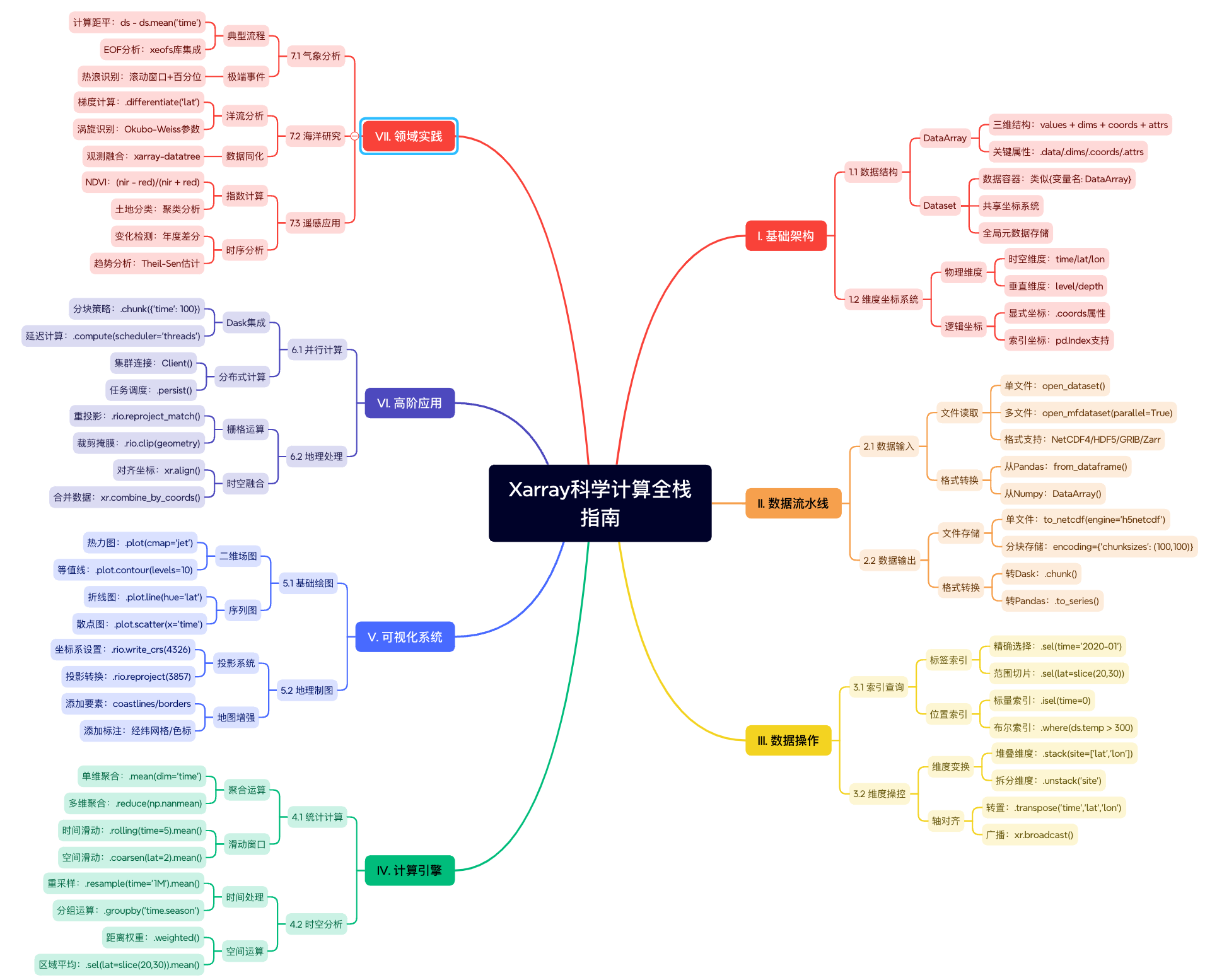
目錄
- xarray 數據處理教程:從入門到精通
- 一、簡介
- **核心優勢**
- 二、安裝與導入
- 1. 安裝
- 2. 導入庫
- 三、數據結構
- (一)DataArray
- (二) Dataset
- (三)關鍵說明
- 四、數據操作
- (一)索引與切片
- 1. 基于標簽選擇(`.sel()`)
- 2. 基于位置選擇(`.isel()`)
- **3. `.sel()` 和 `.isel()` 聯合使用**
- **4. 多維選擇與切片**
- 5. 關鍵說明
- (二) 數據計算
- 1. 聚合運算
- (1) 計算單個維度的平均值
- (2) 計算多個維度的平均值
- (3) 計算單個維度的標準差
- (4) 計算多個維度的標準差
- (5) 忽略缺失值計算統計量
- (6) 關鍵說明
- 2. 算術運算
- **3. 數據重塑**
- (1) `.stack()`:將多個維度堆疊成一個新維度
- (2) `.transpose()`:調整維度順序
- (3) `.stack()` + `.transpose()` 聯合使用
- (4) 關鍵說明
- 4. 數據聚合
- 5. 合并兩個數據集
- 6. 應用自定義函數
- **五、數據可視化**
- (一)二維分布圖
- (二)時間序列圖
- 六、高級功能
- (一) 缺失值處理
- 1. 填充缺失值
- 2. 插值
- (二) 時間重采樣
- (三)地理信息處理
- 1. 設置坐標系
- 2. 繪制地理投影圖
- 七、數據輸入與輸出
- (一)讀取 NetCDF 文件
- (二)保存數據
- 八、性能優化
- (一)分塊處理(Dask)
- (二) 內存優化
- 九、總結
- (一)核心流程
- (二)關鍵優勢
- (三)注意事項
xarray 數據處理教程:從入門到精通
一、簡介
xarray 是 Python 中用于處理多維數組數據的庫,特別適用于帶有標簽(坐標)的科學數據(如氣象、海洋、遙感等)。它基于 NumPy 和 Pandas,支持高效的數據操作、分析和可視化。
