目錄
一、數據庫 order by
二、Redis 的zset
三、抗億級數據存在的問題
3.1 熱點 key 問題
3.1.1 多級緩存(Redis+JVM本地緩存)
3.1.2?讀寫分離 + 從庫負載均衡
3.1.3?分片Key設計
3.2?內存爆炸
3.2.1?縮短鍵名
3.2.2?分片存儲
3.3?數據持久化風險
3.3.1?異步雙寫
3.3.2?混合持久化
一、數據庫 order by
1. 在表數據較少的情況下,推薦使用該做法
2. 如果在數據量比較多的情況下(億級用戶+高并發實時更新):磁盤扛不住、排序算不動、并發撐不起
select?*?from?user_info order?by?step?desc?二、Redis 的zset
當數據量較大且需要實時更新并頻繁查詢時,使用 Redis 的zset有序集合更為適合。zset是?Redis?提供的一種數據結構,它類似于集合(set),但每個成員都關聯著一個分數(score),Redis 使用這個分數來對集合中的成員進行排序。
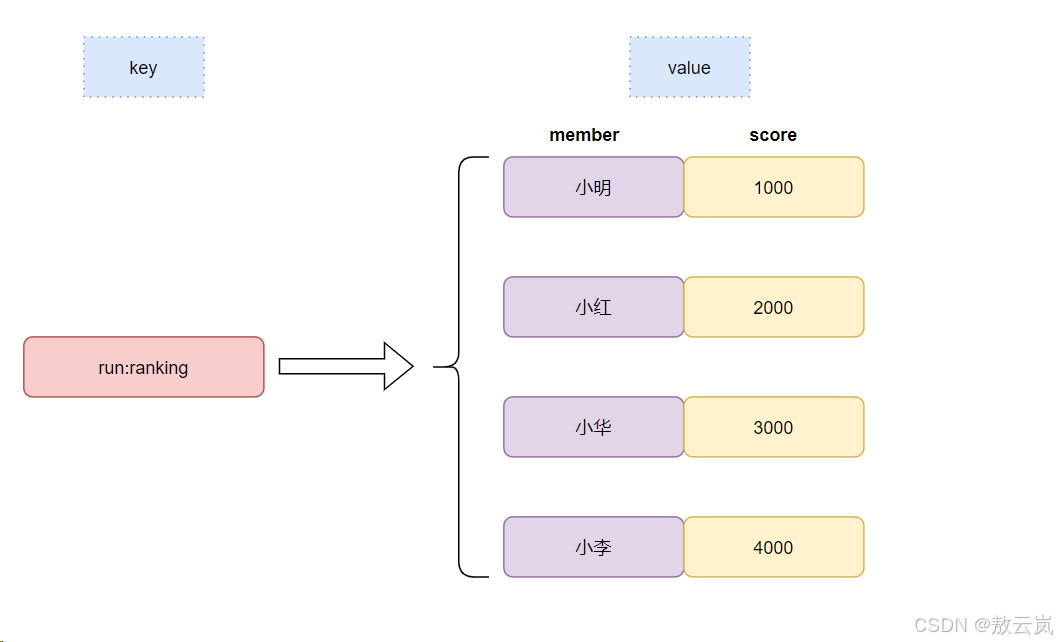 不僅僅是redis的zset支持排序,API簡單易用,還因為redis的排序快(基于內存存儲)、可擴展性強(通過分片存儲可以將數據拆分到多個實例)、能輕松應對高并發(單線程+IO多路復用+內存操作)。
不僅僅是redis的zset支持排序,API簡單易用,還因為redis的排序快(基于內存存儲)、可擴展性強(通過分片存儲可以將數據拆分到多個實例)、能輕松應對高并發(單線程+IO多路復用+內存操作)。
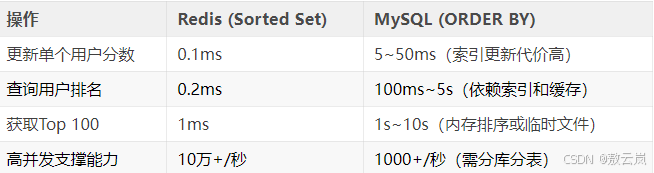
性能對比:
三、抗億級數據存在的問題
3.1 熱點 key 問題
全服玩家頻繁查詢 ZREVRANGE leaderboard 0 99(獲取Top 100),導致所有請求集中訪問 同一個Key(leaderboard)。容易導致單分片CPU和帶寬被打滿(假設數據分片不均勻)。極端情況下Redis實例崩潰,全服排行榜癱瘓
3.1.1 多級緩存(Redis+JVM本地緩存)
-
請求優先讀本地內存緩存
-
緩存未命中時讀Redis集群
-
Redis集群內部緩存Top 100(設置更短TTL)
3.1.2?讀寫分離 + 從庫負載均衡
主庫處理寫請求(更新分數)。多個從庫輪詢處理讀請求(查Top 100)
3.1.3?分片Key設計
操作:將排行榜按分數區間拆分成多個Key,例如:
-
leaderboard:top1(前100名)
-
leaderboard:top2(101~1000名)
-
leaderboard:rest(其他用戶)
查詢邏輯:查Top 100時,只需訪問 leaderboard:top1。
3.2?內存爆炸
存儲1億用戶,若每個鍵占32字節(如 user:123),僅鍵就需約3.2GB,加上分數和指針,內存壓力巨大。
3.2.1?縮短鍵名
縮短鍵名:將 user:123 轉換為整數(如123),利用 Redis 的 int 編碼優化內存。
3.2.2?分片存儲
分片存儲:按用戶ID哈希分片到多個 Redis 實例,分散壓力。
3.3?數據持久化風險
Redis 宕機可能導致最新數據丟失(即使開啟AOF,默認每秒同步一次)。
3.3.1?異步雙寫
異步雙寫:更新分數時,同步寫入 Kafka,由消費者異步落庫 MySQL,用于故障恢復。
3.3.2?混合持久化
混合持久化:開啟 RDB + AOF,平衡恢復速度與數據完整性。
)
)

享元模式)















