = field;_should.append(match);return *this;}Json::Value search(){Json::Value cond;if (_must_not.empty() == false)cond["must_not"] = _must_not;if (_must.empty() == false)cond["must"] = _must;if (_should.empty() == false)cond["should"] = _should;Json::Value query;query["bool"] = cond;Json::Value root;root["query"] = query;std::string body;bool ret = Serialize(root, body);if (ret == false){LOG_ERROR("索引序列化失敗!");return Json::Value();}LOG_DEBUG("{}", body);cpr::Response rsp;try{rsp = _client->search(_name, _type, body);if (rsp.status_code < 200 || rsp.status_code >= 300){LOG_ERROR("檢索數據{}失敗,響應狀態碼異常:{}", body, rsp.status_code);return Json::Value();}}catch (const std::exception &e){LOG_ERROR("刪除數據{}失敗:{}", body, e.what());return Json::Value();}LOG_DEBUG("檢索響應正文:{}", rsp.text);Json::Value json_rsp;ret = UnSerialize(rsp.text, json_rsp);if (ret == false){LOG_ERROR("檢索數據 {} 結果反序列化失敗", rsp.text);return Json::Value();}return json_rsp["hits"]["hits"];}private:std::shared_ptr<elasticlient::Client> _client;std::string _name;std::string _type;Json::Value _must_not;Json::Value _must;Json::Value _should;
};makefile
main : main.cc g++ -std=c++17 $^ -o $@ -lcpr -lelasticlient -lspdlog -lfmt -lgflags -ljsoncpp

深度學習中的損失函數優化技巧)
