核心優勢
- 標簽化操作:通過維度名和坐標直接訪問數據,無需記憶索引位置。
- 多維支持:天然支持多維數組(如時間、緯度、經度)。
- 集成工具:內置 NetCDF、HDF5 等格式讀寫,支持 Dask 處理大文件。
- 可視化:與 Matplotlib 深度集成,簡化數據繪圖流程。
二、安裝與導入
1. 安裝
pip install xarray netCDF4 dask rioxarray
或使用 Conda:
conda install -c conda-forge xarray netCDF4 dask rioxarray
2. 導入庫
import xarray as xr
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
三、數據結構
(一)DataArray
- 定義:帶坐標的 N 維數組,類似帶標簽的 NumPy 數組。
- 示例代碼
import xarray as xr
import numpy as npdata = np.random.rand(12, 5, 100, 200)
coords = {'time': np.arange(12),'sample': np.arange(5),'lat': np.linspace(-90, 90, 100),'lon': np.linspace(-180, 180, 200)
}
da = xr.DataArray(data, dims=['time', 'sample', 'lat', 'lon'], coords=coords)
- 輸出結果
<xarray.DataArray (time: 12, sample: 5, lat: 100, lon: 200)>
array([[[[...]], # 12個時間步 × 5個樣本 × 100緯度 × 200經度的隨機值...,[[...]]],...,[[...]]])
Coordinates:* time (time) int64 0 1 2 ... 11* sample (sample) int64 0 1 2 3 4* lat (lat) float64 -90.0 -89.1 -88.2 ... 88.2 89.1 90.0* lon (lon) float64 -180.0 -179.1 -178.2 ... 178.2 179.1 180.0
- 表1:數據結構DataArray
| 操作/方法 | 功能 | 輸入參數 | 輸出參數 |
|---|---|---|---|
xarray.DataArray | 創建帶有維度和坐標的多維數組(如海溫數據) | data: 數組數據;dims: 維度名列表;coords: 坐標字典 | 生成的 xarray.DataArray 對象 |
(二) Dataset
-
定義:類似字典的容器,包含多個
DataArray(變量),共享坐標。 -
表:xarray.Dataset 操作總結
| 操作/方法 | 功能 | 輸入參數 | 輸出參數 |
|---|---|---|---|
xr.Dataset | 創建多變量數據集 | 變量字典、坐標字典 | xarray.Dataset 對象 |
.sel() / .isel() | 按標簽或索引選擇數據 | 維度名和值 | 子數據集或子數組 |
.mean() / .std() | 計算維度統計量 | 需求平均的維度名 | 統計后的數據集或數據數組 |
.to_netcdf() | 保存為 NetCDF 文件 | 文件路徑和寫入模式 | 無返回值(保存文件) |
xr.open_dataset() | 讀取 NetCDF 文件 | 文件路徑和讀取引擎 | xarray.Dataset 對象 |
.merge() | 合并兩個數據集 | 另一個 Dataset 對象 | 合并后的 xarray.Dataset |
.apply() | 應用自定義函數 | 自定義函數和輸入維度 | 應用后的數據集 |
.chunk() | 設置數據分塊 | 分塊大小字典 | 分塊后的 xarray.Dataset |
- 創建示例:
import xarray as xr
import numpy as np
import pandas as pdds = xr.Dataset({"temperature": (["time", "lat", "lon"], np.random.rand(3, 10, 20)),"humidity": (["time", "lat", "lon"], np.random.rand(3, 10, 20)),},coords={"time": pd.date_range("2025-01-01", periods=3),"lat": np.linspace(-90, 90, 10),"lon": np.linspace(-180, 180, 20),}
)
- 輸出結果:
<xarray.Dataset>
Dimensions: (time: 3, lat: 10, lon: 20)
Coordinates:* time (time) datetime64[ns] 2025-01-01 2025-01-02 ...* lat (lat) float64 -90.0 -81.0 ... 81.0 90.0* lon (lon) float64 -180.0 -171.0 ... 171.0 180.0
Data variables:temperature (time, lat, lon) float64 0.1234 0.5678 ...humidity (time, lat, lon) float64 0.9876 0.4321 ...
(三)關鍵說明
- Dataset vs DataArray:
xarray.Dataset適合處理多變量數據(如溫度、濕度、降水)。xarray.DataArray適合單一變量的多維數組操作。
- 工作流示例:
# 讀取數據并選擇子集 ds = xr.open_dataset("data.nc") subset = ds.sel(lat=slice(-90, -60), lon=slice(-180, -120))# 計算統計量并保存 mean_ds = subset.mean(dim="time") mean_ds.to_netcdf("mean_data.nc")
四、數據操作
(一)索引與切片
表:索引與切片
| 操作/方法 | 功能 | 輸入參數 | 輸出參數 |
|---|---|---|---|
.isel() / .sel() | 快速提取特定維度數據 | isel: 按索引提取;sel: 按坐標標簽提取 | 提取后的子數組(xarray.DataArray) |
1. 基于標簽選擇(.sel())
場景:從數據集中提取特定時間步和緯度范圍的數據。
subset = ds.sel(time="2025-01-01", lat=-90)
輸出結果:
<xarray.Dataset>
Dimensions: (lat: 1, lon: 20)
Coordinates:time datetime64[ns] 2025-01-01lat float64 -90.0lon (lon) float64 -180.0 -171.0 ... 171.0 180.0
Data variables:temperature (lon) float64 0.1234 0.5678 ...humidity (lon) float64 0.9876 0.4321 ...
2. 基于位置選擇(.isel())
場景:從數據集中提取第一個時間步和前三個緯度的數據。
# 按索引位置選擇數據
subset_isel = ds.isel(time=0, lat=slice(0, 3))
輸出結果:
<xarray.Dataset>
Dimensions: (time: 1, lat: 3, lon: 20)
Coordinates:time datetime64[ns] 2025-01-01* lat (lat) float64 -90.0 -76.36 -62.73* lon (lon) float64 -180.0 -171.0 ... 171.0 180.0
Data variables:temperature (time, lat, lon) float64 0.1234 0.5678 ...
3. .sel() 和 .isel() 聯合使用
場景:結合標簽和索引選擇數據(例如,選擇特定時間步和固定經度索引)。
# 按時間標簽和經度索引選擇數據
subset_mixed = ds.sel(time="2025-01-01").isel(lon=0)
輸出結果:
<xarray.Dataset>
Dimensions: (time: 1, lat: 10, lon: 1)
Coordinates:time datetime64[ns] 2025-01-01* lat (lat) float64 -90.0 -81.0 ... 81.0 90.0lon float64 -180.0
Data variables:temperature (time, lat, lon) float64 0.1234 0.5678 ...
4. 多維選擇與切片
場景:同時選擇多個維度(時間、緯度、經度)并使用切片操作。
# 按時間標簽、緯度范圍和經度切片選擇數據
subset_slice = ds.sel(time="2025-01-01",lat=slice(-90, -60),lon=slice(-180, -120)
)
輸出結果:
<xarray.Dataset>
Dimensions: (time: 1, lat: 3, lon: 7)
Coordinates:time datetime64[ns] 2025-01-01* lat (lat) float64 -90.0 -76.36 -62.73* lon (lon) float64 -180.0 -163.6 ... -126.3 -120.0
Data variables:temperature (time, lat, lon) float64 0.1234 0.5678 ...
5. 關鍵說明
-
.sel()vs.isel():.sel():使用坐標標簽(如time="2025-01-01"、lat=-90)進行選擇,適合已知具體坐標的場景。.isel():使用索引位置(如time=0、lat=slice(0, 3))進行選擇,適合已知數組索引的場景。
-
切片操作:
- 可以通過
slice(start, end)實現對維度的范圍選擇(例如lat=slice(-90, -60))。 - 切片是左閉右開的,即包含
start,不包含end。
- 可以通過
-
多維聯合選擇:
- 可以聯合使用
.sel()和.isel(),例如先按標簽選擇時間,再按索引選擇經度。 - 也可以通過鏈式調用實現多步選擇(如
ds.sel(...).isel(...))。
- 可以聯合使用
(二) 數據計算
1. 聚合運算
(1) 計算單個維度的平均值
場景:從數據集中計算時間維度(time)的平均值。
import xarray as xr
import numpy as np
import pandas as pd# 創建示例數據集
ds = xr.Dataset({"temperature": (["time", "lat", "lon"], np.random.rand(3, 10, 20)),"humidity": (["time", "lat", "lon"], np.random.rand(3, 10, 20)),},coords={"time": pd.date_range("2025-01-01", periods=3),"lat": np.linspace(-90, 90, 10),"lon": np.linspace(-180, 180, 20),}
)# 計算時間維度的平均值
mean_time = ds.mean(dim="time")
輸出結果:
<xarray.Dataset>
Dimensions: (lat: 10, lon: 20)
Coordinates:* lat (lat) float64 -90.0 -81.0 -72.0 ... 72.0 81.0 90.0* lon (lon) float64 -180.0 -171.0 -162.0 ... 162.0 171.0 180.0
Data variables:temperature (lat, lon) float64 0.4567 0.8901 ...humidity (lat, lon) float64 0.7654 0.3210 ...
(2) 計算多個維度的平均值
場景:從數據集中計算時間和緯度維度的平均值。
# 計算時間和緯度維度的平均值
mean_time_lat = ds.mean(dim=["time", "lat"])
輸出結果:
<xarray.Dataset>
Dimensions: (lon: 20)
Coordinates:* lon (lon) float64 -180.0 -171.0 -162.0 ... 162.0 171.0 180.0
Data variables:temperature (lon) float64 0.6789 ...humidity (lon) float64 0.5432 ...
(3) 計算單個維度的標準差
場景:從數據集中計算緯度維度(lat)的標準差。
# 計算緯度維度的標準差
std_lat = ds.std(dim="lat")
輸出結果:
<xarray.Dataset>
Dimensions: (time: 3, lon: 20)
Coordinates:* time (time) datetime64[ns] 2025-01-01 ... 2025-01-03* lon (lon) float64 -180.0 -171.0 -162.0 ... 162.0 171.0 180.0
Data variables:temperature (time, lon) float64 0.2345 0.6789 ...humidity (time, lon) float64 0.3456 0.7890 ...
(4) 計算多個維度的標準差
場景:從數據集中計算時間和經度維度的標準差。
# 計算時間和經度維度的標準差
std_time_lon = ds.std(dim=["time", "lon"])
輸出結果:
<xarray.Dataset>
Dimensions: (lat: 10)
Coordinates:* lat (lat) float64 -90.0 -81.0 -72.0 ... 72.0 81.0 90.0
Data variables:temperature (lat) float64 0.1234 ...humidity (lat) float64 0.4567 ...
(5) 忽略缺失值計算統計量
場景:數據集中包含缺失值(NaN),需要在計算時跳過缺失值。
# 創建包含缺失值的數據集
ds_nan = xr.Dataset({"temperature": (["time", "lat", "lon"], np.random.rand(3, 10, 20)),},coords={"time": pd.date_range("2025-01-01", periods=3),"lat": np.linspace(-90, 90, 10),"lon": np.linspace(-180, 180, 20),}
)# 隨機插入缺失值
ds_nan.temperature.values[0, 0, 0] = np.nan# 計算時間維度的平均值(跳過缺失值)
mean_time_skipna = ds_nan.mean(dim="time", skipna=True)
輸出結果:
<xarray.Dataset>
Dimensions: (lat: 10, lon: 20)
Coordinates:* lat (lat) float64 -90.0 -81.0 -72.0 ... 72.0 81.0 90.0* lon (lon) float64 -180.0 -171.0 -162.0 ... 162.0 171.0 180.0
Data variables:temperature (lat, lon) float64 0.4567 0.8901 ...
(6) 關鍵說明
-
.mean()和.std()的區別:.mean():計算指定維度的平均值。.std():計算指定維度的標準差,默認為樣本標準差(ddof=1)。
-
維度選擇:
- 可以指定單個維度(如
dim="time")或多個維度(如dim=["time", "lat"])。 - 維度減少后,輸出數據集的維度會相應調整(如從
(time, lat, lon)變為(lat, lon))。
- 可以指定單個維度(如
-
缺失值處理:
- 通過
skipna=True可以跳過缺失值(NaN)進行計算,避免因缺失值導致整個統計結果為NaN。
- 通過
2. 算術運算
# 溫度乘以 2,降水加 10
new_ds = ds * 2 + 10
3. 數據重塑
總結表格
| 操作/方法 | 功能 | 輸入參數 | 輸出參數 |
|---|---|---|---|
.stack() | 將多個維度堆疊成一個新維度 | new_dim_name: 新維度名;dim: 原始維度列表 | 維度被堆疊后的 xarray.Dataset |
.transpose() | 調整維度順序(不改變維度數量) | *dims: 新維度順序 | 維度順序調整后的 xarray.Dataset |
(1) .stack():將多個維度堆疊成一個新維度
場景:將 lat 和 lon 維度堆疊成一個名為 space 的新維度。
示例代碼
import xarray as xr
import numpy as np
import pandas as pd# 創建示例數據集
ds = xr.Dataset({"temperature": (["time", "lat", "lon"], np.random.rand(3, 10, 20)),},coords={"time": pd.date_range("2025-01-01", periods=3),"lat": np.linspace(-90, 90, 10),"lon": np.linspace(-180, 180, 20),}
)# 將 lat 和 lon 堆疊成 space 維度
stacked_ds = ds.stack(space=["lat", "lon"])
輸出結果:
<xarray.Dataset>
Dimensions: (time: 3, space: 200)
Coordinates:* time (time) datetime64[ns] 2025-01-01 2025-01-02 ...space (space) MultiIndex- lat (space) float64 -90.0 -90.0 ... 90.0 90.0- lon (space) float64 -180.0 -171.0 ... 171.0 180.0
Data variables:temperature (time, space) float64 0.1234 0.5678 ...
(2) .transpose():調整維度順序
場景:將 time, lat, lon 的維度順序調整為 lon, lat, time。
示例代碼:
# 調整維度順序
transposed_ds = ds.transpose("lon", "lat", "time")
輸出結果:
<xarray.Dataset>
Dimensions: (lon: 20, lat: 10, time: 3)
Coordinates:* lon (lon) float64 -180.0 -171.0 ... 171.0 180.0* lat (lat) float64 -90.0 -81.0 ... 81.0 90.0* time (time) datetime64[ns] 2025-01-01 2025-01-02 ...
Data variables:temperature (lon, lat, time) float64 0.1234 0.5678 ...
(3) .stack() + .transpose() 聯合使用
場景:先將 lat 和 lon 堆疊成 space,再調整維度順序為 space, time。
示例代碼:
# 堆疊后調整維度順序
stacked_transposed_ds = ds.stack(space=["lat", "lon"]).transpose("space", "time")
輸出結果:
<xarray.Dataset>
Dimensions: (space: 200, time: 3)
Coordinates:space (space) MultiIndex- lat (space) float64 -90.0 -90.0 ... 90.0 90.0- lon (space) float64 -180.0 -171.0 ... 171.0 180.0* time (time) datetime64[ns] 2025-01-01 2025-01-02 ...
Data variables:temperature (space, time) float64 0.1234 0.5678 ...
(4) 關鍵說明
-
.stack()vs.transpose():.stack():減少維度數量,將多個維度合并為一個新維度(如lat和lon→space)。.transpose():不改變維度數量,僅調整維度的排列順序(如time, lat, lon→lon, lat, time)。
-
應用場景:
.stack():- 將多維數據轉換為二維,便于進行某些計算(如機器學習模型輸入)。
- 簡化高維數據的可視化(如將
lat和lon合并為space后繪圖)。
.transpose():- 調整數據維度順序以匹配其他數據集或模型的輸入格式。
- 提高代碼可讀性,使維度順序更符合邏輯(如先經度后緯度)。
-
注意事項:
.stack()會生成MultiIndex,可通過.unstack()恢復原始維度。.transpose()不會修改原始數據,而是返回一個新對象(惰性操作)。
4. 數據聚合
| 操作/方法 | 功能 | 輸入參數 | 輸出參數 |
|---|---|---|---|
.groupby() / .mean() | 按維度分組計算均值 | group: 分組維度(如 time.month);dim: 聚合維度 | 聚合后的 xarray.DataArray |
.resample() | 時間序列重采樣(如日→月) | freq: 重采樣頻率(如 MS 表示月初);dim: 時間維度名 | 重采樣后的 xarray.DataArray |
示例代碼
# 按月份分組計算均值
monthly_mean = da.groupby("time.month").mean(dim="time")# 時間序列重采樣(日→月)
monthly_resample = da.resample(time="MS").mean()
5. 合并兩個數據集
ds2 = xr.Dataset({"precipitation": (["time", "lat", "lon"], np.random.rand(3, 10, 20))})
ds_merged = ds.merge(ds2)
輸出結果:
<xarray.Dataset>
Dimensions: (time: 3, lat: 10, lon: 20)
Coordinates:* time (time) datetime64[ns] 2025-01-01 2025-01-02 ...* lat (lat) float64 -90.0 -81.0 ... 81.0 90.0* lon (lon) float64 -180.0 -171.0 ... 171.0 180.0
Data variables:temperature (time, lat, lon) float64 0.1234 0.5678 ...humidity (time, lat, lon) float64 0.9876 0.4321 ...precipitation (time, lat, lon) float64 0.3456 0.7890 ...
6. 應用自定義函數
def custom_func(arr):return arr.max() - arr.min()ds_custom = ds.apply(custom_func)
輸出結果:
<xarray.Dataset>
Dimensions: (time: 3, lat: 10, lon: 20)
Coordinates:* time (time) datetime64[ns] 2025-01-01 2025-01-02 ...* lat (lat) float64 -90.0 -81.0 ... 81.0 90.0* lon (lon) float64 -180.0 -171.0 ... 171.0 180.0
Data variables:temperature (time, lat, lon) float64 0.4321 0.8765 ...humidity (time, lat, lon) float64 0.5432 0.9876 ...
五、數據可視化
表:可視化方法
| 操作/方法 | 功能 | 輸入參數 | 輸出參數 |
|---|---|---|---|
.plot() | 快速可視化(等值線圖、色階圖) | x, y: 維度名;cbar_kwargs: 顏色條參數;transform: 投影轉換 | matplotlib.axes.Axes 對象 |
.plot.scatter() | 散點圖可視化 | x, y: 維度名;c: 顏色變量;size: 點大小 | matplotlib.axes.Axes 對象 |
- 示例代碼
# 繪制等值線圖
da.plot.contourf(x="lon", y="lat", cmap="viridis")# 繪制散點圖
da.plot.scatter(x="lon", y="lat", c="temperature", size="precipitation")
(一)二維分布圖
# 繪制溫度的空間分布
ds["temp"].isel(time=0).plot(cmap="viridis")
plt.title("Temperature Distribution")
plt.show()
(二)時間序列圖
# 繪制單個網格點的時間序列
ds["temp"].sel(lat=40, lon=100).plot.line(x="time")
plt.title("Temperature Time Series")
plt.show()
六、高級功能
(一) 缺失值處理
1. 填充缺失值
# 用 0 填充缺失值
filled_temp = ds["temp"].fillna(0)
2. 插值
# 使用線性插值填充缺失值
interpolated = ds["temp"].interpolate_na(dim="lat", method="linear")
(二) 時間重采樣
# 將日數據重采樣為月均值
monthly_mean = ds.resample(time="1M").mean()
(三)地理信息處理
1. 設置坐標系
import rioxarray
ds.rio.write_crs("EPSG:4326", inplace=True) # 設置為 WGS84 坐標系
2. 繪制地理投影圖
import cartopy.crs as ccrs
ax = plt.axes(projection=ccrs.PlateCarree())
ds["temp"].isel(time=0).plot(ax=ax, transform=ccrs.PlateCarree())
ax.coastlines()
plt.show()
七、數據輸入與輸出
表:NetCDF 讀取與保存
| 操作/方法 | 功能 | 輸入參數 | 輸出參數 |
|---|---|---|---|
xr.open_dataset | 讀取單個 NetCDF 文件 | filename: 文件路徑;engine: 讀取引擎(如 netcdf4) | xarray.Dataset 對象 |
xr.to_netcdf | 保存數據為 NetCDF 文件 | filename: 保存路徑;mode: 寫入模式(如 w 表示覆蓋) | 無返回值(直接寫入文件) |
xr.open_mfdataset | 批量讀取多文件數據集 | paths: 文件路徑列表;engine: 讀取引擎(如 h5netcdf);parallel: 是否并行讀取;preprocess: 預處理函數 | 合并后的 xarray.Dataset |
xr.save_mfdataset | 批量保存數據集到文件 | datasets: 數據集列表;paths: 保存路徑列表;encoding: 變量編碼參數(如壓縮設置) | 無返回值(直接寫入文件) |
(一)讀取 NetCDF 文件
ds = xr.open_dataset("data.nc") # 讀取單個文件
ds = xr.open_mfdataset("data/*.nc", combine="by_coords") # 合并多個文件
示例代碼
# 批量讀取 NetCDF 文件
import xarray as xr
ds = xr.open_mfdataset("data/*.nc", engine="h5netcdf", parallel=True)# 批量保存數據集
xr.save_mfdataset([ds1, ds2], ["output1.nc", "output2.nc"], encoding={var: {"zlib": True}})
(二)保存數據
# 保存為 NetCDF 文件并啟用壓縮
ds.to_netcdf("output.nc", encoding={"temp": {"zlib": True}})
八、性能優化
表:數據分塊與性能優化
| 操作/方法 | 功能 | 輸入參數 | 輸出參數 |
|---|---|---|---|
.chunk() | 設置數據分塊大小 | chunks: 分塊字典(如 {"time": 10, "lat": 100}) | 帶分塊的 xarray.DataArray |
.compute() | 觸發延遲計算 | 無 | 實際計算結果(xarray.DataArray 或 xarray.Dataset) |
(一)分塊處理(Dask)
import dask.array as da
ds = ds.chunk({"time": 10}) # 將時間維度分塊
(二) 內存優化
- 使用
.persist()或.compute()控制計算時機。 - 避免不必要的中間變量。
示例代碼
# 設置分塊
da_chunked = da.chunk({"time": 10, "lat": 100})# 觸發計算
result = da_chunked.mean().compute()
九、總結
(一)核心流程
- 讀取數據 → 2. 訪問變量 → 3. 選擇/切片 → 4. 計算/分析 → 5. 保存/可視化
(二)關鍵優勢
- 標簽化操作:通過維度名和坐標直接訪問數據。
- 高效處理:支持多維數據、地理信息和大文件分塊。
- 易用性:與 Pandas、Matplotlib 無縫集成。
(三)注意事項
- 使用
.sel()和.isel()時注意維度名稱和索引范圍。 - 大數據集需結合 Dask 分塊處理(
.chunk())。 - 保存時啟用壓縮(
zlib=True)可減少文件體積。







)


)



)
Handler消息處理機制原理)
)
)

